 一文搞懂Java核心技术
一文搞懂Java核心技术
# 写在文章开头
Java 基础是面试中的必考内容,但知识点零散、概念繁多,很多同学在复习时往往感到无从下手,难以形成系统的知识体系。
为了帮助大家高效备考,本文对 Java 核心基础知识进行了系统梳理,涵盖语法特性、面向对象、集合框架、并发编程等高频面试考点。
通过阅读本文,你将收获:
- 📌 系统化的知识脉络:从基础概念到进阶特性,建立完整的 Java 知识体系
- 🎯 高频面试考点汇总:聚焦面试常见问题,提升备考效率
- 💡 深度原理解析:不仅知其然,更知其所以然
你好,我是 SharkChili ,Java Guide 核心维护者之一,对 Redis、Nightingale 等知名开源项目有深度源码研究经验。熟悉 Java、Go 等多语言技术栈,现任某知名黑厂高级研发。
🌟 开源项目贡献
- mini-redis:教学级 Redis 精简实现,助力分布式缓存原理学习
🔗 https://github.com/shark-ctrl/mini-redis (opens new window)(欢迎 Star & Contribute)
📚 公众号价值 分享企业级架构设计、性能优化、源码解析等核心技术干货,涵盖分布式系统、微服务治理、大数据处理等实战领域,并探索面向AI的vibe coding等现代开发范式。
👥 加入技术社群 关注公众号,回复 【加群】 获取联系方式,与众多技术爱好者交流分布式架构、微服务等前沿技术!

# Java 语言概述
# Java 语言简介
Java 是 1995 年由 Sun 公司推出的一门高级编程语言,具备以下核心特点:
- 简单易学:相较于 C/C++,Java 没有指针概念,程序操作更加安全便捷
- 平台无关性:通过 JVM 实现"一次编写,到处运行",无需针对不同平台重新编译
- 面向对象:以对象为中心组织代码,支持封装、继承、多态。不同于 C++ 的多继承,Java 采用更简洁的接口机制
- 编译与解释并存:源代码先编译为字节码(.class),再由 JVM 解释执行,兼顾效率与灵活性
- 高可靠性:编译期与运行时双重检查,有效避免内存操作错误和数据损坏
- 安全性:专为网络/分布式环境设计,在防病毒、防篡改方面做了诸多努力
- 网络编程支持:提供简洁易用的网络 API,性能表现同样出色
- 多线程支持:内置多线程机制,方便开发并发应用
# Java 与 C++ 的区别
编译机制
Java 属于半编译、半解释型语言,通过 javac 编译器生成 JVM 可识别的字节码(.class),再由 JVM 解释执行。执行效率相对依赖解释器,但跨平台能力出色。
为解决纯解释执行效率低的问题,JVM 引入了 JIT(即时编译,Just-In-Time Compilation) 技术。JIT 在运行时监测代码执行频率,将热点代码(HotSpot)直接编译为机器码缓存,后续调用直接执行机器码,无需再解释执行,从而大幅提升性能。
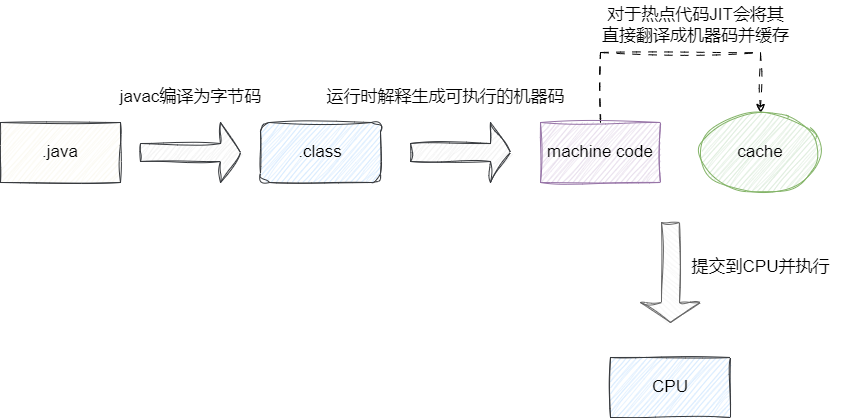
C++ 属于编译型语言,代码编译后直接生成机器码执行,执行效率高、性能优秀。但因直接服务于特定操作系统,跨平台能力相对较弱。
主要区别
| 对比项 | Java | C++ |
|---|---|---|
| 继承机制 | 单继承类,多继承接口 | 支持多继承 |
| 内存管理 | JVM 自动管理 | 手动管理 |
| 参数传递 | 仅值传递 | 值传递、引用、指针 |
| 系统资源控制 | 受 JVM 限制,不够底层 | 可直接操作底层资源 |
# Java 中的 final 关键字
final 关键字可以修饰类、方法、变量,分别具有以下特性:
final 修饰类:类不可被继承
public final class String {
// String类不能被其他类继承
}
// 编译报错:cannot inherit from final String
class MyString extends String {}
2
3
4
5
6
final 修饰方法:方法不可被重写
class Parent {
public final void run() {
System.out.println("Parent running");
}
}
class Child extends Parent {
// 编译报错:method is final and cannot be overridden
public void run() {
System.out.println("Child running");
}
}
2
3
4
5
6
7
8
9
10
11
12
final 修饰变量:变量不可被修改(常量)
public class Example {
public static final int MAX_SIZE = 100;
public final String NAME = "test";
public void test() {
// MAX_SIZE = 200; // 编译报错
// NAME = "new"; // 编译报错
}
}
2
3
4
5
6
7
8
9
# Java 三种技术架构
Java 有三种主要技术架构:
| 架构 | 全称 | 定位 |
|---|---|---|
| Java SE | Standard Edition | 标准版,桌面和服务器应用开发的基础 |
| Java EE | Enterprise Edition | 企业版,分布式企业应用(现更名为 Jakarta EE) |
| Java ME | Micro Edition | 微版,嵌入式/移动设备(已逐步淘汰) |
- Java SE:包含 Java 语言、JVM、核心类库,是其他版本的基础
