 M2.7 真能打!我用两个真实场景测了测,结果有点意外
M2.7 真能打!我用两个真实场景测了测,结果有点意外
# 引言
2026年3月18日,MiniMax发布了M2.7版本。官方数据显示,该版本在SWE-Pro软件工程基准测试中得分56.22%,几乎接近业界领先水平;对于开发而言最亮眼的无非是以下两点:
- 对于线上bug的推理和修复能力
- 复杂工程的上下文推理和重构能力
除了官方数据,第三方评测也给出了印证。更值得关注的是,第三方评测机构PinchBench最新数据显示,M2.7已超越Nemotron 3,跻身排行榜第四位:
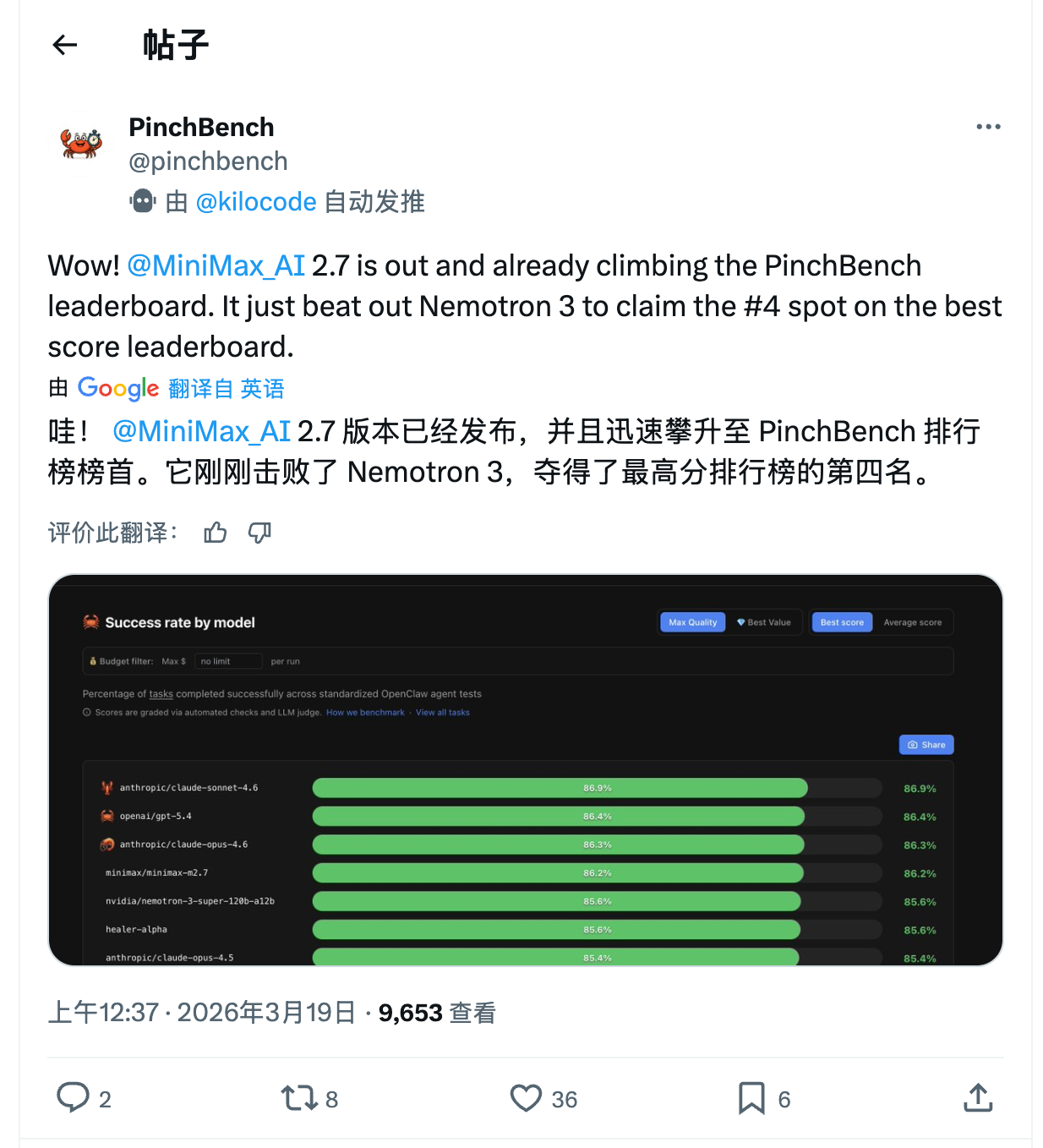
考虑到经济成本,笔者日常的开发工作80%-90%都是MiniMax。继M2.5让我发出"真香"感叹后,M2.7的发布让我好奇:这一次又能做到什么程度?
- 场景一:接口大量超时,日志指向Redis报错,但项目N处用到Redis难以追踪。M2.7如何从海量线索中精准定位根因?
- 场景二:从C语言源码到Go实现,让M2.7主导完成Redis慢查询指令的跨语言复刻,挑战极限重构
# 快速上手
查看官方文档,MiniMax M2.7支持Claude Code、Cursor、TRAE、OpenCode等主流AI开发工具接入。本次测评使用Trae IDE,具体的接入步骤如下。
第一步:到Trae官网下载安装并完成初始化,同时到MiniMax平台完成注册和API Key创建:
https://platform.minimaxi.com/subscribe/token-plan (opens new window)
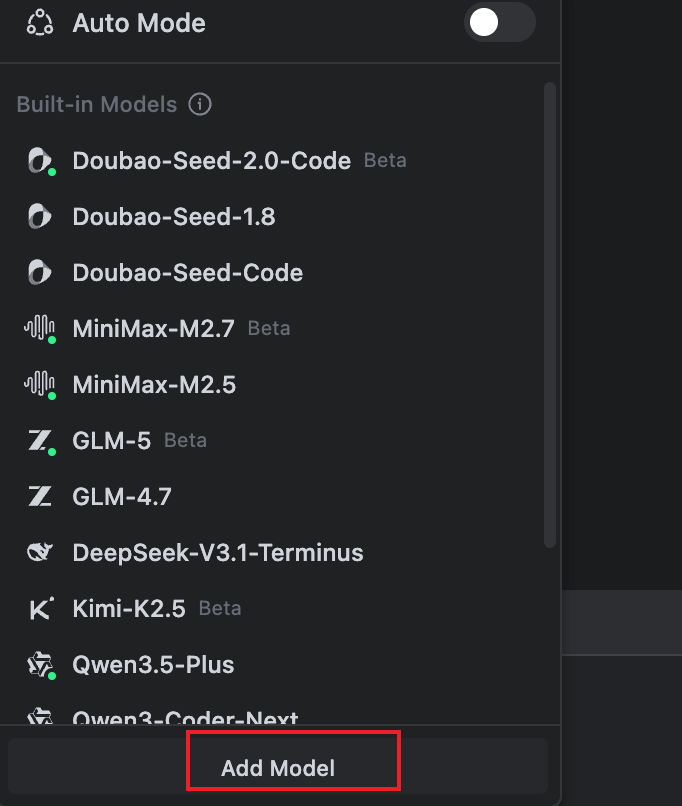
第二步:在Trae中点击"Add Model"添加自定义模型:
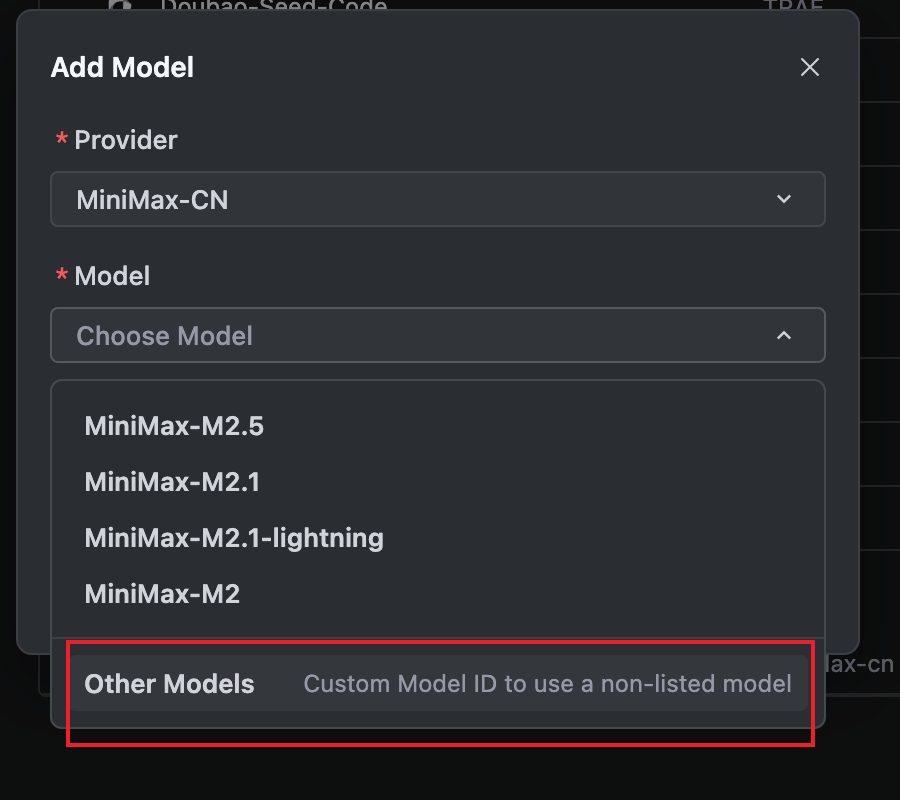
第三步:由于Trae暂未内置M2.7,需要选择"Other Models"并手动输入模型ID和API Key:
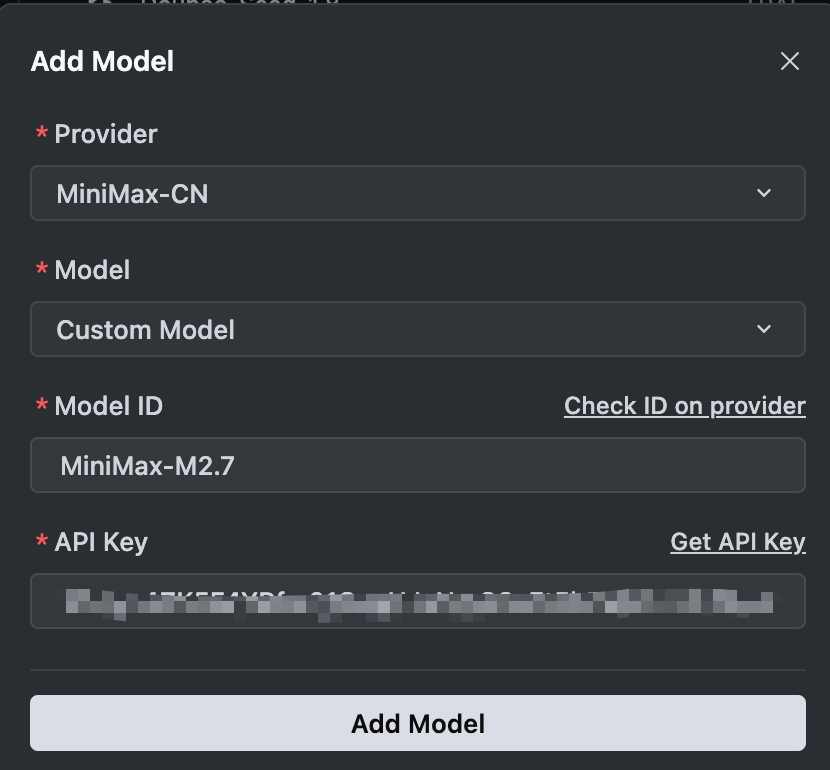
第四步:输入MiniMax-M2.7和申请的API Key,点击"Add Model"。若无报错提示,即表示接入成功:
完成基本安装配置工作之后,接下来我们就基于上述两个相对复杂的场景,看看M2.7的实际表现:
# 场景一:接口超时问题快速止血与根因定位
# 问题定位
第一个案例是某次真实线上故障的复现(已脱敏)。当时部门同学反馈某列表查询接口报错,页面无数据。线上监控系统定位到接口信息如下:
接口:GET http://localhost:8080/api/rbac/user/list
返回结果:
{
"code": 500,
"message": "系统繁忙,请稍后重试",
"data": null,
"timestamp": "2026-03-19T10:11:02.632242"
}
2
3
4
5
6
结合异常堆栈信息关键字Read timed out,以及对应代码段的get(key)操作,我们可以初步认为该报错只是表象并非根因。
@Override
public String getConfigValue(String configKey, String environment) {
String cacheKey = CONFIG_CACHE_PREFIX + configKey + ":" + environment;
String value = stringRedisTemplate.opsForValue().get(cacheKey);
if (value != null) {
return value;
}
// 后续逻辑省略
}
2
3
4
5
6
7
8
9
按照常规处理流程,我们需要快速定位问题根因、完成止血,再联系运维深入排查。但项目中多处用到Redis,逐一排查耗时长,期间可能影响业务稳定性。
