 能不能给我讲讲redis中的列表
能不能给我讲讲redis中的列表
# 写在文章开头
本文将从redis源码的角度直接分析列表操作指令,因为大部分指令操作细节区别不是很大,同时为了更专注于列表逻辑的分析,所以本文笔者将以双向链表这个数据结构为核心对lrange、lindex、llen、rpush、lpop几个操作展开介绍,希望对你有帮助。
Hi,我是 sharkChili ,是个不断在硬核技术上作死的技术人,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
# 详解redis列表操作的指令
# 回顾指令解析过程
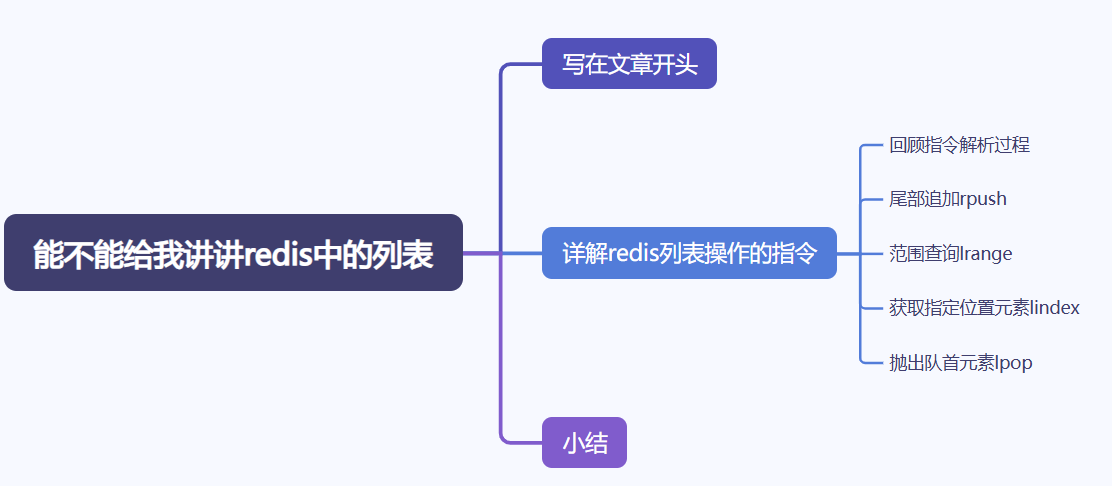
在正式分析列表操作源码之前,我们来复习一下redis-cli传入的指令如何被redis服务端解析并处理的,我们以列表尾部追加指令rpush为例,假如我们键入:
rpush list a b
本质上,redis-cli传入的指令为RESP协议规范的*4\r\n$5\r\nrpush\r\n$4\r\nlist\r\n$1\r\na\r\n$1\r\nb\r\n,看起来非常不好理解,我们不妨按照格式的规范进行切割,如下所示,我们将所有的\r\n转为本意即换行符,最终可以得到如下几行字符,对应含义为:
*4表示后面有4个字符串,分别是rpush、list、a、b。$5表示下一行的字符串长度为5,redis解析时只需换行后截取5个长度即得到rpush。rpush后面跟着一个$4意味着rpush之后跟着的字符串长度为4即list,后续a、b同理这里不多做赘述。
*4
$5
rpush
$4
list
$1
a
$1
b
2
3
4
5
6
7
8
9
10
基于上述的解析我们可以得到一个长度为4的字符串数组,每个元素都通过redis的robj结构体封装为redis字符串对象,我们以字符串a为例可以看到redis所封装的robj包含了对象的类型、编码格式、值的指针地址:
对此我们也给出解析上述字符串并生成数组的函数processMultibulkBuffer,可以看到完成字符串解析后通过createStringObject将其生成字符串类型的robj存入argc这个数组中:
int processMultibulkBuffer(redisClient *c) {
//......
while(c->multibulklen) {//基于长度遍历参数
//......
/* Read bulk argument */
if (sdslen(c->querybuf)-pos < (unsigned)(c->bulklen+2)) {
/* Not enough data (+2 == trailing \r\n) */
break;
} else {
if (pos == 0 &&
c->bulklen >= REDIS_MBULK_BIG_ARG &&
(signed) sdslen(c->querybuf) == c->bulklen+2)
{
//......
