 浅谈Java线程池中拒绝策略与流控的艺术
浅谈Java线程池中拒绝策略与流控的艺术
# 写在文章开头
收到不少读者反馈,其中有这几道关于线程池的问题:
- 在进行线程池设计时,如何选择拒绝策略?
- 如果不允许丢弃任务任务,应该选择哪个拒绝策略?
- 使用
CallerRunsPolicy这个拒绝策略有什么风险?有没有更好的处理方式呢?
基于此问题,笔者就从源码和实践的角度来探讨一下Java线程池中的拒绝策略和流控的运用理念和使用技巧。
我是 SharkChili ,Java 开发者,Java Guide 开源项目维护者。欢迎关注我的公众号:写代码的SharkChili,也欢迎您了解我的开源项目 mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)。
为方便与读者交流,现已创建读者群。关注上方公众号获取我的联系方式,添加时备注加群即可加入。
# 详解拒绝策略常见问题
# 线程池是如何工作的
每次任务提交时,线程池都会尝试将任务提交到核心线程上,如果线程数小于核心线程数,线程池就会添加工作线程并执行当前任务。 若核心线程都处于工作状态,这就表明当前线程池有些忙碌,那么这些无法及时处理的任务就会提交到阻塞任务队列中。 随着任务的递增,任务队列无法容纳最新的任务,线程池就会认为现处于高峰期,便临时增加应急线程处理任务。随着任务逐步处理完成,线程在指定时间内没有要处理的任务,这些线程也就会依次退出。
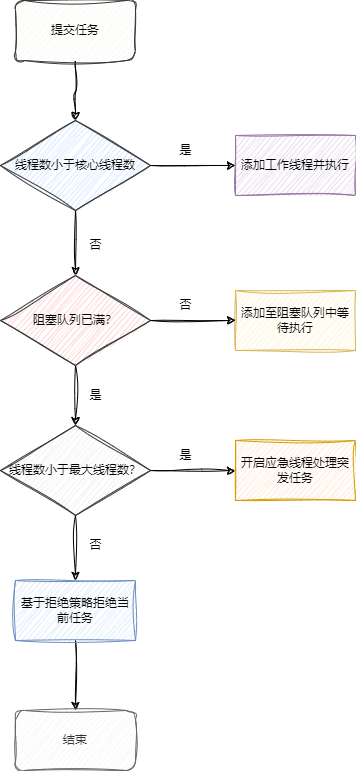
对应我们也给出ThreadPoolExecutor提交任务的execute方法的源码:
public void execute(Runnable command) {
//任务判空
if (command == null)
throw new NullPointerException();
//查看当前运行的线程数量
int c = ctl.get();
//若小于核心线程则直接添加一个工作线程并执行任务
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
//如果线程数等于核心线程数则尝试将任务入队
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//入队失败,调用addWorker参数为false,尝试创建应急线程处理突发任务
else if (!addWorker(command, false))
//如果创建应急线程失败,说明当前线程数已经大于最大线程数,这个任务只能拒绝了
reject(command);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
上文提到了应急线程长时间没有要处理的任务就会被销毁的逻辑,这里我们也简单的介绍一下,首先在线程池中每一个线程是以Worker的形式封装呈现,其本质就是对Thread的封装,Worker启动后会调用run方法调用runWorker方法轮询处理任务:
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
final Thread thread;
/** Delegates main run loop to outer runWorker */
public void run() {
runWorker(this);
}
//......
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
查看runWorker方法,一旦在规定时间内getTask没有拿到任务就会退出循环,直接通过processWorkerExit结束这个工作线程:
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
//对应时间内没有拿到task则退出循环
while (task != null || (task = getTask()) != null) {
//略
}
completedAbruptly = false;
} finally {
//结束这个工作线程
processWorkerExit(w, completedAbruptly);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
自此,我们将线程池整体工作流程简单的梳理完毕。
# 拒绝策略的选择
先来说说第一道题,关于拒绝策略的选择,我们不妨直接查看RejectedExecutionHandler 子类的源码进行说明。
先来看看CallerRunsPolicy ,该拒绝策略会直接用当前调用者执行当前任务:
public static class CallerRunsPolicy implements RejectedExecutionHandler {
public CallerRunsPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
//直接基于当前线程调用run方法执行任务
r.run();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
然后就是AbortPolicy,也很简单,直接抛异常:
public static class AbortPolicy implements RejectedExecutionHandler {
/**
* Creates an {@code AbortPolicy}.