为了验证M2.7的实际能力,笔者复刻了该故障场景(已脱敏),并让M2.7接手处理。按照企业级线上故障处理流程,首先需要定位根因并完成止血。于是笔者向M2.7下达了第一条指令:
针对访问 http://localhost:8080/api/rbac/user/list 接口时出现的500错误(错误信息:"系统繁忙,请稍后重试"),请执行以下操作:
1. 分析提供的异常堆栈信息,准确定位导致服务器内部错误的根本原因;
2. 提供详细的线上紧急止血方案,包括但不限于:临时回滚策略、流量限制措施、服务降级方案或紧急重启流程;
3. 解释错误产生的技术原因,指出具体的代码模块或配置问题;
...... 异常堆栈关键信息:`java.net.SocketTimeoutException: Read timed out`
2
3
4
5
6
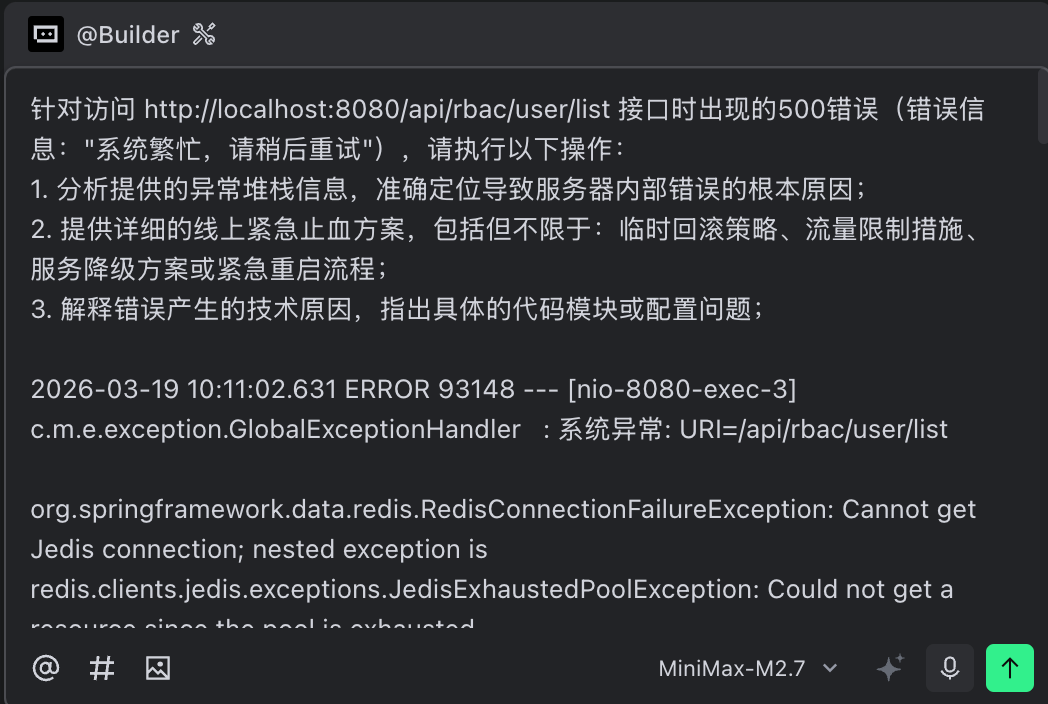
M2.7收到请求后,迅速定位到指定代码的上下文,并快速推理出4种可能的根因:
- Redis 服务器宕机或无响应
- 连接池配置太小,高并发下耗尽
- Redis 连接泄漏(连接未正确关闭)
- Redis 服务器负载过高
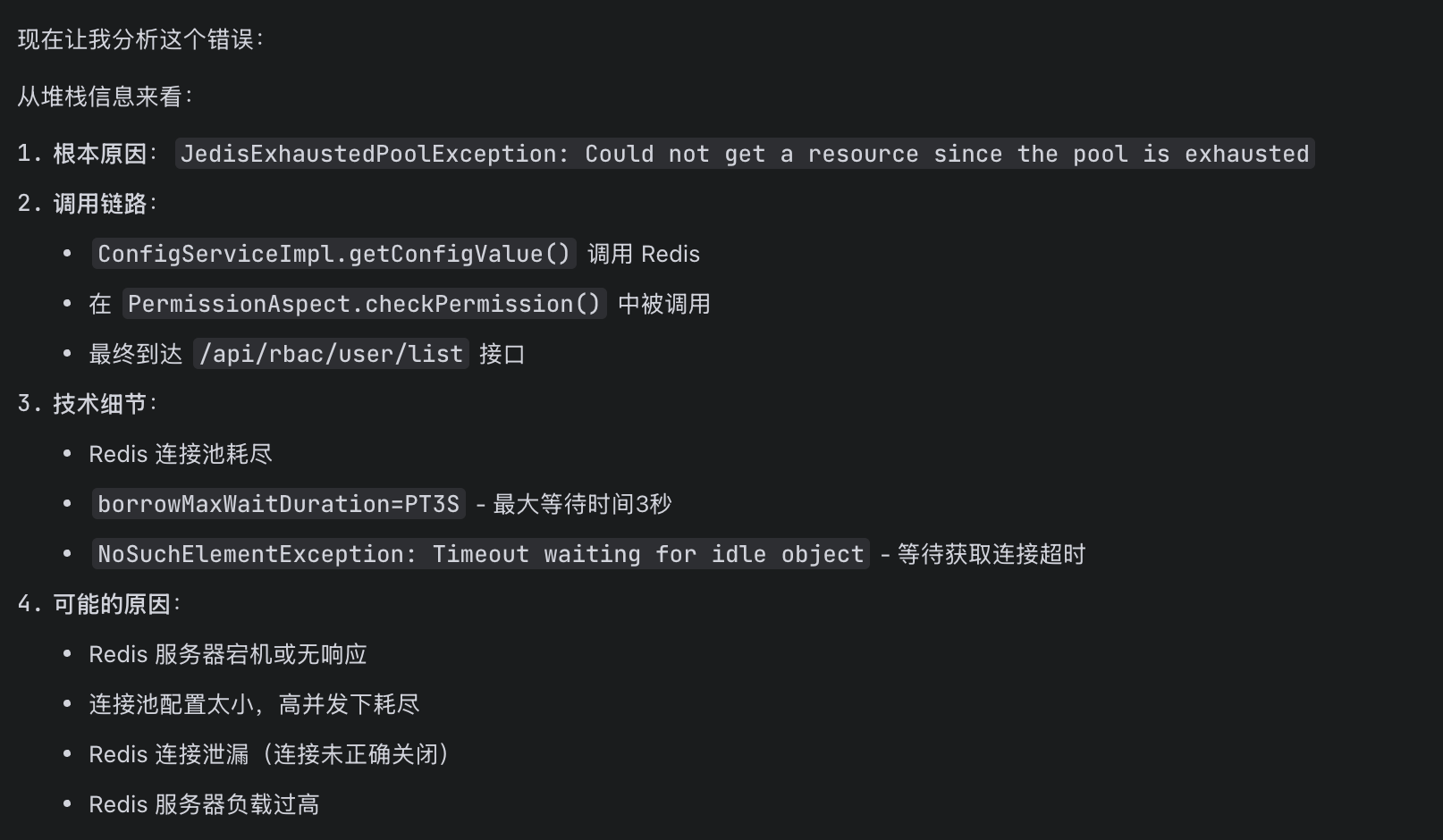
到这一步,M2.7已经把问题空间从"N处Redis调用"压缩到了"4种可能根因"——这种快速收敛问题范围的能力,和官方SWE-Pro 56.22%的成绩基本吻合。接下来看它的止血思路。
# 止血
M2.7针对既定异常栈帧快速梳理了代码调用逻辑,准确地指出:列表查询接口被切面拦截,连接池耗尽是500错误的根因。更关键的是,它指出了这段代码缺乏降级策略——这一点笔者是在复盘会上才意识到的。
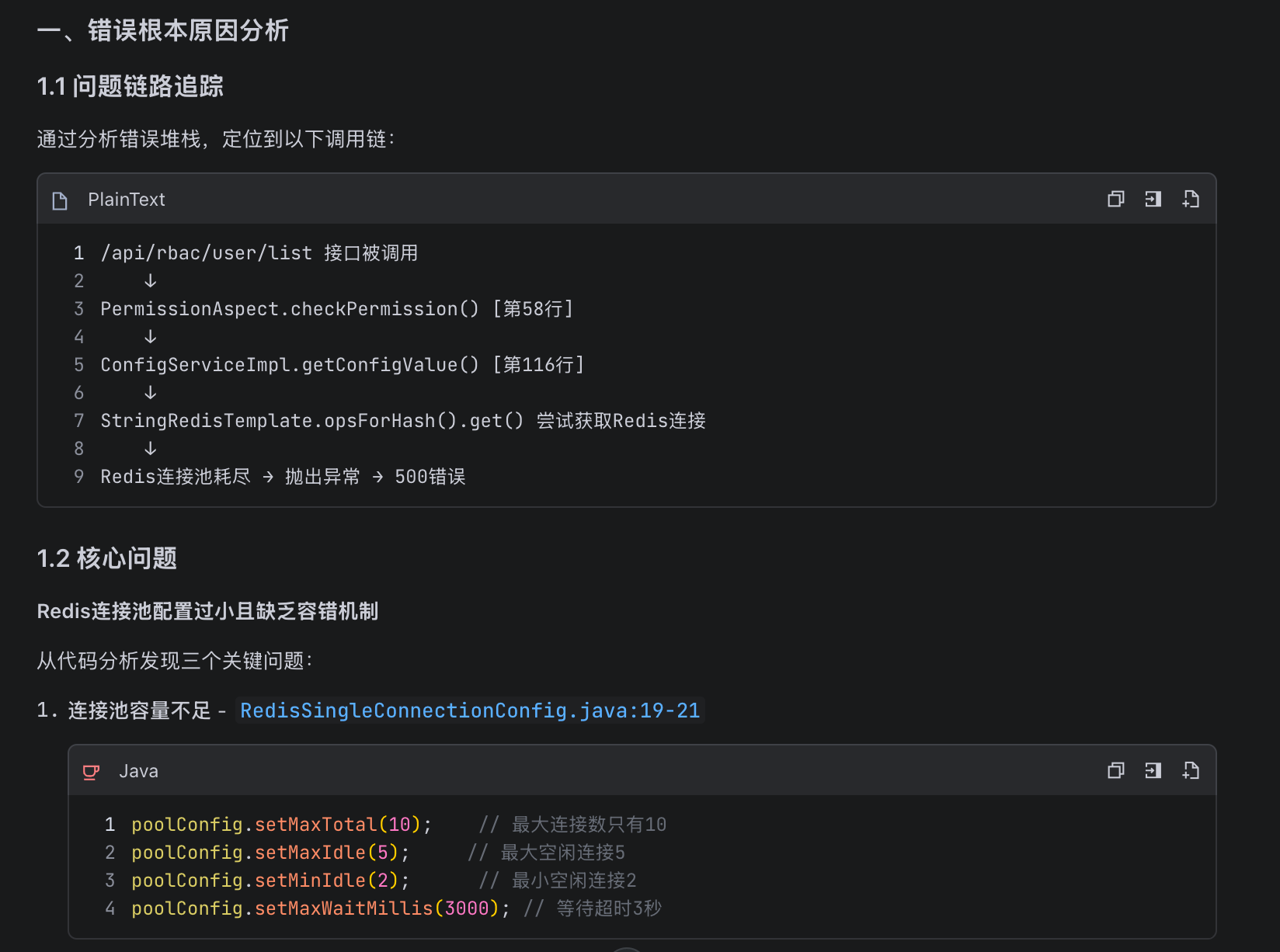
针对线上问题,止血策略是最关键的环节。M2.7给出了几个解决方案,第一个就是临时关闭权限校验开关——原因在于方案一需要清除Redis缓存数据。虽然方案有些激进,不过,它详细指出了代码的调用链路和表结构信息,这也很好的辅助我通过业务语义猜测可能的场景和原因。
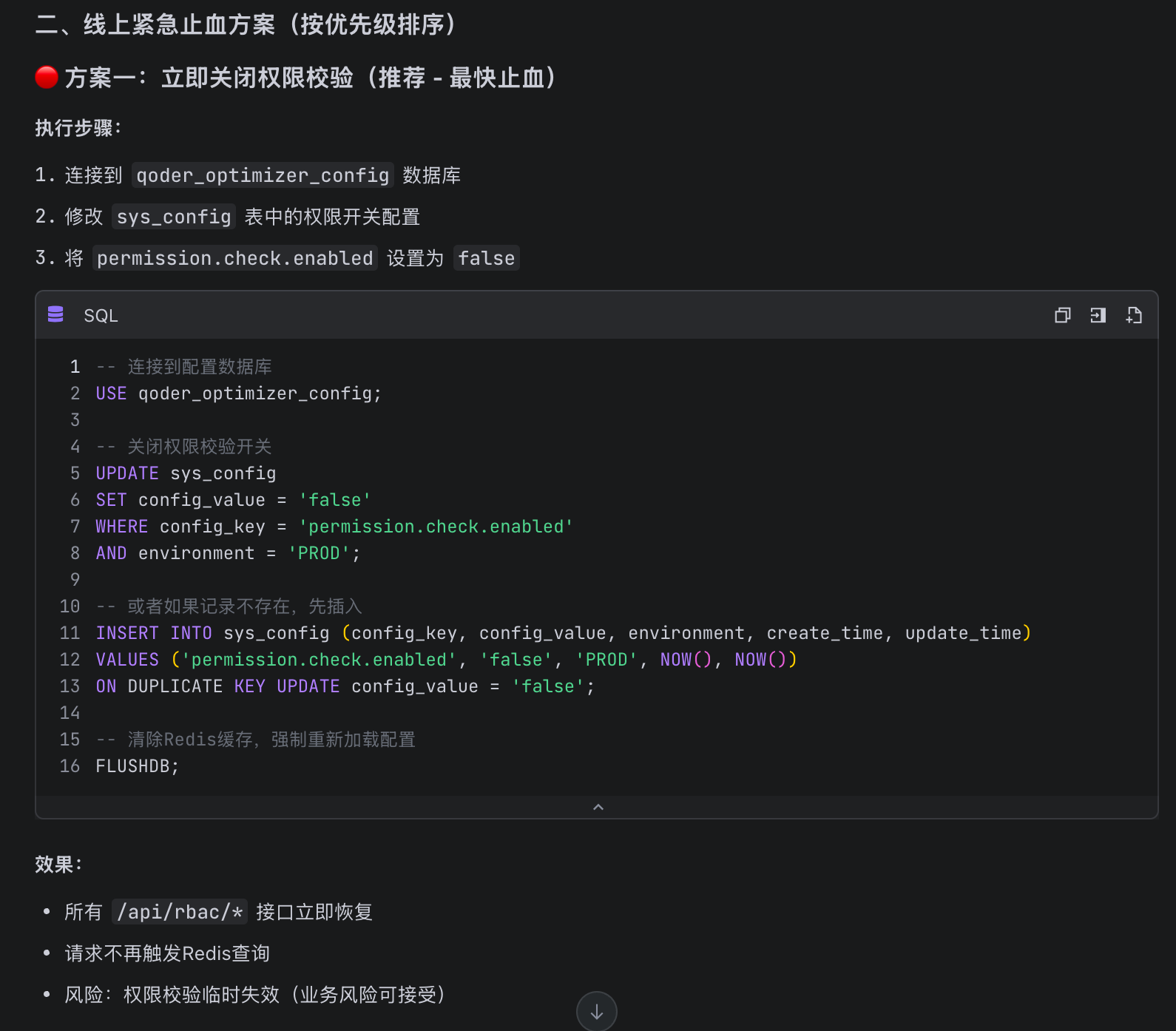
基于M2.7提供的调用链路信息,笔者进一步询问方案一的技术依据,确保业务上快速和M2.7进行对齐:
结合代码开发的完整工作流程,详细阐述方案一的技术依据、设计思路及实施合理性。
这也是让笔者最满意的地方,M2.7非常贴心地给出了问题代码的调用链路图,让笔者快速地了解到列表查询期间所经过的完整切面和具体故障所处位置,辅助我理解当前问题的影响面,以及本次异常的直接原因。
经过不到10分钟的交互,笔者不仅迅速获得一个宏观的架构视角,理解了当前复杂架构的故障和M2.7各个解决方案的依据,例如方案一:通过修改数据库配置重启刷新缓存来规避权限校验。
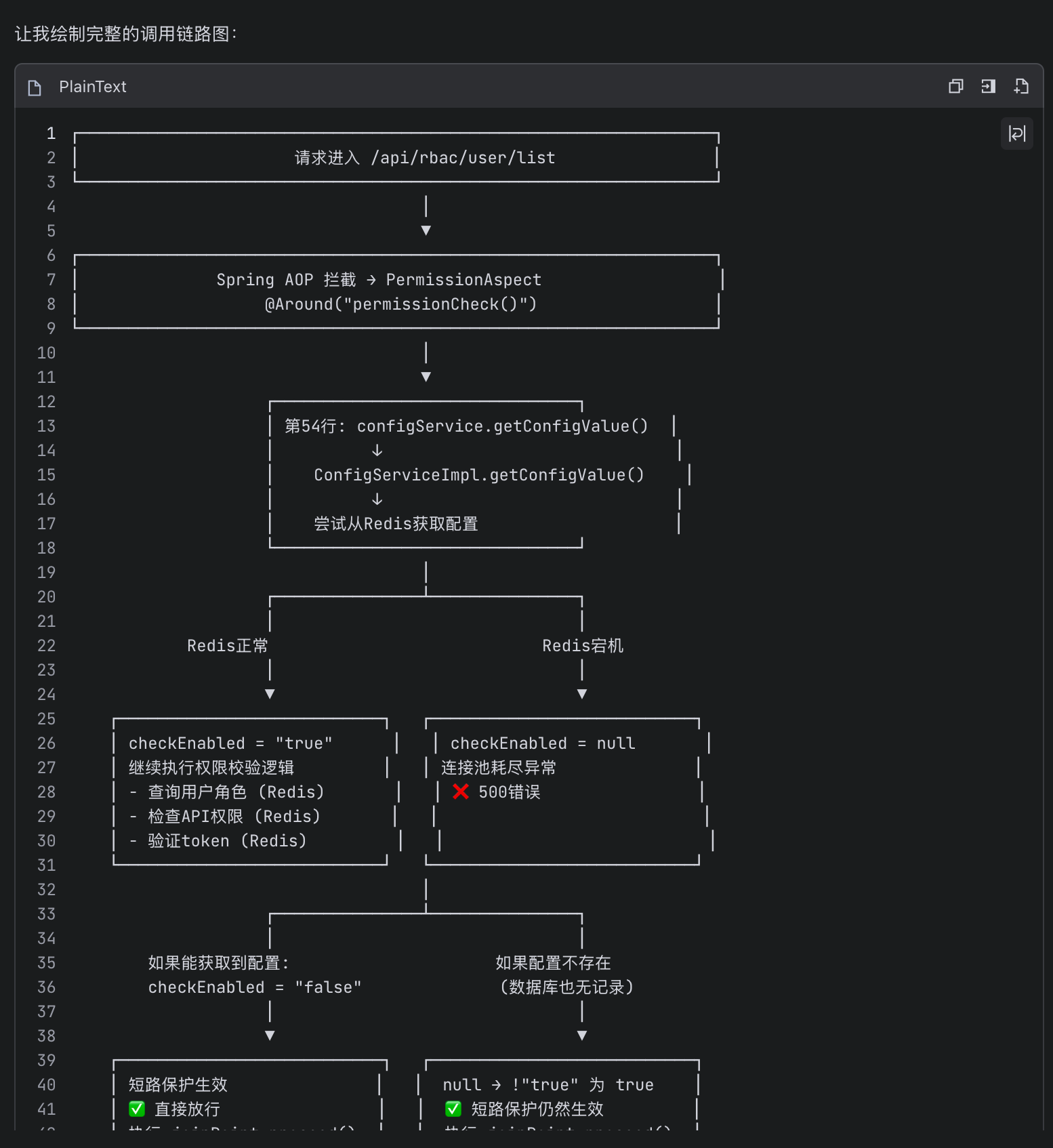
我们再来看看方案三的思路:当Redis不可用时,使用本地缓存或默认值,避免级联失败。M2.7很好地结合当前工程代码段给出修改建议:
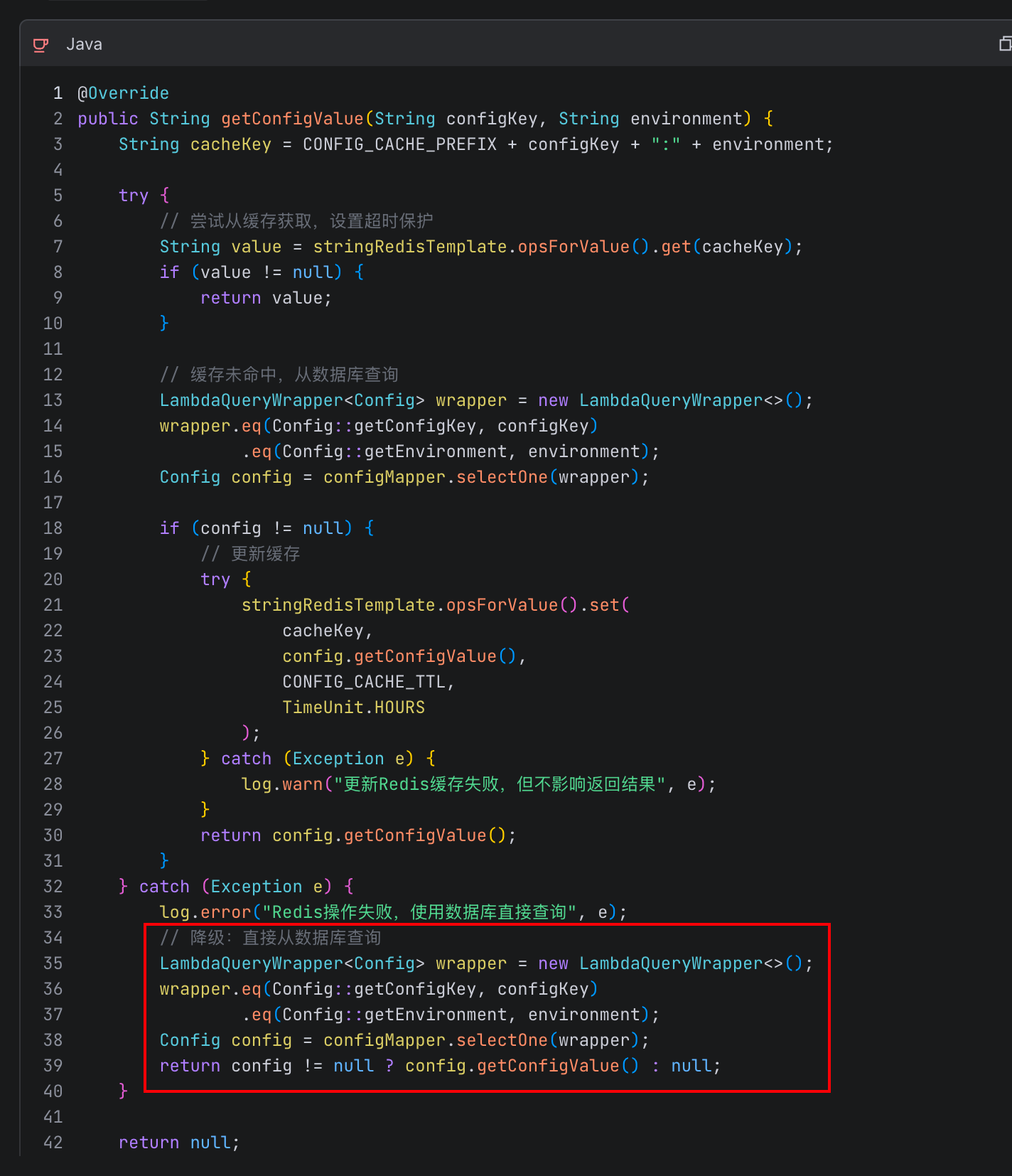
M2.7分析后,我们对问题有了初步的判断:Redis客户端连接池耗尽,导致日常业务接口基于缓存开关查询逻辑崩溃,进而引发雪崩效应。所以,我综合了M2.7给出的多个建议,本着保守、快速止血、业务高峰期不压垮数据库的原则,得出以下hotfix方案:
根据提供的方案,创建一个hotfix止血分支,用于紧急修复Redis异常问题。具体实施步骤如下:
1. 基于当前生产环境代码创建hotfix分支,命名规范为"hotfix/redis-exception-handler"
