 一文快速入门消息队列
一文快速入门消息队列
# 写在文章开头
本文将针对市面上比较常用的两个消息中间件Kafka和rocketMq的架构和设计理念进行深入的分析和讲解,希望对你有所帮助。
Hi,我是 sharkChili ,是个不断在硬核技术上作死的技术人,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
# 基于kafka了解消息中间件整体架构
# 为什么需要消息队列
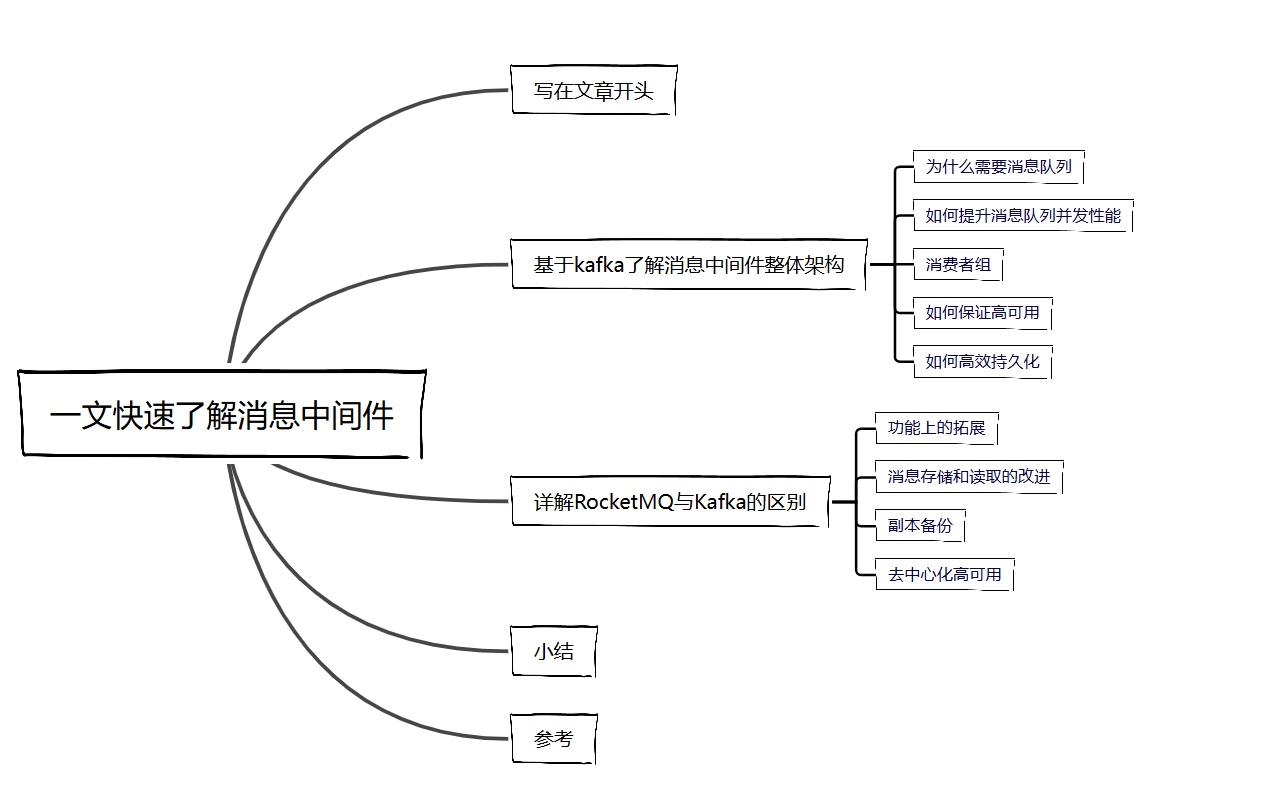
微服务架构下,假设我们的服务A需要调用订单服务B才能完成用户下单,已知服务A的qps为2000,而服务B的qps为1000,如果服务A将全量请求打到服务B上,很可能导致上游服务瘫痪。
初期数据量不是很大的情况下,我们可以在上游服务B的内存上添加一个队列作为缓冲区解决问题,如果是高并发场景,大量未能处理的数据堆积上游服务内存上,还是存在内存溢出的风险:
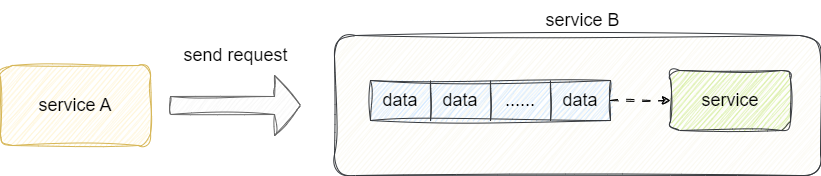
于是就有了消息中间件,即在服务A、B之间添加一个中间曾,通过一个独立的进程解耦两个服务,将两个服务间的消息统一交由消息中间件来统一管理:

# 如何提升消息队列并发性能
通过消息中间件解耦了两个服务,因为服务B性能比较差,为了提升其处理能力,并发的拓展出消费者到消费队列中消费消息,因为这个原因我们也相应的增加几个生产者,因为不同的生产者和消费者都到同一个队列中消费消息即争抢同一个临界资源,再次导致消息队列吞吐量下降:
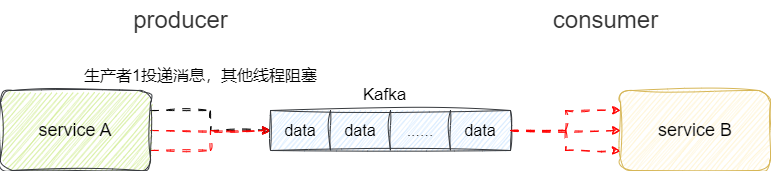
所以需要需要对消息归类,例如创建订单的消息放到topic-1,然后订单查询的消息放到topic-2上,由此通过业务的上的归类,让消费者按需订阅topic进行消费,进而提升服务间操作消息中间件的并发性能:
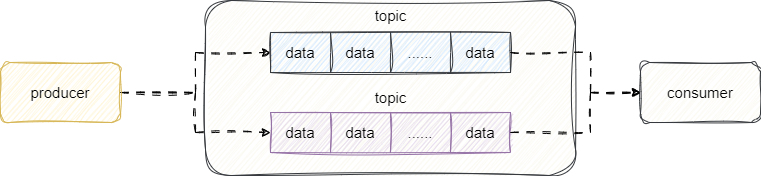
基于这套方案基础上,我们再次提升每秒消息数量,随着时间的推移topic的消息数还是会暴增,对此,Kafka的做法是将不单个topic拆成好几段,每段代表一个partition分区,由此再一次降低的争抢的压力,提升中间件吞吐量:
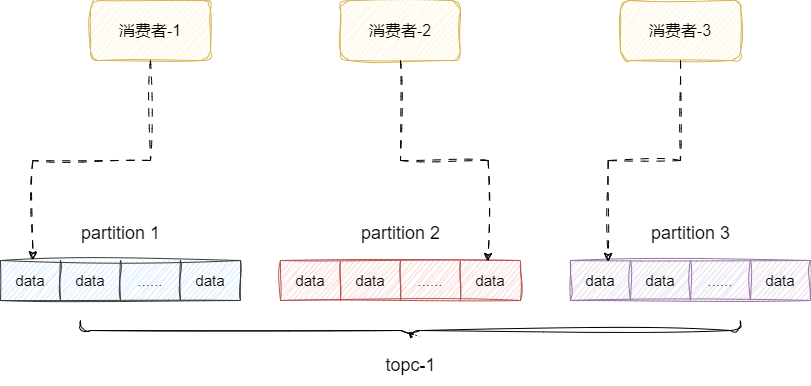
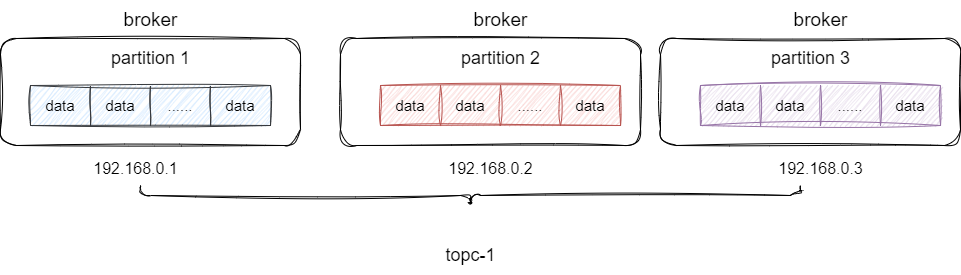
这种方案依然存在问题,多个partition都在一台服务器上很可能出现服务器资源耗尽进而出现性能瓶颈,所以Kafka允许我们进行横向扩容,即增加服务器,通过将partition分散部署到不同服务器上,每个partition作为一个broker由此缓解各个partition对于CPU的资源开销:
# 消费者组
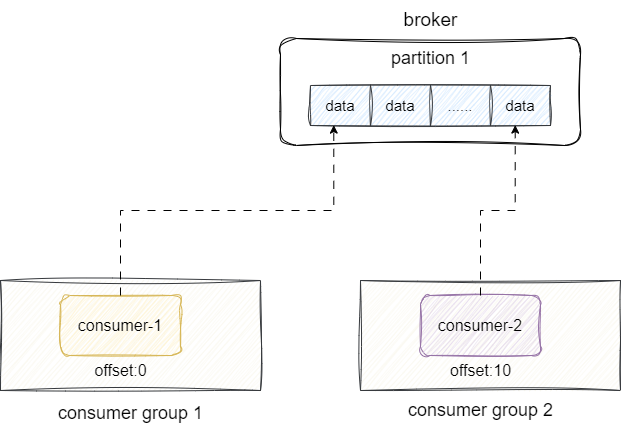
上述的各种方案保证的消费的性能,但还是存在一些小瑕疵,按照现有的方案,我们都知道消费者消费完某个消息后就会实时更新消费进度offset,所以新的消费者都必须按照原有的消费进度进行消费。
假设我们有这样一个场景消费者A消费了队列中offset为1~10的消息,此时又接入了一个消费者B,它同样需要从头开始消费,按照现有情况就必须从10开始,这就不符合我们的要求了,对此Kafka提出了consumer group的概念,让各个消费者按照自己的需要调整消费进度、互相隔离由此保证消费进度的个性化处理:
# 如何保证高可用
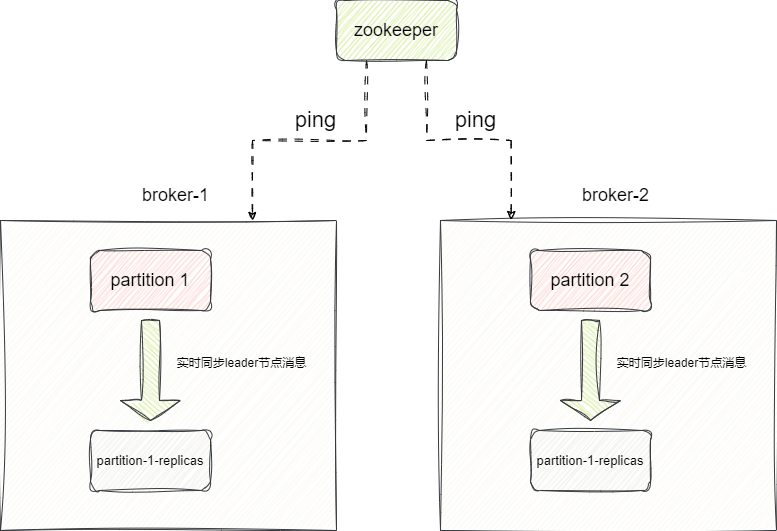
