 聊聊我说如何用go语言实现redis列表操作
聊聊我说如何用go语言实现redis列表操作
# 写在文章开头
redis的列表支持尾部push和头部pop操作,基于这两个操作我们就可以实现一个简单的队列,所以本文将讲解笔者如何在mini-redis中复刻redis几条列表操作指令从而实现一个简单的无界队列。这里需要补充的是,因为笔者实现的mini-redis是采用go语言实现,为了保证逻辑上的精简更专注于复刻redis的设计理念,笔者底层所实现的列表并没有像原生redis那样基于长度在压缩列表也和双向链表中精准变换,而是统一采用双向链表实现。
mini-redis地址:https://github.com/shark-ctrl/mini-redis (opens new window)
Hi,我是 sharkChili ,是个不断在硬核技术上作死的技术人,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。

# 详解用手写列表指令完成队列操作
# rpush尾部追加
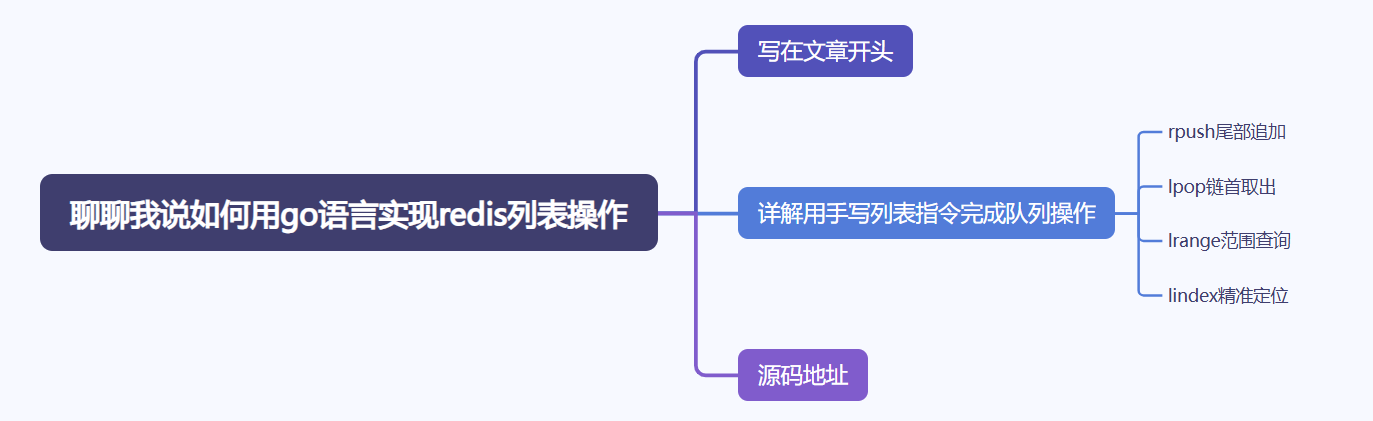
rpush指令就是将元素插入到链表的右端,如果我们想基于redis的列表实现队列,就可以用这条指令实现入队操作,相应的我们给出rpush的操作指令示例:
rpush list a 1
这条指令的含义就是依次将字符串a和数字1插入的链表的右端,redis服务端在解析这条指令时对应的步骤为:
- 查看
list的key是否存在,如果存在则判断这个key是否为链表,如果不是则抛出异常,若不存在则在后续的操作中初始化链表。 - 从a开始遍历元素,因为a是字符串,所以就将其转为字符串类型的redis对象。
- 遍历到1发现是数字,则查看是否大于0且小于
10000,如果符合要求则从redis提前分配好的常量池中取出对应数值对象完成参数封装。 - 将封装成redis对象的a和1存入
list队列中。
对此笔者给出mini-redis的实现,可以看到rpush指令对应的函数为rpushCommand,它会传入客户端指针,该指针所指向的对象我们可以从中获取到要求添加的参数信息,而rpushCommand内部则是调用pushGenericCommand方法,通过REDIS_TAIL标识实现元素追加到链表末端:
func rpushCommand(c *redisClient) {
/**
pass in the REDIS_TAIL flag to indicate that
the current element should be appended to the tail of the list.
*/
pushGenericCommand(c, REDIS_TAIL)
}
2
3
4
5
6
7
步入pushGenericCommand即可看到列表判空、类型判断、元素类型转换、最后再存入链表的操作:
func pushGenericCommand(c *redisClient, where int) {
//check if the corresponding key exists.
i := lookupKeyWrite(c.db, c.argv[1])
var lobj *robj
//if the key exists, then determine if it is a list.