2. 按照方案三实现Redis异常捕获机制,在所有Redis操作处添加try-catch块
3. 当捕获到Redis异常时,自动降级为直接查询数据库获取数据
4. 实现JVM本地缓存机制,将查询结果缓存至内存中,设置合理的缓存过期时间
5. 完成单元测试和集成测试,覆盖率需达到80%以上
6. 准备回滚方案,确保在紧急情况下能够快速恢复到上一版本
2
3
4
5
6
7
8
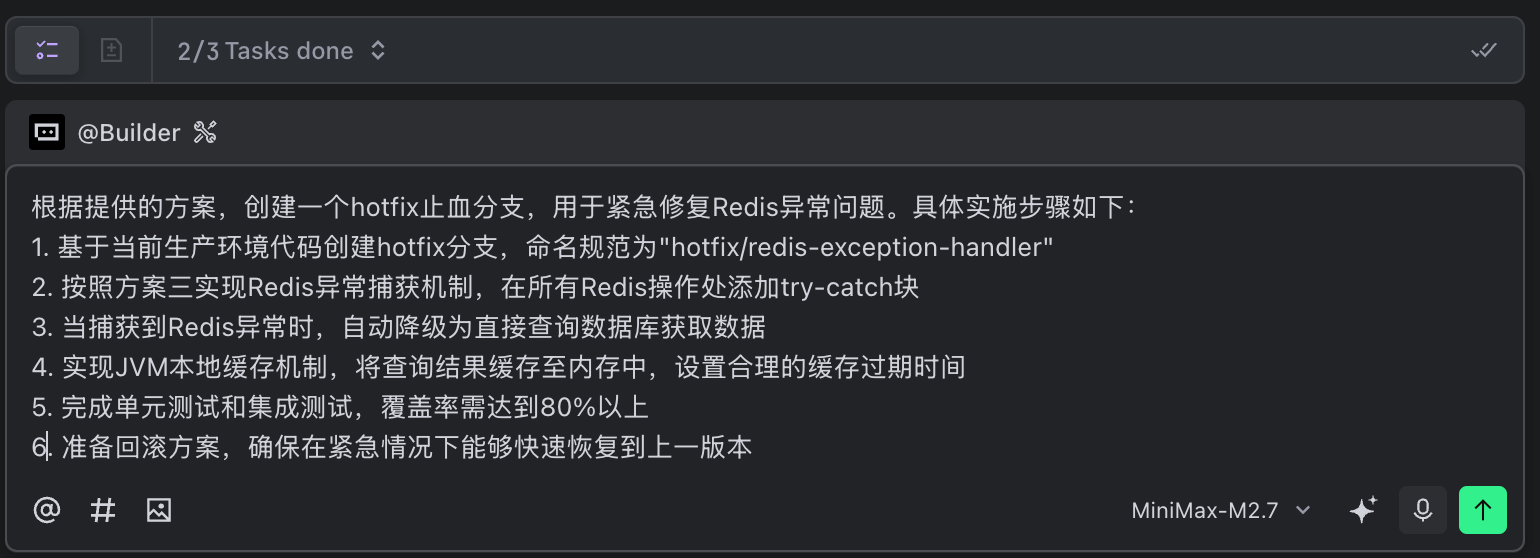
M2.7收到指令后,非常快速准确得理解了问题,完成任务拆解并逐步执行工作:
最终输出的代码结果如下:M2.7在原有权限校验逻辑中整合了数据库降级查询。不得不说,M2.7在代码上下文理解方面确实展现了官方宣称的"SWE-Pro软件工程基准测试56.22%"的实力——它能够深入理解权限校验逻辑,并完成复杂设计的无缝整合。
@Around("permissionCheck()")
public Object checkPermission(ProceedingJoinPoint joinPoint) throws Throwable {
try {
// 从配置中心读取权限校验开关
String checkEnabled = configService.getConfigValue("permission.check.enabled", "PROD");
if (!"true".equalsIgnoreCase(checkEnabled)) {
return joinPoint.proceed();
}
// ... 原有权限校验逻辑 ...
// 尝试从Redis缓存获取权限信息
Boolean hasPermission = checkPermissionFromCache(redisKey);
if (hasPermission != null) {
// ... 命中缓存处理 ...
}
// 降级:从数据库查询权限
boolean hasPermissionFromDB = checkPermissionFromDatabase(userId, apiPath, httpMethod);
// ... 降级逻辑处理 ...
} catch (Exception e) {
if (e instanceof RuntimeException && "无权限访问".equals(e.getMessage())) {
throw e;
}
// 发生异常时,触发监控告警并采用保守策略放行
AlertManager.notify("PERMISSION_CHECK_ERROR", e.getMessage());
return joinPoint.proceed();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
getConfigValue同样补充了本地缓存逻辑,多级缓存设计体现了其容错处理的健壮性。
/**
* 获取配置值(指定环境)
*/
@Override
public String getConfigValue(String configKey, String environment) {
String cacheKey = CONFIG_CACHE_PREFIX + configKey + ":" + environment;
// 【第一步:尝试从本地缓存获取】
String localValue = localCacheManager.get(cacheKey);
if (localValue != null) {
return localValue;
}
// 【第二步:尝试从Redis获取】
try {
if (isRedisAvailable()) {
String value = stringRedisTemplate.opsForValue().get(cacheKey);
