 动手复刻redis之go语言下的字典的设计与落地
动手复刻redis之go语言下的字典的设计与落地
# 写在文章开头
近期一直在忙碌和梳理自己过去的一些文章,所以对于mini-redis的字典指令的复刻的安排稍微延误了一些些。在复刻过程中笔者针对redis的字典指令进行了完整的梳理,为了更加专注于指令的内部设计的思想的复刻,所有指令操作都是通过哈希集这个编码实现,再通过抽取核心逻辑按照原汁原味的函数名和函数逻辑,相信对于某些对原生redis源码感兴趣的读者来说,这份开源项目是有一定的参考价值的。
话不多说,本文将从mini-redis逐个实现的指令的角度对于字典指令实现和设计细节进行深入的拆解和分析,希望对你有帮助。

Hi,我是 sharkChili ,是个不断在硬核技术上作死的技术人,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。

# 详解mini-redis字典的指令的实现
# hset设置字典单键值对
字典操作的单键值对设置都是通过hset指令实现,例如:hset user name xiaoming就是对一个key为user的字典对象设置一个字段为age、值为xiaoming的键值对。
而hset指令的实现细节也比较简单,我们还是以上面那条指令为例,它首先解析用户传入指令,得出要操作的key为user,找到后将name和xiaoming这个键值对插入,如果这个键值对之前存在说明本次操作是覆盖操作,则返回用户0,反之说明本次键值对操作是插入操作则返回1:
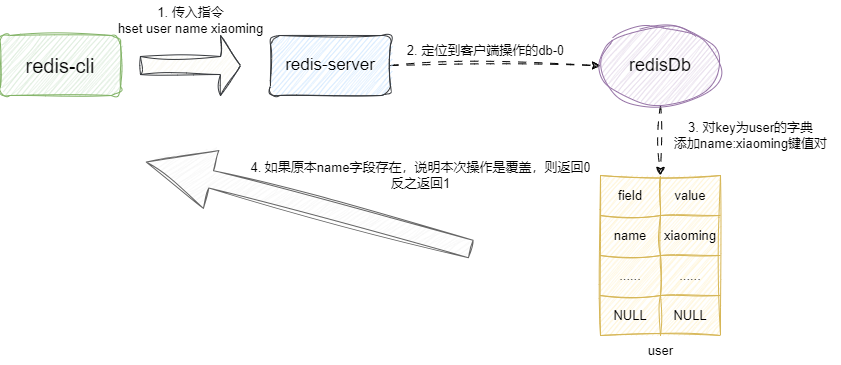
对此,笔者给给出的自己的实现,逻辑步骤和上述说的基本一致,大体为:
- 检查和校验字典是否存在,如果存在但不是字典则响应错误,反之返回字典对象指针,当然如果不存在则说明本次传入指令的字典还没创建,内部完成创建并返回指针。
- 针对上一步返回的指针进行空校验,如果不存在则直接结束该函数。
- 针对
argv[2]、c.argv[3]进行类型优化,如果字符串可以转为数字类型则进行转换。 - 调用
hashTypeSet将字典对象、键值对传入,返回更新结果。 - 如果
update返回1说明本次操作的字段存在,返回用户本次插入0条,反之返回1告知用户你的字段是新插入的。
func hsetCommand(c *redisClient) {
/**
check if the dict object exists, and if it does not exist, create hash obj
if it exists, then determine whether it is a hash obj. If not, return a type error.
