 Elasticsearch核心原理与架构设计
Elasticsearch核心原理与架构设计
# 写在文章开头
在日常业务开发中,你是否遇到过这样的困扰:
- 当数据量达到千万甚至亿级别时,模糊查询变得异常缓慢,传统关系型数据库力不从心
- 分词器琳琅满目,IK、jieba、ansj...究竟该如何选择,它们底层有什么不同
- 为什么 Elasticsearch 能实现秒级返回,而你的 SQL 查询却要等待数秒
- 对
Lucene和Elasticsearch的关系一头雾水,不知道它们各自负责什么
本文将从 lucene 讲起,逐步深入 elasticsearch 的设计理念和工作机制:
- 理解倒排索引、term dictionary、posting list 等核心概念,这是 Lucene 的立身之本
- 探讨从正排索引到倒排索引的演进,以及如何通过排序和二分查找实现从线性扫描到对数级查询的性能跃升
- 看到单机索引如何走向分布式,理解 Sharding、Replication、Consistency 等机制背后的设计哲学
- 最终理解 Elasticsearch 为什么能够实现秒级全文检索
通过本文的学习,你将:
- 深入理解
Lucene的底层数据结构和工作原理 - 掌握倒排索引的设计思路和优化策略
- 理解从单机
lucene到分布式elasticsearch的演进逻辑 - 能够根据业务场景合理设计索引结构和选择分词策略
你好,我是 SharkChili ,Java Guide 核心维护者之一,对 Redis、Nightingale 等知名开源项目有深度源码研究经验。熟悉 Java、Go 等多语言技术栈,现任某知名黑厂高级研发。
🌟 开源项目贡献
- mini-redis:教学级 Redis 精简实现,助力分布式缓存原理学习
🔗 https://github.com/shark-ctrl/mini-redis (opens new window)(欢迎 Star & Contribute)
📚 公众号价值 分享企业级架构设计、性能优化、源码解析等核心技术干货,涵盖分布式系统、微服务治理、大数据处理等实战领域,并探索面向AI的vibe coding等现代开发范式。
👥 加入技术社群 关注公众号,回复 【加群】 获取联系方式,与众多技术爱好者交流分布式架构、微服务等前沿技术!
# Lucene 核心概念
# Lucene 如何实现快速检索
假设我们现在有如下简单示例数据:
hello world
Elasticsearch in action
redis in action
effective java
i am sharkchili
2
3
4
5
我们希望从中找到elasticSearch这个关键词的数据,若按照原有的关系型数据库查询思路,就需要遍历并逐一比对文本关键词才能获得目标文本。然而这种遍历查询效率很低。
考虑到查询效率,Lucene采用了空间换时间的思想,提出了类似字典目录的索引方案:以单词为单位生成多个词项,也就是term,以这些词项作为索引与文本id进行关联。查询时我们只需匹配到对应词项,即可快速定位到document_id。这就像查字典时,我们通过拼音索引(term)快速找到目标页码(document_id),而非MySQL查询那样退化为全表扫描。
基于这个document_id,我们又可以快速定位到对应的文本文档数据。需要补充的是,Lucene中,除了倒排索引外,还通过 stored fields 按需单独存储文档的原始字段值。当需要高性能获取特定字段时,可以将字段设置为 store: true,从 stored fields 中直接获取,而无需解析整个 _source。我们将倒排索引、stored fields 等数据结构组合在一起,就构成下图中这个便于检索的索引结构:
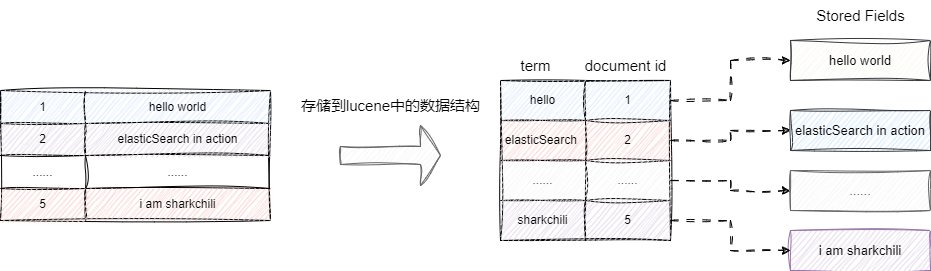
例如,当需要单独获取某篇文章的标题用于高亮展示时,可以将该字段设置为 store: true。
首先创建索引,在 mapping 中声明 title 字段需要单独存储:
curl -X PUT 'http://localhost:9200/blog_index' -H 'Content-Type: application/json' -d'
{
"mappings": {
"properties": {
"title": {
"type": "text",
"store": true
},
"content": {
"type": "text"
}
}
}
}'
2
3
4
5
6
7
8
9
10
11
12
13
14
然后插入一条文档测试数据:
curl -X POST 'http://localhost:9200/blog_index/_doc/1' -H 'Content-Type: application/json' -d'
{
"title": "Elasticsearch 入门教程",
"content": "本文介绍 Elasticsearch 的基本使用方法"
}'
2
3
4
5
搜索时,通过 stored_fields 参数可以直接获取标题,而无需解析整个 _source:
curl -X GET 'http://localhost:9200/blog_index/_search' -H 'Content-Type: application/json' -d'
{
"query": { "match": { "content": "Elasticsearch" } },
"stored_fields": ["title"]
}'
2
3
4
5
返回结果中,各字段含义如下:
| 字段 | 含义 |
|---|---|
took | 查询耗时(毫秒),本例耗时 47ms |
timed_out | 是否超时 |
_shards | 命中的分片信息,successful: 1 表示查询成功 |
hits.total.value | 匹配的文档数量 |
hits.max_score | 相关性得分最大值 |
hits.hits[*]._score | 当前文档的相关性得分 |
fields | 通过 stored_fields 参数获取的字段值 |
{
"took": 47, // 查询耗时 47ms
"timed_out": false, // 未超时
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1, // 匹配到 1 条文档
"relation": "eq"
},
"max_score": 0.2876821, // 最大相关性得分
"hits": [
{
"_index": "blog_index",
"_type": "_doc",
"_id": "1",
"_score": 0.2876821, // 该文档得分
"fields": {
"title": ["Elasticsearch 入门教程"] // 直接获取的 stored field
}
}
]
