 Spring Boot 启动优化实战:1分钟到13秒的排查与优化之路
Spring Boot 启动优化实战:1分钟到13秒的排查与优化之路
# 写在文章开头
你是否遇到过这样的场景?灰度发布时,服务启动慢导致滚动更新时间过长;本地开发调试,每次重启都要等待漫长的时间。随着业务迭代和组件增多,Spring Boot 启动速度逐渐成为开发效率和上线效率的瓶颈。
面对启动慢的问题,借助系统化的方法论与 AI 工具的协同,我们可以快速定位瓶颈并实施优化。以笔者近期为例,一个 Spring Boot 启动优化的任务,原本评估需要 2 天,实际不到半天就完成了。
本着对解决方案的梳理和复盘,笔者创建了一个 demo 工程并以此文进行详细演示。本文将介绍:
- 如何通过 Spring 扩展点机制精准定位启动瓶颈
- Druid 多数据源异步初始化优化方案
- 缓存预热异步化实践
最终将服务启动时间从 1 分钟优化至 13 秒。适合有一定 Spring 基础、希望提升服务启动效率的开发者阅读,预计阅读时长 8 分钟。
# Spring Boot 启动优化实战:借助 AI 快速定位瓶颈
# 背景说明
随着业务迭代和组件增多,Spring Boot 启动速度逐渐变慢。每次灰度发布,滚动更新时间被拉长;本地开发调试,重启等待也让人头疼。于是我们对服务启动流程进行分析和优化。
# 启动流程分析
针对Spring系的Java程序而言,从底层原理来分析,启动环节耗时的核心在于依赖注入环节。从解决收益来看,优化 Spring Bean 的加载效果最为直观。
结合 Spring Boot 源码,我们定位到 run() 方法的核心流程:
- 环境准备 → 配置加载
- 打印 Banner → 个性化展示
- 创建上下文 → BeanFactory 初始化
- 上下文刷新 → Bean 实例化与依赖注入(重点)
- 后置 Runner → 扩展点执行
public ConfigurableApplicationContext run(String... args) {
//......
try {
ApplicationArguments applicationArguments = new DefaultApplicationArguments(args);
//环境准备
ConfigurableEnvironment environment = prepareEnvironment(listeners, bootstrapContext, applicationArguments);
configureIgnoreBeanInfo(environment);
//打印banner
Banner printedBanner = printBanner(environment);
//创建上下文
context = createApplicationContext();
context.setApplicationStartup(this.applicationStartup);
//容器初始化
prepareContext(bootstrapContext, context, environment, listeners, applicationArguments, printedBanner);
//上下文刷新(涉及IOC操作)
refreshContext(context);
//......
afterRefresh(context, applicationArguments);
//......
//调用后置runner拓展点
callRunners(context, applicationArguments);
}
catch (Throwable ex) {
//......
}
//......
return context;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 第一步:利用 Spring 扩展点定位耗时阶段
仔细观察源码发现,Spring Boot 核心方法调用都伴随事件发布。这是典型的监听者模式设计,即 Spring 暴露给开发者的定制化拓展点。结合个人经验,我将相关接口定义提交给 AI,让其完成启动耗时追踪代码的实现:
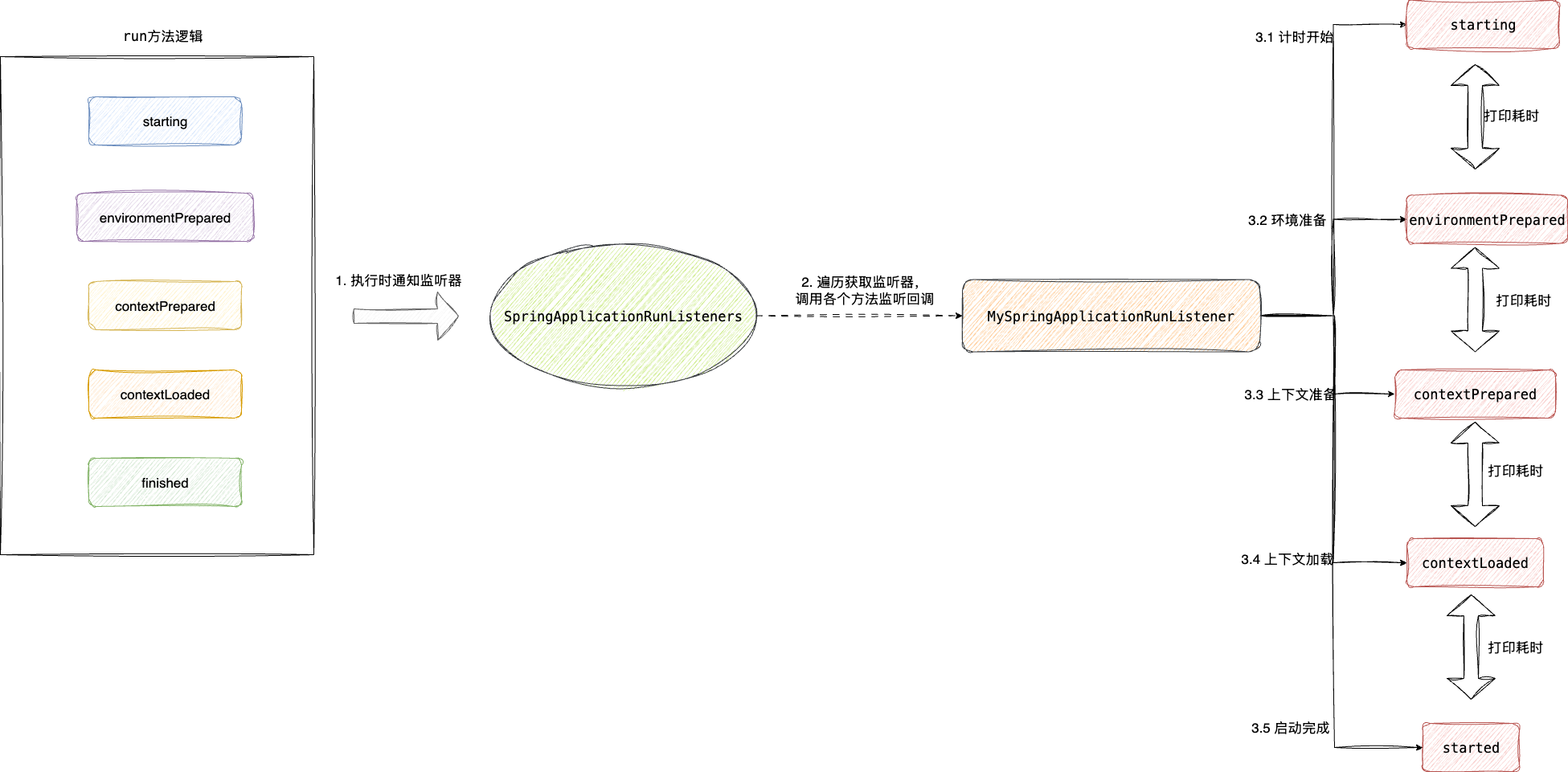
于是我们得到了这样一段代码,它清晰地将 run() 方法的核心流程进行耗时统计:
SpringApplicationRunListener 是 Spring Boot 提供的扩展接口,能够监听应用启动的各个阶段。我们可以实现这个接口,在每个阶段结束时记录耗时,从而定位启动瓶颈。
重要说明:SpringApplicationRunListener 需要通过 SPI 机制注册才能生效。在 src/main/resources/META-INF/spring.factories 文件中添加如下配置:
org.springframework.boot.SpringApplicationRunListener=\
com.example.qoderspringoptimizer.listener.MySpringApplicationRunListener
2
这样 Spring Boot 启动时才会通过 SPI 机制自动加载并调用我们的监听器。
import lombok.extern.slf4j.Slf4j;
import org.springframework.boot.ConfigurableBootstrapContext;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.SpringApplicationRunListener;
import org.springframework.context.ConfigurableApplicationContext;
import org.springframework.core.env.ConfigurableEnvironment;
import java.time.LocalTime;
@Slf4j
public class MySpringApplicationRunListener implements SpringApplicationRunListener {
private Long startTime;
public MySpringApplicationRunListener(SpringApplication application, String[] args) {
}
@Override
public void starting(ConfigurableBootstrapContext bootstrapContext) {
startTime = System.currentTimeMillis();
log.info("MySpringListener启动开始 {}", LocalTime.now());
}
@Override
public void environmentPrepared(ConfigurableBootstrapContext bootstrapContext, ConfigurableEnvironment environment) {
log.info("MySpringListener环境准备 准备耗时:{}毫秒", (System.currentTimeMillis() - startTime));
startTime = System.currentTimeMillis();
}
@Override
public void contextPrepared(ConfigurableApplicationContext context) {
log.info("MySpringListener上下文准备 耗时:{}毫秒", (System.currentTimeMillis() - startTime));
startTime = System.currentTimeMillis();
}
@Override
public void contextLoaded(ConfigurableApplicationContext context) {
log.info("MySpringListener上下文载入 耗时:{}毫秒", (System.currentTimeMillis() - startTime));
startTime = System.currentTimeMillis();
}
@Override
public void started(ConfigurableApplicationContext context) {