if (value != null) {
localCacheManager.put(cacheKey, value, LOCAL_CACHE_TTL);
return value;
}
}
} catch (Exception e) {
// Redis异常,降级到数据库
handleRedisFailure(e);
}
// 【第三步:降级到数据库】
// ... 其他逻辑 ...
return getConfigValueFromDatabaseWithFallback(configKey, environment);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
这其中最让笔者感到惊喜的就是本地缓存的设计:M2.7老道地采用开闭原则,基于ConcurrentHashMap完成了本地缓存工具类的封装,全面考虑到堆内存溢出风险,配合LRU算法实现缓存清理,保障了JVM GC的稳定性:
@Component
public class LocalCacheManager {
// 核心存储:ConcurrentHashMap保证线程安全
private final Map<String, CacheEntry> cache = new ConcurrentHashMap<>();
private final ScheduledExecutorService cleanupExecutor;
// 缓存配置
private static final long DEFAULT_TTL_MILLIS = 300000; // 5分钟
private static final long MAX_CACHE_SIZE = 10000;
public LocalCacheManager() {
// 守护线程执行定时清理
this.cleanupExecutor = Executors.newSingleThreadScheduledExecutor(r -> {
Thread t = new Thread(r, "local-cache-cleanup");
t.setDaemon(true);
return t;
});
this.cleanupExecutor.scheduleAtFixedRate(this::cleanupExpiredEntries, 1, 1, TimeUnit.MINUTES);
}
public void put(String key, String value) {
put(key, value, DEFAULT_TTL_MILLIS);
}
public void put(String key, String value, long ttlMillis) {
// 容量满时触发LRU清理
if (cache.size() >= MAX_CACHE_SIZE) {
cleanupExpiredEntries();
if (cache.size() >= MAX_CACHE_SIZE) {
evictOldestHalf();
}
}
cache.put(key, new CacheEntry(value, System.currentTimeMillis() + ttlMillis));
}
public String get(String key) {
CacheEntry entry = cache.get(key);
if (entry == null || entry.isExpired()) {
cache.remove(key);
return null;
}
return entry.getValue();
}
// ... 其他方法省略 ...
// LRU清理:删除最老的50%数据
private void evictOldestHalf() {
// ...... 省略排序和清理逻辑 ......