} else {//基于bulklen截取字符串放到argv上并自增argc
c->argv[c->argc++] =
createStringObject(c->querybuf+pos,c->bulklen);
pos += c->bulklen+2;//跨过字符串的\r\n移动到下一个$的位置
}
c->bulklen = -1;//重置bulklen并扣减multibulklen
c->multibulklen--;
}
}
//......
return REDIS_ERR;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
这里我们也给出createStringObject的内部实现,可以看到当字符串小于39时,创建的robj的字符串类型为embeddedString,反之为rawString的robj的redis对象:
#define REDIS_ENCODING_EMBSTR_SIZE_LIMIT 39
robj *createStringObject(char *ptr, size_t len) {
//若小于39则创建embeddedString类型的字符串
if (len <= REDIS_ENCODING_EMBSTR_SIZE_LIMIT)
return createEmbeddedStringObject(ptr,len);
else //反之生成rawString类型
return createRawStringObject(ptr,len);
}
2
3
4
5
6
7
8
最后我们再给出robj 的创建过程,可以看到它会将外部传入的字符串指针的和字符串长度记录到sdshdr ,然后交由robj 统一记录其类型、编码、sds字符串指针地址:
robj *createEmbeddedStringObject(char *ptr, size_t len) {
robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr)+len+1);
struct sdshdr *sh = (void*)(o+1);
//设置类型为REDIS_STRING
o->type = REDIS_STRING;
//设置编码格式为REDIS_ENCODING_EMBSTR意为REDIS_ENCODING_EMBSTR的字符串type类型的对象
o->encoding = REDIS_ENCODING_EMBSTR;
//ptr指向sdshdr结构体
o->ptr = sh+1;
o->refcount = 1;
//......
//sh将传入指针的字符串地址和长度记录下来
sh->len = len;
//......
if (ptr) {
//......
sh->buf[len] = '\0';
} else {
memset(sh->buf,0,len+1);
}
return o;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 尾部追加rpush
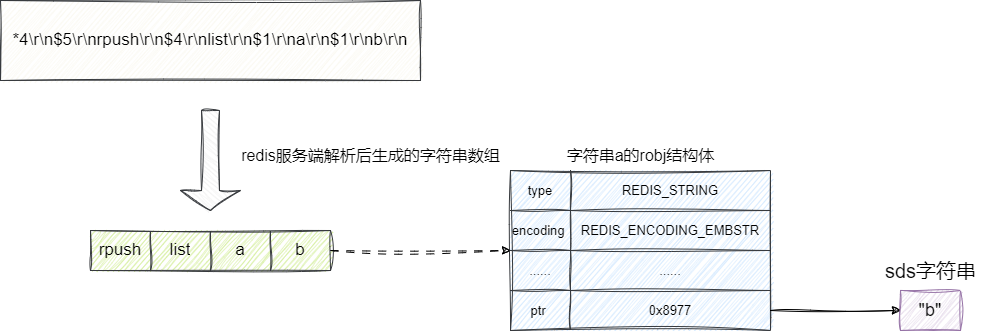
通过上文的步骤我们得到的实际的字符串数组,随后redis会根据数组0得到指令字符串为rpush,由此走到rpushCommand将传入的元素值a、b追加到链表末尾:
对此我们给出rpushCommand的源码实现,可以看到其内部调用pushGenericCommand传入尾节点的常量定义告知pushGenericCommand执行尾部追加:
void rpushCommand(redisClient *c) {
//调用pushGenericCommand操作链表,传入REDIS_TAIL告知函数从尾部追加
pushGenericCommand(c,REDIS_TAIL);
}
2
3
4
最终函数就来到了pushGenericCommand,其内部首先会查看是否有key为list的值,如果有则判断是否为列表类型如果不是则报错。完成检查之后从索引2开始遍历元素,在此期间会检查列表是否存在,如果不存在则调用通过createZiplistObject创建一个列表,然后调用listTypePush将元素添加到列表中:
void pushGenericCommand(redisClient *c, int where) {
int j, waiting = 0, pushed = 0;
robj *lobj = lookupKeyWrite(c->db,c->argv[1]);//查看列表对象是否存在
if (lobj && lobj->type != REDIS_LIST) {//查看类型是否是列表类型,如果不是则直接返回异常
addReply(c,shared.wrongtypeerr);
return;
}
//从元素索引位置开始
for (j = 2; j < c->argc; j++) {
c->argv[j] = tryObjectEncoding(c->argv[j]);
if (!lobj) {//如果列表对象不存在则手动创建一个列表
lobj = createZiplistObject();
dbAdd(c->db,c->argv[1],lobj);
}
listTypePush(lobj,c->argv[j],where);
pushed++;
}
//判断列表是否存在,如果存在则返回当前列表数
addReplyLongLong(c, waiting + (lobj ? listTypeLength(lobj) : 0));
//......
