 Java集合框架深度解析与面试指南
Java集合框架深度解析与面试指南
# 写在文章开头
又到了每年的面试旺季,看到很多读者反馈希望笔者可以根据近几年的面试对这篇文章进行补充迭代,所以笔者结合各大网站的面试题型对这篇文章进行进一步的补充和迭代。
你好,我叫sharkchili,目前还是在一线奋斗的Java开发,经历过很多有意思的项目,也写过很多有意思的文章,是CSDN Java领域的博客专家,也是Java Guide的维护者之一,非常欢迎你关注我的公众号:写代码的SharkChili,实时获取笔者最新的技术推文同时还能和笔者进行深入交流。

# Java集合的体系概览
从Java顶层设计角度分类而言,集合整体可分为两大类型:
第1大类是存放单元素的Collection,从源码的注释即可看出,该接口用于表示一组对象的抽象,该接口下的实现的集合空间或允许或不允许元素重复,JDK不提供此几口的任何直接实现,也就是说,该接口底层有包括List、Set等接口的抽象实现:
The root interface in the collection hierarchy. A collection represents a group of objects, known as its elements. Some collections allow duplicate elements and others do not. Some are ordered and others unordered. The JDK does not provide any direct implementations of this interface: it provides implementations of more specific subinterfaces like Set and List. This interface is typically used to pass collections around and manipulate them where maximum generality is desired.
第2大类则是存放键值对的Map,该类型要求键不可重复,且每个键最多可以到映射到一个值(注意这是从宏观角度说的值,该值可以是一个对象、可以是一个集合):
An object that maps keys to values. A map cannot contain duplicate keys; each key can map to at most one value.
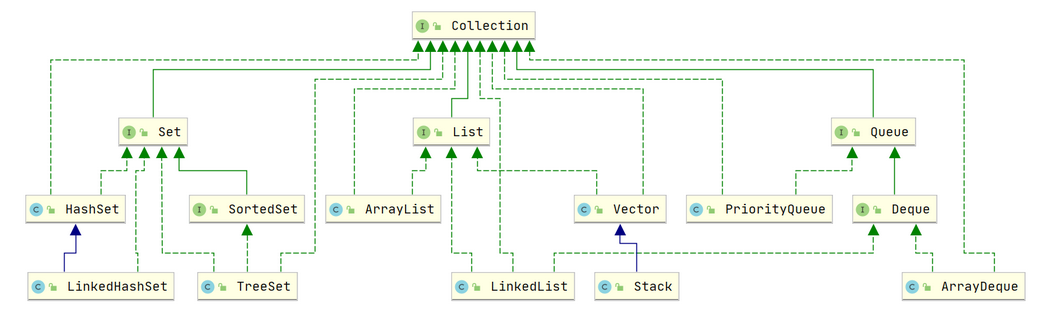
我们针对Collection接口进行展开说明,按照元素存储规则的不同我们又可以分为:
- 有序不重复的
Set集合体系。 - 有序可重复的
LIst集合体系。 - 支持
FIFO顺序的队列类型Queue。
对应的我们给出类图:
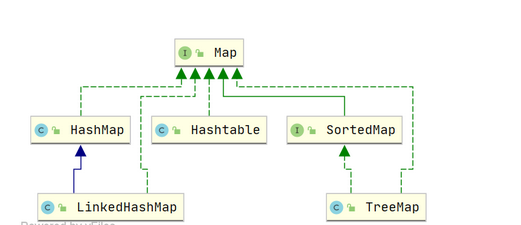
同理我们将Map接口进行展开,他的特点就是每一个元素都是由键值对组成,我们可以通过key找到对应的value,类图如下,集合具体详情笔者会在后文阐述这里我们只要有一个粗略的印象即可:
# 详解List集合体系知识点
# List集合概览
List即有序集合,该接口体系下所实现的集合可以精确控制每一个元素插入的位置,用户可以通过整数索引定位和访问元素:
An ordered collection (also known as a sequence). The user of this interface has precise control over where in the list each element is inserted. The user can access elements by their integer index (position in the list), and search for elements in the list.
从底层结构角度,有序集合还可以有两种实现,第一种也就是我们常说的ArrayList ,从ArrayList源码找到的ArrayList底层存储元素的变量elementData,可以看出ArrayList本质上就是对原生数组的封装:
transient Object[] elementData;
第2中则是LinkedList即双向链表所实现的有序集合,它由一个个节点构成,节点有双指针,分别指向前驱节点和后继节点。
private static class Node<E> {
E item;
// 指向后继节点
Node<E> next;
//指向前驱节点
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
Vector底层实现ArrayList一样都是通过空间连续的数组构成,与ArrayList的区别是它在操作时是有上锁的,这意味着多线程场景下它是可以保证线程安全的,但vector现在基本不用了,这里仅仅做个了解:
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
//......
protected Object[] elementData;
//......
}
2
3
4
5
6
7
8
# ArrayList容量是10,给它添加一个元素会发生什么?
我们不妨看看这样一段代码,可以看到我们将集合容量设置为10,第11次添加元素时,由于ArrayList底层使用的数组已满,为了能够容纳新的元素,它会进行一次动态扩容,即创建一个更大的容器将原有空间的元素拷贝过去:
//创建1个容量为10的数组
ArrayList<Integer> arrayList = new ArrayList<>(10);
//连续添加10次至空间满
for (int i = 0; i < 10; i++) {
arrayList.add(i);
}
//再次添加引发动态扩容
arrayList.add(10);
2
3
4
5
6
7
8
我们查看add源码实现细节,可以每次插入前都会调用ensureCapacityInternal来确定当前数组空间是否可以容纳新元素:
public boolean add(E e) {
//判断本次插入位置是否大于容量
ensureCapacityInternal(size + 1);
elementData[size++] = e;
return true;
}
2
3
4
5
6
查看ensureCapacityInternal的细节可知,一旦感知数组空间不足以容纳新元素时,ArrayList会创建一个新容器大小为原来的1.5倍,然后再将原数组元素拷贝到新容器中:
private void ensureCapacityInternal(int minCapacity) {
//传入当前元素空间和所需的最小数组空间大小
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
//当需求空间大于数组
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// 创建一个原有容器1.5倍的数组空间
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
//......