log.info("MySpringListener启动完成 耗时:{}毫秒", (System.currentTimeMillis() - startTime));
startTime = System.currentTimeMillis();
}
@Override
public void running(ConfigurableApplicationContext context) {
log.info("MySpringListener正在运行 {}", LocalTime.now());
}
@Override
public void failed(ConfigurableApplicationContext context, Throwable exception) {
log.error("MySpringListener启动失败", exception);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
从日志中可以看到,从"上下文载入"到"启动完成"这一步整整花费了 45 秒:
2026-03-17 10:52:59.863 INFO [main] - c.e.q.l.MySpringApplicationRunListener:28 MySpringListener环境准备 准备耗时:140毫秒
2026-03-17 10:52:59.901 INFO [main] - c.e.q.l.MySpringApplicationRunListener:34 MySpringListener上下文准备 耗时:37毫秒
2026-03-17 10:52:59.992 INFO [main] - c.e.q.l.MySpringApplicationRunListener:40 MySpringListener上下文载入 耗时:91毫秒
2026-03-17 10:53:45.479 INFO [main] - c.e.q.l.MySpringApplicationRunListener:46 MySpringListener启动完成 耗时:45486毫秒
2026-03-17 10:53:45.480 INFO [main] - c.e.q.l.MySpringApplicationRunListener:52 MySpringListener正在运行 10:53:45.480610
2
3
4
5
6
7
8
9
结合日志分析,从"上下文载入"到"启动完成"耗时 45 秒,这段时间主要对应 refreshContext() 方法的执行,即 Spring 容器的刷新过程,涉及 Bean 的实例化、依赖注入和初始化。因此我们将排查重点放在 IOC 容器的 Bean 加载环节。
从日志可以清晰看到,环境准备、上下文准备、上下文载入都很快(总计不到 1 秒),但从"上下文载入"到"启动完成"耗时高达 45 秒。这段时间主要是 refreshContext() 在执行,核心是 Bean 的实例化和依赖注入。接下来我们需要进一步细化定位是哪些 Bean 在拖累启动速度。
# 第二步:Bean 生命周期耗时监控
依赖注入即完成 Bean 的加载和注入,要想明确定位耗时点,我们需要一个类似上述拓展点的接口来观察 Bean 生命周期的耗时。
查阅资料后,笔者很快找到了 InstantiationAwareBeanPostProcessor 这个接口:
{@link BeanPostProcessor} 的子接口,它添加了两个回调方法:
- 实例化前回调**(before-instantiation callback)**
- 实例化后但在显式属性设置或自动装配发生前的回调**(callback after instantiation but before explicit properties are set or autowiring occurs)**
典型用途:
- 抑制特定目标 bean 的默认实例化
- 例如:创建带有特殊 TargetSource 的代理(如池化目标、延迟初始化目标等)
- 实现额外的注入策略,如字段注入(field injection)
注意:这是一个特殊用途的接口,主要用于框架内部使用。建议尽可能实现普通的 {@link BeanPostProcessor} 接口。
基于该接口,我们可以实现一个 Bean 生命周期耗时监控器:
为什么选择 InstantiationAwareBeanPostProcessor?
