 Qoder JetBrains插件评测:祖传代码重构与接口优化实战
Qoder JetBrains插件评测:祖传代码重构与接口优化实战
随着 Qoder、Trae、Claude Code、Cursor 等 AI 编程工具的兴起,后端开发者逐渐分化为四大阵营:
| 阵营 | 工具组合 | 特点 |
|---|---|---|
| 原生派 | CLI + JetBrains IDE | 极致效率,学习成本高 |
| 极简派 | VS Code + 插件 | 轻量灵活,功能受限 |
| 混合派 | Cursor/Trae → JetBrains 验收 | AI 辅助 + 专业 IDE 兜底 |
| 一体派 | JetBrains + Qoder JetBrains 插件 | 心流专注,开箱即用 |
而笔者正属于最后一派——一体派。原因也很简单:让我快速进入工作的心流,迅速拉满生产力,高效完成眼下所有的工作。这种模式也正如乔布斯所说——真正的专注,不是看你同时能打开多少窗口,而是看你能否在一个窗口里,连接整个世界。
That's been one of my mantras — focus and simplicity. Simple can be harder than complex... once you get there, you can move mountains.
乔布斯所说的"一个窗口",对后端开发者而言,意味着无需在 IDE、数据库客户端、API 测试工具、文档编辑器之间频繁切换——所有工作流在一个环境内完成,心流不被打断。而 Qoder JetBrains 插件,正是实现这一愿景的关键拼图。
所以这篇文章,笔者将安利一款强大的 JetBrains AI 编程插件——Qoder - Agentic AI Coding Platform。
# 为什么选择 Qoder JetBrains 插件
当前主流的 AI 编程工具——Cursor、Trae、CodeBuddy、Claude Code 等——大多基于 VS Code 二次开发。对于后端开发而言,这种组合存在天然局限:
| 维度 | VS Code 模式 | 后端开发痛点 |
|---|---|---|
| 代码提示 | 依赖插件,配置繁琐 | 模糊匹配弱,Spring 生态支持不足 |
| 调试能力 | 基础断点,高级特性缺失 | Lambda、多线程调试困难 |
| 工具链 | 手动安装插件 | Java/Go 生态无法开箱即用 |
| 数据库 | 需额外客户端 | 频繁切换打断心流 |
相比之下,JetBrains IDE 专为后端开发设计:代码提示精准、调试功能完备、Git 与数据库工具内置。问题是如何在保持这些优势的同时,获得 AI 的赋能?
Qoder JetBrains 插件给出了答案——无需离开熟悉的 IDE,即可享受 AI Agent 的推理分析与编码落地能力:
- 记忆感知:自动沉淀个人编码习惯与项目规范,持续对话中"越用越懂你"
- 工程感知:双引擎架构支持 10 万+ 文件项目的深度理解,自动感知任务所需的文件、框架与依赖
下面通过两个实战案例,分享 Qoder JetBrains 插件在实际开发中的表现。
# Qoder JetBrains 插件上手教程
# 安装与配置
在正式介绍案例之前,我们首先要完成 Qoder JetBrains 插件的安装与配置工作。
第一步:点击 Settings | Plugins 并搜索 "qoder" 关键字,选择 Qoder - Agentic AI Coding Platform 并点击安装。
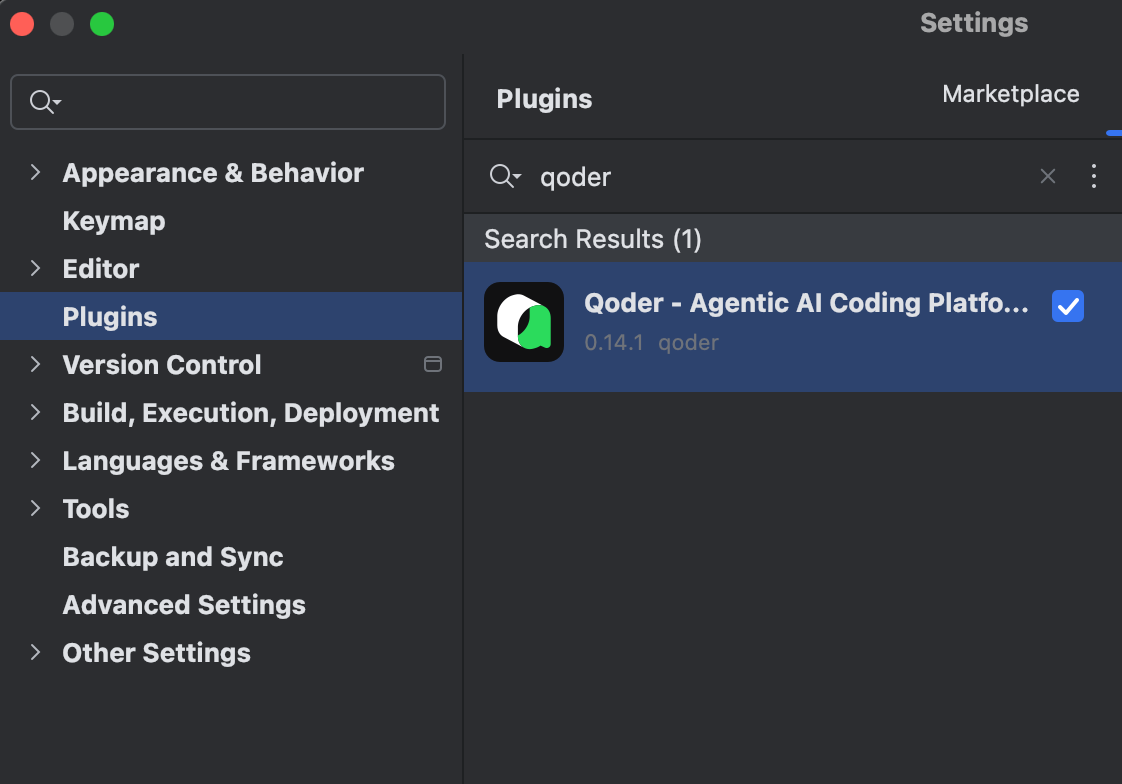
第二步:稍等片刻完成安装,点击 Sign In 进行必要的登录与注册:
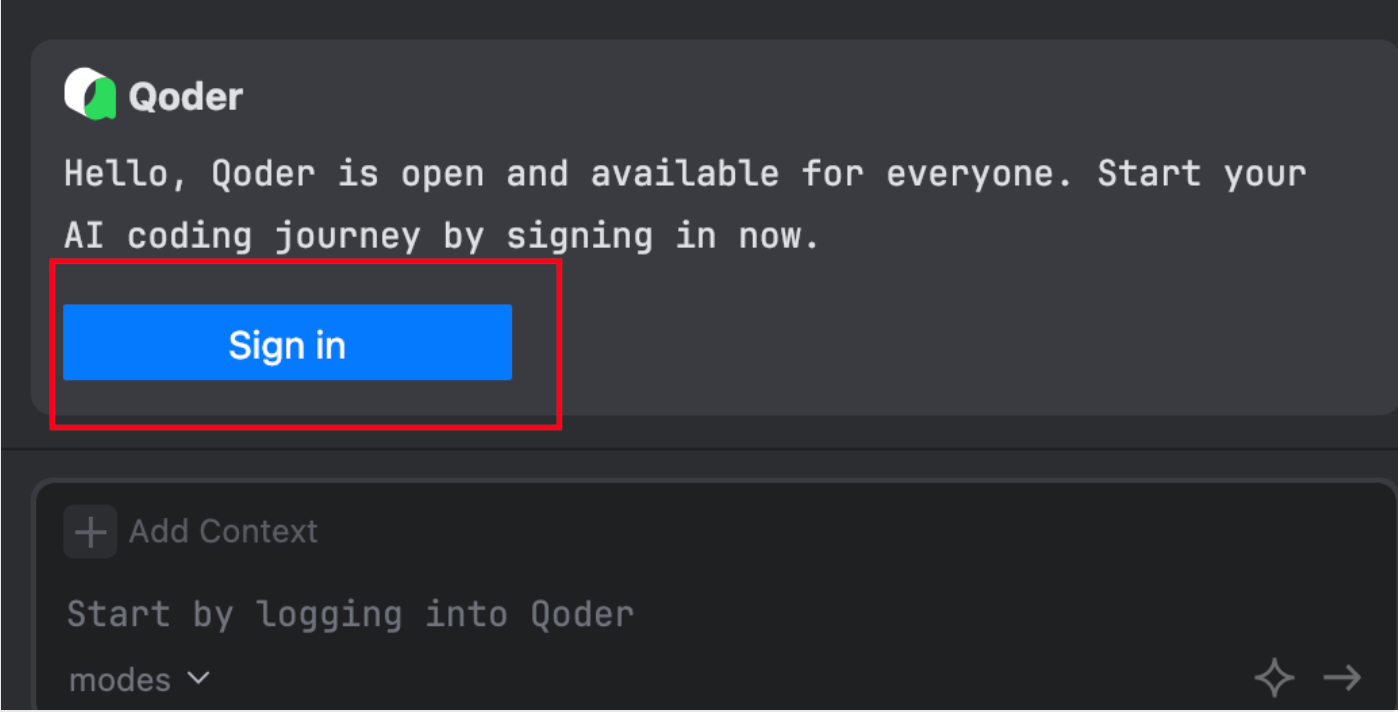