- Java EE:在 SE 基础上扩展,提供 Servlet、JSP、EJB、JPA 等企业级 API。目前主流框架为 Spring Boot,实际仍基于 Java EE 规范
- Java ME:面向资源受限设备,已逐渐被 Android 取代
注:Java EE 已更名为 Jakarta EE,传统企业级开发多使用 Spring Boot 框架
# JVM 与编译机制
# JVM 工作原理
JVM(Java Virtual Machine) 是 Java 平台的核心组成部分,负责运行 Java 字节码。其核心工作流程如下:
┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Java 源 │ ──► │ Java 字节 │ ──► │ JVM │ ──► │ 机器码 │
│ 代码 .java │ │ 码 .class │ │ 解释/编译 │ │ 执行 │
└─────────────┘ └─────────────┘ └─────────────┘ └─────────────┘
javac JIT CPU
2
3
4
5
详细流程:
- 编译阶段:源代码(.java)通过
javac编译器编译为字节码文件(.class) - 加载阶段:类加载器(ClassLoader)将字节码加载到 JVM
- 执行阶段:
- 解释执行:JVM 逐行解释字节码
- JIT 编译:热点代码被即时编译为机器码缓存,提升执行效率
- 操作系统调用:机器码通过底层操作系统调度到 CPU 执行
JVM 的核心作用:
| 作用 | 说明 |
|---|---|
| 平台无关性 | 一次编译,处处运行 |
| 内存管理 | 自动垃圾回收(GC) |
| 安全性 | 字节码校验,防止恶意操作 |
# JDK 与 JRE 的区别
JDK(Java Development Kit) 和 JRE(Java Runtime Environment) 是 Java 开发中的两个核心概念:
| 组件 | 说明 |
|---|---|
| JRE | Java 运行环境,仅能运行 Java 程序(包含 JVM + 类库) |
| JDK | Java 开发工具包,包含 JRE + 编译工具(javac)+ 开发工具 |
如何选择?
| 场景 | 安装 |
|---|---|
| 只运行 Java 程序 | JRE 即可 |
| 开发 Java 程序 | 必须安装 JDK |
| 运行 JSP/Servlet 等 Web 程序 | 必须安装 JDK |
建议:无论开发还是运行,都建议直接安装 JDK,避免后续因编译需求反复配置。
# 字节码文件及其优势
字节码(Bytecode) 是 Java 编译后的中间代码格式(.class 文件),是 JVM 能识别的指令集。
Java 代码执行流程:
Java 源代码 → javac 编译 → 字节码文件 → JVM 解释/JIT 编译 → 机器码 → CPU 执行
字节码的优势:
| 优势 | 说明 |
|---|---|
| 平台无关性 | 字节码不针对特定操作系统,只需不同平台安装对应 JVM 即可运行 |
| 安全性 | 字节码需通过类加载器验证,防止恶意代码直接操作底层系统 |
| JIT 优化 | JVM 可将热点字节码编译为机器码缓存,执行次数越多速度越快 |
注意:字节码运行效率低于直接编译的机器码,但 JIT 编译器通过热点检测和缓存机制,能有效弥补这一差距。
# JDK 9 的 AOT 编译技术
AOT(Ahead-of-Time) 是 JDK 9 引入的编译技术,在程序运行前将字节码直接编译为机器码。
优势:
| 优势 | 说明 |
|---|---|
| 启动速度快 | 避免运行时编译开销 |
| 全局优化 | 编译时进行整体代码分析 |
劣势:
| 劣势 | 说明 |
|---|---|
| 不支持动态特性 | 反射、动态加载类、动态代理等无法静态确定 |
| 不支持运行时优化 | 无法根据实际运行情况动态调整 |
实际应用:纯 Java 生态中 AOT 很少直接使用。Java 应用通常是长期运行的服务端程序,JIT 的热点优化已足够。若需极快启动,可关注 GraalVM Native Image 技术。
# 数据类型
# Java 基本数据类型
Java 有 8 种基本数据类型,分为四类:
| 分类 | 类型 | 字节 | 位数 | 默认值 |
|---|---|---|---|---|
| 整数 | byte | 1 | 8 | 0 |
| 整数 | short | 2 | 16 | 0 |
| 整数 | int | 4 | 32 | 0 |
| 整数 | long | 8 | 64 | 0L |
| 浮点 | float | 4 | 32 | 0f |
| 浮点 | double | 8 | 64 | 0d |
| 字符 | char | 2 | 16 | '\u0000' |
| 布尔 | boolean | 1 | - | false |
为什么整数类型字节数不同?
计算机用不同位数存储数据,位数越多表示的范围越大:
- byte(8位):最小整数单位,能表示 -128~127。常用于:二进制数据流、网络协议、文件字节
- short(16位):2个字节,能表示约 -3万~3万。常用于:年龄(0-150)、月份(1-12)、RGB 颜色值
- int(32位):4个字节,能表示约 -21亿~21亿,日常开发最常用的整数类型。常用于:ID、计数、金额
- long(64位):8个字节,能表示超大范围。常用于:时间戳(毫秒)、大数值计算
理解要点:byte 是最小单元,short 是 2 个 byte,int 是 4 个 byte,long 是 8 个 byte。位数翻倍,范围呈指数增长。选类型时,够用就行,越大的类型越占内存。
为什么 float 是 4 字节、double 是 8 字节?
