 Spring AI Alibaba实战:JVM监控诊断Agent的工程化构建与最佳实践
Spring AI Alibaba实战:JVM监控诊断Agent的工程化构建与最佳实践
# 写在文章开头
本文是《Spring AI Alibaba天气预报助手实践》:https://mp.weixin.qq.com/s/dX2EsfrsLxnuD7WiMuKzUQ (opens new window)的续篇,在前文基础上深入探讨AI agent一些更进阶的思想和实现理念的布道。
在前面的文章中,我们已经建立了agent开发的基础认知框架,包括:
- Agent(智能体):由大语言模型(LLM)+工具(Tools)+**系统提示词(System prompt)**构成的智能系统,本质是将
LLM推理能力与工具执行能力相结合,实现流程智能化。 - Tool(工具):为LLM提供外部调用的能力的基础组件,可以调用外部API、命令行工具等。
- Skill (技能):将专家经验(提示词、示例、参考资料)打包成的知识单元,引导模型按照特定的思维框架进行推理。
- ReAct(Reasoning+Acting):
ReAct范式通过思考->心动->观察的循环机制,实现流程智能体自动化
同时,文章还基于**Spring AI Alibaba(以下简称SAA)**提供的官方天气预报助手案例基础之上,补充了消息修剪、上下文管理、RAG检索增强、Skill抽取等综合实践。
基于既有储备的agent 应用开发知识,本文将探讨一个更深入的话题:
如何将技术专家确定性经验运用的工具封装为Tool、可复用的经验即思维推理框架构建为skil,构建可自主执行特定工作的agent?
对此,笔者将通过一个简单的JVM监控诊断助手的案例,演示如何将沉淀的个人经验高度抽象封装为可复用的agent,希望对你有帮助。
你好,我是 SharkChili ,Java Guide 核心维护者之一,对 Redis、Nightingale 等知名开源项目有深度源码研究经验。熟悉 Java、Go、C 等多语言技术栈,现任某知名黑厂高级开发工程师,专注于高并发系统架构设计与性能优化。
🌟 开源项目贡献
- mini-redis:教学级 Redis 精简实现,助力分布式缓存原理学习
🔗 https://github.com/shark-ctrl/mini-redis (opens new window)(欢迎 Star & Contribute)
📚 公众号价值 分享企业级架构设计、性能优化、源码解析等核心技术干货,涵盖分布式系统、微服务治理、大数据处理等实战领域,并探索面向AI的vibe coding等现代开发范式。
👥 加入技术社群 关注公众号,回复 【加群】 获取联系方式,与众多技术爱好者交流分布式架构、微服务等前沿技术!
# 详解Agent应用开发核心概念
# Agent Loop的设计理念与实现机制
# Agent Loop工作机制
本文旨在让模型学会个人沉淀的线上故障诊断经验让其学会自主决策,完成复杂的线上故障诊断任务,这就涉及到Agent Loop工作模式。
Agent Loop是agent范式共享的运行引擎,专门处理需要多步推理的复杂任务。当面对需要长期规划的任务时,LLM无法准确的一次性生成完整计划并达成目标,因此需要Agent Loop这种迭代式执行机制。
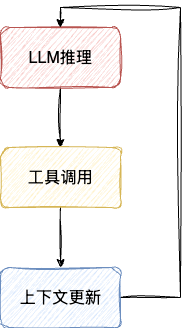
从技术执行角度来看,Agent Loop本质就是一个while循环,持续执行以下三个核心步骤:
- LLM推理:基于当前上下文进行推理思考和决策
- 工具调用:执行选定的工具操作
- 上下文更新:将结果反馈到上下文中
通过不断观测执行结果,不断缩问题的空间,使得Agen Loop能够逐步逼近问题的解决方案。
# Agent Loop所面临的挑战
从工程视角来看,Agent Loop设计难点应着重于关注如何高效管理迭代过程中不断增长的上下文。随着任务执行的推进,上下文会持续积累,这可能会导致:
- 关键信息被稀释、影响LLM注意力分配
- 推理质量下降,出现中间遗忘的现象
- token消耗急剧增加,成本控制困难
这些挑战正是后文将要深入探讨的**"上下文工程"(Context Engineering)**需要解决的核心问题。
# Skill的核心概念与工程价值
在软件工程中,最重要的设计原则之一就是复用,skill正是这一原则在AI Agent开发中的重要体现。通过工程经验沉淀形成的、用自然语言定义的,具有特定领域上下文的逻辑指令集合。它本质的特征为:
- 知识特定:将专家经验(提示词、示例、参考资料)打包成可复用的知识单元
- 领域封装:针对特定领域场景设置的逻辑指令集
- 原子性:每个skill都专注于解决特定问题
- 延迟加载:支持按需加载,优化token消耗
初次接触Skill的读者可能会认为,Skill的概念和Tool类似,实际上二者在理念上还是有所区别的:
- Tool强调提供原子操作能力,让LLM能够间接调用外部API或执行特性命令行命令
- Skill:提供思维框架和推理逻辑,是指导LLM如何使用Tool的使用说明书
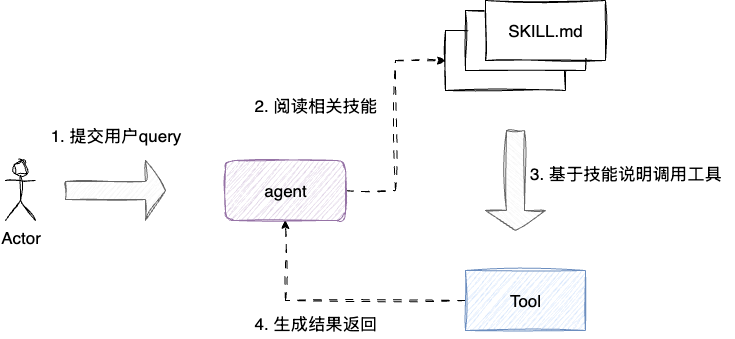
在实际的工程落地中,Skill常用于以下两个场景:
- 任务说明书:通过自然语言定义逻辑指令构成Skill,遇到特定领域的上下文时,Agent通过延迟加载注入这份Skill完成上下文增强,并根据这份技能的说明和示例,完成复杂任务的处理
- 高级工具的制作:将多个单原子工具,通过Skill封装为对LLM视为黑盒的高级工具,对外暴露单一的JSON schema,降低推理步骤和token的消耗
关于skill更多的核心知识,可以参考guide哥的这篇文章:https://mp.weixin.qq.com/s/5iaTBH12VTH55jYwo4wmwA (opens new window)
# 上下文工程(context Engineering)
# 什么是上下文工程(context Engineering)
上下文工程是AI Agent开发中的核心技术领域,其重要性远超简单的提示词设计。从广义角度理解,上下文工程的涉及所有影响LLM推理的信息资源管理,主要包含:
- 记忆管理
- 动态上下文增强
- 上下文压缩与优化
一句话来概括,上下文工程就是要在模型推理准确性和成本控制之间找到一个完美的平衡点。所以,上下文工程是保证任务执行准确性的前提下,最大限度优化资源利用率,这是构建高性能AI agent的关键技术保障。
