 详解Netty中的责任链Pipeline如何管理ChannelHandler
详解Netty中的责任链Pipeline如何管理ChannelHandler
# 写在文章开头
前面几篇文章我们简单的介绍了一下Netty的基本使用与核心组成,这篇文章我们就在此基础上拓展一下以下对于channelHandler与channelPipeline之间的关系,希望对你有帮助。
Hi,我是 sharkChili ,是个不断在硬核技术上作死的 java coder ,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。

# 详解channelHandler与channelPipeline
# 为什么channelHandler需要channelPipeline
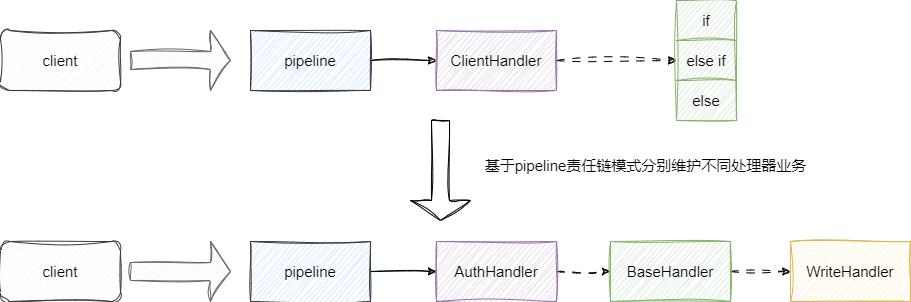
我们之前的文章中,无论是客户端handler还是服务端handler都是编写在同一个handler中,随着业务拓展每一个handler的逻辑都会变得十分笨重且难以维护,按照Netty的设计,实际上我们可以基于Netty的责任链模式,将不同的业务下沉到不同的handler中:
# ChannelInboundHandlerAdapter的执行
ChannelInboundHandlerAdapter顾名思义是处理客户端读事件的处理器,我们首先创建几个InboundHandler处理服务端读到的消息,这里笔者以InboundHandlerA 为例,后续的B、C逻辑一样这里就不多赘述了:
public class InboundHandlerA extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
System.out.println("InBoundHandlerA : " + ((ByteBuf)msg).toString(StandardCharsets.UTF_8));
//将当前的处理过的msg转交给pipeline的下一个ChannelHandler
super.channelRead(ctx, msg);
}
}
2
3
4
5
6
7
8
9
10
然后我们将其添加到我们引导类的pipeline上:
serverBootstrap.group(boss, worker)//3. 基于上述线程池创建主从reactor模型
.channel(NioServerSocketChannel.class)//server channel采用NIO模型
.childHandler(new ChannelInitializer<NioSocketChannel>() {//添加客户端读写请求处理器到subreactor中
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
// 对于ChannelInboundHandlerAdapter,收到消息后会按照顺序执行即 A -> B
ch.pipeline().addLast(new InboundHandlerA())
.addLast(new InboundHandlerB());
}
});
2
3
4
5
6
7
8
9
10
11
12
13
从输出结果来看InBoundHandler是按照处理器添加顺序执行的:
InBoundHandlerA : hello Netty Server
InBoundHandlerB: hello Netty Server
2
当服务端收到客户端的连接请求时 ,eventLoop会为其生成一个channel,然后通过ch.pipeline().addLast(new InboundHandlerA()) .addLast(new InboundHandlerB()),将InboundHandler封装为AbstractChannelHandlerContext ,将其追加到DefaultChannelPipeline的head节点的尾部,完成之后服务端还会回调handlerAdd方法传播添加的通知:
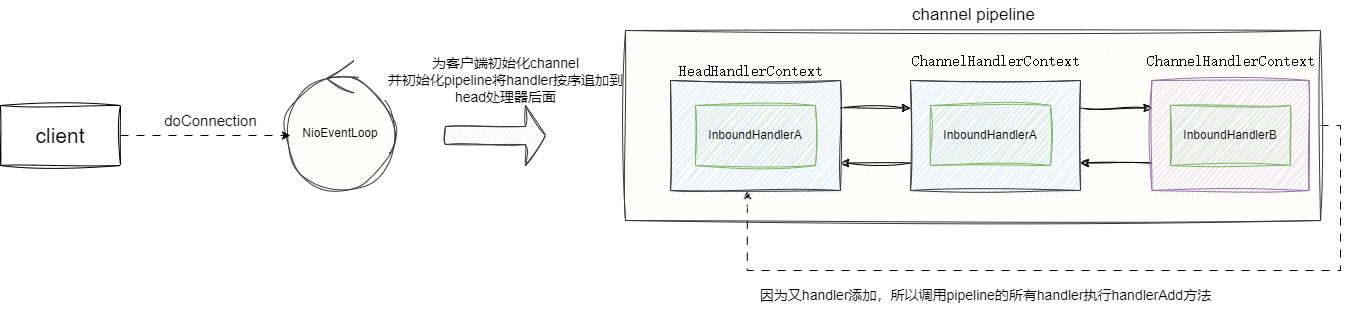
这里我们也给出ChannelPipeline的addLast方法内部执行的核心逻辑,当服务端acceptor收到新建立的连接之后,为连接分配一个channel后,其内部会针对当前channel的pipeline上个对象锁然后将处理器封装成AbstractChannelHandlerContext追加到双向链表中:
@Override
public final ChannelPipeline addLast(EventExecutorGroup group, String name, ChannelHandler handler) {
final AbstractChannelHandlerContext newCtx;
//对当前客户端channel上对象锁
synchronized (this) {
checkMultiplicity(handler);
//将channelHandler封装为ChannelHandlerContext
newCtx = newContext(group, filterName(name, handler), handler);
//调用addLast0将其追加到pipeline尾部
addLast0(newCtx);
//......
