 聊聊redis中的有序集合
聊聊redis中的有序集合
# 写在文章开头
有序集合(sorted set)是redis中比较常见的数据库结构,它不仅支持O(logN)界别的有序的范围查询,同时也支持O(1)级别的单元素查询,基于此问题,本文就将从redis源码的角度分析一下有序集合的设计与实现。
Hi,我是 sharkChili ,是个不断在硬核技术上作死的 java coder ,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
# 详解redis中的有序集合
# 基本结构介绍
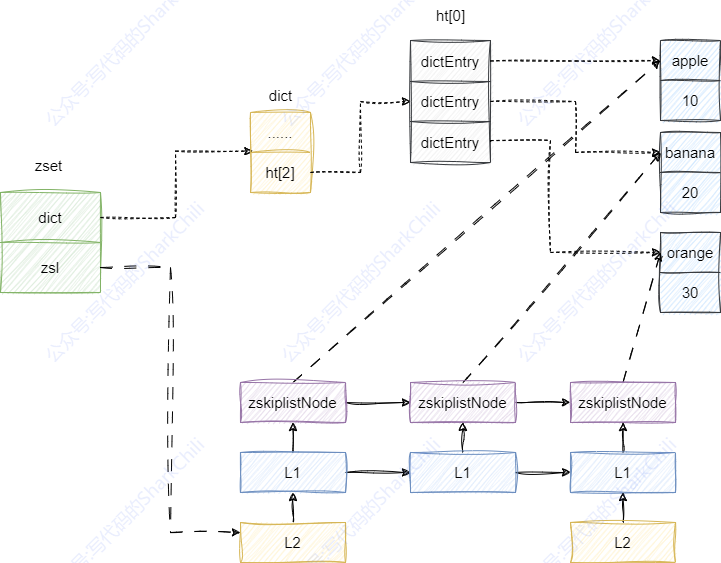
有序集合的实现可以说是集大成于一身,它之所以支持单元素查询和范围查询,是字典(dict)和跳表(skipList)的组合结果,它将带有权重的元素指针分别交给字典和跳表进行管理。
关于跳表的介绍,笔者之前也写过一篇关于跳表的设计与实现思路的文章,感兴趣的可以移步JavaGuide官网:
Redis为什么用跳表实现有序集合 (opens new window)
当我们需要通过元素名称定位其权重时,我们可以通过哈希算法到字典中定位到对应的元素,以下图为例,若我们希望定位到apple这个元素的权重时,可以直接计算apple的哈希值结合哈希算法即可实现O(1)级别的元素定位。
当我们希望进行范围查询时,很明显哈希表算法的无序性很难快速做到这一点,对应的我们可以直接通过跳表的索引快速定位到指定范围,以下图为例,假设我们希望查询权重在20到30之间的元素,对应的跳表的查询路径为:
apple节点的2级索引。apple节点的1级索引。- 通过
banana的1级索引锁定范围。
这种通过多级索引的方式使得跳表范围查询的时间复杂度为O(logN)级别非常之高效。
关于有序集合的源码定义,因为该数据结构是组合而非自实现,所以其定义在redis.h这个头文件中:
typedef struct zset {
//字典
dict *dict;
//跳表
zskiplist *zsl;
} zset;
2
3
4
5
6
# 有序集合的初始化和保存操作
假设我们键入如下指令插入一个权重为1的元素:
ZADD runoobkey 1 dskadjksldksdjsdjskdjksldklsdjlksdjklsadjksladjklsdjksldjksladjskaldjskdjsalkdlksadksdklsadjklsadklsaddkslkadsakdjdlkjsdlkjdlkadjlksadjklsajlksjdjsakldjksadjklsdjlsakdjlsadadasdjsakdljskaldjlksdjlksdjlksajdklsdjksladjklsadjklsajdlksadjlksajdksajdskldjaslkdjsalkdjslkajdskadjlksadjksladjklsadskadjlskajdksajdksaldjksldjkldjsalkdjklsadjlksajdlkadjksajdksladjksladjsdjslakdjlksadjsakldjlksajdlksajdlksajdlksajdlksajdlksajdsladjladskdjlsakjdlksajdlkajdlsakdj
redis服务端收并解出zadd命令后就会调用zaddGenericCommand初始化字典和跳表,再进行元素的保存操作,对应的源码如下,这里笔者省去了有序集合为压缩列表时元素维护的逻辑,可以看到当插入的元素值的长度若大于64字节,则创建的有序集合是由跳表和字典构成。
完成初始化之后,无论是更新还是插入操作,有序集合都会基于该元素的指针将其分别维护到跳表和字典中:
void zaddGenericCommand(redisClient *c, int incr) {
//......