//if it is not, then throw an error exception.
if *i != nil && (*i).(*robj).encoding != REDIS_ENCODING_LINKEDLIST {
addReply(c, shared.wrongtypeerr)
return
} else if *i != nil { //if it exists and is a list, then retrieve the Redis object for the list.
lobj = (*i).(*robj)
}
//foreach element starting from index 2.
var j uint64
for j = 2; j < c.argc; j++ {
//call `tryObjectEncoding` to perform special processing on the elements.
c.argv[j] = tryObjectEncoding(c.argv[j])
/**
If the list is empty, then initialize it, create it, and store it in the Redis database.
*/
if lobj == nil {
lobj = createListObject()
dbAdd(c.db, c.argv[1], lobj)
}
/**
pass in the list pointer, element pointer,
and add flag to append the element to the head or tail of the list.
*/
listTypePush(lobj, c.argv[j], where)
}
//return the current length of the list.
addReplyLongLong(c, (*lobj.ptr).(*list).len)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
为了逻辑的完整性,笔者这里也给出了编码转换的方法tryObjectEncoding,该方法如果发现元素可以转为整数则会按照数值范围从常量池或者手动的方式完成元素对象编码的转换,具体逻辑为:
- 如果在0~10000则从
shared.integers这个常量数组中获取。 - 不在上述范围则手动转为整数并修改编码类型为
REDIS_ENCODING_INT。
func tryObjectEncoding(o *robj) *robj {
var value int64
var s string
var sLen int
//get string value and length
s = (*o.ptr).(string)
sLen = len(s)
/**
If it can be converted into an integer and is between 0 and 10000,
it is obtained from the constant pool.
*/
if sLen < 21 && string2l(&s, sLen, &value) {
if value >= 0 && value < REDIS_SHARED_INTEGERS {
return shared.integers[value]
} else {
/**
If it is not within the scope of constant pool,
it will be manually converted into an object of integer encoding type.
*/
o.encoding = REDIS_ENCODING_INT
num := interface{}(value)
o.ptr = &num
}
}
return o
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# lpop链首取出
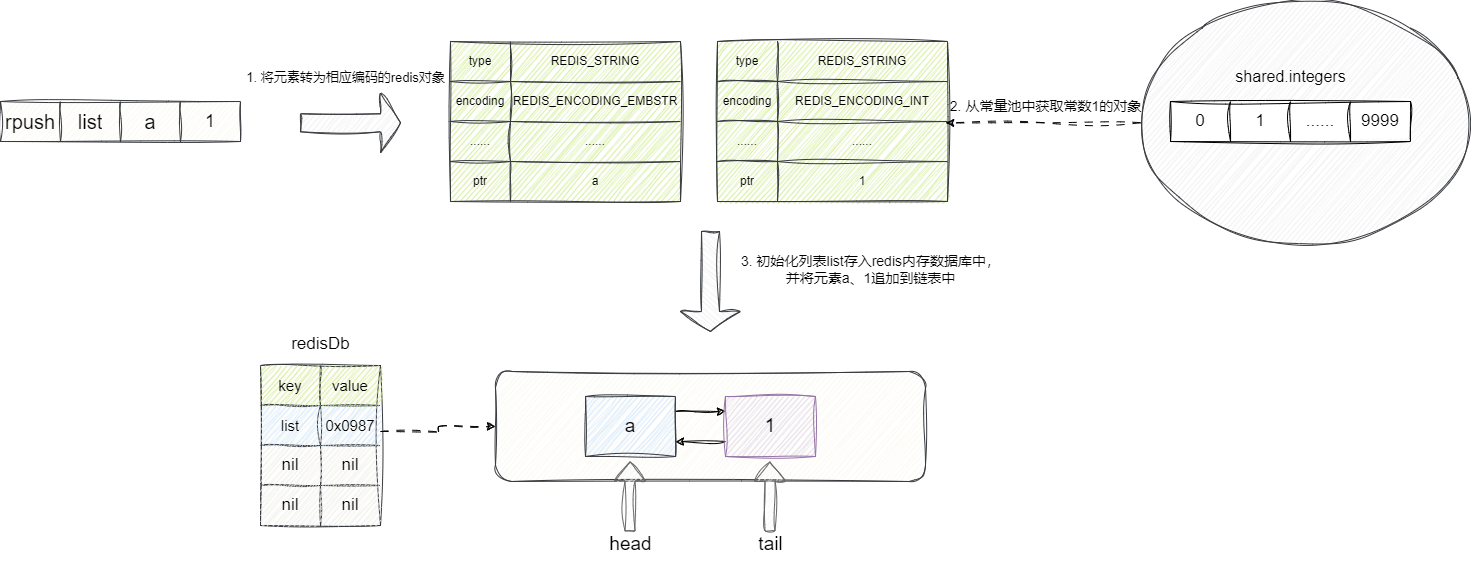
完成了尾部追加的动作之后,我们就可以继续实现头部取出的指令lpop来模拟队列出队,整体逻辑为:
- 查看传入的
key是否存在,如果存在则判断类型是否为链表,如果不是则抛出异常。 - 从列表中获取元素的值。
- 将该元素从链表从移除。
- 如果链表为空则将链表从
redis内存中删除。 - 返回头节点值。
对此我们给出lpop指令的实现方法lpopCommand,可以看到其内部传入REDIS_HEAD给popGenericCommand告知要抛出链表首部元素:
func lpopCommand(c *redisClient) {
// params is REDIS_HEAD, which means to retrieve the head element.