浮点数用科学计数法存储,由三部分组成:符号位 + 指数位 + 尾数位
- float(单精度):1位符号 + 8位指数 + 23位尾数 = 32位 = 4字节
- double(双精度):1位符号 + 11位指数 + 52位尾数 = 64位 = 8字节
应用场景:金融计算用 double(精度高),3D 游戏图形用 float(够用且省内存)。
为什么 char 是 2 字节?
char 用来存储字符。英文用 1 字节(ASCII),但中文、日文等需要更多字符。Unicode 要覆盖全世界所有文字,1 字节不够,所以 char 用 2 字节(UTF-16)。
为什么 boolean 是 1 字节?
布尔只需表示 true/false 两种状态,理论上 1 位就够。但 JVM 以字节为单位寻址,所以 boolean 占 1 字节。
# 引用类型与基本类型的区别
什么是引用类型?
基本类型存储的是值本身,而引用类型存储的是对象在内存中的地址。
栈内存 堆内存
┌─────────┐ ┌─────────────────┐
│ 10 │ │ │
└─────────┘ │ String 对象 │
基本类型:直接存储值 │ address="Tom" │
└────────┬────────┘
┌─────────┐ │
│ 0x0010 │ ─────────────────────────────┘
└─────────┘
引用类型:存储对象地址
2
3
4
5
6
7
8
9
10
为什么需要引用类型?
- 基本类型只能存简单数据,无法表达复杂对象
- 对象较大,存在堆内存中,通过地址引用访问
- 多个变量可引用同一对象,节省内存
栈内存 堆内存
┌─────────┐ ┌─────────────────┐
│ 0x0010 │ ──┐ │ │
└─────────┘ │ │ 用户对象 │
┌─────────┐ ├── 都指向 ─────────▶│ name="Tom" │
│ 0x0010 │ ──┘ 同一对象 │ age=18 │
└─────────┘ └─────────────────┘
p1
p2 ← 两个引用指向同一对象
2
3
4
5
6
7
8
9
Java 引用类型分为三种:
| 类型 | 关键字 | 示例 |
|---|---|---|
| 类类型 | class | String、Object |
| 接口类型 | interface | Runnable、Comparable |
| 数组类型 | [] | int[]、String[] |
# String 专题
# String 为什么是不可变的?
String 是不可变类,这是 Java 设计中的重要特性。
不可变的原因:
- String 是 final 类,无法被继承
- 内部存储数据的 char[] 是 final 的
- 没有暴露修改数据的方法
public final class String {
private final char[] value; // value 数组不可变
// 没有 setValue() 等修改方法
}
2
3
4
什么是不可变?
不可变不是说变量不能重新赋值,而是对象创建后其内部数据不能被修改:
String s = "hello";
s = "world"; // 变量 s 可以重新指向新对象
// 但下面这个操作会编译报错,因为字符串内容不可修改
// s[0] = 'H'; // 编译错误
2
3
4
5
String 的"修改"其实是创建新对象:
String s = "hello";
String s2 = s.concat("world"); // concat 返回新字符串,不修改原对象
System.out.println(s); // 输出 "hello",s 未改变
System.out.println(s2); // 输出 "helloworld"
2
3
4
不可变性带来的好处:
线程安全:
堆内存(字符串常量池)
┌─────────────────────────────────┐
│ │
│ "hello" │◀── 线程1: String s1 = "hello"
│ @0x0010 │◀── 线程2: String s2 = "hello"
│ │ 两个线程指向同一个对象
│ │
└─────────────────────────────────┘
线程1 ──s1引用──▶ "hello" ◀──s2引用── 线程2
无需同步:String 不可变,多线程共享安全
2
3
4
5
6
7
8
9
10
11
12
hashCode 可缓存:
String 作为 HashMap 的 key 时,由于不可变,hashCode 可以缓存,避免重复计算。
安全性:数据库连接、文件路径等使用 String,防止被篡改。
# String + int 发生了什么?
当 String 与其他类型使用 + 运算符时,会触发字符串拼接,系统自动将其他类型转换为字符串后拼接。
String a = "999";
int b = 1;
System.out.println(a + b); // 输出 "9991",不是 1000!
2
3
原理:编译器将 + 操作转换为 StringBuilder 拼接
a + b
↓
编译器转换为
↓
new StringBuilder()
.append(a) // "999"
.append(b) // "1"
.toString() // "9991"
2
3
4
5
6
7
8
如何让 int 参与数学运算?
String a = "999";
int b = 1;
// 方式一:先转换再运算
System.out.println(Integer.parseInt(a) + b); // 1000
// 方式二:括号改变运算顺序
System.out.println(Integer.valueOf(a) + b); // 1000
2
3
4
5
6
7
8
# String 的 == 与 equals 有什么区别?
== 比较的是引用地址,equals 比较的是内容。
String s1 = "hello";
String s2 = "hello";
String s3 = new String("hello");
System.out.println(s1 == s2); // true
System.out.println(s1 == s3); // false
System.out.println(s1.equals(s3)); // true
2
3
4
5
6
7
为什么结果不同?
s1 = "hello" ──────────┐
├── 指向常量池中的同一个对象
s2 = "hello" ──────────┘
s3 = new String("hello") ──→ 堆中新建的对象
2
3
4
5
s1 == s2:true,两者指向常量池中同一个对象,地址相同s1 == s3:false,s3 用 new 创建,在堆中分配了新空间,地址不同s1.equals(s3):true,String 重写了 equals(),比较内容而非地址
为什么 String 要重写 equals()?