*/
public AbortPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}
2
3
4
5
6
7
8
9
10
11
12
13
DiscardPolicy 则是什么也不做,这也就意味着这个任务没有任务处理,等同于丢弃:
public static class DiscardPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code DiscardPolicy}.
*/
public DiscardPolicy() { }
//不做任何事情任务直接丢弃
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}
2
3
4
5
6
7
8
9
10
最后一个就是DiscardOldestPolicy ,该策略会将队首部任务丢弃,然后尝试将再次execute这个任务:
public static class DiscardOldestPolicy implements RejectedExecutionHandler {
public DiscardOldestPolicy() { }
//丢掉队首的任务,然后往线程池提交当前任务
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
不同拒绝策略都有着不同的使用场景:
- 如果我们的任务不算耗时还要保证能够被执行,那么
CallerRunsPolicy则是第一选择。 - 若突增大量任务导致无法及时处理从业务的角度认为是异常的话,那么我们则建议抛出
AbortPolicy让开发介入及时调优处理,前提是当前业务正处于业务提测阶段。 - 对于那些需要提交实时性消息的监控型任务,那么新提交的任务势必实时性会由于更早的任务,这种场景使用
DiscardOldestPolicy即可。 - 如果这些任务相较于系统可靠性来说,如果不是很重要,那么直接采用
rejectedExecution丢弃任务即可。
# 主流框架对于拒绝策略的选择
只要继承RejectedExecutionHandler 就可以实现相应的拒绝策略,所以我们也不妨看看一些主流的框架是如何使用拒绝策略的吧。
tomcat线程池的拒绝策略也是抛出异常:
private static class RejectHandler implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r,
java.util.concurrent.ThreadPoolExecutor executor) {
throw new RejectedExecutionException();
}
}
2
3
4
5
6
7
8
而Dubbo则相对友好一些,它会优先打印一个日志,并告知异常堆栈信息,然后抛出异常:
public class AbortPolicyWithReport extends ThreadPoolExecutor.AbortPolicy {
//......
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
String msg = String.format("Thread pool is EXHAUSTED!" +
" Thread Name: %s, Pool Size: %d (active: %d, core: %d, max: %d, largest: %d), Task: %d (completed: %d)," +
" Executor status:(isShutdown:%s, isTerminated:%s, isTerminating:%s), in %s://%s:%d!",
threadName, e.getPoolSize(), e.getActiveCount(), e.getCorePoolSize(), e.getMaximumPoolSize(), e.getLargestPoolSize(),
e.getTaskCount(), e.getCompletedTaskCount(), e.isShutdown(), e.isTerminated(), e.isTerminating(),
url.getProtocol(), url.getIp(), url.getPort());
logger.warn(msg);
dumpJStack();
throw new RejectedExecutionException(msg);
}
private void dumpJStack() {
//省略实现
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
Netty就相对稳健一些,它的拒绝策略则是直接创建一个线程池以外的线程处理这些任务,为了保证任务的实时处理,这种做法可能需要良好的硬件设备且临时创建的线程无法做到准确的监控:
private static final class NewThreadRunsPolicy implements RejectedExecutionHandler {
