 聊一个MySQL插入死锁问题
聊一个MySQL插入死锁问题
# 写在文章开头
在进行MySQL数据备份迁移时,很多人为了避免网络IO的开销而选用insert into ...... select 进行数据迁移备份,但你是否知道这种做法会存在那些隐患呢?
所以本文就以一个简单的功能示例为大家演示一下insert into ...... select 可能引发的问题和解决方案:
Hi,我是 sharkChili ,是个不断在硬核技术上作死的技术人,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
# 问题复现
这里为了演示问题,笔者生成了一张带有500w数据的数据表,对应DDL语句如下:
CREATE TABLE `batch_insert_test` (
`id` int NOT NULL AUTO_INCREMENT,
`fileid_1` varchar(100) DEFAULT NULL,
`fileid_2` varchar(100) DEFAULT NULL,
`fileid_3` varchar(100) DEFAULT NULL,
`fileid_4` varchar(100) DEFAULT NULL,
`fileid_5` varchar(100) DEFAULT NULL,
`fileid_6` varchar(100) DEFAULT NULL,
`fileid_7` varchar(100) DEFAULT NULL,
`fileid_8` varchar(100) DEFAULT NULL,
`fileid_9` varchar(100) DEFAULT NULL,
`create_date` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2520001 DEFAULT CHARSET=utf8mb3 COMMENT='测试批量插入,一行数据1k左右';
2
3
4
5
6
7
8
9
10
11
12
13
14
15
使用count语句查看数据量:
select count(*) from batch_insert_test;
稍微久等了一小会,输出语句如下,可以看到一张表数据刚刚好达到500w:
count(*)|
--------+
5000000|
2
3
同样的我们给出备份迁移表的DDL,表结构是一样的,唯一区别就是表名后缀多了个bak:
CREATE TABLE `batch_insert_test_bak` (
`id` int NOT NULL AUTO_INCREMENT,
`fileid_1` varchar(100) DEFAULT NULL,
`fileid_2` varchar(100) DEFAULT NULL,
`fileid_3` varchar(100) DEFAULT NULL,
`fileid_4` varchar(100) DEFAULT NULL,
`fileid_5` varchar(100) DEFAULT NULL,
`fileid_6` varchar(100) DEFAULT NULL,
`fileid_7` varchar(100) DEFAULT NULL,
`fileid_8` varchar(100) DEFAULT NULL,
`fileid_9` varchar(100) DEFAULT NULL,
`create_date` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2520001 DEFAULT CHARSET=utf8mb3 COMMENT='测试批量插入,一行数据1k左右';
2
3
4
5
6
7
8
9
10
11
12
13
14
此时我们使用数据库连接工具在会话窗口,执行如下迁移语句:
insert into batch_insert_test_bak select * from batch_insert_test;
然后我们再写一段程序模拟插入:
@Test
public void insert() {
while (true) {
BatchInsertTest batchInsertTest = new BatchInsertTest();
batchInsertTest.setFileid1(RandomUtil.randomString(1));
batchInsertTest.setFileid2(RandomUtil.randomString(1));
batchInsertTest.setFileid3(RandomUtil.randomString(1));
batchInsertTest.setFileid4(RandomUtil.randomString(1));
batchInsertTest.setFileid5(RandomUtil.randomString(1));
batchInsertTest.setFileid6(RandomUtil.randomString(1));
batchInsertTest.setFileid7(RandomUtil.randomString(1));
batchInsertTest.setFileid8(RandomUtil.randomString(1));
batchInsertTest.setFileid9(RandomUtil.randomString(1));
batchInsertTest.setCreateDate(new Date());
long begin = System.currentTimeMillis();
batchInsertTestMapper.insert(batchInsertTest);
long end = System.currentTimeMillis();
log.info("插入耗时:{} ms", end - begin);
ThreadUtil.sleep(10000L);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
从输出结果来看,一开始插入并不是很耗时,基本都是毫秒级完成,但是随着时间的推移,插入的耗时逐渐增加,最慢的一次数据插入竟然花费了1分多钟:
18.546 INFO c.s.w.WebTemplateApplicationTests:117 main 插入耗时:148 ms
28.778 INFO c.s.w.WebTemplateApplicationTests:117 main 插入耗时:221 ms
38.926 INFO c.s.w.WebTemplateApplicationTests:117 main 插入耗时:143 ms
49.588 INFO c.s.w.WebTemplateApplicationTests:117 main 插入耗时:652 ms
59.763 INFO c.s.w.WebTemplateApplicationTests:117 main 插入耗时:166 ms