增加机器之后,我们就需要考虑不同节点单点故障,为了保证某个broker因为故障或者某种原因下线,集群仍能够对外提供该broker的消息与服务,于是就有了副本的概念,我们以partition-1为例,当这个partition对外提供服务同时,额外设置一个replicas节点作为它的follower,实时同步leader的消息,一旦感知到主节点下线,从节点直接升级为主节点对外提供服务:
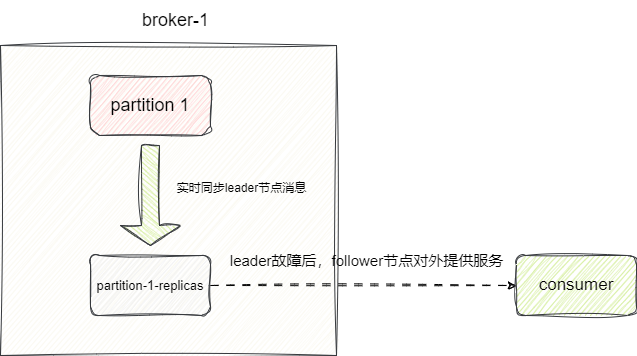
这其中故障转移就会涉及选举和状态信息维护的过程,在kafka2.8.0之前都是通过zookeeper完成的,它会定期和broker进行通信,实时感知broker状态以此判断是否需要进行故障转移等工作,当然后续的版本考虑到这种方案过于笨重就简化broker之间通过raft一致性算法保证高可用:
# 如何高效持久化
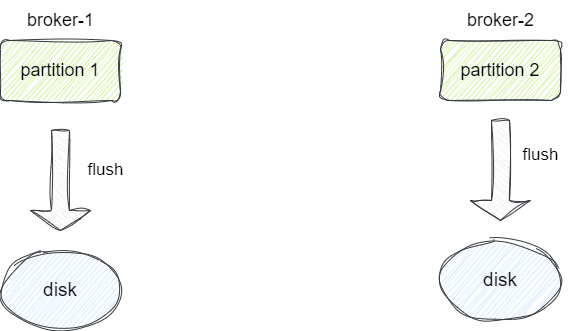
如果所有broker都因为故障而下线,因为消息没有持久化,这就导致重启后服务等同于不可用,所以消息持久化也是很重要的,所以Kafka的做法会按照刷盘策略将数据写入磁盘中,然后按照retention policy策略决定多久清理一次磁盘数据:
# 详解RocketMQ与Kafka的区别
# 功能上的拓展
RocketMQ 是阿里自研的消息中间件,相较于Kafka,RocketMQ在软件架构上进行了简化,同时在功能做了更多的拓展,都知道Kafka是通过topic对消息进行分类,而rocketmq在此基础上增加了tag标签消息的进一步分类。
我们举个实际的业务场景来说明这个功能的作用,例如某个折扣消息只有会员的用户可以收到,某些更加优惠的消息只有会员等级超过3级的用户才能收到,如果在Kafka我们可能需要这样做:
- 针对普通会员折扣建立