}
// 缓存条目
private static class CacheEntry {
private final String value;
private final long expirationTime;
public CacheEntry(String value, long expirationTime) {
this.value = value;
this.expirationTime = expirationTime;
}
public String getValue() {
return value;
}
public boolean isExpired() {
return System.currentTimeMillis() > expirationTime;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
# 根因定位
通过hotfix分支针对线上故障止血之后,我们再来深入排查Redis连接池耗尽的原因。按照模型的输出结果和推断,一个常规的get指令操作按照Redis 10w qps的性能表现来看,10个连接(平均每个指令1~2ms),理想情况下每秒处理约6600条指令,远低于Redis的极限处理能力,所以问题可能出在代码层面,我们需要进一步推断项目中是否存在不合理的Redis操作:
结合本次发生的具体故障现象和表现特征,对项目进行全面的系统性全局分析。分析范围应覆盖项目架构、代码实现、依赖管理、环境配置、数据交互等多个维度,重点识别并输出可能导致生产故障的直接原因。
此时M2.7开始基于全局项目结构和上下文进行详细的阅读和推理分析:
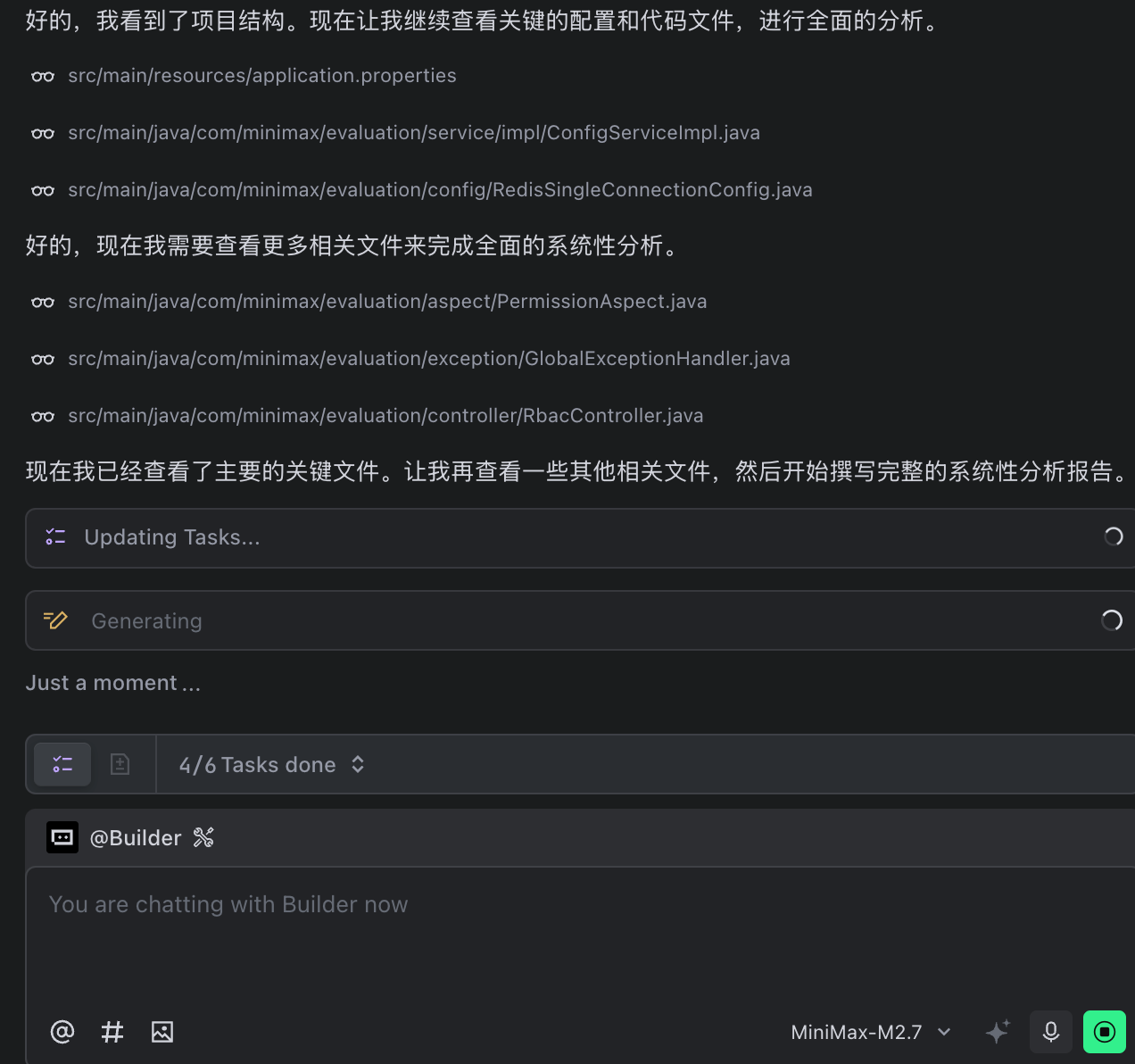
最终M2.7给出非常精准且详细的给出故障分析报告,指出根因:不当的Redis数据结构设计使用scan操作导致连接池夯死。同时,文档还结合上下文给出了该操作的业务流程,便于我们迅速理解这条故障链路:
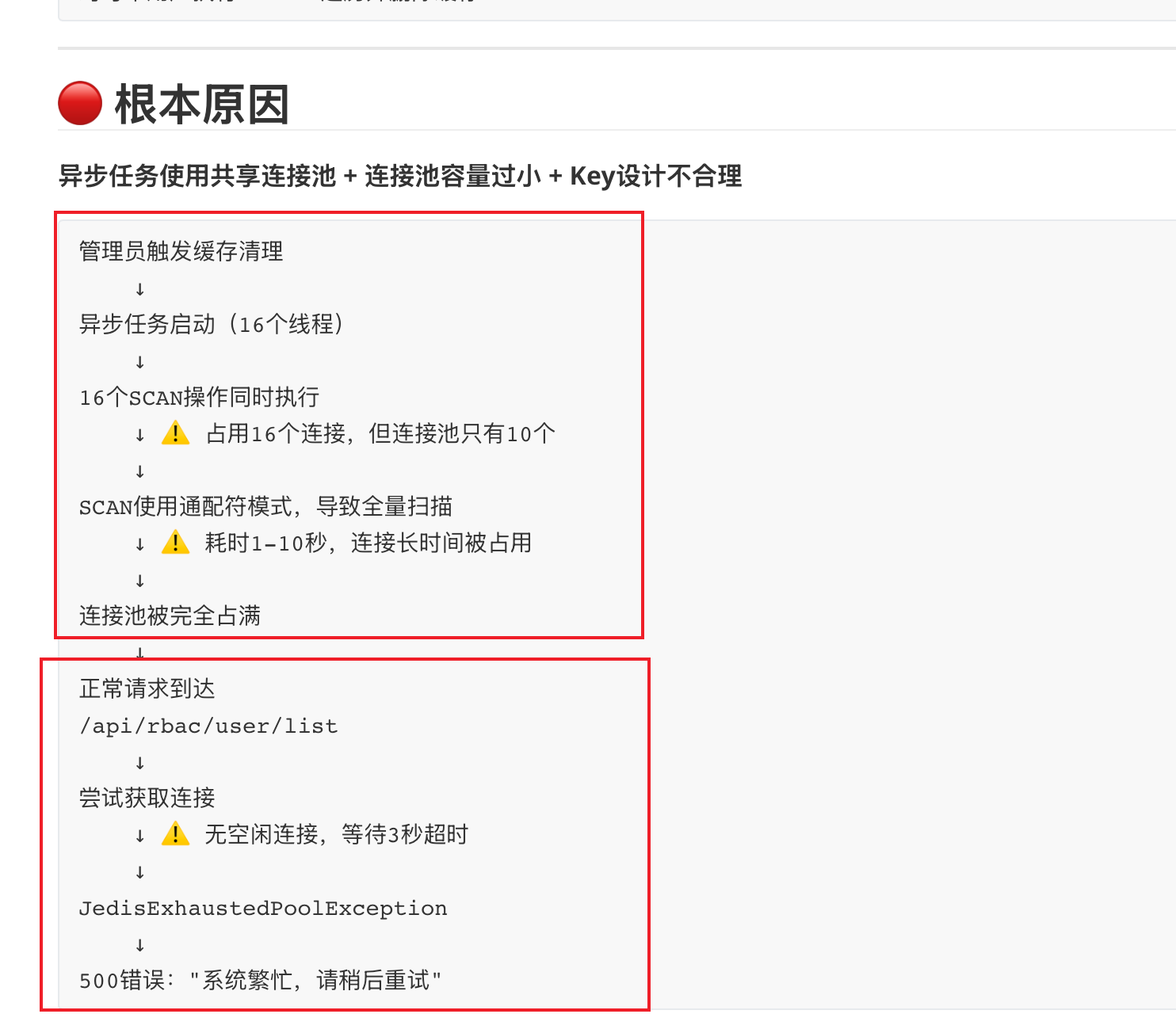
而解决方案也是非常干净利落,通过优化数据结构的方式降低Redis读写操作的时间复杂度,避免连接池夯死:
场景一测下来,M2.7的表现确实超出预期。从N处Redis调用中精准定位根因,到给出完整止血方案,整个推理链条清晰完整。这种问题空间快速收敛的能力,和官方SWE-Pro 56.22%的成绩基本吻合。
# 场景2:从Redis C源码到Go实现的跨语言重构
# 背景说明
接下来我们再来一个高难度场景——复刻Redis慢查询指令。mini-redis是采用Go语言goroutine-per-connection理念提升吞吐量,并以C语言的风格实现符合RESP协议的缓存中间件,由于语言在设计理念上存在偏差,涉及复杂逻辑梳理和易构方案落地。用于验证M2.7官方宣称的"复杂工程系统深层理解"与跨语言架构设计能力再合适不过。
# 需求梳理与方案设计
针对项目重构类需求,按传统开发模式,我们需要大量时间阅读源代码梳理逻辑,期间因历史原因代码无注释,需结合上下文推理调试。了解原有逻辑后,还需结合新项目架构制定实施步骤,并设计单元测试确保既有逻辑稳定运行。整个流程(研发、测试到发布)保守估计需要3个工作日。抱着试试看的心态,笔者将源代码阅读和技术文档整理工作交给M2.7负责。