NewThreadRunsPolicy() {
super();
}
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
try {
final Thread t = new Thread(r, "Temporary task executor");
t.start();
} catch (Throwable e) {
throw new RejectedExecutionException(
"Failed to start a new thread", e);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
ActiveMq则是尝试在指定的时效内尽可能的争取将任务入队,以保证最大交付:
new RejectedExecutionHandler() {
@Override
public void rejectedExecution(final Runnable r, final ThreadPoolExecutor executor) {
try {
executor.getQueue().offer(r, 60, TimeUnit.SECONDS);
} catch (InterruptedException e) {
throw new RejectedExecutionException("Interrupted waiting for BrokerService.worker");
}
throw new RejectedExecutionException("Timed Out while attempting to enqueue Task.");
}
});
2
3
4
5
6
7
8
9
10
11
# CallerRunsPolicy存在的问题及解决对策
默认情况下,我们都会为了保证任务不被丢弃都优先考虑CallerRunsPolicy,这也是相对维稳的做法,这种做法的隐患是假设走到CallerRunsPolicy的任务是个非常耗时的任务,就会导致主线程就很卡死。
下面就是笔者通过主线程使用线程池的方法,该线程池限定了最大线程数为2还有阻塞队列大小为1,这意味着第4个任务就会走到拒绝策略:
//创建线程池
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(1,
2,
60,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(1),
new ThreadPoolExecutor.CallerRunsPolicy());
threadPoolExecutor.execute(() -> {
log.info("核心线程执行");
ThreadUtil.sleep(1, TimeUnit.DAYS);
});
threadPoolExecutor.execute(() -> {
log.info("任务入队");
ThreadUtil.sleep(1, TimeUnit.DAYS);
});
threadPoolExecutor.execute(() -> {
log.info("应急线程处理");
ThreadUtil.sleep(1, TimeUnit.DAYS);
});
threadPoolExecutor.execute(() -> {
log.info("CallerRunsPolicy task");
ThreadUtil.sleep(1, TimeUnit.DAYS);
});
threadPoolExecutor.execute(() -> {
log.info("因为主线程卡住,无法被处理的任务");
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
从输出结果可以看出,因为CallerRunsPolicy这个拒绝策略,导致耗时的任务用了主线程执行,导致线程池阻塞,进而导致后续任务无法及时执行,严重的情况下很可能导致OOM:
2024-04-03 00:08:12.617 INFO 20804 --- [ main] com.sharkChili.ThreadPoolApplication : 启动成功!!
2024-04-03 00:08:15.739 INFO 20804 --- [pool-1-thread-1] com.sharkChili.ThreadPoolApplication : 核心线程执行
2024-04-03 00:08:36.768 INFO 20804 --- [pool-1-thread-2] com.sharkChili.ThreadPoolApplication : 应急线程处理
2024-04-03 00:08:49.333 INFO 20804 --- [ main] com.sharkChili.ThreadPoolApplication : CallerRunsPolicy task
2
3
4
我们从问题的本质入手,调用者采用CallerRunsPolicy是希望所有的任务都能够被执行,按照笔者的经验,假如我们的场景是偶发这种突发场景,在内存允许的情况下,我们建议增加阻塞队列BlockingQueue的大小并调整堆内存以容纳更多的任务,确保任务能够被准确执行。
