 从操作系统底层浅谈程序栈的高效性
从操作系统底层浅谈程序栈的高效性
# 写在文章开头
写于2025.12.19,随着ai的不断发展,编程成为一种思想上的抽象,开发者将更专注于软件架构设计与功能抽象本身,技术或许将会成为一种"黑盒"的技术手段,当然笔者这里说的"黑盒"需要打上引号,因为笔者强调的黑盒并非是说明开发者无需关注技术实现的内核,而是强调开发者无需过分关注技术底层,只有在必要时需要针对性的研究技术本身的特性,从而更好的在软件系统这个不断进行封装和抽象的世界推进。
而本文也是一篇关于元认知的文章,即操作系统实现层面,让读者了解编程语言底层的工作机制,了解栈的工作原理,相信通过这篇文章,读者将会对编程技术有着更深层次的理解和掌握。
你好,我是 SharkChili ,禅与计算机程序设计艺术布道者,希望我的理念对您有所启发。
📝 我的公众号:写代码的SharkChili
在这里,我会分享技术干货、编程思考与开源项目实践。
🚀 我的开源项目:mini-redis
一个用于教学理解的 Redis 精简实现,欢迎 Star & Contribute:
https://github.com/shark-ctrl/mini-redis (opens new window)
👥 欢迎加入读者群
关注公众号,回复 【加群】 即可获取联系方式,期待与你交流技术、共同成长!
# 前置知识铺垫
# 执行栈或程序栈的基本概念
学习过数据结构的同学想必都知道,栈是后进先出的数据结构,即先压入栈中的元素最后才会弹出,注意这里笔者所说压入和弹出都是逻辑上的概念,栈的底层本质上还是用数组来表达,通过数组结合指针的游走表达栈元素的压入和弹出。
而本文笔者要聊的并不是栈这个数据结构,而是程序中的执行栈,它的核心工作原理也是运用到数据结构上的栈,每当涉及变量分配或者函数调用时,都会将相应的方法或者变量压入栈中,处理完成后弹出并销毁。
例如我们现在有下面这样一段代码,即声明两个整形变量之后,通过add方法将其相加然后返回运算结果:
func main() {
num1 := 1
num2 := 2
sum := add(num1, num2)
println(sum)
}
func add(num1 int, num2 int) int {
return num1 + num2
}
2
3
4
5
6
7
8
9
10
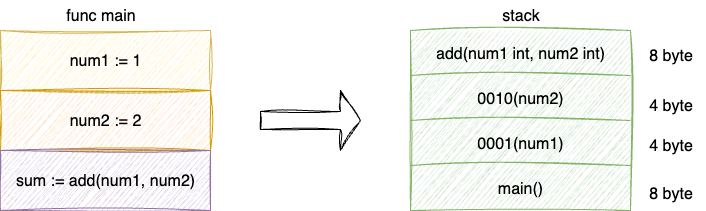
对应的栈的执行过程如下:
- 将
main方法压入栈中 - 将