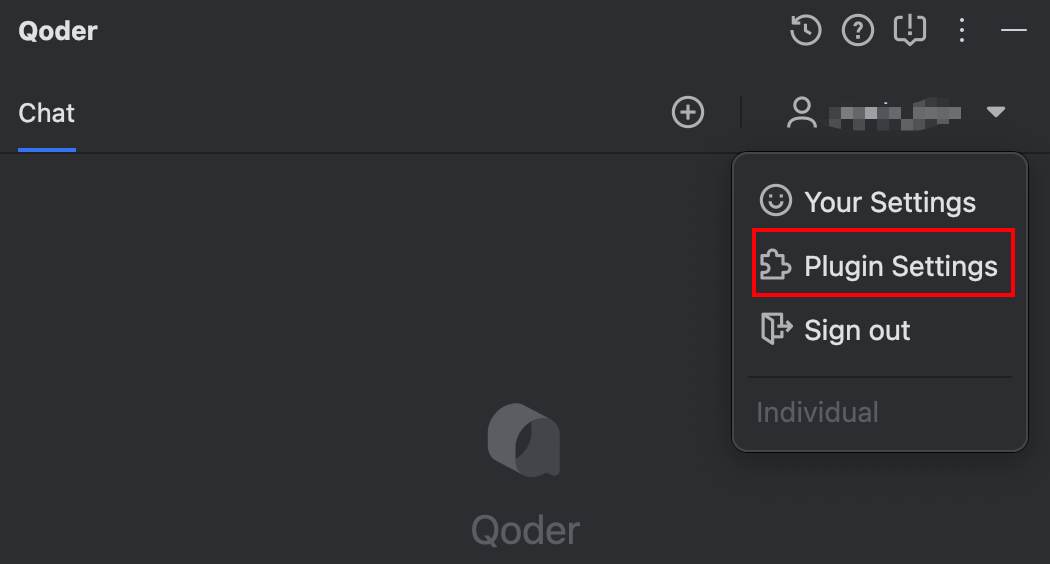
第三步(可选):默认情况下,Qoder JetBrains 插件显示英文。习惯中文语境的读者可点击右上角 Plugin Settings 进入插件设置界面:
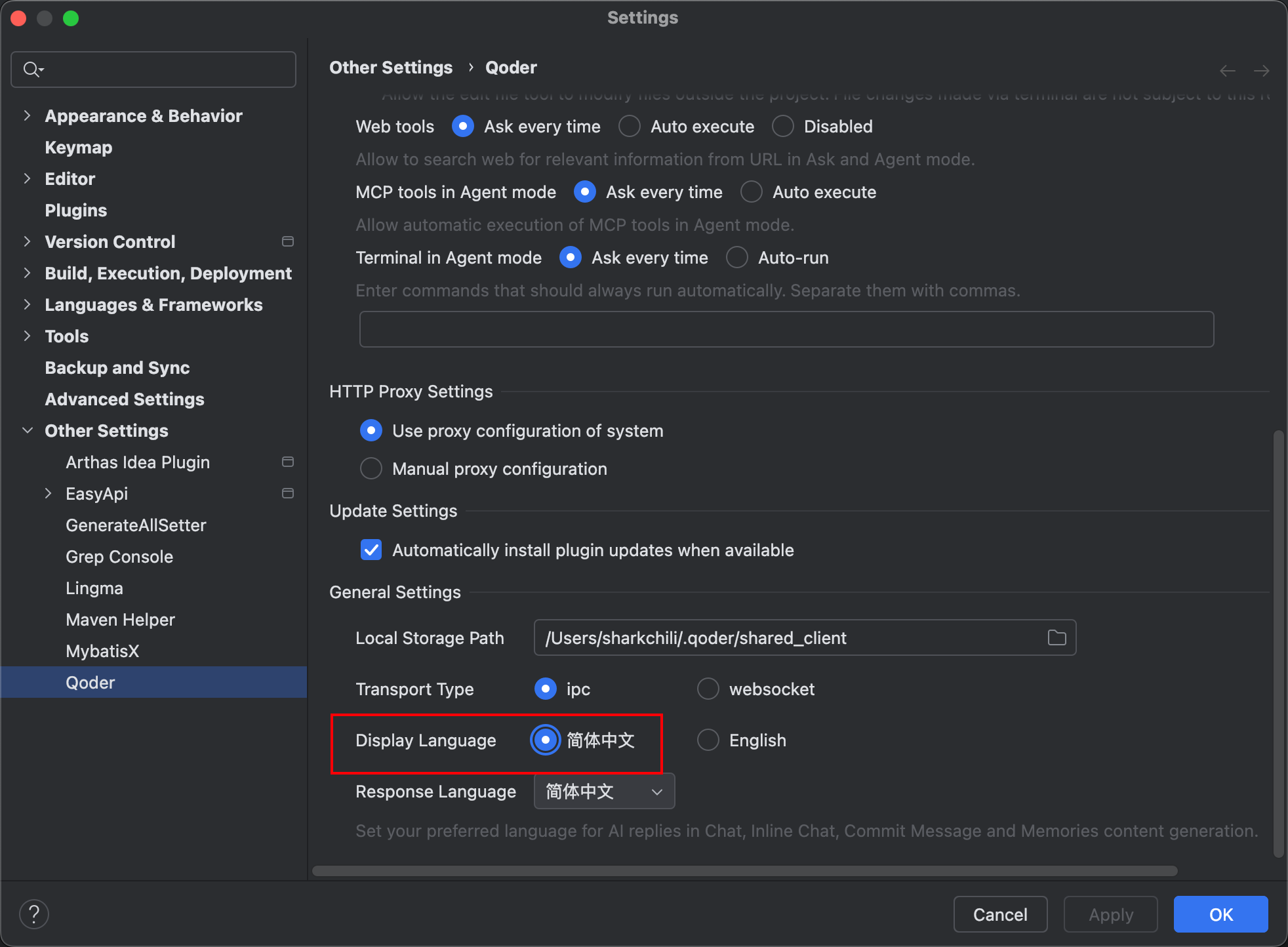
定位 Display Language 并将其设置为简体中文:
第四步(可选):配置数据库连接。Qoder JetBrains 插件全新支持 @database 上下文,可直接引用数据库表结构。考虑到后续开发工作深度依赖数据库,建议提前配置项目相关数据库。
以笔者当前项目所用到的 MySQL 数据库为例,打开右侧 Database 工具窗口,点击 + 号,选择 Data Source | MySQL:
填写数据库连接信息,等待驱动下载完成。点击 Test Connection 测试连通性,确认成功后点击 OK 完成配置。至此,所有前期准备工作已完成:
# 任务一:订单查询频繁报错?原本一天的工作,现在 10 分钟搞定
# 背景说明
本项目模拟一个真实的电商后台管理系统,运营部门每月需要生成经营分析报表。由于数据量较大(订单表 1000 万+),且开发时间紧张,代码存在多个性能隐患。
运营部门反馈订单查询频繁报错,我们定位到接口和参数:
curl -X POST http://localhost:8080/api/report/orders \
-H "Content-Type: application/json" \
-d '{"page": 1000000, "size": 10}'
2
3
这是一个典型的深分页请求。接口代码逻辑如下:
@Transactional(readOnly = true)
public OrderListResponse getOrderList(OrderListRequest request) {
int pageNum = request.getPage() == null ? 1 : request.getPage();
int pageSize = request.getSize() == null ? 10 : request.getSize();
// ⚠️ 问题核心:深分页查询
Page<Order> pageParam = new Page<>(pageNum, pageSize);
LambdaQueryWrapper<Order> wrapper = new LambdaQueryWrapper<>();
if (request.getStatus() != null && !request.getStatus().isEmpty()) {
wrapper.eq(Order::getStatus, request.getStatus());
}
if (request.getShopId() != null) {
wrapper.eq(Order::getShopId, request.getShopId());
}
// ⚠️ 排序字段可能无索引,触发全表扫描
wrapper.orderByDesc(Order::getCreatedAt);
// ⚠️ 深分页:LIMIT 9999990, 10
IPage<Order> orderPage = orderMapper.selectPage(pageParam, wrapper);
// 关联查询用户、店铺信息...
Set<Long> userIds = orders.stream().map(Order::getUserId).collect(Collectors.toSet());
Set<Long> shopIds = orders.stream().map(Order::getShopId).collect(Collectors.toSet());