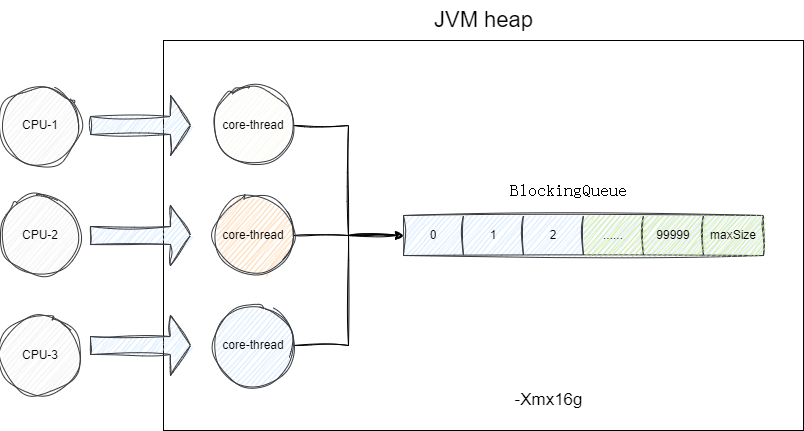
若当前服务器内存资源紧张,但我们配置线程池还为尽可能利用到CPU,我们建议调整线程中maximumPoolSize以保证尽可能压榨CPU资源:
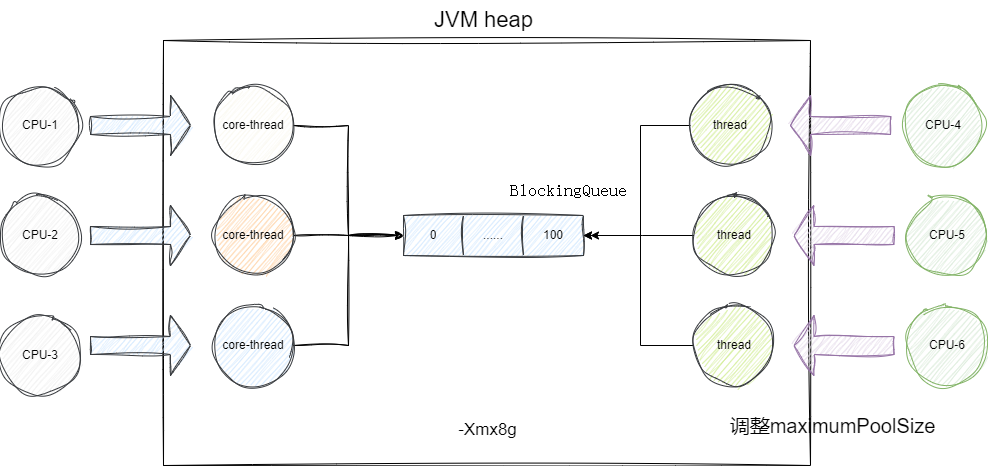
如果服务器资源达到可利用的极限,这就意味我们要在设计策略上改变线程池的调度了,我们都知道,导致主线程卡死的本质就是因为我们不希望任何一个任务被丢弃。换个思路,有没有办法既能保证任务不被丢弃且在服务器有余力时及时处理呢?
这里笔者提供的一种思路,即任务持久化,注意这里笔者更多强调的是思路而不是实现,这里所谓的任务持久化,包括但不限于:
- 设计一张任务表间任务存储到
MySQL数据库中。 Redis缓存任务。- 将任务提交到消息队列中。
笔者以方案一为例,通过继承BlockingQueue实现一个混合式阻塞队列,该队列包含JDK自带的ArrayBlockingQueue和一个自定义的队列(数据表),通过魔改队列的添加逻辑达到任务可以存入ArrayBlockingQueue或者数据表的目的。
如此一来,一旦我们的线程池中线程达到满载时,我们就可以通过拒绝策略将最新任务持久化到MySQL数据库中,等到线程池有了有余力处理所有任务时,让其优先处理数据库中的任务以避免"饥饿"问题。
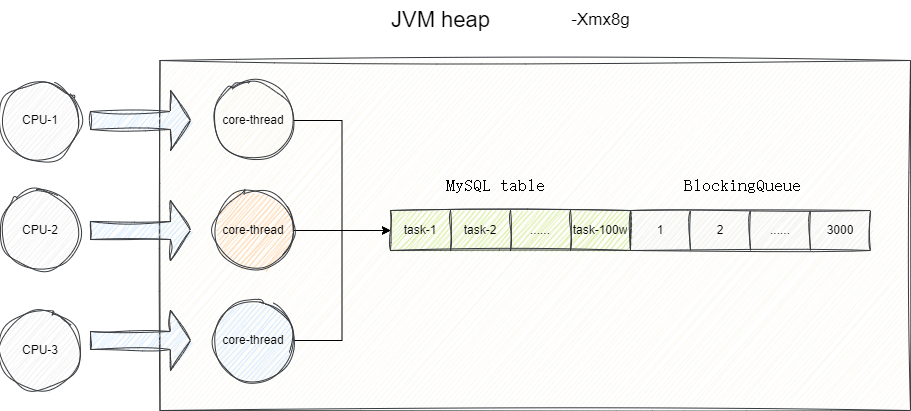
这里笔者也给出混合队列实现的核心源码,即通过继承BlockingQueue魔改了入队和出队的逻辑:
public class HybridBlockingQueue<E> implements BlockingQueue<E> {
private Object mysqlLock = new Object();
private ArrayBlockingQueue<E> arrayBlockingQueue;
//构造方法初始化阻塞队列大小
public HybridBlockingQueue(int maxSize) {
arrayBlockingQueue = new ArrayBlockingQueue<>(maxSize);
}
/**
* 线程池会调用的入队方法
* @param e
* @return
*/
@Override
public boolean offer(E e) {
return arrayBlockingQueue.offer(e);
}
/**
* 取任务时,优先从数据库中读取最早的任务
*
* @return
* @throws InterruptedException
*/
@Override
public E take() throws InterruptedException {
synchronized (mysqlLock) {
//从数据库中读取任务,通过上锁读取避免重复消费
TaskInfoMapper taskMapper = SpringUtil.getBean(TaskInfoMapper.class);
TaskInfo taskInfo = taskMapper.selectByExample(null).stream()
.findFirst()
.orElse(null);
//若数据库存在该任务,则先删后返回
if (ObjUtil.isNotEmpty(taskInfo)) {
taskMapper.deleteByPrimaryKey(taskInfo.getId());
Task task = new Task(taskInfo.getData());
return (E) task;
}
}
//若数据库没有要处理的任务则从内存中获取
return arrayBlockingQueue.poll();
}
/**
* 带有时间限制的任务获取
*
* @param timeout
* @param unit
* @return
* @throws InterruptedException
*/
@Override
public E poll(long timeout, TimeUnit unit) throws InterruptedException {
//从数据库中读取任务,通过上锁读取避免重复消费
synchronized (mysqlLock) {
//从数据库中读取任务,
TaskInfoMapper taskMapper = SpringUtil.getBean(TaskInfoMapper.class);
TaskInfo taskInfo = taskMapper.selectByExample(null).stream()
.findFirst()
.orElse(null);
//若数据库存在该任务,则先删后返回
if (ObjUtil.isNotEmpty(taskInfo)) {
taskMapper.deleteByPrimaryKey(taskInfo.getId());
Task task = new Task(taskInfo.getData());
