 CompletableFuture异步IO密集型任务最佳实践
CompletableFuture异步IO密集型任务最佳实践
# 写在文章开头
CompletableFuture相比于jdk8所内置的并行流,处理并发的IO密集型任务有着如下两大优势:
- 在流式处理下,构建即启动,回调即可获取
- 支持提交到自定义线程池,方便针对性动态调整线程池参数
所以本文将基于一个多商品查询的案例,演示一下CompletableFuture实践技巧,希望对你有所帮助。
你好,我是 SharkChili ,禅与计算机程序设计艺术布道者,希望我的理念对您有所启发。
📝 我的公众号:写代码的SharkChili
在这里,我会分享技术干货、编程思考与开源项目实践。
🚀 我的开源项目:mini-redis
一个用于教学理解的 Redis 精简实现,欢迎 Star & Contribute:
https://github.com/shark-ctrl/mini-redis (opens new window)
👥 欢迎加入读者群
关注公众号,回复 【加群】 即可获取联系方式,期待与你交流技术、共同成长!
# 详解CompletableFuture多任务并行查询实践
# 案例说明
本文所有案例都会基于这样的一个需求,某网站有多个商家,用户会在不同的店铺查看同一件商品进行货比三家的过程,只要用户在提供给商店对应的产品名称,商店就会返回对应产品的最终价格。
同时这个案例有几个注意点:
- 每次到一家商店查询时,同一时间只能查询一个商品。
- 允许用户同一时间在系统里查询多个商店的一个商品。
- 查询的商品售价是需要耗时的,平均
500ms-2500ms不等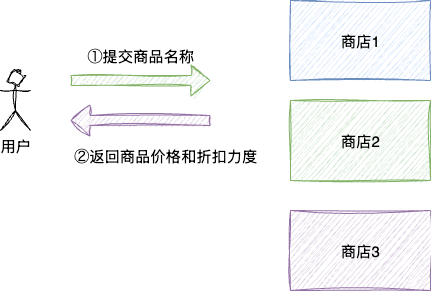
考虑到商品查询和耗时以及展示CompletableFuture所带来直观的提升,笔者后文会分别以串行、并行流、CompletableFuture三种方式执行商品查询逻辑。
# 案例涉及相关实体代码
为了方便后续更直观了解核心逻辑的实现,笔者专门借此篇幅说明一下案例中所涉及的实体代码,首先是商店类,对应要点为:
- 该实体通过name初始化商店方便后续案例的区分
- 支持传入商品名称获取折扣后的价格
- 查询商品的函数getPrice实际是通过calculatePrice获取价格
- 为了模拟慢查询用到了随机休眠的方法
对应代码示例如下,读者可结合注释理解这个重要实体类:
/**
* 商店实体,传入商品计算价格
*/
@Data
public class Shop {
private final String name;
public Shop(String name) {
this.name = name;
}
/**
* 传入产品名称返回对应价格
*/
public double getPrice(String product) {
double price = calculatePrice(product);
return price;
}
/**
* 获取商品价格
*/
public double calculatePrice(String product) {
try {
TimeUnit.MILLISECONDS.sleep(RandomUtil.randomInt(500, 2500));
} catch (InterruptedException e) {
e.printStackTrace();
}
return RandomUtil.randomDouble();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
明确商店实体信息后,我们不妨初始化一份商店列表演示后续的查询逻辑:
private final static List<Shop> shops = Arrays.asList(new Shop("Nike"),
new Shop("Apple"),
new Shop("Coca-Cola"),
new Shop("Amazon"),
new Shop("Samsung"),
new Shop("McDonald's"),
new Shop("Mercedes-Benz"),
new Shop("Google"),
new Shop("Louis Vuitton"),
new Shop("Chanel"),
new Shop("Gucci"),
new Shop("Adidas"),
new Shop("Pepsi"),
new Shop("Ford"),
new Shop("Microsoft"),
new Shop("Rolex"),
new Shop("Ferrari"),
new Shop("IKEA")
);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 基于顺序流
第一版我们先用顺序流实现改需求,代码很简单用stream遍历商家并调用getPrice获得结果,最终存到List中。
long begin = System.currentTimeMillis();
List<String> resultList = shops.stream()
.map(shop -> shop.getName() + " price is " + shop.getPrice("Air Jordan shoes"))
.collect(Collectors.toList());
long end = System.currentTimeMillis();
System.out.println("执行结束 执行耗时:" + (end - begin) + "ms");
2
3
4
5
6
最终输出结果如下,整个查询耗时将近30s:

# 基于并行流
对此我们采用并行流尝试以多线程的形式执行任务,所以我们基于上述示例将stream改为parallelStream:
long begin = System.currentTimeMillis();
List<String> resultList = shops.parallelStream()
.map(shop -> shop.getName() + " price is " + shop.getPrice("Air Jordan shoes"))
.collect(Collectors.toList());
long end = System.currentTimeMillis();
System.out.println("执行结束 执行耗时:" + (end - begin) + "ms");
2
3
4
5
6
可以看到耗时仅仅5s,这里补充一下笔者的机器信息,笔者的CPU是10核的,所以并行流执行时会有10个线程并行工作,耗时差不多4s左右:

# 基于CompletableFuture执行异步多查询任务
我们给出了CompletableFuture执行多IO查询任务的代码示例,可以看到代码的执行流程大致为:
- 遍历商家构建异步任务CompletableFuture
- 提交异步查询任务
- 调用join(),注意这里的join和CompletableFuture的get方法作用是一样的,都是阻塞获取查询结果,唯一的区别就是join方法签名没有抛异常,所以无需try-catch处理:
long begin = System.currentTimeMillis();
List<String> resultList = shops.stream()