默认的 equals() 比较的是引用地址。重写后比较内容,这样内容相同的字符串可以视为"相等"。
# String 拼接与 intern()
字符串拼接的行为不同:
| 拼接方式 | 结果存放位置 | 是否复用常量池 |
|---|---|---|
"Program" + "ming" | 编译期优化,直接生成常量 | 是 |
s3 + s4(变量) | 运行时通过 StringBuilder 在堆中生成 | 否 |
String s1 = "Programming";
String s3 = "Program";
String s4 = "ming";
String s5 = s3 + s4; // 运行时:new StringBuilder().append(s3).append(s4).toString()
String s6 = "Program" + "ming"; // 编译期优化:直接变成 "Programming"
2
3
4
5
6
intern() 方法:
- 调用
intern()会将字符串放入常量池,并返回常量池中的引用 - 如果常量池中已有相同内容,返回已有引用
String s2 = new String("Programming");
String s3 = s2.intern(); // s3 指向常量池中的 "Programming"
System.out.println(s1 == s2); // false(s2 在堆中)
System.out.println(s1 == s3); // true(s3 在常量池)
常量池 堆
┌──────────────┐ ┌──────────────┐
│ "Programming"│◀──────────│new String() │
│ @0x0010 │ intern() │ @0x0020 │
└──────────────┘ └──────────────┘
↑ ↑
s1 == s3 (true) s1 == s2 (false)
2
3
4
5
6
7
8
9
10
11
12
# new String("abc") 创建了几个对象?
String s = new String("abc");
答案是 2 个对象:
1. "abc" 字符串字面量 → 先检查常量池,不存在则创建
2. new String("abc") → 在堆中创建新对象
2
# 自动类型转换与强制类型转换
类型转换规则:小范围 → 大范围(自动),大范围 → 小范围(强制)。
自动类型转换(隐式转换)
小范围类型的值可以直接赋值给大范围类型,不需要显式声明。
char c = 'a';
int num = c; // char 自动转换为 int
2
原理:char 占 2 字节(16位),int 占 4 字节(32位),int 的范围完全覆盖 char,所以自动转换不会丢失数据。
char (2字节) ──────▶ int (4字节)
0~65535 -21亿 ~ 21亿
2
强制类型转换(显式转换)
大范围类型的值赋值给小范围类型时,需要强制转换,但可能丢失数据。
int num = 100;
char c = (char) num; // 需要强制转换
2
类型转换图:
┌─────────────────────────────────────────────────────┐
│ byte → short → int → long → float → double │
│ 1 2 4 8 4 8 │
│ │
│ ◀──────────── 自动转换(隐式)───────────────▶ │
│ │
│ ◀──────────── 强制转换(显式)───────────────▶ │
└─────────────────────────────────────────────────────┘
char ───▶ int ───▶ long
◀──── 强制转换
2
3
4
5
6
7
8
9
10
11
注意:byte、short、char 三种类型在运算时会自动提升为 int。
# 什么是自动装箱和自动拆箱?
装箱:基本类型 → 包装类型 拆箱:包装类型 → 基本类型
基本类型 (int) 包装类型 (Integer)
10 ───▶ Integer(10)
装箱 拆箱
2
3
为什么需要装箱/拆箱?
基本类型不是对象,无法直接存入集合。包装类型解决了这个问题。
装箱示例:
Integer i = 10; // 自动装箱
通过字节码可以看到底层调用 Integer.valueOf():
INVOKESTATIC java/lang/Integer.valueOf (I)Ljava/lang/Integer;
拆箱示例:
Integer i = 10;
int num = i; // 自动拆箱
2
通过字节码可以看到底层调用 Integer.intValue():
INVOKEVIRTUAL java/lang/Integer.intValue ()I
# 运算符与流程控制
# & 和 && 的区别
&(不短路):两边表达式都会执行,即使左边已经是 false。
&&(短路):左边为 false 时直接跳过右边,不执行。
& 执行流程:
func1() → 返回 false → 继续执行 func2() → 最终返回 false
&& 执行流程:
func1() → 返回 false → 直接跳过 func2() → 返回 false
2
3
4
5
示例代码验证:
boolean b1 = func() & func(); // func() 执行 2 次
boolean b2 = func() && func(); // func() 执行 1 次
2
什么时候用 &&? 当右边表达式有副作用(如调用方法、计算)时,用 && 可以避免不必要的开销。
什么时候用 &? 需要确保两边都执行时,比如按位运算或特殊业务逻辑。
# switch 支持的数据类型
JDK 7 之后,switch 支持以下数据类型:
| 支持 | 不支持 |
|---|---|
| byte、short、char、int | long |
| 包装类(Byte、Short、Character、Integer) | float、double |
| 枚举(enum) | boolean |
| String(JDK 7+) | - |
为什么 long 不支持?
switch 底层用跳转表实现,case 值作为数组下标跳转。int 范围约 21 亿,创建跳转表可行;但 long 范围约 922 亿亿,无法创建这么大的表。
为什么浮点数不支持?
switch 要求 case 值精确相等,但浮点数有精度问题:0.1 + 0.2 != 0.3,无法保证精确匹配。
为什么 boolean 不支持?