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 倒排索引:词项检索的基石
# 倒排索引核心概念
我们的文本远远不止这些词项,随着时间的推移需要维护的词项越来越多。当前场景下,我们查询词项时需要进行扫描遍历,平均时间复杂度为O(n)。于是Lucene提出将这些词项按照字典序从小到大进行排序,通过二分查找法将时间复杂度从O(n)提升为O(logN)。
我们整理一下这些概念:
- 排序的字典统称为
term dictionary - 字典匹配的文本文档统称为
posting list
这几个部分共同构成Lucene的核心——倒排索引(Inverted Index)
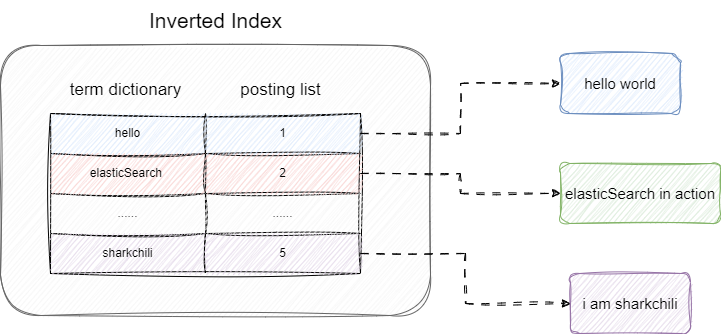
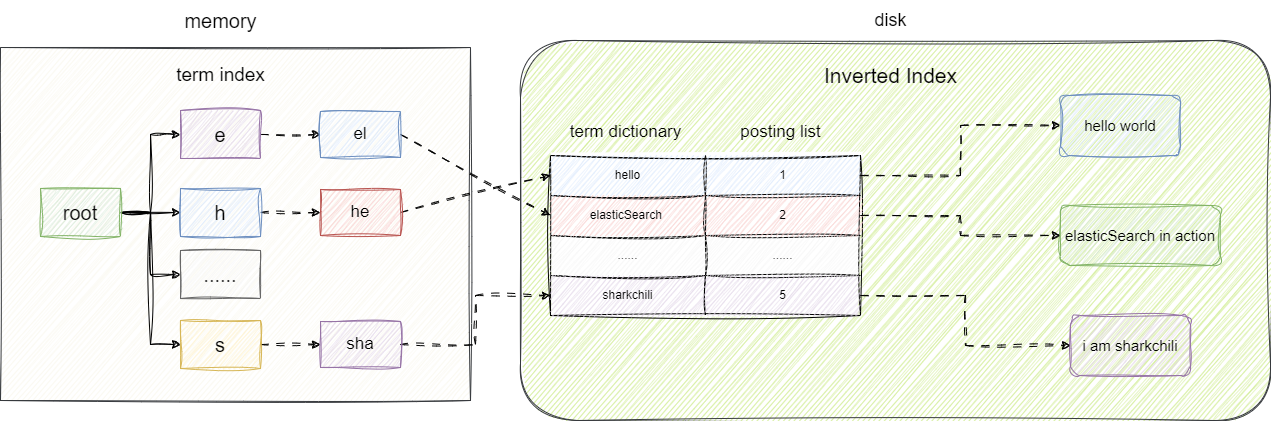
然而,随着词项数量持续增长,即使二分查找,查询性能仍会下降。term dictionary 规模过于庞大时,无法完全加载到内存中进行查询处理。
于是就有了term index。它基于 FST(Finite State Transducer,有限状态转换器)实现,这是一种基于前缀共享的有限状态自动机结构。FST 将 term dictionary 中具有相同前缀的词项压缩存储在同一个路径上,大幅减少存储空间。term index 占用少量内存,通过它可以快速定位到term dictionary在磁盘中的物理地址,从而高效检索文本文档:
# 倒排索引与正排索引对比
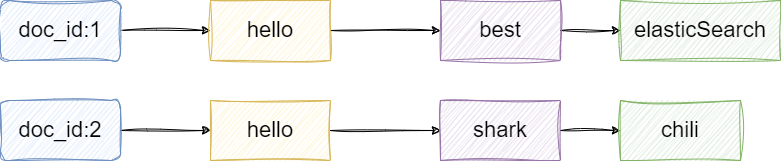
正排索引是与倒排索引相反的概念。它以文档为维度,存储每个文档包含的所有词项,即 doc_id → [term1, term2, ...]。这种结构的优势在于更新文档时只需修改该文档的词项列表,无需维护全局的词项到文档的映射关系,因此维护成本较低。
以一个文档更新为例,假设我们有两篇文档:
| doc_id | title | content |
|---|---|---|
| doc_1 | Elasticsearch 入门 | 介绍 ES 基本用法 |
| doc_2 | Redis 实战 | 讲解 Redis 缓存 |
对应的正排索引结构为:
{
"doc_1": {
"title": ["Elasticsearch", "入门"],
"content": ["介绍", "ES", "基本", "用法"]
},
"doc_2": {
"title": ["Redis", "实战"],
"content": ["讲解", "Redis", "缓存"]
}
}
2
3
4
5
6
7
8
9
10
假设我们把 doc_1 的 title 从 "Elasticsearch 入门" 改为 "Elasticsearch 进阶",只需更新 doc_1 的 title 字段:
{
"doc_1": {
"title": ["Elasticsearch", "进阶"],
"content": ["介绍", "ES", "基本", "用法"]
}
}
2
3
4
5
6
整个过程只涉及 doc_1 内部的数据变更,无需触碰其他文档或全局的词项映射。相比之下,倒排索引如果修改一个词项,需要更新该词项对应的整个 posting list,影响范围更大。
然而,正排索引在关键词检索时必须扫描每个文档的词项列表才能找到目标关键词,检索性能远不如倒排索引。
以搜索 "Redis" 为例,检索过程如下:
| 步骤 | 操作 | 结果 |
|---|---|---|
| 1 | 扫描 doc_1 的 title 和 content | 未找到 "Redis" |
| 2 | 扫描 doc_2 的 title | 找到!title 中包含 "Redis" |
| 3 | 返回 doc_2 | 搜索完成 |
随着文档数量从 2 增长到 100 万,扫描次数也从 2 次增长到 100 万次,时间复杂度为 O(n)。相比之下,倒排索引只需一步定位:"Redis" → [doc_2],时间复杂度为 O(1)(不考虑 posting list 遍历)。
# Doc Values:排序性能优化
有时候我们还希望检索的数据按特定规则进行排序,例如搜索 Elasticsearch 相关文本后,按插入日期排序。尽管可以将查询结果拉到内存中进行排序,但为了提升排序性能,Lucene 采用空间换时间的思想,通过 doc values 将需要排序的字段值以列式存储整合。这样在检索到相应数据后,可以基于 doc values 一次性取出排序字段进行排序。
Doc Values 的底层实现本质上是列式存储,假设我们有 3 篇文档需要按日期排序:
| doc_id | title | date(时间戳) |
|---|---|---|
| doc_1 | Elasticsearch 入门 | 2024-01-15 |
| doc_2 | Redis 实战 | 2024-03-20 |
| doc_3 | MySQL 优化 | 2024-02-10 |
传统的行式存储需要逐行读取并解析才能获取 date 字段,而 Doc Values 以列式存储:
{
"doc_id": ["doc_1", "doc_2", "doc_3"],
"title": ["Elasticsearch 入门", "Redis 实战", "MySQL 优化"],
"date": ["2024-01-15", "2024-03-20", "2024-02-10"]
}
2
3
4
5
排序时,只需读取 date 列即可,无需解析整行数据。同时,Doc Values 还会对数值型字段进行预排序和压缩,进一步提升排序效率。
| 对比项 | 无 Doc Values | 有 Doc Values |
|---|---|---|
| 获取排序字段 | 需要解析每行数据 | 直接读取排好序的列 |
| 时间复杂度 | O(n) | O(1) 读取列 |
| 内存占用 | 临时排序开销大 | 预计算,固定空间 |
实验验证:创建一个包含 keyword、date、long 类型字段的索引,这些字段默认启用 Doc Values:
# 1. 创建索引
curl -X PUT 'http://localhost:9200/test_docvalues' -H 'Content-Type: application/json' -d'
{
"mappings": {
"properties": {
"title": { "type": "text" },
"author": { "type": "keyword" },
"publish_date": { "type": "date" },
"views": { "type": "long" }
}
}
}'
2
3
4
5
6
7
8
9
10
11
12
插入 3 条测试数据:
curl -X POST 'http://localhost:9200/test_docvalues/_doc/1' -H 'Content-Type: application/json' -d'