*/
o := hashTypeLookupWriteOrCreate(c, c.argv[1])
if o == nil {
return
}
//try to convert strings that can be converted to numerical types into numerical types.
hashTypeTryObjectEncoding(o, &c.argv[2], &c.argv[3])
/**
pass the information to the database to find the dictionary object along with the fields and values,
return the dict update count
*/
update := hashTypeSet(o, c.argv[2], c.argv[3])
//if it is an update operation, return 0; if it is the first insertion of a field, return 1.
if update == 1 {
addReply(c, shared.czero)
} else {
addReply(c, shared.cone)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
我们先来看看hashTypeLookupWriteOrCreate传入c.argv[1]即我们指令的第二个字符串也就是key的值,检查这个字典是否存在,该方法内部有如下几个判断:
- 如果
key对应的类型存在但不是字典类型,则告知用户类型异常,并返回nil。 - 如果
key存在且是字典的值,则直接返回给对象的指针。 - 如果
key不存在,则创建一个字典并存入内存数据库并返回该字典指针。
对此我们给出这段代码的的实现细节,读者可自行参阅:
func hashTypeLookupWriteOrCreate(c *redisClient, key *robj) *robj {
//check if the dictionary exists.
o := lookupKeyWrite(c.db, key)
//if it is nil, create a hash object and add to redisDb.
if o == nil {
o = createHashObject()
dbAdd(c.db, key, o)
return o
}
/**
if it exists but is not a hash object,
reply the user of a type error.
*/
if o.robjType != REDIS_HASH {
addReply(c, shared.wrongtypeerr)
return nil
}
return o
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
完成字典检查和创建工作之后,就开始针对键值对进行处理,以我们的的指令为例,对应的参数为c.argv[2]、c.argv[3]也就是name、xiaoming该方法内部会判断键值对是否可以转为数值类型,如果是则进行转换,反之说明是字符串类型无法转为数值则返回原始类型。
对应我们给出这段代码的逻辑实现,逻辑和笔者表述基本一致,读者可参阅注释了解:
func hashTypeTryObjectEncoding(subject *robj, o1 **robj, o2 **robj) {
/**
determine if the subject encoding is a dict .
if it is, proceed with the logic processing
*/
if subject.encoding == REDIS_ENCODING_HT {
//perform type conversion on the field.
if o1 != nil {
*o1 = tryObjectEncoding(*o1)
}
//perform type conversion on the field.