09.820 INFO c.s.w.WebTemplateApplicationTests:117 main 插入耗时:56 ms
19.930 INFO c.s.w.WebTemplateApplicationTests:117 main 插入耗时:99 ms
30.027 INFO c.s.w.WebTemplateApplicationTests:117 main 插入耗时:86 ms
40.145 INFO c.s.w.WebTemplateApplicationTests:117 main 插入耗时:113 ms
50.238 INFO c.s.w.WebTemplateApplicationTests:117 main 插入耗时:79 ms
17.178 INFO c.s.w.WebTemplateApplicationTests:117 main 插入耗时:76927 ms
2
3
4
5
6
7
8
9
10
11
# 原因剖析
我们不妨使用如下语句查看一下执行计划:
explain insert into batch_insert_test_bak select * from batch_insert_test;
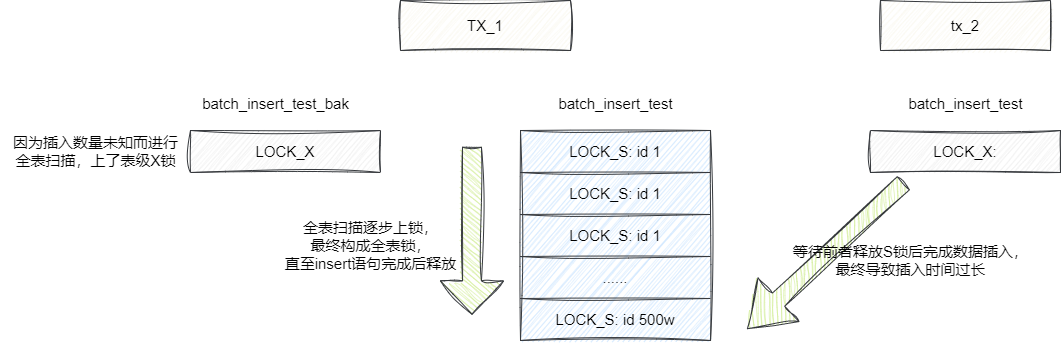
可以看出无论是insert还是select都是走全表扫描,因为select查询没有走索引导致select子句的执行过程会针对整张表从上到下的扫描进行一个逐步锁(S锁)的过程,随着时间的推移它最终就会变为全表锁。
而insert语句也因为对于插入数量未知而上全表锁,进而长期持有auto-inc锁,当然因为insert的表是用于迁移备份数据的,auto-inc锁的长时间持有对于业务来说影响不大。
id|select_type|table |partitions|type|possible_keys|key|key_len|ref|rows |filtered|Extra|
--+-----------+---------------------+----------+----+-------------+---+-------+---+-------+--------+-----+
1|INSERT |batch_insert_test_bak| |ALL | | | | | | | |
1|SIMPLE |batch_insert_test | |ALL | | | | |4692967| 100.0| |
2
3
4
而select则不同,select查询操作上的是读锁也就是S锁,这使得其他事务针对扫描到的数据只能上S锁不能上X锁即写锁。
通过执行计划可以看到我们的操作是全表扫描ALL,这也就意味着该查询逐步上S锁,导致一段时间后,整张表都被锁住,使得我们的新的会话的插入语句的事务无法提交。进而导致大量连接数阻塞积压,各种超时问题也就随之诞生,严重一点就很可能导致整个业务线瘫痪:
# 解决方案
所以如果我们希望迁移时不锁住全表,可以在指定在每次迁移时指定一个范围,所以我们针对时间字段增加索引,通过缩小范围加索引查询避免全表锁:
ALTER TABLE db1.batch_insert_test DROP INDEX batch_insert_test_create_date_IDX;
CREATE INDEX batch_insert_test_create_date_IDX USING BTREE ON db1.batch_insert_test (create_date);
2
3
然后迁移的sql改为:
insert into batch_insert_test_bak select * from batch_insert_test where create_date <now() ;
查看执行计划发现,select走了range索引,避免全表扫描,解决了上述的风险:
id|select_type|table |partitions|type |possible_keys |key |key_len|ref|rows|filtered|Extra |
--+-----------+---------------------+----------+-----+---------------------------------+---------------------------------+-------+---+----+--------+---------------------+
1|INSERT |batch_insert_test_bak| |ALL | | | | | | | |
1|SIMPLE |batch_insert_test | |range|batch_insert_test_create_date_IDX|batch_insert_test_create_date_IDX|6 | | 1| 100.0|Using index condition|
2
3
4
# 小结
由此可以得出,再使用数据insert into ...... select进行数据迁移时,无比考虑读写锁的工作机制,以及迁移可能导致的锁的粒度和范围,只有精确的评估风险点才能保证功能上限不影响正常业务的工作。
我是 sharkchili ,CSDN Java 领域博客专家,mini-redis的作者,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
# 参考
同事埋了个坑:Insert into select 语句把生产服务器炸了!:https://zhuanlan.zhihu.com/p/139486473 (opens new window)
一条 SQL 引发的事故,同事直接被开除:https://blog.csdn.net/youanyyou/article/details/108592296 (opens new window)
insert into ... select 由于SELECT表引起的死锁情况分析:https://blog.csdn.net/asdfsadfasdfsa/article/details/83030011https://blog.csdn.net/asdfsadfasdfsa/article/details/83030011 (opens new window)
探秘 MySQL 锁:原理与实践 :https://blog.csdn.net/shark_chili3007/article/details/109141299 (opens new window)
同事埋了个坑:Insert into select语句把生产服务器炸了:https://cloud.tencent.com/developer/article/1622847 (opens new window)
详解共享锁(S锁)和排它锁(X锁):https://blog.csdn.net/u012184539/article/details/88561195 (opens new window)