普通的 BeanPostProcessor 只能在 Bean 初始化前后(postProcessBeforeInitialization/postProcessAfterInitialization)进行拦截,无法捕获 Bean 实例化阶段的耗时。
而 InstantiationAwareBeanPostProcessor 提供了更细粒度的扩展点:
postProcessBeforeInstantiation:实例化前(构造函数执行前)postProcessAfterInstantiation:实例化后(构造函数执行后,属性注入前)postProcessProperties:属性注入阶段
这样可以完整监控 Bean 从实例化到初始化完成的全流程耗时,更精准地定位性能瓶颈。
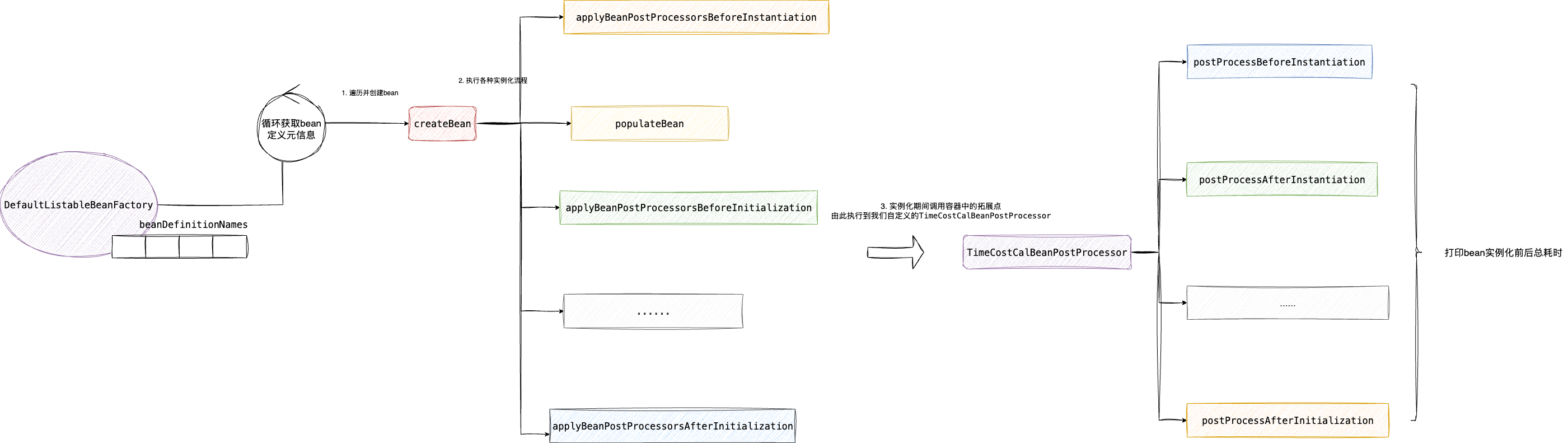
在编写提示词时,笔者先大致浏览了 InstantiationAwareBeanPostProcessor 的方法与逻辑,确保 AI 生成的代码符合预期。
对应源代码如下,笔者为了更直观看到问题的 Bean,以 5 秒作为阈值进行告警打印:
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.BeansException;
import org.springframework.beans.PropertyValues;
import org.springframework.beans.factory.config.InstantiationAwareBeanPostProcessor;
import org.springframework.stereotype.Component;
import java.beans.PropertyDescriptor;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
/**
* Bean创建耗时计算后置处理器
*
* InstantiationAwareBeanPostProcessor 是 BeanPostProcessor 的子接口,
* 它扩展了更多的扩展点,可以在 Bean 实例化前后进行干预。
*
* Bean生命周期中的扩展点调用顺序:
* 1. InstantiationAwareBeanPostProcessor.postProcessBeforeInstantiation() - 实例化前
* 2. Bean构造函数执行
* 3. InstantiationAwareBeanPostProcessor.postProcessAfterInstantiation() - 实例化后
* 4. InstantiationAwareBeanPostProcessor.postProcessProperties() - 属性注入
* 5. BeanPostProcessor.postProcessBeforeInitialization() - 初始化前
* 6. @PostConstruct / InitializingBean.afterPropertiesSet() / init-method