// ... 结果组装
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
当 page=1000000 时,MySQL 执行 LIMIT 9999990, 10,需要扫描前 1000 万行数据后丢弃,性能急剧下降。
# 传统方式的困境
按照传统流程,接口调优需要:
- 阅读梳理代码逻辑(非自己负责的接口还需沟通)
- 分析代码逻辑优化空间
- 结合日志分析 SQL 执行计划
- 输出解决方案并实施
- 回归测试与部署上线
整个过程需要阅读大量代码、调试、整理执行计划,如果涉及高风险影响面还需完整单元测试。一套完整的排查优化下来,基本一天就过去了。
# Qoder JetBrains 插件辅助模式:从执行者到指挥者
有了 Qoder JetBrains 插件后,工作模式发生根本转变:决策编排 → 方案沟通 → 指挥执行 → 验收确认。
我们只需整理思路,给出明确目标,Qoder JetBrains 插件便会自动完成代码分析、SQL 诊断、方案输出等繁琐工作:
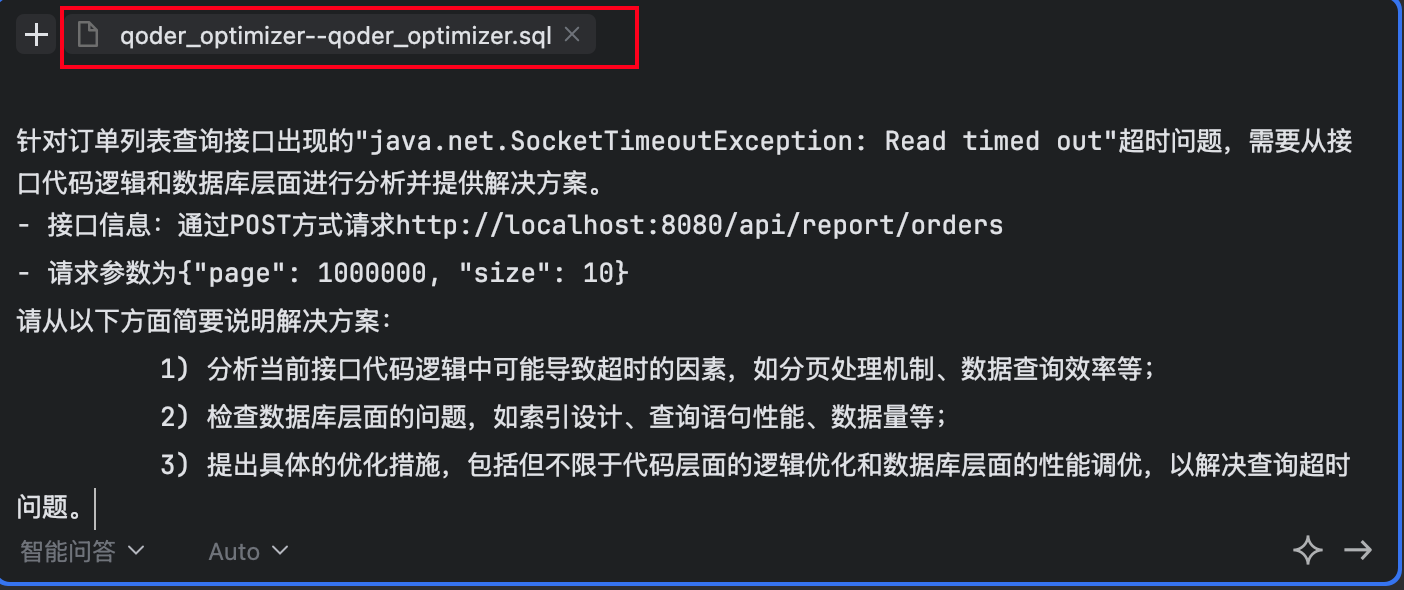
针对订单列表查询接口出现的"java.net.SocketTimeoutException: Read timed out"超时问题,需要从接口代码逻辑和数据库层面进行分析并提供解决方案。
- 接口信息:POST http://localhost:8080/api/report/orders
- 请求参数:{"page": 1000000, "size": 10}
请从以下方面给出解决方案:
1. 分析接口代码逻辑中可能导致超时的因素
2. 检查数据库层面的问题(索引、查询性能、数据量)
3. 提出具体的优化措施
2
3
4
5
6
7
8
9
为了让 Qoder 更好地完成工作,我们在会话中添加数据库上下文:
- 点击 +Add Context 按钮
- 选择 @database,选择对应的数据库 Schema
# 问题分析与方案输出
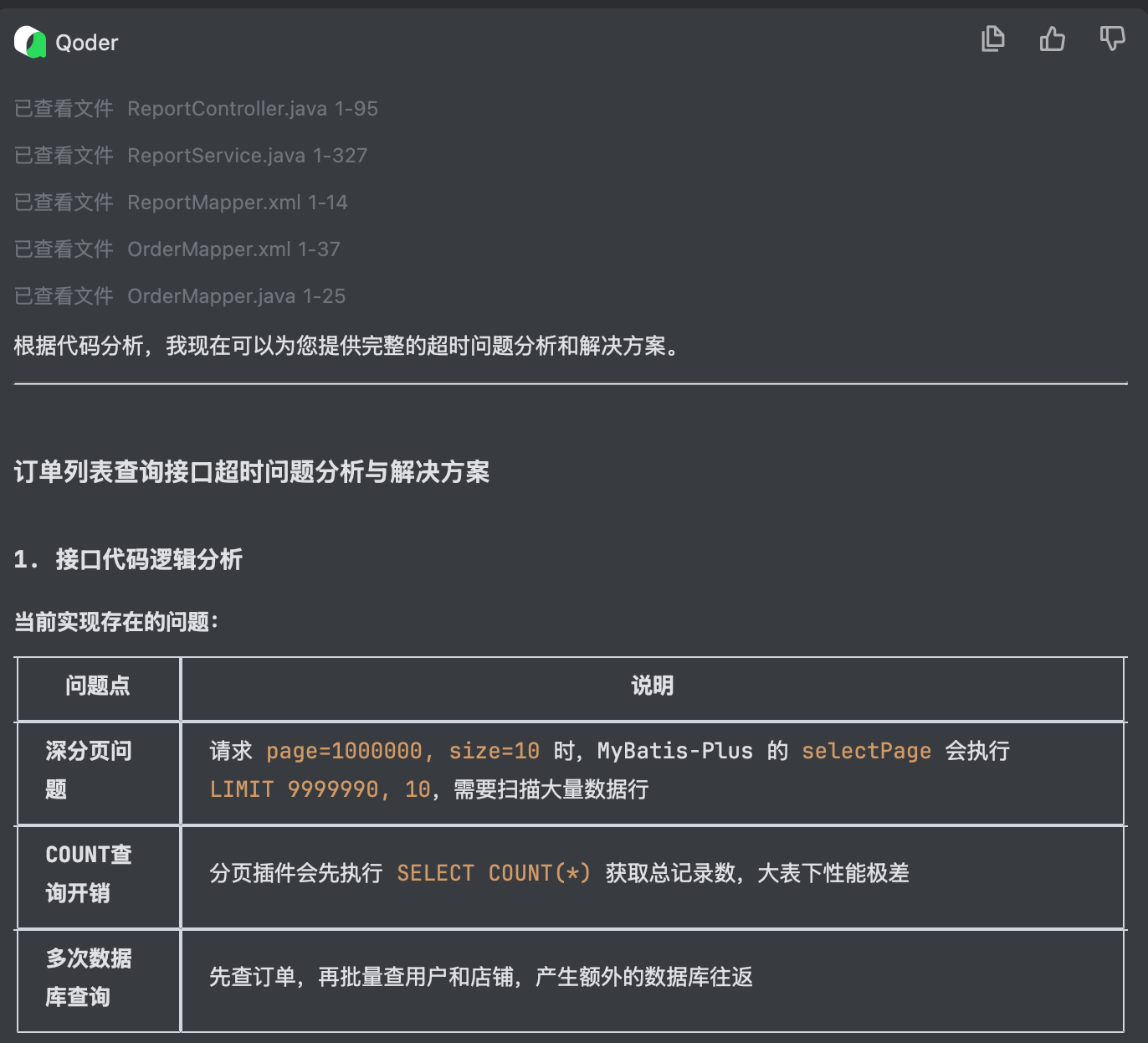
秒级定位问题根因
Qoder 精准定位到代码入口,完成分析并给出问题根因——无需人工逐行阅读代码:
独到之处:代码与数据库联合诊断
结合数据库 Schema,Qoder 给出了综合分析报告——这一点是笔者日常工作中容易忽略的。传统方式下,开发者往往只关注代码层面,而 Qoder 会主动关联数据库结构,给出更全面的诊断:
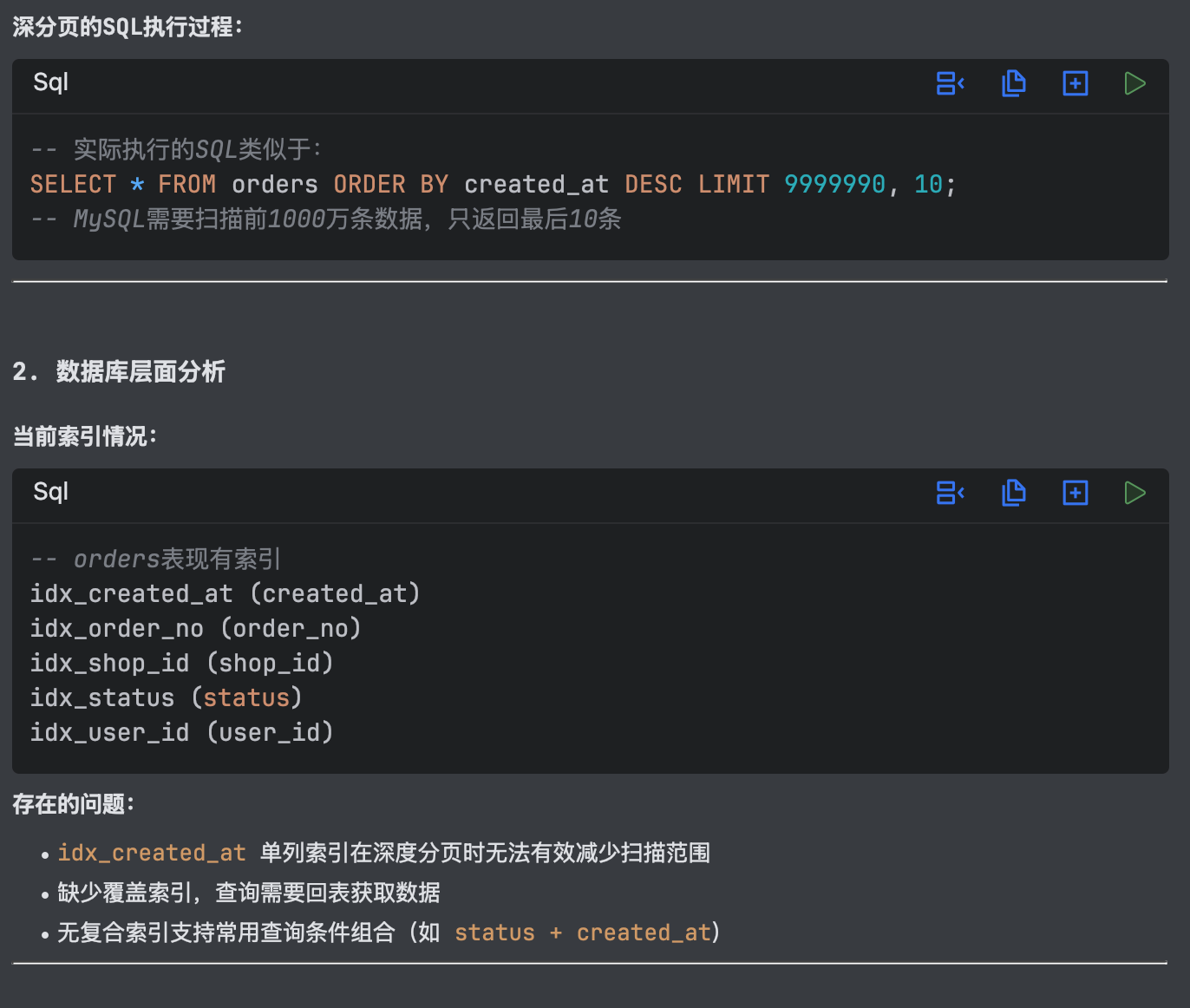
代码层面优化:Qoder 给出了三套方案,包括延迟关联查询(子查询只返回 ID,利用覆盖索引快速定位)。
惊喜发现:开发者没想到的方案
分页查询总记录计算,Qoder 给出了一个笔者从未见过的方案——通过主键索引页数和页内平均行数进行数学估算。这种方案对大数据量且精度要求不高的场景非常适用。Qoder 不仅解决了问题,还拓展了笔者的技术视野:
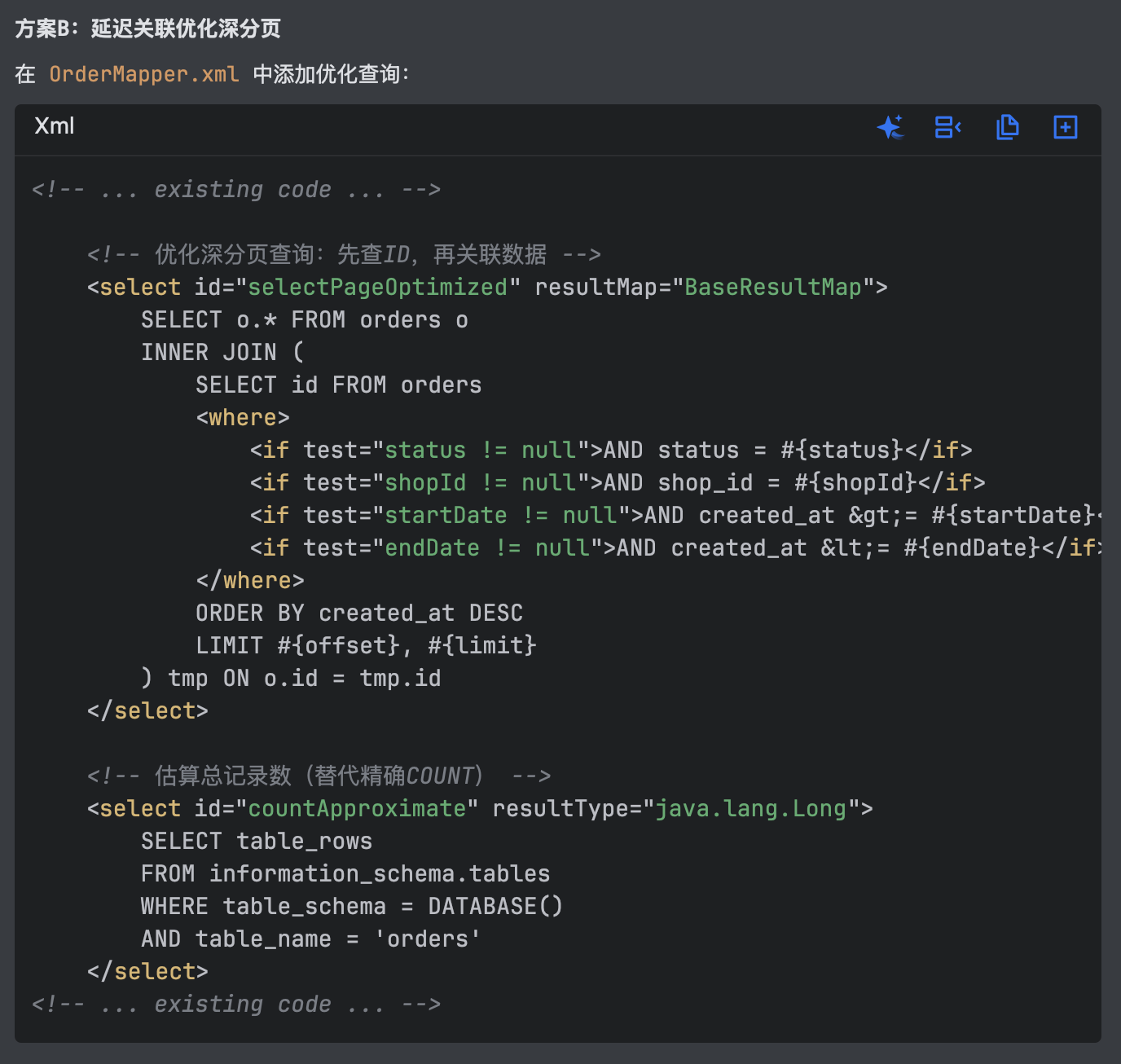
数据库层面优化:Qoder 分析了所有条件查询和 MySQL 版本信息,给出了全面的索引建议——无需手动整理 SQL、无需逐条分析执行计划:
# 方案实施与验收
审核评估后,我们选定延迟关联 + 索引优化方案:
基于审核评估结果,执行以下优化:
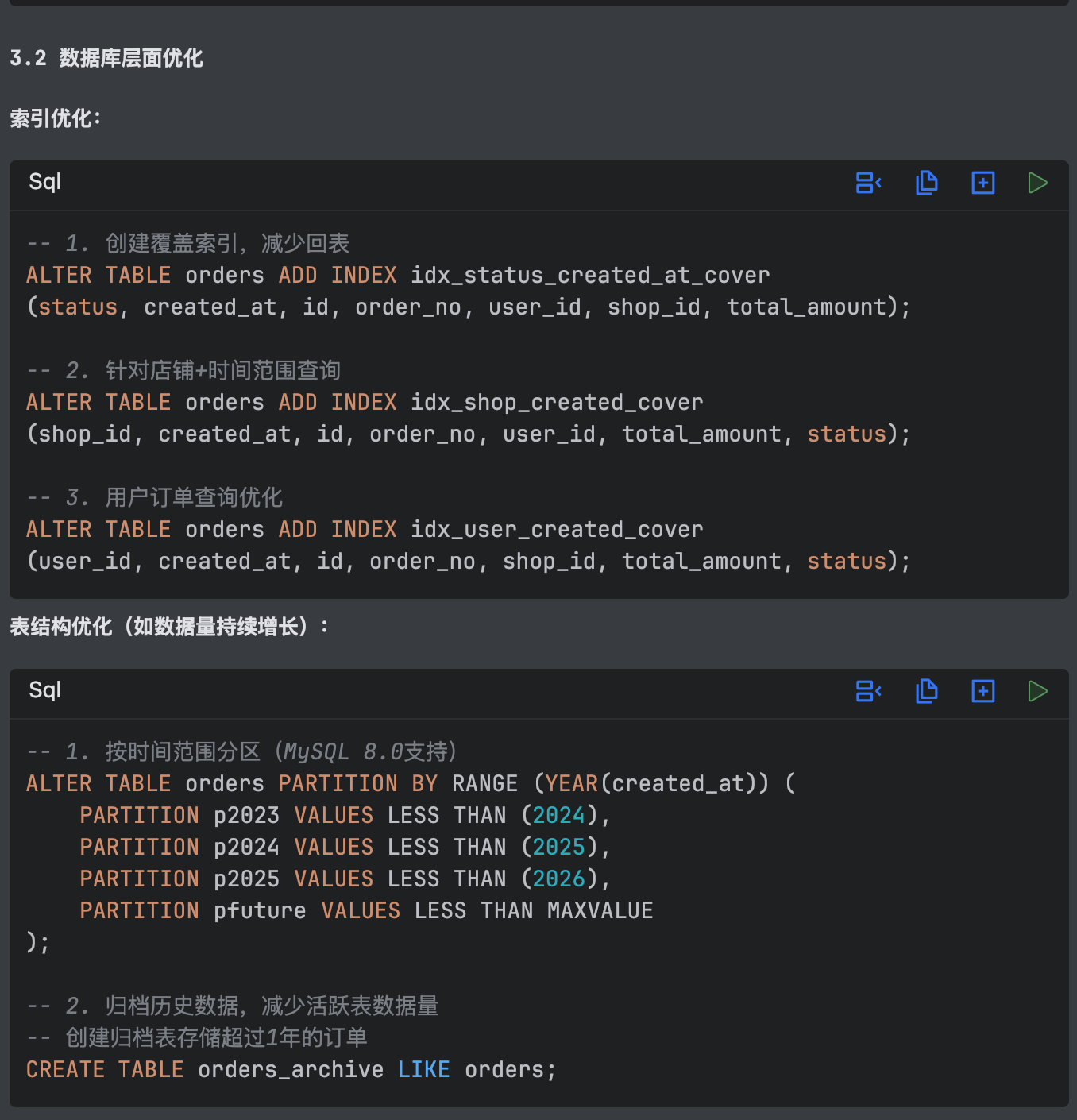
1. 实施延迟关联查询策略,重构深分页查询逻辑
2. 根据索引建议创建优化索引结构
3. 编写单元测试,覆盖核心功能点,建立性能基准
2
3
4
5
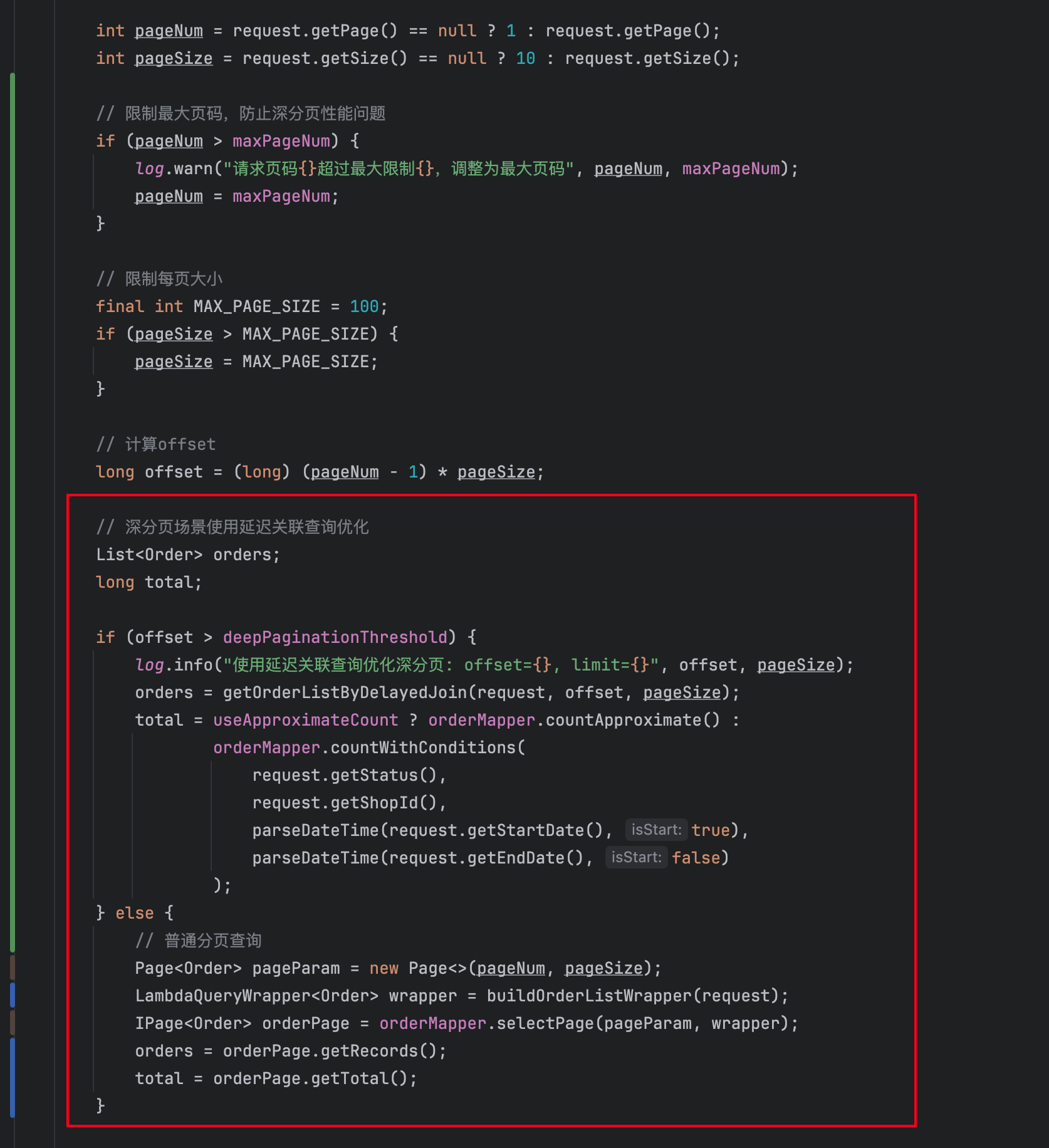
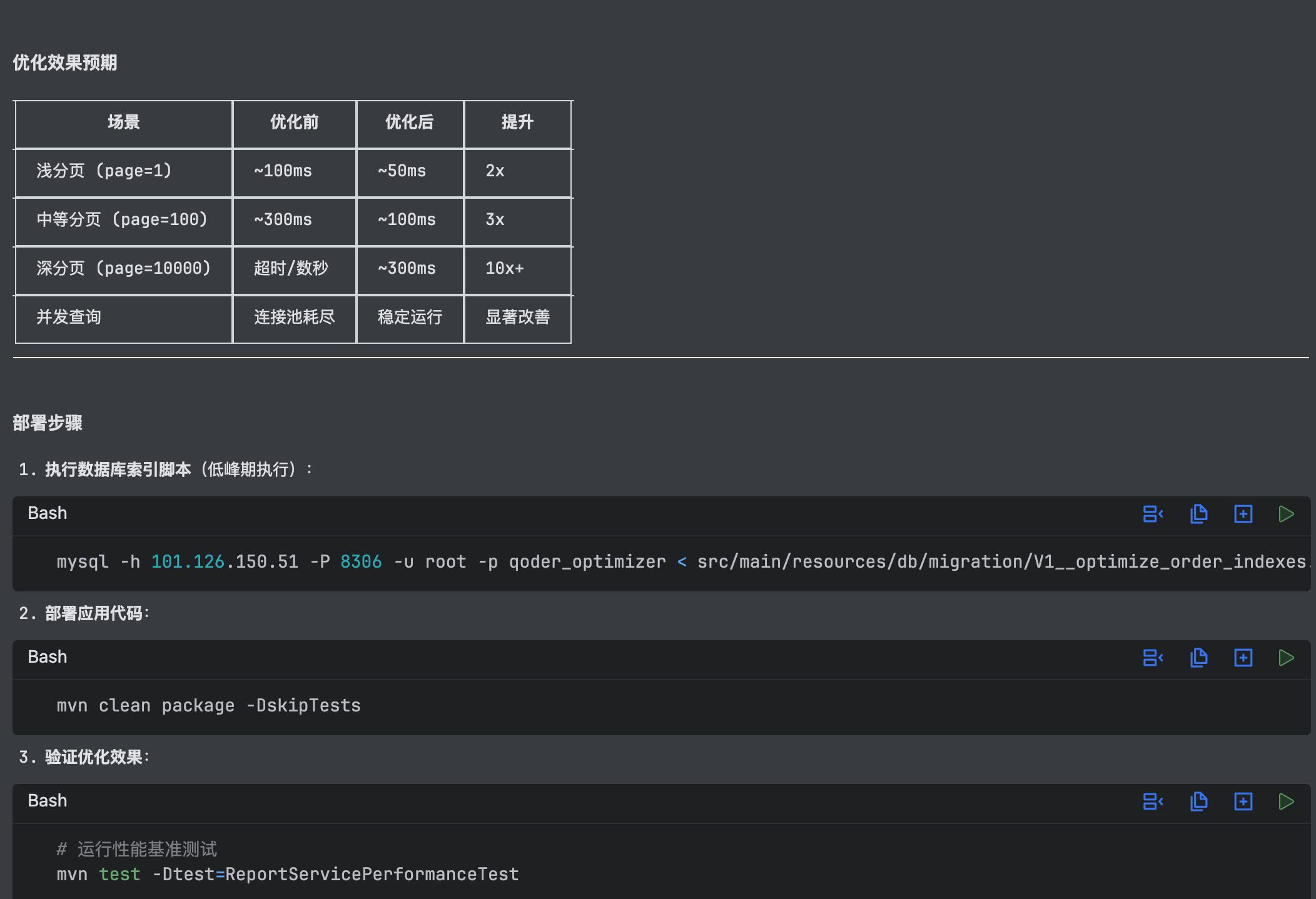
