 ES 基础使用指南:开启高效搜索之旅
ES 基础使用指南:开启高效搜索之旅
@[toc]
# 写在文章开头
之前的文章简单介绍了ES中的核心概念,而本文将基于Linux系统简单介绍ES的安装和使用演示,希望对你有帮助。
Hi,我是 sharkChili ,是个不断在硬核技术上作死的技术人,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。

# 详解ES环境搭建
# ES下载安装
首先我们需要下载ES压缩包,以本文为例,笔者使用的是7.12.0版本的ES对应下载指令如下,读者可按需修改完成下载:
curl -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.12.0-linux-x86_64.tar.gz
通过curl指令完成下载后,通过tar 指令进行解压:
tar -zxvf elasticsearch-7.12.0-linux-x86_64.tar.gz
此时我们就可以开始ES的基本配置了,以笔者为例,为了更好的检测ES运行情况信息,笔者通过vim指令修改了ES数据存储和日志的目录,对应文件和路径如下,可以看到配置文件位于ES根目录下的config文件夹下:
vim config/elasticsearch.yml
对应的修改内容和配置如下所示:
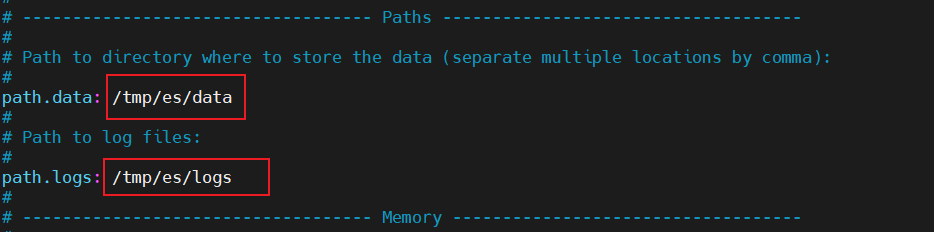
完成配置后我们就可以进入bin目录,执行./elasticsearch将es启动。
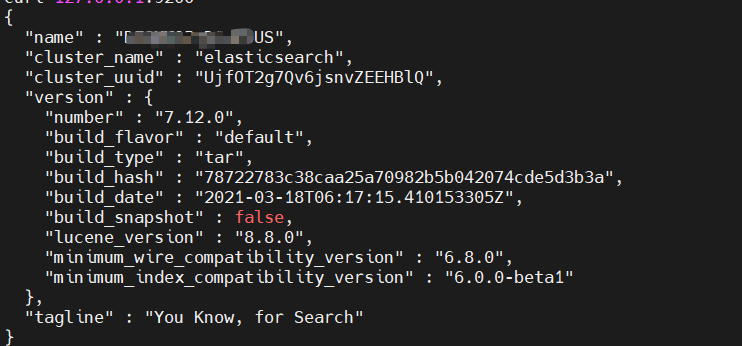
查看控制台没有报错后,我们可以通过curl指令查看es是否正常运行:
curl 127.0.0.1:9200
如下图,在curl之后如果输出es的基本信息则说明本次es配置部署成功:
注意:个别读者可能在使用es的过程中会抛出org.elasticsearch.cluster.block.clusterblockexception: blocked by: [service_unavailable/1/state not这样的问题,原因可能是磁盘空间不足触发的保护机制,强制将所有索引的设置变为只读模式,导致我们后续操作索引过程各种失败,解决方式也比较简单,在明确磁盘空间充分的情况下,针对我们的单节点关闭该配置即可。
以笔者为例,对应的节点node-1只需按照添加下面这条配置即可:
node.name: node-1
