 聊聊我基于dict优化mini-redis数据性能这件事
聊聊我基于dict优化mini-redis数据性能这件事
# 写在文章开头
mini-redis这个开源项目做了也有好一段时间,原有的设计理念是将go语言中一些内置可直接复用的数据结构和轮子直接作为工具简便redis的复刻,而随着笔者对于redis深入的理解和学习后发现,redis中许多优秀的设计理念和算法都和其底层优秀的数据结构有着千丝万缕的关系。
考虑到scan指令底层扫荡算法的落地,以及还原更真实的redis,笔者最终还是打算将mini-redis底层数据库的数据结构重构为dict字典,而本文将针对笔者dict复刻的设计思路和落地代码核心部分进行介绍,帮助读者更好的阅读和理解这个项目。
我是 SharkChili ,Java 开发者,Java Guide 开源项目维护者。欢迎关注我的公众号:写代码的SharkChili,也欢迎您了解我的开源项目 mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)。
为方便与读者交流,现已创建读者群。关注上方公众号获取我的联系方式,添加时备注加群即可加入。
# 详解dict复刻与重构过程
# 字典创建
redis底层的数据库都是通过字典进行存储,而字典本质上就是由两个数组构成我们称每个数组为hash table也就是哈希表,简称为ht而ht索引每个位置都代表一个bucket也就是哈希桶,如下图所示:
- 默认情况下键值对都会存储在
ht[0]上,当ht[0]元素大于数组大小后就会触发渐进式哈希(后续会结合源码深入讲解),才会创建数组使用ht[1]元素元素,所以ht[1]默认情况下是空的 ht数组存储的是dictEntry,而dictEntry就是维护键值对信息的元素结构体- 因为
ht数组空间有限,键值对经过哈希运算存在索引冲突的情况,所以ht上每个bucket都采用拉链法解决冲突,这也就是为什么下图中的dictEntry都用箭头next指针相互关联:
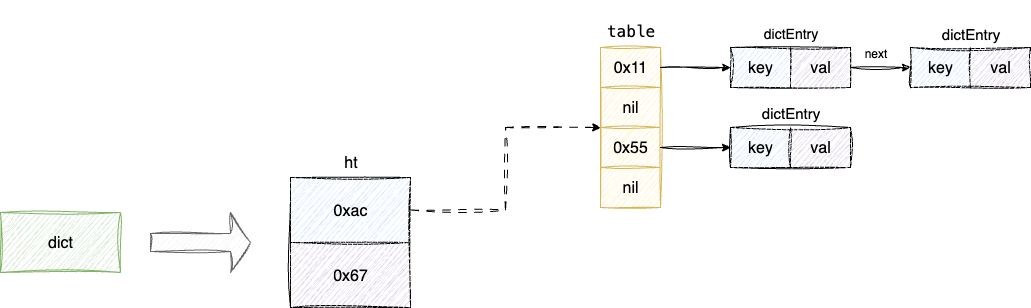
对应笔者也给出数组的数组结构,该结构体内部存储一个长度为2的数组,每个数组都是一个hash table即dictht用于存储键值对:
/**
* 字典核心数据结构定义
*/
type dict struct {
//......
//存储键值对的两个数组
ht *[2]dictht
//......