Qoder 完成实施后,getOrderList 方法的改造:
- 结合生产故障,完成最大页码配置和逻辑限制
- 按不同策略完成分页统计和列表查询
代码风格符合《阿里巴巴 Java 开发手册》最佳实践:
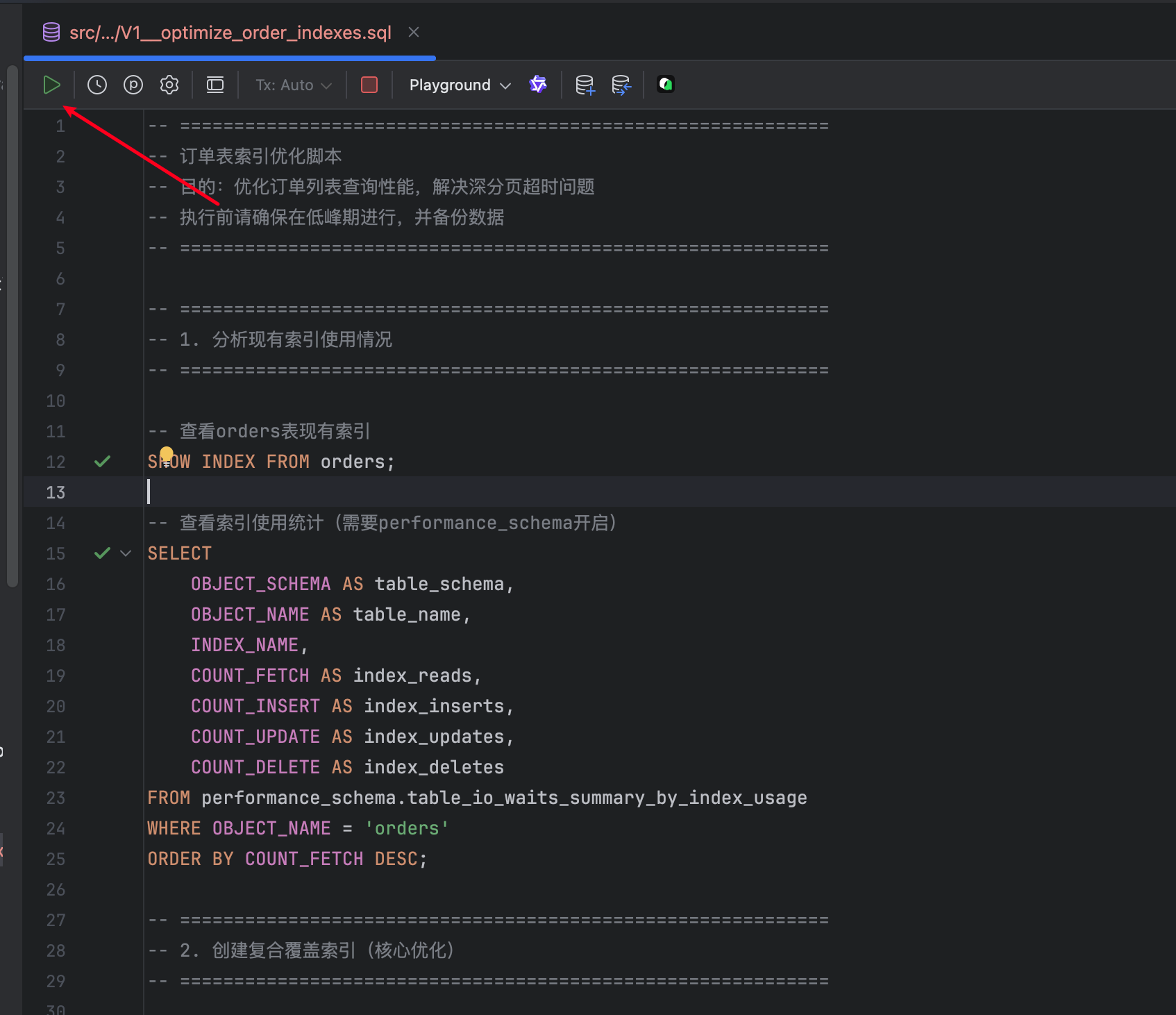
索引脚本可直接在 IDE 中执行,整个工作流无需切换窗口:
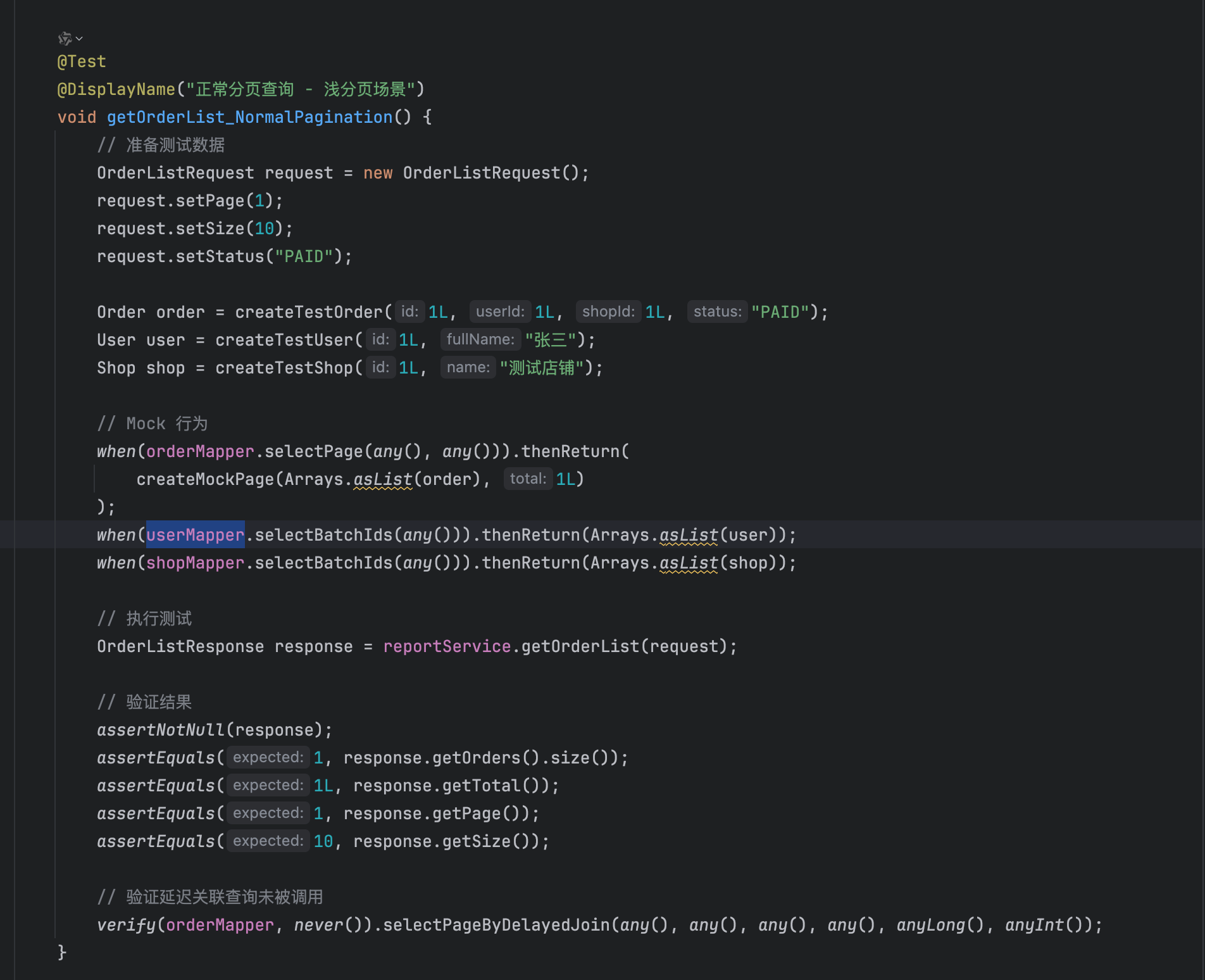
回归测试:Qoder 完成代码分支梳理,并针对不同场景生成单元测试:
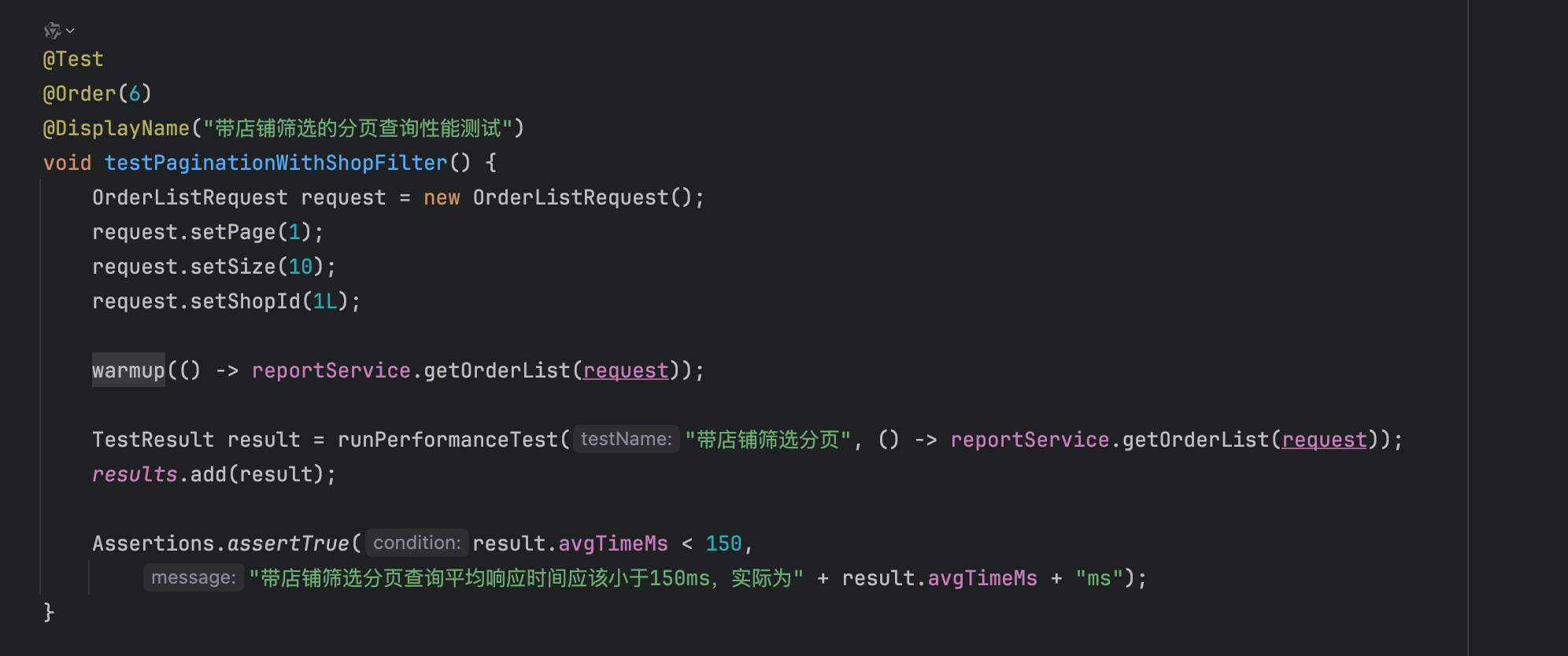
压测环节:Qoder 完成了所有压力测试编写,并很好地完成了代码预热,编译优化为机器码,尽可能贴合生产实际运行情况:
最后,Qoder 输出了完整的工作总结,包括技术方案和沟通汇报建议:
在代码提交窗口点击 Qoder,自动生成本次提交说明。至此,不到 10 分钟完成了一个接口的优化工作。
# 任务二:祖传代码不敢动?2-3 天的工作,现在半天搞定
# 背景:一坨不敢动的"祖传代码"
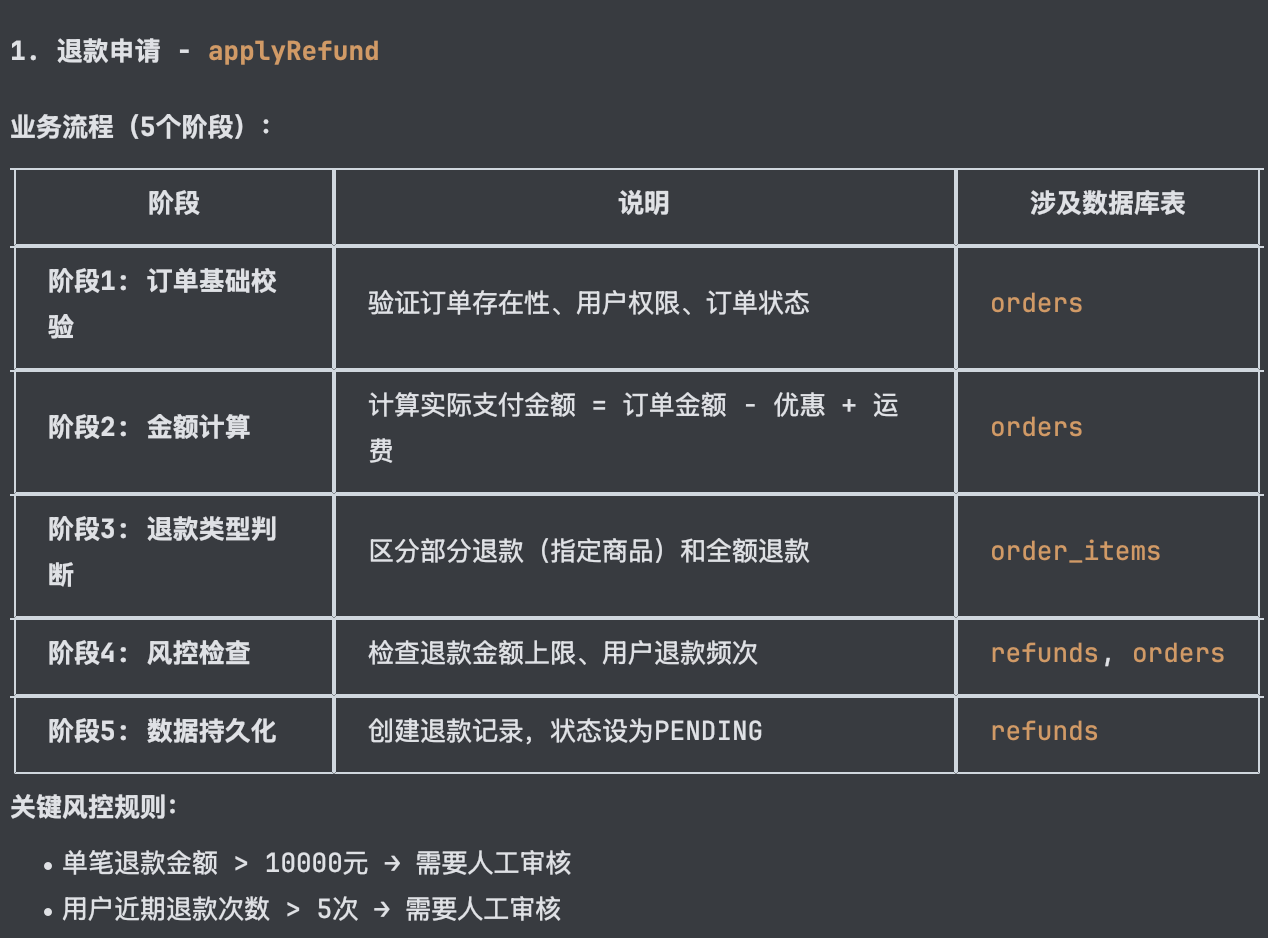
退款模块的 applyRefund 方法,150+ 行代码,无注释,魔法值遍地,重复逻辑冗余。新需求来了:新增风控规则——72 小时内存在未完成订单的用户禁止申请退款。
传统方式的困境:
- 代码逻辑复杂,不敢轻易改动(怕改崩)
- 新增规则需要全量回归测试
- 预估工作量:2-3 天
# Qoder 解法:重构 + 新功能 + 测试,一次完成
@Transactional
public RefundResponse applyRefund(RefundApplyRequest request) {
Order order = orderMapper.selectById(request.getOrderId());
// ⚠️ 状态值硬编码
if (!"PAID".equals(orderStatus) && !"SHIPPED".equals(orderStatus)) {
return RefundResponse.fail("订单状态不允许退款");
}
// ⚠️ 金额计算逻辑散落各处
BigDecimal paidAmount = order.getTotalAmount();
if (order.getDiscountAmount() != null) {
paidAmount = paidAmount.subtract(order.getDiscountAmount());
}
// ⚠️ 魔法数字:10000
if (request.getRefundAmount().compareTo(new BigDecimal("10000")) > 0) {
return RefundResponse.fail("退款请求存在风险,请联系客服");
}
// ⚠️ 魔法数字:5,且这段逻辑在部分退款和全额退款中重复出现
if (recentRefundCount > 5) {
return RefundResponse.fail("退款请求存在风险,请联系客服");
}
// ... 还有 100+ 行类似逻辑
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 逻辑梳理:让 Agent 替你读懂祖传代码
有了 Qoder JetBrains 插件后,借助其背后模型强大的算力和上下文推理能力,以及 Agent 的任务规划与执行能力,我们可以让其完成业务功能的阅读并重构,改善既有代码:
请结合一个简单的数据流,详细介绍退款申请的完整业务流程,并在代码中补充相应注释