# 关闭磁盘保护
cluster.routing.allocation.disk.threshold_enabled: false
2
3
# kibana下载安装
kibana是操作es的图形界面工具,用起来非常方便,接下来我们就开始介绍一下kibana的安装步骤,我们首先到达kibana官网,找到和我们ES一致的Linux版本进行下载,以笔者为例选择的就是7.12.0版本,对应下载地址如下:
Kibana 7.12.0:https://www.elastic.co/cn/downloads/past-releases/kibana-7-12-0 (opens new window)
完成后我们进入kibana根目录的bin目录执行./kibana将其启动。完成后我们通过浏览器访问5601端口如果出现如果进入kibana初始化界面则说明安装成功:
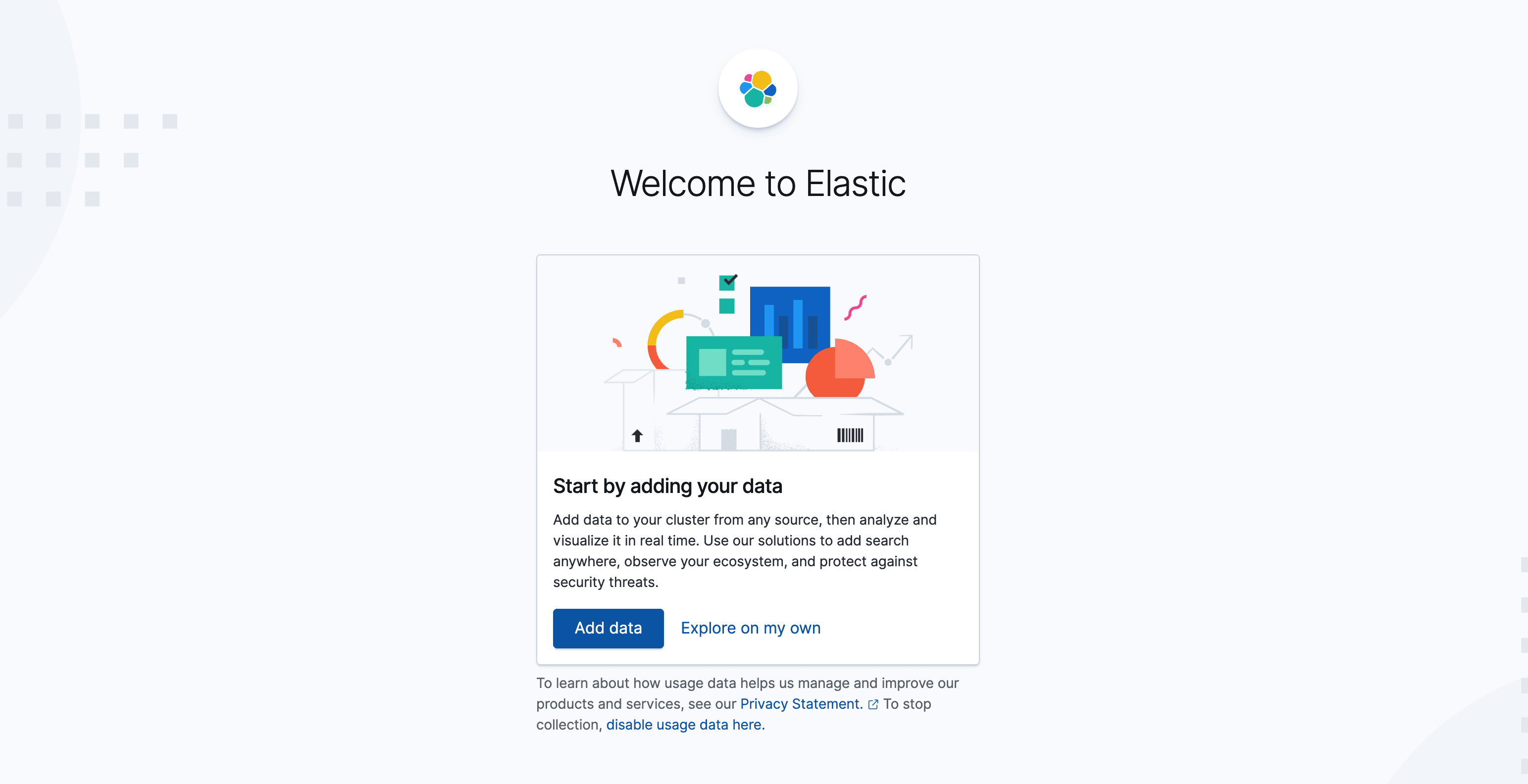
基于上述界面我们可以按需点击add data选择simple data等面板数据导入,这里笔者就不多
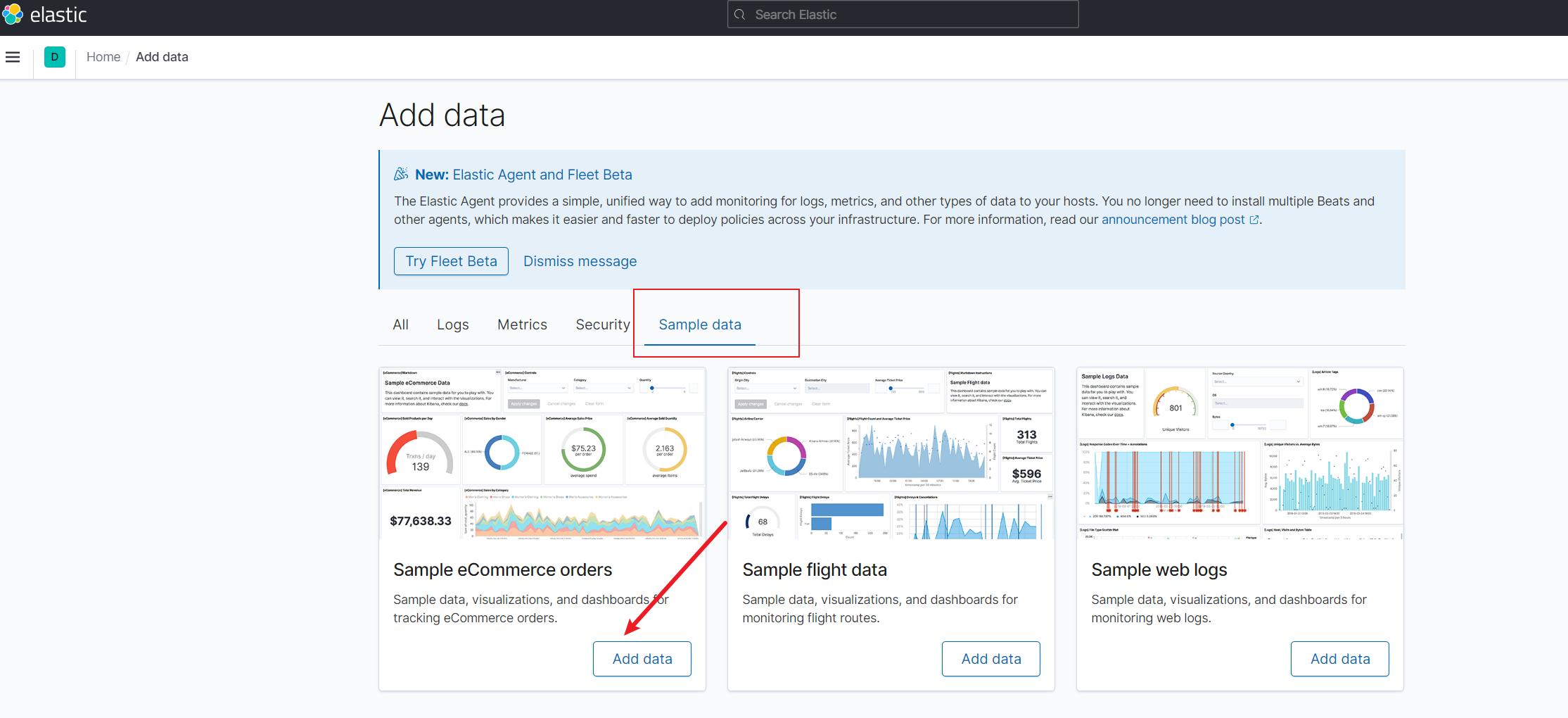
完成之后我们就可以在面板看到各种导入数据的概览信息:
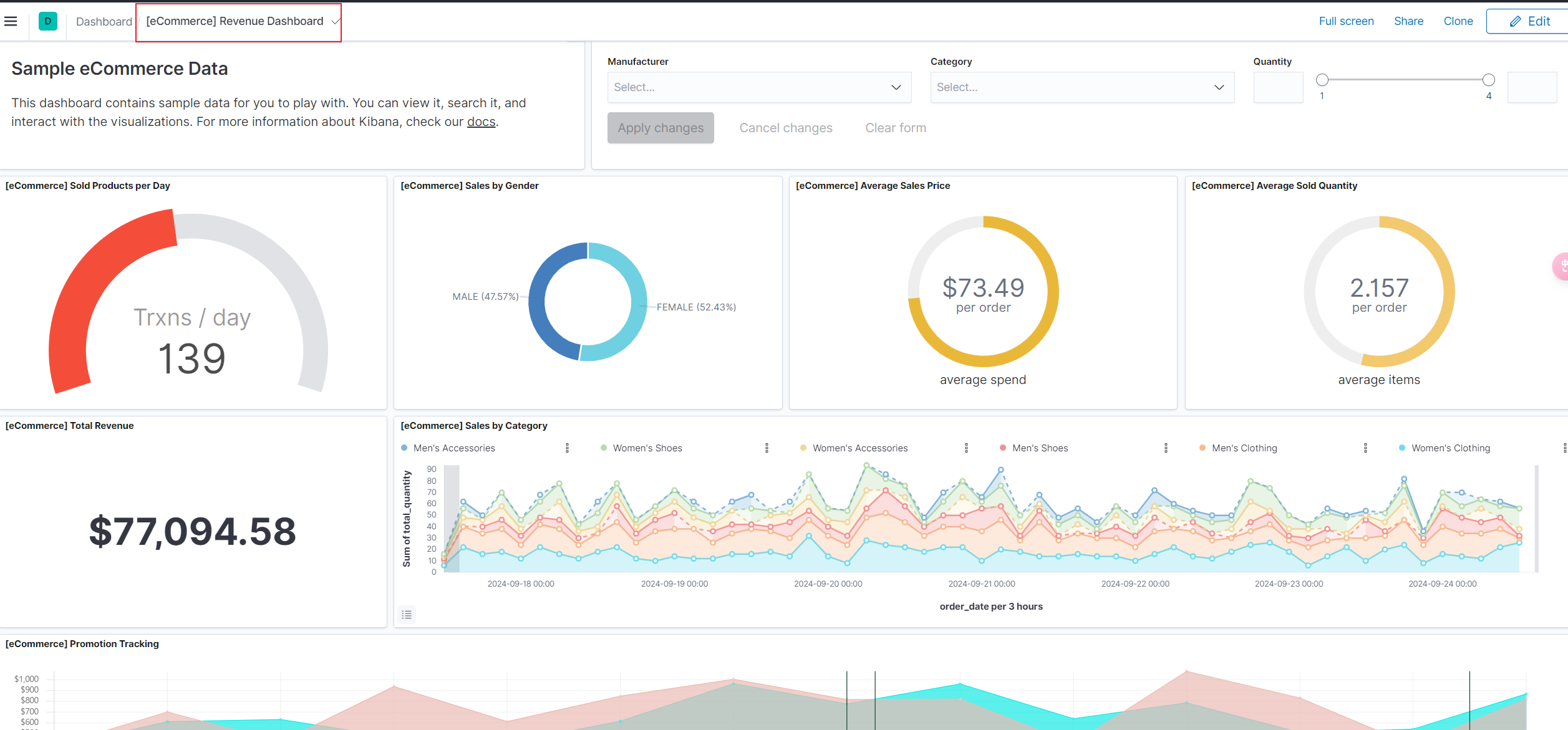
向下翻阅查看就可以看到导入数据的具体详情信息:
# 详解ElasticSearch和Kibana基础搜索姿势
# 基础插入和查询
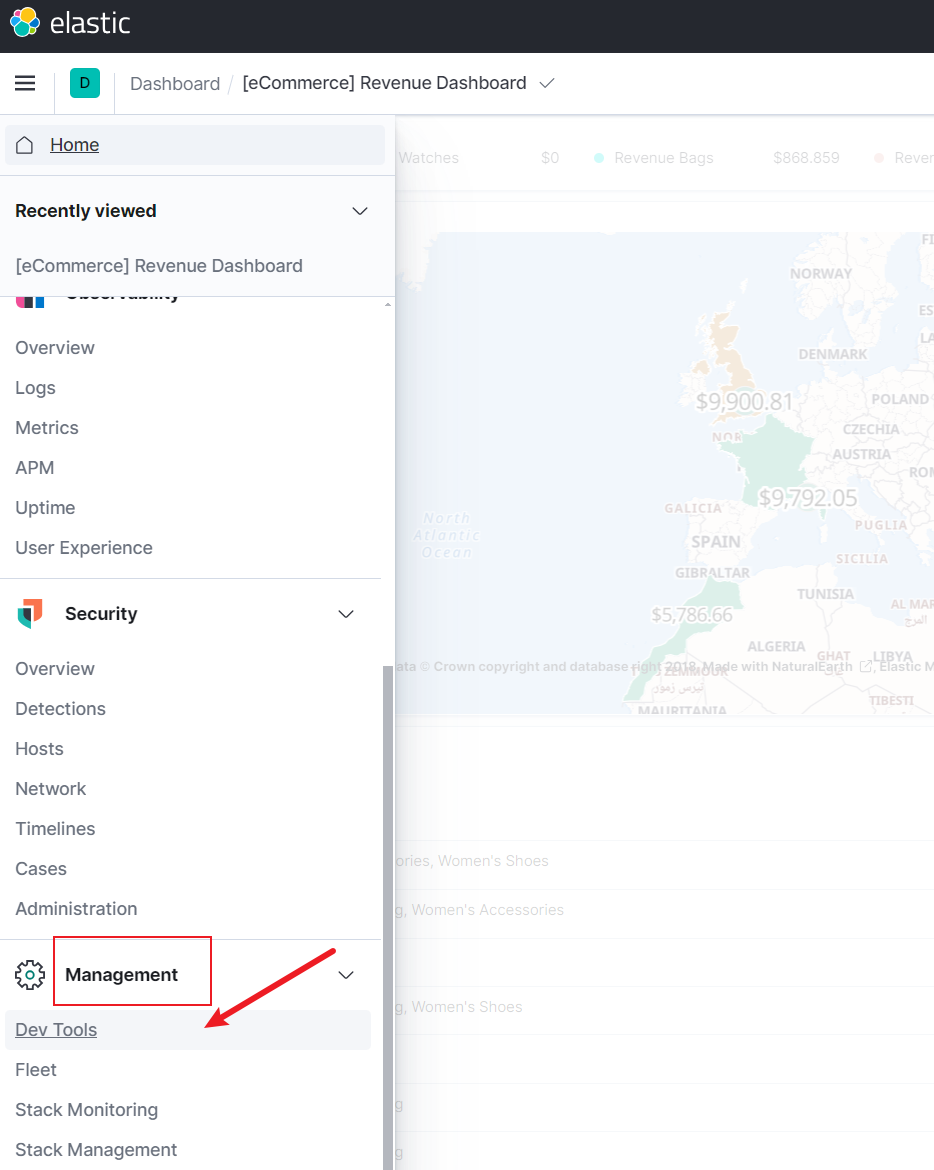
接下来就是正式的介绍Kibana对于ES的操作步骤了,在此之前我们先找到dev tools界面:
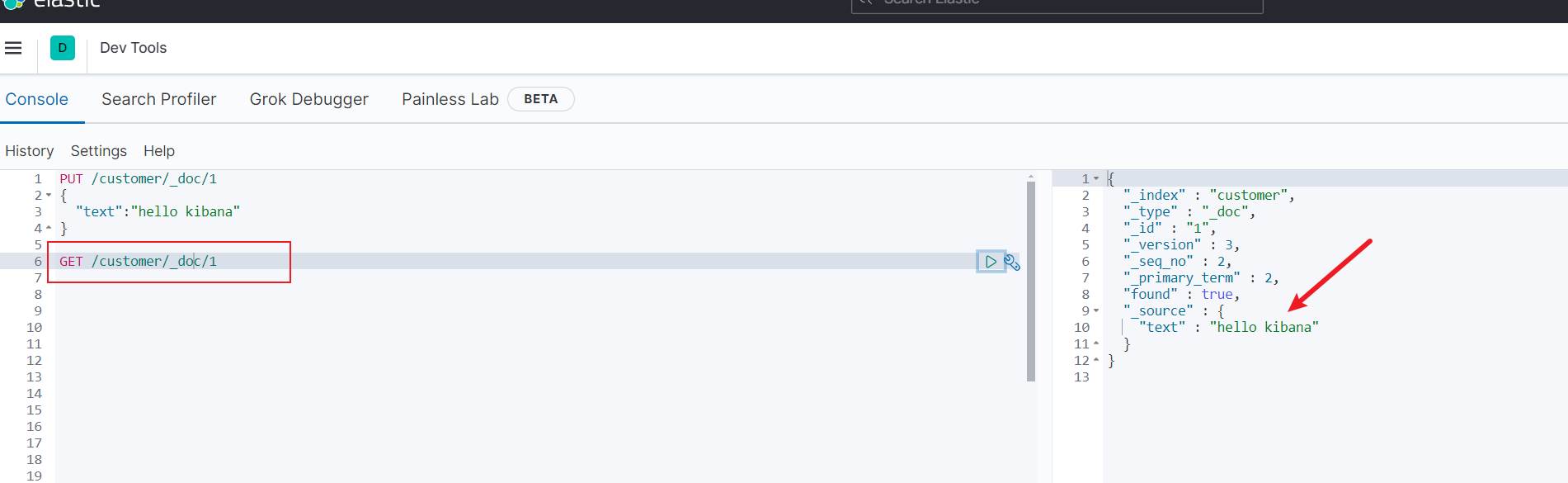
若我们希望通过kibana插入一条数据,我们就可以通过put指令完成,如下所示,我们指定索引名为customer,type为_doc并指定id为1的文档设置数据text为hello kibana
PUT /customer/_doc/1
{
"text":"hello kibana"
}
2
3
4
5
完成后我们可以直接通过GET指令获取对应的指令为GET /customer/_doc/1,最终查询结果如下:
# 查询所有
通过上一个例子我们了解了基于kibana的基础读写ES操作,接下来我们就来演示一下几种比较常见的查询姿势,还记得我们上文导入的simple data嘛?这里我就基于导入的数据演示一下查询所有数据的操作。
对应指令如下,可以看到我们指定导入数据的index为kibana_sample_data_ecommerce,并键入_search指令:
GET /kibana_sample_data_ecommerce/_search
最终我们就可以看到下面这样的输出,这里笔者简单介绍一下几个比较重要的字段:
took:查询耗费时间,单位为毫秒。timed_out:搜索请求是否超时,这里显示false即没有超时。_shards:查询的分片数,并列出成功、失败、跳过的条目数。max_score:最匹配的一份文档的分数值。hits.sort:具体文档列表信息hits._score:具体文档的相关性得分,例如下图第一条目的文档就是1分。

# 分页查询
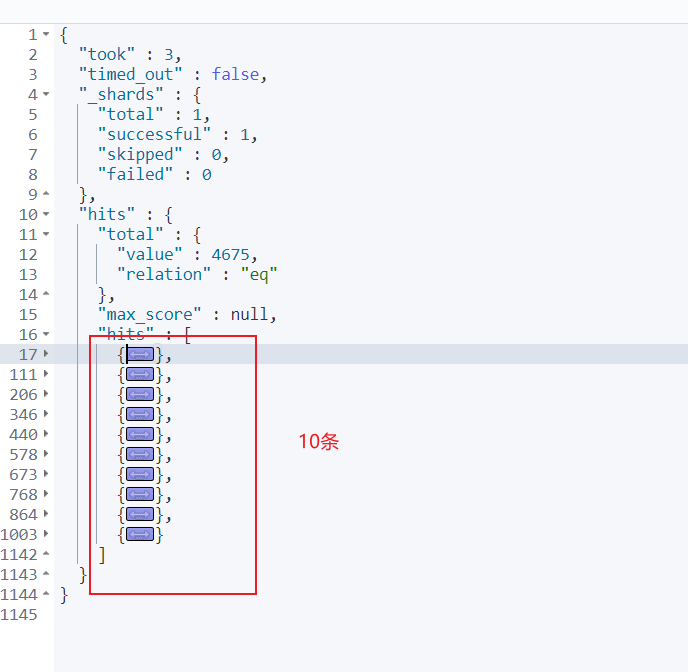
如果我们希望分页查询,则可以通过from指定起始页,通过size指定每页的大小,对应的查询示例如下:
GET /kibana_sample_data_ecommerce/_search
{
"query": { "match_all": {} },
"sort": [
{ "email": "asc" }
],
"from": 1,
"size": 10
}
2
3
4
5
6
7
8
9
输出结果:
# 指定条件字段
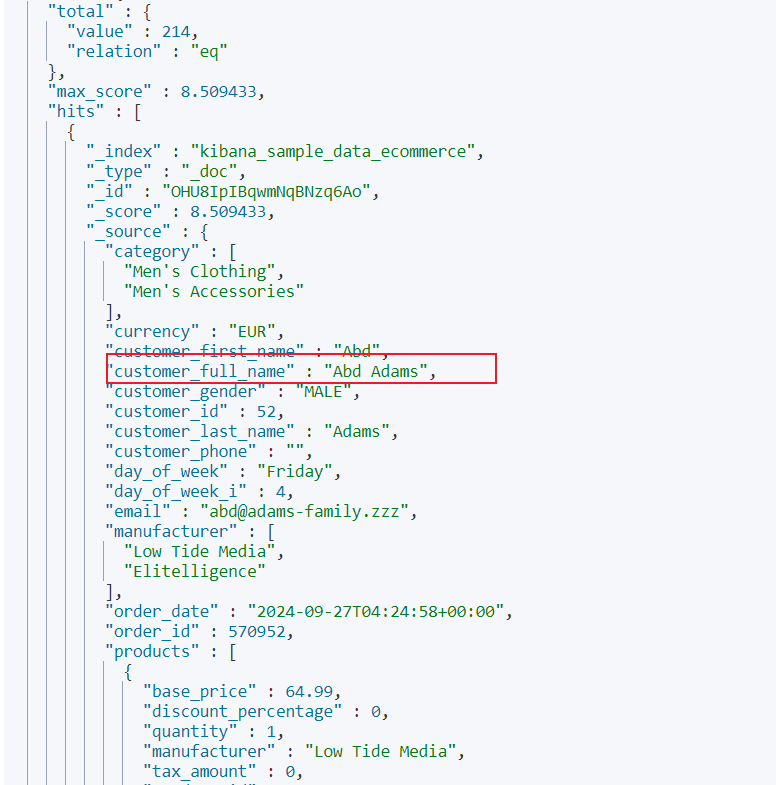
我们希望查询customer_full_name中包含Abd或者Adams中的数据,对此我们就可以通过match指明查询的字段和字段值即可:
GET /kibana_sample_data_ecommerce/_search
{
"query": { "match": { "customer_full_name": "Abd Adams" } }
}
2
3
4
输出结果:
# 段落匹配
上一个例子是针对每一个词项进行匹配,如果我们希望查到customer_full_name中带有Abd Adams的数据,我们就可以通过段落匹配即可实现,对应的指令如下:
GET /kibana_sample_data_ecommerce/_search
{
"query": { "match_phrase": { "customer_full_name": "Abd Adams" } }
}
2
3
4
5
输出结果:
# 多条件查询
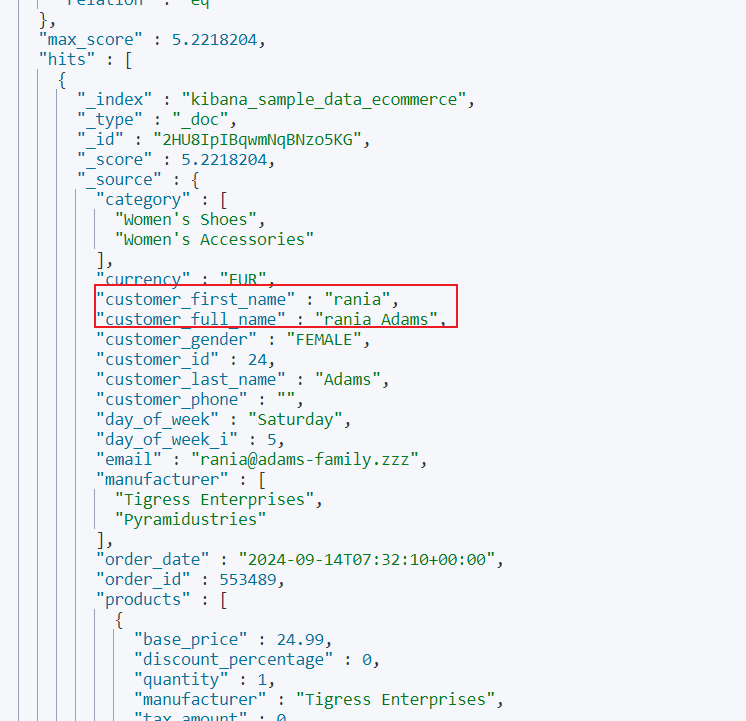
es支持多条件查询,例如我们希望查询customer_full_name带有Abd、Adams但是customer_first_name不包含Abd的数据,那么我们就可以指定:
must中指明customer_full_name为Abd、Adams。must_not中指明customer_first_name为Abd。
对应的指令示例如下:
GET /kibana_sample_data_ecommerce/_search
{
"query": {
"bool": {
"must": [
{ "match": { "customer_full_name": "Abd Adams" } }
],
"must_not": [
{ "match": { "customer_first_name": "Abd" } }
]
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
输出结果:
# 复合条件查询
我们希望查询符合如下3个条件的数据:
customer_full_name为Abd、Adams。currency为EUR。customer_id范围在50~55。
对此我们的编写的检索语句为:
- 指定查询为
bool多条件查询。 must通过match_phrase关键字限定customer_full_name为Abd Adams。filter过滤出值为EUR的currency。- 通过
customer_id限定customer_id范围为50~55。
对应的我们给出查询语句,读者可结合表述进行理解,这里笔者需要补充一点,如果查询时单单使用filter进行过滤的话,查询结果是是不会计算max_score等匹配相关的结果,所以如果读者希望查询时得到每份文档的匹配分数还是建议使用must:
GET /kibana_sample_data_ecommerce/_search
{
"query": {
"bool": {
"must": [
{
"match_phrase": {
"customer_full_name": "Abd Adams"
}
}
],
"filter": [
{
"term": {
"currency": "EUR"
}
},
{
"range": {
"customer_id": {
"gte": 50,
"lte": 55
}
}
}
]
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 简单聚合查询
es同样是支持聚合操作,例如我们希望看到每个customer_full_name对应的文档数,我们就可以通过group_by_state查询指定term(词项)为customer_full_name,被聚合的字段无需对分词统计,所以使用customer_full_name.keyword对整个字段统计:
GET /kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "customer_full_name.keyword"
}
}
}
}
2
3
4
5
6
7
8
9
10
11
输出结果:

# 嵌套聚合
基于上述基础,我们希望查询出这每个人taxful_total_price的平均值,我们可以通过es的嵌套聚合实现,语句如下,基于上述语法基础再声明一个aggs指明avg的字段为taxful_total_price即可:
GET /kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "customer_full_name.keyword"
},
"aggs": {
"average_total_price": {
"avg": {
"field": "taxful_total_price"
}
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 聚合结果排序查询
还是以上面的排序为例,如果我们希望通过taxful_total_price的结果进行升序排序的话,我们可以通过order指明使用的排序结果,以笔者本次示例来说,也就是通过average_total_price的结果进行排序,所以对应的语法如下:
GET /kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "customer_full_name.keyword",
"order": {
"average_total_price": "asc"
}
},
"aggs": {
"average_total_price": {
"avg": {
"field": "taxful_total_price"
}
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
从结果来看,输出的数据确实是按照聚合排序数据显示:

# 详解分词器的概念
# 为什么需要分词器
es所有搜索引擎最重要的就是关键数据检索功能,通过分词器可以提取用户的提交的文档得到带有语义的term构建合理的倒排索引,后续进行查询也可以按照语义进行检索快速定位相关词项。
# 几种常见的分词器
- 标准分词器:支持英文分词
- 空格分词器:按照空格分词
- xx分词器:按照非语义的或者be动词等进行分词