topic-1解决问题。 - 针对更高优惠粒度的折扣建立
topic-2进行消息发布。
在简单的场景,我们可以通过迭代topic来解决问题,如果在此基础在添加以下几个需求:
- 会员等级2的折扣。
- 会员为女性的三八节折扣。
- 会员为老年人的折扣。
因为一个折扣消息堆叠出无数个topic,并且有些会员即是女性又是会员等级2,那么进行功能开发时就不得不针对性的特殊处理发送,由此造成业务复杂和维护上的困难:
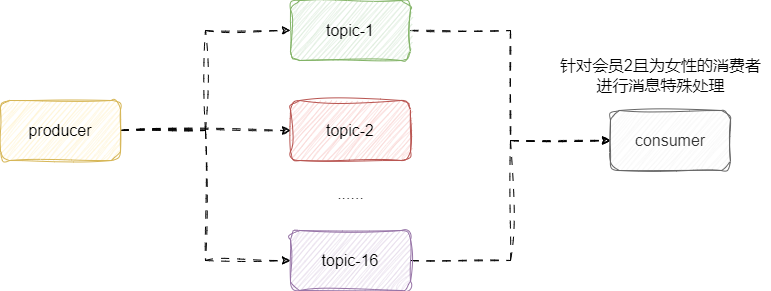
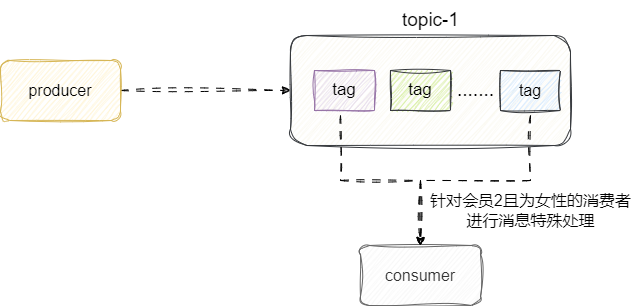
对此rocketmq提出了tag的概念,也就是在topic的基础上加个二级分类,这样就可以针对各种会员折扣消息进行标签,然后消费者按需订阅消息即可:
同时rocketmq还是事务消息,通过事务消息实现分布式事务,即保证业务上的操作(例如数据入库)和消费者消息可靠消费的原子性,所以这也是为什么rocketMQ常用于处理分布式事务问题:
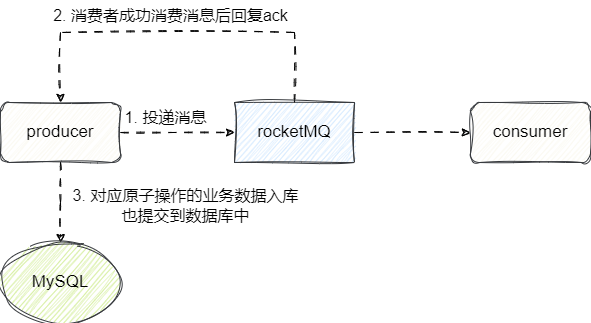
同时rocketMQ还支持这些功能:
- 如果我们希望投递的消息在一定时间后被消费,可以直接通过
rocketMQ将其封装为延迟消息进行推送。 - 消息可能会因为网络波动等原因导致多次重试消费失败,
rocketMQ会将其放到死信队列中供用户按需处理。 RocketMQ除了可以调整offset让新的消费者从对应的偏移量开始消息消费, 还支持调整时间从指定时间开始消费消息。
# 消息存储和读取的改进
上文提到过Kafka通过分区将topic进行拆分提升并发性能,与之对应rocketmq也同样将topic拆成多个分区,并设置分区名为queue。