return (E) task;
}
}
//若数据库没有要处理的任务则从内存中获取
return arrayBlockingQueue.poll(timeout, unit);
}
//......
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
接下来就是自定义拒绝策略了,很明显我们的拒绝策略就叫持久化策略:
public class PersistentTaskPolicy implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
//任务入库
TaskInfoMapper taskMapper = SpringUtil.getBean(TaskInfoMapper.class);
Task task = (Task) r;
TaskInfo taskInfo = new TaskInfo();
taskInfo.setData(JSONUtil.toJsonStr(task.getTaskInfo()));
taskMapper.insertSelective(taskInfo);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
最终我们的使用示例如下:
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(1,
2,
60, TimeUnit.SECONDS,
new HybridBlockingQueue<>(1),
new PersistentTaskPolicy());
threadPoolExecutor.execute(new Task("core thread"));
threadPoolExecutor.execute(new Task("queueTask"));
threadPoolExecutor.execute(new Task("max thread"));
threadPoolExecutor.execute(new Task("insert into mysql database"));
2
3
4
5
6
7
8
9
10
11
12
13
因为线程池无法及时处理而走了我们自定义的拒绝策略而持久化入库,最终我们的insert into mysql database,等待线程池中其他任务完成后被取出执行:
2024-04-14 11:30:16.865 INFO 1052 --- [ main] com.sharkChili.PersistentTaskPolicy : 任务持久化,taskInfo:{"data":"insert into mysql database"}
2024-04-14 11:31:08.516 INFO 1052 --- [pool-1-thread-2] com.sharkChili.Task : task execution completed,task info:max thread
2024-04-14 11:31:08.516 INFO 1052 --- [pool-1-thread-1] com.sharkChili.Task : task execution completed,task info:core thread
2024-04-14 11:32:08.563 INFO 1052 --- [pool-1-thread-1] com.sharkChili.Task : task execution completed,task info:queueTask
2024-04-14 11:32:08.563 INFO 1052 --- [pool-1-thread-2] com.sharkChili.Task : task execution completed,task info:insert into mysql database
2
3
4
5
# 更高维度的思考——线程池限流的艺术
上文我们以大篇幅的维度探讨拒绝策略上优化,需要保证准确、有效执行的任务能够被线程池处理,且不会破坏程序的稳定性,即提交的任务能够被正确处理且线程池不会被打死。
这一点,结合《Java并发编程实战》的说法,我们也可以利用信号量Semaphore作为令牌,确保只有拿到令牌的线程才能将任务提交到线程池,保证线程池可以在单位时间内按照我们设定的并发数执行任务:
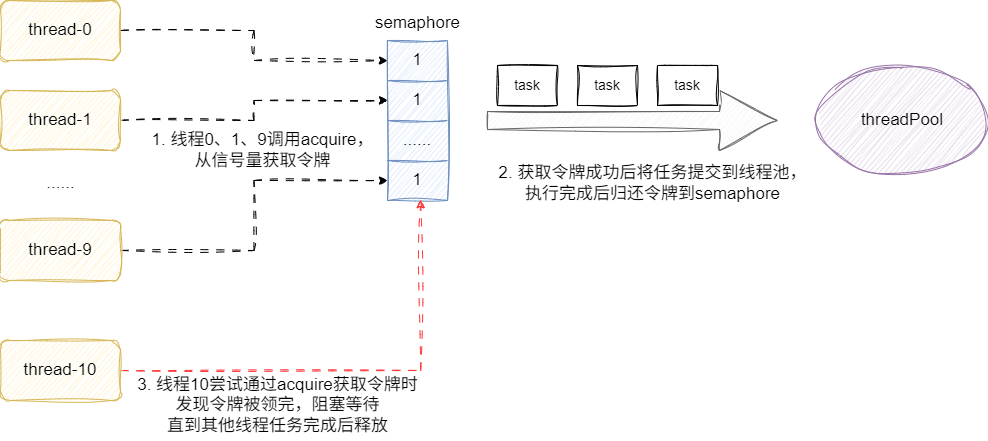
利用信号量完成线程池的限流,既保证任务可被执行和工作线程池的稳定性,又能将性能瓶颈和程序稳定性问题抛给更高层级的调用者,尤上层根据需要决定当前任务是等待被线程池处理,还是直接中断结束。
对应的我们给出流控性质的线程池代码示例,从这不难看出笔者设计流限线程池的核心要点:
- 通过外部传入的
bound决定线程池的上界。 - 同时基于
bound作为信号量数量,确保单位时间内只有bound个任务可以使用RateLimitedExecutor中的线程:
public class RateLimitedExecutor {
private final ExecutorService threadPool;