{ "title": "Elasticsearch 入门", "author": "张三", "publish_date": "2024-01-15", "views": 1000 }'
curl -X POST 'http://localhost:9200/test_docvalues/_doc/2' -H 'Content-Type: application/json' -d'
{ "title": "Redis 缓存实战", "author": "李四", "publish_date": "2024-03-20", "views": 2500 }'
curl -X POST 'http://localhost:9200/test_docvalues/_doc/3' -H 'Content-Type: application/json' -d'
{ "title": "MySQL 优化指南", "author": "王五", "publish_date": "2024-02-10", "views": 1800 }'
2
3
4
5
6
7
8
执行按时间戳升序排序的查询:
curl -X GET 'http://localhost:9200/test_docvalues/_search' -H 'Content-Type: application/json' -d'
{
"sort": [
{ "publish_date": { "order": "asc" } }
]
}'
2
3
4
5
6
返回结果中,sort 字段直接返回排好序的时间戳值,证明 Doc Values 已生效:
{
"took": 29,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "test_docvalues",
"_type": "_doc",
"_id": "1",
"_score": null,
"_source": {
"title": "Elasticsearch 入门",
"author": "张三",
"publish_date": "2024-01-15",
"views": 1000
},
"sort": [1705276800000]
},
{
"_index": "test_docvalues",
"_type": "_doc",
"_id": "3",
"_score": null,
"_source": {
"title": "MySQL 优化指南",
"author": "王五",
"publish_date": "2024-02-10",
"views": 1800
},
"sort": [1707523200000]
},
{
"_index": "test_docvalues",
"_type": "_doc",
"_id": "2",
"_score": null,
"_source": {
"title": "Redis 缓存实战",
"author": "李四",
"publish_date": "2024-03-20",
"views": 2500
},
"sort": [1710892800000]
}
]
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
可以看到返回结果按 publish_date 升序排列(从 1月15日 → 2月10日 → 3月20日),sort 字段中的时间戳值也已预排序好。
# Segment:数据读写的核心机制
基于上述概念,我们将Inverted Index、term index、doc values、stored fields等组合起来,就构成Lucene中一个非常重要的文件——segment。Lucene支持将多份文档写入一个segment中,为了保证并发写入的效率,Lucene提出一旦segment生成后就不可修改,所有新文档都写入新的segment中。
随着文档增加,segment也会不断增加,此时Lucene底层会将这些小segment合并成更大的segment(类似 Leveled Compaction 策略)。这种设计导致要检索的数据可能分布在不同的segment上,所以Lucene在查询时往往会并发查询多个segment并聚合结果:
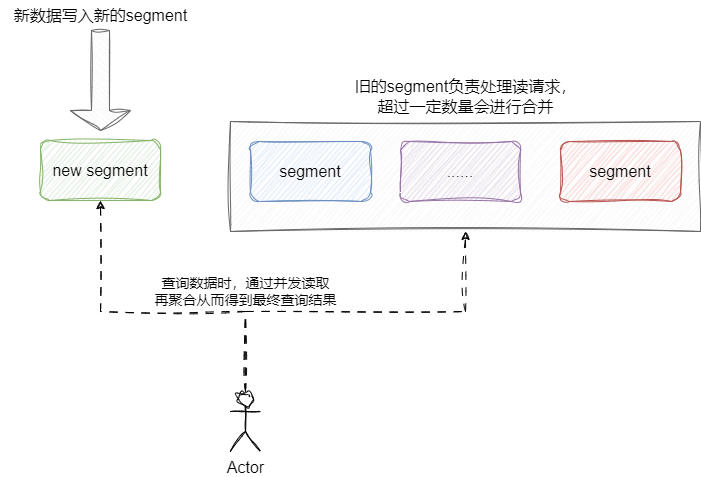
即使如此,高并发场景下仍可能出现资源争抢导致的阻塞。为此,Elasticsearch按业务划分不同的index,每个index由多个shard(Lucene 索引实例)组成,数据隔离到不同的shard中,从而实现资源的隔离和负载均衡:
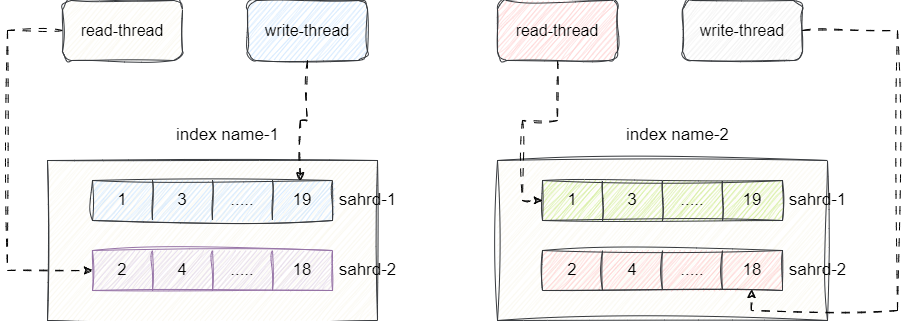
在此基础上,再将每个Lucene内部进行分片,通过shard将数据切片后分摊到多台服务器上,从而缓解单台服务器的压力:
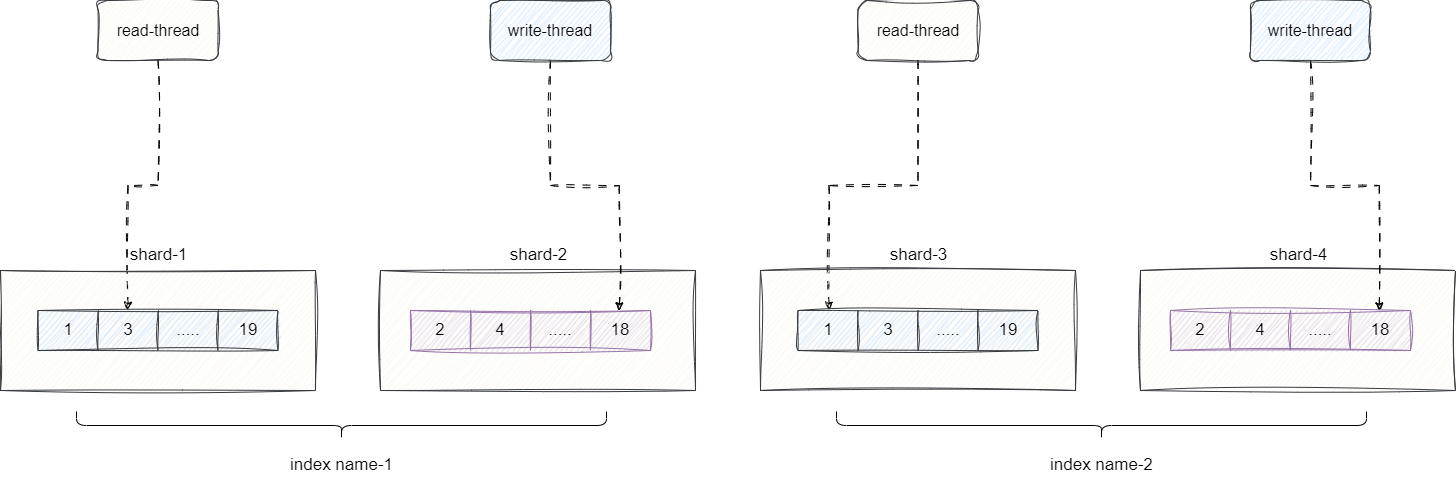
# Elasticsearch 数据类型
# 常见数据类型概览
# Keyword 类型
Elasticsearch 常见的关键词类型有:keyword、constant_keyword 和 wildcard。
keyword 类型用于精准匹配和聚合查询,该类型在查询时以整个词项为单位,无需像 text 类型那样进行分词。
精准匹配即精确查找数据,例如创建一个 product_index 索引,包含 product_id 和 product_category 两个 keyword 类型字段。查询时 ES 不会进行分词,而是基于完整的词项进行匹配:
# 创建索引
curl -X PUT 'http://localhost:9200/product_index' -H 'Content-Type: application/json' -d'
{
"mappings": {
"properties": {
"product_id": { "type": "keyword" },
"product_category": { "type": "keyword" }
}
}
}'
# 插入文档
curl -X POST 'http://localhost:9200/product_index/_doc/1' -H 'Content-Type: application/json' -d'
{
"product_id": "P001",
"product_category": "Electronics"
}'
# 查询(使用 term 精准匹配)
curl -X GET 'http://localhost:9200/product_index/_search' -H 'Content-Type: application/json' -d'
{
"query": {
"term": { "product_id": "P001" }
}
}'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