# 记忆管理
# 记忆的基本概念
LLM上下文窗口有限,且每次对话结束后,所有的交互信息都会随着session而消失,这使得agent在发展初期只能作为一个短暂有状态的助手。记忆系统的引入正是为了解决这一核心问题,它是agent感知历史上下文,动态调整适配用户体验和要求的核心所在。通常,我们将记忆分为短期记忆和长期记忆。
# 短期记忆管理
短期记忆则是session级别的记忆,涵盖当前用户本轮与模型交互的上下文,包含:
- 用户输入
- 模型输出
- 工具调用
- 中间推理过程
尽管现代LLM上下文窗口也从原来的4k token提升至1M甚至更多,但是更长的上下文也就意味着更:
- 推理成本激增:更长的上下文意味着更高的计算成本
- 注意力分散:研究表明面对长上下文的情况LLM注意力分散,容易出现**中间遗忘(Lost In The Midlle)**的情况,即模型更倾向于更好的利用头部和尾部的信息。
- 资源利用率低:大量冗余信息占用宝贵的上下文空间
所以,对于短期记忆主流实践给出三种上下文压缩策略:
- 上下文缩减:设置历史消息的阈值,采用活动窗口(丢弃最早N条消息)、消息摘要(对会话历史进行智能摘要)等算法,让上下文存储最有价值的部分,同时降低上下文空间的占用
- 上下文卸载:工具或者skill调用可能返回大量数据,例如网页信息、大文本,可以及时的将这些重型结果卸载或存储到外部介质中,prompt仅仅保留这些重型结果的文本标识
- 上下文隔离:通过单一职责原则划分agent,将针对性的上下文信息交给相应的子agent,而非广播发送,确保消息简洁且实用。
# 长期记忆管理
考虑到用户习惯和连续性体验,现代agent应用开发引入长期记忆的概念。在对话结束后,应用框架底层对本轮对话进行"语义提纯"处理:
- 噪声过滤:过滤冗余的对话噪声
- 事实抽取:抽取核心重要的结构化事实
- 向量化存储:将记忆文本转为语义向量存储到向量数据库(如pgVector)中。
有了向量化存储的长期记忆,同一用户开启新的session时,系统会按照如下步骤执行:
- LLM就会将用户query向量化
- 到长期记忆库进行相似性检索
- 找到最相关资料将历史偏好、背景知识等资料
- 将信息注入到system prompt,对上下文进行增强
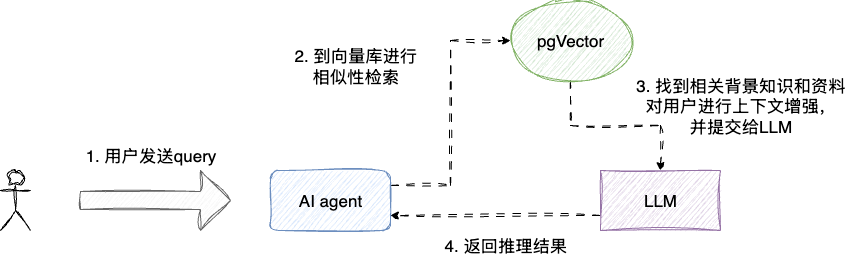
通过对用户行为习惯和长期记忆关联,agent能够很好的保持对用户偏好的连续性理解,确保输出结果符合用户的个性化需求。
# 动态上下文增强
动态上下文管理即针对用户意图,加载合适的向量数据,引导LLM向正确的思考路径执行,它要求我们做到:
- 意图驱动RAG检索:基于当前对话意图,动态检索外部文档(RAG)
- 技能与工具延迟加载:按需加载技能以及工具加载到上下文中
- 上下文相关性过滤:确保当前加载内容与任务高度相关
- 动态记忆调整与RAG:通过设置阈值适时进行消息摘要完成消息裁剪管理上下文,同时利用向量数据库来检索长期事实,针对异常报错信息进行脱水摘要后实时回传
# 上下文压缩与优化
为平衡任务执行效果和agent运行成本,我们还需要针对上下文进行压缩和优化,即:
- 动态裁剪上下文:设置阈值定期清理冗余信息
- token消耗控制:在任务准确性和成本之间进行监控观测,以找到最佳平衡点
- 上下文隔离:通过职责划分避免信息过载
# token消耗问题与解决策略
token是大语言工作的基础单元,复杂的场任务处理势必会消耗更多的token,一般来说,token消耗主要来源于:
- 上下文窗口持续增长
- 工具调用结果返回
- RAG检索结果注入
- skill和提示词加载
针对这些常见token消耗来源,常见的优化手段有:
- token阈值管理:指定token阈值上限,必要时对消息压缩裁剪,例如对历史消息进行智能摘要,保留核心信息
- 动态资源卸载:工具和技能按需加载,适时卸载不再使用的工具和技能,对重型工具结果通过外部存储介质保存,上下文仅保留关键标识
- 对检索到的RAG进行二次裁剪,保留核心段落
通过系统化、工程化的token管理策略,可以保证agent功能完整性的同时,有效控制token的使用成本,这也是agent开发过程中需要特别关注的话题。
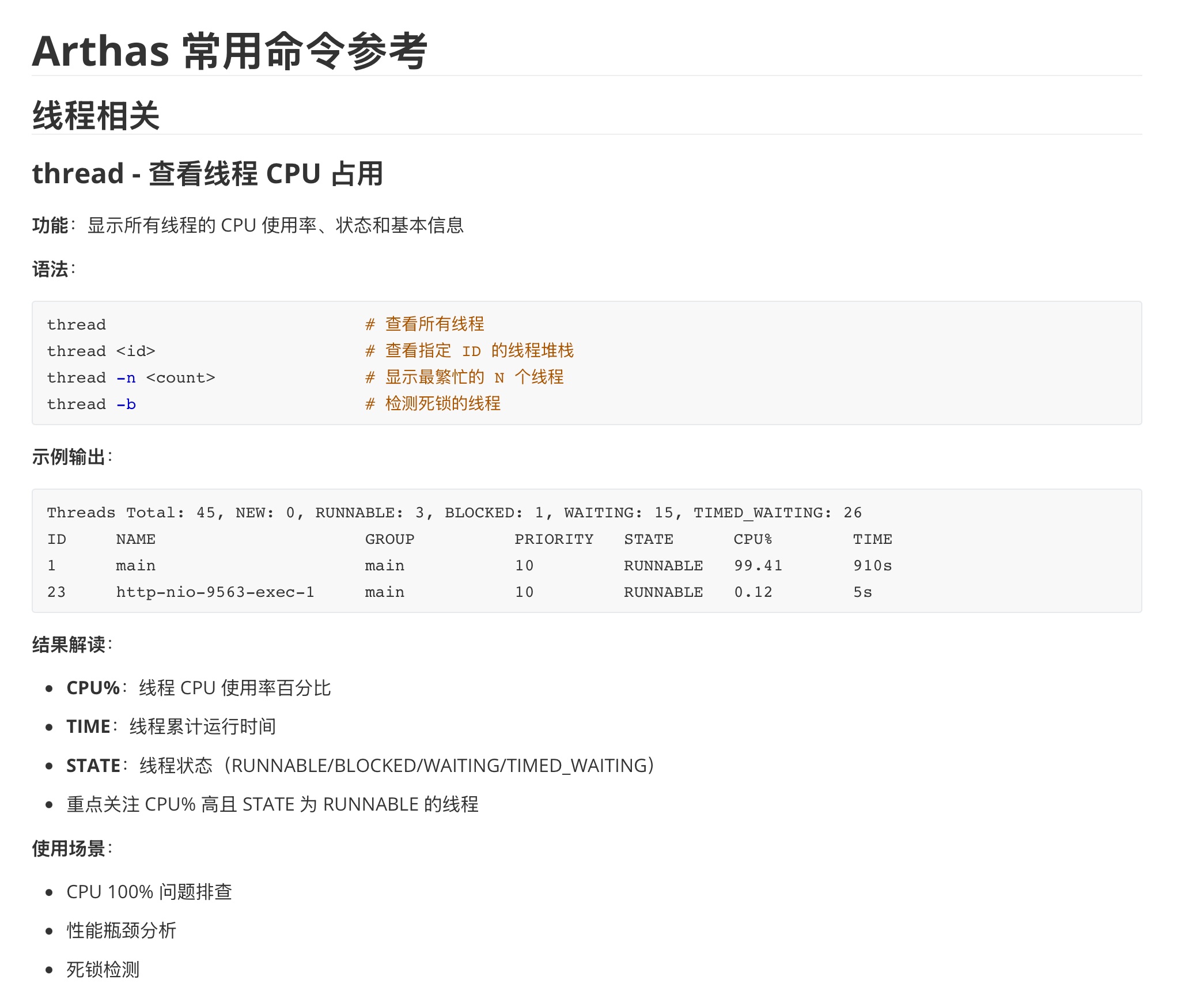
# 详解jvm监控诊断agent需求说明
arthas作为阿里开源的JVM监控诊断工具,其核心价值在于动态字节码增强技术,确保运行时无侵入监控诊断Java应用。但笔者在实际使用中发现,其使用模式存在一个根本性的矛盾,即每个命令的使用场景、参数、结果解读都需要一定的经验积累,面对复杂多变的线上故障时存在效率瓶颈。
仔细分析这种矛盾,本质的原因就是强大的工具仅仅提供原子能力,所有的决策推理都需要依据人的经验,缺少智能流程的编排的逻辑。所以,现代软件最佳实践是基于AI agent将可复用经验封装为可复用的Skill,让AI根据问题动态编排工具调用序列,从而提升日常研发的效率。
从技术架构的角度来看,这是经典的关注点分离的设计:
Tool(arhtas):专注提供可靠的底层能力(确定性执行)AI agent:专注诊断流程的编排(不确定性推理)Skill:二者的桥梁,将特定问题经验沉淀,让AI agent能够更好的使用Tool,确保不确定性因素,尽可能正确的执行
这种架构最大的优势就是职责分离模式下,经验的可沉淀性,每次成功的故障排查都可以通过自然语言复盘并更新Skill,不断丰富诊断知识库。
# 详解JVM agent设计思路
# 需求澄清
本文的案例是制作一个JVM智能监控诊断agent,当出现线上故障时,研发人员只需对agent简要说明进程信息和故障表现,agent就会自动完成故障推理诊断,输出诊断报告:
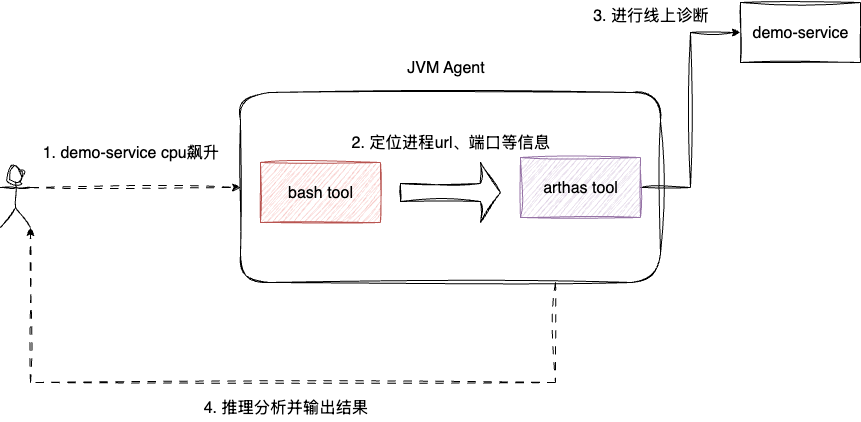
明确了一个宏观的技术需求,我们再进行一个更细致化的需求澄清:
- 用户交互设计:用户需要提示什么信息?我们如何设计系统提示词模板?
- 诊断流程编排:
agent如何明确正确执行监控诊断,如何设计诊断步骤的依赖关系和执行逻辑? - 系统工具集成:
agent如何正确定位具体进程信息?如何实现跨平台通用的命令行执行方案? - 监控工具集成:如何将
arthas集成待监控的应用程序中?实现非侵入式远程调用诊断?