在读取消息时,Kafka可以直接定位到partition物理文件即可得到实际的消息,而rocketmq则不同,分区文件夹consumequeue存储的仅仅是消息偏移量offset,用户在读写消息时只能通过consumequeue下的文件获取偏移量,然后基于这个偏移量到一个名为commitLog文件中进行消息读写:
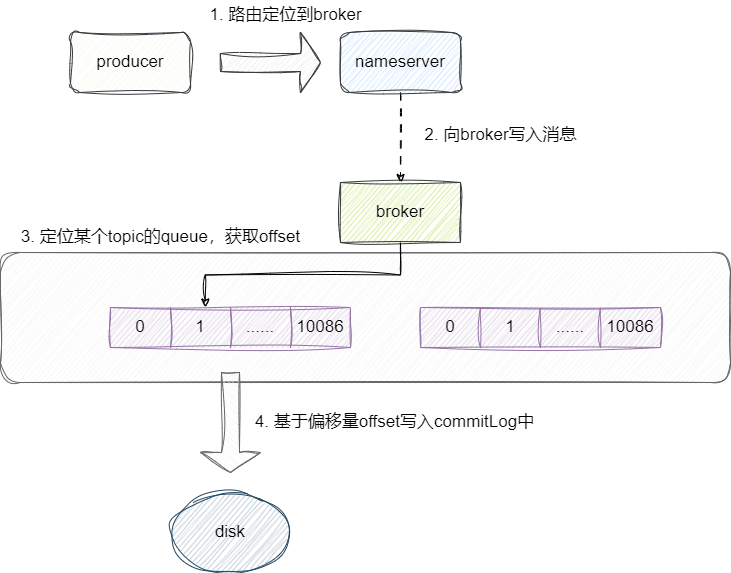
rocketmq的这种设计是有原因的,都知道Kafka对应topic的分区底层是partition,而这些partition底层是由多个物理文件segment构成,假设我们有多个topic且topic有多个分区,进行消息存储时底层都是通随机写完成,这对于磁盘来说效率不算很高。
所以rocketmq采用单文件写,将数据顺序写入单个commitlog实现高效的文件写入,再通过queue索引消息在commitLog中的物理偏移信息,一旦单个commitLog大于1g后就会创建一个新的文件存储新消息。
# 副本备份
上文提到Kafka会将单个topic拆成多个partition然后分布到不同的服务器上的broker提升消息处理效率,所以Kafka的主从节点进行同步时都是以partition为单位的物理文件segment进行完成数据同步:
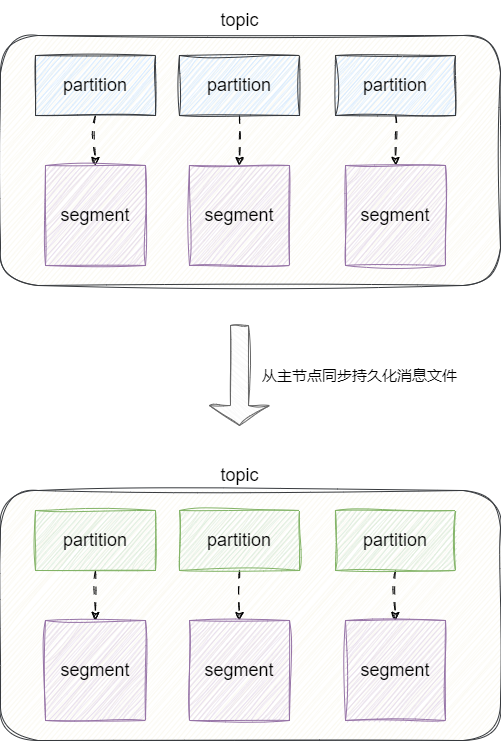
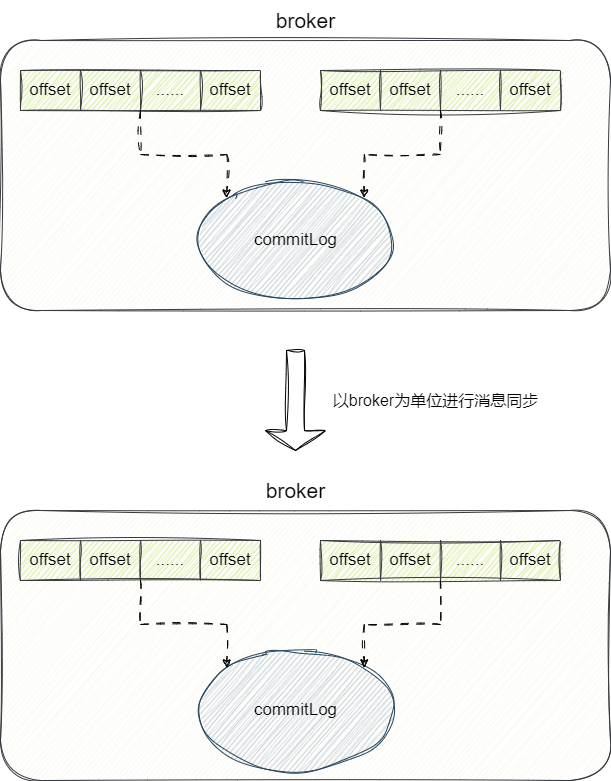
与之相反,RocketMQ进行数据写入时会将每个topic对应的多个分区queue对应的消息写入到同一个commitLog中,这使得RocketMQ无法像Kafka那样以分区为简单进行写入,就算可以也得将commitLog拆分成多个文件然后进行数据同步,这就违背了rocketMQ设计commitLog的初衷——顺序写提升写入效率。