因为 keyword 类型是精准匹配的,在进行分类字段的聚合统计时可以高效完成。
constant_keyword 用于索引中所有文档该字段值必须相同的场景,适用于日志级别、订单状态等固定枚举值。一旦设置后,所有文档的该字段值必须与预设值一致,否则写入失败:
# constant_keyword 适用于固定枚举值场景
curl -X PUT 'http://localhost:9200/logs_index' -H 'Content-Type: application/json' -d'
{
"mappings": {
"properties": {
"log_level": {
"type": "constant_keyword",
"value": "INFO"
},
"message": { "type": "text" }
}
}
}'
2
3
4
5
6
7
8
9
10
11
12
13
因为天然不可变且精准匹配,检索效率比 keyword 更高。
wildcard 用于通配符匹配,适用于数据量小且查询方式多样的场景:
curl -X GET 'http://localhost:9200/books/_search' -H 'Content-Type: application/json' -d'
{
"query": {
"wildcard": { "title": "*search*" }
}
}'
2
3
4
5
6
由于需要遍历匹配,性能远不如精准匹配,仅适用于特殊查询场景。
# 基本数值类型
ES 的基本数值类型与编程语言类似:
long、integer、short、bytedouble、float、half_float、scaled_floatboolean(布尔型)date、date_nanos(日期型)binary(二进制)
# 结构化数据类型
结构化数据类型相对少见,常见的有范围类型和 IP 地址类型。
范围类型通过指明文档字段的数值区间,查询时也是通过区间进行匹配,只要文档的区间与查询区间存在交集就会返回。例如创建一个 price_range 索引,文档区间为 10~20,查询区间为 15~25 时,该文档会被返回:
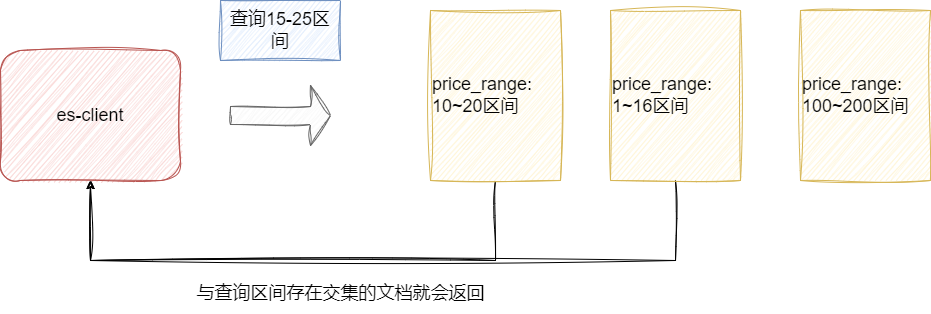
# 创建索引
curl -X PUT 'http://localhost:9200/range_index' -H 'Content-Type: application/json' -d'
{
"mappings": {
"properties": {
"price_range": { "type": "integer_range" }
}
}
}'
# 插入区间为 10~20 的文档
curl -X POST 'http://localhost:9200/range_index/_doc/1' -H 'Content-Type: application/json' -d'
{
"price_range": { "gte": 10, "lte": 20 }
}'
# 查询 15~25 区间的数值
curl -X GET 'http://localhost:9200/range_index/_search' -H 'Content-Type: application/json' -d'
{
"query": {
"range": {
"price_range": { "gte": 15, "lte": 25 }
}
}
}'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
ES 除了 integer_range 以外还有:
float_rangelong_rangedouble_rangedate_range
IP 地址类型用于记录 IPv4 和 IPv6 两种地址,支持范围查询,同时进行格式校验,对于非法的 IP 地址,ES 会明确抛出错误并禁止插入。
# 文本搜索类型
文本类型是 ES 中最常用的类型之一,它基于分词器对检索词进行切词,然后匹配合适结果。主要包括:
textannotated-text(Elasticsearch 7.8.0 引入)completion
text 类型是常规的文本类型,支持全文搜索,允许在大量文本中进行模糊匹配和相关性搜索。传入的检索词会按照分词器的规则进行切词,通过 match 或 match_phrase 等手段实现不同程度的文本匹配:
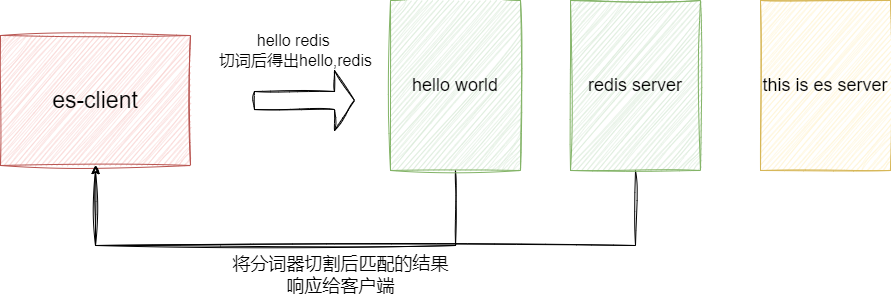
# 创建索引
curl -X PUT 'http://localhost:9200/text_index' -H 'Content-Type: application/json' -d'
{
"mappings": {
"properties": {
"article_content": { "type": "text" }
}
}
}'
# 插入文档
curl -X POST 'http://localhost:9200/text_index/_doc/1' -H 'Content-Type: application/json' -d'
{ "article_content": "hello world" }'
curl -X POST 'http://localhost:9200/text_index/_doc/2' -H 'Content-Type: application/json' -d'
{ "article_content": "redis server" }'
# 查询 "hello" 会被分词,可能匹配到 "hello world"
curl -X GET 'http://localhost:9200/text_index/_search' -H 'Content-Type: application/json' -d'
{
"query": {
"match": { "article_content": "hello" }
}
}'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
annotated-text 是 text 的特殊变种,用于结构化注释文本。通过 annotations 数组为文本中的实体添加类型、位置等信息,支持根据注释进行过滤、分组、排序:
curl -X POST 'http://localhost:9200/annotated_text_index/_doc/1' -H 'Content-Type: application/json' -d'
{
"annotated_text_field": {
"text": "Apple is looking at buying U.K. startup for $1 billion",
"annotations": [
{ "type": "entity", "start": 0, "end": 5, "value": "Apple", "category": "company" },