- 中文分词器:最常见的就是ik中文分词器,按照中文词典进行分词。
# 为什么需要ik中文分词器
上文中我们已经给出es的基本使用教程,这里我们介绍一个针对中文搜索的分词器ik中文分词器 ,我们都知道es的进行数据的检索过程大体是:
- 用户传入搜索语句。
- 基于语句过滤掉一些非法字符,例如
html标签、&、and等。 - 将英文分词进行切词、大小归一,得到相关的
key_word。 - 基于切词结果进行匹配得到文档id。
- 基于文档id算出
tf、idf得出_score的值。 - 将最终结果回传客户端。
可能讲的比较抽象,这里笔者给一个比较简单的例子说明一下,假设客户端传的要搜索的是如下数据:
<p> this is es guide</p>
es server收到该请求之后,首先会过滤掉无效的词汇,如上图所示的html中的p标签和is这个be动词,基于英文词汇切除如下几个分词:
this es guide
需要注意的是英文切词还有一个特点,即提取有效词汇,假如我们传的是apple,分词器考虑到可能存在复数或者多种变式的单词后,提取的词可能就算appl,这里读者需要注意一下。
得到切词之后,就可以直接到keyword中定位文档id,然后定位到对应的文档,之后就进入打分阶段,在介绍打分策略前我们需要了解一下TF-IDF的基本概念:
TF:词频(Term Frequency)即每个文档中对应搜索词汇出现的频率,频率越高代表这个文档和检索词相关性越高。DF:检索词在文档中出现的频率,频率越高代表这个词在索引中IDF:逆向文件频率(Inverse Document Frequency)可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到,如果包含词条的文档越少,IDF越大,则说明词条具有很好的类别区分能力。TF-IDF:实际上是:TF * IDF,某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
如下图,按照TF-IDF算法,如果我们用es作为检索词汇来说,它的区分粒度和检索效果相较于this来说是比较好的:

按照默认的英文切词可以做到这一点,针对中文的场景,因为es没有针对中文做出相应的分词器,所以在进行分词的时候会将所有中文逐个切割进行匹配,这就导致的搜索的效果不尽人意,于是就有了ik中文分词器。
ik中文分词器内置了一套带有生活用语的词库针对检索词进行切割,同时它还提供了停用词,不参与索引拆分,就像下面这样,我们的检索词汇是中国的故事,有了中文ik分词器,它按照语义拆分出中国和故事,并且会将停顿词例如的、得这些过滤掉进行搜索:

同时,ik中文分词器还支持同义词关联,例如上述结果中查询的是中国,对应语义下的中华也会当作分词结果返回。
# ik中文分词器安装和使用
我们首先到官网下载一下ik中文分词器,对应网站地址为:https://release.infinilabs.com/analysis-ik/stable/ (opens new window),唯一需要注意的就是版本的选择,因为笔者用的es版本为7.12.0所以对应的分词器也要下载相同的版本:

然后我们在es的目录下新建一个名为ik的文件夹,将我们下载的分词器解压到下面这个目录中,完成后基于./elasticsearch -d将es后台启动:

# ik中文分词器几种使用姿势
随后我们就可以使用ik中文分词器了,通过postman调用http://localhost:9200/_analyze ,并传入搜索词汇,可以看到笔者传入ik_smart模式:
{
"text": "人民共和国",
"analyzer":"ik_smart"
}
2
3
4
5
对应搜索结果如下,可以看到基于ik_smart下只定位到了人民共和国这个token,很明显该查询原则是基于词典进行尽可能小的拆分得出一个完整的词汇:
{
"tokens": [
{
"token": "人民共和国",
"start_offset": 0,
"end_offset": 5,
"type": "CN_WORD",
"position": 0
}
]
}
2
3
4
5
6
7
8
9
10
11
我们再将分词要求改为ik_max_word之后的搜索结果如下,可以看到相较于前者,ik_max_word是尽最大努力根据词库中的词典进行拆分:
{
"tokens": [
{
"token": "人民共和国",
"start_offset": 0,
"end_offset": 5,
"type": "CN_WORD",
"position": 0
},
{
"token": "人民",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 1
},
{
"token": "共和国",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
},
{
"token": "共和",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 3
},
{
"token": "国",
"start_offset": 4,