}
2
3
4
5
6
7
8
9
查看哈希表dictht的结构体,可以看到如下核心组件:
- 存储键值对的数组
table - 记录数组大小的变量
size - 记录数组中存储多少个元素的变量
used
对应结构体如下,可以看到table数组存储的键值对都是用结构体dictEntry记录:
/**
* 字典哈希表定义
*/
type dictht struct {
//存储键值对的数组
table *[]*dictEntry
//记录hash table的大小
size uint64
sizemask int
//记录数组存储了多少个键值对
used uint64
}
2
3
4
5
6
7
8
9
10
11
12
而dictEntry内部也是用key和value存储键值对,同时因为我们的字典是通过拉链法解决哈希后出于相同索引下的键值对,所以还需要专门一个next字段维护键值对间的关系:
/**
* 字典键值对定义
*/
type dictEntry struct {
//存储key
key *robj
//存储value
val *robj
//存储后继节点
next *dictEntry
}
2
3
4
5
6
7
8
9
10
11
有了上述数据结构的概念之后,我们就可以深入的探讨字典的创建,大体来说字典的核心步骤比较简单:
- 初始化结构体空间
- 针对哈希表ht内部信息调用
_dictInit进行初始化
对应笔者给出字典初始化函数dictCreate的入口,可以看到在完成字典初始化之后,直接调用_dictInit:
func dictCreate(typePtr *dictType, privDataPtr *interface{}) *dict {
//初始化字典及其ht数组空间
d := dict{ht: &[2]dictht{}}
_dictInit(&d, privDataPtr, typePtr)
return &d
}
2
3
4
5
6
_dictInit本质上就是针对哈希表ht进行重置后,将渐进式哈希和迭代器使用标识都设置为初始值-1,代表数组不存在渐进式哈希,后续如果触发渐进式哈希,rehashidx就会被设置为0,即代表从0开始将元素驱逐到新的哈希表上。逻辑比较简单,读者可以直接查看笔者标注的注释理解一下:
func _dictInit(d *dict, privDataPtr *interface{},
typePtr *dictType) int {
//重置哈希表空间
_dictReset(&(d.ht)[0])
_dictReset(&(d.ht)[1])
d.privdata = privDataPtr
d.dType = typePtr
//设置rehashidx为-1,代表当前不存在渐进式哈希
d.rehashidx = -1
//设置iterators为0,代表字典并不存在迭代
d.iterators = 0
return DICT_OK
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
最后我们再给出_dictReset的逻辑,大体就是执行如下几个核心步骤:
- 数组空间设置为空
- size设置为0
- 哈希取模的
sizemask初始化为0 used为0标识数组没有存储任何元素