我现在需要通过Go语言复刻Redis慢查询指令的实现。请你详细阅读Redis源代码,深入理解慢查询功能的完整实现原理、数据结构设计、处理流程和关键步骤。具体包括但不限于:慢查询日志的存储机制、慢查询阈值的配置与调整、慢查询命令的收集与记录流程、相关API接口的设计与实现,以及慢查询信息的查询与展示方式。请基于这些理解,整理出清晰的技术文档,包括核心原理说明、关键数据结构分析、实现步骤分解以及可能的性能优化考量。
等待片刻后,M2.7明确指出技术要求,自底向上地介绍数据结构到执行链路,进行了详尽的分析和介绍:
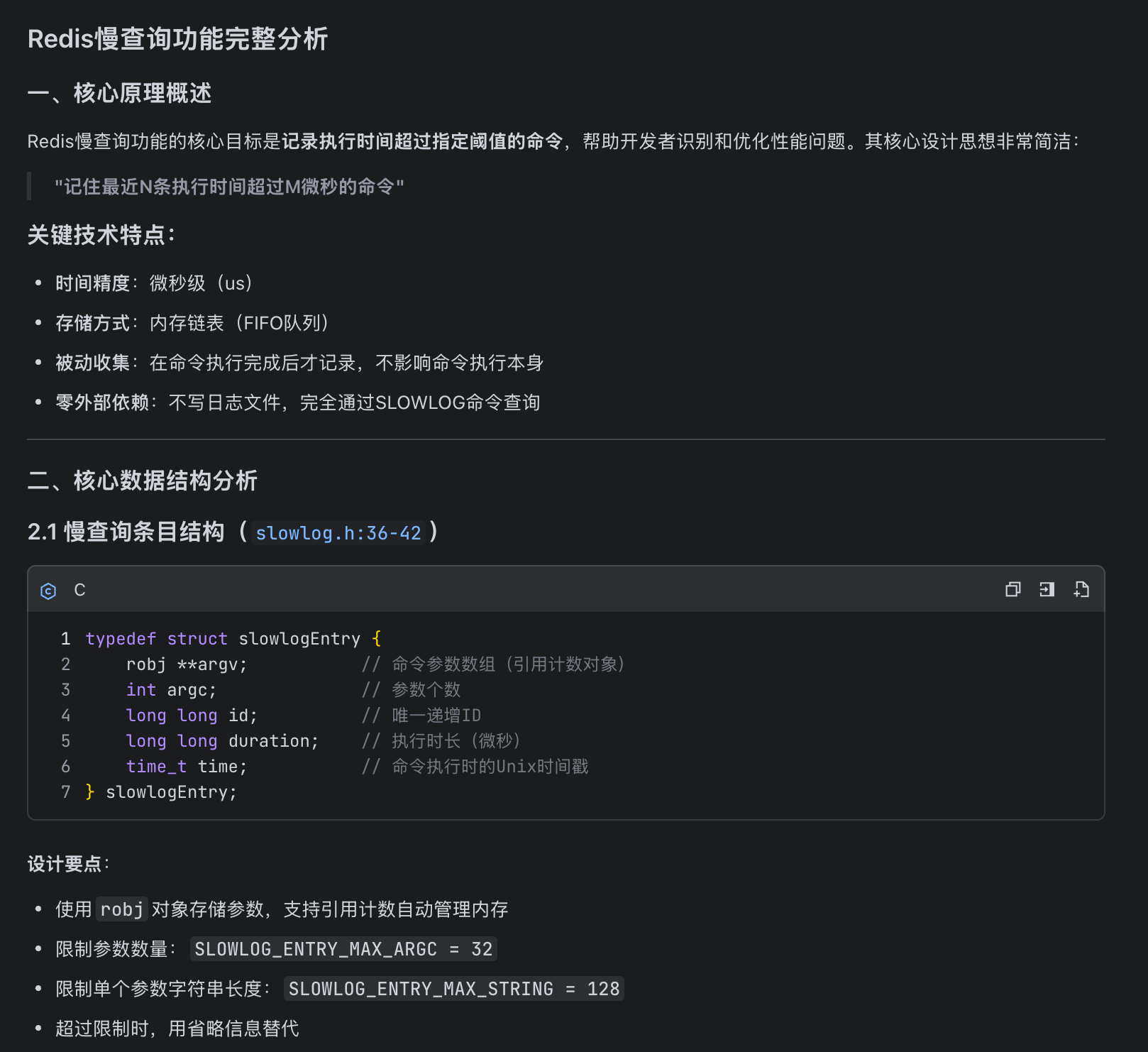
查看其对慢查询切面逻辑的定位非常准确,在主流程上输出了必要的注释,让我快速了解慢查询的整体处理流程:
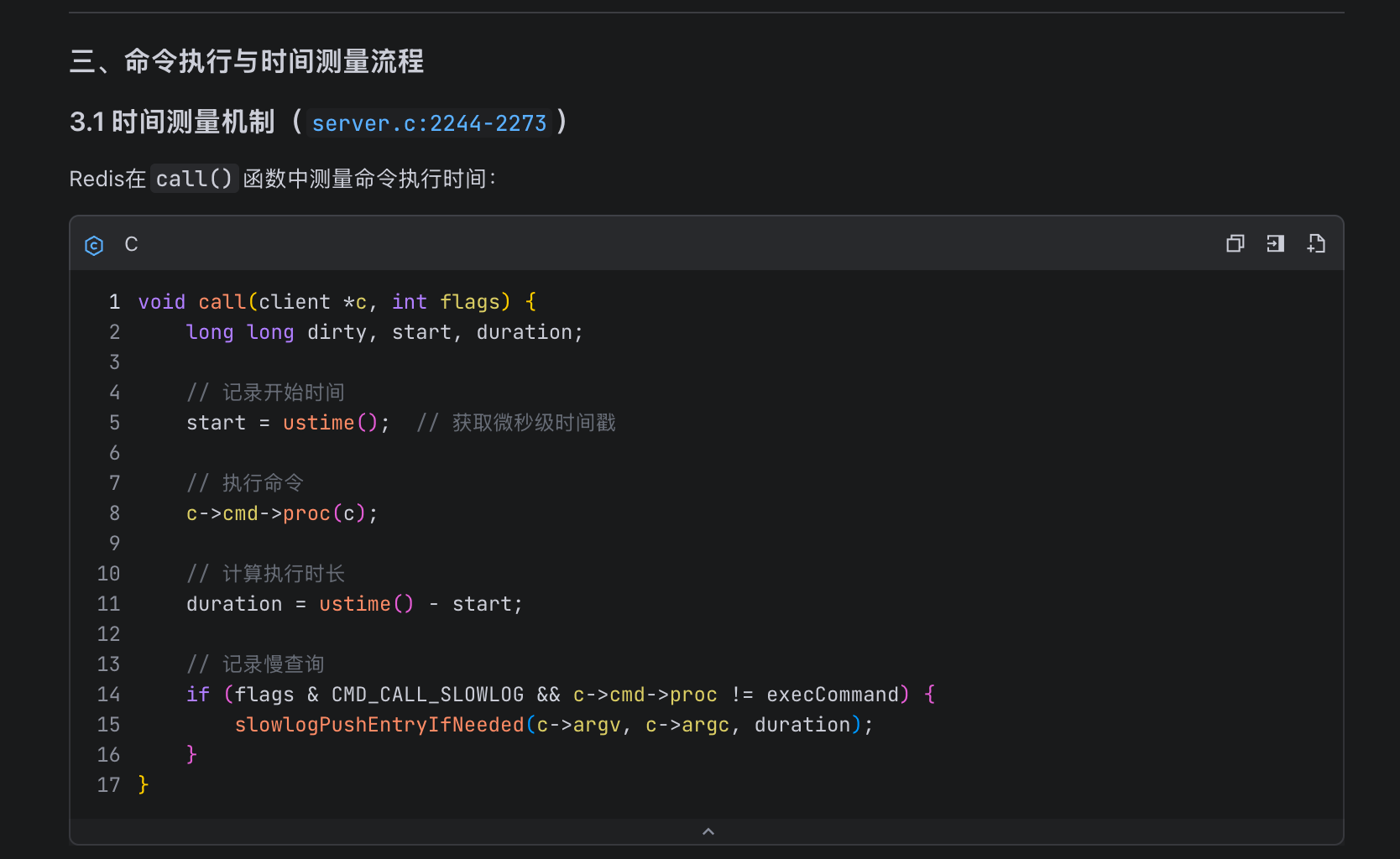
查看其对slot get指令的理解也非常到位,思路和资深开发一样,抓大放小,明确核心逻辑,在主流程上输出必要的注释:
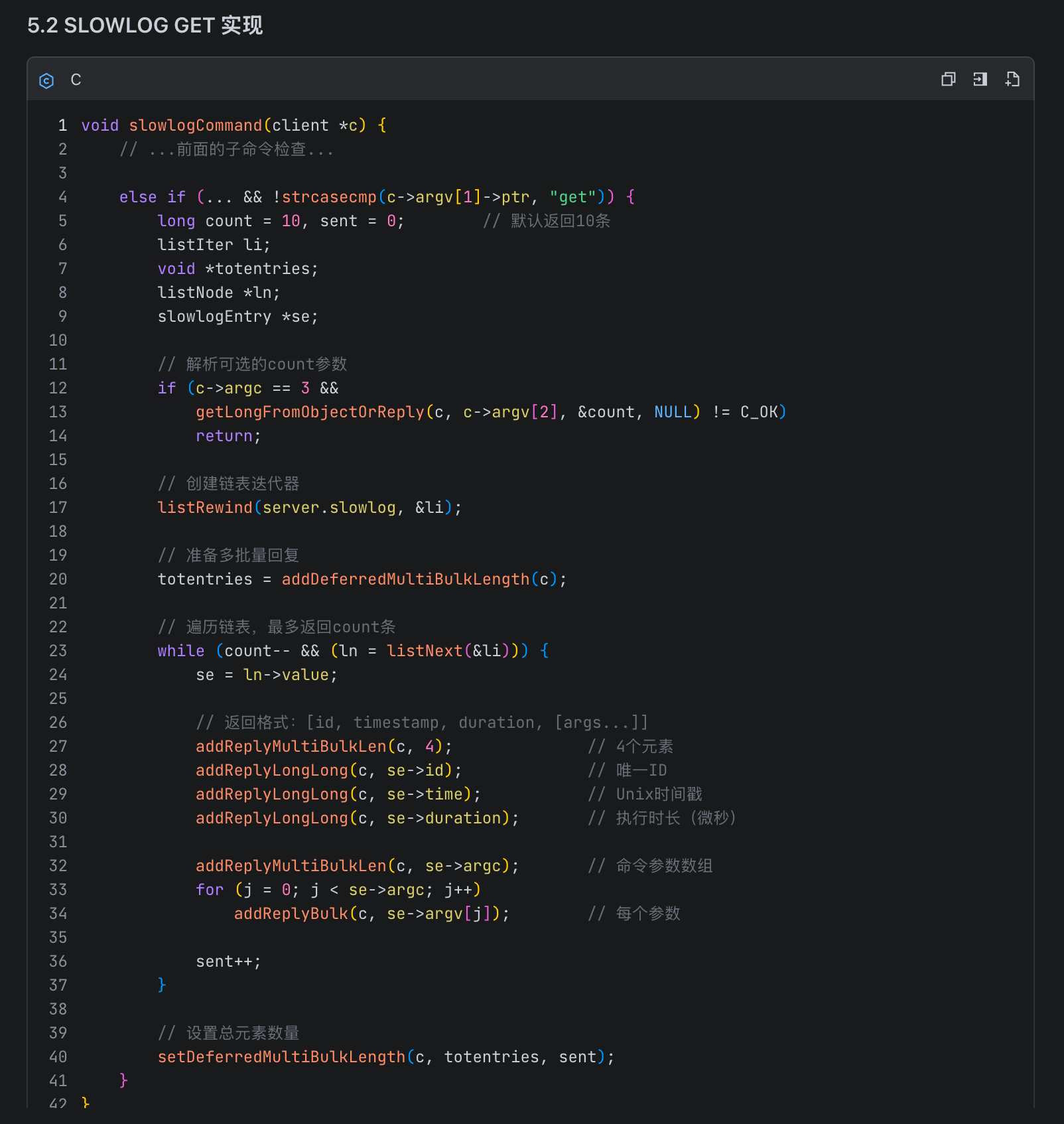
明确M2.7对慢查询有了准确的理解后,我们让M2.7以开发专家的视角进行功能拆解、落地、测试回归的完整设计文档:
按照测试驱动开发(TDD)方法论,使用Go语言创建一个全面详细的开发教程文档,指导复刻Redis的实现。该教程必须符合以下规范:
1. 开发方法:
- 严格执行测试驱动开发工作流程:先编写会失败的测试,然后实现最简代码以通过测试,最后进行重构
- 采用类似于原始Redis C语言实现的面向过程的编程风格
- 尽可能使用纯Go语法和标准库
2. 教程结构:
- 从项目设置和环境配置说明开始
- 按Redis功能拆分为逻辑模块进行开发
- 针对每个模块/特性,提供:
a. 明确的测试用例定义,包含预期输入和输出
b. 逐步的代码实现,附带逐行解释
c. 明确的测试命令和验证流程
d. 预期测试结果和成功标准
3. 技术要求:
- 包含所有组件的完整代码片段
- 指定确切的文件结构和命名规范
- 详细说明编译和测试命令
- 解释常见问题的调试流程
- 在适用时参考相关的Redis C源代码模式
4. 实现细节:
- 从核心数据结构(字符串、列表、哈希等)开始
- 逐步推进到命令处理和协议实现
- 包含网络层和客户端-服务器通信
- 涵盖持久化机制(RDB/AOF)
- 按照相同的行为模式实现基本的Redis命令
5. 测试要求:
- 为每个组件提供完整的测试代码
- 解释测试断言和验证方法
- 包含单元测试和集成测试
- 指定如何运行测试并解读结果
- 详细说明如何根据Redis规范验证正确行为
该教程应足够全面,让具备中级Go知识的开发者能够按照指定方法成功构建一个功能类似的Redis系统。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
等待片刻后,我们收到一份设计文档。M2.7非常准确地结合Redis源代码上下文,梳理出慢查询的核心脉络和关键定义,并规划出完整的开发步骤。这正是官方宣称的"复杂工程系统深层理解"能力:
# 编码实现
我们从Redis源代码中抽取设计文档后,为确保C语言工程的设计思路能在个人Go语言项目工程规范中准确落地,将其复制到mini-redis项目,让M2.7分析方案的可行性和修改建议:
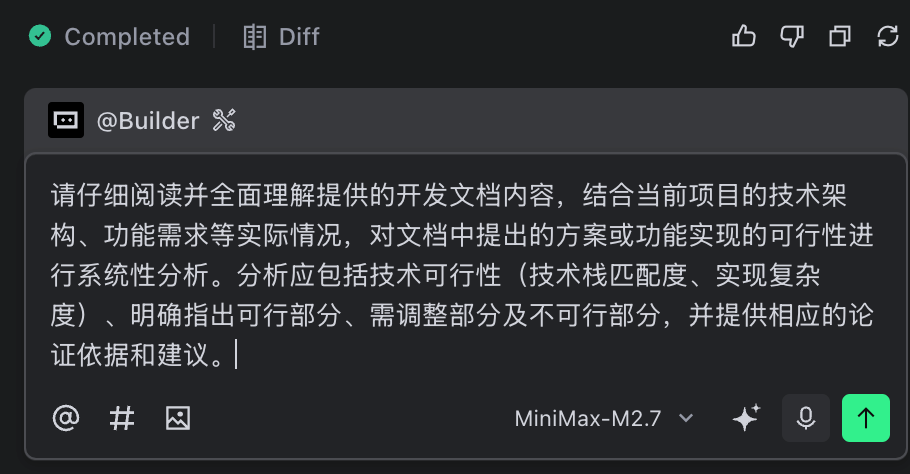
等待片刻后M2.7完成文档最后的可行性分析和整理,我们开始对其设计方案进行进一步的复核确认,从项目概述上可以看到M2.7很好地针对mini-redis项目结构进行分析,很准确地定位到慢查询可以直接复用的链表结构体并完成文档微调:
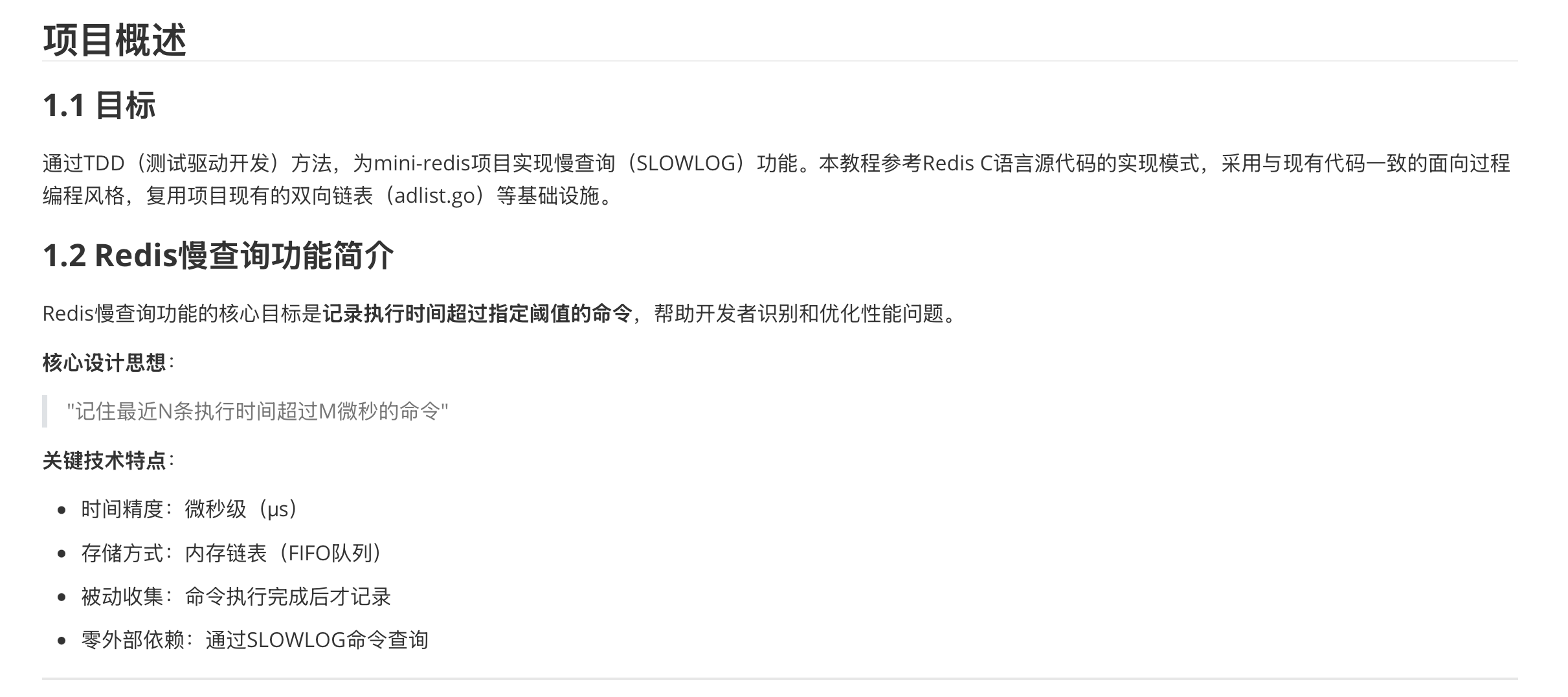
再来看看最关键的数据结构实现思路,M2.7也非常准确地结合mini-redis的编码规范,生成Go语言风格的结构体:

针对慢查询时间测量,这点让笔者感到惊喜。个人实现的指令处理入口和原生Redis有些设计上的出入:由于Go语言语法糖特性,笔者对指针、指针函数以及文件编排做了特殊处理。M2.7非常准确地基于笔者的协程模型定位到时间测量的切面,完成前置计时和后置统计,实现慢查询监控。

最后就是核心的慢查询指令实现,无论是参数解析还是指令查询和响应处理函数,M2.7都非常准确地结合笔者的当前项目封装的逻辑给出明确的编码方案:

经过仔细复核设计文档,整体开发思路基本一致,但在代码组织细节上仍有调优空间——例如M2.7将slowlog指令独立成文件,而未遵循项目惯例统一放入command.go。考虑到慢查询功能并非核心内存读写指令,且其日志管理逻辑相对独立,这一处理也算合理折中。权衡之后,我们决定保留M2.7的实现方式,同时手动调整部分文件布局以符合既有工程规范,随后推进剩余开发工作。
这一细节也提示我们:AI生成的代码架构虽具合理性,但与既有工程规范的适配仍需人工把关。
# 验收
因为笔者明确指出TDD的开发模型,所以M2.7在这期间很好地结合输出反馈和文档说明完成自循环修复,最终保质保量地结合mini-redis的项目风格完成了慢查询指令的复刻。
因为M2.7强大的推理能力和重构能力,在验收过程中我们有了更多的构思空间,之前一直因为源代码梳理总结和技术验收成本过大,所导致的redis.conf配置加载逻辑一直没有实现。
因为笔者需要将慢查询时间设置为0,方便对慢查询指令做最后的验收工作,所以笔者索性再次对其提出加载配置的需求:
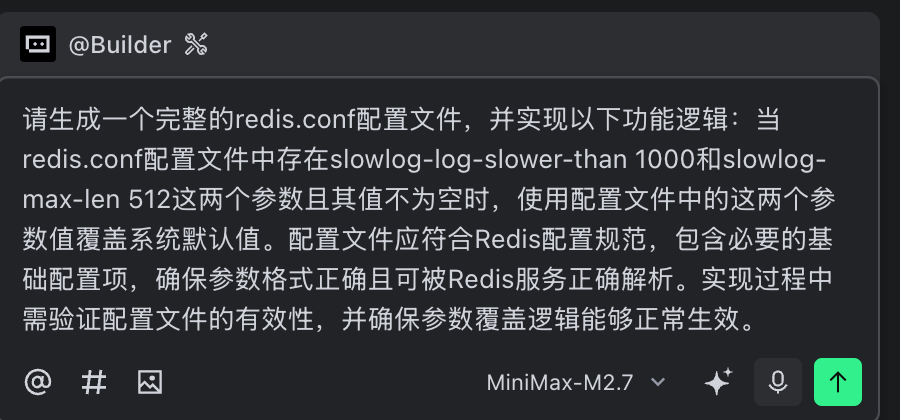
整个逻辑梳理和开发工作不到1小时,笔者顺利完成了慢查询指令复刻和验收,为了演示慢查询功能,将mini-redis的慢查询阈值设置为0:
# 慢查询阈值(微秒)
# 执行时间超过此值的命令会被记录到慢查询日志中
# 负值表示禁用慢查询日志,0 表示记录所有命令
# 默认值:10000(10毫秒)
slowlog-log-slower-than 0
2
3
4
5
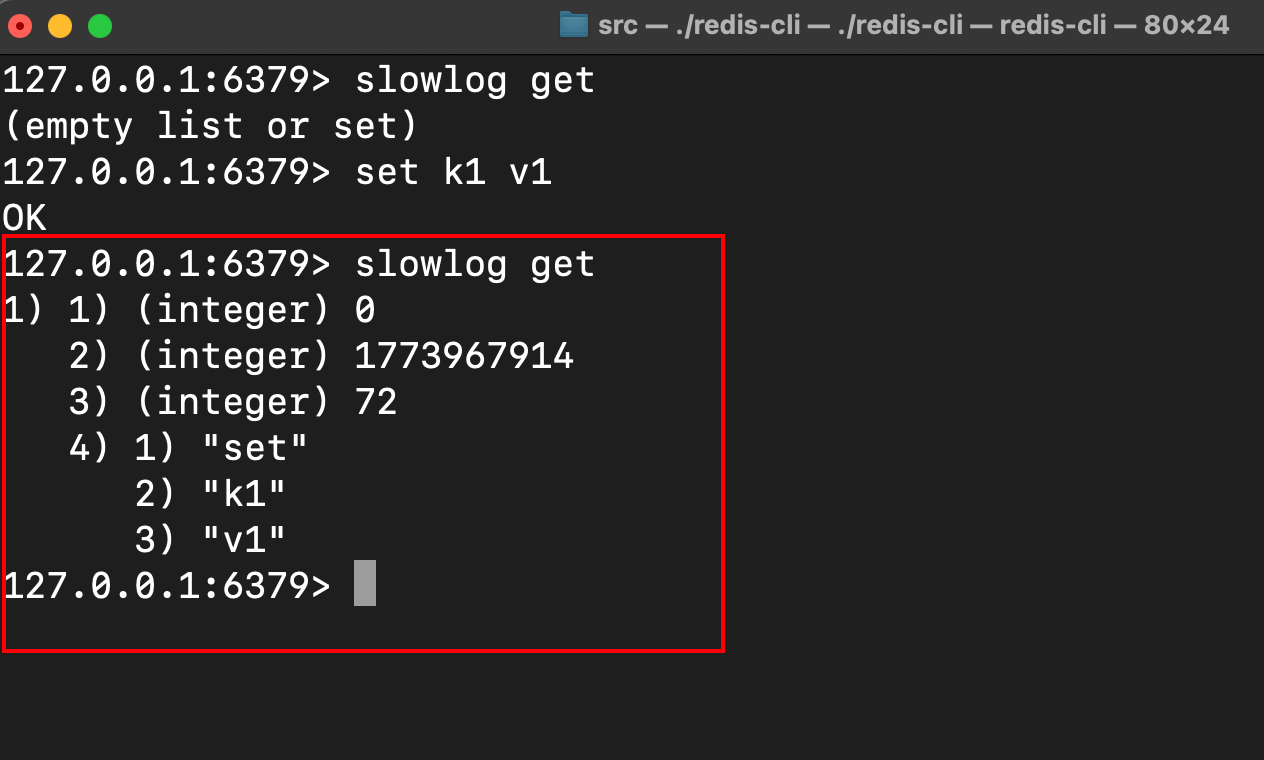
启动mini-redis服务端后,键入slowlog get 默认返回空:
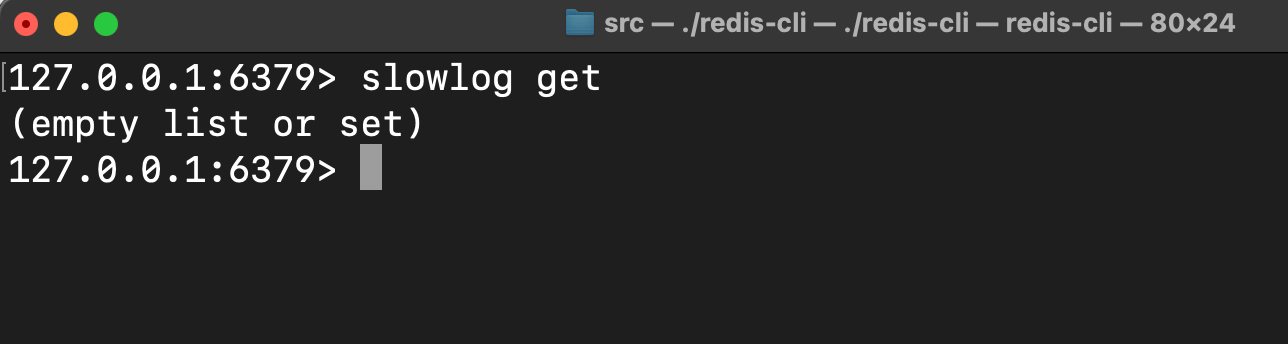
执行简单的set操作后,键入slowlog get,这条指令如预期被判定为慢查询指令并输出:
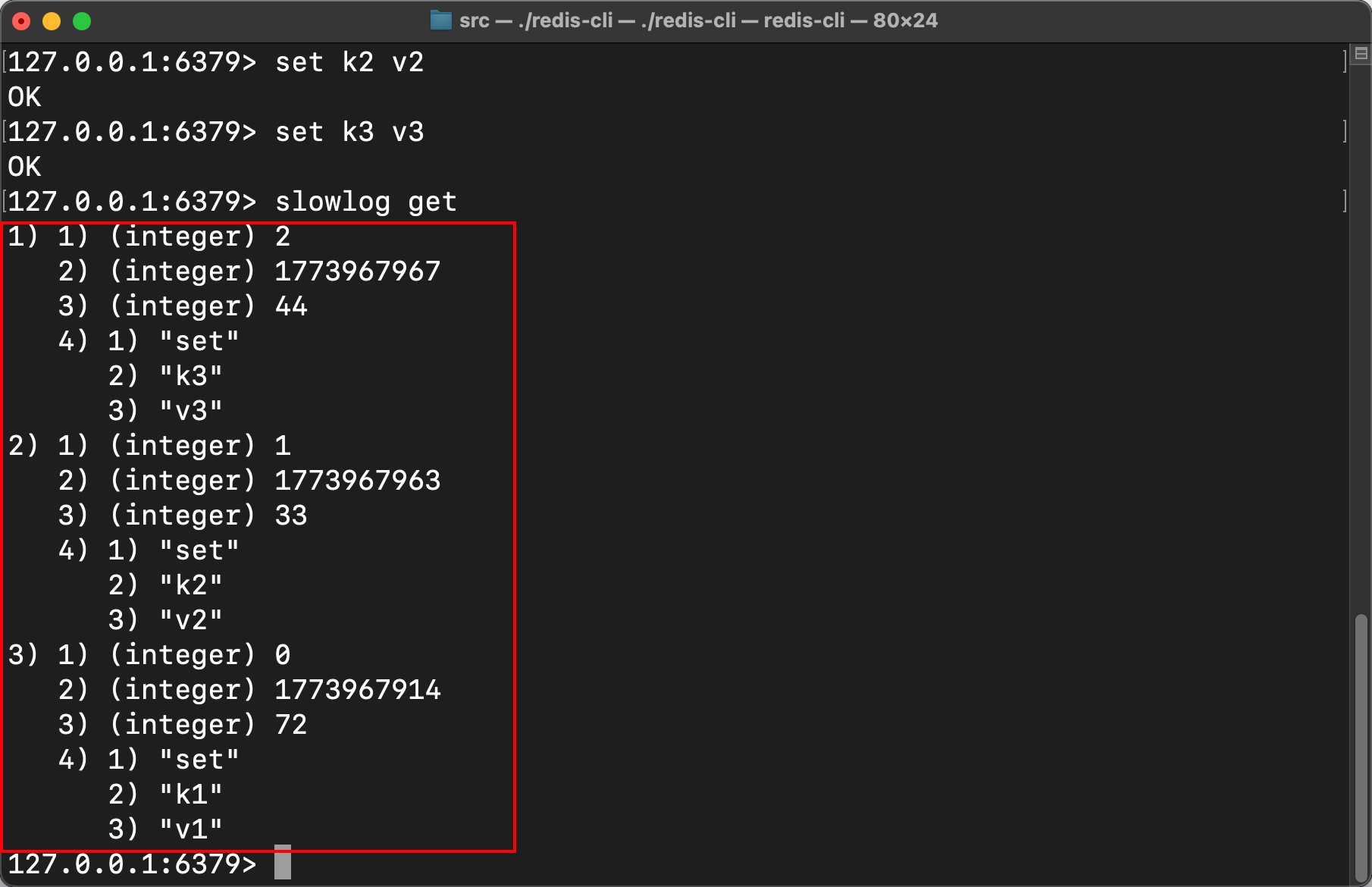
同理,我们依次键入后续几条指令,也都准确按照链表头插法入队,实现按照时间降序排列输出:
# MiniMax M2.7核心优势分析
通过对两个典型场景的深度测评,结合官方公布的基准测试数据,我们总结出MiniMax M2.7在开发辅助领域的核心优势:
# 基准测试表现
| 基准测试 | M2.7得分 | 行业对标 |
|---|---|---|
| SWE-Pro | 56.22% | ≈ GPT-5.3-Codex |
| VIBE-Pro | 55.6% | ≈ Opus 4.6 |
| Terminal Bench 2 | 57.0% | 复杂系统理解能力 |
| SWE Multilingual | 76.5 | 多语言编程 |
| Multi SWE Bench | 52.7 | 多问题处理 |
数据来源:MiniMax官方发布及第三方评测机构
# 1. 强大的上下文理解能力
M2.7能够理解整个项目的代码结构和业务逻辑,而非孤立地处理单个问题点。在场景1中,它准确梳理了从接口请求到Redis操作的完整调用链路;在场景2中,它快速把握了Redis源代码的设计理念。
# 2. 多层级问题处理能力
| 问题层级 | M2.7表现 |
|---|---|
| 止血处理 | 提供快速应急方案,支持服务降级 |
| 根因定位 | 深入分析代码逻辑,识别架构问题 |
| 长期优化 | 给出数据结构和架构层面的改进建议 |
# 3. 跨语言迁移能力
在场景2中,M2.7成功完成了从Redis C语言实现到Go语言复刻的技术文档编写,证明其在异构语言场景下的迁移和推理能力。
# 4. 开发效率提升
| 传统方式 | 使用M2.7 | 效率提升 |
|---|---|---|
| 3个工作日 | 数小时完成核心功能 | 约80% |
| 需要反复调试 | 自动修复和自循环验证 | 减少试错成本 |
| 依赖个人经验 | 结合最佳实践给出方案 | 降低经验门槛 |
# 总结与建议
基于两个真实场景的试用体验,对MiniMax M2.7形成以下客观评价:
# 能力验证总结
| 能力维度 | 场景表现 | 评价 |
|---|---|---|
| 故障诊断与止血 | 场景1:快速定位连接池问题,提供降级方案 | 表现优秀,推理链条完整 |
| 跨语言代码迁移 | 场景2:C到Go的慢查询复刻 | 核心逻辑准确,工程规范适配有优化空间 |
| 复杂系统理解 | 场景2:Redis源码分析 | 设计意图把握到位 |
| 端到端交付 | 设计→编码→测试全流程 | 可独立完成,关键节点需人工确认 |
# 使用建议
- 适用场景:线上故障应急、遗留系统重构、技术方案预研
- 最佳实践:
- 提供完整上下文,明确约束条件
- 复杂架构分阶段确认,避免一次性生成过多代码
- 工程规范相关的文件组织需提前说明或后期调整
- 质量把控:核心逻辑务必人工复核,特别是与既有代码风格的兼容性
# 客观评价
M2.7在代码理解和方案设计层面表现亮眼,能够显著缩短从问题到方案的时间。但在实际使用中也有一些需要注意的地方:
- 工程规范适配:生成的代码结构虽合理,但与个人/团队既有规范的契合度需要磨合
- 长流程一致性:在复杂项目的持续迭代中,需要关注上下文记忆的衰减问题
- 边界情况处理:部分极端场景的防御性代码建议人工补充
总体而言,M2.7已具备作为日常开发助手的实用价值,适合承担70%-80%的方案设计和编码工作,剩余部分仍需开发者把控。
