 深入理解Java中的final关键字
深入理解Java中的final关键字
# 写在文章开头
关于final关键字也是笔者早期整理的一篇文章,内容比较基础,所以借着假期将文章迭代一些,聊一些final关键字中的一些比较有意思的技术点,希望对你有帮助。
我是 SharkChili ,Java 开发者,Java Guide 开源项目维护者。欢迎关注我的公众号:写代码的SharkChili,也欢迎您了解我的开源项目 mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)。
为方便与读者交流,现已创建读者群。关注上方公众号获取我的联系方式,添加时备注加群即可加入。
# final关键字的不可变性
# 为什么String要用final关键字修饰
final可以保证构造时的安全初始化,从而实现不受限制的并发访问,查看String源码可以看到无论是在类声明还是存储字符串的value成员变量,都通过final符加以修饰结合构造时安全初始化:
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
//......
//安全构造,从而保证当前string类不受限制的被安全访问
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}
}
2
3
4
5
6
7
8
9
10
11
这也就是利用到final关键字的第一个关键特性——不可变性,在Java中一切皆为对象,字符串类型也是一样,所有的字符串对象也都存放在堆内存中,为了更好的做到解决堆内存空间和字符串的复用,一旦字符串类型做好了声明并完成字符串创建之后,这个字符串对象的对应值就不可再修改了。
例如,我们通过下面这段代码:
String str = new String("hello world");
在完成该字符串对象的创建时,因为final对于value的修饰,其底层本质上就是创建了一个hello world的original不可变字符串,然后再创建一个String对象,并将其value和hash值设置hello world以及hello world的hash值:
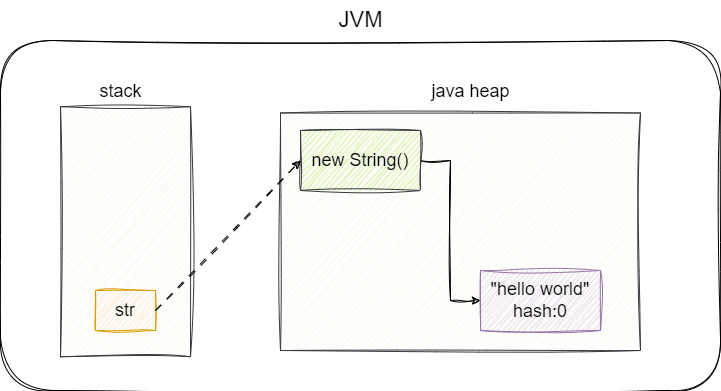
这一点我们查看String的源码定义也可以知晓这一点,可以看到上述的动作本质上就是将堆区的常量和我的字符串类进行关联,后续对于代码的各种修改操作,本质上也都是在字符串常量池中创建新的字面量与字符串类进行关联:
public String(String original) {
//将字符串常量复制给当前字符串类
this.value = original.value;
//将字符串常量hash赋值给当前字符串
this.hash = original.hash;
}
2
3
4
5
6
通过上述的原因保证了字符串的不可变性,使得堆内存中有了字符串常量池的概念,保证同一字符串可以复用,节约堆内存的同时还提升了程序的性能。同时为了保证这些操作不可被开发者修改与破坏,对于字符串类,设计者也将该类通过final修饰,保证字符串类的不可变性不被使用者通过继承等方式遭到破坏,避免了一些字符串操作的安全漏洞和线程安全问题。
# 利用final关键字实现常量折叠
我们再来看一个例子,如下所示,可以看到不同变量声明的字符串test都和数字1进行拼接,最终与test1字符串进行==判断引用地址是否一致:
//字符串常量池
String str1 = "test1";
//字符串变量
final String constStr = "test";
String str2 = "test";
//字符串拼接
String concatenatedWithConst = constStr + 1;
String concatenatedWithVar = str2 + 1;
//判断是否是同一个对象
System.out.println(str1 == concatenatedWithConst);
System.out.println(str1 == concatenatedWithVar);
2
3
4
5
6
7
8
9
10
11
12
最终输出结果如下,可以看到采用final修饰的test字符串和数字1进行拼接之后,和str1的引用一致是一致的:
true
false
2
对应的我们也给出上述代码的字节码,可以看到在JIT阶段,对应19行(将constStr和数字1拼接),因为constStr的不可变性,JIT阶段就会直接将其视为编译时常量和1进行拼接运算,由此直接得出test1。由此concatenatedWithConst就和str1同时指向字符串常量test1所以输出结果比对一致:
// access flags 0x9
public static main([Ljava/lang/String;)V
// parameter args
//......