popGenericCommand(c, REDIS_HEAD)
}
2
3
4
而内部获取链表头部元素就是我们所说的:
- 查询链表是否存在。
- 如果存在对类型进行校验,
- 根据
where标识获取链表首或者尾部的元素。 - 返回链表取出的元素给客户端。
- 判断此时链表是否为空,若为空则删除redis数据库中的链表。
func popGenericCommand(c *redisClient, where int) {
//check if the key exists, and if it doesn't, respond with an empty response.
o := lookupKeyReadOrReply(c, c.argv[1], shared.nullbulk)
r := (*o).(*robj)
//If the type is not a linked list, throw an exception and return.
if o == nil || checkType(c, r, REDIS_LIST) {
return
}
value := listTypePop(r, where)
//retrieve the first element of the linked list based on the WHERE identifier.
if value == nil {
addReply(c, shared.nullbulk)
} else {
/**
return the element value, and check if the linked list is empty.
If it is empty, delete the key-value pair in the Redis database.
*/
addReplyBulk(c, value)
if listTypeLength(r) == 0 {
dbDelete(c.db, c.argv[1])
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
因为笔者的列表是通过双向链表实现的,所以这里就给出REDIS_ENCODING_LINKEDLIST 编码的实现,链表的处理逻辑就是根据标识获取首或尾的节点,然后将该节点从链表中删除:
func listTypePop(subject *robj, where int) *robj {
var value *robj
if subject.encoding == REDIS_ENCODING_ZIPLIST {
//todo
} else if subject.encoding == REDIS_ENCODING_LINKEDLIST {
lobj := (*subject.ptr).(*list)
var ln *listNode
//get the head or tail element based on the linked list identifier.
if where == REDIS_HEAD {
ln = lobj.head
} else {
ln = lobj.tail
}
//read the value of the element and remove it from the linked list.
value = (*ln.value).(*robj)
listDelNode(lobj, ln)
} else {
log.Panic("Unknown list encoding")
}
return value
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# lrange范围查询
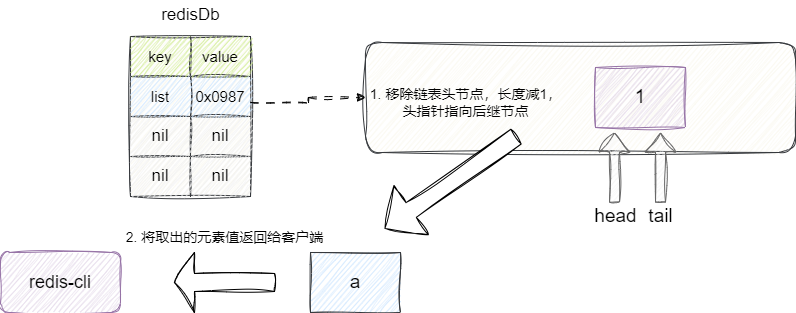
有了上述的操作指令我们就可以从链表中读取元素,如果我们希望读取链表中所有元素,我们可以键入下面这段lrange 指令:
lrange list 0 -1
该操作指明要查询的链表为list,从0开始获取到倒数第一个元素的元素,之所以-1可以理解为倒数第一个元素,因为lrange 对应的函数遇到end值为负数会让其加上链表长度。
假设我们链表长度为3,加上-1就得到2,最终得到的指令就等同于lrange list 0 2,由此就可以拿到链表中的所有元素:
基于这个思路我们给出lrangeCommand的实现,内部逻辑比较简单:
- 将索引2、3转为整数,获取查询的起止位置。
- 起止位置负数取正以及上限范围界定,例如end为-1则加上链表长度获取到最终的end值。
- 如果
start小于0则设置为0。 - 基于上述计算后对
start和end值进行边界值校验。 - 通过
start获取起始位置开始遍历指定范围内的元素范围。
func lrangeCommand(c *redisClient) {
var o *robj
var start int64
var end int64
var llen int64
var rangelen int64
/**
convert the strings at indexes 2 and 3 to numerical values.