//判断有序集合是否存在
zobj = lookupKeyWrite(c->db,key);
//若为空则当前元素长度大于zset_max_ziplist_value(默认为64)则创建上文所说的有序集合
if (zobj == NULL) {
if (server.zset_max_ziplist_entries == 0 ||
server.zset_max_ziplist_value < sdslen(c->argv[3]->ptr))
{
//创建通过字典和跳表组合实现的有序集合
zobj = createZsetObject();
} else {
zobj = createZsetZiplistObject();
}
//将有序集合存入键值对中
dbAdd(c->db,key,zobj);
} else {
//......
}
//
for (j = 0; j < elements; j++) {
score = scores[j];
//有序集合为压缩列表的逻辑
if (zobj->encoding == REDIS_ENCODING_ZIPLIST) {
//......
} else if (zobj->encoding == REDIS_ENCODING_SKIPLIST) {//基于字典和跳表生成有序集合
zset *zs = zobj->ptr;
zskiplistNode *znode;
dictEntry *de;
ele = c->argv[3+j*2] = tryObjectEncoding(c->argv[3+j*2]);
//到哈希表中定位元素并完成保存或者更新操作
de = dictFind(zs->dict,ele);
if (de != NULL) {
//更新操作
} else {
//插入操作,先将其元素插入到跳表
znode = zslInsert(zs->zsl,score,ele);
//......
//再将元素的指针同时维护到字典中
redisAssertWithInfo(c,NULL,dictAdd(zs->dict,ele,&znode->score) == DICT_OK);
//......
}
} else {
redisPanic("Unknown sorted set encoding");
}
}
//......
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
# 利用字典完成单值查询(ZRANGE指令)
有了这样一个组合的数据结构,不同的查询操作就变得非常方便,例如我们使用Zrank 查询对应有序集合zset的element-1的权重:
Zrank zsets element-1
redis解析该字符串后走到zrankCommand方法,其内部调用zrankGenericCommand,直接通过当前传入的元素的名称到字典中快速定位元素权重并返回:
void zrankCommand(redisClient *c) {
//调用zrankGenericCommand完成O(1)级别的查询
zrankGenericCommand(c, 0);
}
void zrankGenericCommand(redisClient *c, int reverse) {
//获取参数中的key和要查询的元素
robj *key = c->argv[1];
robj *ele = c->argv[2];
robj *zobj;
unsigned long llen;
unsigned long rank;
//......
redisAssertWithInfo(c,ele,sdsEncodedObject(ele));
//有序集合为跳表的逻辑,不重要所以直接跳过
if (zobj->encoding == REDIS_ENCODING_ZIPLIST) {
//......
} else if (zobj->encoding == REDIS_ENCODING_SKIPLIST) {
//......
//通过有序集合的字典快速定位元素并返回
de = dictFind(zs->dict,ele);
if (de != NULL) {
//获取score
score = *(double*)dictGetVal(de);
//从跳表中获得对应等级
rank = zslGetRank(zsl,score,ele);
//......
//将结果写出去
if (reverse)
addReplyLongLong(c,llen-rank);
else
addReplyLongLong(c,rank-1);
} else {
addReply(c,shared.nullbulk);
}
} else {
redisPanic("Unknown sorted set encoding");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# 利用跳表完成范围查询(ZRANGE指令)
对应的假如我们通过ZRANGE 指令查询索引2到3范围以内的元素:
ZRANGE zsets 2 3 WITHSCORES
2
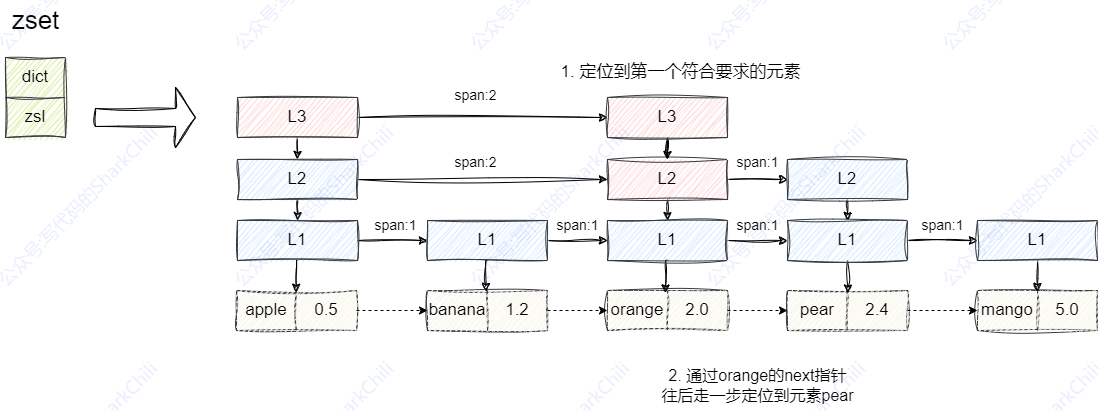
该操作对应有序集合中时,会算得我们要获取的是第3、4个元素,此时有序集合就会通过跳表完成这一查询,如下图所示,我们以红色标识为路径即可知晓,因为多级索引的存在,范围查询过程为:
- 由
2 3算的我们要查询的长度为(3-2)+1即2个元素。 - 头节点
apple的3级索引,其span为2代表跨越两个节点,加上自己本身相当于跨了3个节点定位到了目标元素的起始位置。 - 因为我们的查询长度为2,所以
orange元素的指针向后1步即可拿到所有元素。 - 自此我们拿到元素