//
L3
LINENUMBER 19 L3
//将字符串常量test1放到操作数栈
LDC "test1"
//将操作数栈上的test1存储到局部变量concatenatedWithConst 中
ASTORE 4
2
3
4
5
6
7
8
9
10
11
12
对应我们也给出concatenatedWithVar生成的字节码,可以看到其底层本质上就是通过StringBuilder拿到字符串常量中的test和数值1进行拼接从而得到常量池中的test1,然后将当前concatenatedWithVar的引用指向这个常量,因为concatenatedWithVar间接的指向test1字符串,所以和str1的比对结果就不一致了:
L4
//初始化StringBuilder
LINENUMBER 20 L4
NEW java/lang/StringBuilder
DUP
INVOKESPECIAL java/lang/StringBuilder.<init> ()V
//将第三个变量也就是我们的str2 压入操作数栈
ALOAD 3
//str2追加一个数值1
INVOKEVIRTUAL java/lang/StringBuilder.append (Ljava/lang/String;)Ljava/lang/StringBuilder;
ICONST_1
INVOKEVIRTUAL java/lang/StringBuilder.append (I)Ljava/lang/StringBuilder;
//基于toString 生成字符串
INVOKEVIRTUAL java/lang/StringBuilder.toString ()Ljava/lang/String;
ASTORE 5
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# final语义中的常量折叠
上文我们提到JIT会针对运行时常量进行常量折叠避免非必要的字符串运算,这是否意味着编码时针对局部变量采用final修饰字符串就一定可以做到常量折叠呢?
来看看下面这个例子,我们通过final修饰两个从静态方法得出字符串的变量,然后进行拼接返回:
public static String function() {
final String str = getStr();
final String str2 = getStr();
return str + str2;
}
public static String getStr() {
return "hello";
}
2
3
4
5
6
7
8
9
下面这段代码就是function的字节码,可以看到final语义在字节码并没有很实际的体现(和普通局部变量的JIT编译后的代码无异),所有的字符串操作本质上都是从静态函数中获取字符串然后通过StringBuilder完成拼接返回:
public static function()Ljava/lang/String;
//final String str = getStr();
L0
LINENUMBER 17 L0
INVOKESTATIC com/sharkchili/Main.getStr ()Ljava/lang/String;
ASTORE 0
// final String str2 = getStr();
L1