num1和num2的数值都压入栈中 - 触发add函数调用将
add方法压入栈中 - 完成运算结果,
add返回栈指针复位,回到add调用前的地址
对应执行流程如下图,可以看到栈可以在编译时预分配指定大小空间以保证程序可以正确的写入和执行,理想情况下合适大小的内存空间可以保证:
- 栈执行的性能表现出色(后文会展开说明)
- 内存利用率高,不会因为不连续的内存空间使用造成内存碎片
# 详解操作系统内存管理
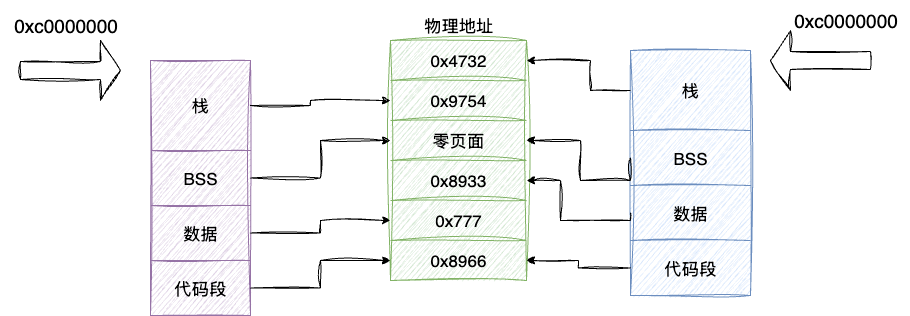
上文提到了一些关于内存碎片的一点概念,鉴于本文关于栈的执行性能表现需要一定的计算机理论基础,所以笔者也在这里聊一些关于内存方面的知识。上述笔者提到内存利用率不高这一问题,假定我们程序没有合理连续的使用内存造成预分配内存空间不足的情况。 实际上,这种情况程序是可以向操作系统再申请内存空间的,按照《现代操作系统》一书中的说法,一个进程大体范围如下三个部分:
- 代码段:代码段即可执行的物理代码,对应相同逻辑的多进程是共享的,所以内存空间分配固定
- 数据段:它存在用户初始化的值和非初始化的值,操作系统为了减少非必要的内存资源浪费,在进程初始化时仅会针对代码段和存在初始化值(例如全局变量num=1)分配内存空间,针对未初始化的变量则是将这些变量指向一个零页面的内存空间,等到真正使用的时候再通过
malloc函数申请分配内存空间 - 栈:每个进程对应的线程线程独享,栈段执行永远是从虚拟地址的
0xc0000000或其附近的地址开始向低地址不断延伸(将函数或者变量入栈、弹出完成运算任务)
如果我们在预分配指定大小的栈空间中进行非连续的写入,就会造成所分配的内存空间不足,此时,程序就需要向操作系统申请内存空间,这就涉及操作系统的内存管理问题了。
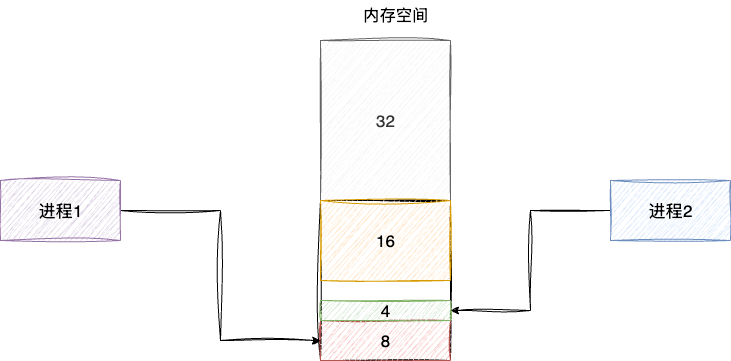
我们以操作系统最经典的伙伴算法为例,进行内存分配时永远是基于2的次幂进行分配,假设我们现在有64个页面,与此同时出现两个分别发起8、4页面内存请求,那么64个页面就会从从低地址开始进行等分切割。即:
- 将64个页面切分为32个页面
- 低位的32再切分为16个页面
- 低位的16切分为2个8个页面
- 低位的8分配给进程1个页面
- 低位的另一个8的页面切割为4,分配给进程2
如下图伙伴算法正是通过这种不断二分的算法管理内存分配,完成后就会将内存空间释放返回:
以伙伴算法为例,因为2的次幂申请和其内存管理的理念,尝尝会出现大量内存碎片问题,最经典的场景就是为了65大小的页面请求,到内存中寻找128大小的页面。所以如果大量的进程没有合理的使用内存空间,按照现代操作系统的内存管理理念,如果内存空间不足,则会将某些进程交换至虚拟内存空间,也就是所谓的swap分区,对应我们可以通过linux的free指令查看,需要了解的是这块空间本质上就是磁盘空间,其读写性能表现相对于内存而言要逊色许多:
[root@iv-xxxx ~]# free -m
total used free shared buff/cache available
Mem: 1782 635 199 40 1215 1147
Swap: 0 0 0
[root@iv-xxxx ~]#
2
3
4
5
这也是为什么比较本文已经强调的要学会通过当前需求获取合理紧凑的内存空间,而这也就是为什么栈的执行相较于堆要高效的原因之一。
# 内存也可能是性能瓶颈的罪魁祸首
考虑到CPU时钟周期与内存一个维度上(CPU访问速度大约2-4个时钟周期,内存大约是200-300个时钟周期),如果一味指望完成内存读写后,CPU在着手处理读写任务,这就很可能出现CPU大量时钟周期被浪费,也就是我们常说的空转问题。所以设计者也在CPU内部增加了一层由SRAM电路构成的缓存来减少CPU对于内存的访问,从而提升CPU处理效率以及减少CPU空转的概率。
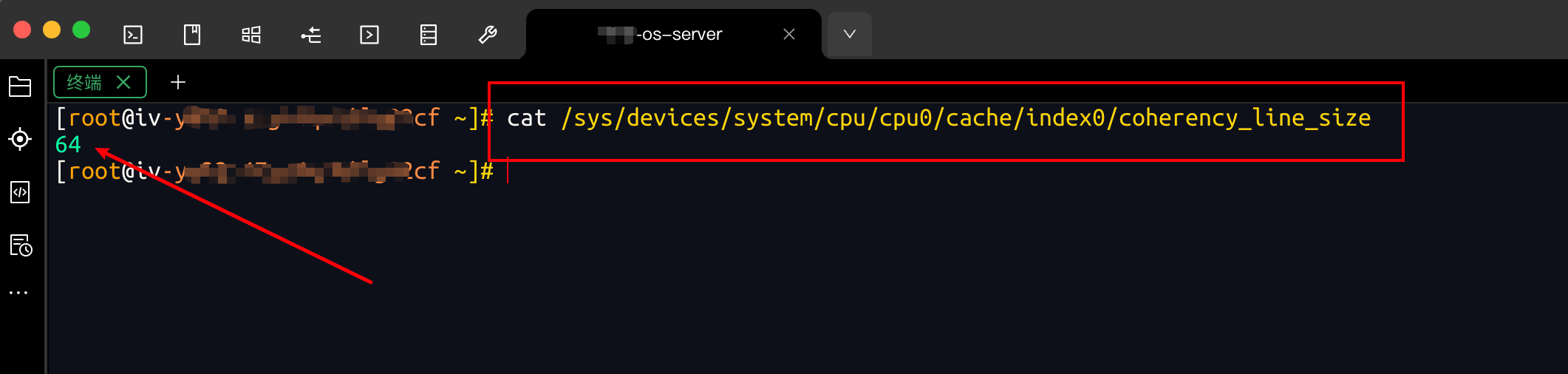
对应cpu默认L1缓存行大小可以通过如下指令查看:
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
以笔者的服务器为例,对应第0个CPU的缓存行大小大约是64字节:
需要补充说明的是每个CPU核心的一级缓存行缓存都是独享的,所以处理操作系统在进行相同数据读写时本质都是通过总线通知和缓存一致性协议来确保数据一致性,由于缓存一致性协议涉及的内容较多,且不属于本文的范畴,这里笔者也仅仅简要说明一下大体的思路,整体来说CPU缓存一致性协议的原理就是相同缓存数据涉及最新的修改操作都需要进行如下操作:
- CPU-0读取的数据不在缓存行,则检查总线是否忙碌,若不忙碌则发起控制信号,等待存储器将目标数据放到总线上读取
- CPU-0触发修改操作,通过总线通知其它CPU核心这个写操作
- 其它CPU缓存收到通知后,查看各自数据是否标记为脏,若为脏则会将数据写入内存,并通过总线通知写操作的CPU-0操作数据为过期数据
- CPU-0收到通知后,拉取最新数据完成写操作