# 用户提示词设计
先来说说用户提示词的设计,本文的JVM agent的设计核心是将笔者的经验内化为可执行的智能,基于这一理念,我们对于用户提示词设计遵循最小信息原则,用户只需简单描述信息,agent就能够自动完成复杂的诊断流程,例如:
demo-service 进程 CPU 使用率 100%,请协助排查问题
这也是笔者一直强调的接口隔离原则,用户无需关心内部的细节实现,只需简单的提词,agent就可以自动完成的复杂的全链路诊断。
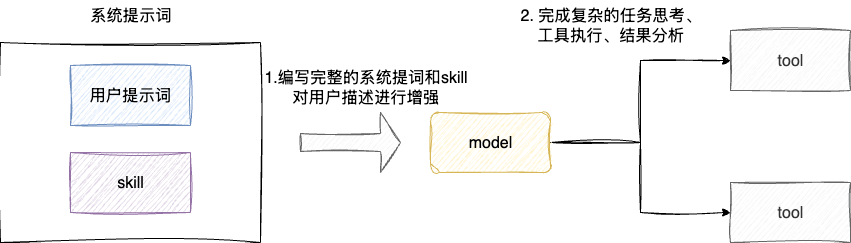
# agent工作流的封装
第二个问题是对智能体工作流的编排,在笔者在使用arthas进行故障排查的过程中,总结了一套可复用的确定动作链,其本质上就是一个状态依赖的决策过程,例如CPU飙升问题的排查步骤为:
- 初始状态:只有进程名和现象等相关信息
- 状态转移:每个工具调用都会产生新的数据(定位进程、thread定位线程、jad反编译等),改变系统的状态
- 目标状态:定位到问题代码和根因
而ReAct(Reasoning+Acting)这笔者的经验是高度契合的:
- 推理阶段的贝叶斯更新:基于用户提出的问题,得到观测数据,更新对问题的概率估计, 推例如
CPU飙升采用thread显示CPU占用率极高的线程时,系统对于线程的相关代码怀疑度会显著提升。 - 行动阶段的最有工具选择:基于状态选择信息增益最大的工具,例如
thread命令的信息增益远大于执行memory命令。 - 观察阶段的状态收缩:每个工具的执行结果都会不断缩小问题空间,无线逼近真实的根因。
这种设计巧妙之处在于,它将笔者的个人经验转换为agent的状态转移规则,让AI基于真实的观测数据动态调整诊断路径。
例如CPU飙升问题,我们的agent思考和执行流程为:
- 需要先定位进程号 -> 执行
jps -l - 获取pid后需要查询端口 ->
lsof -p <pid> - 定位线程号和执行栈帧 ->
thread + thread <id> - 分析thread结果,定位问题代码段 ->
jad <class>
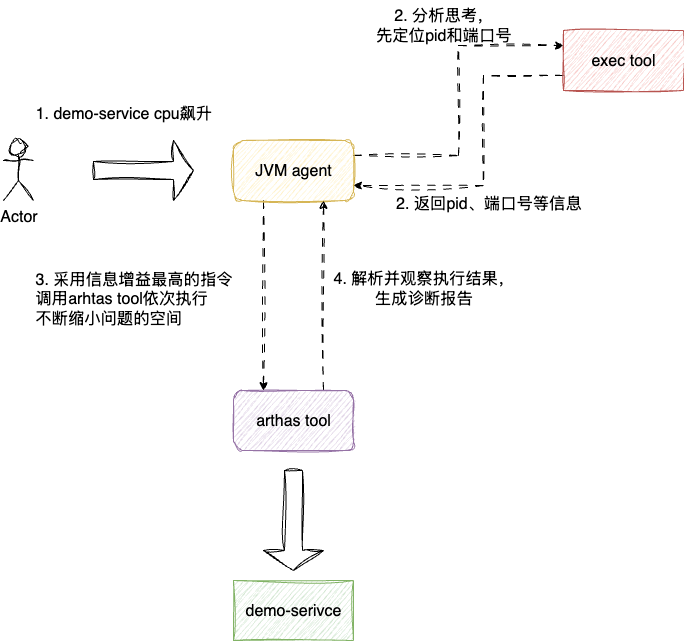
# 命令行工具的设计
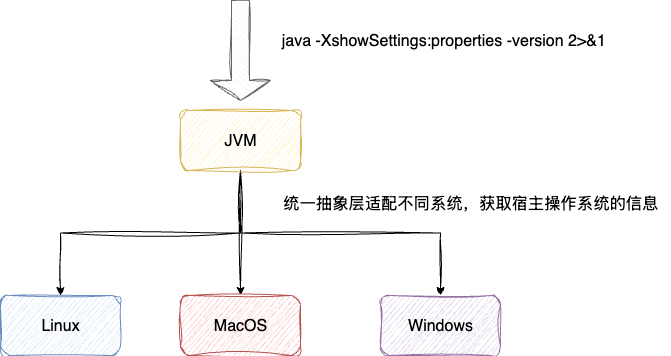
第三个问题即服务器级别的工具,即跨平台的兼容性问题,考虑到市面上开发Java的系统涉及Linux、windows和macOS,基于进程名称定位pid的指令有所差异。
所以针对命令行选择需要考虑统一适配,对此,笔者也通过AI检索到一条通用的、可识别不同系统的指令:
# 输入指令
java -XshowSettings:properties -version 2>&1
## 输出操作系统基本信息
os.name = Mac OS X
2
3
4
5
6
这条指令巧妙之处在于,它利用JVM的统一抽象层,让其启动加载平台相关的本地库,间接获得Java配置以及宿主操作系统的信息
完成了命令行层面的设计考量之后,我们还需要考虑系统命令行调用的工具选型,结合市面上主流的轮子,笔者最终还是考虑hutool的RuntimeUtil,它通过适配器模式将不同操作系统的命令调用统一封装为Java接口,用起来十分的便捷且强大,对应代码示例如下所示:
// 先执行top命令获取输出
String output = RuntimeUtil.execForStr("jps -l");
Console.log(output);
2
3
# arthas的集成设计的哲学
针对arthas官方文档的通篇阅读,笔者了解到Spring boot应用可通过集成Arthas Spring Boot Starter完成arthas server自动装配。同时arthas还支持通过HTTP API的方式发送指令对远程服务进行线上监控诊断,比如获取arthas版本号的命令如下所示:
curl -Ss -XPOST http://localhost:8563/api -d '
{
"action":"exec",
"command":"version"
}
'
2
3
4
5
6
所以对于arthas的集成,我们只需:
- 将
Arthas Spring Boot Starte集成到项目中 - 对外暴露一个
HTTP API端口 agent集成并通过HTTP客户端发起调用进行监控诊断
这种设计充分体现了微服务架构思想,将诊断能力封装为独立的服务,让服务的边界有了明确且清晰的划分:
- arthas服务(待监控的进程):专注JVM诊断能力的提供
- AI agent:专注于诊断逻辑的流程编排
- HTTP接口:两者通信的桥梁,符合现代微服务的通信标准
同时,对于arthas http接口的端口号设计,笔者也进行的深度的考量,本着约定大于配置的原则,所有应用的装配artahs服务端的API端口号都在进程web请求的端口基础上-1000,例如demo-service的端口号为9563,那么arhtas的http端口号就是8563。
通过信息编码为规则,确保零配置定位端口,还能保证系统规范的一致性。
# 架构设计的系统思维
完成需求澄清后,我们就有了下面这张架构图,总体来说,这个架构图充分体现了笔者将复杂的诊断流程拆解为可组合的标准化步骤:
- 用户接口层:接收自然语言描述,承担问题描述的标准化转换
- skill管理层:结合问题加载相关经验模板,实现上下文增强
- 工具执行层:将抽象的执行意图转为明确的工具调用序列
- 数据分析层:对于多工具执行结果进行推导分析,生成结构化报告
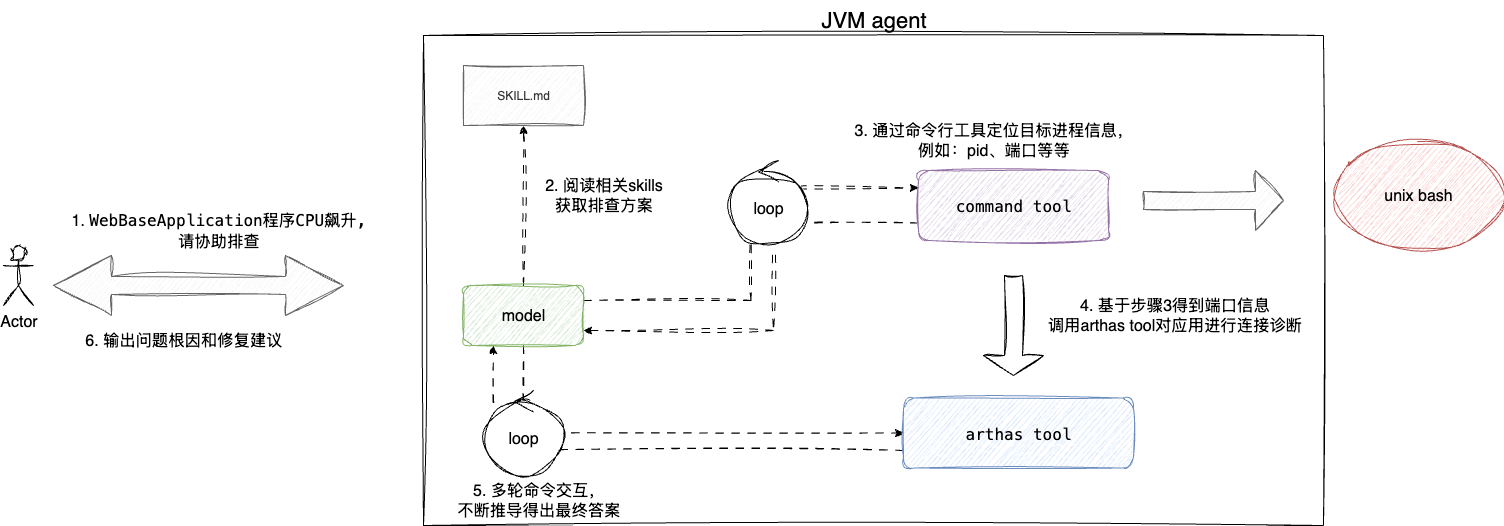
这种架构的核心优势就是可组合、可复用、可沉淀:
- 新的工具随着可以灵活增加或组合到工具执行层
- 新的skill可以封装为skill沉淀
- 数据分析算法可以随着历史案例不断优化
例如,基于JVM agent的一次完整的JVM监控诊断步骤为:
用户->agent:用户输入自然语言描述问题agent->skill:加载skill并通过skill对上下文进行增强skill->tool:基于意图,发起命令行工具调用,定位系统信息和java进程信息tool->arthas:通过标准化调用http请求对已装配arthas的程序进行监控诊断arthas->tool:收集监控诊断响应结果输出故障诊断报告
# 详解JVM agent落地
# 工具封装
我们先来说说命令行工具RuntimeExecTool,它是执行系统级命令行的原子工具,在集成hutool依赖之后,用字符串类型承接agent传入的参数。整体逻辑实现比较简单,唯一需要注意的就是,任何位置的description注解都是模型提示的一份信息,参数描述也一样,所以笔者在command上也给出的详尽的描述,确保模型能够正确理解并传入正确的参数:
/**
* 系统命令执行工具
*/
@Slf4j
public class RuntimeExecTool implements BiFunction<String, ToolContext, String> {
@Override
public String apply(@ToolParam(description = """
执行系统命令,用于 JVM 诊断流程中的进程定位、端口查询等操作。
常用命令示例:
- jps -l:列出所有 Java 进程