* 7. BeanPostProcessor.postProcessAfterInitialization() - 初始化后
*/
@Slf4j
@Component
public class TimeCostCalBeanPostProcessor implements InstantiationAwareBeanPostProcessor {
private static final DateTimeFormatter TIME_FORMATTER = DateTimeFormatter.ofPattern("HH:mm:ss.SSS");
private static final long WARN_THRESHOLD = 5000L;
private static final long INFO_THRESHOLD = 1000L;
private static final long DEBUG_THRESHOLD = 100L;
private final Map<String, Long> costMap = new ConcurrentHashMap<>();
private final Map<String, String> startTimeMap = new ConcurrentHashMap<>();
@Override
public Object postProcessBeforeInstantiation(Class<?> beanClass, String beanName) throws BeansException {
if (!costMap.containsKey(beanName)) {
long startTime = System.currentTimeMillis();
costMap.put(beanName, startTime);
startTimeMap.put(beanName, LocalDateTime.now().format(TIME_FORMATTER));
log.debug("[Bean开始创建] {} - 类型: {}", beanName, beanClass.getSimpleName());
}
return null;
}
@Override
public boolean postProcessAfterInstantiation(Object bean, String beanName) throws BeansException {
return true;
}
@Override
public PropertyValues postProcessProperties(PropertyValues pvs, Object bean, String beanName) throws BeansException {
return pvs;
}
@Override
@Deprecated
public PropertyValues postProcessPropertyValues(PropertyValues pvs, PropertyDescriptor[] pds, Object bean, String beanName) throws BeansException {
