 一文快速掌握高性能内存队列Disruptor
一文快速掌握高性能内存队列Disruptor
# 写在文章开头
Disruptor是英国外汇公司LMAX开源的一款高性能内存消息队列,理想情况下单线程可支撑600w的订单。所以本文会从使用以及设计的角度来探讨一下这款神级java消息队列。
Hi,我是 sharkChili ,是个不断在硬核技术上作死的 java coder ,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。

# 基础使用示例
# 前置步骤
我们会基于该框架实现一个简单的生产者消费者模型,在此之前我们需要引入一下依赖:
<dependency>
<groupId>com.lmax</groupId>
<artifactId>disruptor</artifactId>
<version>3.3.4</version>
</dependency>
2
3
4
5
# 约定消息模型
生产者消费者沟通的媒介就是消息,所以我们首先需要创建发送消息的消息模型,这里仅仅简单创建一个对象用户记录发送的字符串消息:
@Data
public class MessageModel {
/**
* 消息内容
*/
private String message;
}
2
3
4
5
6
7
# 基于消息模型初始化消息队列空间
Disruptor对于事件的存储进行更新操作都是基于RingBuffer,项目启动前它会基于我们的消息也就是上文的MessageModel 进行空间预初始化,所以我们需要继承EventFactory编写创建实例方法,告知Disruptor如何创建什么样消息对象空间,这一点我们可以在源码RingBufferFields的构造方法中得以印证:
RingBufferFields(
EventFactory<E> eventFactory,
Sequencer sequencer)
{
//基于sequencer完成队列数组entries 数组初始化
this.sequencer = sequencer;
this.bufferSize = sequencer.getBufferSize();
//......
this.indexMask = bufferSize - 1;
this.entries = new Object[sequencer.getBufferSize() + 2 * BUFFER_PAD];
//基于我们给定的MsgEventFactory完成数组内部元素空间预初始化
fill(eventFactory);
}
private void fill(EventFactory<E> eventFactory)
{
for (int i = 0; i < bufferSize; i++)
{
//调用我们的工厂方法完成元素内部元素空间初始化
entries[BUFFER_PAD + i] = eventFactory.newInstance();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
所以我们直接继承EventFactory给出消息模型创建的工厂方法:
public class MsgEventFactory implements EventFactory<MessageModel> {
@Override
public MessageModel newInstance() {
return new MessageModel();
}
}
2
3
4
5
6
# 定制消息处理器
通过继承EventHandler并指定泛型即可接手并处理MessageModel消息,逻辑比较简单,读者可自行参阅:
@Slf4j
public class MsgEventHandler implements EventHandler<MessageModel> {
@Override
public void onEvent(MessageModel messageModel, long sequence, boolean endOfBatch) {
//休眠2s,模拟异步消费
ThreadUtil.sleep(2000);
log.info("消费者处理消息开始");
if (messageModel != null) {
log.info("收费者收到消息,序列号:{},消息内容:{}", sequence, messageModel.getMessage());
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 配置Disruptor核心参数
上述步骤完成之后,我们就可以配置环形队列RingBuffer了:
@Configuration
public class RingBufferConfig {
@Bean
public RingBuffer<MessageModel> messageModelRingBuffer() {
//定义事件处理线程池,即消费者线程池
ThreadFactory threadFactory = ThreadFactoryBuilder.create()
.setNamePrefix("thread-")
.build();
//指定事件工厂
MsgEventFactory msgEventFactory = new MsgEventFactory();
//指定ringbuffer字节大小,必须为2的N次方(能将求模运算转为位运算提高效率),否则将影响效率
int bufferSize = 1024 * 256;