{ "type": "entity", "start": 23, "end": 31, "value": "U.K.", "category": "country" },
{ "type": "entity", "start": 34, "end": 40, "value": "startup", "category": "organization" }
]
}
}'
2
3
4
5
6
7
8
9
10
11
completion 用于前缀搜索和自动补全,常用于搜索引擎的关键词推荐功能:
curl -X POST 'http://localhost:9200/completion_index/_doc/1' -H 'Content-Type: application/json' -d'
{
"suggestions": ["apple", "application", "banana", "cherry"]
}'
2
3
4
搜索 "ap" 时,会返回 "apple" 和 "application" 等前缀匹配的建议。
# 对象关系类型
对象关系类型强调对象间的组合关系,常见的两种对象关系大类有:
- 嵌套类型:
nested、join - 对象类型:
object、flattened
object 类型即 JSON 对象类型,这里不做赘述。我们以 nested 类型为例讨论:假设需要通过 reviews 字段记录评论者信息,默认使用 object 类型时,ES 底层的 Lucene 并不会针对该类型进行结构化,存储时 reviews 会按照字段的方式归类并构建成一个个字段数组,导致查询时可能出现错误的跨对象匹配:

为了保证结构化数据的完整性,ES 提出了 nested 类型:
# 创建索引
curl -X PUT 'http://localhost:9200/nested_example_index' -H 'Content-Type: application/json' -d'
{
"mappings": {
"properties": {
"product_name": { "type": "text" },
"reviews": {
"type": "nested",
"properties": {
"reviewer_name": { "type": "text" },
"rating": { "type": "integer" },
"comment": { "type": "text" }
}
}
}
}
}'
# 插入文档(包含两条评论)
curl -X POST 'http://localhost:9200/nested_example_index/_doc/1' -H 'Content-Type: application/json' -d'
{
"product_name": "Sample Product",
"reviews": [
{ "reviewer_name": "Alice", "rating": 4, "comment": "This product is great!" },
{ "reviewer_name": "Bob", "rating": 3, "comment": "It's okay, but could be better." }
]
}'
# 查询评分 4 且评论者名称为 Alice 的文档
curl -X GET 'http://localhost:9200/nested_example_index/_search' -H 'Content-Type: application/json' -d'
{
"query": {
"nested": {
"path": "reviews",
"query": {
"bool": {
"must": [
{ "match": { "reviews.rating": 4 } },
{ "match": { "reviews.reviewer_name": "Alice" } }
]
}
}
}
}
}'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
nested 类型将每个对象单独结构化,针对单个对象的字段使用数组的方式维护,保证对象的独立性:

join 类型用于文档间的父子关系,通过 join 可以使不同文档通过父子 ID 构成关联,常用于问答系统等需要父子结构化的场景:
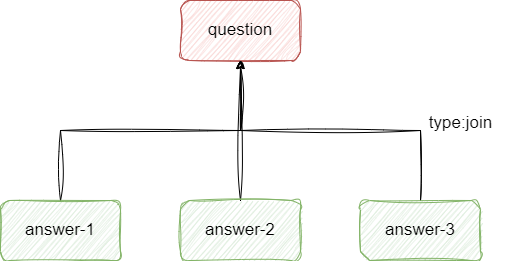
# 创建父子索引
curl -X PUT 'http://localhost:9200/my_index' -H 'Content-Type: application/json' -d'
{
"mappings": {
"properties": {
"text": { "type": "keyword" },
"my_join_field": {
"type": "join",
"relations": { "question": "answer" }
}
}
}
}'
# 创建父文档(question)
curl -X PUT 'http://localhost:9200/my_index/_doc/1?refresh' -H 'Content-Type: application/json' -d'
{
"text": "我是第一个问题",
"my_join_field": { "name": "question" }
}'
# 创建子文档(answer),通过 parent 关联到 id=1 的问题
curl -X PUT 'http://localhost:9200/my_index/_doc/3?routing=1&refresh' -H 'Content-Type: application/json' -d'
{
"text": "问题一的答案1",
"my_join_field": { "name": "answer", "parent": "1" }
}'
# 查询问题 1 的所有答案
curl -X GET 'http://localhost:9200/my_index/_search' -H 'Content-Type: application/json' -d'
{
"query": {
"parent_id": { "type": "answer", "id": "1" }
}
}'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
需要注意的是,has_child 和 has_parent 查询对性能影响较大,查询耗时随子文档数量增加而上升。根据压测数据,在 5 个分片的情况下,十万级父表和千万级子表关联耗时基本可以在 100ms 内完成,对于大部分 B 端业务是可接受的。
应谨慎使用 join 类型。在业务允许的情况下,更推荐通过宽表冗余的非规范化方案解决问题。