//将原有元素elementData拷贝到新空间去
elementData = Arrays.copyOf(elementData, newCapacity);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 针对动态扩容导致的性能问题,你有什么解决办法嘛?
我们可以提前调用ensureCapacity顶下最终容量一次性完成动态扩容提高程序执行性能。
public static void main(String[] args) {
int size = 1000_0000;
ArrayList<Integer> list = new ArrayList<>(1);
long start = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
list.add(i);
}
long end = System.currentTimeMillis();
System.out.println("无显示扩容,完成时间:" + (end - start));
//显示扩容显示扩容,避免多次动态扩容的拷贝
ArrayList<Integer> list2 = new ArrayList<>(size);
start = System.currentTimeMillis();
list2.ensureCapacity(size);
for (int i = 0; i < size; i++) {
list2.add(i);
}
end = System.currentTimeMillis();
System.out.println("显示扩容,完成时间:" + (end - start));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
输出结果如下,可以看到在显示指明大小空间的情况下,性能要优于常规插入:
无显示扩容,完成时间:6122
显示扩容,完成时间:761
2
# ArrayList和LinkedList性能差异体现在哪
我们给出两种集合的头插法的示例代码:
public static void main(String[] args) {
int size = 10_0000;
List<Integer> arrayList = new ArrayList<>();
List<Integer> linkedList = new LinkedList<>();
long start = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
arrayList.add(0, i);
}
long end = System.currentTimeMillis();
System.out.println("arrayList头插时长:" + (end - start));
start = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
linkedList.add(0, i);
}
end = System.currentTimeMillis();
System.out.println("linkedList 头插时长:" + (end - start));
start = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
((LinkedList<Integer>) linkedList).addFirst(i);
}
end = System.currentTimeMillis();
System.out.println("linkedList addFirst 耗时:" + (end - start));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
从性能表现上来看arrayList表现最差,而linkedList 的addFirst 表现最出色。
arrayList头插时长:562
linkedList 头插时长:8
linkedList addFirst 耗时:4
2
3
这里我们不妨说一下原因,arrayList性能差原因很明显,每次头部插入都需要挪动整个数组,linkedList的add方法在进行插入时,若是头插法,它会通过node方法定位头节点,然后在使用linkBefore完成头插法。
public void add(int index, E element) {
//......
if (index == size)
linkLast(element);
else
//通过node定位到头节点,再进行插入操作
linkBefore(element, node(index));
}
2
3
4
5
6
7
8
9
而链表的addFirst 就不一样,它直接定位到头节点,进行头插法,正是这一点点性能上的差距造成两者性能表现上微小的差异。
private void linkFirst(E e) {
//直接定位到头节点,进行头插法
final Node<E> f = first;
//创建新节点
final Node<E> newNode = new Node<>(null, e, f);
//直接让first 直接引用该节点
first = newNode;
//让原有头节点指向当前节点
if (f == null)
last = newNode;
else
f.prev = newNode;
//调整元素空间数量
size++;
modCount++;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
再来看看尾插法:
public static void main(String[] args) {
int size = 10_0000;
List<Integer> arrayList = new ArrayList<>();
List<Integer> linkedList = new LinkedList<>();
long start = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
arrayList.add(i, i);
}
long end = System.currentTimeMillis();
System.out.println("arrayList 尾插时长:" + (end - start));
start = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
linkedList.add(i, i);
}
end = System.currentTimeMillis();
System.out.println("linkedList 尾插时长:" + (end - start));
start = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
((LinkedList<Integer>) linkedList).addLast(i);
}
end = System.currentTimeMillis();
System.out.println("linkedList 尾插时长:" + (end - start));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
输出结果,可以看到还是链表稍快一些,为什么arraylist这里性能也还不错呢?原因也很简单,无需为了插入一个节点维护其他位置。
arrayList 尾插时长:5
linkedList 尾插时长:2
linkedList 尾插时长:3
2
3
最后再来看看随机插入,为了公平实验,笔者将list初始化工作都放在计时之外,避免arrayList动态扩容的时间影响最终实验结果:
public static void main(String[] args) {
int size = 10_0000;
//填充足够量的数据
ArrayList<Integer> arrayList = new ArrayList<>();
for (int i = 0; i < size; i++) {
arrayList.add(i);
}
//随机插入
long begin = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
arrayList.add(RandomUtil.randomInt(0, size), RandomUtil.randomInt());
}
long end = System.currentTimeMillis();
System.out.println("arrayList随机插入耗时:" + (end - begin));
//填充数据
LinkedList<Integer> linkedList = new LinkedList<>();
for (int i = 0; i < size; i++) {
linkedList.add(i);
}
//随机插入
begin = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
linkedList.add(RandomUtil.randomInt(0, size), RandomUtil.randomInt());
}
end = System.currentTimeMillis();
System.out.println("linkedList随机插入耗时:" + (end - begin));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
从输出结果来看,随机插入也是arrayList性能较好,原因也很简单,arraylist随机访问速度远远快与linklist:
arrayList随机插入耗时:748
linkedList随机插入耗时:27741
2
针对两者的性能差异,笔者也在这里进行一下简单的小结:
- 头插法,由于
LinkedList节点维护只需管理原有头节点和新节点的关系,无需大费周章的调整整个地址空间,相较于ArrayList,它的表现会相对出色一些。 - 尾插法:和头插法类似,除非动态扩容,ArrayList无需进行大量的元素转移,所以大体上两者性能差异不是很大,总的来说
linkedList会稍胜一筹。 - 随机插入:
ArrayList在进行元素定位时只需O(1)的时间复杂度,相较于LinkedList需要全集合扫描来说,这些时间开销使得前者性能表现更加出色。
# ArrayList 和 Vector 的异同
这个问题我们可以从以下两个维度分析:
先来说说底层数据结构,两者底层存储都是采用数组,ArrayList存储用的是new Object[initialCapacity];
public ArrayList(int initialCapacity) {
//给定容量后初始化定长数组存储元素
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
2
3
4
5
6
7
8
9
10
11
Vector底层存储元素用的也是是 new Object[initialCapacity];,即一个对象数组:
public Vector(int initialCapacity, int capacityIncrement) {
//......