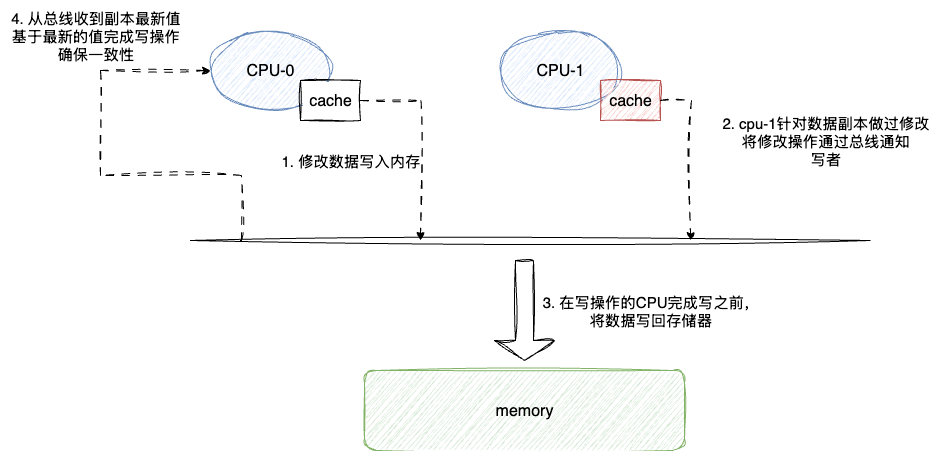
所以要想提升程序的执行性能,我们也可以从这个角度来考虑,即确保将本次需要用到的数据尽可能缓存到CPU缓存行,尽可能在当前CPU缓存行中完成数据读取和并基于CPU高速缓存完成目标代码对应的逻辑操作。
# 详解程序执行栈执行高效的奥秘
# 合理空间预分配
实际上,栈在操作系统中就是一块连续且紧凑的内存空间,以java为例,我们可以通过jinfo -flag ThreadStackSize [pid] 查看每个线程对应的栈大小,以笔者的系统为例,可以看到对应java进程的默认栈大小为2MB左右,这个大小相对于日常被的函数执行已经是非常冗余了,毕竟我们的日常编码都是以字节为单位在函数内操作各种字符串、整数、小数作为成员变量的类对象:
➜ ~ jinfo -flag ThreadStackSize 88954
-XX:ThreadStackSize=2048
2
# cpu寄存器对于栈指针的灵活把控
上文提及,程序执行对应的栈段都以虚拟地址的0xc0000000或其附近开始执行,这也就是栈基址的位置,程序的执行本质就是从栈基址开始不断将函数或者变量压入弹出的过程。现代CPU考虑到栈的空间连续且紧凑,结合编程语言中对于类型声明(int、long、byte)保证空间推进的可预测性,CPU内部专门有一块寄存器stack register维护执行栈的栈顶位置,所以在信息栈的逻辑压栈或者出栈等操作时,完全可以根据变量类型确定偏移量,通过指针快速移动定位,这一点相比于在堆内存申请的对象操作要简单高效许多。
如下图所示,执行完byte数据分配后,CPU看到当前程序需要声明一个4字节的函数,本质上就是通过栈指针定位栈地址向前推进4字节的空间将变量压入,相比于堆内存中malloc申请中申请各种算法以及可能存在的内存空间不足造成segmentation fault异常,栈明显是高效且可靠很多:
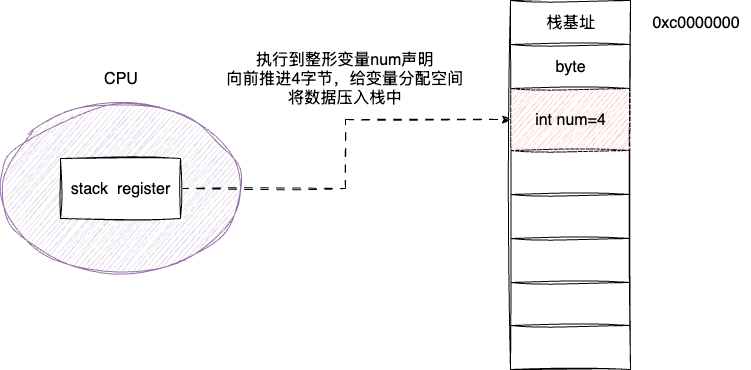
与之同时,相比于堆内存或是通过垃圾回收器或者开发者手动释放内存空间,栈中变量的生命周期随着函数的终止而直接消亡,栈可直接通过出栈快速完成内存空间,这一点也是栈执行高效的原因之一。
# 局部性友好
结合上文提及的CPU缓存行,以及栈天然良好空间连续分配和紧凑的数据结构,CPU操作栈上变量和函数时,基本可以做到一次预加载拉取到目标数据及其对应相邻存储单元变量,例如下面这段代码,按照缓存行64字节为单元,我们拉取num1时就会连带将num2拉取到缓存行,这使得CPU缓存行有非常大的概率在高速缓存行上完成程序运算:
func main() {
num1 := 1
num2 := 2
sum := add(num1, num2)
println(sum)
}
func add(num1 int, num2 int) int {
return num1 + num2
}
2
3
4
5
6
7
8
9
10
11
对应我们也给出栈的连续空间和CPU缓存行紧密配合下发挥局部性原理的最大威力示意图:
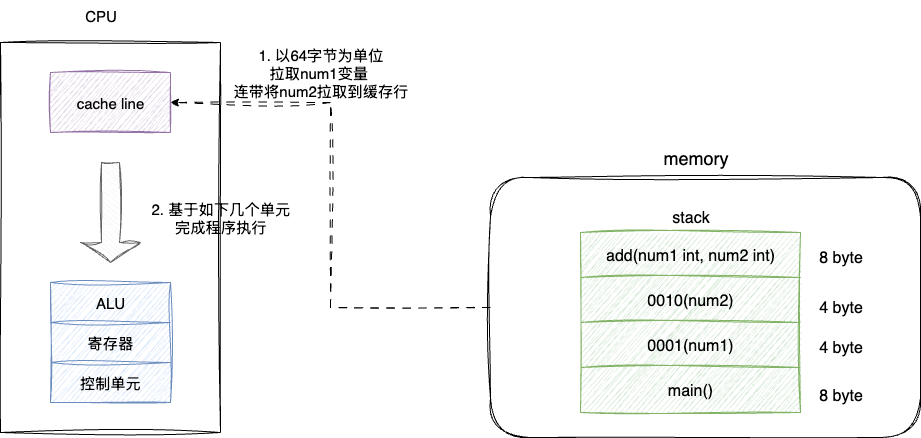
# 栈的局限性
# 不可动态扩容
栈空间随着编译固定分配,无法动态根据变换而申请内存空间,同时因为stack的空间固定,如果递归逻辑没有明确写好结束终止条件,可能会将栈空间耗尽造成stack overflow。
# 线程隔离
栈内部的变量只有栈独享,对于并发场景下可以通过栈封闭保证线程安全,但是对于需要并发共享变量的场景则是捉襟见肘。
# 基于栈上分配技术说明栈的实际性能表现
因为java是笔者主力开发语言,对于栈的性能执行表现就从java这门语言的角度出发,以jdk8及更高版本为例,默认都是开启逃逸分析的,对应参数为(-XX:+DoEscapeAnalysis),通俗来说该参数一旦发现创建的对象并没有被外部线程访问,即没有逃逸或者方法逃逸(可被外部方法访问到)的情况下,对象就会在栈上分配。
对于下面这段代码而言,创建的TestObj并没有发生线程逃逸,符合栈上分配的标准:
public static void main(String[] args) {
long start = System.currentTimeMillis();
for (int i = 0; i < Integer.MAX_VALUE; i++) {
new TestObj();
}
long end = System.currentTimeMillis();
System.out.println("耗时:" + (end - start) + "ms");
ThreadUtil.sleep(Integer.MAX_VALUE);
}
static class TestObj {
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