为了保证 Agent 输出的准确性,我们还是把存量的 Schema 作为上下文提交给 Qoder JetBrains 插件,让其智能体模式完成任务:

Qoder 插件收到任务后,从整体概述开始,通过逐个分支梳理注释的方式执行任务:
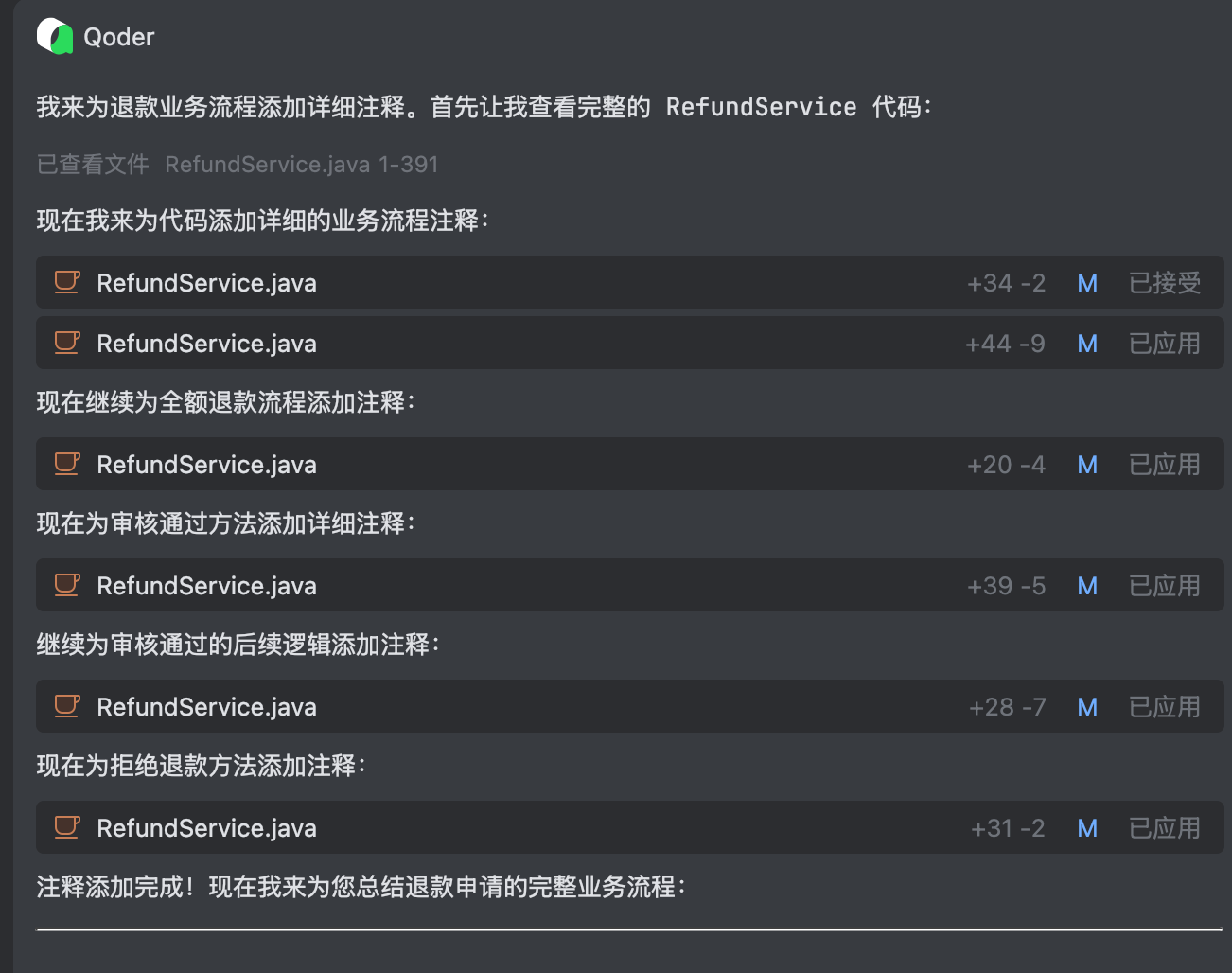
对应注释代码如下,非常整洁清晰,结合 Agent 给出的数据流,我们稍加调测就可以快速完成逻辑梳理:
任务结束后,Qoder 总是会进行摘要总结,可以看到它非常清晰地归纳了接口逻辑和特殊规则点:
# 代码重构:增量重构,安全可控
通过上述步骤,我们准确完成了退款申请的业务流程梳理。按照以往的经验主义,如果代码清晰且可运行的情况下,笔者一般不会进行重构,原因也很简单:在开发周期紧凑的情况下,无法快速完成逻辑梳理与重构后的回归。
但现在有了 Qoder JetBrains 插件——一个上下文推理和算力都非常强大的编程助手。
结合上述的逻辑梳理和对齐,我们下达第二条指令,完成功能重构与回归,提升代码可维护性的同时,为后续业务功能迭代做铺垫:
请按照《阿里巴巴 Java 开发手册》中的编码规范、命名约定、异常处理及安全规范,结合《重构:改善既有代码的设计》中提出的代码重构原则与方法,对退款申请功能模块进行系统性重构。完成重构后,需编写全面的单元测试、集成测试及功能测试,覆盖所有业务逻辑分支与边界条件,确保重构前后功能一致性及系统稳定性,实现 100% 的逻辑回归验证。
在此期间,Qoder 插件依次完成:
- 目标文件查看:定位重构代码段
- 代码问题分析:指出魔法值、重复代码、方法过长以及重构原则性错误
- 系统重构:依次完成常量创建、重复代码提取、领域建模设计和职责分离等工作
- 编写测试代码完成逻辑回归
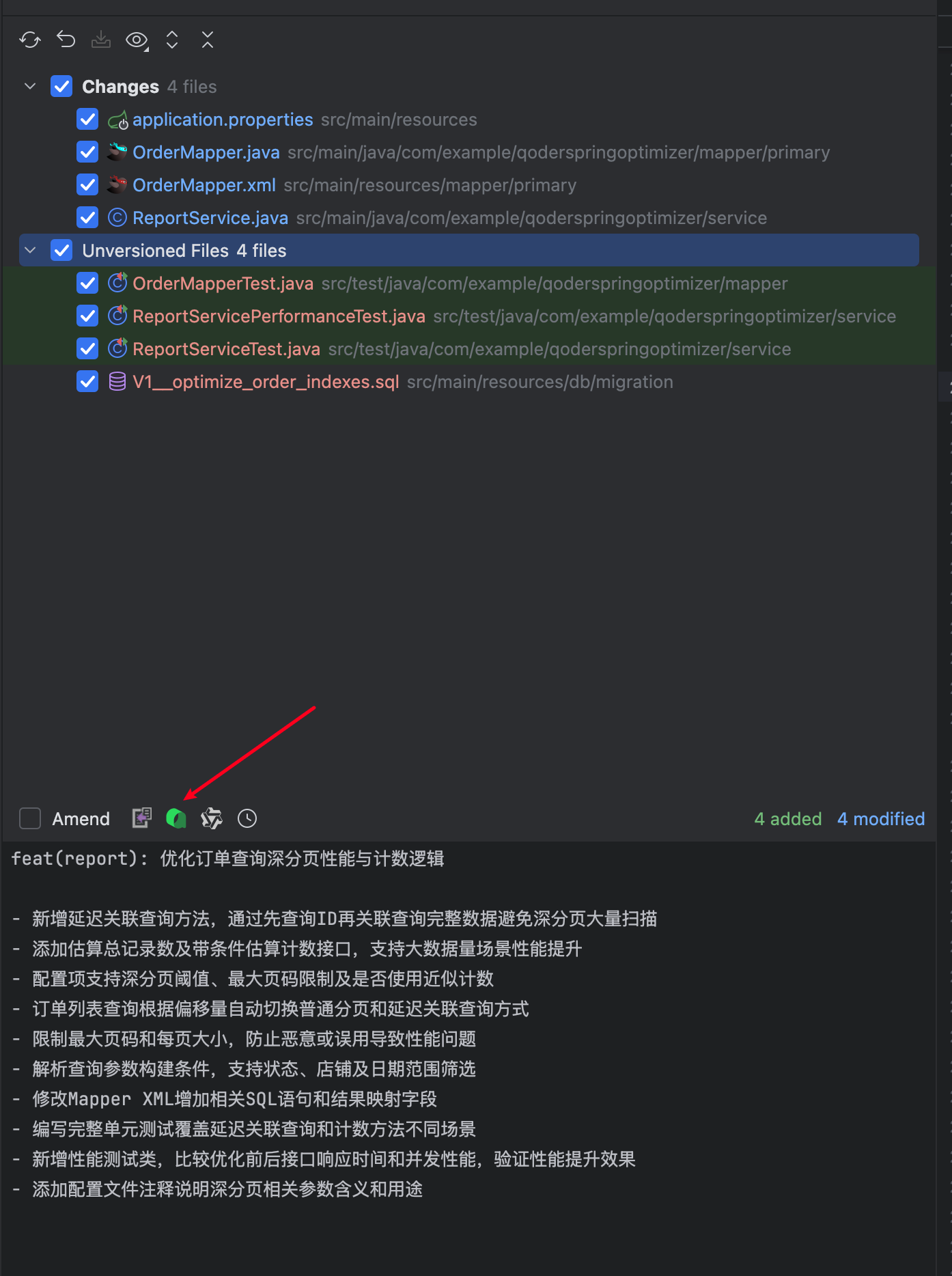
最终完成后的代码如下。在进行 diff 审核 Qoder 代码过程中,笔者发现 Qoder 非常老道的一点:它的重构工作并非在既有文件基础上进行大刀阔斧的修改,而是创建一个全新的 RefundServiceRefactored,采用安全重构策略:
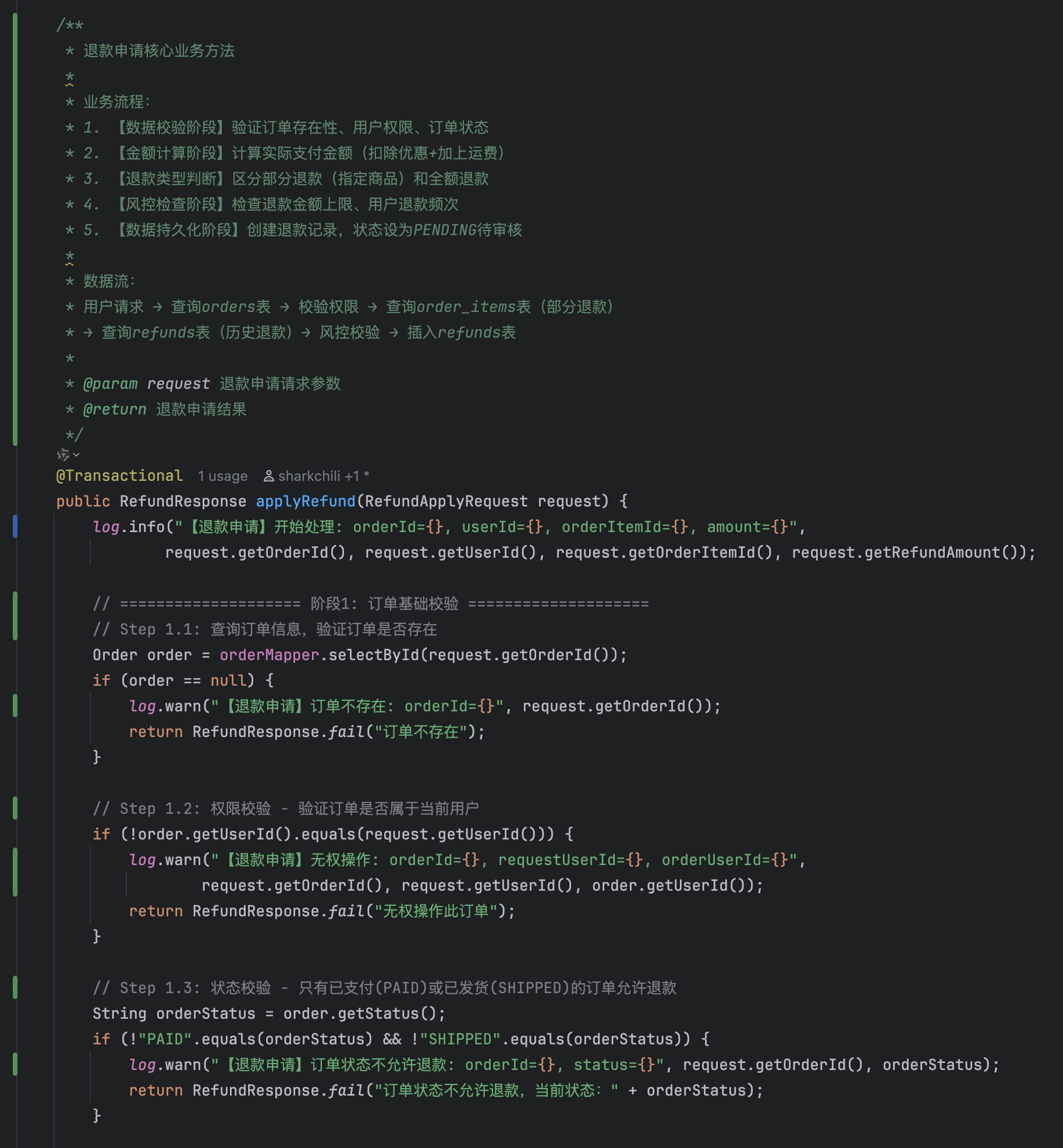
/**
* 退款申请(重构后)
*
* @param request 退款申请请求
* @return 退款申请结果
*/
@Transactional(rollbackFor = Exception.class)
public RefundResponse applyRefund(RefundApplyRequest request) {
log.info("【退款申请】开始处理: orderId={}, userId={}, amount={}",
request.getOrderId(), request.getUserId(), request.getRefundAmount());
// 1. 查询并校验订单
Order order = getAndValidateOrder(request.getOrderId(), request.getUserId());
// 2. 判断退款类型并处理
if (request.getOrderItemId() != null) {
return processPartialRefund(request, order); // 部分退款
} else {
return processFullRefund(request, order); // 全额退款
}
}
/**
* 处理部分退款
*/
private RefundResponse processPartialRefund(RefundApplyRequest request, Order order) {
log.info("【退款申请】处理部分退款: orderItemId={}", request.getOrderItemId());