func _dictReset(ht *dictht) {
ht.table = nil
ht.size = 0
ht.sizemask = 0
ht.used = 0
}
2
3
4
5
6
对应的创建过程笔者这里给出自己的测试单元,即TestDictCreate函数,可以看到笔者通过dictCreate完成必要的初始化之后,针对字典内部各个参数进行进行的断言校验:
func TestDictCreate(t *testing.T) {
d := dictCreate(&dbDictType, nil)
ht := d.ht
if ht[0].table != nil || ht[1].table != nil {
log.Fatal("table is not nil")
}
if ht[0].size != 0 || ht[1].size != 0 {
log.Fatal("size is not 0")
}
if ht[0].used != 0 || ht[1].used != 0 {
log.Fatal("used is not 0")
}
if ht[0].sizemask != 0 || ht[1].sizemask != 0 {
log.Fatal("sizemask is not 0")
}
if d.rehashidx != -1 {
log.Fatal("rehashidx is not -1")
}
if d.iterators != 0 {
log.Fatal("iterators is not 0")
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 键值对插入
字典执行键值对插入逻辑比较简单,每次执行插入前,都会计算key对应的哈希,然后定位到对应的数组索引,然后通过头插法将key封装为dictEntry存到ht即hashtable上。
以下图为例,key为字符串17通过哈希运算,对应的规则为17的哈希值%数组长度,需要注意的是redis针对这个取模算法做了一定的优化。众所周知,位运算的效率原有考虑常规数学运算,所以redis取模算法通过如下步骤实现将取模运算变为位运算:
- 初始化数组长度时永远保持数组为2的次幂,例如:2、4、8、16这样的数字
- 因为数组长度永远是2的次幂,所以原有
hash%size就可以优化为hash&(size-1),这一点读者可以拿起纸笔推算一下,这一经典的取模算法的设计在netty的轮询算法中也有提现
通过上述算法定位到明确定位到对应的bucket,将key封装为entry存储若插入成功则返回非空entry,最后明确返回的entry非空的情况下,将entry的val设置为我们插入的value值,这种做法确保了的只有正确插入的情况下,在使用entry的内存空间存储value,保证绝不浪费每一刻时间和每一个空间资源:
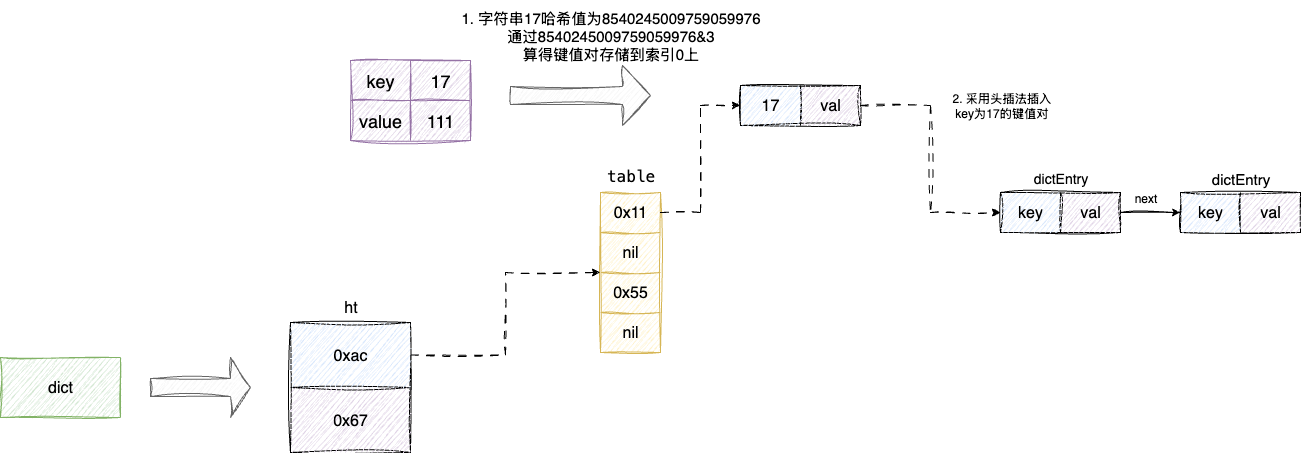
对应的我们给出字典插入元素的函数入口dictAdd,可以看到入参为key和value,然后调用dictAddRaw尝试插入键值对,成功后会返回dictEntry,明确dictEntry非空(即落库成功)的情况下,将val设置到dictEntry上:
func dictAdd(d *dict, k *robj, v *robj) int {
//将key存储到哈希表某个索引中,如果成功则返回这个key对应的entry的指针
entry := dictAddRaw(d, k)
if entry == nil {
return DICT_ERR
}
//将entry的val设置为v
entry.val = v
return DICT_OK
}
2
3
4
5
6
7
8
9
10
而dictAddRaw本质上也就是通过_dictKeyIndex计算索引位置,然后定位索引通过头插法将dictEntry存储到数组(默认情况下用ht[0])中:
func dictAddRaw(d *dict, k *robj) *dictEntry {
//.......
//哈希运算定位索引
index := _dictKeyIndex(d, k)
//检查索引是否正确,若为-1则说明异常直接返回nil
if index == -1 {
return nil
}
//根据渐进式哈希表确定table
var ht *dictht
if dictIsRehashing(d) {
ht = &d.ht[1]
} else {
ht = &d.ht[0]
}
//通过头插法将元素插入到数组中
entry := &dictEntry{key: k}
entry.next = (*(ht.table))[index]
(*(ht.table))[index] = entry
//累加used告知数组增加一个元素
ht.used++
return entry
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
这里我们着重说明一下_dictKeyIndex函数,它会根据key通过hashFunction计算key的哈希值,然后通过上述理念说明的位运算计算索引,然后判断这个索引下是否存在当前key,如果如果存在则返回-1,告知外部不用添加entry,有需要直接改dictentry的val即可。反之返回索引(非-1)让上述的代码完成dictEntry完成创建并通过头插法落入字典中:
func _dictKeyIndex(d *dict, key *robj) int {
var idx int
//......
//计算索引位置
h := d.dType.hashFunction((*key.ptr).(string))
//基于索引定位key
for i := 0; i < 2; i++ {
//通过位运算计算数组存储的索引
idx = h & d.ht[i].sizemask
he := (*(d.ht[i].table))[idx]
////判断这个索引下是否存在相同的key,如果存在则返回-1,告知外部不用添加entry,有需要直接改dictentry的val即可
for he != nil {
if d.dType.keyCompare(nil, (*key.ptr).(string), (*he.key.ptr).(string)) {
return -1
}
he = he.next
}
// 如果正在rehash,则检查ht[1]
if !dictIsRehashing(d) {
break
}
}
return idx