flattened 类型用于处理动态 JSON 对象。ES 在没有预先创建 mapping 的情况下插入文档时,会根据字段推断类型完成 mapping 创建。但如果 JSON 对象中的键值对是动态变化的,无法预先统计类型,此时可以将字段声明为 flattened 类型:
# 创建索引
curl -X PUT 'http://localhost:9200/bug_reports' -H 'Content-Type: application/json' -d'
{
"mappings": {
"properties": {
"title": { "type": "text" },
"labels": { "type": "flattened" }
}
}
}'
# 动态插入 JSON 数据
curl -X POST 'http://localhost:9200/bug_reports/_doc/1' -H 'Content-Type: application/json' -d'
{
"title": "Results are not sorted correctly.",
"labels": {
"priority": "urgent",
"release": ["v1.2.5", "v1.3.0"],
"timestamp": { "created": 1541458026, "closed": 1541457010 }
}
}'
# 查询
curl -X GET 'http://localhost:9200/bug_reports/_search' -H 'Content-Type: application/json' -d'
{
"query": {
"term": { "labels": "v1.2.5" }
}
}'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
flattened 类型支持精准查询,但不支持数字范围查询和高亮显示。
# 空间类型
空间类型用于存储地理坐标等数据,常见的有:
- 地理坐标类型:
geo_point - 地理形状类型:
geo_shape
使用场景较少,了解即可。
# Keyword 与 Text 的区别
text 类型进行数据检索时会经过分词的步骤,通过分词得到词项后再进行数据检索;而 keyword 类型直接作为检索词项进行查询,所以 keyword 查询效率更高:
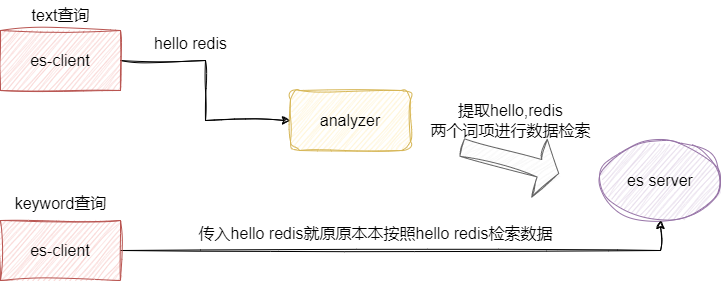
# Nested 类型详解
传统 object 类型传入对象数组进行查询时会因数组扁平化导致多字段笛卡尔积检索问题:
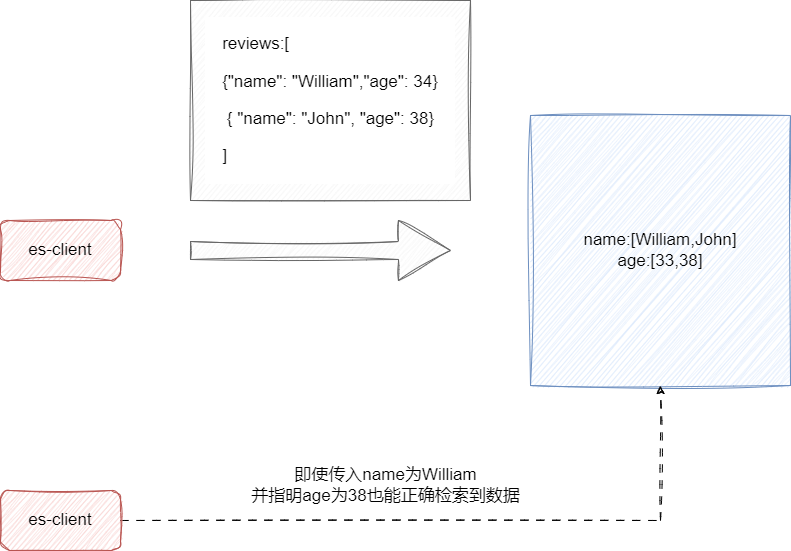
而 nested 类型本质上就是保持对象数组中各个对象的独立性,底层会将对象数组中每个对象独立划分,保证查询维度能够精准定位到数组中各个独立的对象,避免上述问题:

# ES 数组类型的处理方式
ES 没有明确定义数组类型,但每个字段可以用数组形式记录多个值,间接实现了数组类型。例如 tags 字段可以同时存储多个标签值:
curl -X POST 'http://localhost:9200/articles/_doc/1' -H 'Content-Type: application/json' -d'
{
"title": "Elasticsearch 入门",
"tags": ["教程", "搜索", "数据库"],
"views": [100, 200, 300]
}'
2
3
4
5
6
ES 会自动将数组中所有值索引,无需额外配置。
# Mapping 字段类型修改
不支持修改。ES 的 mapping 可类比于 MySQL 的 schema,字段类型在存在数据的情况下不能修改,但可以增加字段。如果需要修改,只能通过 reindex 等方式重建索引。
# 防止 Mapping 字段膨胀
可以参考 ES 官网给出的配置加以限定: https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-settings-limit.html (opens new window)
# Mapping 映射机制
# Mapping 是什么
Mapping 本质上是对索引中字段名称、数据类型、优化信息(是否索引)等结构的定义,相当于数据表的 schema。一个 index 对应一个 mapping。
Mapping 分为动态 mapping和静态 mapping:
- 动态 mapping:用户提交索引数据时自动创建 mapping
- 静态 mapping:通过 PUT 请求显式创建
# 插入数据为何无需指定 Mapping
ES 接受插入数据请求时会检查该索引是否存在,如果不存在则会基于参数推断并自动创建相应的 mapping。但自动推断的类型往往与预期不符,所以一般不建议依赖自动创建。
# 字段索引控制
将 index 设置为 false 即可使字段不可搜索:
# 创建索引时指定字段不可搜索
curl -X PUT 'http://localhost:9200/my_index' -H 'Content-Type: application/json' -d'
{
"mappings": {
"properties": {
"title": { "type": "text" },
"description": {
"type": "text",
"index": false
}
}
}
}'
# 插入文档
curl -X POST 'http://localhost:9200/my_index/_doc/1' -H 'Content-Type: application/json' -d'
{
"title": "示例文档标题",
"description": "这是一段示例描述"
}'
# 查询 description 字段时会抛出异常
curl -X GET 'http://localhost:9200/my_index/_search' -H 'Content-Type: application/json' -d'
{
"query": {
"match": { "description": "示例" }
}
}'
# 错误:Cannot search on field [description] since it is not indexed.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
index: false 的字段不会建立倒排索引,无法被搜索,但字段值仍会存储在 _source 中。
# Elasticsearch 设计理念
# ES 解决的问题与使用场景
Elasticsearch 简称 ES,是一款基于 Lucene 实现的开源搜索引擎和分析引擎,主要用于以下场景:
- 全文检索:对海量文本进行快速搜索
- 结构化查询:支持精确匹配、范围查询、布尔查询等
- 数据分析:聚合统计、实时分析
ES 对外提供 RESTful Web API,可以非常方便地完成数据查询与检索。