LINENUMBER 18 L1
INVOKESTATIC com/sharkchili/Main.getStr ()Ljava/lang/String;
ASTORE 1
//return str + str2;
L2
LINENUMBER 19 L2
NEW java/lang/StringBuilder
DUP
INVOKESPECIAL java/lang/StringBuilder.<init> ()V
ALOAD 0
INVOKEVIRTUAL java/lang/StringBuilder.append (Ljava/lang/String;)Ljava/lang/StringBuilder;
ALOAD 1
INVOKEVIRTUAL java/lang/StringBuilder.append (Ljava/lang/String;)Ljava/lang/StringBuilder;
INVOKEVIRTUAL java/lang/StringBuilder.toString ()Ljava/lang/String;
ARETURN
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
对此我们不将代码改一下,所有final语义的字符串直接显示赋值字面量字符串:
public static String function() {
final String str = "hello";
final String str2 = "hello";
return str + str2;
}
2
3
4
5
此时查看JIT编译后的字节码即可看到因为字符串return str + str2;分配的字符串直接就是上述两个变量的拼接结果,由此可知,JIT对于final变量的优化更多是针对编译时常量即final修饰的字面量才能进行一定的优化:
public static function()Ljava/lang/String;
//final String str = "hello";
L0
LINENUMBER 17 L0
LDC "hello"
ASTORE 0
// final String str2 = "hello";
L1
LINENUMBER 18 L1
LDC "hello"
ASTORE 1
//return str + str2;
L2
LINENUMBER 19 L2
LDC "hellohello"
ARETURN
L3
LOCALVARIABLE str Ljava/lang/String; L1 L3 0
LOCALVARIABLE str2 Ljava/lang/String; L2 L3 1
MAXSTACK = 1
MAXLOCALS = 2
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 详解final关键字在内存模型中的语义
# final域关于写的重排序规则
实际上final关键字也能针对一些特殊场景插入内存屏障从而避免一些指令重排序,它要求编译器和处理器遵守下面这条规则:
对于一个构造函数的初始化,涉及的final域的写,与随后把这个构造对象引用到外部引用,这两个操作之间不能重排序。
例如,我们用final修饰User类的成员变量name,执行new操作时,按照final的语义它会在name初始化后面插入一个storestore屏障,保证name初始化完成之后,user对象才能发布:
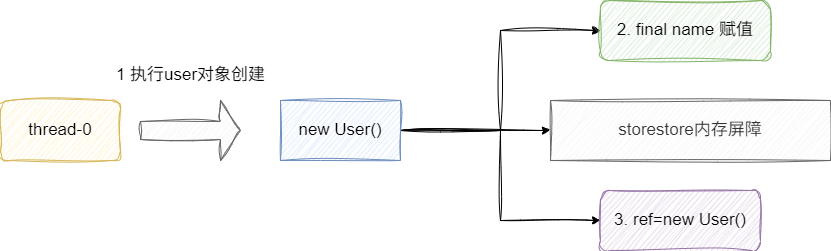
对应的我们也给出User类的定义:
public class User {
private final String name;
public User() {
name = "sharkchili";
//隐含的storestore内存屏障
//隐式的 sharedRef = new User()和 return
}
}
2
3
4
5
6
7
8
9
那么如果final关键字修饰会怎样呢?我们都知道CPU为了提升指令执行效率是允许前后没有依赖的指令乱序执行的,所以我们不妨带入下面这段代码说明一下,首先我们先介绍一下这段代码的含义:
- 线程0先执行init,执行new User并将引用赋值给obj
- 线程1后执行,基于obj获取name字段值
//线程0执行初始化
public static void init(){
obj=new User();
}
public static String getName(){
//线程1的引用接住obj中的user
Object o=obj;
//返回user的名称
return ((User)o).name;
}
2
3
4
5
6
7
8
9
10
11
试想这样一个场景,并发场景下线程0初始化user,在此期间如果线程1访问user的name字段,如果没有内存屏障,很可能出现:
return和name = "sharkchili";的指令重排序,未完全体的user提前发布- 线程1访问到的
name的null值,导致一致性问题:
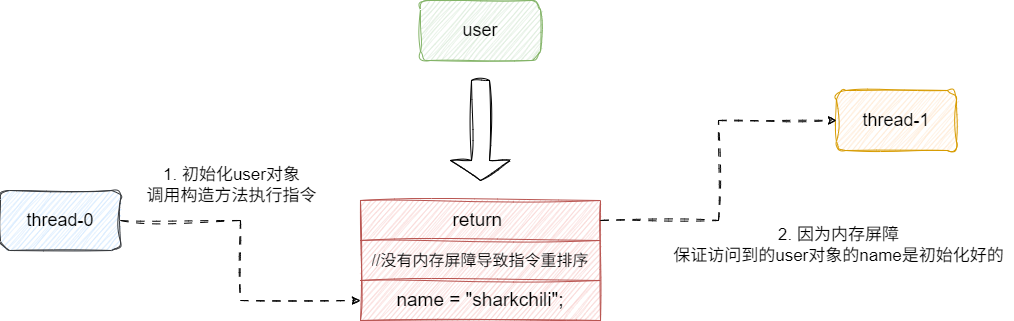
而通过final修饰name之后,对应的final成员变量初始化位置就会插入内存屏障,从而保证线程1访问到的name是user对象完成初始化后的值:
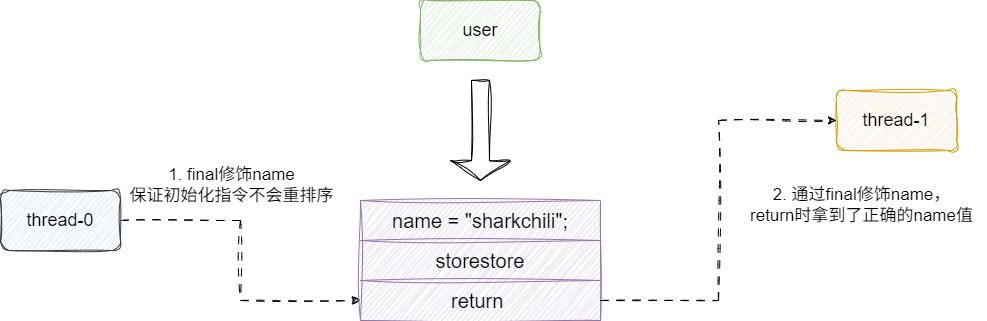
# final域关于读的重排序规则
对于final域的读,JMM内存模型规定了编译器(注意只有编译器)遵守下面这条规则:
对于包含final域的对象读以及对应的final域字段的读,两者不能发生重排序。
举个例子,假设我们的线程0还是执行user的初始化,将创建的user赋值给obj静态引用:
private static final Object obj;
public static void init(){
obj=new User();
}
2
3
4
5
线程2并发读取obj和obj对应的name的值:
public static void getName() {
//线程2的引用接住obj中的user
User user = obj;
//获取user的name
String userName = user.name;
}
2
3
4
5
6
我们试想一下下面这个双线程并发读user的场景,线程0执行user创建,针对线程1的并发读,我们不妨带入obj有final修饰和没有final修饰的场景:
- 假设user对象完成初始化过程中,因为obj和name都有final修饰,获取obj和name操作没有发生重排序,当线程1读取到一个非空的user,就一定能够得到一个非空的name。