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
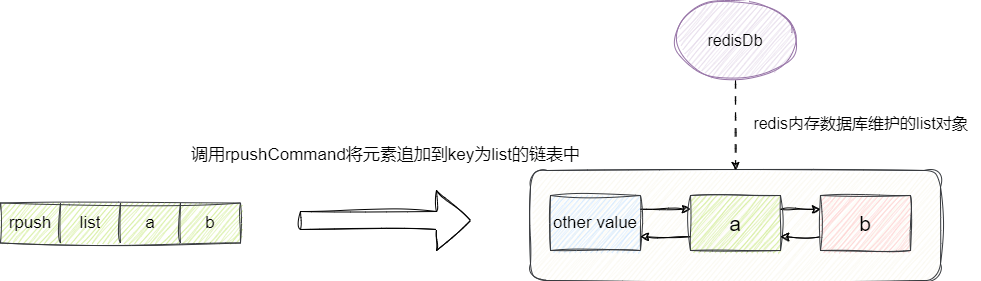
这里我们补充一个实现的细节,我们将数组元素存到链表前有个tryObjectEncoding的逻辑,为了尽可能节省内存空间,redis将数组内部元素存到列表前会针对这些元素进行类型转换,如果能转为数字类型则查看这个数值类型是否小于10000,如果是则用常量池中的数值类型robj作为转换后的结果,反之如果大于10000则手动强转为数值类型并封装成robj返回,若不能转为数字类型则按照字符串长度生成embstr或者rawString再封装到robj中返回:
对此我们给出tryObjectEncoding的源码和注释,大体逻辑和笔者描述的基本一致:
robj *tryObjectEncoding(robj *o) {
long value;
sds s = o->ptr;
size_t len;
//......
len = sdslen(s);
if (len <= 21 && string2l(s,len,&value)) {//尝试是否可以转换为数值类型
if ((server.maxmemory == 0 ||
(server.maxmemory_policy != REDIS_MAXMEMORY_VOLATILE_LRU &&
server.maxmemory_policy != REDIS_MAXMEMORY_ALLKEYS_LRU)) &&
value >= 0 &&
value < REDIS_SHARED_INTEGERS)//如果小于10000则从常量池里获取robj对象
{
decrRefCount(o);
incrRefCount(shared.integers[value]);
return shared.integers[value];
} else {//反之手动创建数值类型的redis对象
if (o->encoding == REDIS_ENCODING_RAW) sdsfree(o->ptr);
o->encoding = REDIS_ENCODING_INT;
o->ptr = (void*) value;
return o;
}
}
if (len <= REDIS_ENCODING_EMBSTR_SIZE_LIMIT) {//如果长度没有超过39则创建embStr类型的robj
robj *emb;
if (o->encoding == REDIS_ENCODING_EMBSTR) return o;
emb = createEmbeddedStringObject(s,sdslen(s));
decrRefCount(o);
//将外部传入的字符串封装成embstr类型的robj对象返回
return emb;
}
//......
return o;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
来到listTypePush即可看到我们的核心逻辑,我们以链表为例,可以看到如果传入的链表encoding 为REDIS_ENCODING_LINKEDLIST,它会根据传入的where判断是头插还是尾插,以我们上一步的rpushCommand为例传入的是REDIS_TAIL,所以它会调用listAddNodeTail将元素追加到链表尾部,最终结果就如上文图解,具体逻辑读者可参阅笔者给出源码及其注释:
void listTypePush(robj *subject, robj *value, int where) {
//......
if (subject->encoding == REDIS_ENCODING_ZIPLIST) {
//......