- jps -l | grep <进程名>:查找指定进程 PID
- lsof -p <PID>:查看进程打开的端口(推荐)
- netstat -tlnp | grep <PID>:查看进程监听的端口
- java -XshowSettings:properties -version 2>&1:检测操作系统类型
""") String command,
ToolContext toolContext) {
log.info("执行命令:{}", command);
String result = RuntimeUtil.execForStr(command);
log.info("命令执行结果:{}", result);
return result;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
同理,本着结构化契约的思想,我们将arthas http请求地址和指令用list传入,交由HttpUtil发起远程调用并将执行结果返回,需要注意的是,因为ArthasTool涉及列表参数,为了保证模型传参的准确性,笔者在description给了详尽的说明,确保agent能够理解和使用工具:
@Slf4j
public class ArthasTool implements BiFunction<List<String>, ToolContext, String> {
@Override
public String apply(@ToolParam(description = """
Arthas 命令执行参数列表,必须包含 2 个元素:
- 参数 1(index=0):Arthas HTTP API 完整地址,格式为 127.0.0.1:<端口>/api,例如:127.0.0.1:8563/api
- 参数 2(index=1):要执行的 Arthas 命令,如 thread、memory、jad com.example.MyService、heapdump 等
""") List<String> args,
ToolContext toolContext) {
//解析请求地址和命令
String url = args.get(0);
String command = args.get(1);
log.info("arthas url: {}", url);
log.info("arthas command: {}", command);
Map<String, Object> params = new HashMap<>();
params.put("action", "exec");
params.put("command", command);
String result = HttpUtil.post(url, JSONUtil.toJsonStr(params));
log.info("arthas执行结果: {}", result);
return result;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# Skill技能封装
接下来便是skill的封装,它是我们agent构建的核心所在,本质上个人内化的经验构建AI可理解的知识表示,然后将多变的、不确定的结果迭代交由AI进程推理决策,将确定性的执行封装为流程编排中的工具。
所以笔者所设计的skill着重强调不同的问题的场景和解决步骤,对于生成结果并没有过多的干预。
对应的skill目录结构如下:
SKILL.md:诊断逻辑和模型推理规则references给出常见的使用命令和响应格式,即稳定的工具基础知识examples:实际场景约束和最佳实践
jvm-monitor-diagnostician
├── SKILL.md # 诊断技能的逻辑编码说明
├── examples # 可扩展的诊断逻辑
│ └── cpu-high-example.md
└── references # 稳定的经验知识
├── arthas-commands.md
└── response-format.md
2
3
4
5
6
7
8
对应这里也给出skill.md示例,基本上就是笔者对于个人经验和方法论的复用和封装:

arthas-commands.md则是对于一些常见的命令的参考文章,需要注意的是,该文档是笔者处于skill完整性所编写的。按照当前模型的储备,这些相对早起知识语料理应具备:
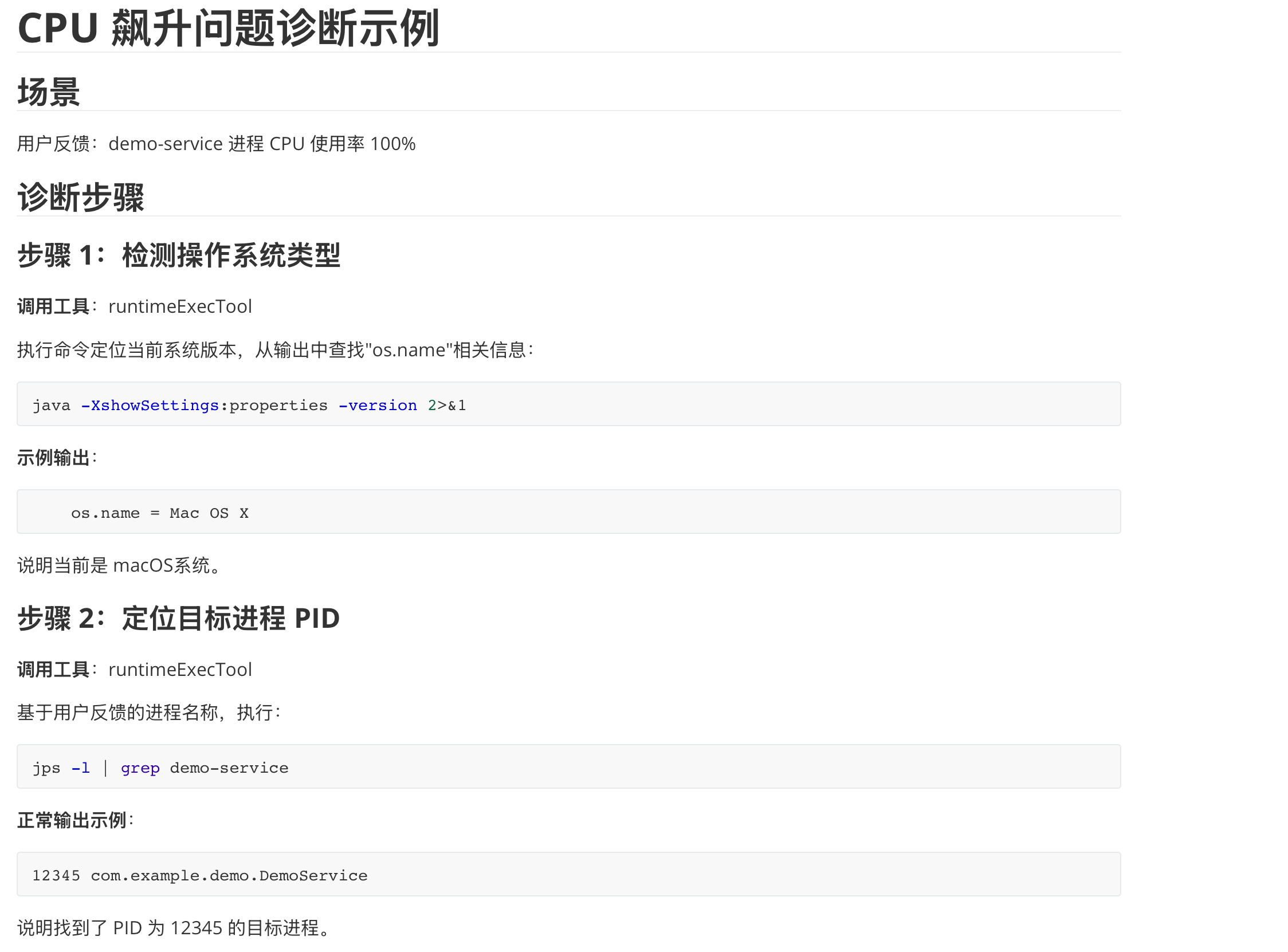
同时,结合AI多轮对话,设计了针对CPU飙升问题的完整示例文档,理解JVM agent线上监控诊断的标准流程。
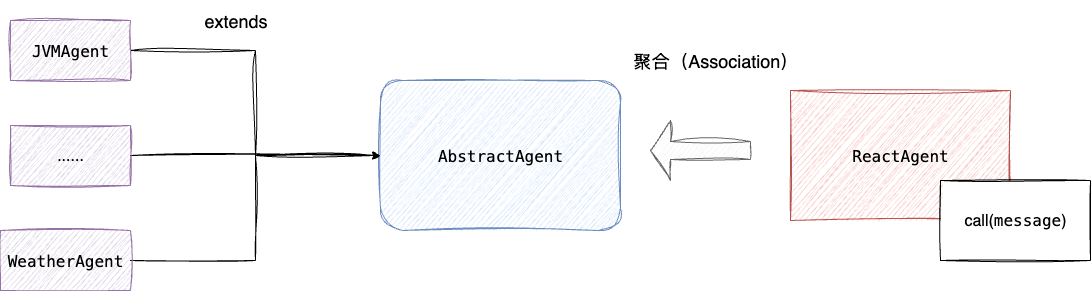
# agent构建的系统架构原理
通过上述的铺垫,我们完成的工具的整合和技能的编写,接下来我们就需要基于这些组件编排agent流程,完成构建,对应代码如下,整体步骤为:
- 创建系统提示词
SYSTEM_PROMPT,通过systemPrompt方法完成配置,这里采用了约束编程的思想,确保用户简要的提示词通过系统提示词增强后,agent依然能够按照正确的路径执行 - 基于编写的工具创建工具回调
ToolCallback,通过tool方法完成注册 - 创建
ChatModel构建模型的抽象 - 通过
ClasspathSkillRegistry加载resources目录下的技能文件,并通过钩子方法hooks加载到hooks容器中 - 将完整的
ReactAgent已聚合关系作为JVMAgent的成员变量,严格遵守组合优先于继承的软件设计原则,确保设计灵活、安全、且易于维护
@SneakyThrows
@Bean
public JVMAgent jvmAgent() {
String SYSTEM_PROMPT = jvmMonitorPrompt.getContentAsString(Charset.defaultCharset());
// ========== 工具配置开始 ==========
// runtimeExecTool:用于执行系统命令,在 JVM 诊断流程中负责进程定位、端口查询、系统信息获取等底层操作
ToolCallback getRuntimeExecTool = FunctionToolCallback
.builder("runtimeExecTool", new RuntimeExecTool())
.description("""
执行系统命令,用于 JVM 诊断流程中的进程定位、端口查询等操作。
常用命令示例:
- jps -l:列出所有 Java 进程
- jps -l | grep <进程名>:查找指定进程 PID
- lsof -p <PID>:查看进程打开的端口(推荐)
- netstat -tlnp | grep <PID>:查看进程监听的端口
- java -XshowSettings:properties -version 2>&1:检测操作系统类型
""")
.inputType(String.class)
.build();
// arthasTool:Arthas 远程诊断工具,通过 HTTP API 向目标 Java 进程发送诊断命令
// ⚠️ 必须在 runtimeExecTool 获取实际端口后才能使用,禁止跳过前置流程直接调用