- 假设user对象完成初始化过程中,没有final修饰,获取obj和name操作发生重排序,极端情况就可能得到一个空的name和非空的user
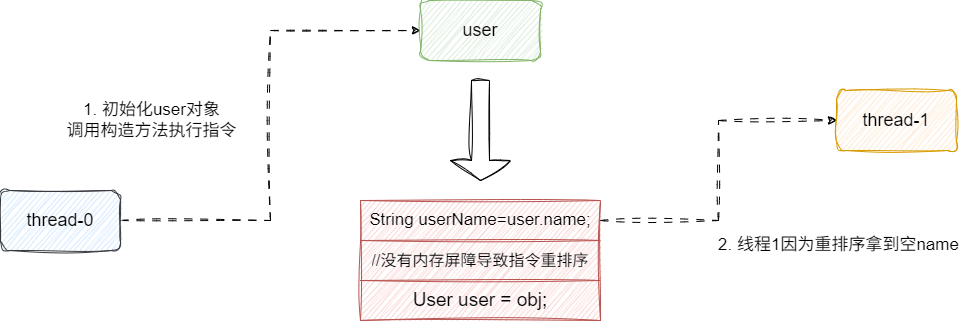
所以,这才有了final语义中对于读操作的重排序规则,在对象读和对象final域读这两个先后顺序之间,编译器会插入一个loadload内存屏障避免两者重排序,从而保证user非空的情况下一定能够读到final域中的name。
# final关键字中需要注意的逸出问题
final关键字通过内存屏障避免指令重排序保证变量读写的正确性,但我还是需要在使用上明确避免对象的逸出,例如下面这初始化user并赋值给obj静态引用的代码:
@Data
public class User {
private final String name;
public static Object obj;
public User() {
name = "sharkchili";
obj = this;
}
}
2
3
4
5
6
7
8
9
10
11
12
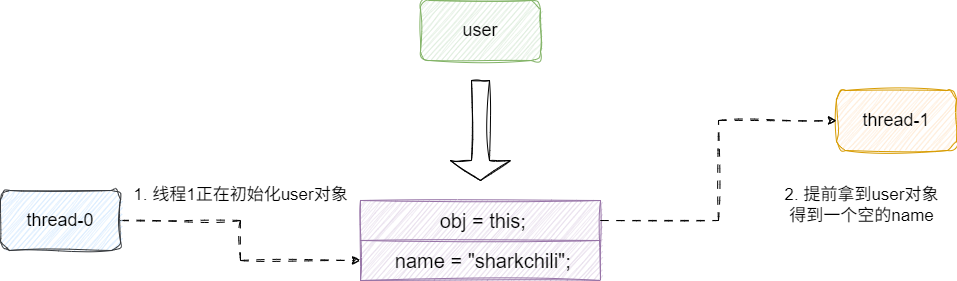
试想一下,在处理器进行构造函数初始化时其内部操作就可能非顺序将指令交由不同的电路单元执行,即:
- 先执行
obj = this;。 - 再对
name进行字符串分配。
面对上述的指令重排序,线程1执行如下代码,判断obj非空后获取obj指向的user和name值:
public static void getName() {
if (obj!=null){
//线程2的引用接住obj中的user
User user = obj;
//获取user的name
String userName = user.name;
}
}
2
3
4
5
6
7
8
9
按照上述逻辑,即使构造函数发生重排序(即obj=this提前),它依然会得到一个非空的obj,步入逻辑,就可能因为指令重排序提前拿到obj进而获取到一个空name值,所以尽管final语义带有指令重排序的语义,我们在使用时也需要明确去避免对象的逸出:
# 详解可见性下的哲学
# 发布与逸出的把控
发布(publish)的定义即将内部一些对象对外发布使得外部代码可操作,使得发布可以操作或者修改这个变量,例如下面这段代码,这就是最简单的发布模式,它将set采用public修饰使其对外部类和线程都可见:
/**
* public修饰使外部代码可见
*/
public static Set<String> set;
public void init() {
set = new HashSet<String>();
}
2
3
4
5
6
7
8
9
10
在并发编程中我们务必要把控要发布的粒度,例如下面这段,我们仅仅是要求map保管我们的元素,但是getMap方法却将私有变量map发布,这种通过公有方法返回或者非私有字段引用私有变量的做法我们统称为不安全的发布,存在各种并发操作的风险:
private ConcurrentHashMap<String, Object> map = new ConcurrentHashMap<>();
public void put(String key, Object obj) {
map.put(key, obj);