} else if (subject->encoding == REDIS_ENCODING_LINKEDLIST) {//如果传入的列表类型为链表
if (where == REDIS_HEAD) {//如果where为REDIS_HEAD则调用listAddNodeHead插入到链表头部
listAddNodeHead(subject->ptr,value);
} else {//调用尾插法将数据插入
listAddNodeTail(subject->ptr,value);
}
incrRefCount(value);
} else {
//......
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 范围查询lrange
redis支持对列表进行范围查询,以我们上文存入的key为list的链表元素a、b为例,我们可以通过下面这段指令获取所有的元素:
lrange list 0 -1
对应的输出结果如下:
1) "a"
2) "b"
2
需要注意的是redis-cli看到的数据本质上也是通过解析RESP协议规范所得到的数据,实际上redis返回的数据是:*2\r\n$1\r\na\r\n$1\r\nb\r\n,我们还是按照上文的解读进行翻译将\r\n转为换行符:
*2
$1
a
$1
b
2
3
4
5
对应的含义为长度为2,第一个元素长度为1值为a,第二个元素长度为1值为b。对应的我们也给出lrange指令的抓包截图:

我们键入lrange最终就会走到到lrangeCommand, 以我们传入的指令lrange list 0 -1为例,函数解析会将start设置为0,end设置为-1,因为end是负数,lrangeCommand会通过加上链表长度将其转为正数最终得到end为1,由此得到最终的结果start为0而end为1,这就是为什么我们传入lrange 的end为-1即可得到链表所有元素的原因:
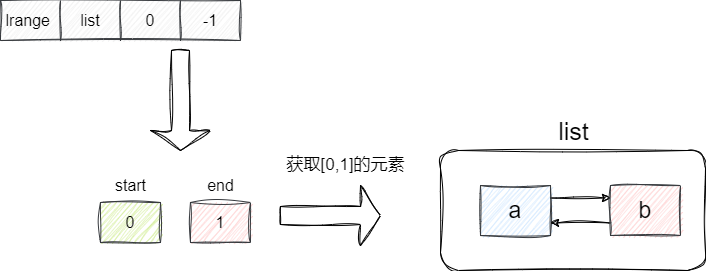
对此我们给出lrangeCommand的源码实现,大体逻辑和上文描述差不多,即计算起止索引坐标,然后遍历链表将结果按照RESP协议返回:
void lrangeCommand(redisClient *c) {
robj *o;
long start, end, llen, rangelen;
//将解析后的argc数组的索引2元素设置为start位置,索引3设置为end位置
if ((getLongFromObjectOrReply(c, c->argv[2], &start, NULL) != REDIS_OK) ||
(getLongFromObjectOrReply(c, c->argv[3], &end, NULL) != REDIS_OK)) return;
if ((o = lookupKeyReadOrReply(c,c->argv[1],shared.emptymultibulk)) == NULL
|| checkType(c,o,REDIS_LIST)) return;
//获取链表长度
llen = listTypeLength(o);
/* convert negative indexes */
//如果小于0则+链表长度转为正数
if (start < 0) start = llen+start;
//这就是为什么end我们传-1可以拿到链表所有元素的原因,-1+llen拿到的索引就是链表最后一个元素值
if (end < 0) end = llen+end;
if (start < 0) start = 0;
//......
rangelen = (end-start)+1;//获取需要遍历的长度
/* Return the result in form of a multi-bulk reply */
addReplyMultiBulkLen(c,rangelen);
if (o->encoding == REDIS_ENCODING_ZIPLIST) {
//......
} else if (o->encoding == REDIS_ENCODING_LINKEDLIST) {
listNode *ln;
//......
while(rangelen--) {//循环遍历链表长度输出每一个元素给客户端
addReplyBulk(c,ln->value);
ln = ln->next;
}
} else {
//......
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
# 获取指定位置元素lindex
对应索引位置的元素我们可以通过lindex 指令获取,假设我们希望获取list中索引0的元素,我们就可以通过lindex 获取,对应的指令示例如下:
lindex list 0
对此我们给出lindexCommand的源码实现,以链表为例,可以看到我们拿到索引值之后直接调用listIndex即可拿到对应索引位置的节点,然后通过listNodeValue拿到元素值返回:
void lindexCommand(redisClient *c) {
//查看值是否存在,如果不存在则返回空响应nullbulk
robj *o = lookupKeyReadOrReply(c,c->argv[1],shared.nullbulk);
//......
if ((getLongFromObjectOrReply(c, c->argv[2], &index, NULL) != REDIS_OK))
return;
if (o->encoding == REDIS_ENCODING_ZIPLIST) {
//......