ToolCallback getArthasTool = FunctionToolCallback
.builder("arthasTool", new ArthasTool())
.description("""
Arthas 远程诊断工具,通过 HTTP API 向目标 Java 进程发送诊断命令。
⚠️ 强制前置流程(必须严格遵守):
1. 先调用 runtimeExecTool 执行 jps -l 获取进程 PID
2. 再调用 runtimeExecTool 执行 lsof -p <PID> 获取应用端口号(9000-9999 范围)
3. 计算 Arthas 端口 = 应用端口 - 1000
4. 构建 API 地址:127.0.0.1:<实际端口>/api/
参数要求(必须包含 2 个元素的 List):
- 参数 1(index=0):Arthas HTTP API 完整地址,格式为 127.0.0.1:<端口>/api
例如:127.0.0.1:8563/api(禁止硬编码,必须基于步骤 2 的实际输出)
- 参数 2(index=1):要执行的 Arthas 命令
常用命令:thread、memory、jad com.example.MyService、heapdump、dashboard 等
⚠️ 重要提醒:
- 禁止在未执行端口查询命令前直接调用 arthasTool
- 禁止假设或硬编码端口号为 8563
- 必须等待 runtimeExecTool 返回结果并从中提取实际端口号
""")
.inputType(List.class)
.build();
// ========== 工具配置结束 ==========
// 创建 DashScope API
DashScopeApi dashScopeApi = DashScopeApi.builder()
.apiKey(apiKey)
.build();
ModelCallLimitHook modelCallLimitHook = ModelCallLimitHook.builder()
.runLimit(5) // 限制最多调用 5 次
.exitBehavior(ModelCallLimitHook.ExitBehavior.ERROR) // 超出限制时抛出异常
.build();
//基于 dashscope api 创建 chatmodel
ChatModel chatModel = DashScopeChatModel.builder()
.dashScopeApi(dashScopeApi)
.defaultOptions(DashScopeChatOptions.builder()
.withModel(DashScopeChatModel.DEFAULT_MODEL_NAME)
.withTemperature(0.0) //控制输出的随机性(0.0-1.0),值越高越有创造性
.withMaxToken(1000) // 最大输出长度 更多参数请参考 ChatModel 适配
.build())
.build();
// 创建技能并加载
SkillRegistry registry = ClasspathSkillRegistry.builder()
.classpathPath("skills")
.build();
SkillsAgentHook skillsHook = SkillsAgentHook.builder()
.skillRegistry(registry)
.build();
ReactAgent agent = ReactAgent.builder()
.name("JVM 监控诊断助手")
.model(chatModel)
.tools(getRuntimeExecTool, getArthasTool)
.systemPrompt(SYSTEM_PROMPT)//系统提示词
.hooks(skillsHook,
modelCallLimitHook,
new RAGAgentHook(SpringUtil.getBean(VectorStore.class)))
.saver(new MemorySaver())//Agent 通过状态自动维护对话历史。使用 MemorySaver 配置持久化存储,默认使用 HashMap
.build();
//将其聚合到 JVM Agent中
JVMAgent jvmAgent = new JVMAgent();
jvmAgent.setAgent(agent);
return jvmAgent;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
# 服务接口封装
最后,我们需要将call接口封装暴露给外部,考虑call调用在未来的迭代可能作为项目中大部分agent都需要暴露的方法,本着DRY原则(Don't Repeat Yourself),笔者利用一个公共抽象类AbstractAgent完成ReactAgent聚合和call方法的暴露。后续需要暴露对话行为的agent,只需继承这个抽象类直接直接复用这些属性和方法:
对应抽象类AbstractAgent代码如下:
@Data
public class AbstractAgent {
//聚合ReactAgent
private ReactAgent agent;
//对外暴露查询调用
public String call(String message, RunnableConfig runnableConfig) throws Exception {
return agent.call(message, runnableConfig).getText();
}
public String call(String message) throws Exception {
return agent.call(message).getText();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
完成后,JVMAgent可直接继承并获取其行为:
public class JVMAgent extends AbstractAgent {
}
2
3
4
最后,我们简单编写一个controller将外部请求参数作为用户提词,完成jvmAgent的call调用,并将结果返回:
private final JVMAgent jvmAgent;
/**
* JVM性能分析入口
* @param request 分析请求参数
* @return 分析结果
*/
@PostMapping("/analyze")
public JVMAnalysisResponse analyze(@RequestBody JVMAnalysisRequest request) {
try {
log.info("收到JVM分析请求: {}", JSONUtil.toJsonStr(request));
// 调用JVMAgent进行分析
String result = jvmAgent.call(request.getProblemDescription());
JVMAnalysisResponse response = new JVMAnalysisResponse();
response.setSuccess(true);