//查看注册的线程是否是eventLoop,如果不是则封装一个任务回调pipeline上的handlerAdded方法
EventExecutor executor = newCtx.executor();
if (!executor.inEventLoop()) {
newCtx.setAddPending();
executor.execute(new Runnable() {
@Override
public void run() {
callHandlerAdded0(newCtx);
}
});
return this;
}
}
//反之直接回调pipeline上的handlerAdd
callHandlerAdded0(newCtx);
return this;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
后续的NioEventLoop轮询到该客户端socket给服务端发送的消息之后就会,轮询处理这个事件对应的channel,channel会从pipeline中的head节点开始传播这个read事件,由此走到我们的InboundHandler:

对应我们给出读事件源码的入口,即位于NioEventLoop的run方法,其内部轮询到当前客户端的就绪key之后,就会调用processSelectedKeys处理就绪的IO事件:
@Override
protected void run() {
for (;;) {
try {
//基于策略轮询是否有就绪事件
switch (selectStrategy.calculateStrategy(selectNowSupplier, hasTasks())) {
case SelectStrategy.CONTINUE:
continue;
case SelectStrategy.SELECT:
select(wakenUp.getAndSet(false));
//......
if (wakenUp.get()) {
selector.wakeup();
}
default:
// fallthrough
}
cancelledKeys = 0;
needsToSelectAgain = false;
final int ioRatio = this.ioRatio;
if (ioRatio == 100) {
//......
} else {
final long ioStartTime = System.nanoTime();
try {
//处理就绪的客户端读事件
processSelectedKeys();
} finally {
//......
}
}
} catch (Throwable t) {
//......
}
//......
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
步入其内部核心逻辑即可看到,它会通过AbstractNioChannel定位到unsafe 这个对于socket抽象,然后解析该事件的操作位是读事件,于是直接调用unsafe.read();处理读事件:
private void processSelectedKey(SelectionKey k, AbstractNioChannel ch) {
final AbstractNioChannel.NioUnsafe unsafe = ch.unsafe();
if (!k.isValid()) {
final EventLoop eventLoop;
//......
try {
int readyOps = k.readyOps();
//......
//对应事件的ops为OP_READ 即读事件,于是调用 unsafe.read();
if ((readyOps & (SelectionKey.OP_READ | SelectionKey.OP_ACCEPT)) != 0 || readyOps == 0) {
unsafe.read();
//......
}
} catch (CancelledKeyException ignored) {
unsafe.close(unsafe.voidPromise());
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
于是触发AbstractNioByteChannel的read方法,其内部会将这个数据封装成bytebuf,然后调用pipeline的fireChannelRead触发所有挂到pipeline上的``:
@Override
public final void read() {
//......
ByteBuf byteBuf = null;
boolean close = false;
try {
do {
//将数据封装成byteBuf
byteBuf = allocHandle.allocate(allocator);
allocHandle.lastBytesRead(doReadBytes(byteBuf));
//......
//调用pipeline传播read事件
pipeline.fireChannelRead(byteBuf);
byteBuf = null;
} while (allocHandle.continueReading());
//......
} catch (Throwable t) {
//......
} finally {
//......
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
可以看到pipeline的fireChannelRead就如我们上文所说的从head节点开始传播数据给所有handler的channelRead方法:
@Override
public final ChannelPipeline fireChannelRead(Object msg) {
AbstractChannelHandlerContext.invokeChannelRead(head, msg);
return this;
}
2
3
4
5
我们步入该方法即可看到每个ChannelHandlerContext 执行时都会判断自己是否处于EventLoop中,如果不是则异步提交任务给线程,反之直接执行,以保证所有任务无锁串行化执行:
static void invokeChannelRead(final AbstractChannelHandlerContext next, Object msg) {
//......