orange和pear,并将score一并写出。
对应的命令就会走到t_zset.c的zrangeCommand的逻辑,可以看到其内部本质就是对zrangeGenericCommand的调用,这其中0表示按照升序查询:
void zrangeCommand(redisClient *c) {
//调用zrangeGenericCommand到跳表获取范围结果
zrangeGenericCommand(c,0);
}
2
3
4
5
6
我们继续步入这段逻辑即可看到跳表整体逻辑,先计算索引的查询范围,然后继续该范围通过跳表定位到第一个符合要求的元素,再基于该元素的指针继续往后查询:
void zrangeGenericCommand(redisClient *c, int reverse) {
robj *key = c->argv[1];
robj *zobj;
int withscores = 0;
long start;
long end;
int llen;
int rangelen;
//......
//根据传入的范围计算本次范围查询的长度rangelen
llen = zsetLength(zobj);
//边界判断
if (start < 0) start = llen+start;
if (end < 0) end = llen+end;
if (start < 0) start = 0;
//......
if (end >= llen) end = llen-1;
//计算查询范围
rangelen = (end-start)+1;
//......
if (zobj->encoding == REDIS_ENCODING_ZIPLIST) {
//......
} else if (zobj->encoding == REDIS_ENCODING_SKIPLIST) {//跳表的逻辑
zset *zs = zobj->ptr;
zskiplist *zsl = zs->zsl;
zskiplistNode *ln;
robj *ele;
if (reverse) {//倒叙查找元素
ln = zsl->tail;
if (start > 0)
ln = zslGetElementByRank(zsl,llen-start);
} else {
//升序查询第一个符合要求的元素
ln = zsl->header->level[0].forward;
if (start > 0)
ln = zslGetElementByRank(zsl,start+1);
}
//根据范围长度rangelen通过ln的next指针开始不断遍历截取对应个数的元素
while(rangelen--) {
redisAssertWithInfo(c,zobj,ln != NULL);
ele = ln->obj;
addReplyBulk(c,ele);
if (withscores)
addReplyDouble(c,ln->score);
//基于最底层的叶子节点的forward前进获取后续的元素
ln = reverse ? ln->backward : ln->level[0].forward;
}
} else {
redisPanic("Unknown sorted set encoding");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
这里我们重点查看zslGetElementByRank,该函数会传入要查询的第一个元素的编号rank(该值为索引号+1),和我们图解的逻辑基本一致,从跳表首元素的索引开始累加查看span是否等于rank,一旦等于rank就说明当前节点就是我们的要查询范围的第一个元素,有序集合就会将该元素的指针返回:
zskiplistNode* zslGetElementByRank(zskiplist *zsl, unsigned long rank) {
zskiplistNode *x;
unsigned long traversed = 0;
int i;
x = zsl->header;
//从最高级别的索引开始遍历
for (i = zsl->level-1; i >= 0; i--) {
//查看当前元素是否还有前驱节点且当亲累加结果是否小于rank,若都符合要求则说明当前还没到到达要查询的第一个元素的位置,进入该循环,不断向前或者向下跨span
while (x->level[i].forward && (traversed + x->level[i].span) <= rank)
{
traversed += x->level[i].span;
x = x->level[i].forward;
}
//经过的节点长度traversed 等于第一个元素的编号rank时将该指针返回
if (traversed == rank) {
return x;
}
}
return NULL;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 小结
自此我们就将redis中有序集合的最核心的思想和设计都分析完成了,希望对你有帮助。
我是 sharkchili ,CSDN Java 领域博客专家,开源项目—JavaGuide contributor,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。 因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
# 参考
《redis设计与实现》
Redis 有序集合(sorted set):https://www.runoob.com/redis/redis-sorted-sets.html (opens new window)