// 查询并校验订单明细
OrderItem orderItem = orderItemMapper.selectById(request.getOrderItemId());
refundValidator.validateOrderItemBelongsToOrder(orderItem, order.getId());
// 校验退款数量与金额
Integer refundQuantity = getRefundQuantity(request.getQuantity());
refundValidator.validateRefundQuantity(refundQuantity, orderItem.getRefundableQuantity());
BigDecimal itemRefundableAmount = refundCalculator.calculateItemRefundableAmount(orderItem, refundQuantity);
refundValidator.validateRefundAmount(request.getRefundAmount(), itemRefundableAmount);
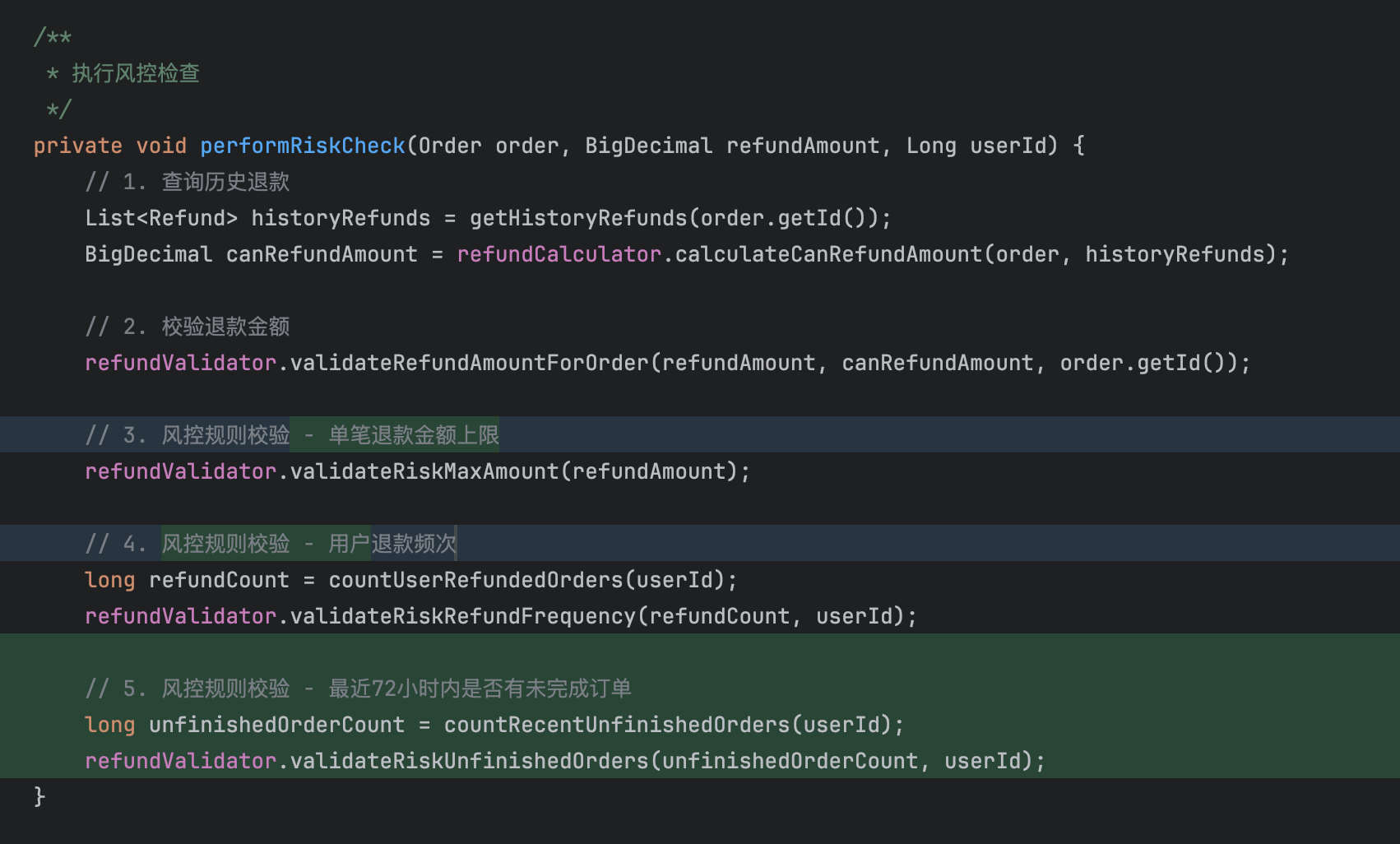
// 执行风控检查 + 创建退款记录
performRiskCheck(order, request.getRefundAmount(), request.getUserId());
Refund refund = createRefundRecord(request, order, refundQuantity);
log.info("【退款申请】部分退款成功: refundId={}", refund.getId());
return RefundResponse.success(refund.getId());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
重构亮点:
| 亮点 | 说明 |
|---|---|
| 方法拆分 | 主方法仅 15 行,部分退款/全额退款逻辑分离 |
| 职责分离 | refundValidator、refundCalculator 独立处理校验与计算 |
| 注释清晰 | 每个步骤标注明确,一目了然 |
| 日志规范 | 使用【】标注关键节点,便于追踪 |
| 异常处理 | rollbackFor = Exception.class 确保事务回滚 |
这里笔者也贴出 Qoder 工作过程中自动进行单元测试验收的过程,非常高效地完成了 80% 既有逻辑的分支覆盖:

# 功能迭代:一行指令,规则上线
有了这样一套简洁的代码之后,既有业务迭代就变得非常轻松。我们很快定位到了风控的逻辑代码段 validateRiskMaxAmount,对 Qoder 下达最后一条指令:
在风控系统中新增一条退款限制规则:当用户在最近 72 小时(3 天)内存在任何未完成状态的订单记录时,系统应自动拒绝该用户提交的退款申请。
对应实现代码如下。可以看到,结合 Qoder 强大的上下文推理能力和任务执行质量,完成既有逻辑的梳理后,职责单一的校验框架和配套的单元测试已经就位,后续的增量迭代也变得易于处理和回归:
# 记忆沉淀:越用越懂你的编程习惯
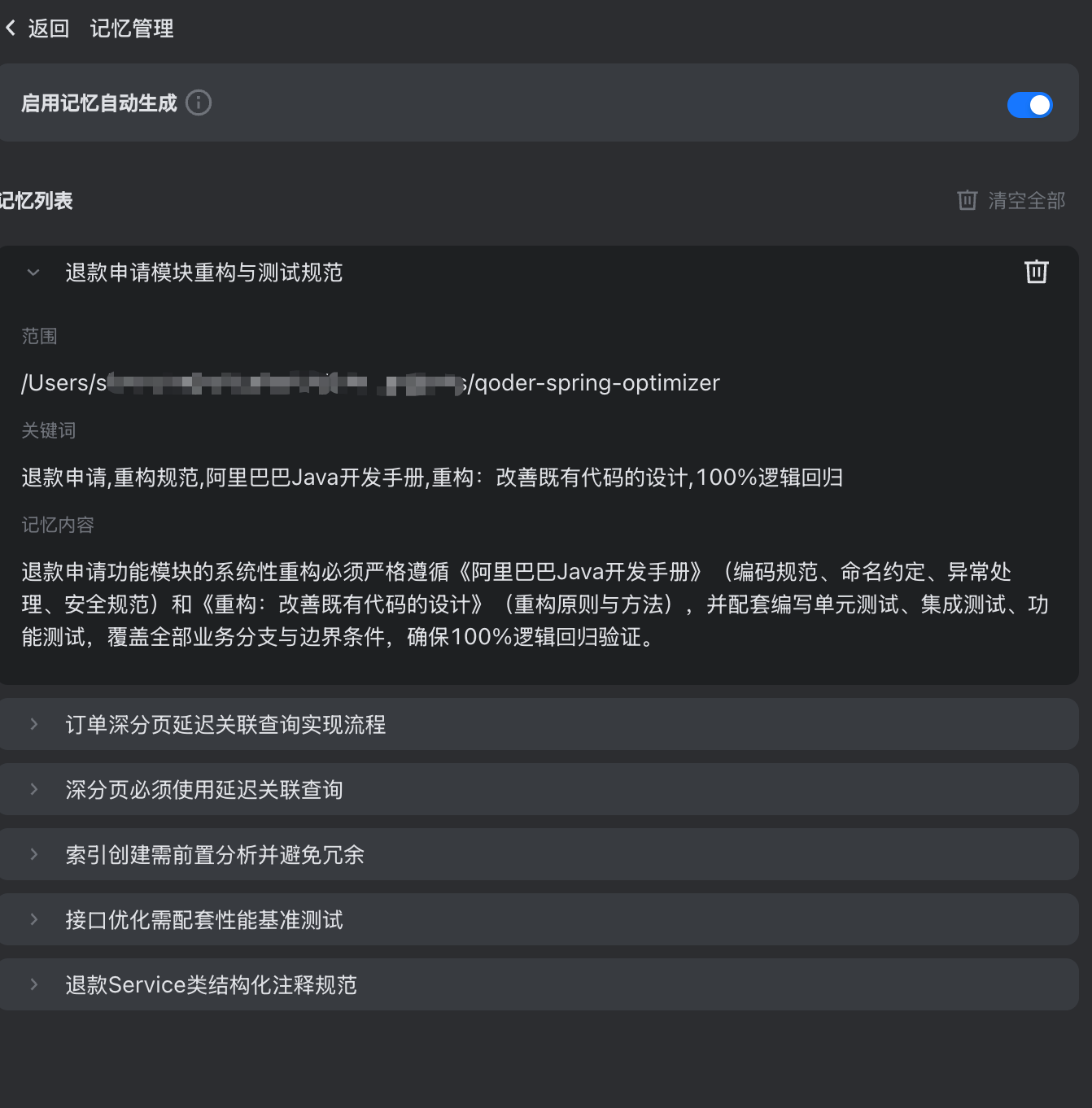
完成任务后,为了印证官方所说的 Qoder JetBrains 插件会自动形成针对个人编码习惯、项目特点、常见问题的记忆,笔者通过插件右上角查看这一轮对话的记忆信息,如预期看到了几条不错的摘要信息:
- 订单延迟分页:因为笔者在写提示词的过程中,明确提出选用延迟分页而非游标分页这种影响用户体验的方案,所以 Qoder 将其作为项目特点记忆下来