return pvs;
}
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
if (costMap.containsKey(beanName)) {
Long start = costMap.get(beanName);
String startTimeStr = startTimeMap.get(beanName);
long cost = System.currentTimeMillis() - start;
String endTimeStr = LocalDateTime.now().format(TIME_FORMATTER);
if (cost > WARN_THRESHOLD) {
log.warn("[Bean创建完成] {} | 开始: {} | 结束: {} | 耗时: {}ms ⚠️耗时过长",
beanName, startTimeStr, endTimeStr, cost);
} else if (cost > INFO_THRESHOLD) {
log.info("[Bean创建完成] {} | 开始: {} | 结束: {} | 耗时: {}ms",
beanName, startTimeStr, endTimeStr, cost);
} else if (cost > DEBUG_THRESHOLD) {
log.debug("[Bean创建完成] {} | 开始: {} | 结束: {} | 耗时: {}ms",
beanName, startTimeStr, endTimeStr, cost);
}
costMap.remove(beanName);
startTimeMap.remove(beanName);
}
return bean;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
从日志中的 dataSource 和 Redisson 可以看出,当前容器中最耗时的操作是数据源的加载和缓存预热:


# 第三步:定位根因
定位到耗时操作所在的 Bean 后,接下来我们需要深入了解其内部工作机制。按照常规调试思路,我们采用宏观打点、逐步深入的策略。
以 DataSource 为例,我们在实例化阶段设置断点,追踪后续耗时的调用:
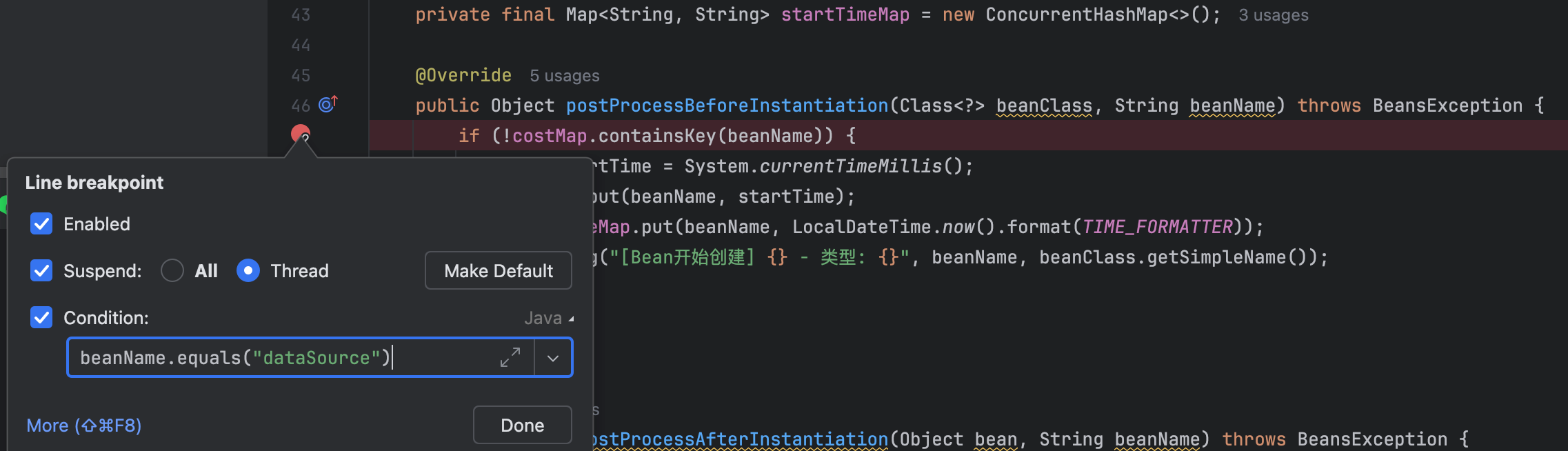
经过逐步跳过,我们发现 doCreateBean 出现长时间卡顿,于是在这里设置断点,下一轮调试直接从这里开始深入分析:
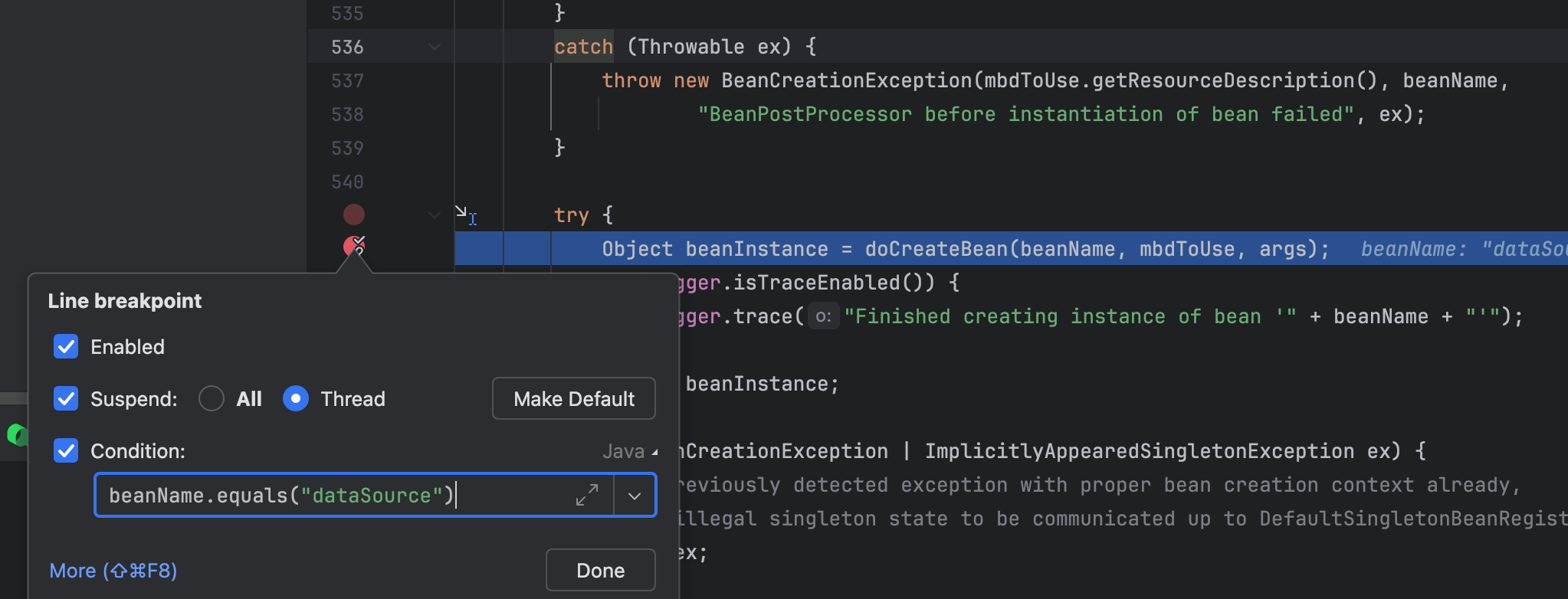
同理,我们在初始化环节也遇到了较长的等待:
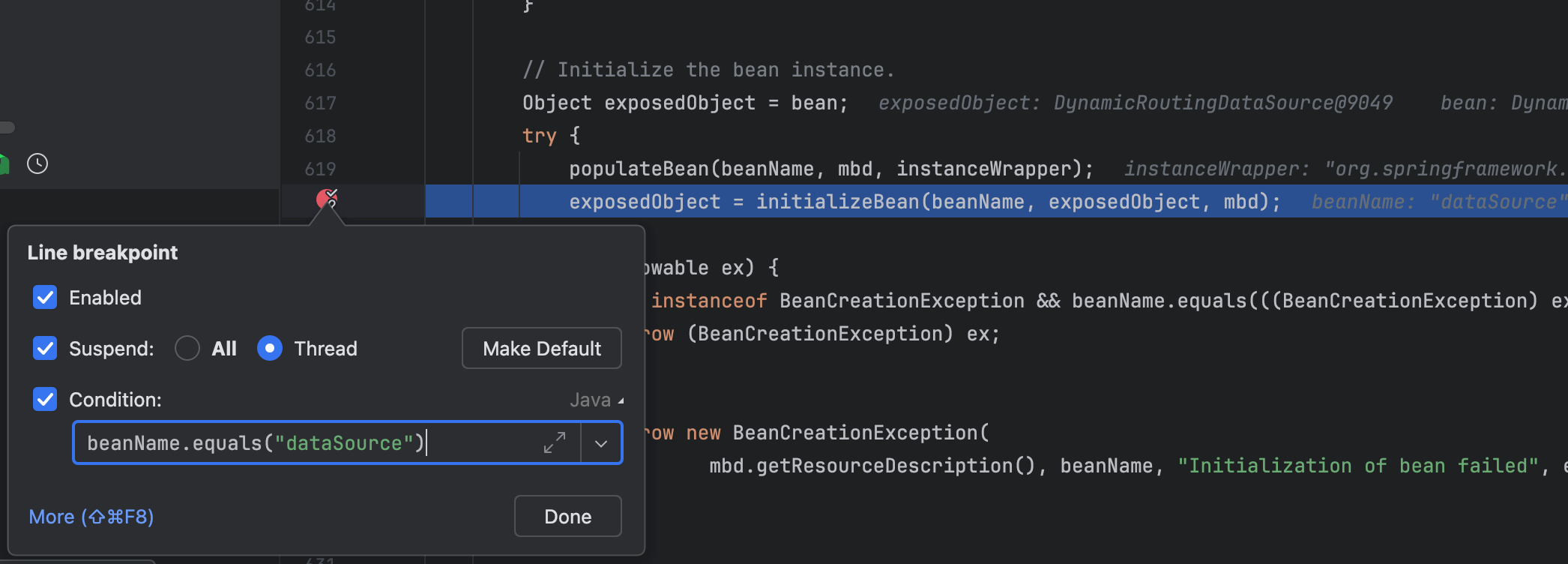
最终,我们定位到了根因:项目中引入的多数据源,在 asyncInit(默认为 false)的情况下,数据源是逐个进行加载,由于数据源较多导致网络 I/O 将主流程阻塞,进而导致启动效率低下:
public void init() throws SQLException {
//......