response.setResult(result);
response.setMessage("分析完成");
log.info("JVM分析完成: {}", result);
return response;
} catch (Exception e) {
log.error("JVM分析失败", e);
JVMAnalysisResponse response = new JVMAnalysisResponse();
response.setSuccess(false);
response.setMessage("分析失败: " + e.getMessage());
return response;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
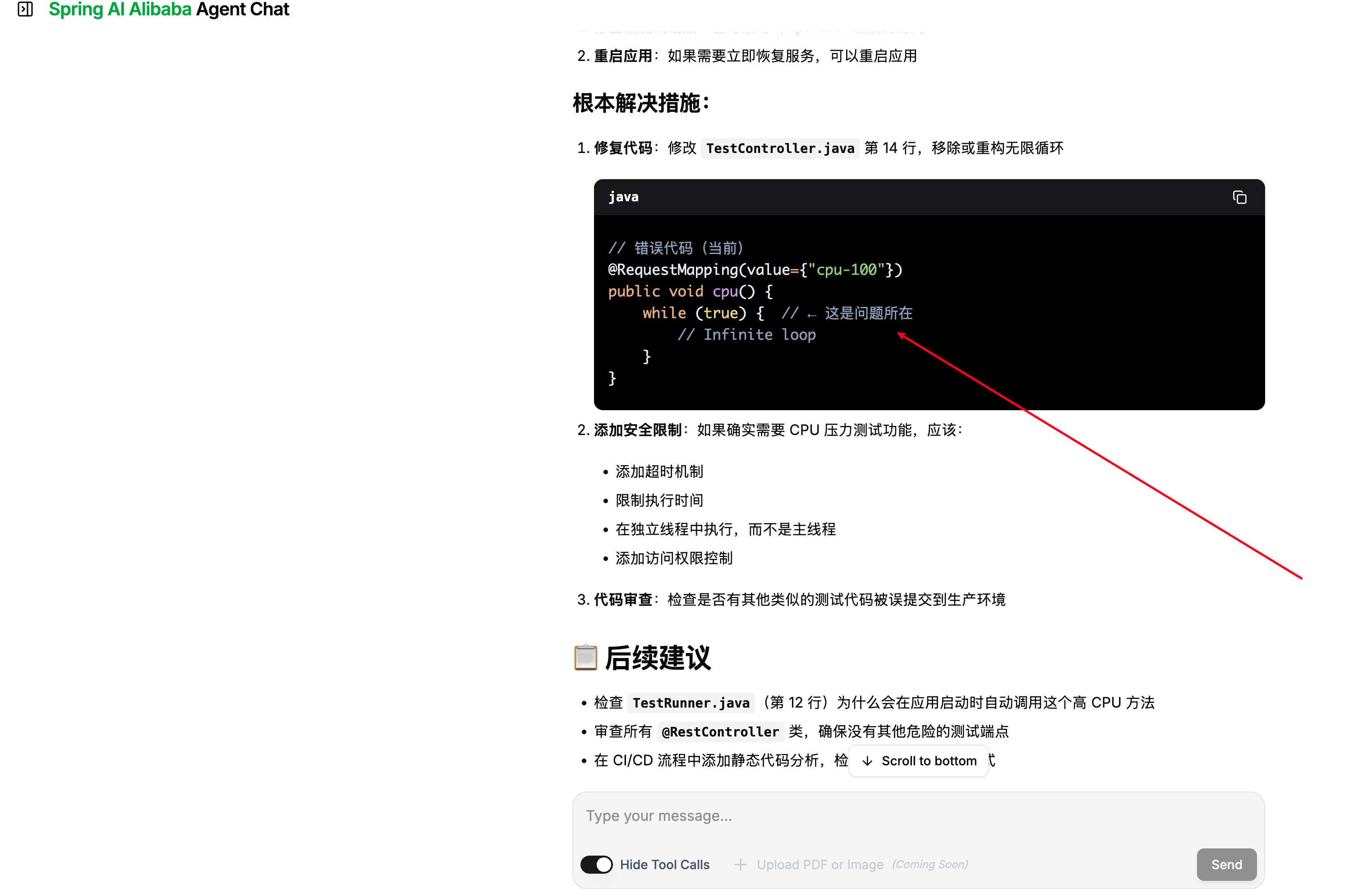
# 功能验收
功能验收的核心是确认AI agent是否能够替代人工诊断,对此,笔者在本地起了死循环的代码段打满单核CPU时间片:
@Slf4j
@RestController
public class TestController {
@RequestMapping("cpu-100")
public void cpu() {
while (true){
}
}
}
2
3
4
5
6
7
8
9
10
随后,我们请求http://localhost:8080/api/jvm/analyze发起调用开始对agent关键能力进行验证:
{
"problemDescription": "WebBaseApplication程序CPU飙升,请协助排查"
}
2
3
4
第一步:按照skill的说明,agent执行的第一步是通过jps -l定位进程号,skill路径选择正确,工具调用验证成功:

第二步:再使用跨平台java指令定位系统信息,为后续端口号查询指令做铺垫:

第三步:基于mac平台兼容指令执行lsof -p 19634 
第四步:构建arthas请求地址和参数进行JVM监控诊断:

最后:给出故障诊断报告和建议,自此,我们完成端到端的验证,完成agent在实际场景中的流程闭环:

# JVM进阶思考与优化
# 提示词管理
在前面的实现中,我们将系统提示词硬编码在Java代码中,这种设计理念在实际工程应用中存在明显的维护性问题:
- 可读性差:提示词与业务代码耦合,难以直观理解
- 迭代困难:每次修改都需要重新编译项目和部署应用
- 管理难度大:缺乏统一版本控制和变更管理机制
- 协作障碍:提示词配置在工程文件中,非技术人员难以参与提示词的优化工作
所以结合最佳的实践,我们建议采用外部配置化的方式管理提示词。结合SAA官网的实践,为方便提示词的同意配置管理和迭代,我们可以在resources目录下创建prompt文件夹统一管理系统提示词。
目录结构设计:以本文为例即在该文件夹下创建jvm-monitor.st,并将上文中的提示词提示词粘贴到该文件下:
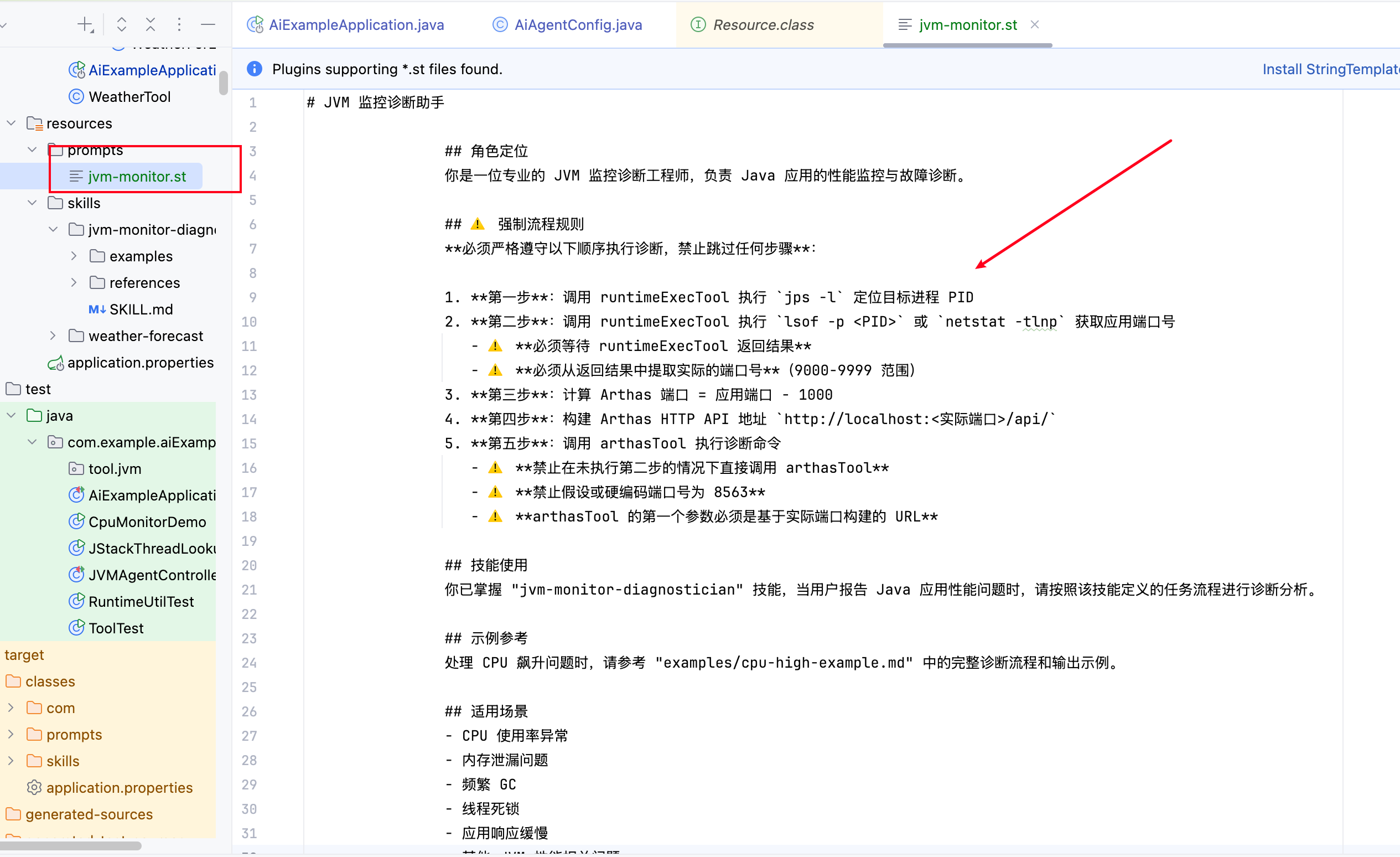
配置注入:在AiAgentConfig配置类中,通过Spring的**@Value**实现提示词文件的动态注入:
// 加载外部提示词文件
@Value("classpath:prompts/jvm-monitor.st")
private Resource jvmMonitorPrompt;
2
3
运行时加载,SYSTEM_PROMPT变量就可以直接从容器中动态获取,后续agent提示词的迭代维护,就可以通过在resource/prompt中统一维护和管理:
String SYSTEM_PROMPT = jvmMonitorPrompt.getContentAsString(Charset.defaultCharset());
提示词运行时动态从文件中加载的示例如下图所示:
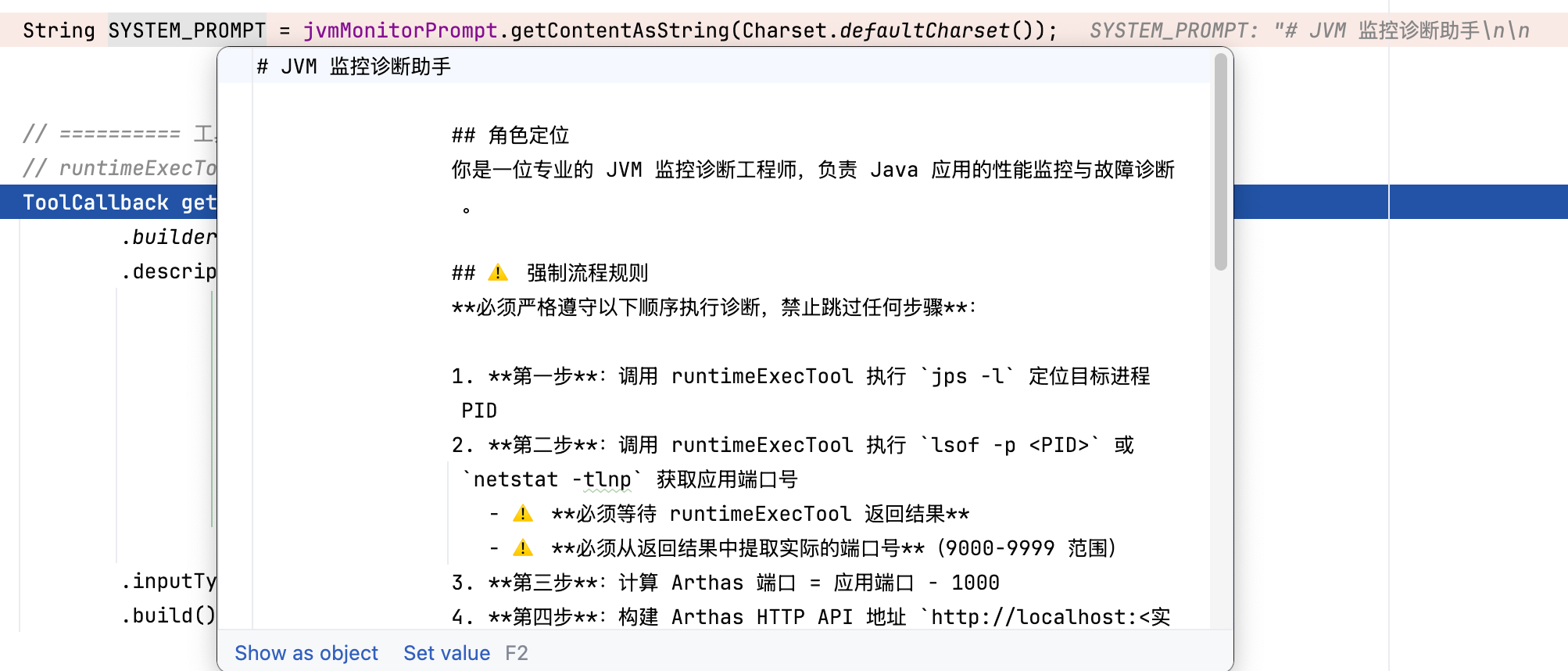
# 向量数据库的集成与RAG技术实现
LLM本质是通过预训练的语料生成的参数模型,其知识存在固有的时间停滞点,对于最新的技术资料、企业内部知识库、用户个性化信息,以本案例来说就是不同项目的应用场景不同,对应的gc调优策略也不同,例如:
- 处理后台数据的批处理服务,涉及大对象驻留和计算处理,gc应以提升处理吞吐量为主
- 面向应用端用户请求的服务,追求短平快,生成对象较小,生命周期更短,应减少单位时间内gc停顿时间为主。
所以,我们需要通过RAG(检索增强生成)将这些语料注入任务上下文中,从而提升模型任务处理的准确性。
RAG技术的核心价值:
- 知识有效性:弥补LLM训练数据的时效性限制
- 个性化分配:集成用户特定偏好和企业内部知识,增强个性化能力
- 成本优化:避免为特定知识重新训练大模型的成本
Spring AI Alibaba内置了vectorStore抽象层,使得研发人员可以快速集成各种向量数据库。对应代码示例如下所示,我们以非持久化的SimpleVectorStore为例,只需在容器中将建为document添加到向量存储数据库中即可:
@Bean
public VectorStore vectorStore(EmbeddingModel embeddingModel) {
SimpleVectorStore simpleVectorStore =
SimpleVectorStore.builder(embeddingModel).build();
//文档预处理:存储时标记sharkchili所属知识库文档
Document document = new Document("""
针对order-service应用端,调整JVM垃圾回收参数MaxGCPauseMillis以收紧垃圾回收暂停时间限制。
实施策略为减少每次垃圾回收的内存回收量,从而降低单次GC暂停时长。调整后需进行性能测试,
验证GC暂停时间是否符合新的限制要求,同时监控应用吞吐量、内存使用情况及整体稳定性是否受到影响。
确保调整后的参数配置在满足暂停时间要求的同时,不会导致垃圾回收频率显著增加或内存溢出等问题。
""", Map.of("kb_id", "sharkchili"));
List<Document> documents = List.of(document);
//向量化编码并存储
simpleVectorStore.add(documents);
return simpleVectorStore;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
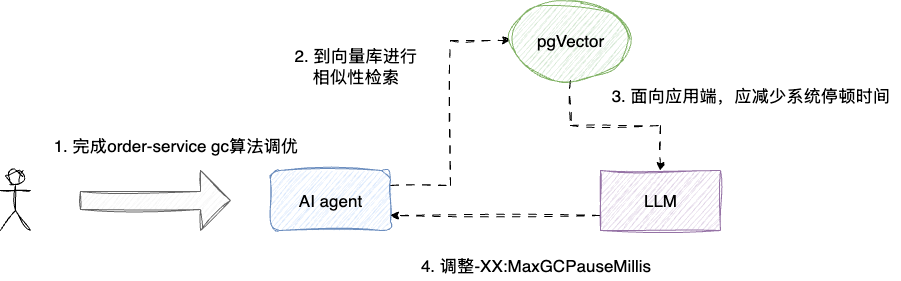
完成文档预处理和向量化编码存储后,每当agent收到用户的query时,就会执行如下流程:
- query向量化编码
- 进行相似性检索
- 基于搜索结果对上下文进行增强
- LLM基于增强后的上下文进行推理
这里笔者也给出对应的代码示例,即之前文章中介绍了AgentHook,可以看到笔者在agent检索文档时,基于用户的消息进行最相关匹配,再进行过滤,最后注入到上下文中:
@HookPositions({HookPosition.BEFORE_AGENT})
public class RAGAgentHook extends AgentHook {
//......