if o2 != nil {
*o2 = tryObjectEncoding(*o2)
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
这里补充的go语言的实现细节,读者可按需了解,因为在指令解析阶段笔者将所有参数都封装为robj指针,所以笔者在传入的字段和值都是通过二级指针进行操作,原因很简单,因为go语言是值拷贝语言,如果我们传入字段和值的一级指针,这意味着我们内部针对指针的修改操作仅仅是影响实参的指向地址:
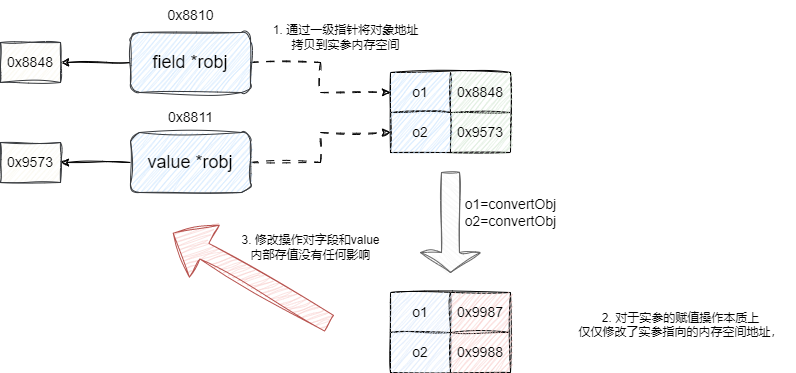
所以在进行函数值传递时,要求用户传入robj的二级指针,通过对于二级指针的*操作拿到这个指针的内存空间从而完成内存空间指向的对象地址修改,由此保证我们的转换后的对象可以正确存入到robj指针中:
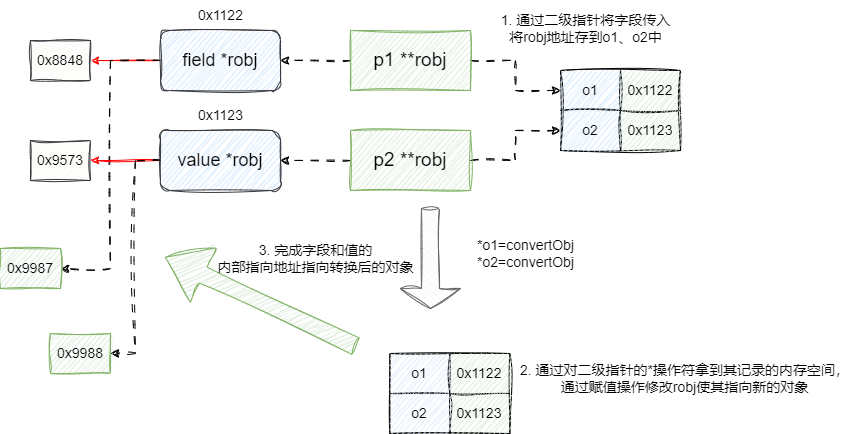
最后就是插入键值对操作了,这里算是笔者阅读redis源码认为最拗口和语义表达最差的地方,因为笔者实现字典字典都是通过哈希集实现,所以对于REDIS_ENCODING_ZIPLIST 实现略掉了。
可以看到我们对于字典插入键值对的操作是通过dictReplace操作,该操作从函数上看是针对字典字段的替换操作,但其实不是的,该函数如果是插入操作则返回true(C语言返回1),如果字段存在则进行值覆盖所以返回false(C语言返回0),所以笔者认为这个函数的函数应该改为dictAdd更合适。
当然本着原汁原味复刻的想法,笔者也沿用了这个函数名:
dictReplace返回true说明是插入操作,对外返回0说明更新了0条。dictReplace返回false说明是值覆盖即更新操作,对外返回1说明更新1条。
func hashTypeSet(o *robj, field *robj, value *robj) int {
if o.encoding == REDIS_ENCODING_ZIPLIST {
//todo
return 0
} else if o.encoding == REDIS_ENCODING_HT {
m := (*o.ptr).(map[string]*robj)
/**
if it is an add operation, return true,
and then the function returns 1 .
conversely,return 0 to inform the external system
that the current operation is an update
*/
if dictReplace(m, field, value) {
return 0
}
return 1
} else {
log.Panic("Unknown hash encoding")
return -1
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# hmset设置字典多键值对
对应hmset则是设置字典多个键值对,例如我们希望设置user字典的姓名、性别、年龄等字段,就可以通过hmset进行设置:
hmset user name xiaoming sex man age 18
hmset执行过程与hset差不多,唯一补充的地方就是hmset是设置多个键值对,所以它会检查键值对是否两两配对,一旦发现传入的指令不是双数就会响应异常给用户。
反之就会从索引2,以我们的指令就是name字段开始,逐对进行编码转换然后设置到user字典中,如果操作成功则返回用户ok:
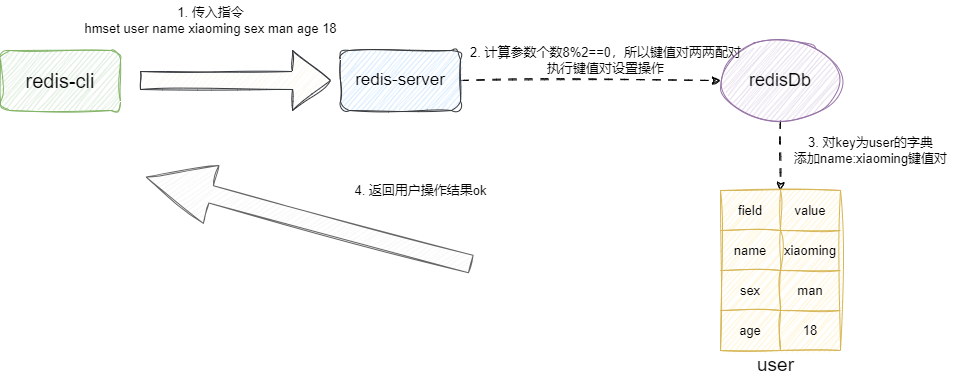
对应的我们给出hmsetCommand的源码,大体逻辑和上述图解差不多,这里我们给出一个redis实现的优化点,进行键值对遍历时,它是每次循环都会拿到field的索引,然后基于field的索引+1拿到value的索引,通过这样的细节优化,减少了一半的遍历过程:
func hmsetCommand(c *redisClient) {
/**
determine if the command params is singular