boolean init = false;
try {
//......
if (createScheduler != null && asyncInit) { //若asyncInit则并行加载数据源
for (int i = 0; i < initialSize; ++i) {
submitCreateTask(true);
}
} else if (!asyncInit) {//串行加载数据源
// init connections
while (poolingCount < initialSize) {
try {
PhysicalConnectionInfo pyConnectInfo = createPhysicalConnection();
DruidConnectionHolder holder = new DruidConnectionHolder(this, pyConnectInfo);
connections[poolingCount++] = holder;
} catch (SQLException ex) {
//......
}
}
//......
initedLatch.await();
init = true;
//......
} catch (SQLException e) {
//......
} finally {
//......
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# 优化实践与效果验证
明确根因后,只需定位对应变量的配置即可。这属于繁琐的追踪和配置工作,为提升效率,我将任务提交给 AI,让其自行分析上下文并完成优化。
通过配置多数据源内置的参数即可解决当前问题。具体而言,解决方案涉及调整DruidDataSource类中init()方法内部的asyncInit参数配置。请详细分析该参数的作用机制,修改相关配置项,并验证其对多数据源初始化流程的影响,确保问题得到有效解决。
在此期间,我通过搜索引擎对照验证,确保解决思路与通用方案一致后再验收 AI 的处理结果:
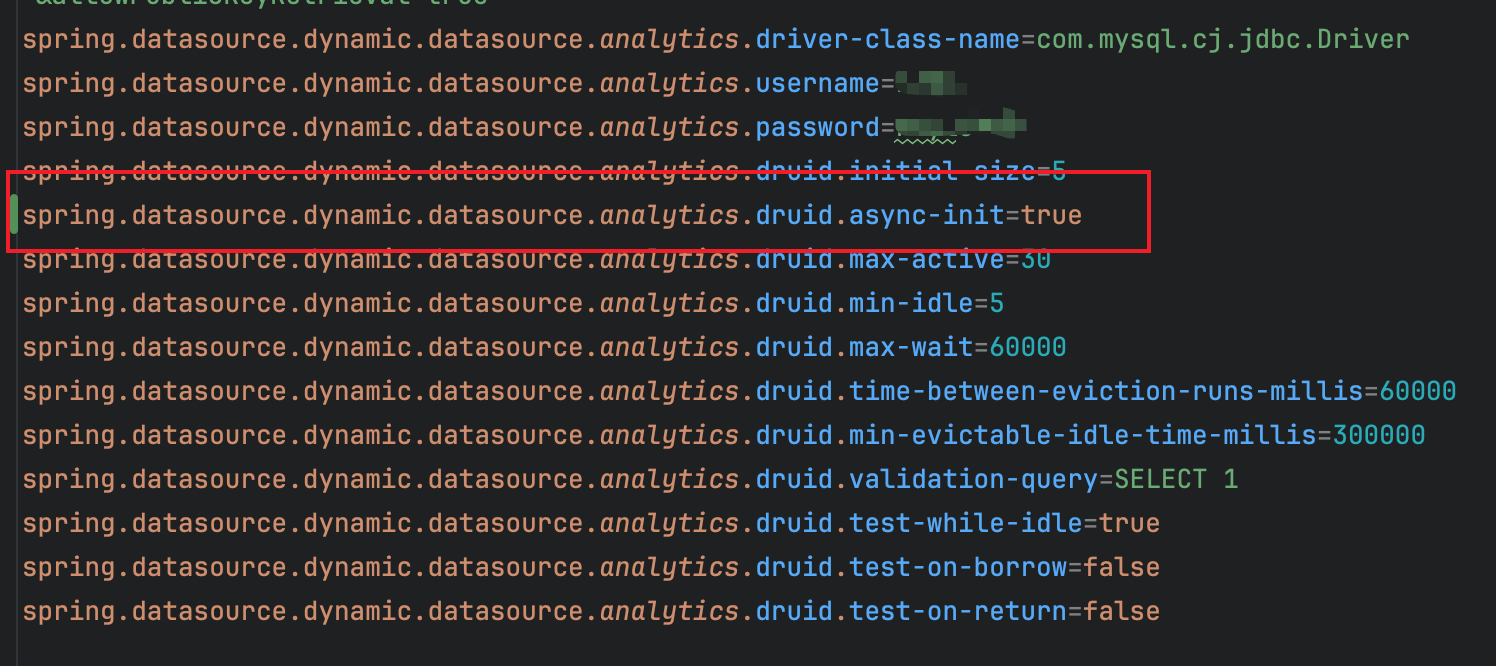
经过配置优化后,对于数据源优化,在 application.properties 中为每个数据源添加异步初始化配置:
spring.datasource.dynamic.datasource.primary.druid.async-init=true
spring.datasource.dynamic.datasource.secondary.druid.async-init=true
spring.datasource.dynamic.datasource.analytics.druid.async-init=true
spring.datasource.dynamic.datasource.archive.druid.async-init=true
spring.datasource.dynamic.datasource.config.druid.async-init=true