//基于定长容量初始化数组
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
2
3
4
5
6
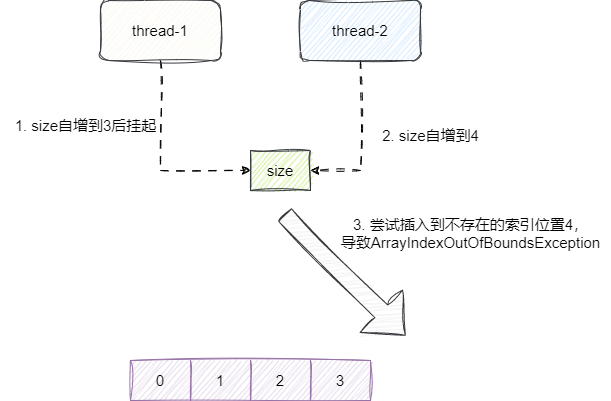
从并发安全角度来说,Vector 为线程安全类,ArrayList 线程不安全,如下所示我们使用ArrayList进行多线程插入出现的索引越界问题。
List<Integer> list = new ArrayList<>();
CountDownLatch countDownLatch = new CountDownLatch(2);
Thread t1 = new Thread(() -> {
//插入1000个元素
for (int i = 0; i < 1000; i++) {
list.add(i);
}
//完成后按下倒计时门闩
countDownLatch.countDown();
});
Thread t2 = new Thread(() -> {
//插入1000个元素
for (int i = 0; i < 1000; i++) {
list.add(i);
}
//完成后按下倒计时门闩
countDownLatch.countDown();
});
t1.start();
t2.start();
countDownLatch.await();
System.out.println(list.size());
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
因为多线程访问的原因,底层索引不安全操作的自增,导致插入时得到一个错误的索引位置导致ArrayIndexOutOfBoundsException:
对应我们也给出ArrayList可能存在隐患的代码段,可以多线程情况下ensureCapacityInternal的预扩容到元素添加这段操作的size,很可能因为并发计算的线程不安全性导致各种异常:
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
2
3
4
5
相较之下,vector的add方法有加synchronized 关键字,保证单位时间内只有一个线程可以操作底层的数组,由此保证了有序集合操作的准确性:
//任何操作都是上锁的,保证一次插入操作互斥和原子性
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
2
3
4
5
6
7
# ArrayList 与 LinkedList 的区别
从上文中我们基本可以了解两者区别,这里我们就做一个简单的小结:
- 底层存储结构:
ArrayList底层使用的是数组,LinkedList底层使用的是链表 - 线程安全性:两者都是线程不安全,因为
add方法都没有任何关于线程安全的处理。 - 随机访问性:虽然两者都支持随机访问,但是链表随机访问不太高效。
- 内存空间占用:
ArrayList的空间浪费主要体现在在List列表的结尾会预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗比ArrayList更多的空间(因为要存放直接后继和直接前驱以及数据)。
# ArrayList 的扩容机制
Java的ArrayList 底层默认数组大小为10,的动态扩容机制即ArrayList 确保元素正确存放的关键,了解核心逻辑以及如何基于该机制提高元素存储效率也是很重要的,感兴趣的读者可以看看读者编写的这篇博客:
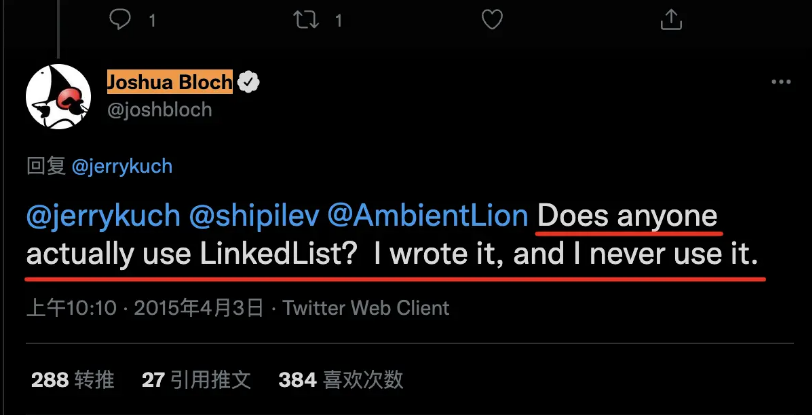
尽管从上面来看两者各有千秋,但比较有趣的是,LinkedList的作者Josh Bloch基本没有用过这个集合:
# 详解Map集合
# Map接口定义概览
Map即映射集,是线上就是将对应的key映射到对应value上,由此构成一个数学上的映射的概念,该适合存储不可重复键值对类型的元素,key不可重复,value可重复,我们可以通过key找到对应的value:
An object that maps keys to values. A map cannot contain duplicate keys; each key can map to at most one value.
# HashMap(重点)
JDK1.8的HashMap默认是由数组+链表/红黑树组成,通过key算得hash寻址从而定位到Map底层数组的索引位置。
在进行put操作时,若冲突时使用拉链法解决冲突,如下面这段代码所示,当相同索引位置存储的是链表时,它会进行for循环定位到相同hash值的索引位置的尾节点进行追加。当链表长度大于8且数组长度大于64的情况下,链表会进行树化变成红黑树,减少元素搜索时间。
注意 : 若长度小于64链表长度大于8只会HashMap底层数组的扩容操作,对此我们给出Map进行put操作时将元素添加到链表结尾的代码段,可以看到当链表元素大于等于8时会尝试调用treeifyBin进行树化操作:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
//......
for (int binCount = 0; ; ++binCount) {
//遍历找到空位尝试插入
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//如果链表元素加上本次插入元素大于8( TREEIFY_THRESHOLD )时,则尝试进行树化操作
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
//.......