- 接口优化需配套性能测试:因为笔者在接口优化的过程中提出压测回归,所以 Qoder 也很好的将这点作为记忆保留下来
其中最让笔者惊喜的是,Qoder 考虑到订单退款功能的重要性,在记忆列表中明确记录了笔者与其交互的理念和规范。这使得后续的增量迭代时,只要 Qoder 能够准确将这份记忆召回,退款核心功能的维护就会随着迭代愈发从容:
# 能力拆解:Qoder 在这个示例中做了什么
通过上述两个实战案例,我们可以清晰地看到 Qoder JetBrains 插件如何在实际开发 workflow 中发挥价值。下面从四个维度拆解其核心能力:
# 1. 工程感知与上下文理解
Qoder 展现出了对大型工程项目的深度理解能力:
数据库 Schema 感知:在任务一中,Qoder 结合
@database上下文,精准分析了订单表结构、索引情况与查询模式,给出了覆盖索引优化建议。这种能力使得 AI 不再是"盲人摸象",而是基于真实的数据库状态做出决策。代码逻辑溯源:在任务二中,面对没有任何注释的冗长退款代码,Qoder 通过静态分析快速梳理出业务流程:订单校验 → 金额计算 → 风控检查 → 数据持久化,并准确识别出重复代码、魔法值等代码坏味道。
跨文件关联:Qoder 能够自动感知任务所需的关联文件,如从
RefundService自动追踪到OrderMapper、RefundValidator等依赖组件,无需开发者手动添加上下文。
# 2. 端到端的任务执行能力
Qoder 不是简单的代码补全工具,而是能够完成从分析到落地的完整闭环:
| 能力维度 | 具体表现 | 效果量化 |
|---|---|---|
| 工程感知 | 自动分析数据库 Schema、代码依赖关系 | 减少 80% 上下文切换 |
| 端到端执行 | 分析→设计→编码→测试→验收完整闭环 | 接口优化从 1 天 → 10 分钟 |
| 渐进重构 | 增量式重构,保留原有代码 | 重构风险降低 90% |
| 记忆学习 | 自动沉淀项目规范与编码习惯 | 后续迭代效率提升 50%+ |
这种端到端的能力让开发者从繁琐的实现细节中解放出来,专注于更高层次的决策与验收。
# 3. 渐进式重构与增量迭代
Qoder 在任务二中展现了一个非常老道的工程实践:渐进式重构而非大爆炸式重写。
增量式重构:Qoder 没有直接修改原有的
RefundService,而是创建了全新的RefundServiceRefactored类,通过增量方式完成重构。这种方式的优势在于:- 保留原有代码作为备份,降低重构风险
- 便于 A/B 测试和灰度发布
- 新功能直接在重构后的代码上迭代
职责分离:Qoder 按照单一职责原则(SRP),将原本混杂在一起的校验逻辑、金额计算、单号生成抽离到独立组件:
RefundValidator:统一业务校验RefundCalculator:金额计算逻辑RefundNoGenerator:退款单号生成
防御性编程:在重构过程中,Qoder 自动添加了空指针检查、边界条件处理等防御性代码,提升了系统的健壮性。
# 4. 记忆感知与持续学习
在任务完成后,Qoder 自动形成了针对该项目的记忆:
- 项目特点记忆:延迟关联查询优于游标分页、接口优化需配套性能测试
- 编码规范记忆:遵循《阿里巴巴 Java 开发手册》、BigDecimal 使用
compareTo比较 - 业务规则记忆:退款风控规则(72 小时未完成订单拦截、单笔金额上限等)
这些记忆会在后续交互中被自动召回,让 AI 的建议越来越精准,实现"越用越懂你"的效果。
# 总结:与 Qoder 一起,成为更好的工程师
Qoder JetBrains 插件为后端开发者提供了一种全新的工作范式:在保持 JetBrains IDE 使用习惯的同时,充分利用 AI Agent 的推理分析与编码落地能力。