boolean 只有 true/false 两个值,用 if-else 更简洁,没必要用 switch。
# break 与 continue 的区别
break:跳出整个循环体,提前结束循环。
continue:跳过本次循环,继续下一次循环。
break 执行流程:
┌─────────────────────┐
│ for 循环 │ ← break 在这里触发
│ ┌─────────────┐ │
│ │ if 条件满足 │──break──▶ 跳出整个循环
│ └─────────────┘ │
└─────────────────────┘
continue 执行流程:
┌─────────────────────┐
│ for 循环 │
│ ┌─────────────┐ │
│ │ if 条件满足 │──continue──▶ 跳过本次迭代,继续下次
│ └─────────────┘ │
└─────────────────────┘
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# do-while 与其他循环的区别
do-while:先执行,后判断条件,循环体至少执行一次。
while / for:先判断条件,后执行,循环体可能一次都不执行。
do-while 执行流程:
┌─────────────────────┐
│ 执行循环体 │ ← 先执行
│ ↓ │
│ while(条件) │ ← 再判断
│ ┌────┴────┐ │
│ │ 满足? │ │
│ └──┬──────┘ │
│ 是│ │
└──────┴──────────────►继续执行
2
3
4
5
6
7
8
9
10
使用场景:当需要确保循环体至少执行一次时(如用户输入验证),使用 do-while。
# switch case 穿透
如果 case 后没有 break,会继续执行后面的 case,直到遇到 break 或 switch 结束。
int day = 3;
switch (day) {
case 1: System.out.print("周一 ");
case 2: System.out.print("周二 ");
case 3: System.out.print("周三 ");
default: System.out.print("周末 ");
}
// 输出:周三 周末
2
3
4
5
6
7
8
实际应用:可以用 case 穿透来实现多个 case 共用一段逻辑。
# 嵌套循环中的 break
break 默认只跳出当前层循环,无法跳出外层循环。
int count = 0;
for (int i = 1; i <= 3; i++) {
for (int j = 1; j <= 3; j++) {
if (i == j) {
break; // 只跳出内层循环
}
count++;
}
}
// count = 3(而非0)
2
3
4
5
6
7
8
9
10
进阶:如果需要跳出多层循环,可以使用标签(label)。
# break、continue、return 的区别
break:跳出当前层循环体,提前结束整个循环。
continue:跳过本次循环的剩余代码,直接进入下一次循环判断。
return:结束当前方法,将结果返回给调用者。
break:
for (...) {
if (条件) {
break; ← 跳出整个 for 循环
}
}
continue:
for (...) {
if (条件) {
continue; ← 跳过本次循环,继续下一次
}
// 这段代码会被跳过
}
return:
for (...) {
if (条件) {
return; ← 直接结束方法
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
区别总结:
- break 和 continue 只能用于循环或 switch
- return 用于结束整个方法,无论方法在哪里
# 位运算:乘除 2 的最快方式
位运算比算术运算更快,因为位运算是直接在二进制位上操作,不需要 CPU 做复杂的乘除计算。
左移 n 位 = 乘以 2 的 n 次方
右移 n 位 = 除以 2 的 n 次方
2 << 3 等价于 2 * 8 = 16
8 >> 1 等价于 8 / 2 = 4
2
3
4
5
JDK 源码中的实际应用:
ArrayList 的 grow() 方法用左移实现扩容:
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1); // 扩容 1.5 倍
// ...
}
2
3
4
5
二分查找中的中间索引计算:
int mid = (low + high) >>> 1; // 等价于 (low + high) / 2
为什么位运算更快? CPU 直接操作二进制位,而乘除需要调用 ALU(算术逻辑单元)进行复杂运算。
# 线性查找数组最大值的复杂度是?
时间复杂度为 O(n),这是最优解,因为必须遍历每个元素至少一次才能确定最大值。
int max = arr[0];
for (int i = 1; i < arr.length; i++) {
if (arr[i] > max) {
max = arr[i];
}
}
2
3
4
5
6
并行流真的更快吗? 对于小数组,fork/join 框架开销反而更慢;对于大数组+多核 CPU,并行流才能发挥优势。
# 高频面试考点
# 为什么不能用浮点数表示金额?
浮点数存在精度丢失问题,不适合金融计算。
double a = 0.1;
double b = 0.2;
System.out.println(a + b); // 输出 0.30000000000000004,而非 0.3
2
3
原因:浮点数采用二进制表示,无法精确表示十进制小数(如 0.1、0.2),会产生舍入误差。
解决方案:使用 BigDecimal
BigDecimal a = new BigDecimal("0.1");
BigDecimal b = new BigDecimal("0.2");