//单线程模式,获取额外的性能
Disruptor<MessageModel> disruptor = new Disruptor<>(msgEventFactory, bufferSize, threadFactory,
ProducerType.SINGLE, new BlockingWaitStrategy());
//设置事件业务处理器---消费者
disruptor.handleEventsWith(new MsgEventHandler());
// 启动disruptor线程
disruptor.start();
//获取RingBuffer,用于接取生产者生产的事件
RingBuffer<MessageModel> ringBuffer = disruptor.getRingBuffer();
return ringBuffer;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 实现生产者
上述步骤已经完成的Disruptor的所有创建和配置工作,注入环形队列,我们的服务就可以投递的消息了,这里我们给出对应的DisruptorMqServiceImpl 的实现代码:
@Slf4j
@Component
@Service
public class DisruptorMqServiceImpl implements DisruptorMqService {
@Autowired
private RingBuffer<MessageModel> messageModelRingBuffer;
@Override
public void sendMsg(String message) {
log.info("投递消息,消息内容: {}", message);
//获取下一个Event槽的下标
long sequence = messageModelRingBuffer.next();
try {
//给Event填充数据
MessageModel event = messageModelRingBuffer.get(sequence);
event.setMessage(message);
log.info("往消息队列中添加事件:{}", JSONUtil.toJsonStr(event));
} catch (Exception e) {
log.error("消息发送失败,失败原因 {}", e.getMessage(), e);
} finally {
//发布Event,激活观察者去消费,将sequence传递给改消费者
//注意最后的publish方法必须放在finally中以确保必须得到调用;如果某个请求的sequence未被提交将会堵塞后续的发布操作或者其他的producer
messageModelRingBuffer.publish(sequence);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 效果展示
我们通过外部接口直接调用,可以看到MsgEventHandler接收并准确的处理了我们投递的消息:
2024-02-16 00:17:14.223 INFO 9924 --- [io-18080-exec-1] c.s.service.impl.DisruptorMqServiceImpl : 投递消息,消息内容: demoData
2024-02-16 00:17:14.254 INFO 9924 --- [io-18080-exec-1] c.s.service.impl.DisruptorMqServiceImpl : 往消息队列中添加事件:{"message":"demoData"}
2024-02-16 00:17:14.255 INFO 9924 --- [io-18080-exec-1] c.sharkChili.controller.TestController : 消息队列已发送完毕
2024-02-16 00:17:16.268 INFO 9924 --- [ thread-0] com.sharkChili.handler.MsgEventHandler : 消费者处理消息开始
2024-02-16 00:17:16.268 INFO 9924 --- [ thread-0] com.sharkChili.handler.MsgEventHandler : 收费者收到消息,序列号:0,消息内容:demoData
2
3
4
5
# Disruptor工作流程详解
Disruptor官网文档详尽给出所有核心的组件概念,详情可参考:LMAX Disruptor User Guide (opens new window)
这里我们以流程化的方式给出几个比较核心的概念,如下图所示,首先是生产者Producer也就是我们上文中的DisruptorMqServiceImpl通过RingBuffer获取对应序列号的消息对象MessageModel的引用将消息设置进去。此时基于等待策略等待就绪事件的对应的SequenceBarrier就会拿到这个消息的序列号并传递给消费者即EventHandler,EventHandler会基于当前收到的序列号到RingBuffer中获取对应的消息并处理。
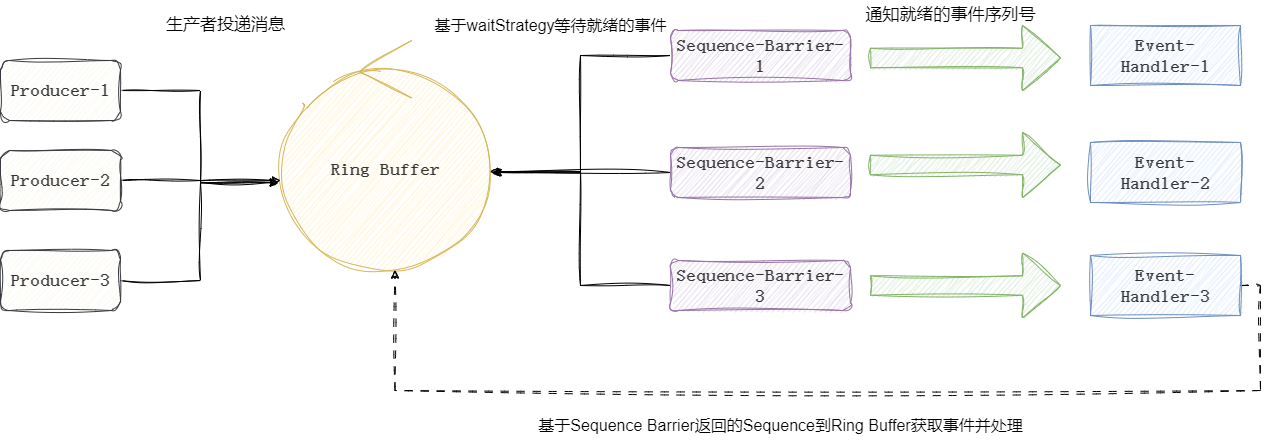
这一点我们可以在BatchEventProcessor的run方法中得以印证:
@Override
public void run()
{
//......