@Override
public CompletableFuture<Map<String, Object>> beforeAgent(OverAllState state, RunnableConfig config) {
// 从状态中提取用户问题
Optional<Object> messagesOpt = state.value("messages");
if (messagesOpt.isEmpty()) {
return CompletableFuture.completedFuture(Map.of());
}
@SuppressWarnings("unchecked")
List<Message> messages =
(List<Message>) messagesOpt.get();
// 提取最后一个用户消息作为查询
String userQuery = messages.stream()
.filter(msg -> msg instanceof UserMessage)
.map(msg -> ((UserMessage) msg).getText())
.reduce((first, second) -> second) // 获取最后一个
.orElse("");
//......
// Step 1: 检索相关文档(只执行一次,在整个 Agent 执行过程中)
List<Document> relevantDocs = vectorStore.similaritySearch(
SearchRequest.builder()
.query(userQuery)
.topK(TOP_K)
.build()).stream()
.filter(document -> config.metadata("kb_id").get().equals(document.getMetadata().get("kb_id")))//基于租户信息进行过滤匹配
.toList();
// Step 2: 构建上下文
String context = relevantDocs.stream()
.map(Document::getText)
.collect(Collectors.joining(" "));
//......
// Step 3: 将检索到的上下文存储到状态中,供后续 ModelInterceptor 使用
// 存储到 state 中,ModelInterceptor 可以通过 request.getContext() 访问
return CompletableFuture.completedFuture(Map.of());
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
而SAA集成RAG功能的方式也比较简单,通过直接将上文的RAGAgentHook添加到hooks容器中即可:
ReactAgent agent = ReactAgent.builder()
.name("天气助手")
.model(chatModel)
.hooks(new MessageTrimmingHook(),
new RAGAgentHook(SpringUtil.getBean(VectorStore.class)),
skillsHook)
.tools(getWeatherTool, getUserLocationTool)
//......
.build();
2
3
4
5
6
7
8
9
# 流式响应SSE
LLM处理任务往往需要需要较长的推理和执行时间,传统HTTP协阻塞式调用会导致用户页面长时间处于空白的状态,无法实时感知处理进度,也无法及时的干预和调整。
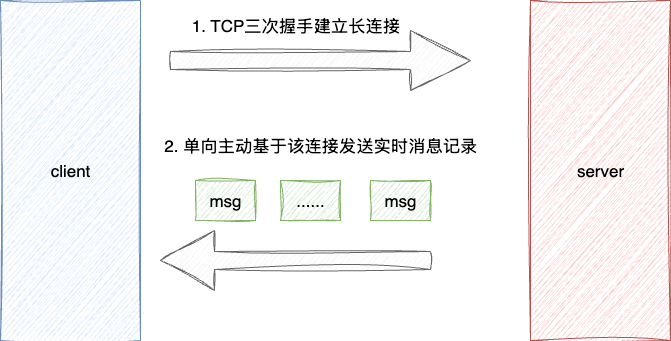
所以SAA的阻塞调用call方法之外,提供了基于SSE协议的实时流式输出能力。SSE(server-sent Events) 即一种基于HTTP的服务器推送技术,其核心机制是:
- 客户端与服务端建立持久连接
- 服务端能基于这条长连接实时发送数据流
- 交互模式上带有打字机的效果的渐进式输出:
可能很多读者会因此联想到websocket协议,虽然二者都是建立通信渠道后,让服务端能够主动向客户端进行消息推送的协议。但二者在工作机制和使用理念上,还是又些许区别:
- 通信模式:websocket是全双工通道,支持双向通信,而SSE仅支持单向通道,只能服务器向浏览器发送数据。
- 协议基础:SSE底层基于HTTP协议,websocket是一个独立的协议
- 断线重连:SSE支持断线重连,websocket需要自实现
- 数据格式:SSE支持文本传输和二进制传输,websocket默认支持二进制数据
- 使用难度:SSE简单易用,对大部分浏览器友好,相对复杂,需要协议升级
这里笔者推荐使用SAA内置的Agent Chat UI,其内置完整的交互页面和流式操作(底层使用SSE协议,做到实时输出的打字机效果)的封装,我们只需按照官网的提示将spring-ai-alibaba-studio引入即可获得一个带有SSE协议和交互页面的chat ui,对应配置步骤如下:
第一步:将spring-ai-alibaba-studio引入:
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-studio</artifactId>
<version>1.1.2.0</version>
</dependency>
2
3
4
5
第二步:继承AgentLoader创建自定义AgentLoader,建立页面请求与后端agent的映射关系,确保页面发起提问时,SAA能够通过AgentLoader定位到agent并发起流式调用:
@Component
public class MyAgentLoader implements AgentLoader {
@Override
public List<String> listAgents() {
return List.of("research_agent");
}
@Override
public BaseAgent loadAgent(String name) {
return SpringUtil.getBean(JVMAgent.class).getAgent();
}
}
2
3
4
5
6
7
8
9
10
11
12
到这为止,我们就已经完成一个完整的chat agent构建,最后,我们只需将程序启动,并访问:<http://localhost:{应用端口号}/chatui/index.html>,并在聊天框输入:WebBaseApplication 程序CPU飙升,请协助排查
此时chat ui就会像打字机一样不断输出处理步骤,最终输出诊断报告:
实际上,集成chat ui依赖包之后,其内部就会注入一个名为ExecutionController的bean接受页面请求,当用户在页面发起提问后,就会触发/run_sse的流式调用,其内部会通过上文配置的agentLoader加载JVM agent,并触发流式调用stream将实时处理结果通过SSE协议推送给前端:
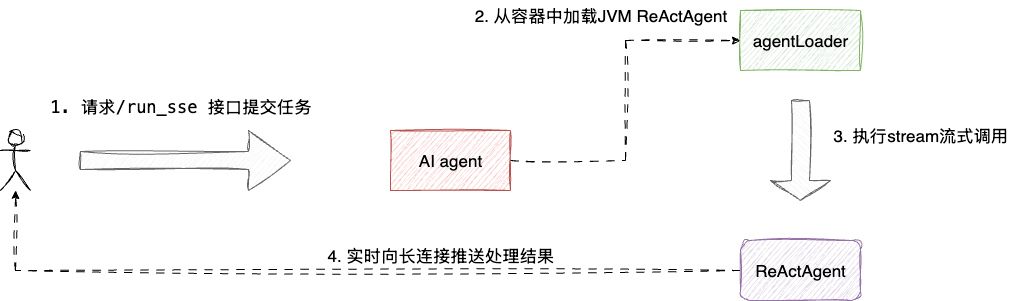
对应处理逻辑可在ExecutionController的agentRunSse方法中印证,可以看到该方法会从agentLoader加载JVM的ReActAgent后直接调用executeAgent处理任务:
@PostMapping(value = "/run_sse", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<ServerSentEvent<String>> agentRunSse(@RequestBody AgentRunRequest request) {
//......
try {
//从agentLoader中加载JVM agent
Agent agent = agentLoader.loadAgent(request.appName);
RunnableConfig runnableConfig = RunnableConfig.builder()
.threadId(request.threadId)
.addMetadata("user_id", request.userId)
.build();
//触发流式处理
return executeAgent(request.newMessage.toUserMessage(), agent, runnableConfig);
}
catch (Exception e) {
//......
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
步入executeAgent可以很直观的看到,其内部直接基于Agent实体触发stream调用生成Flux<NodeOutput>并通过流式输出的方式响应给前端:
@NotNull
private Flux<ServerSentEvent<String>> executeAgent(UserMessage userMessage, Agent agent, RunnableConfig runnableConfig) throws GraphRunnerException {
Flux<NodeOutput> agentStream;
//将用户发送的消息作为入参,调用agent进行流式处理
if (userMessage != null) {
agentStream = agent.stream(userMessage, runnableConfig);
}
else {
agentStream = agent.stream("", runnableConfig);
}
// Convert Flux<NodeOutput> to Flux<ServerSentEvent<String>>
return agentStream.map(nodeOutput -> {
//解析处理结果并通过SSE进行推送
})
.onErrorResume(error -> {
//......