通过本文的两个实战案例,我们可以看到:
| 维度 | 传统方式 | Qoder 辅助 |
|---|---|---|
| 效率 | 接口优化 1 天,重构 2-3 天 | 30-50 分钟完成 |
| 质量 | 依赖个人经验,容易遗漏 | 系统性重构 + 全面测试覆盖 |
| 体验 | 多工具切换,心流频繁打断 | 一个窗口,心流专注 |
| 成长 | 重复劳动,知识难以沉淀 | 自动记忆,越用越懂你 |
Qoder 不是来取代工程师的,而是来放大工程师价值的。
它帮你把重复性、机械性的工作自动化——写样板代码、跑回归测试、整理 Commit Message——让你把省下来的时间,投入到更有价值的事情上:系统架构设计、业务抽象、技术选型。
正如本文案例所示:
- 原本需要一天的接口优化,现在 30 分钟完成,省下的时间可以用来做更深入的压测分析
- 原本不敢动的祖传代码,现在可以从容重构,省下的时间可以用来完善监控和告警
AI 时代,工程师的核心竞争力不再是"写代码的速度",而是问题定义能力、架构设计能力、质量判断能力。Qoder 帮你打好脚手架,但大楼的设计图,永远在你手中。
# 写在最后:AI 时代的工程师自我修养
在本文即将收尾之际,笔者想分享一些关于 AI 时代工程师成长的个人思考。
现在的技术环境很像是在盖大楼。AI 和新框架帮你把脚手架搭得飞快,而且像 Qoder 这样的插件让你在熟悉的 IDE 环境中就能完成这一切,无需切换窗口打断思路。但如果你缺乏底层原理知识和优秀的软件架构设计思维,即使 AI 能帮你完成各种功能的落地,你也无法合理把控系统的交付质量。
回顾本文的两个案例,你会发现 Qoder 的每一次出色表现,背后都有笔者对经典软件工程理论的理解在引导和验收:
任务一中的延迟关联查询,是笔者基于对数据库索引原理的理解,才能判断 Qoder 给出的方案是否合理。正如《高性能 MySQL》所强调的:"理解索引是如何工作的,是优化查询性能的基础。"
任务二中的代码重构,是笔者熟悉《重构:改善既有代码的设计》和《阿里巴巴 Java 开发手册》中的 SRP、DRY 等原则,才能准确评估 Qoder 重构的质量,并识别出潜在的改进空间。
性能基准测试中的 JIT 预热,是笔者对 JVM 底层执行机制的把握。正如《深入理解 Java 虚拟机》所阐述的:HotSpot 虚拟机通过分层编译和热点代码探测,将字节码逐步优化为本地机器码——不了解这一点,性能测试的数据就可能失真。
方案选择与权衡,更是笔者对业务场景和技术边界的把握。比如选择延迟关联查询而非游标分页,是因为后者会影响用户体验——这种判断,AI 无法替你做。
因此,在享受 Qoder 带来的沉浸式开发体验和效率红利的同时,笔者想给读者三点建议:
保持对底层原理的敬畏:数据库索引、JVM 内存模型、并发编程原理——这些"地基"知识不会因 AI 而贬值,反而会更加珍贵。
阅读经典书籍:《重构》《设计模式》《高性能 MySQL》《深入理解 Java 虚拟机》——这些经典帮助你建立判断 AI 输出质量的"标尺"。
培养架构思维:把省下来的时间投入到对系统架构、业务本质的思考上,这才是 AI 时代工程师的核心竞争力。
正如 Robert C. Martin 所言:"学会编写整洁的代码是一项艰苦的工作。它需要的不仅仅是原则和模式的知识。你必须为之付出汗水,必须亲自实践并目睹自己的失败,必须观察他人的实践与失败。"
软件设计的认知提升没有捷径,需要持续的学习与实践。愿我们都能在这个 AI 飞速发展的时代,既善用工具提升效率,也不忘夯实基础、提升认知,成为真正的**"建筑师",而非仅仅是"脚手架工人"**。
如果你也是 JetBrains IDE 的忠实用户,不妨尝试一下 Qoder JetBrains 插件。笔者用下来感觉非常顺手——在熟悉的 IDE 环境里,一个窗口搞定所有工作,心流不打断,效率翻倍。