}
//......
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
对应我们步入treeifyBin即可直接印证我们的逻辑,当底层数组空间小于64时只会进行数组扩容,而非针对当前bucket的树化操作:
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
//若当前数组空间小于64则直接会进行数组空间扩容
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {//反之进行树化操作
TreeNode<K,V> hd = null, tl = null;
do {
//......
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 更多关于HashMap的知识
Java集合hashMap小结:https://blog.csdn.net/shark_chili3007/article/details/123241124 (opens new window)
# 更多关于LinkedHashMap
LinkedHashMap继承自HashMap,他在HashMap基础上增加双向链表,由于LinkedHashMap维护了一个双向链表来记录数据插入的顺序,因此在迭代遍历生成的迭代器的时候,是按照双向链表的路径进行遍历的,所以遍历速度远远快于HashMap,具体可以查阅笔者写的这篇文章:
Java集合LinkedHashMap小结:https://blog.csdn.net/shark_chili3007/article/details/107249595 (opens new window)
# 更多ConcurrentHashMap
# 详解Hashtable核心添加操作
Hashtable底层也是由数组+链表(主要用于解决冲突)组成的,操作时都会上锁,可以保证线程安全,底层数组是 Hashtable 的主体,在插入发生冲突时,会通过拉链法即将节点追加到同索引位置的节点后面:
public synchronized V put(K key, V value) {
//......
//插入元素寻址操作
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
//修改操作时,通过遍历对应index位置的链表完成覆盖操作
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
//发生冲突时,会将节点追加到同索引位置的节点后面
addEntry(hash, key, value, index);
return null;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 详解Set集合
# Set基本核心概念
Set集合不可包重复的元素,即如果两个元素在equals方法下判定为相等就只能存储其中一个,这意味着该集合也最多包含一个null的元素,它常用于一些需要进行去重的场景。
A collection that contains no duplicate elements. More formally, sets contain no pair of elements e1 and e2 such that e1.equals(e2), and at most one null element. As implied by its name, this interface models the mathematical set abstraction.
Set有两种我们比较熟悉的实现:
HashSet:HashSet要求数据唯一,但是存储是无序的(底层通过Hash算法实现寻址),所以基于面向对象思想复用原则,Java设计者就通过聚合关系封装HashMap,基于HashMap的key实现了HashSet:
//HashSet底层复用了Map的put方法,value统一使用PRESENT对象
private static final Object PRESENT = new Object();
public boolean add(E e) {
// 返回null说明当前插入时并没有覆盖相同元素
return map.put(e, PRESENT)==null;
}
2
3
4
5
6
7
LinkedHashSet:LinkedHashSet即通过聚合封装LinkedHashMap实现的。TreeSet:TreeSet底层也是TreeMap,一种基于红黑树实现的有序树O(logN)级别的黑平衡树:
A Red-Black tree based NavigableMap implementation. The map is sorted according to the natural ordering of its keys, or by a Comparator provided at map creation time, depending on which constructor is used.
关于红黑树可以参考笔者之前写过的这篇文章:
数据结构与算法之红黑树小结:https://blog.csdn.net/shark_chili3007/article/details/108382322) (opens new window)
对应的从源码中我们也可以看出TreeSet底层是对TreeMap的复用:
public TreeSet() {
this(new TreeMap<E,Object>());
}
2
3
# HashMap 和 Hashtable 的区别(重点)
针对该问题,笔者建议从以下5个角度进行探讨:
从线程安全角度:HashMap 操作是线程不安全、Hashtable 是线程安全,这一点我们已经在上文中源码进行了相应的介绍,这里就不多做赘述了。
从底层数据结构角度:HashMap 初始情况是数组+链表,特定情况下会变数组+红黑树,Hashtable 则是数组+链表。
从保存数值角度:HashMap 允许null键或null值,而Hashtable则不允许null的value,这一点我们可以直接查看的Hashtable的put方法:
public synchronized V put(K key, V value) {
// 如果value为空则抛出空指针异常
if (value == null) {
throw new NullPointerException();
}
//......
}
2
3
4
5
6
7
从初始容量角度考虑:HashMap默认16,对此我们可以通过直接查看源码的定义印证这一点:
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
同时HashMap进行扩容时都是基于当前容量*2,这一点我们可以直接通过resize印证:
final Node<K,V>[] resize() {
//......
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
//基于原有数组容量*2得到新的数组空间完成map底层数组扩容
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
//......
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Hashtable 默认的初始大小为 11,之后每次扩充,容量变为原来的 2n+1:
//初始化容量为11
public Hashtable() {
this(11, 0.75f);
}
//扩容方法
protected void rehash() {
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
//扩容的容量基于原有空间的2倍+1
int newCapacity = (oldCapacity << 1) + 1;
//......