if it is, respond with wrong number
*/
if c.argc%2 == 1 {
errMsg := "wrong number of arguments for HMSET"
addReplyError(c, &errMsg)
return
}
/**
starting from index 2,foreach key-value pair,
perform encoding conversion, and save to dict obj
*/
var i uint64
o := hashTypeLookupWriteOrCreate(c, c.argv[1])
for i = 2; i < c.argc; i += 2 {
hashTypeTryObjectEncoding(o, &c.argv[i], &c.argv[i+1])
hashTypeSet(o, c.argv[i], c.argv[i+1])
}
addReply(c, shared.ok)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# hsetnx设置非存在键值对
hsetnx只有在当前字典中某个字段不存在的时候才会进行插入操作,如果字段存在则返回0,例如我们执行:hset user name xiaoming,如果user中存在name这个字段,那么该操作就会返回0,反之将name字段插入然后返回1:
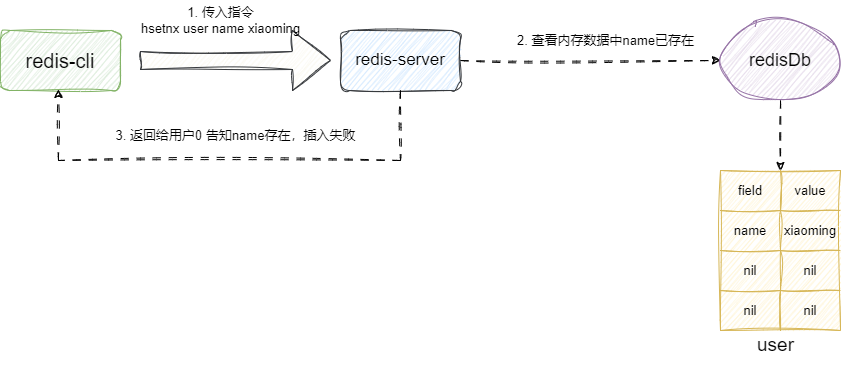
对应我们给出hsetnxCommand的实现,其逻辑与上述表述基本一致读者可参考注释了解细节:
func hsetnxCommand(c *redisClient) {
//perform dict lookup, type validation, and creation if it does not exist.
o := hashTypeLookupWriteOrCreate(c, c.argv[1])
//if it does not exist, return 0 and do not perform any operation.
if hashTypeExists(o, c.argv[2]) {
addReply(c, shared.czero)
return
}
/**
1. perform the field type and value type conversion.
2. save field(argv[2])、value(argv[3]) to the dict obj
3. respond to the client with the result 1
*/
hashTypeTryObjectEncoding(o, &c.argv[2], &c.argv[3])
hashTypeSet(o, c.argv[2], c.argv[3])
addReply(c, shared.cone)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
这里我们唯一需要说明的就是hashTypeExists,因为笔者用go语言,而go语言没有万能指针的概念,所以采用所有类型都可以转换成的接口指针记录对象指针,于是笔者在获取字典的时候,需要将接口指针所指向的接口还原为原有类型,如下所示的dict和key,然后判断key是否存在,如果存在则返回true,反之返回false:
func hashTypeExists(o *robj, field *robj) bool {
/**
because the robj pointer records the interface type,
when storing, the field is forcefully cast to the interface type,
and the same applies to the key
*/
dict := (*o.ptr).(map[string]*robj)
key := (*field.ptr).(string)
//if it exists, return true.