# 从关系型数据库理解 ES 核心概念
初学 ES 的读者可能对某些概念比较陌生,下面以关系型数据库作为类比:
| ES 概念 | 关系型数据库 | 说明 |
|---|---|---|
| 索引(index) | 数据表 | 具有相似特征文档的集合 |
| 文档(document) | 行 | 搜索的最小单位,由多个字段构成 |
| 类型(type) | - | ES 7.x 后已废弃(ES 6.x 支持多 type,ES 8.x 完全移除) |
| 映射(mapping) | schema | 字段名称、类型、分词器、是否索引等定义 |
| 倒排索引(Inverted Index) | 索引 | 提升检索速度的核心数据结构 |
| 字段(field) | 列 | 文档的基本组成单元 |
| DSL | SQL | ES 数据查询检索语法 |
| 节点(node) | - | ES 实例运行的单个进程 |
| 集群(cluster) | - | 多个节点组成的分布式系统 |
| 分片(shard) | - | 索引的水平拆分,分散读写压力 |
| 副本(replica) | - | 分片的冗余备份,保证高可用 |
# 自定义路由的优势
默认路由使用 MurmurHash3 算法对 doc_id 取模,均匀分发数据到每个分片。这导致某些查询需要向多个分片发送请求,再进行过滤、聚合、归并,在数据量较大时查询性能较差。
通过自定义路由,使用 routing 参数指定路由值(如 user_id),保证同一用户的数据都存放到同一个分片下,从而减少跨分片查询,提升检索效率。
# 同一用户的所有数据路由到同一分片
curl -X POST 'http://localhost:9200/orders/_doc?routing=user_123' -H 'Content-Type: application/json' -d'
{
"user_id": "user_123",
"product": "iPhone",
"amount": 8999
}'
2
3
4
5
6
7
使用场景:用户中心场景下,同一用户的订单、收藏等数据应路由到同一分片,避免跨分片关联查询。
# 查看集群健康状态
curl -X GET 'http://localhost:9200/_cluster/health'
| 状态 | 说明 |
|---|---|
green | 所有主分片和副本分片都已分配,理想状态 |
yellow | 所有主分片已分配,但副本分片因节点故障或刚启动等原因未分配 |
red | 有分片未分配,通常发生在集群刚启动时 |
假设启动一个单节点集群,有一个针对 student 的索引,配置 3 个主分片和 3 个副本分片。启动时这些分片尚未分配,状态为红色。
单节点启动后,所有主分片完成分配,此时状态为黄色,副本尚未分配。由于所有分片在同一节点存在单点故障风险,我们新增一个节点加入集群。此时 Elasticsearch 集群会触发重平衡操作,将分片重新分布。但状态仍为黄色,因为副本分片仍未分配到新节点。
新节点加入并完成副本分配后,基于高可用原则,每个主分片的副本会创建在不同的节点上。此时状态变为绿色。
硬件故障风险始终存在。假设节点 1 突然崩溃,集群会经历以下过程:
- 主分片 1 和分片 2、分片 3 副本下线,状态变为红色
- 节点 2 的副本分片晋升为主分片,所有主分片都存在,状态变为黄色
Elasticsearch 通过副本冗余实现重平衡和故障恢复,后续只需恢复节点 1,集群就会重新分配分片,最终恢复为绿色状态。
# 高可用设计
为避免单个分片宕机导致服务不可用,ES 通过主从复制保证分片间数据同步。当主分片不可用时,从分片直接取代主分片对外提供服务:
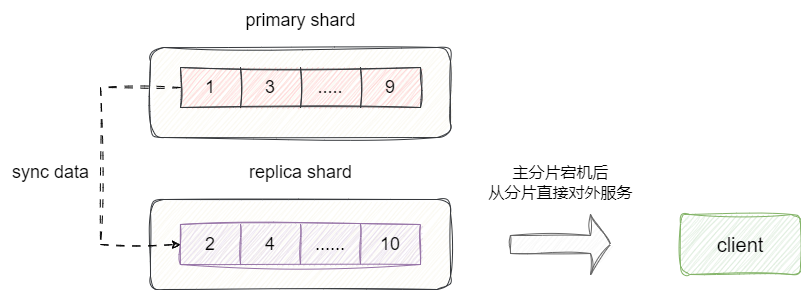
副本数可在创建索引时设置:number_of_replicas: 2。与 MySQL 主从复制的区别:ES 是异步复制。
# 角色化节点设计
ES 不同的工作由不同角色承担:
| 角色 | 说明 |
|---|---|
| 主节点(master node) | 负责集群管理,如创建/删除索引、节点加入/离开、分片分配 |
| 协调节点(coordinate node) | 接收客户端请求,分发到数据节点,聚合结果(所有节点默认都是协调节点) |
| 数据节点(data node) | 存储数据,执行 CRUD、搜索、聚合(默认所有节点都是数据节点) |
每个角色可独立扩展,按需配置资源:
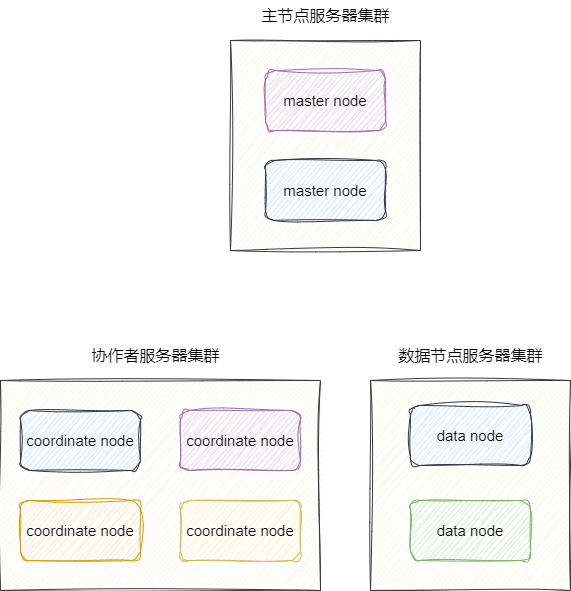
# elasticsearch.yml 配置示例
node.master: true # 可参与主节点选举
node.data: true # 可存储数据
node.ingest: true # 可处理预处理管道
2
3
4
# 主节点选举机制
ES 并未采用中心化选举,而是通过 Raft 协议实现节点间通信,通过节点间数据信息交换完成实时状态更新和主节点选举:
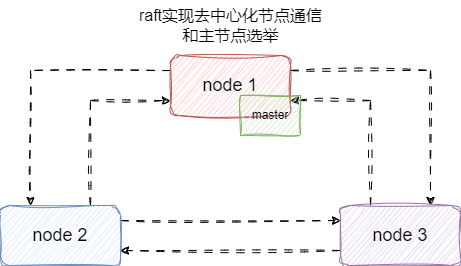
Raft 协议三个核心机制:
- Leader Election:通过 term 和投票机制选主
- Log Replication:主节点写入后同步到从节点
- Safety:term 更大的节点才能成为主节点
防止脑裂:minimum_master_nodes = (num_nodes/2)+1 确保只有多数派节点能组成集群。
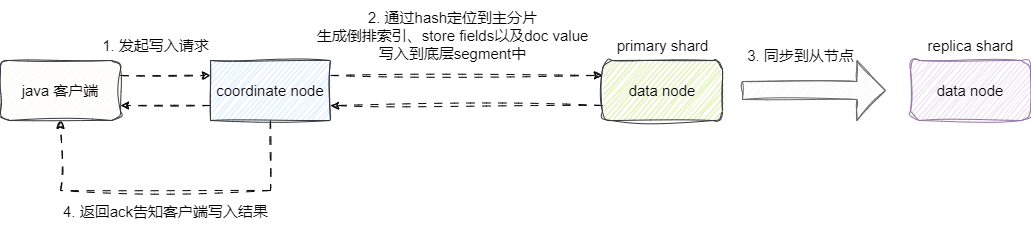
# 数据写入流程
基于上述架构,数据写入流程如下:
- 客户端发起写请求,到达协调节点
- 协调节点根据
routing参数计算 hash 值,定位主分片 - 主分片将数据写入内存 Buffer,同时写入 Translog(类似 MySQL redo log,保证宕机数据不丢失)
- 同步:将数据转发到副本分片,等待副本确认
- 返回确认给客户端
- 异步:Buffer → Lucene Segment(Refresh,默认 1 秒一次,这就是 ES 近实时搜索的原理)
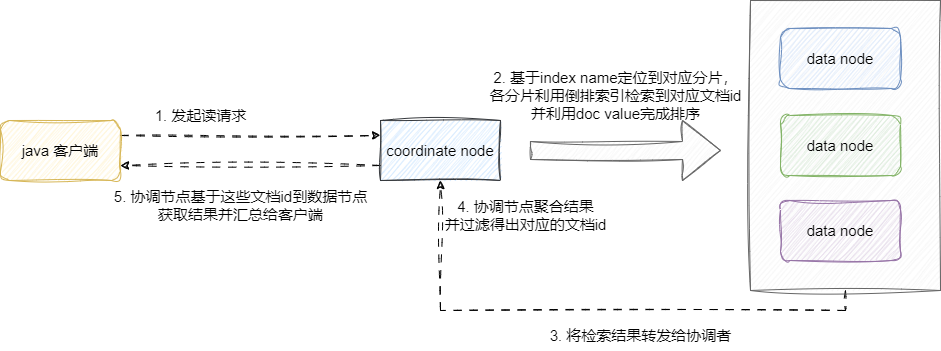
# 数据查询流程
- 客户端发起查询请求,到达协调节点
- 协调节点根据 index 获取所有相关分片信息
- 并发查询所有分片,利用倒排索引定位匹配的 doc_id + 评分
- 各分片返回 doc_id + score,协调节点合并结果
- 协调节点执行全局 Sort → Pagination
- 根据 doc_id 到数据节点批量获取完整文档(
_source或 stored fields),返回结果
# 分片数量设计策略
针对分片数量的设计,建议从以下几个问题入手:
- 如何设计索引?
- 单个分片大小多少合适?
- 一个索引设置多少个主分片合适?
- 一个索引副本分片设置多少合适?
- 单个节点允许多少个分片合适?
- 设置多少个节点合适?