.map(shop -> CompletableFuture.supplyAsync(() -> shop.getName() + " price is "
+ shop.getPrice("Air Jordan")))//CompletableFuture提交价格查询任务
.map(CompletableFuture::join) //用join阻塞获取结果
.collect(Collectors.toList());//组成列表
long end = System.currentTimeMillis();
System.out.println("执行结束, 执行耗时:" + (end - begin) + "ms");
2
3
4
5
6
7
8
最终执行结果也比较以外,整体耗时为31s,查询效率还不如顺序流:
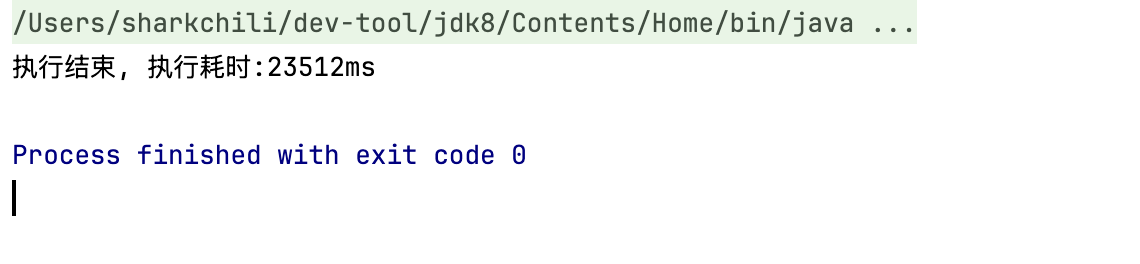
执行分析推导上述数据流的编写可以看出,虽然我们构建了异步任务CompletableFuture并提交,但是后续的join操作将stream顺序流阻塞,这使得原本应该连续提交的异步任务需要等到join操作结束后才能构建提交:
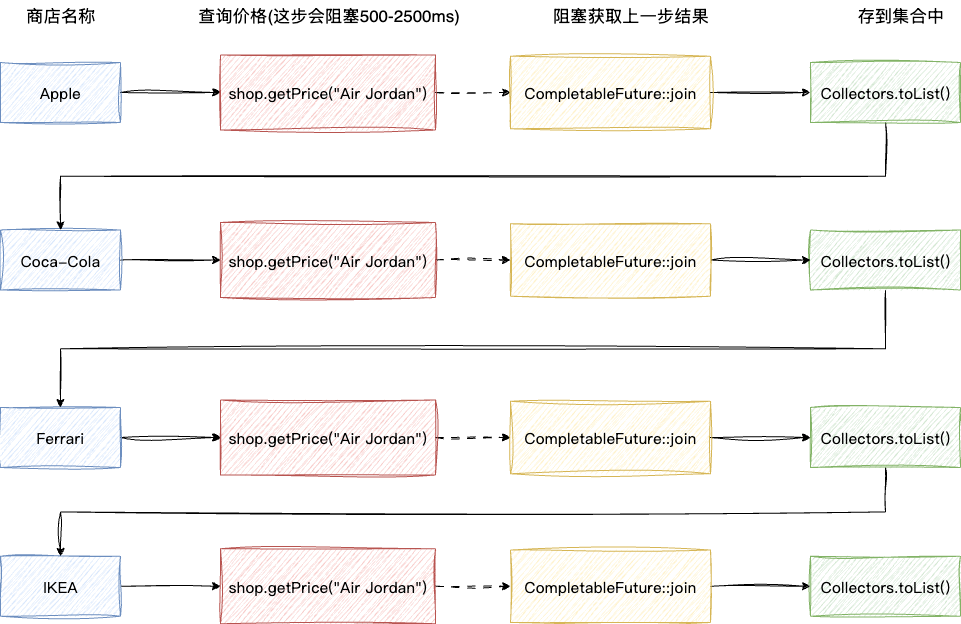
# 分解流优化使用CompletableFuture
上述我们提到过,之所以慢是因为join阻塞了流的操作,所以提升效率的方式就是不要让join阻塞流的操作。所以笔者将流拆成了两个。 如下图,第一个流负责顺序提交任务,即遍历每一个商家并将查询价格的任务提交出去,期间不阻塞,最终会生成一个CompletableFuture的列表,可以理解为需要获取结果的任务清单。
紧接着我们遍历上一个流生成的List<CompletableFuture>,调用join方法阻塞获取结果,因为上一个流操作提交任务时不阻塞,所以每个任务一提交时就可能已经在执行了,所以join方法获取结果的耗时也会相对短一些。
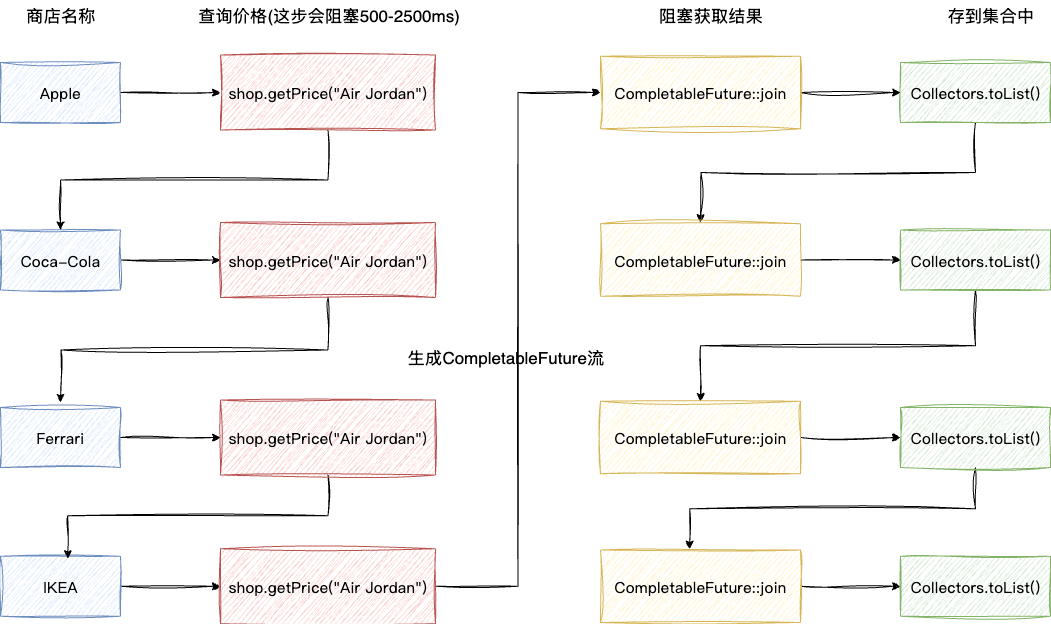
所以我们的代码最后改造成了这样:
public static void main(String[] args) {
long begin = System.currentTimeMillis();
List<CompletableFuture<String>> completableFutureList = shops.stream()
.map(shop -> CompletableFuture.supplyAsync(() -> shop.getName() + " price is " + shop.getPrice("Air Jordan")))//构建异步任务
.collect(Collectors.toList());//生成异步任务列表
//顺序获取结果
List<String> resultList = completableFutureList.stream()
.map(CompletableFuture::join) //用join阻塞获取结果
.collect(Collectors.toList());//组成列表
long end = System.currentTimeMillis();
long end = System.currentTimeMillis();
System.out.println("执行结束,执行结果:" + JSONUtil.toJsonStr(resultList) + " 执行耗时:" + (end - begin) + "ms");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