if _, e := dict[key]; e {
return true
}
return false
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# hget/hmget获取指定字典字段
我们已经将字典中核心的几个存储操作都完成了复刻,接下来就是取值的操作,以hget为例,例如我希望获取user字典的name字段的值,那么对应的操作指令为:
hget user name
该指令对应实现的函数实现逻辑比较简单:
- 查看字段对象是否存在,如果不存在直接返回空。
- 若存在则检查是否是哈希对象,如果不是则返回类型错误。
- 如果存在且是哈希对象,则携带用户传入的字段查看字段是否存在,若存在则返回该字段对应的值。
对此我们直接给出这段代码的实现:
func hgetCommand(c *redisClient) {
//check if the dictionary exists, and if it does not exist, return null.
o := lookupKeyReadOrReply(c, c.argv[1], shared.nullbulk)
//if it is not a hash object, return a type error
if o == nil || checkType(c, o, REDIS_HASH) {
return
}
//if the corresponding field in the dictionary exists, return this value
addHashFieldToReply(c, o, c.argv[2])
}
2
3
4
5
6
7
8
9
10
11
这里我们着重强调一下addHashFieldToReply的实现,它要求我们传入客户端、字典、字段三个对象,如果字典为空则直接响应nullbulk。如果字典存在则创建一个一级指针value的指针传入hashTypeGetFromHashTable,如果字典o有值则会将对应值的指针记录到value中。
最后如果value不为空则返回value,反之返回空响应:
func addHashFieldToReply(c *redisClient, o *robj, field *robj) {
//If the dictionary is empty, return nullbulk
if o == nil {
addReply(c, shared.nullbulk)
return
}
if o.encoding == REDIS_ENCODING_ZIPLIST {
//todo something
} else if o.encoding == REDIS_ENCODING_HT {
value := new(robj)
/**
pass the secondary pointer of the value to record the value corresponding to the field in the dictionary.
if it is not null, return value; otherwise, return nullbulk.
*/
if hashTypeGetFromHashTable(o, field, &value) {
addReplyBulk(c, value)
} else {
addReply(c, shared.nullbulk)
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
对应的我们也给出hashTypeGetFromHashTable的实现,可以看到本质上就是拿到value的指针然后查看key对应的值是否存在,如果存在则记录到value二级指针所指向的指针的内存空间中:
func hashTypeGetFromHashTable(o *robj, field *robj, value **robj) bool {
dict := (*o.ptr).(map[string]*robj)
key := (*field.ptr).(string)
if v, e := dict[key]; e {
*value = v
return true
}
return false
}
2
3
4
5
6
7
8
9
10
11
而hmget顾名思义就是获取字典中多字段,实现和hget差不多,只不过可以拿到多个key的value,整体逻辑大差不差:
func hmgetCommand(c *redisClient) {
o := lookupKeyReadOrReply(c, c.argv[1], shared.nullbulk)
if o == nil || checkType(c, o, REDIS_HASH) {
return
}
addReplyMultiBulkLen(c, int64(c.argc-2))
var i uint64
//starting from the first field, read the fields from the dictionary and return them.
for i = 2; i < c.argc; i++ {
addHashFieldToReply(c, o, c.argv[i])
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# hgetall获取字典所有值
该方法获取字典对象所有的键值对,例如我们键入:
hgetall user
该指令就会返回user哈希对象所有的键值对,对应的函数hgetallCommand本质上就是调用genericHgetallCommand,而genericHgetallCommand为了保证复用性要求第二个参数传入标识,这是一个非常典型的位运算技巧:
- 如果希望仅仅查询
key则传REDIS_HASH_KEY即1。 - 如果希望仅仅查询
value则传REDIS_HASH_VALUE即2。 - 如果都需要则通过按位或将两者结合传3。
func hgetallCommand(c *redisClient) {
/**
Use the XOR operation between the key and value to indicate that
the current function needs to retrieve all keys and values from the dict.