}
2
3
4
5
6
7
8
9
10
11
12
13
14
从性能角度考虑:Hashtable 针对冲突总是通过拉链法解决问题,长此以往可能会导致节点查询复杂度退化为O(n)相较于HashMap在达到空间阈值时通过红黑树进行bucket优化来说性能表现会逊色很多。
# HashMap 和 HashSet有什么区别
HashSet 聚合了HashMap ,通俗来说就是将HashMap 的key作为自己的值存储来使用:
//HashSet底层本质是通过内部聚合的map完成元素插入操作
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
2
3
4
# HashMap 和 TreeMap 有什么区别
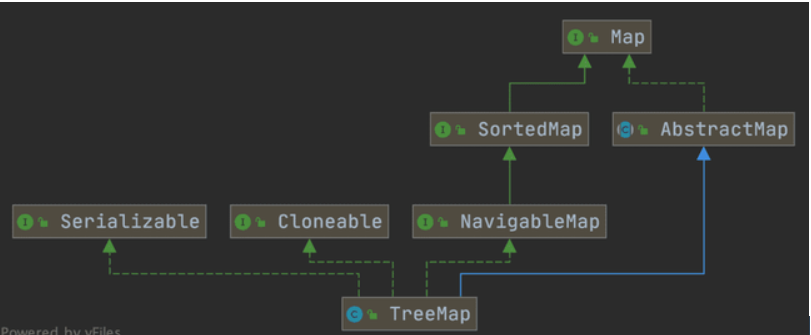
类图如下,TreeMap 底层是有序树,所以对于需要查找最大值或者最小值等场景,TreeMap 相比HashMap更有优势。因为他继承了NavigableMap接口和SortedMap 接口。
如下源码所示,我们需要拿最大值或者最小值可以用这种方式或者最大值或者最小值
Object o = new Object();
//创建并添加元素
TreeMap<Integer, Object> treeMap = new TreeMap<>();
treeMap.put(3213, o);
treeMap.put(434, o);
treeMap.put(432, o);
treeMap.put(2, o);
treeMap.put(432, o);
treeMap.put(31, o);
//顺序打印
System.out.println(treeMap);
//拿到第一个key
System.out.println(treeMap.firstKey());
//拿到最后一个key
System.out.println(treeMap.lastEntry());
2
3
4
5
6
7
8
9
10
11
12
13
14
15
输出结果:
{2=231, 31=231, 432=231, 434=231, 3213=231}
2
3213=231
2
3
# HashSet实现去重插入的底层工作机制了解嘛?
当你把对象加入HashSet时其底层执行步骤为:
HashSet会先计算对象的hashcode值定位到bucket。- 若
bucket存在元素,则与其hashcode值作比较,如果没有相符的hashcode,HashSet会认为对象没有重复出现,直接允许插入了。 - 但是如果发现有相同
hashcode值的对象,这时会调用equals()方法来检查hashcode相等的对象是否真的相同。 - 如果两者相同,
HashSet就会将其直接覆盖返回插入前的值。
对此我们给出HashSet底层的去重的实现,本质上就算map的putVal方法:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
//......
//bucet不存在元素则直接插入
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//若存在元素,且hash、key、equals相等则覆盖元素并返回旧元素
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
//......
//若存在元素,且hash、key、equals相等则覆盖元素并返回旧元素
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//返回旧有元素的值
if (e != null) { // existing mapping for key
V oldValue = e.value;
//......
return oldValue;
}
}
//......
return null;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# HashSet、LinkedHashSet 和 TreeSet 使用场景
HashSet:可在不要求元素有序但唯一的场景。LinkedHashSet:可用于要求元素唯一、插入或者访问有序性的场景,或者FIFO的场景。TreeSet:要求支持有序性且按照自定义要求进行排序的元素不可重复的场景。
# 优先队列PriorityQueue
关于优先队列的文章,笔者已将该文章投稿给了Javaguide,感兴趣的读者可以参考一下这篇文章:
# Java集合使用以及工具类小结
Java集合使用以及工具类小结 (opens new window)
# 一道比较偏门的校招笔试题
以下代码分别输出多少?
List a=new ArrayList<String>();
a.add(null);
a.add(null);
a.add(null);
System.out.println(a.size());//3
Map map=new HashMap();
map.put("a",null);
map.put("a",null);
map.put("a",null);
System.out.println(map.size());//1
2
3
4
5
6
7
8
9
10
# 迭代器遍历时如何正确删除元素
Iterator it = list.iterator();
int index = 0;
while (it.hasNext()) {
Object obj = it.next();
if (needDelete(obj)) {
// 哪种删除方式是正确的?
}
}
2
3
4
5
6
7
8
- A.
it.remove() - B.
list.remove(obj) - C.
list.remove(index) - D.
list.remove(obj, index)
解析:
- 选项A正确:
it.remove()是正确方式 - 选项B错误:
list.remove(obj)会导致ConcurrentModificationException(并发修改异常) - 选项C错误:
list.remove(index)索引不匹配,且会导致异常 - 选项D错误:不存在此方法
原因:迭代器遍历时使用list.remove()修改集合,会导致modCount(修改次数)与expectedModCount(期望修改次数)不一致,触发并发修改异常。
源码印证:以ArrayList的内部迭代器为例:
// ArrayList.Itr的remove方法
public E remove(int index) {
rangeCheck(index);
checkForComodification(); // 先检查是否并发修改
E result = parent.remove(parentOffset + index);
this.modCount = parent.modCount; // 同步modCount
this.size--;
return result;
}
// 检查并发修改的核心方法
private void checkForComodification() {
if (ArrayList.this.modCount != this.modCount)