}
/**
* 通过方法将私有域对象发布
* @return
*/
public ConcurrentHashMap<String, Object> getMap() {
return map;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
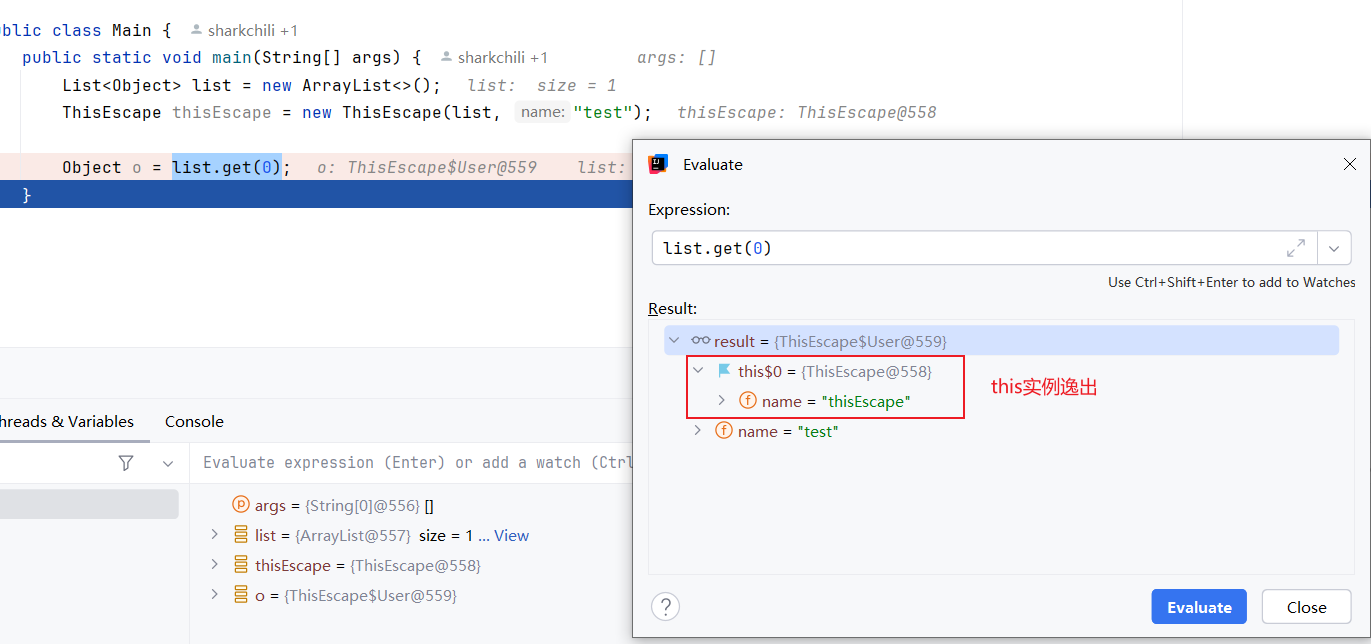
另一个典型例子就是下面这段代码,我们仅仅需要通过构造方法对外发布User实例,却因为构造方法的public修饰符使得this被隐式发布导致逸出,这也是一种典型的错误:
public class ThisEscape {
private String name="thisEscape";
/**
* 将内部类存入list时,将this实例发布
* @param list
* @param name
*/
public ThisEscape(List<Object> list, String name) {
list.add(new ThisEscape.User(name));
}
class User {
private String name;
public User(String name) {
this.name = name;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
只有完全返回的的构造才处于可预测和一致的状态,这种做法及时构造函数运行到代码的最后一行,本质上构造的对象都不是完整且不争取的被发布了:
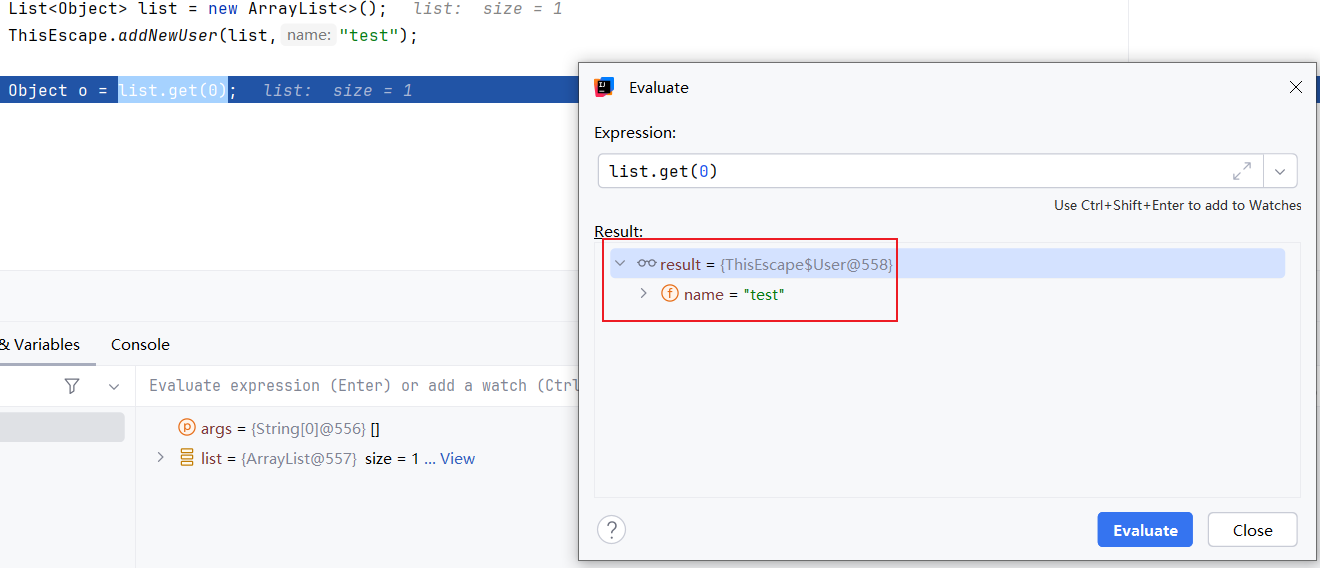
而正确的做法是采用构造私有,通过对外暴露一个初始化工厂发布内部类:
/**
* 将构造函数私有
*/
private ThisEscape() {
}
/**
* 对外暴露一个创建工厂方法安全构造并添加user
* @param list
* @param name
*/
public static void addNewUser(List<Object> list, String name) {
list.add(new ThisEscape.User(name));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
最终调测结果如下,可以看到外部类的this实例构造不再逸出:
# 不安全的发布
下面这段代码就是典型的就存在构造发布不可见的情况,因为构造函数初始化存在指令重排序,实际上下面这个构造初始化可能存在:
- 初始化
holder - 发布
holder - 完成n的赋值
public class Holder {
private int n;
public Holder(int n) {
this.n = n;
}
public void assertSanity() {
if (n != n) {
throw new RuntimeException("Sanity check failed");
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
所以如果线程并发初始化时,可能看到一个尚未初始化好的Holder ,使得其他并发线程通过assertSanity访问这个变量就既有可能存在不一致而报错的情况,所以必要时我们建议需要保证并发安全性的成员字段需要在构造函数内部采用final关键字修饰:
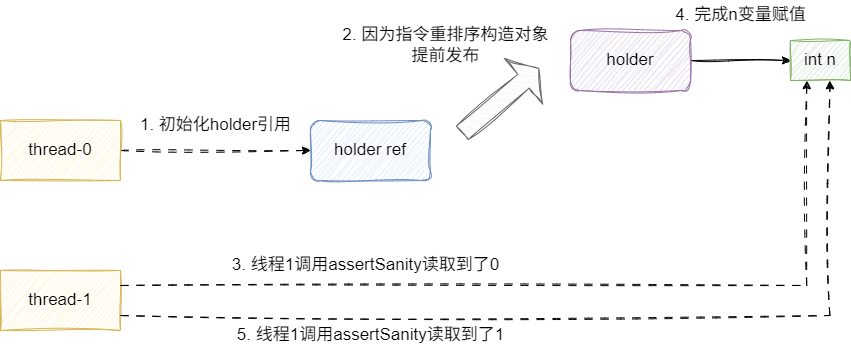
引发异常的场景如下所示,因为构造函数的指令重排序等原因,显示的访问就可能存在线程2读取不一致的情况。
这里也需要补充说明一下,这份代码示例不知道是因为现代计算机性能优势还是JIT某种机制的优化,即使笔者关闭了JIT优化也未能复现这个错误,也希望有读者如果复现,务必指导一下笔者不对的地方:
// 线程1:初始化Holder
new Thread(() -> {
holder = new Holder(RandomUtil.randomInt()); // 不安全发布
}).start();
new Thread(() -> {
while (holder == null) {
// 等待holder被初始化
}
holder.assertSanity(); // 可能抛出异常
}).start();
2
3
4
5
6
7
8
9
10
11
12
# 利用final域下不可变性的安全访问
利用final不可变语义,在构造时初始化需要被外部线程访问的变量,在访问时通过拷贝的方式安全发布对象到外部,保证所有线程对于共享变量的访问是一致的。
就例如下面这段代码,笔者在构造函数上显示完成数组arr初始化,后续线程对于该内部变量的访问一律以getArrayList为入口,其内部逻辑采用拷贝的方式将变量发布让其进行自由操作,而原有对象内部元素对所有线程仍旧保持一致:
public class SafeAccessArr {
/**
* 使用final修饰在构造函数初始化保证可见性和一致性
*/
private final int[] arr;
private final int len;
public SafeAccessArr(int[] arr) {
this.arr = arr;
this.len = arr.length;
}
//访问时通过拷贝的方式安全发布
public int[] getArrayList(int len) {
if (this.len == len) {
return Arrays.copyOf(arr, len);
}
return null;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
对此,我们也给出安全发布的几个要点:
- 使用final保证不可变
- 使用synchronized保证访问的互斥
- 使用volatile修饰保证可见性
- 在静态初始化函数中初始化一个对象引用(保证可见、一致、安全访问)
# 栈封闭技术在并发编程中的使用
实际上保证不可变性的手段还有一种名为栈封闭的技术,该技术利用线程栈私有的特性,将外部引用参数拷贝到内部进行逻辑计算,然后利用Java语言的语义天生保证了基本类型的引用无法获得即基本类型的不可变性,将计算结果直接返回交由外部使用。由此保证操作变量只有一个线程的局部引用操作,保证了线程安全和不可变性:
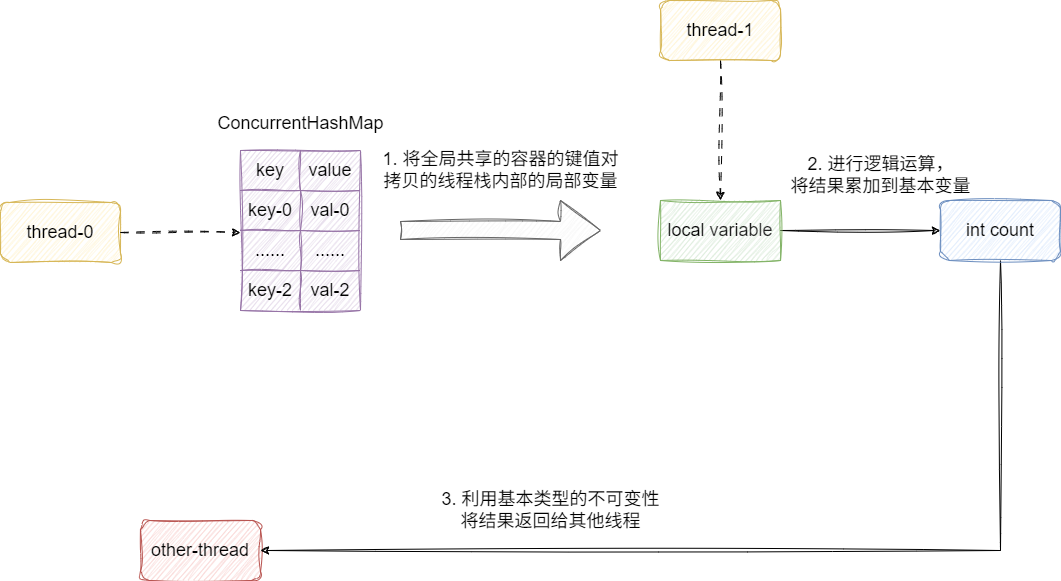
就像下面这段代码,可以看到笔者针对容器计数的功能进行如下处理:
- 将外部全局操作的并发容器键值对拷贝的线程内部的