EventExecutor executor = next.executor();
//查看当前线程是否是eventLoop如果
if (executor.inEventLoop()) {
next.invokeChannelRead(m);
} else {
executor.execute(new Runnable() {
@Override
public void run() {
next.invokeChannelRead(m);
}
});
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
最后来到ChannelHandlerContext 的fireChannelRead,它会调用findContextInbound获取下一个ChannelHandlerContext 然后执行其channelRead方法:
@Override
public ChannelHandlerContext fireChannelRead(final Object msg) {
invokeChannelRead(findContextInbound(), msg);
return this;
}
2
3
4
5
对此我们也给出了findContextInbound的实现,可以看到其本质就是从head开始用next往后找对应的inbound即读事件处理器:
private AbstractChannelHandlerContext findContextInbound() {
AbstractChannelHandlerContext ctx = this;
do {
ctx = ctx.next;
} while (!ctx.inbound);
return ctx;
}
2
3
4
5
6
7
于是代码就来到了InboundHandlerA,在InboundHandlerA调用结束后InboundHandlerA会调用channelRead继续将事件向后传播,流程和上述源码解析一样。
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
System.out.println("InBoundHandlerA : " + ((ByteBuf)msg).toString(StandardCharsets.UTF_8));
//将当前的处理过的msg转交给pipeline的下一个ChannelHandler
super.channelRead(ctx, msg);
}
2
3
4
5
6
# ChannelOutboundHandlerAdapter的执行
对应如果我们在事件中使用客户端channel发送数据时,就会调用write方法:
ctx.channel().writeAndFlush(out);
假如我们希望对于write方法进行相应的事件处理,我们也可以像InboundHandler那样将追加到pipeline上,可以看到笔者给出的代码段是依次追击A、B、C处理器:
// 处理写数据的逻辑,顺序是反着的 C->B -> A
ch.pipeline().addLast(new OutboundHandlerA())
.addLast(new OutboundHandlerB())
.addLast(new OutboundHandlerC());
2
3
4
我们收到处理顺序却是相反的:
OutBoundHandlerC: Hello Netty client
OutBoundHandlerB: Hello Netty client
OutBoundHandlerA: Hello Netty client
2
3
原因很简单,inbound和outbound处理器都是以顺序的方式追加到pipeline上,但是两者的区别是前者会从head搜寻所有inbound处理器顺序执行,而后者则是从tail处理器开始倒叙遍历执行:

所以我们给出AbstractChannel的writeAndFlush的实现来印证这个问题,可以看到其内部就是调用pipeline的writeAndFlush方法:
@Override
public ChannelFuture writeAndFlush(Object msg) {
return pipeline.writeAndFlush(msg);
}
2
3
4
可以看到从pipeline的tali即尾节点开始倒叙遍历handler进行处理:
@Override
public final ChannelFuture writeAndFlush(Object msg) {
return tail.writeAndFlush(msg);
}
2
3
4
步入writeAndFlush的核心我们即可看到AbstractChannelHandlerContext的write方法的实现,可以看到其内部本质就是调用findContextOutbound方法倒叙获取outboundHandler:
private void write(Object msg, boolean flush, ChannelPromise promise) {
//从尾节点开始查询下一个outboundHandler
AbstractChannelHandlerContext next = findContextOutbound();
final Object m = pipeline.touch(msg, next);
EventExecutor executor = next.executor();
//根据线程类型决定是直接调用handler执行write,还是提交一个异步任务执行Write
if (executor.inEventLoop()) {
if (flush) {
next.invokeWriteAndFlush(m, promise);
} else {
next.invokeWrite(m, promise);
}
} else {
AbstractWriteTask task;
if (flush) {
task = WriteAndFlushTask.newInstance(next, m, promise);
} else {
task = WriteTask.newInstance(next, m, promise);
}
safeExecute(executor, task, promise, m);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
我们查看findContextOutbound就可以看到从尾部开始遍历迭代查找第一个outboundHandler并返回:
private AbstractChannelHandlerContext findContextOutbound() {
AbstractChannelHandlerContext ctx = this;
//遍历到outboundHandler直接退出循环,并返回结果
do {
ctx = ctx.prev;
} while (!ctx.outbound);
return ctx;
}
2
3
4
5
6
7
8
# 小结
自此我们通过示例和源码分析的方式简单的介绍了一下Pipeline和ChannelHandler的关系,以及传播顺序,建议读者按照笔者的说明进行handler编排,并解耦各个处理器的逻辑,由此提升程序的稳定性和可维护性。
全文结束,希望对你有帮助。
我是 sharkchili ,CSDN Java 领域博客专家,开源项目—JavaGuide contributor,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。 因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。

# 参考文献
Netty源码------Pipeline详细分析:https://blog.csdn.net/qqq3117004957/article/details/106470684 (opens new window)
《跟闪电侠学Netty》