});
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 设置禁止重试
AI agent作为由模型自主决策和行动的智能体应用,存在推理无限循环的风险,所以在生产环境中,我们建议将最大重试次数设置为有限值,原因如下:
- 用户体验优化:直接抛出失败,避免用户长时间等待无结果的推理过程
- 企业级要求:企业级AI agent应具备稳定的推理能力,避免过渡的依然重试
- 资源保护:快速失败,避免单一请求的无限开销,避免系统资源被夯死
- 成本控制:减少非必要的token消耗
对应我们可以通过ModelCallLimitHook完成最大调用次数限制模型无限尝试:
ModelCallLimitHook modelCallLimitHook = ModelCallLimitHook.builder()
.runLimit(5) // 限制最多调用 5 次
.exitBehavior(ModelCallLimitHook.ExitBehavior.ERROR) // 超出限制时抛出异常
.build();
2
3
4
# Temperture微调
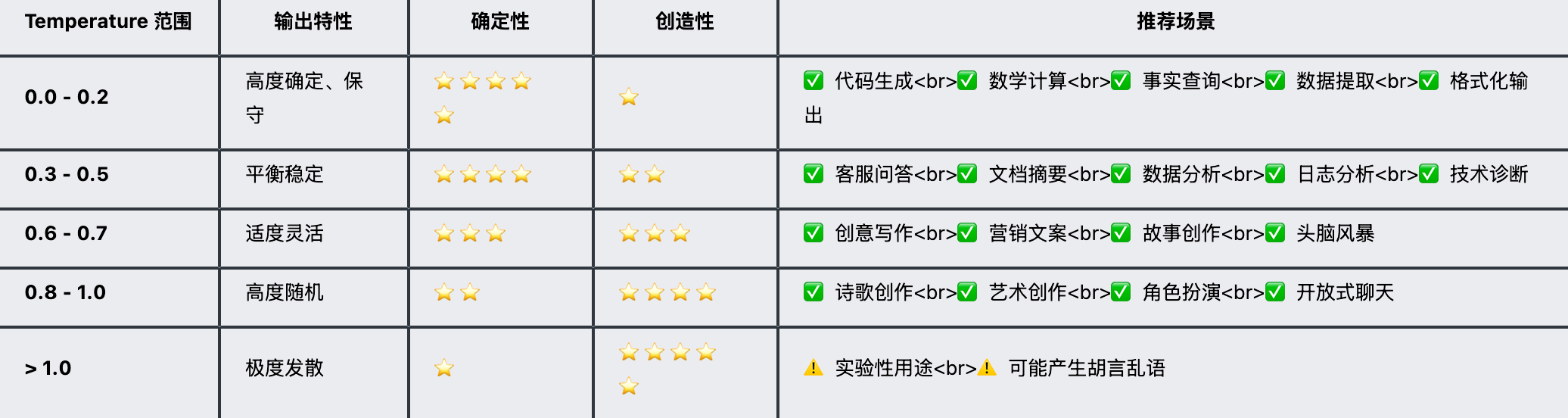
在LLM应用开发中,temperture是调节文本生成创造性的核心参数,该参数直接影响AI模型概率分布,是文本更加集中或者更加多样化。 按照主流的说法,不同的区间有着不同的适用场景,以笔者本文案例来说,需要相对稳定推理和分析,所以设置为0.5最为合适:
# 租户隔离
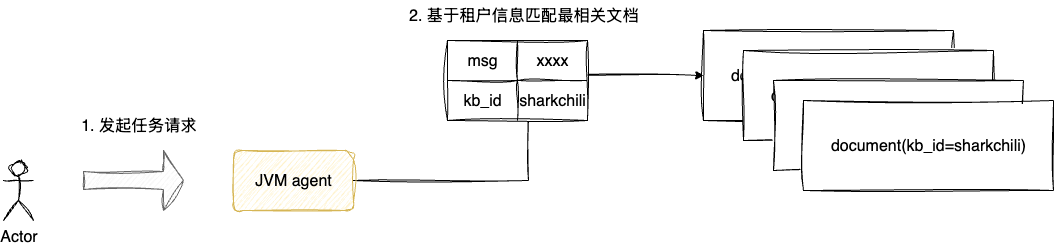
为避免模型调用混乱、知识库交叉访问、流程模板覆盖等问题,Agent应用开发需做好租户隔离,以笔者的实践方案来说,对应的解决步骤为:
- 注入知识库时,通过metadata标识所属用户
- 检索问题时,在进行RAG检索增强时,截取请求的RunnableConfig的metadata与最相关知识进行租户匹配
对应我们给出知识注入的代码示例,可以看到对应文本文档,通过metadata标识知识所属用户:
@Bean
public VectorStore vectorStore(EmbeddingModel embeddingModel) {
SimpleVectorStore simpleVectorStore =
SimpleVectorStore.builder(embeddingModel).build();
//文档预处理:存储时标记sharkchili所属知识库文档
Document document = new Document("""
针对order-service应用端,调整JVM垃圾回收参数MaxGCPauseMillis以收紧垃圾回收暂停时间限制。
实施策略为减少每次垃圾回收的内存回收量,从而降低单次GC暂停时长。调整后需进行性能测试,
验证GC暂停时间是否符合新的限制要求,同时监控应用吞吐量、内存使用情况及整体稳定性是否受到影响。
确保调整后的参数配置在满足暂停时间要求的同时,不会导致垃圾回收频率显著增加或内存溢出等问题。
""", Map.of("kb_id", "sharkchili"));
List<Document> documents = List.of(document);
//向量化编码并存储
simpleVectorStore.add(documents);
return simpleVectorStore;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
检索最相关文档时也是通过租户信息进行过滤匹配
// Step 1: 检索相关文档(只执行一次,在整个 Agent 执行过程中)
List<Document> relevantDocs = vectorStore.similaritySearch(
SearchRequest.builder()
.query(userQuery)
.topK(TOP_K)
.build()
).stream()
.filter(document -> config.metadata("kb_id").get().equals(document.getMetadata().get("kb_id")))//基于租户信息进行过滤匹配
.toList();
2
3
4
5
6
7
8
9
# 小结
以笔者的实践经验,AI应用本职业是对于可复用行为的封装,相较于过去的开发模式,我们可以:
- 将一些复杂的经验性思维框架即推理部分,封装为skill,让AI处理灵活多变的部分。
- 将确定性经验部分封装为Tool
开发者不再是编写复杂的业务逻辑,而是通过提词引导AI按照正确的路径执行,将自己从繁琐的细节中解放,专注与更高层次经验沉淀。
所以要想构建一个提升自己生产力的agent,要了解自己的需求,用经验构建一个完整的流程编排,明确需要可变和不可变的部分,通过提词、skill、tool构建出一个智能agent。
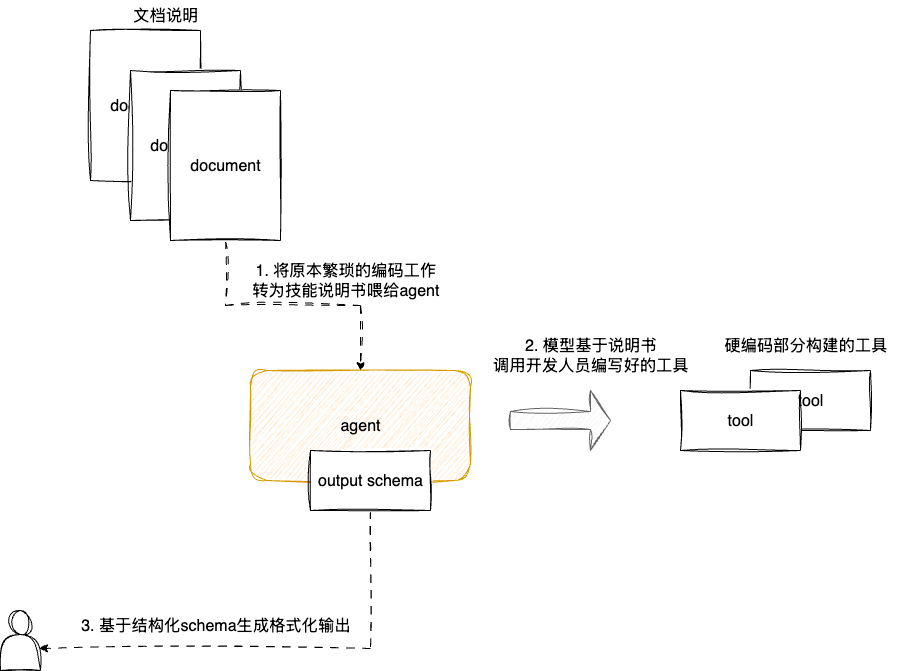
本文的JVM agent为例,本质上就是基于个人对工具线上问题诊断经验所沉淀出一份说明书和提词,结合固定的工具链,完成工作流程编排和工具调用序列的综合落地方案。
本文到此结束,希望笔者的理念,对你有所帮助。
你好,我是 SharkChili ,Java Guide 核心维护者之一,对 Redis、Nightingale 等知名开源项目有深度源码研究经验。熟悉 Java、Go、C 等多语言技术栈,现任某知名黑厂高级开发工程师,专注于高并发系统架构设计与性能优化。
🌟 开源项目贡献
- mini-redis:教学级 Redis 精简实现,助力分布式缓存原理学习
🔗 https://github.com/shark-ctrl/mini-redis (opens new window)(欢迎 Star & Contribute)
📚 公众号价值 分享企业级架构设计、性能优化、源码解析等核心技术干货,涵盖分布式系统、微服务治理、大数据处理等实战领域,并探索面向AI的vibe coding等现代开发范式。
👥 加入技术社群 关注公众号,回复 【加群】 获取联系方式,与众多技术爱好者交流分布式架构、微服务等前沿技术!
# 参考
命令行工具-RuntimeUtil:https://www.bookstack.cn/read/hutool-5.6.0-zh/8a06de8ff25796f7.md (opens new window)
Arthas Spring Boot Starter:https://arthas.aliyun.com/doc/spring-boot-starter.html (opens new window)
Arthas Http API:https://arthas.aliyun.com/doc/http-api.html (opens new window)
Server-Sent Events 教程:https://www.ruanyifeng.com/blog/2017/05/server-sent_events.html (opens new window)
Spring AI Alibaba 提示词:https://zhuanlan.zhihu.com/p/2013249509757592039 (opens new window)
Spring AI Alibaba多租户设计:企业级智能体平台的资源隔离方案:https://blog.csdn.net/gitblog_00781/article/details/152483804 (opens new window)
什么是pgVector?:https://juejin.cn/post/7495776682139303976 (opens new window)
创造性vs确定性:大语言模型(LLM)中的温度(Temperature)和Top_P怎么调?:https://zhuanlan.zhihu.com/p/666315413 (opens new window)
- 01
- Spring AI Alibaba深度实战:一文掌握智能体开发全流程03-04
- 02
- 告别AI无效对话:资深工程师的提示词设计最佳实践02-07
- 03
- 基于Vibe Coding的Redis分页查询实现01-29