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 键值对更新
键值对的更新逻辑和插入差不多,唯一区别是更新操作首先会调用插入操作查看是否成功,已确定当前元素是否存在,若成功则说明本次传入的键值对是第一次插入完成落库后直接返回,反之说明这个key存在则执行如下步骤:
- 基于
dictFind定位dictEntry的指针 - 基于返回的
dictEntry将val修改为新值 - 返回
true,告知客户端操作成功
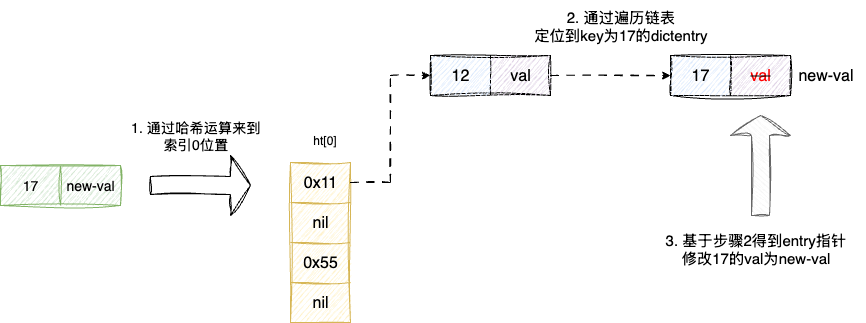
对应的我们也给出字典更新函数dictReplace的实现,读者可结合上述说明了解一下如下的代码逻辑,不难看出这段代码也有健壮性的兜底,为了保证用户的更新(本质也是种写入)能够正确完成,这段逻辑还是复用了dictAdd先尝试进行一次写入,然后根据写入(java开发可以理解为redis的一种insert操作)成功与否决定是否进行后续的更新操作:
func dictReplace(d *dict, key *robj, val *robj) bool {
//先尝试用dictadd添加键值对,若成功则说明这个key不存在,完成后直接返回
if dictAdd(d, key, val) == DICT_OK {
return true
}
//否则通过dictFind定位到entry,修改值再返回true
de := dictFind(d, (*key.ptr).(string))
if de == nil {
return false
}
de.val = val
return true
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 键值对删除
字典的删除操作本质上就是针对bucket链表节点关系的维护,如下图我们要删除节点17通过哈希算法结合链表定位到之后,就可以开始执行删除操作了。
对应的删除逻辑需要判断被删节点he是否存在前驱节点,若存在则说明当前节点处于中间,则将前驱指向he后继,使其从当前bucket中断开,反之则说明当前节点是bucket的第一个节点,直接让bucket指向后继节点即可:
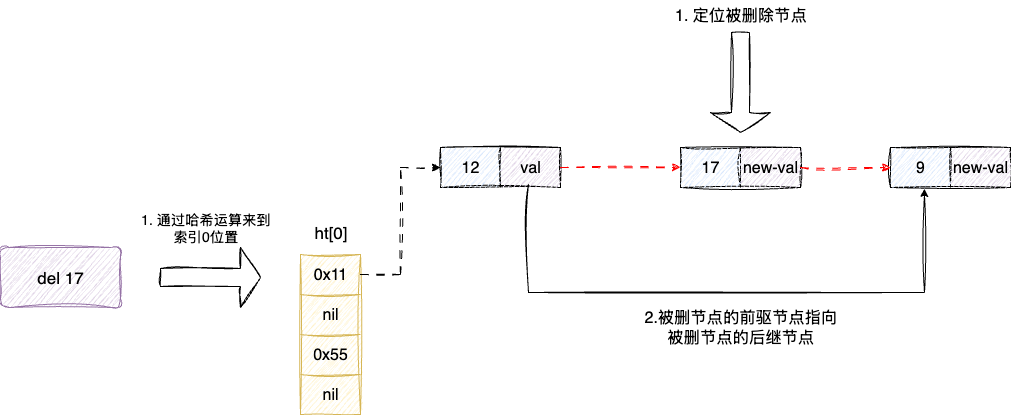
这里笔者也直接将字典删除的核心逻辑代码dictDelete贴出,可以看到其内部的dictGenericDelete调用就是笔者所说的哈希定位+解链的操作:
func dictDelete(ht *dict, key string) int {
return dictGenericDelete(ht, key, 0)
}
// 删除字典中的key
func dictGenericDelete(d *dict, k string, nofree int) int {
//若size为0则说明没有bucket还未初始化,直接返回错误
if d.ht[0].size == 0 {
return DICT_ERR
}
if dictIsRehashing(d) {
_dictRehashStep(d)
}
//哈希定位bucket
h := dictGenHashFunction(k, len(k))
var preDe *dictEntry