throw new ConcurrentModificationException();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
注意:list.remove()会改变ArrayList的modCount,但不会同步更新迭代器中的this.modCount,导致两者不一致,触发异常。而Iterator.remove()会同时更新两者,所以是安全的。
// 错误写法 - 会抛出ConcurrentModificationException
Iterator it = list.iterator();
while (it.hasNext()) {
if (condition) {
list.remove(it.next()); // ❌ 错误
}
}
// 正确写法
Iterator it = list.iterator();
while (it.hasNext()) {
if (condition) {
it.remove(); // ✅ 正确
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 关于ArrayList的哪个说法是正确的(多选)
- A. ArrayList是同步的
- B. ArrayList允许元素为null
- C. ArrayList提供快速的随机访问
- D. ArrayList的元素保持其插入顺序
正确答案:B、C、D
解析:
选项A错误:ArrayList是非同步的,线程不安全。在单线程环境下建议使用ArrayList,如果需要线程安全可以使用Vector或Collections.synchronizedList()包装。
选项B正确:ArrayList允许存储null元素,可以有多个null值。这与HashMap类似,允许键或值为null。
选项C正确:ArrayList底层是基于数组实现,通过索引可以实现O(1)的随机访问,这是ArrayList的主要优势之一,对应我们给出ArrayList的源码实现:
// ArrayList的get方法,直接通过数组索引访问
public E get(int index) {
rangeCheck(index); // 检查索引是否越界
return elementData(index); // 直接返回数组对应位置的元素
}
// 底层就是数组的索引访问
E elementData(int index) {
return (E) elementData[index]; // 直接通过数组下标获取,时间复杂度O(1)
}
2
3
4
5
6
7
8
9
10
ArrayList的随机访问效率很高,因为底层是数组,可以通过索引直接计算内存地址偏移量获取元素,时间复杂度为O(1)。而LinkedList的随机访问需要遍历链表,时间复杂度为O(n)。
选项D正确:ArrayList维护元素的插入顺序,遍历时元素的顺序与插入顺序一致。
ArrayList<String> list = new ArrayList<>();
list.add("A"); // 插入顺序: A
list.add(null); // 允许null
list.add("B"); // 插入顺序: A, null, B
list.add("A"); // 可以有重复元素
list.get(0); // O(1)随机访问,返回"A"
2
3
4
5
6
7
ArrayList和Vector的区别主要在于线程安全性和性能。ArrayList是非同步的,性能更高,适合单线程环境;Vector是同步的,性能较低,适合多线程环境。另外ArrayList的扩容策略是原容量的1.5倍,而Vector默认是2倍。如果在多线程环境下需要高性能的List,可以考虑使用CopyOnWriteArrayList。
# Set和List的主要区别是?(多选)
A. Set接口允许重复元素,而List不允许
B. List接口允许元素的重复,而Set不允许
C. Set没有定义顺序,而List定义了元素的顺序
D. 以上所有说法都是正确的
正确答案:B、C
解析:
选项A错误:Set接口不允许重复元素,而List允许重复元素。Set集合通过hashCode()和equals()方法来保证元素的唯一性。
Set<String> set = new HashSet<>();
set.add("A");
set.add("A"); // 不允许重复,第二个"A"不会添加进去
System.out.println(set); // 输出: [A]
List<String> list = new ArrayList<>();
list.add("A");
list.add("A"); // 允许重复,list中现在有两个"A"
System.out.println(list); // 输出: [A, A]
2
3
4
5
6
7
8
9
选项B正确:List接口允许元素的重复,而Set不允许重复。
Set<String> set = new HashSet<>();
set.add("A");
set.add("A"); // 不允许重复,第二个"A"不会添加进去
System.out.println(set); // 输出: [A]
List<String> list = new ArrayList<>();
list.add("A");
list.add("A"); // 允许重复
System.out.println(list); // 输出: [A, A]
2
3
4
5
6
7
8
9
选项C正确:从接口层面看,Set接口不保证元素顺序,而List接口保证元素按插入顺序存储。
// List有序
List<String> list = new ArrayList<>();
list.add("C");
list.add("A");
list.add("B");
System.out.println(list); // 输出: [C, A, B],保持插入顺序
// HashSet无序(Set不保证顺序)
Set<String> hashSet = new HashSet<>();
hashSet.add("3");
hashSet.add("1");
hashSet.add("2");
System.out.println(hashSet); // 输出顺序不确定
// TreeSet有序(虽然有序,但不是插入顺序)
Set<String> treeSet = new TreeSet<>();
treeSet.add("3");
treeSet.add("1");
treeSet.add("2");
System.out.println(treeSet); // 输出: [1, 2, 3],按自然顺序
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
选项D错误:因为选项A不正确,所以"以上所有说法都正确"的结论不成立。
# 小结
我是sharkchili,CSDN Java 领域博客专家,开源项目—JavaGuide contributor,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili,同时我的公众号也有我精心整理的并发编程、JVM、MySQL数据库个人专栏导航。