*/
genericHgetallCommand(c, REDIS_HASH_KEY|REDIS_HASH_VALUE)
}
2
3
4
5
6
7
8
这样内部就可以通过按位与定位到调用方对于键值对的需求,然后按需取值返回了:
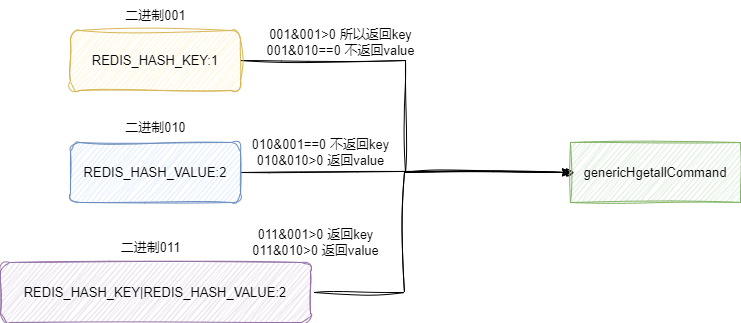
这里我们就以user字典为例它有name、age、sex三个字段,待入上述的运算公式了解一下genericHgetallCommand的工作流程,因为我们传入的值是REDIS_HASH_KEY|REDIS_HASH_VALUE也就是二进制的011,对应的multiplier结果为2,所以addReplyMultiBulkLen就会返回3*2即键值对总数为6的字符串。
然后通过传入的flags 和REDIS_HASH_KEY 及REDIS_HASH_VALUE进行按位与,因为我们的flags都会大于0,所以键值对都会返回:
func genericHgetallCommand(c *redisClient, flags int) {
multiplier := 0
o := lookupKeyReadOrReply(c, c.argv[1], shared.emptymultibulk)
if o == nil || checkType(c, o, REDIS_HASH) {
return
}
/**
if the result of the bitwise AND operation between the key and REDIS_HASH_KEY is greater than 0,
increment the multiplier.
*/
if flags&REDIS_HASH_KEY > 0 {
multiplier++
}
/**
if the result of the bitwise AND operation between the key and REDIS_HASH_VALUE is greater than 0,
increment the multiplier.
*/
if flags&REDIS_HASH_VALUE > 0 {
multiplier++
}
/**
response the client to return the value of the dictionary size multiplied by multiplier.
*/
dict := (*o.ptr).(map[string]*robj)
l := len(dict)
addReplyMultiBulkLen(c, int64(l*multiplier))
//return the key-value pairs as required.
for key, value := range dict {
if flags&REDIS_HASH_KEY > 0 {
i := interface{}(key)
object := createObject(REDIS_STRING, &i)
addReplyBulk(c, object)
}
if flags&REDIS_HASH_VALUE > 0 {
addReplyBulk(c, value)
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
# hdel删除字典某字段
hdel则比较简单了,例如我们需要删除user字典的name字段,那么我们的指令就是:
hdel user name
对应逻辑如下所示,从索引2开始遍历key,如果key存在且删除成功则deleted累加,最终返回用户删除数。需要注意的是,如果完成删除操作后字典没有任何字典则该字典会被删除:
func hdelCommand(c *redisClient) {
var deleted int64
o := lookupKeyWriteOrReply(c, c.argv[1], shared.czero)
if o == nil || checkType(c, o, REDIS_HASH) {
return
}
//starting from index 2, locate all the keys.
var i uint64
for i = 2; i < c.argc; i++ {
if hashTypeDelete(o, c.argv[i]) { //If the deletion is successful, increment the deleted counter.
deleted++
}
}
//If the dictionary has no key-value pairs after deletion, delete it directly.
dict := (*o.ptr).(map[string]*robj)
if len(dict) == 0 {
dbDelete(c.db, c.argv[1])
}
addReplyLongLong(c, deleted)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 小结
自此笔者将mini-redis复刻字典操作的核心源码解析都分析完成,希望对你有帮助。
我是 sharkchili ,CSDN Java 领域博客专家,mini-redis的作者,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。