for i := 0; i < 2; i++ {
idx := h & d.ht[i].sizemask
he := (*(d.ht[i].table))[idx]
//遍历链表直到找到这个key
for he != nil {
if (*he.key.ptr).(string) == k {
//如果preDe非空则说明被删除元素he在中间,则将he前驱指向he后继
if preDe != nil {
preDe.next = he.next
} else { //否则说明被删除元素he是数组的第一个元素,则直接让数组的第一个元素为he的后继节点
(*(d.ht[0].table))[idx] = he.next
}
//减少used告知数组减少一个元素
d.ht[i].used--
if nofree != 0 {
//help gc
he = nil
}
return DICT_OK
}
preDe = he
he = he.next
}
if !dictIsRehashing(d) {
break
}
}
return DICT_ERR
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
# 键值对查询
上述各种操作我们基本都会看到键值对查询函数dictFind,现在我们就来分析梳理一下笔者对于这块的实现,笔者一直强调,redis字典本质就是通过两个通过拉链法解决冲突的数组(哈希表)存储键值对,一旦第一个哈希表达到阈值后则开启渐进式哈希模式,将哈希表2设置为哈希表1的2倍,然后一小批一小批的驱逐旧有哈希表中的键值对。
这使得查询操作定位元素就需要格外小心,通过哈希算法定位到哈希表1索引查询元素无果后,我们还需要判断当前数组是否正在渐进式哈希,如果存在则还需再哈希计算到哈希表2再查询一遍:
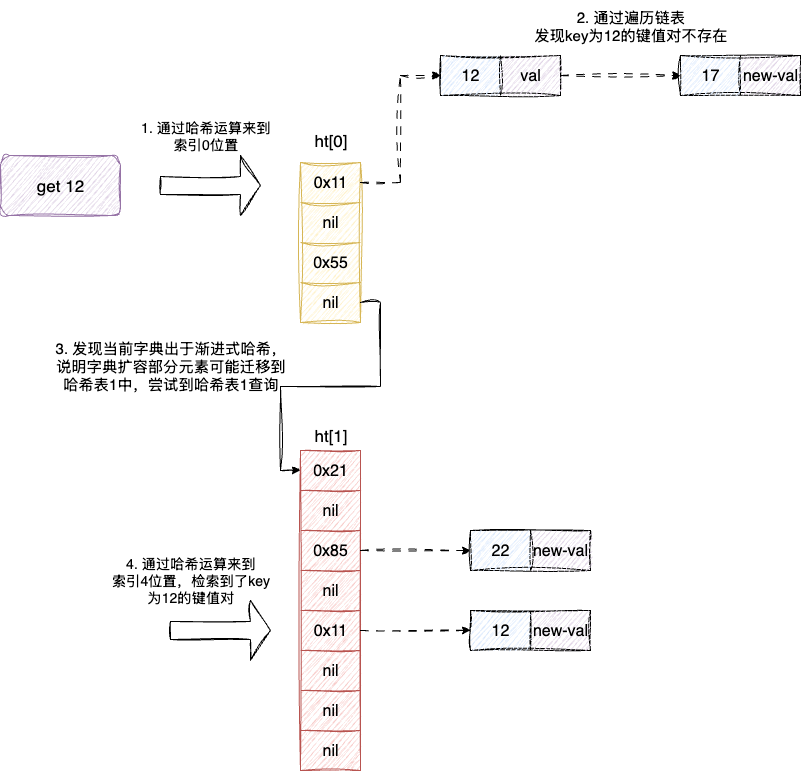
对应的笔者也给出这段查询源码的实现,整体逻辑和上述一样,即通过哈希定位bucket若不存在key则看看是否存在渐进式哈希,再决定是否再哈希到新的哈希表定位查询。
这里笔者也补充几点dictFind中几个比较不错的设计点:
- 为了避免非必要的循环指令的执行,redis的字典基于哈希表中的used字段判断哈希表是否存在键值对,所以进行查询前会先将两个哈希表used相加判断是否非空,已决定是否进行后续查询操作,由此避免非必要的渐进式驱逐和哈希算法定位
- 默认循环遍历两次哈希表,
redis字典操作第二次遍历会通过渐进式哈希标识决定是否执行第二轮的哈希定位查询,由此避免非必要的循环
func dictFind(d *dict, key string) *dictEntry {
//查看哈希表数组是否都为空,若都为空则直接返回
if d.ht[0].used+d.ht[1].used == 0 {
return nil
}
//若元素正处于渐进式哈希则进行一次元素驱逐
if dictIsRehashing(d) {
_dictRehashStep(d)
}
//定位查询key对应的哈希值
h := dictGenHashFunction(key, len(key))
//执行最多两次的遍历(因为我们有两个哈希表,一个未扩容前使用,一个出发扩容后作为渐进式哈希的驱逐点)