所以我们可以在添加-XX:+PrintGC后,将程序启动,可以发现在最终耗时在4ms左右,对应gc次数为0,与之对应通过-XX:-DoEscapeAnalysis -XX:+PrintGC关闭逃逸分析使对象分配在堆内存上,再打印gc情况,对应输出结果如下,可以看到,不仅gc次数频繁,且方法执行耗时猛涨:
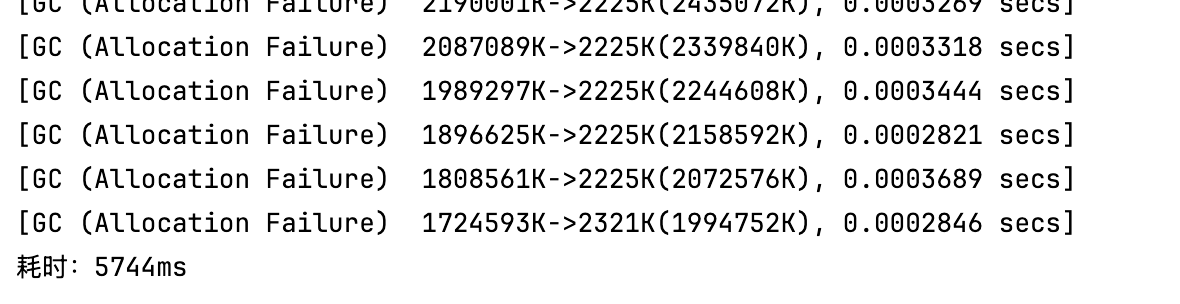
由此,不难看出,利用好程序栈的特性,不仅可以提升程序的性能表现,还能显著降低系统资源开销,由此是动态内存分配和gc回收这两块大头。
# 小结
利用好栈天然紧凑的内存结构,编写良好可达到栈上分配的面向对象程序让编译器组织好栈内数据,从而减少内存碎片,这种做法不仅可以提升其对象创建和销毁的性能表现,还能够利用好CPU缓存达到局部性加载以减少CPU对内存的访问从而提升程序性能,希望这个思路对你有所启发。
你好,我是 SharkChili ,禅与计算机程序设计艺术布道者,希望我的理念对您有所启发。
📝 我的公众号:写代码的SharkChili
在这里,我会分享技术干货、编程思考与开源项目实践。
🚀 我的开源项目:mini-redis
一个用于教学理解的 Redis 精简实现,欢迎 Star & Contribute:
https://github.com/shark-ctrl/mini-redis (opens new window)
👥 欢迎加入读者群
关注公众号,回复 【加群】 即可获取联系方式,期待与你交流技术、共同成长!
# 参考
栈与堆的性能对比:深入探讨栈为何通常比堆更快 :https://blog.csdn.net/weixin_67120523/article/details/145305406 (opens new window)
java 如何查看最大栈空间 :https://docs.pingcode.com/baike/395110 (opens new window)
局部性原理:https://baike.baidu.com/item/局部性原理/3334556 (opens new window)
深入理解Java内存与运行时机制:逃逸分析、栈上分配与标量替换 :https://cloud.tencent.com/developer/article/2560474 (opens new window)
《深入理解Java虚拟机 (第3版)》
- 02
- 详解AI时代下生产力最佳实践—Iterm2+zsh06-12
- 03
- 打造高效mac终端:oh-my-zsh与插件配置06-11