} else if (o->encoding == REDIS_ENCODING_LINKEDLIST) {
listNode *ln = listIndex(o->ptr,index);//基于传入的index循环遍历获取节点
if (ln != NULL) {//取出节点值然后返回
value = listNodeValue(ln);
addReplyBulk(c,value);
} else {
addReply(c,shared.nullbulk);
}
} else {
redisPanic("Unknown list encoding");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 抛出队首元素lpop
与push操作相反pop就是抛出链表中的元素,我们以lpop为例,它本质上就是将链表首部的元素抛出,对应的指令和输出结果如下:
127.0.0.1:6379> lpop list
"a"
(45.81s)
2
3
lpop 操作最终会走到lpopCommand函数,该函数先先得到链表首元素,将其从链表中删除后将这个value返回给客户端:
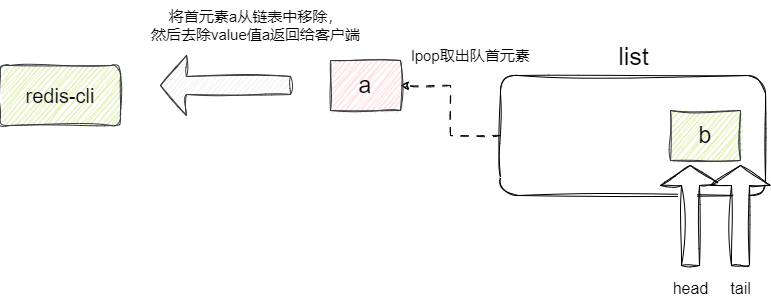
该操作比较简单,我们直接从源码角度进行分析,其内部调用popGenericCommand传入REDIS_HEAD告知当前操作要抛出链表第一个元素:
void lpopCommand(redisClient *c) {//调用popGenericCommand,传入REDIS_HEAD意为抛出链表第一个元素
popGenericCommand(c,REDIS_HEAD);
}
2
3
步入popGenericCommand即可看到其内部会从内存数据库中拿到链表,然后调用listTypePop将我们的操作标识where也就是我们传入的REDIS_HEAD传入,该方法就会返回链表首元素,并将该元素从链表中删除:
void popGenericCommand(redisClient *c, int where) {
//查看链表对应的key是否存在,如果不存在则返回nullbulk
robj *o = lookupKeyWriteOrReply(c,c->argv[1],shared.nullbulk);
if (o == NULL || checkType(c,o,REDIS_LIST)) return;
//传入where(即抛出链表头还是链表尾标识)取出链表元素
robj *value = listTypePop(o,where);
if (value == NULL) {
addReply(c,shared.nullbulk);
} else {
addReplyBulk(c,value);//将结果返回给redis客户端
//......
if (listTypeLength(o) == 0) {//如果抛出元素后链表长度为0则直接删除该元素
//......
dbDelete(c->db,c->argv[1]);
}
//......
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
基于上述解析我们给出listTypePop的源码分析,以链表为例讲解我们的操作,实际上其底层就是拿到链表的首元素并获取这个元素的值赋值给value,然后将该元素从链表中删除后返回:
robj *listTypePop(robj *subject, int where) {
robj *value = NULL;
if (subject->encoding == REDIS_ENCODING_ZIPLIST) {
//......
} else if (subject->encoding == REDIS_ENCODING_LINKEDLIST) {//链表的lpop逻辑
list *list = subject->ptr;
listNode *ln;
if (where == REDIS_HEAD) {//获取链表头元素
ln = listFirst(list);
} else {
ln = listLast(list);
}
if (ln != NULL) {//将元素从链表中删除
value = listNodeValue(ln);
incrRefCount(value);
listDelNode(list,ln);
}
} else {
redisPanic("Unknown list encoding");
}
//返回链表这个元素的值
return value;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 小结
自此我们以链表的角度将redis列表核心操作都分析完成,希望对你有帮助。
我是 sharkchili ,CSDN Java 领域博客专家,mini-redis的作者,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。 因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