for i := 0; i < 2; i++ {
//基于位运算定位索引
idx := h & d.ht[i].sizemask
//定位到对应bucket桶,通过遍历定位到本次要检索的key
he := (*d.ht[0].table)[idx]
for he != nil {
if (*he.key.ptr).(string) == key {
return he
}
he = he.next
}
//若未进行渐进式哈希则说明哈希表-1没有元素,直接结束循环,反之执行2次遍历
if !dictIsRehashing(d) {
break
}
}
return nil
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# mini-redis进阶优化
# 渐进式哈希
渐进式哈希是笔者最喜欢的设计,没有之一,redis字典为了避免大量哈希冲突导致某个bucket生成一条很长的链表,使得原本O(1)级别的查询时间复杂度变为链表遍历的O(n)级别,其内部会在字典任意操作时都会查看当前数组元素大小是否大于数组空间,若大于则判定为哈希碰撞激烈,则执行如下步骤:
- 基于当前
ht[0]数组大小创建2倍大小的数组空间作为ht[1] - 后续所有添加元素都会存储到
ht[1] - 在此期间所有增删改查操作都会逐步驱逐一批元素到
ht[1]中 - 当所有元素都驱逐到
ht[1]时,ht[0]就会指向ht[1]的数组,然后将原本的数组空间释放
上述操作步骤如下图,当我们插入一个键值对到数组时,redis发现此时元素数量4已经等于数组大小了,于是在ht[1]创建一个2倍大小的数组并将1000存储到新的bucket中。后续执行任意get等操作,字典都会驱逐一批元素到ht[1]中,直到完成所有元素的驱逐。
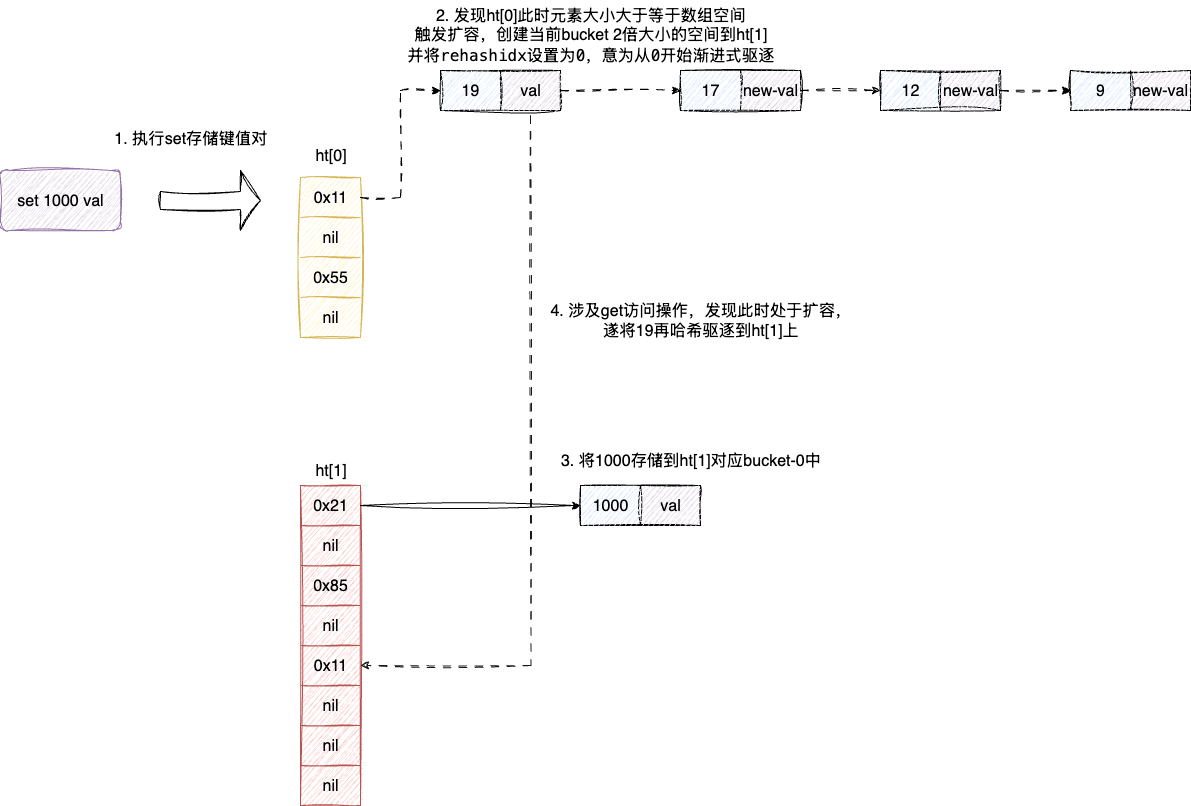
最后因为新元素都存到ht[1],且ht[0]的元素都通过渐进式驱逐的方式迁移到ht[1],此时旧有的ht[0]就没有存在的必要了,所以ht[0]就会直接指向ht[1]的数组,并将ht[1]这个结构体信息重置等待下次扩容使用,自此完成数组扩容和元素迁移:
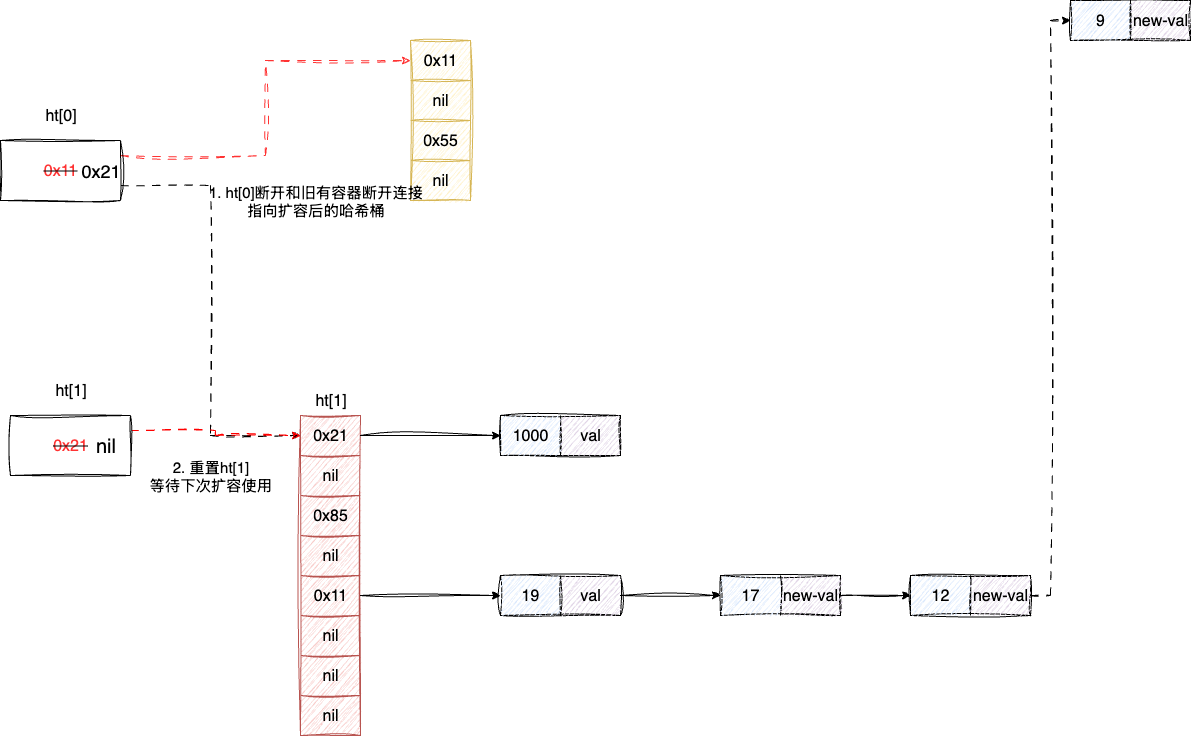
对应的笔者这里也给出渐进式哈希的核心实现dictRehash,可以看到该函数执行渐进式驱逐是顺序遍历ht[0]索引bucket,一旦发现当前bucket为空则继续往前遍历探索下一个bucket,所以极端情况就看存在好几个bucket都没元素造成漫长的扫荡耗时。
考虑到redis处理读写和这些元素驱逐整理都是使用单线程,设计者们在每一轮驱逐给出一个空访问上限empty_visits(默认为10次),一旦扫描空bucket超过这个次数就直接结束本轮渐进式哈希。
定位到非空bucket后,redis就会基于ht[1]的sizemask再哈希计算元素在新哈希表的位置然后采用头插法迁移到新桶上,渐进式哈希每轮会迁移一个bucket的元素,直到完成所有元素迁移再进行原子交换:
// 渐进式哈希
func dictRehash(d *dict, n int) int {
//最大容错次数
empty_visits := n * 10
//......