2
3
4
5
注意事项:
- 异步初始化依赖
createScheduler,若未配置会自动回退到同步初始化模式 - 异步初始化可能导致启动后短暂时间内连接池未完全就绪,首次请求可能稍慢
- 建议配合
initial-size合理设置初始连接数,避免启动时创建过多连接
方案选型思考:最初也有同事建议使用 Spring 的 @Lazy 懒加载来优化启动速度,但我们评估后放弃了这个方案:
- 懒加载会影响首次请求体验,将启动成本转移到运行时
- 无法解决数据源预热的需求,连接池仍需在首次使用时初始化
- 异步初始化是更优解,将初始化从主流程剥离到后台线程
排查过程中的挑战:在定位问题过程中,我们也遇到了一些困难。Bean 数量庞大,日志信息过多,难以快速筛选关键耗时点。通过设置阈值(5秒)进行日志过滤,才快速定位到目标 Bean。这也是一个经验总结:面对大量日志时,阈值过滤是提升效率的关键。
除数据源外,缓存预热也存在类似问题。系统配置和用户黑名单需要从数据库加载数据到 Redis,若在 Bean 初始化阶段同步执行,会阻塞启动流程。优化后,使用 CompletableFuture 实现异步预热:
@PostConstruct
public void warmup() {
// 异步并行加载,不阻塞主流程
CompletableFuture<Void> configFuture = warmupSystemConfigAsync();
CompletableFuture<Void> blacklistFuture = warmupUserBlacklistAsync();
CompletableFuture.allOf(configFuture, blacklistFuture)
.thenRun(() -> log.info("=== Cache warmup completed ==="));
}
2
3
4
5
6
7
8
这样缓存预热不会阻塞 Spring 容器的启动过程。最终代码效果如下:
# 小结
完成问题修复后,服务启动速度由 1 分钟 优化至 13 秒:
效果验证方法:
- 本地多次启动测试,平均启动时间从 60s 降至 13s
- 监控启动后首次 DB/Redis 请求耗时,确保连接池已就绪
- 压测验证异步初始化不会影响线上稳定性

可以看到,整个过程中我一直以自己的思路为主导,给定明确的方法论,引导 AI 按照正确的上下文构建推理路径。例如:
- 在问题排查阶段,我先了解 Spring Boot 的启动流程,明确容器具体的慢加载点,然后将接口定义交由 AI 进行编码实现
- 确定容器刷新较慢后,结合对 IOC 的理解,寻找能够定位 Bean 生命周期的拓展点,让 AI 完成处理器代码
最后,借助这些追踪工具定位到具体 Bean 信息后,我将繁琐的配置工作提交给 AI 完成,从而提升整体效率。
# 参考
Spring Boot 启动优化实践:https://www.cnblogs.com/vivotech/p/18936065 (opens new window)