map中 - 进行需要的非空过滤计数,同时笔者使用的计数器是采用基本类型的
int而非包装类,保证引用只有局部线程持有,且返回结果也是基本类型保证不可变性
public int getValidCount(ConcurrentHashMap<String, Object> params) {
int count = 0;
//将外部参数拷贝到线程局部变量中
Map<String, Object> map = new HashMap<>();
map.putAll(params);
//进行有效计数
for (String key : map.keySet()) {
if (map.get(key) != null) {
count++;
}
}
return count;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
当然维持对象引用的栈封闭时,程序员还是需要额外注意一下引用对象的逸出问题,例如上文示例中map 引用就局限在当前线程栈内,利用线程栈私有的特性,即使map是非线程安全的对象,也可以利用栈的特性保证即时运算的准确性。
# 事实不可变对象
最后一种,也算是并发哲学中大道至简的方式,即事实不可变用笔者的话也就是业务不可变,例如下面这段代码:
private ConcurrentHashMap<Integer, Date> map = new ConcurrentHashMap<>();
2
3
事实上Date对象的操作是非线程安全的,但是我们业务上的场景它是只读即不可变的,在协定的情况下这段代码也变为事实不可变的并发安全。
# 小结
本文从final关键字底层工作机制以及常量折叠、JIT优化和几个实践案例全方位的演示了final关键字在并发编程中的最佳实践,希望对你有帮助。
我是 SharkChili ,Java 开发者,Java Guide 开源项目维护者。欢迎关注我的公众号:写代码的SharkChili,也欢迎您了解我的开源项目 mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)。
为方便与读者交流,现已创建读者群。关注上方公众号获取我的联系方式,添加时备注加群即可加入。
# 参考
Java中的String类为什么用final修饰?:https://blog.csdn.net/u011147339/article/details/109231728 (opens new window)
JVM对于声明为final的局部变量(local var)做了哪些性能优化?:https://www.zhihu.com/question/21762917 (opens new window)
Final关键字的使用技巧及其性能优势:https://blog.csdn.net/qq_72935001/article/details/130495554 (opens new window)
《Java并发编程实战》
怎样提升这个多线程bug重现的几率?:https://segmentfault.com/q/1010000011611908 (opens new window)
- 01
- mini-redis SCAN指令复刻:自底向上的工程方法论实践06-08
- 03
- 重读 Redis SCAN 源码:那些当年没看懂的反向迭代细节06-01