//循环n次的渐进式重试,在最大限制内完成
for n > 0 && d.ht[0].used != 0 {
n--
var de *dictEntry
var nextde *dictEntry
//定位到非空的bucket桶
for (*(d.ht[0].table))[d.rehashidx] == nil {
d.rehashidx++
empty_visits--
//一旦访问空bucket超过10次则返回
if empty_visits == 0 {
return 1
}
}
//从非空的bucket桶开始
de = (*(d.ht[0].table))[d.rehashidx]
for de != nil {
//再哈希定位元素通过头插法迁移元素到ht[1]
nextde = de.next
h := dictGenHashFunction((*de.key.ptr).(string), len((*de.key.ptr).(string))) & d.ht[1].sizemask
de.next = (*(d.ht[1].table))[h]
(*(d.ht[1].table))[h] = de
d.ht[0].used--
d.ht[1].used++
de = nextde
}
//rehashidx+1告知下一次驱逐的索引位置
(*(d.ht[0].table))[d.rehashidx] = nil
d.rehashidx++
}
//ht[0]为空则原子交换,将ht[1]变为ht[0]
if d.ht[0].used == 0 {
d.ht[0].table = nil
d.ht[0] = d.ht[1]
_dictReset(&(d.ht[1]))
d.rehashidx = -1
}
return 1
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
# 重构思路和落地
完成字典的开发之后,笔者便打算将mini-redis数据库底层数据结构进行重构,将go原生map改为复刻的redis经典的dict,于是笔者索性直接从结构体开始改造:

对应的原有go map操作全部改为封装的dict操作函数

查询等也是同理,笔者就这样一步一步梳理语义并采用最新的轮子进行改造:

# 测试验收
# 基本常规指令覆盖
最后就是测试验收环节,本着严谨的态度笔者打算覆盖所有操作的指令查看mini-redis服务端是否正常运行,首先我们进行一次ping操作:
# set get指令覆盖
然后执行set和get,可以看到键值对可以正常存取:
设置过期时间为1s,1s后查询也是可以正常返回nil:
# 列表操作覆盖
针对列表操作,笔者也进行了:
- 尾部追加元素
- 从左开始遍历查看元素
- 索引定位元素
- 从左开始取出元素
对应的执行也是一切正常:
# 字典操作
同理针对map操作的:
- 单键值对插入
- 单键值对读取
- 多键值对插入
- 多键值对读取
- 单键值对删除
也都是正常运行的
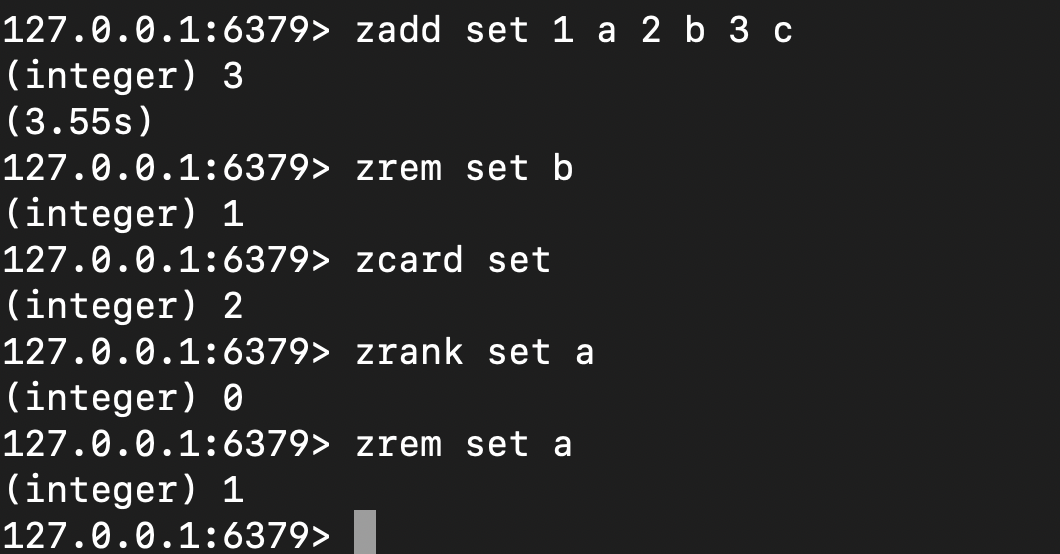
# 有序集合
针对有序集合,笔者也通过:
- 批量添加
- 移除指定裁员
- 获取成员数量
- 查看元素排名 也都一切正常,本次重构大功告成
# 小结
本文通过自底向上向上的方式,先完成dict的开发工作,完成必要的底座调试之后,从db.go模块将原有的数据库数据结构注释,逐步迁移完成功能模块的迁移还进行指令覆盖测试。
同时本文也结合笔者的开发思路简单介绍了一下redis字典这一数据结构的核心理念和开发技巧,希望对你有所启发。
我是 SharkChili ,Java 开发者,Java Guide 开源项目维护者。欢迎关注我的公众号:写代码的SharkChili,也欢迎您了解我的开源项目 mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)。
为方便与读者交流,现已创建读者群。关注上方公众号获取我的联系方式,添加时备注加群即可加入。
# 参考
《redis设计与实现》
redis中的hash是怎么存储的:https://worktile.com/kb/ask/742095.html (opens new window)