System.out.println(a.add(b)); // 输出 0.3,精确计算
2
3
注意:使用
BigDecimal(double)构造仍可能有精度问题,推荐用BigDecimal(String)或BigDecimal.valueOf(double)。
# BigDecimal用equals进行比较可以吗?为什么?
BigDecimal重写的equals方法比较的是两个值的精度的大小是否一致:
@Override
public boolean equals(Object x) {
if (!(x instanceof BigDecimal))
return false;
BigDecimal xDec = (BigDecimal) x;
if (x == this)
return true;
//先比较精度
if (scale != xDec.scale)
return false;
//再比较数值
long s = this.intCompact;
long xs = xDec.intCompact;
if (s != INFLATED) {
if (xs == INFLATED)
xs = compactValFor(xDec.intVal);
return xs == s;
} else if (xs != INFLATED)
return xs == compactValFor(this.intVal);
return this.inflated().equals(xDec.inflated());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
假设我们BigDecimal声明的分别是1.0和1.00,最终的结果就可能返回false,所以一般情况下,BigDecimal进行数值比较时我们建议使用compareTo
# BigDecimal(double) 和 BigDecimal(String) 的区别
BigDecimal(double):将 double 直接转为 BigDecimal,精度问题已经被 double 带入了。
BigDecimal(String):将字符串解析为精确的小数值,不会丢失精度。
public class BigDecimalDemo {
public static void main(String[] args) {
// String 方式:精确
System.out.println(new BigDecimal("0.1").add(new BigDecimal("0.2")));
// 输出:0.3
// double 方式:不精确
System.out.println(new BigDecimal(0.1).add(new BigDecimal(0.2)));
// 输出:0.30000000000000004
}
}
2
3
4
5
6
7
8
9
10
11
结论:涉及金额计算时,永远使用 BigDecimal(String) 或
BigDecimal.valueOf(double)。
# 为什么 Integer.MIN_VALUE 取绝对值是负数?
Integer.MIN_VALUE = -2147483648,其绝对值是 2147483648,超出了 int 的最大值(2147483647),导致溢出变成负数。
public class MinValueDemo {
public static void main(String[] args) {
System.out.println(Math.abs(Integer.MIN_VALUE));
// 输出:-2147483648(负数!)
System.out.println(Integer.MIN_VALUE);
// 输出:-2147483648
System.out.println(-Integer.MIN_VALUE);
// 输出:-2147483648(越界)
}
}
2
3
4
5
6
7
8
9
10
11
12
原因:int 的取值范围是 -2147483648 ~ 2147483647,MIN_VALUE 没有对应的正数。
-2147483648 ← MIN_VALUE(负数最大值)
↓
取绝对值后得到 2147483648
↓
超出 int 最大值 2147483647
↓
溢出变成 -2147483648
2
3
4
5
6
7
注意:Long.MIN_VALUE 同样存在这个问题。
# Lambda 表达式是如何实现的?
Lambda 本质上是语法糖,编译阶段会被解糖为对应的函数式接口调用。
Lambda 表达式 编译后
i -> i % 2 == 0 → Predicate.test(i)
String::valueOf → Function.apply(String)
// 编译后的字节码
invokedynamic #5, 0 // Predicate.test()
invokedynamic #7, 0 // Function.apply()
2
3
4
5
6
# finally 中的代码一定会执行吗?
不一定,以下情况会导致 finally 不执行:
- 执行
System.exit(0)终止 JVM - try-catch 中存在死循环
- JVM 崩溃或服务器宕机
- finally 在守护线程中执行,主线程结束时守护线程可能直接退出
# Java 枚举的用处
- 类型安全:限定取值范围,如
enum Color { RED, GREEN, BLUE } - 单例模式:枚举天然是单例,线程安全,可直接用于实现单例
- 可带属性和方法:枚举可以定义属性和业务方法
enum OrderStatus {
PENDING("待支付"),
PAID("已支付"),
SHIPPED("已发货");
private final String desc;
OrderStatus(String desc) { this.desc = desc; }
}
2
3
4
5
6
7
8
# BIO、NIO、AIO 的区别
| 类型 | 名称 | 说明 |
|---|---|---|
| BIO | 同步阻塞 | 线程发起请求后阻塞,直到 IO 完成。传统 Socket 编程 |
| NIO | 同步非阻塞 | 线程发起请求后立即返回,通过 Selector 轮询就绪通道。解决 C10K 问题 |
| AIO | 异步非阻塞 | 线程发起请求后立即返回,IO 完成后回调通知 |
应用场景:NIO 适合高并发场景(Netty 是经典框架),AIO 适合 IO 密集型任务。
# UUID 是什么?
UUID(Universally Unique Identifier)是全局唯一标识符,由以下部分组成:
- MAC 地址 + 时间戳 + 随机数
理论上是极大概率唯一,几乎不可能重复。
String uuid = UUID.randomUUID().toString();
// 输出:550e8400-e29b-41d4-a716-446655440000
2
# Arrays.sort 使用什么排序算法?
JDK 7+ 使用双路快速排序(DualPivotQuicksort),时间复杂度 O(n log n)。
public static void sort(int[] a) {
DualPivotQuicksort.sort(a, 0, a.length - 1, null, 0, 0);
}
2
3
小数组优化:对于短数组,使用插入排序,避免递归开销。
# main 方法为什么必须是 public static void?
| 修饰符 | 原因 |
|---|---|
| public | JVM 需要从外部调用 main 方法 |
| static | JVM 调用时不需要创建对象 |
| void | main 是程序入口,不需要返回值 |
# BigDecimal 和 Long 哪个更适合表示金额?
BigDecimal,因为:
- Long 只能表示整数,无法精确表示小数(如 0.1 元)