所以rocketMQ进行数据写入时,这才简化为了以broker为单位的数据同步从而保证数据持久化的效率以及主从同步的实现:
# 去中心化高可用
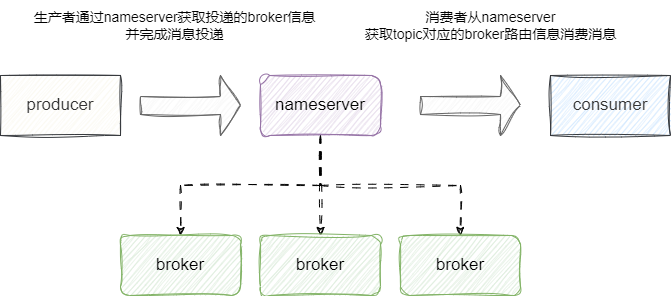
与早期2.8.0的Kafka版本有所不同,RocketMQ从设置之初就避免引入额外组件保证高可用的设计思路,它通过角色规划了各个节点的职责,在集群的情况下,RocketMQ可以设置一个节点为nameserver统一管理集群信息,生产者和消费者进行消息投递和消费时都可以通过nameserver获取到相应broker和topic的路由信息,由此实现相对轻量级的服务发现和负载均衡:
# 小结
自此我们将市面上主流的消息中间件的基本架构和功能都进行的简单的分析和介绍,希望对你有帮助。
我是 sharkchili ,CSDN Java 领域博客专家,mini-redis的作者,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。 因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
# 参考
软件开发中的上游和下游:https://segmentfault.com/a/1190000041894011 (opens new window)
Kafka 是什么?:https://mp.weixin.qq.com/s/SNMmCMV-gqkHtWS0Ca3j4g (opens new window)
RocketMQ 是什么?它的架构是怎么样的?和 Kafka 又有什么区别?:https://mp.weixin.qq.com/s/oje7PLWHz_7bKWn8M72LUw (opens new window)