"end_offset": 5,
"type": "CN_CHAR",
"position": 4
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
所以我们建议创建索引的使用ik_max_word进行分词,而搜索的时候尽量使用ik_smart,通过ik_max_word保证文档中所有相关性词汇能够被提取,基于ik_smart可以保证搜索的时候可以得到最相关的词汇。
上述也说过,ik中文分词器更多是针对生活词库,对于特殊领域需要补充词典的,ik分词器也是支持自定义并导入的,相关的配置教程读者可以参考这篇文章:https://blog.csdn.net/qq_43692950/article/details/122274613 (opens new window)
# 小结
自此笔者将所有es的基础操作都演示完成,希望对你有帮助。
我是 sharkchili ,CSDN Java 领域博客专家,mini-redis的作者,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
# 参考
ES详解 - 安装:ElasticSearch和Kibana安装:https://www.pdai.tech/md/db/nosql-es/elasticsearch-x-install.html (opens new window)
ES详解 - 入门:查询和聚合的基础使用:https://www.pdai.tech/md/db/nosql-es/elasticsearch-x-usage.html (opens new window)
ElasticSearch——Kibana 的Windows安装和Dev Tools的使用 :https://blog.csdn.net/wpc2018/article/details/121118269#:~:text=Kibana 是一款 (opens new window)
https://blog.csdn.net/WU4566285/article/details/104958216
https://blog.csdn.net/qq_43692950/article/details/122274613
https://blog.csdn.net/asialee_bird/article/details/81486700
https://blog.csdn.net/weixin_43447266/article/details/121716105