# 面试真题
# 1. 以下关于ArrayList和LinkedList的说法正确的是?(多选)
答案:A B C D
| 选项 | 说法 | 正确性 | 说明 |
|---|---|---|---|
| A | ArrayList底层是数组,LinkedList底层是双向链表 | ✅ | |
| B | ArrayList随机访问O(1) | ✅ | 数组下标访问 |
| C | LinkedList头插比ArrayList效率高 | ✅ | O(1) vs O(n) |
| D | 两者iterator都是fail-fast | ✅ | modCount机制 |
# 2. 以下关于HashSet的说法正确的是?
答案:A
| 选项 | 说法 | 正确性 | 说明 |
|---|---|---|---|
| A | HashSet允许存储null元素 | ✅ | HashMap允许一个null键 |
| B | HashSet保证插入顺序 | ❌ | 不保证 |
| C | HashSet底层是数组 | ❌ | 底层是HashMap |
| D | HashSet的contains是O(n) | ❌ | 是O(1) |
# 3. 以下关于HashSet底层实现的说法正确的是?
答案:A B C D
| 选项 | 说法 | 正确性 | 说明 |
|---|---|---|---|
| A | HashSet底层使用HashMap存储 | ✅ | |
| B | HashSet的add方法调用HashMap的put | ✅ | |
| C | HashSet使用Object作为HashMap的value | ✅ | PRESENT占位符 |
| D | 以上说法都正确 | ✅ | A B C都正确 |
# 4. 以下关于TreeMap的说法正确的是?
答案:A C
| 选项 | 说法 | 正确性 | 说明 |
|---|---|---|---|
| A | TreeMap基于红黑树实现 | ✅ | |
| B | TreeMap保证自然顺序排列 | ❌ | key需实现Comparable |
| C | TreeMap不允许null键 | ✅ | compare(key,key)会抛NPE |
| D | 以上说法都正确 | ❌ | B错误 |
# 5. 以下关于ArrayList扩容机制的说法正确的是?(多选)
答案:A B C
| 选项 | 说法 | 正确性 | 说明 |
|---|---|---|---|
| A | 默认初始容量是10 | ✅ | DEFAULT_CAPACITY = 10 |
| B | 扩容时容量变为原来的1.5倍 | ✅ | newCapacity = oldCapacity + oldCapacity/2 |
| C | 使用Arrays.copyOf()进行扩容 | ✅ | 复制数组 |
| D | 扩容操作是线程安全的 | ❌ | ArrayList非线程安全 |
扩容公式:newCapacity = oldCapacity + (oldCapacity >> 1)
# 6. 以下关于Queue接口的说法正确的是?(多选)
答案:A C
| 选项 | 说法 | 正确性 | 说明 |
|---|---|---|---|
| A | Queue继承自Collection | ✅ | extends Collection |
| B | offer()失败时抛异常 | ❌ | 返回false |
| C | poll()队列为空时返回null | ✅ | 返回特殊值 |
| D | element()队列为空时返回null | ❌ | 抛NoSuchElementException |
# 7. 以下关于Deque接口的说法正确的是?
答案:A B C D
| 选项 | 说法 | 正确性 | 说明 |
|---|---|---|---|
| A | Deque是双端队列 | ✅ | 两端都可插入/删除 |
| B | Deque可以用于实现栈 | ✅ | push/pop方法 |
| C | ArrayDeque是Deque的实现类 | ✅ | |
| D | 以上说法都正确 | ✅ | A B C都正确 |
# 8. 以下关于LinkedList的说法正确的是?(多选)
答案:A B C D
| 选项 | 说法 | 正确性 | 说明 |
|---|---|---|---|
| A | LinkedList实现List和Deque接口 | ✅ | |
| B | LinkedList可以作为栈使用 | ✅ | push/pop |
| C | LinkedList可以作为队列使用 | ✅ | offer/poll |
| D | LinkedList的addFirst是O(1) | ✅ | 只需修改指针 |
# 9. 以下关于HashMap和Hashtable的说法正确的是?
答案:A B C D
| 选项 | 说法 | 正确性 | 说明 |
|---|---|---|---|
| A | Hashtable是线程安全的 | ✅ | synchronized方法 |
| B | Hashtable不允许null键和null值 | ✅ | 同步方法中无法区分 |
| C | Hashtable迭代器是fail-fast | ✅ | modCount机制 |
| D | 以上说法都正确 | ✅ | A B C都正确 |
# 10. 以下关于LinkedHashSet的说法正确的是?
答案:A B C D
| 选项 | 说法 | 正确性 | 说明 |
|---|---|---|---|
| A | LinkedHashSet保证插入顺序 | ✅ | 双向链表维护 |
| B | LinkedHashSet底层使用LinkedHashMap | ✅ | |
| C | LinkedHashSet迭代顺序是插入顺序 | ✅ | |
| D | 以上说法都正确 | ✅ | A B C都正确 |
# 11. 以下关于TreeSet的说法正确的是?(多选)
答案:A B C D
| 选项 | 说法 | 正确性 | 说明 |
|---|---|---|---|
| A | TreeSet基于TreeMap实现 | ✅ | |
| B | TreeSet保证元素有序 | ✅ | 红黑树 |
| C | TreeSet不允许null元素 | ✅ | compareTo会抛NPE |
| D | TreeSet迭代器是fail-fast | ✅ | modCount机制 |
# 12. 以下关于Arrays.asList的说法正确的是?
答案:B C
| 选项 | 说法 | 正确性 | 说明 |
|---|---|---|---|
| A | 返回的是java.util.ArrayList | ❌ | 返回Arrays$ArrayList |
| B | 返回的List长度是固定的 | ✅ | 底层是原数组引用 |
| C | add或remove会抛异常 | ✅ | UnsupportedOperationException |
| D | 以上说法都正确 | ❌ | A错误 |
# 13. 以下关于List.subList的说法正确的是?
答案:A B C D
| 选项 | 说法 | 正确性 | 说明 |
|---|---|---|---|
| A | subList返回的是原List的视图 | ✅ | SubList持有原List引用 |
| B | 对subList的修改会影响原List | ✅ | 共享底层结构 |
| C | 对原List的修改可能导致subList异常 | ✅ | checkForComodification |
| D | 以上说法都正确 | ✅ | A B C都正确 |
# 14. 以下关于List与数组的说法正确的是?(多选)
答案:A B C D
| 选项 | 说法 | 正确性 | 说明 |
|---|---|---|---|
| A | List可以存储不同类型的对象(泛型除外) | ✅ | |
| B | 数组可以存储基本类型和对象 | ✅ | int[] vs Object[] |
| C | 数组的大小固定 | ✅ | length是final |
| D | List可以通过add和remove动态改变大小 | ✅ | 自动扩容 |
# 15. 以下关于排序算法的说法正确的是?
答案:A B C
| 选项 | 说法 | 正确性 | 说明 |
|---|---|---|---|
| A | 快排时间复杂度O(NlogN) | ✅ | 平均复杂度 |
| B | 计数排序可以实现O(N) | ✅ | 数据范围固定时 |
| C | Arrays.sort使用双路快排 | ✅ | JDK 7+ DualPivotQuicksort |
| D | 冒泡排序时间复杂度O(NlogN) | ❌ | 是O(N²) |
# 16. 时间复杂度怎么表示?能不能举个o logN的案例?oLogn怎么实现
用大 O 表示法,描述算法执行时间随数据规模增长的趋势:
| 复杂度 | 举例 |
|---|---|
| O(1) | HashMap 查找、数组按下标访问 |
| O(logN) | 二分查找、跳表查找、平衡二叉树查找 |
| O(N) | 遍历数组、链表查找 |
| O(NlogN) | 归并排序、快速排序(平均) |
| O(N²) | 冒泡排序、双重 for 循环 |
O(logN) 的本质:每次操作将数据规模减半(分治思想)
# 17. 写个二分查找? log2 16是多少
log₂16 = 4(因为 2⁴ = 16)
public int binSearch(int[] arr, int target) {
int left = 0;
int right = arr.length - 1;
while (left <= right) {
int mid = (left + right) >>> 1;
if (arr[mid] == target) {
return mid;
} else if (arr[mid] > target) {
right = mid - 1;
} else {
left = mid + 1;