执行结果如下,可以看到代码耗时差不多也是4s和并行流差不多,原因很简单,线程池默认用10个,对于IO密集型任务来说显然是不够的:
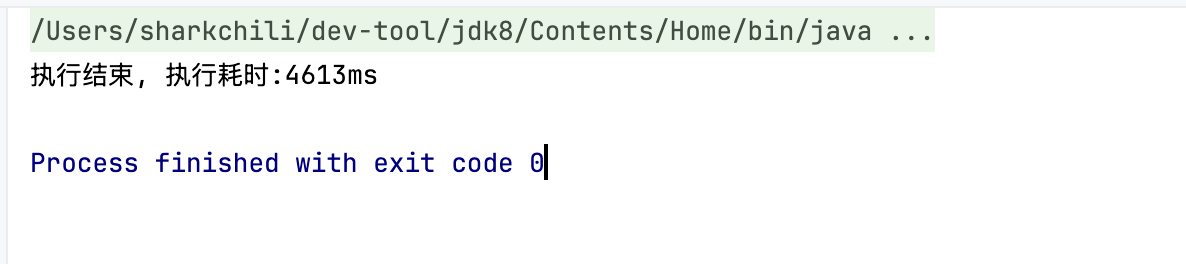
# CompletableFuture使用自定义线程池
《Java并发编程实战》一书中,Brian Goetz和合著者们为线程池大小的优化提供了不少中肯的建议。这非常重要,如果线程池中线程的数量过多,最终它们会竞争稀缺的处理器和内存资源,浪费大量的时间在上下文切换上。反之,如果线程的数目过少,正如你的应用所面临的 情况,处理器的一些核可能就无法充分利用。BrianGoetz建议,线程池大小与处理器的利用率 之比可以使用下面的公式进行估算: N(threads) = N(CPU)* U(CPU) * (1+ W/C) 其中: N(CPU)是处理器的核的数目,可以通过 Runtime.getRuntime().available Processors() 得到。 U(CPU)是期望的 CPU利用率(该值应该介于 0和 1之间) W/C是等待时间与计算时间的比率。
我们的CPU核心数为10,我们希望的CPU利用率为1,而等待时间按照这种的计算应该是1250ms而计算时间可以忽略不计,所以W/C差不多可以换算为1000。 最终我们计算结果为:
N(threads) = N(CPU)* U(CPU) * (1+ W/C)
= 10*1*1000
= 1_0000
2
3
很明显1_0000个线程非常不合理,原因如下:
- 这是基于CPU 100%利用率推算出来的估值,不符合实际项目需求。
- 当前项目用户请求量不大,可能一天只有几个用户进行这种查询。
- 6000这个线程数实际上大部分线程都不会被用到(因为当前项目只有18家商店)。
所以我们使用了和商店数差不多的线程数,所以我们将线程设置为18(这也是个大概的数字,具体情况还需要经过压测进行增减)。
最终代码写成这样。
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(20,
20,
1,
TimeUnit.MINUTES,
new ArrayBlockingQueue<>(100),
new ThreadFactoryBuilder().setNamePrefix("threadPool-%d").build());
long begin = System.currentTimeMillis();
List<CompletableFuture<String>> completableFutureList = shops.stream()
.map(shop -> CompletableFuture.supplyAsync(() -> shop.getName() + " price is " + shop.getPrice("Air Jordan"), threadPool))//构建异步任务,并制指定自定义线程池
.collect(Collectors.toList());//生成异步任务列表
//顺序获取结果
List<String> resultList = completableFutureList.stream()
.map(CompletableFuture::join) //用join阻塞获取结果
.collect(Collectors.toList());//组成列表
long end = System.currentTimeMillis();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
输出结果如下,可以看到,因为我们针对IO密集型任务调大了线程池数量,确保IO阻塞期间CPU时间片可以执行别的线程商品查询任务,由此提升CPU利用率,最终将耗时压降到3s左右:

实际上,上述案例解决了流式任务阻塞的问题,我们还可以通过并行流的方式实现并行构建任务和并行获取结果:
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(20,
20,
1,
TimeUnit.MINUTES,
new ArrayBlockingQueue<>(100),
new ThreadFactoryBuilder().setNamePrefix("threadPool-%d").build());
long begin = System.currentTimeMillis();
List<CompletableFuture<String>> completableFutureList = shops.parallelStream()
.map(shop -> CompletableFuture.supplyAsync(() -> shop.getName() + " price is " + shop.getPrice("Air Jordan"), threadPool))//构建异步任务,并制指定自定义线程池
.collect(Collectors.toList());//生成异步任务列表
//顺序获取结果
List<String> resultList = completableFutureList.parallelStream()
.map(CompletableFuture::join) //用join阻塞获取结果
.collect(Collectors.toList());//组成列表
long end = System.currentTimeMillis();
System.out.println("执行结束, 执行耗时:" + (end - begin) + "ms");
//停止线程池
threadPool.shutdownNow();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 并行流一定比CompletableFuture烂吗?
如果是计算密集型的任务,使用stream是最佳姿势,因为密集型需要一直计算,加多少个线程都无济于事,使用stream简单使用了。 而对于io密集型的任务,例如上文这种大量查询都需要干等的任务,使用CompletableFuture是最佳姿势了,通过自定义线程创建比cpu核心数更多的线程来提高工作效率才是较好的解决方案
# 小结
本文基于一个商品慢查询案例逐步推进演示了多核操作系统下并行查询的作用,同时结合流式编程演示了CompletableFuture异步查询最佳实践技巧要点,即:
- 构建任务不阻塞
- 阻塞获取正确回归
- 结合硬件系统调优线程池,最大粒度压榨CPU利用率
你好,我是 SharkChili ,禅与计算机程序设计艺术布道者,希望我的理念对您有所启发。
📝 我的公众号:写代码的SharkChili
在这里,我会分享技术干货、编程思考与开源项目实践。
🚀 我的开源项目:mini-redis
一个用于教学理解的 Redis 精简实现,欢迎 Star & Contribute:
https://github.com/shark-ctrl/mini-redis (opens new window)
👥 欢迎加入读者群
关注公众号,回复 【加群】 即可获取联系方式,期待与你交流技术、共同成长!
# 参考
Java 8实战:https://book.douban.com/subject/26772632/ (opens new window)
- 02
- Spring AI Alibaba深度实战:一文掌握智能体开发全流程03-04
- 03
- 告别AI无效对话:资深工程师的提示词设计最佳实践02-07