private final Semaphore semaphore;
//基于bound创建对应并发度的线程池和流控令牌
public RateLimitedExecutor(int bound) {
this.threadPool = Executors.newFixedThreadPool(bound);
this.semaphore = new Semaphore(bound, true);
}
public void submitTask(final Runnable command) throws InterruptedException {
semaphore.acquire();
Console.log("{}获取令牌成功,执行时间:{}", Thread.currentThread().getName(), DateUtil.now());
try {
threadPool.execute(() -> {
try {
//执行任务
command.run();
} finally {
//线程执行完成后释放令牌
semaphore.release();
}
});
} catch (RejectedExecutionException e) {//异常兜底
semaphore.release();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
与之对应我们再利用装饰者模式封装一个RunnableDecorator作为提交任务给RateLimitedExecutor的任务工具,其核心步骤为:
- 声明
RunnableDecorator并集成runnable获取run行为 - 将线程池和
runnable作为成员变量引入 - 通过
RunnableDecorator重写的run方法逻辑对runnable进行装饰,将runnable任务提交到流控线程池中

public class RunnableDecorator implements Runnable {
private final RateLimitedExecutor executor;
private final Runnable task;
/**
* 构造函数
*
* @param executor 执行任务的线程池, 基于bound创建对应并发度的线程池和流控令牌
* @param task 当前task需要执行的任务
*/
public RunnableDecorator(RateLimitedExecutor executor,
Runnable task) {
this.executor = executor;
this.task = task;
}
/**
* 通过装饰者模拟封装一个RunnableDecorator,将需要执行的runnable提交到流控线程池中执行
*/
@SneakyThrows
@Override
public void run() {
executor.submitTask(task);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
最后我们给出使用示例,可以看到笔者用一个循环创建大量线程用RunnableDecorator提交任务,模拟java程序中各种工作线程用RunnableDecorator作为统一入口提交任务给流控线程池的使用场景:
public static void main(String[] args) {
RateLimitedExecutor executor = new RateLimitedExecutor(5);
//用new thread提交RunnableDecorator,模拟系统中其他线程提交异步任务到我们的流控线程池
for (int i = 0; i < 10; i++) {
int finalI = i;
new Thread(new RunnableDecorator(executor, () -> {
ThreadUtil.sleep(5000);
Console.log("task-{}执行完成", finalI);
})).start();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
输出结果如下,可以看到流控符合预期为5,同时我们也将程序稳定性和性能瓶颈等各方面的压力转移给上层调用者,避免了非必要的拒绝策略处理,让线程池专注于并发度的优化:
Thread-4获取令牌成功,执行时间:2025-11-24 09:27:40
Thread-2获取令牌成功,执行时间:2025-11-24 09:27:40
Thread-0获取令牌成功,执行时间:2025-11-24 09:27:40
Thread-3获取令牌成功,执行时间:2025-11-24 09:27:40
Thread-1获取令牌成功,执行时间:2025-11-24 09:27:40
task-2执行完成
Thread-5获取令牌成功,执行时间:2025-11-24 09:27:45
task-4执行完成
task-1执行完成
task-3执行完成
task-0执行完成
Thread-6获取令牌成功,执行时间:2025-11-24 09:27:45