- BigDecimal 可以精确表示任意精度的小数
# 如何修改 private 修饰的字段?
- 反射:通过
Field.setAccessible(true)绕过访问限制 - set 方法:如果类提供了 setter 方法
# 并行流适合什么场景?
并行流底层使用 Fork/Join 框架,核心要求是操作可并行化。
适合并行流:
- 独立元素的映射、过滤等操作
- 无状态的聚合运算
不适合并行流:
- 累加操作(涉及线程间同步)
- 有副作用的操作
- 阻塞 IO 操作(见下文)
压测代码:
import java.util.*;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
public class ParallelStreamTest {
private static final int WARMUP = 5; // 预热轮数:触发 JIT 编译优化
private static final int BENCHMARK = 10; // 正式测试轮数:多轮取平均
public static void main(String[] args) {
int[] data = IntStream.rangeClosed(1, 90_000_000).toArray();
warmup(data); // 预热触发 JIT 编译
benchmark(data);
}
// 预热阶段:执行多轮操作,使热点代码达到编译后的最优性能
private static void warmup(int[] data) {
for (int i = 0; i < WARMUP; i++) {
// 串行预热
Arrays.stream(data).filter(x -> x % 2 == 0)
.map(x -> complexTransform(x)).filter(x -> x > 100).boxed().toList();
// 并行预热
Arrays.stream(data).parallel().filter(x -> x % 2 == 0)
.map(x -> complexTransform(x)).filter(x -> x > 100).boxed().toList();
}
}
// 正式测试:交替执行串行/并行,统计平均耗时
private static void benchmark(int[] data) {
long serialTotal = 0, parallelTotal = 0;
for (int i = 0; i < BENCHMARK; i++) {
// 每轮前清理内存,降低 GC 干扰
System.gc();
try { Thread.sleep(100); } catch (InterruptedException e) {}
// 串行 Stream 测试
long start = System.currentTimeMillis();
List<Integer> serial = Arrays.stream(data).filter(x -> x % 2 == 0)
.map(x -> complexTransform(x)).filter(x -> x > 100).boxed().toList();
long serialTime = System.currentTimeMillis() - start;
serialTotal += serialTime;
System.gc();
try { Thread.sleep(100); } catch (InterruptedException e) {}
// 并行 Stream 测试
start = System.currentTimeMillis();
List<Integer> parallel = Arrays.stream(data).parallel()
.filter(x -> x % 2 == 0).map(x -> complexTransform(x))
.filter(x -> x > 100).boxed().toList();
long parallelTime = System.currentTimeMillis() - start;
parallelTotal += parallelTime;
System.out.printf("第 %d 轮 - 串行: %dms, 并行: %dms%n",
i + 1, serialTime, parallelTime);
}
System.out.printf("平均值 - 串行: %.2fms, 并行: %.2fms, 加速比: %.2fx%n",
(double) serialTotal / BENCHMARK, (double) parallelTotal / BENCHMARK,
(double) serialTotal / parallelTotal);
}
// 复杂变换函数:模拟 CPU 密集型计算
private static int complexTransform(int x) {
int r = x * 3 + 1;
r = (r ^ (r >>> 16)) * 0x45d9f3b;
r = (r ^ (r >>> 16)) * 0x45d9f3b;
return Math.abs(r) % 10000;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
输出结果:
第 1 轮 - 串行: 680ms, 并行: 672ms
第 2 轮 - 串行: 786ms, 并行: 678ms
...
第 10 轮 - 串行: 775ms, 并行: 692ms
平均值 - 串行: 744.40ms, 并行: 713.10ms, 加速比: 1.04x
2
3
4
5
6
结论:即使对独立元素操作(如 filter、map),并行流受 Fork/Join 分治开销限制,加速比通常有限。
IO 操作需谨慎:
并行流默认使用 ForkJoinPool.commonPool(),这是一个全局共享的线程池(默认大小 = CPU 核心数 - 1)。如果在其中进行阻塞 IO 操作:
- 线程耗尽:所有线程被 IO 阻塞,导致其他并行流任务无法执行
- 线程饥饿:commonPool 线程被占满,新任务只能排队等待
- 死锁风险:如果业务链路过长,可能导致全局并行流夯死
// 危险示例:IO 操作阻塞 commonPool
list.parallelStream().map(this::fetchFromRemote).collect(Collectors.toList());
// 解决方案:使用专用线程池
ExecutorService executor = Executors.newFixedThreadPool(20);
list.stream()
.map(x -> executor.submit(() -> fetchFromRemote(x)))
.collect(Collectors.toList());
2
3
4
5
6
7
8
原则:并行流只适合CPU 密集型或短暂等待的操作,长时间阻塞 IO 请使用专用线程池。
# String s1 == s2、s1 == s3、s1 == s4 的结果是?
String s1 = "Programming";
String s2 = new String("Programming");
String s3 = "Program" + "ming";
String s4 = s3.intern();
2
3
4
- A. false false true true
- B. true false true true
- C. false false false true
- D. false true true true
答案:D。s2 是 new 在堆中(false),s3 编译期优化在常量池(true),s4 调用 intern() 返回常量池引用(true)。
# final 可以修饰什么?
- A. 类
- B. 方法
- C. 变量
- D. 所有以上
答案:D。final 可以修饰类(不可继承)、方法(不可重写)、变量(不可修改)。
# 哪种数据类型占 8 字节?
- A. byte
- B. short
- C. int
- D. long
答案:D。byte 1字节、short 2字节、int 4字节、long 8字节。
# byte 强转结果是什么?
int a = 200;
byte b = (byte) a;
System.out.println(b);