# 如何设计索引
设计索引时,需要避免创建过多的索引和分片,以减少查询时归并与聚合的开销。推荐采用时序性的方式创建索引,按照日、周、月等周期管理索引,以便根据不同业务时期灵活调整分片数量。
# 单个分片大小
分片是由一个个 Lucene 索引实例构成,每个 Lucene 实例都是持有文件句柄的单独文件。分片过小会导致段过小,增加开销;分片过大则带来以下问题:
- 堆内存压力:Segment 元数据、Field Data Cache、Query Cache 等组件占用堆内存,分片越大占用越多,可能导致 OOM 或频繁 GC
- 故障恢复:节点故障时,集群需要从副本复制数据重建分片。分片越大(如 100GB),恢复所需复制的数据量越大,集群处于 yellow/red 状态的时间越长
- Segment 合并开销:Lucene 的合并流程为"读取多个小 Segment → 内存排序 → 写入新的大 Segment → 删除旧 Segment"。合并时需要同时持有被合并的所有 Segment,分片越大,合并涉及的数据量越大,磁盘 I/O 和内存占用越高,且会与查询竞争资源
按照 Elasticsearch 官方建议,单分片大小应控制在 20GB 至 40GB 之间。这个建议更多是官方基于通用场景的经验值,实际生产中应根据业务特点灵活调整。例如 GitHub 的 Elasticsearch 集群采用 128 个分片,每个分片约 120GB。官方建议与大规模生产环境的实践存在差异,说明具体配置需要结合数据量、查询模式、硬件资源等因素综合考量。
# 主分片数量
结合堆内存分配法则:
- 物理内存的 50%:堆内存不应超过物理内存的 50%(剩余内存供 Lucene 缓存文件系统数据)
- 绝对上限 32GB:即使物理内存超过 64GB,堆内存也不应超过 32GB(与 JVM 指针压缩技术有关)
Elasticsearch 官方建议:每 GB 堆内存对应少于 20 个分片。
假设服务器 16G 内存,堆空间约 8G,单节点最多可维护 160 个分片。结合单个分片 40G 的经验值,若每日数据量约 200G,则 5 个主分片即可满足需求。
# 副本分片数量
ES 6 默认配置为 5 主分片 + 1 副本,ES 7 改为 1 主分片 + 1 副本。在分布式场景下,ES 7 的策略足够满足大多数需求;若对高可用要求较高,建议设置 2 个副本。
PUT /testindex
{
"settings" : {
"number_of_shards" : 5,
"number_of_replicas" : 1
}
}
2
3
4
5
6
7
# 节点数量
根据主分片和副本分片的规划,计算所需的数据节点数量。副本应分布在不同节点上以保证高可用。
注:上述为理论参考,具体建议结合业务场景进行基准测试后调整。
# 实际评估示例
假设业务场景:企业级日志分析平台
| 参数 | 数值 |
|---|---|
| 每月数据量 | 500GB |
| 保留周期 | 12 个月 |
| 单节点内存 | 64GB |
| 单节点堆内存 | 30GB(留 50% 给 Lucene 页缓存) |
| 高可用要求 | 支持 1 个节点故障 |
步骤 1:确定单分片大小
根据官方建议和 GitHub 实践,取中间值 50GB 作为单分片目标大小。
步骤 2:计算主分片数量
由于采用时序性索引按月管理,每月生成一个新索引,因此索引大小应与单月数据量匹配:
每月数据量 / 单分片大小 = 500GB / 50GB ≈ 10 个主分片
总数据量 6TB(500GB × 12 个月)分散在 12 个索引中,每个索引约 500GB。
步骤 3:确定副本分片数量
基于上述推算,单月索引需要 10 个主分片。高可用要求支持 1 个节点故障,至少需要 1 个副本:
总分片数 = 主分片 × (1 + 副本数) = 10 × (1 + 1) = 20 个分片
步骤 4:验证节点分片容量
验证单节点能否承载总分片数(考虑 6TB 总数据量分散在 12 个索引中):
单节点最大分片数 = 堆内存 30GB × 20 = 600 个分片
单索引总分片数 = 10 × 2 = 20 个分片
2
每个索引 20 个分片,12 个索引共 240 个分片(主 + 副本),远低于单节点上限 600 个,节点分片容量充足。
步骤 5:确定节点数量
考虑高可用,副本应分布在不同节点:
- 数据节点:至少 2 个(主分片 + 副本分片分布)
- 考虑 1 个节点故障的场景,建议配置 3 个数据节点
最终配置:
PUT /logs-2024-03-01
{
"settings" : {
"number_of_shards" : 10,
"number_of_replicas" : 1
}
}
2
3
4
5
6
7
集群拓扑:
节点 1:P0-P3 + R4-R9
节点 2:P4-P6 + R0-R3
节点 3:P7-P9 + R0-R3
2
3
任意 1 个节点故障,仍有完整数据副本,集群保持绿色状态。
# 小结
本文从 Lucene 底层引擎出发,逐步展开介绍了 Elasticsearch 的核心概念与架构设计:
- Lucene 基础:通过倒排索引、Doc Values 和 Segment 机制,理解 ES 高效检索的底层原理
- 数据类型:掌握 ES 常见数据类型(Keyword/Text/Nested/Geo 等)及其适用场景
- Mapping 映射:理解 Mapping 的定义、动态映射机制及字段索引控制
- 分布式架构:了解集群健康状态、副本高可用、角色化节点设计及主节点选举机制
- 数据流:掌握数据写入(Buffer → Translog → Segment)与查询(协调节点 → 分片合并 → 聚合排序)的完整流程
- 分片设计:学会基于数据量、堆内存、高可用要求设计合理的分片数量与副本策略
你好,我是 SharkChili ,Java Guide 核心维护者之一,对 Redis、Nightingale 等知名开源项目有深度源码研究经验。熟悉 Java、Go 等多语言技术栈,现任某知名黑厂高级研发。
🌟 开源项目贡献
- mini-redis:教学级 Redis 精简实现,助力分布式缓存原理学习
🔗 https://github.com/shark-ctrl/mini-redis (opens new window)(欢迎 Star & Contribute)
📚 公众号价值 分享企业级架构设计、性能优化、源码解析等核心技术干货,涵盖分布式系统、微服务治理、大数据处理等实战领域,并探索面向AI的vibe coding等现代开发范式。
👥 加入技术社群 关注公众号,回复 【加群】 获取联系方式,与众多技术爱好者交流分布式架构、微服务等前沿技术!
# 参考
ES详解 - 认知:ElasticSearch基础概念:https://www.pdai.tech/md/db/nosql-es/elasticsearch-x-introduce-1.html (opens new window)
elasticSearch 是什么?工作原理是怎么样的?:https://mp.weixin.qq.com/s/RUQXIyN95hvi2wM3CyPI9w (opens new window)
【图解】IO趣事|图文结合让你搞透Elasticsearch:https://www.cnblogs.com/-wenli/p/12763887.html (opens new window)
深度剖析 Elasticsearch 集群是如何分片的,一文讲透:https://blog.csdn.net/laoyang360/article/details/82950393 (opens new window)
ES 索引分片内部原理,看完这篇就懂了:https://blog.csdn.net/ubuntutouch/article/details/103713730 (opens new window)
Elasticsearch 面试题第三弹:https://www.cnblogs.com/vincentfhr/p/14006855.html (opens new window)
我的 Elasticsearch 集群应该有多少个分片?:https://www.elastic.co/cn/blog/how-many-shards-should-i-have-in-my-elasticsearch-cluster (opens new window)
Elasticsearch面试题汇总:https://www.cnblogs.com/c9999/p/13686126.html (opens new window)
《Elasticsearch 实战》第二版:https://book.douban.com/subject/34972209/ (opens new window)
- 01
- Windows 10 下的 Maven 安装配置教程05-11
- 02
- 基于 Claude Code 复刻 Redis 慢查询指令实践05-11
- 03
- VSCode与Claude Code后端开发环境搭建与AI编程工作流实践05-09