Thread-7获取令牌成功,执行时间:2025-11-24 09:27:45
Thread-9获取令牌成功,执行时间:2025-11-24 09:27:45
Thread-8获取令牌成功,执行时间:2025-11-24 09:27:45
task-5执行完成
task-7执行完成
task-6执行完成
task-9执行完成
task-8执行完成
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 流限线程池优化思路
当然关于流限,如果用户明确知晓超时中断的时机并具备灵活响应中断的能力,我们完全可以补充一个带有超时限制的任务提交函数trySubmitTask:
public boolean trySubmitTask(final Runnable command,
long timeout,
TimeUnit unit) throws InterruptedException {
if (!semaphore.tryAcquire(timeout, unit)) {
Console.log("{}获取令牌失败,执行时间:{}", Thread.currentThread().getName(), DateUtil.now());
return false;
}
Console.log("{}获取令牌成功,执行时间:{}", Thread.currentThread().getName(), DateUtil.now());
try {
threadPool.execute(() -> {
try {
//执行任务
command.run();
} finally {
//线程执行完成后释放令牌
semaphore.release();
}
});
} catch (RejectedExecutionException e) {//异常兜底
semaphore.release();
return false;
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
对应我们也给出使用示例:
public static void main(String[] args) {
RateLimitedExecutor executor = new RateLimitedExecutor(1);
for (int i = 0; i < 2; i++) {
new Thread(new Task("任务" + i, executor)).start();
}
}
private static class Task implements Runnable {
private final String threadName;
private final RateLimitedExecutor executor;
public Task(String threadName, RateLimitedExecutor executor) {
this.threadName = threadName;
this.executor = executor;
}
@SneakyThrows
@Override
public void run() {
executor.trySubmitTask(() -> {
ThreadUtil.sleep(5000);
Console.log("{}执行任务完成", threadName);
}, 1, TimeUnit.SECONDS);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
输出结果如下,可以看到线程1按照正确的超时等待返回了:
Thread-0获取令牌成功,执行时间:2025-07-04 09:28:27
Thread-1获取令牌失败,执行时间:2025-07-04 09:28:28
任务0执行任务完成
2
3
# 小结
针对线程池拒绝策略的设计和使用更多是考察读者对于线程池源码的理解和使用经验,这里笔者仅在思路上给出示例,当然实现上也存在很多不完美的地方,例如:
- 如何保证持久化任务被可靠消费。
- 如何保证数据库和内存中任务的公平调度。
- 持久化任务是先删后返回还是先返回处理完成后删除如何决定?
文章结束,希望对你有帮助。
我是 SharkChili ,Java 开发者,Java Guide 开源项目维护者。欢迎关注我的公众号:写代码的SharkChili,也欢迎您了解我的开源项目 mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)。
为方便与读者交流,现已创建读者群。关注上方公众号获取我的联系方式,添加时备注加群即可加入。
# 参考
线程池除了常见的4种拒绝策略:https://blog.csdn.net/huangjinjin520/article/details/103047363 (opens new window)
《Java并发编程实战》
- 01
- mini-redis SCAN指令复刻:自底向上的工程方法论实践06-08
- 03
- 重读 Redis SCAN 源码:那些当年没看懂的反向迭代细节06-01