2
3
- A. 200
- B. -56
- C. 编译错误
- D. 运行时报错
答案:B。200 超过 byte 范围(-128~127),强转后发生溢出。int 200 的二进制 11001000,最高位为1表示负数,补码运算得 -56。
# float 和 double 谁精度更高?
- A. float 精度更高
- B. double 精度更高
- C. 两者都是 8 字节
- D. float 8 字节,double 4 字节
答案:B。float 4字节(23位尾数),double 8字节(52位尾数),尾数位越多精度越高。
# char 使用什么编码?
- A. ASCII
- B. UTF-8
- C. Unicode
- D. GBK
答案:C。Java 的 char 使用 Unicode 编码(UTF-16),占 2 字节。
# 'a' + 1 输出什么?
System.out.println('a' + 1);
- A. a1
- B. 97
- C. 98
- D. 编译错误
答案:C。char 与 int 相加时,char 自动转为 int,'a' 的 ASCII 码是 97,97+1=98。
# 运算符优先级最高的是?
- A. +
- B. &&
- C. =
- D. ()
答案:D。括号 () 优先级最高。
# 10 / 3 * 3 结果是?
- A. 9
- B. 10
- C. 9.0
- D. 10.0
答案:A。从左到右计算,10/3=3(整除),3*3=9。
# 3 | 5 结果是?
- A. 7
- B. 6
- C. 1
- D. 5
答案:A。位运算:3(011) | 5(101) = 7(111)。
# String 类是可变的还是不可变的?
- A. 可变
- B. 不可变
答案:B。String 是不可变类,final 类 + final char[] + 无修改方法。
# String + int 的结果是?
String a = "999";
int b = 1;
System.out.println(a + b);
2
3
- A. 999
- B. 1000
- C. 1000
- D. 9991
答案:D。输出 "9991",因为 String + int 会进行字符串拼接,而非数学运算。
# String s1 == s2、s1 == s3、s1.equals(s3) 的结果是?
String s1 = "hello";
String s2 = "hello";
String s3 = new String("hello");
System.out.print((s1 == s2) + " ");
System.out.print((s1 == s3) + " ");
System.out.print(s1.equals(s3));
2
3
4
5
6
- A. true true true
- B. true false true
- C. false true true
- D. false false true
答案:B。s1==s2=true(同一常量池对象),s1==s3=false(new 在堆中新建对象),s1.equals(s3)=true(比较内容)。
# new String("abc") 创建了几个对象?
- A. 1个
- B. 2个
- C. 3个
- D. 0个
答案:B。2 个对象:1 个是字符串常量池中的 "abc",1 个是堆中 new 出来的对象。
# Java 数据类型分为哪两大类?
- A. 常量类型
- B. 基本数据类型
- C. 引用数据类型
- D. 变量类型
答案:B、C。基本数据类型(8种)和引用数据类型(类、接口、数组)。
# char 类型占几个字节?
- A. 1
- B. 2
答案:B。char 在 Java 中占 2 字节,使用 Unicode 编码(UTF-16)。
# int 类型占几个字节?
- A. 1
- B. 2
- C. 3
- D. 4
答案:D。int 占 4 字节(32位)。
# continue 搭配循环的输出结果是?
for (int i = 0; i < 3; i++) {
if (i == 1) {
continue;
}
System.out.print(i + " ");
}
2
3
4
5
6
- A. 0 1 2
- B. 0 2
- C. 1
- D. 0 1
答案:B。continue 跳过 i==1 的那次输出。
# break 和 continue 的区别是?
- A. break 结束整个循环,continue 结束当前迭代
- B. break 和 continue 都结束整个循环
- C. break 结束当前迭代,continue 结束整个循环
- D. 两者的作用完全相同
答案:A。
# i++ 与 ++i 的区别是?
int i = 0;
while (i++ < 2) {
System.out.print(i + " ");
}
2
3
4
- A. 1 2
- B. 0 1
- C. 2 3
- D. 1 2 3
答案:A。i++ 是后置++,先比较后自增。
# switch 不支持哪种数据类型?
- A. int
- B. String
- C. double
- D. char
答案:C。switch 支持 byte、short、char、int、枚举、String(JDK 7+),不支持 long、float、double、boolean。
# 哪种循环至少执行一次?
- A. for 循环
- B. while 循环
- C. do-while 循环
- D. foreach 循环
答案:C。do-while 先执行后判断条件。
# 嵌套循环中 break 跳出几层?
for (int i = 1; i <= 3; i++) {
for (int j = 1; j <= 3; j++) {
if (i == j) {
break;
}
}
}
2
3
4
5
6
7
- A. 0 层
- B. 1 层
- C. 2 层
- D. 3 层
答案:B。break 默认只跳出当前层循环。
# 找数组最大值的最好复杂度是?
- A. O(1)
- B. O(n)
- C. O(n²)
- D. O(log n)
答案:B。O(n),必须遍历所有元素才能确定最大值。
# 小结
本文全面解析了 Java 核心技术知识点,从基础概念到底层原理,通过代码示例和性能压测印证每个观点。
核心内容覆盖:
- Java 语言概述与 JVM 工作原理
- 数据类型系统(基本类型、引用类型、包装类)
- String 专题(不可变性、拼接机制、intern 原理)
- 运算符与流程控制
- 常见面试题精选
希望对你有帮助。
# 关于作者
我是 SharkChili ,Java Guide 核心维护者之一,对 Redis、Nightingale 等知名开源项目有深度源码研究经验。熟悉 Java、Go 等多语言技术栈,现任某知名黑厂高级研发。
🌟 开源项目
- mini-redis:教学级 Redis 精简实现,助力分布式缓存原理学习
🔗 https://github.com/shark-ctrl/mini-redis (opens new window)(欢迎 Star & Contribute)
📚 公众号 分享企业级架构设计、性能优化、源码解析等核心技术干货。
👥 技术交流 关注公众号,回复 【加群】 获取联系方式。

- 01
- Windows 10 下的 Maven 安装配置教程05-11
- 02
- 基于 Claude Code 复刻 Redis 慢查询指令实践05-11
- 03
- VSCode与Claude Code后端开发环境搭建与AI编程工作流实践05-09