If an error occurs, respond with an exception and return.
*/
if !getLongFromObjectOrReply(c, c.argv[2], &start, nil) ||
!getLongFromObjectOrReply(c, c.argv[3], &end, nil) {
return
}
/**
check if the linked list exists,
and if it doesn't, respond with a null value.
*/
val := lookupKeyReadOrReply(c, c.argv[1], shared.emptymultibulk)
o = (*val).(*robj)
/**
check if the type is a linked list; if it is not, return a type error.
*/
if o == nil || !checkType(c, o, REDIS_LIST) {
return
}
//get the start and end values of a range query. If they are negative, add the length of the linked list.
llen = (*o.ptr).(*list).len
if start < 0 {
start += llen
}
if start < 0 {
start += llen
}
if end < 0 {
end += llen
}
//if start is still less than 0, set it to 0.
if start < 0 {
start = 0
}
/**
check if start is greater than the length of the linked list or if start is greater than end.
If either of these exceptions occurs, respond with an error.
*/
if start >= llen || start > end {
addReplyError(c, shared.emptymultibulk)
return
}
//if end is greater than list length, set it to the list length.
if end > llen {
end = llen - 1
}
rangelen = end - start + 1
addReplyMultiBulkLen(c, rangelen)
if o.encoding == REDIS_ENCODING_ZIPLIST {
//todo
} else if o.encoding == REDIS_ENCODING_LINKEDLIST {
lobj := (*o.ptr).(*list)
node := listIndex(lobj, start)
//foreach the linked list starting from "start" based on "rangelen."
for rangelen > 0 {
rObj := (*node.value).(*robj)
addReplyBulk(c, rObj)
node = node.next
rangelen--
}
} else {
log.Panic("List encoding is not LINKEDLIST nor ZIPLIST!")
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
# lindex精准定位
当我们需要获取元素中某个索引位置元素时。就可以通过lindex指令,例如获取list第0个元素:
lindex list 0
实现精准定位的逻辑比较简单,将索引2的参数转为整数到链表中遍历获取到该索引位置元素返回即可,对应的笔者这里也给出的自己的实现:
- 查询列表是否存在。
- 索引2参数转整数。
- 调用
listIndex获取对应元素。 - 读取其
value值响应给客户端。
func lindexCommand(c *redisClient) {
/**
check if the linked list exists; if it doesn't, return empty.
*/
i := lookupKeyReadOrReply(c, c.argv[1], shared.nullbulk)
r := (*i).(*robj)
//verify if the type is a linked list.
if *i == nil || checkType(c, r, REDIS_LIST) {
return
}
if r.encoding == REDIS_ENCODING_ZIPLIST {
//todo
} else if r.encoding == REDIS_ENCODING_LINKEDLIST {
/**
retrieve the parameter at index 2 to obtain the index position,
then fetch the element from the linked list at that index and return it.
*/
lobj := (*r.ptr).(*list)
s := (*c.argv[2].ptr).(string)
idx, _ := strconv.ParseInt(s, 10, 64)
ln := listIndex(lobj, idx)
if ln != nil {
value := (*ln.value).(*robj)
addReplyBulk(c, value)
} else {
addReply(c, shared.nullbulk)
}
} else {
log.Panic("Unknown list encoding")
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# 源码地址
自此,笔者将个人开源项目mini-redis对于列表的核心指令复刻完成,希望对你阅读笔者的项目源码有帮助。
mini-redis地址:https://github.com/shark-ctrl/mini-redis (opens new window)
我是 sharkchili ,CSDN Java 领域博客专家,mini-redis的作者,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。 因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。