}
}
return -1;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
关键点:left <= right(不是 <),>>> 1 无符号右移防溢出
# 18. 有很多数字?0-几十万?要给他排序,最快的方法?
单线程快排:
- 时间复杂度 O(NlogN),常数因子小,实际性能好
- 适用于内存排序
多线程并行排序:
- ForkJoinPool + Arrays.parallelSort(),自动分片并行排序
- 充分利用多核 CPU
外部排序:
- 数据量超过内存时,分片读入内存 → 快排 → 归并写磁盘
- 适用于百万级数据
计数排序/基数排序:
- 数据范围固定时(如 0~几十万),可做到 O(N)
- 适用于整数范围已知的场景
计数排序原理:
- 不比较,用数组下标天然有序的特性
- 遍历数组统计每个数出现次数,再按次数输出
计数排序核心步骤:
第一步: 找出最小值和最大值,确定数值范围
原数组: [3, 4, 2, 3, 4, 1, 4]
min=1, max=4, range=4
2
3
4
5
第二步: 创建计数数组,统计每个数字出现的次数
数值: 1 2 3 4
下标: 0 1 2 3
计数数组: [ 1, 1, 2, 3 ]
↑ ↑ ↑ ↑
| | | +-- 4出现3次
| | +------- 3出现2次
| +------------ 2出现1次
+----------------- 1出现1次
2
3
4
5
6
7
8
9
10
第三步: 计算前缀和,将计数数组转为位置数组
计数数组: [ 1, 1, 2, 3 ]
↓ ↓ ↓ ↓
前缀和: [ 1, 2, 4, 7 ]
↑ ↑ ↑ ↑
| | | +-- 小于等于4的有7个,放位置0-6
| | +------- 小于等于3的有4个,放位置0-3
| +------------ 小于等于2的有2个,放位置0-1
+----------------- 小于等于1的有1个,放位置0
2
3
4
5
6
7
8
9
10
第四步: 从后向前遍历原数组(保证稳定性)
原数组: [3, 4, 2, 3, 4, 1, 4]
↑
当前元素4
位置数组: [ 1, 2, 4, 7 ]
↓
--countArray[3] = 6
↓
结果数组: [ _, _, _, _, _, _, 4 ]
↑
4放在位置6
继续遍历: 元素1 → 放位置0
元素4 → 放位置5
元素3 → 放位置3
元素2 → 放位置1
元素4 → 放位置4
元素3 → 放位置2
最终结果: [ 1, 2, 3, 3, 4, 4, 4 ]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
为什么逆序遍历保证稳定性?
原数组: [3a, 4, 2, 3b, 4, 1, 4]
↑
3b在3a右边
逆序遍历时:
3b先处理 → 放位置3
3a后处理 → 放位置2
结果: [1, 2, 3a, 3b, 4, 4, 4]
↑ ↑
3a仍在3b左边,保持原顺序 ✓ 稳定
2
3
4
5
6
7
8
9
10
11
正序遍历时(错误做法):
3a先处理 → 放位置2
3b后处理 → 放位置3
结果: [1, 2, 3a, 3b, 4, 4, 4]
↑ ↑
看似正确?其实问题在前缀和机制:
前缀和数组: [1, 2, 4, 7]
正序遍历时:
元素3a: --countArray[2] = 3, 放位置3
元素3b: --countArray[2] = 2, 放位置2
结果: [1, 2, 3b, 3a, 4, 4, 4]
↑ ↑
3b跑到了3a左边 ✗ 不稳定
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
完整代码实现:
/**
* 计数排序
* 时间复杂度: O(n + k),n是数组长度,k是数值范围
* 空间复杂度: O(k)
* 稳定性: 稳定
*/
public static int[] countingSort(int[] sourceArray) {
if (sourceArray == null || sourceArray.length <= 1) {
return sourceArray;
}
// 第一步: 找出数组中的最小值和最大值
int minValue = sourceArray[0];
int maxValue = sourceArray[0];
for (int i = 1; i < sourceArray.length; i++) {
if (sourceArray[i] < minValue) minValue = sourceArray[i];
if (sourceArray[i] > maxValue) maxValue = sourceArray[i];
}
// 第二步: 创建计数数组,统计每个数字出现的次数
int range = maxValue - minValue + 1;
int[] countArray = new int[range];
for (int num : sourceArray) {
countArray[num - minValue]++;
}
// 第三步: 计算前缀和,将计数数组转换为位置数组
int prefixSum = 0;
for (int i = 0; i < countArray.length; i++) {
prefixSum += countArray[i];
countArray[i] = prefixSum;
}
// 第四步: 从后向前遍历原数组,根据位置数组将元素放入结果数组
int[] sortedArray = new int[sourceArray.length];
for (int i = sourceArray.length - 1; i >= 0; i--) {
int position = --countArray[sourceArray[i] - minValue];
sortedArray[position] = sourceArray[i];
}
return sortedArray;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
适用场景:
- 数据范围固定且较小(如0~几十万)
- 需要稳定排序
- 数据量大但对内存不敏感
# 参考文献
Java集合常见面试题总结(上):https://javaguide.cn/java/collection/java-collection-questions-01.html#arraylist-简介 (opens new window)
ArrayList源码&扩容机制分析:https://javaguide.cn/java/collection/arraylist-source-code.html#arraylist-简介 (opens new window)
计数排序可视化讲解(YouTube):https://www.youtube.com/watch?v=IcIig2uY0YI (opens new window)
计数排序算法详解(掘金):https://juejin.cn/post/6844903704273879048 (opens new window)