T event = null;
long nextSequence = sequence.get() + 1L;
try
{
while (true)
{
try
{
//sequenceBarrier基于等待策略获取就绪的消息序列号
final long availableSequence = sequenceBarrier.waitFor(nextSequence);
//拿到序列号之后从ringbuffer(也就是下文的dataProvider)获取对应的消息事件,并通过我们重写的eventHandler处理掉
while (nextSequence <= availableSequence)
{
event = dataProvider.get(nextSequence);
eventHandler.onEvent(event, nextSequence, nextSequence == availableSequence);
nextSequence++;
}
sequence.set(availableSequence);
}
catch (final TimeoutException e)
{
//......
}
//......
}
}
finally
{
//......
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# 详解Disruptor高效的原因
# 缓存填充
JDK自带的队列ArrayBlockingQueue通过上锁并阻塞线程的方式却保证生产者和消费者之间安全通信,我们的入队(在我们的场景可直接理解为消息投递)为例,可以看到put方法会先上锁如果得不到锁线程会直接进入WAIT状态,然后判断队列是否达到上限,同样的若达到上限当前线程也会被阻塞,等待队列不满时被唤醒再次进行添加操作:
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
//上锁,若得不到锁则进入等待状态
lock.lockInterruptibly();
try {
//队列已满则等待未满再进行操作
while (count == items.length)
notFull.await();
//入队
enqueue(e);
} finally {
//释放锁
lock.unlock();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
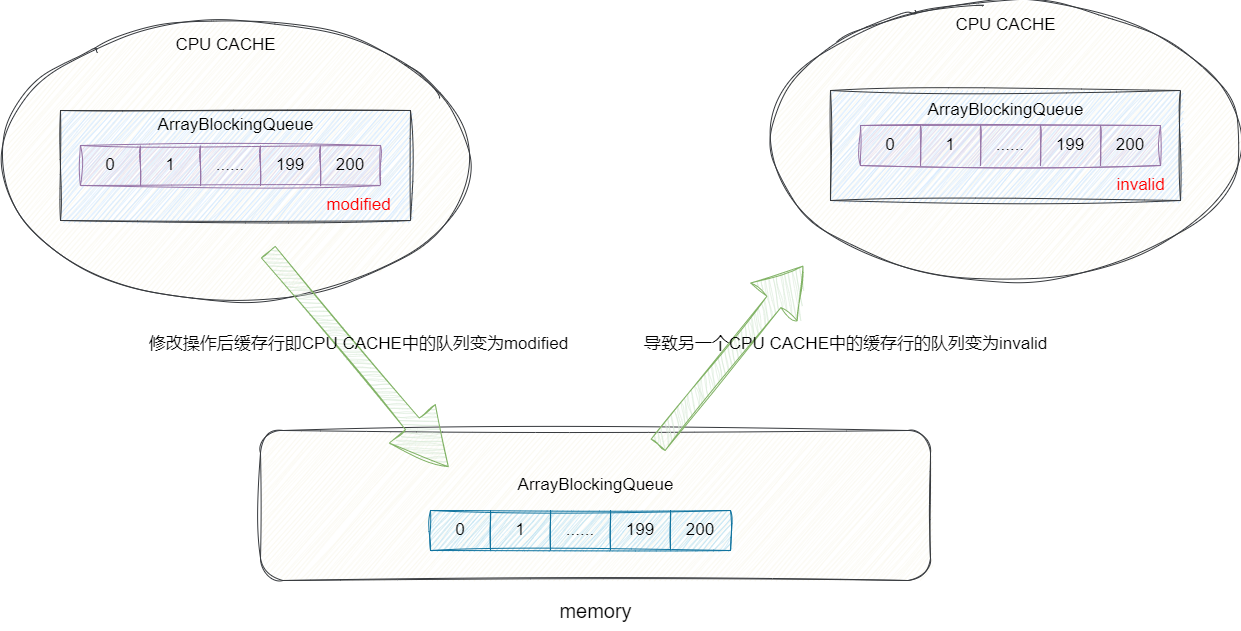
除此之外JDK自带的ArrayBlockingQueue也没有考虑到并发场景下的伪共享问题,例如每个线程对应的CPU核心都将内存中的ArrayBlockingQueue加载到缓存行中,为了保证双方的缓存一致性,一旦一端修改了ArrayBlockingQueue,那么另一端的ArrayBlockingQueue就会被视为脏数据,这就意味着另一端的CPU需要操作ArrayBlockingQueue就需要重新从内存加载一份全新的ArrayBlockingQueue才能进行更新操作,在并发激烈的场景下,这种情况操作效率大大降低:
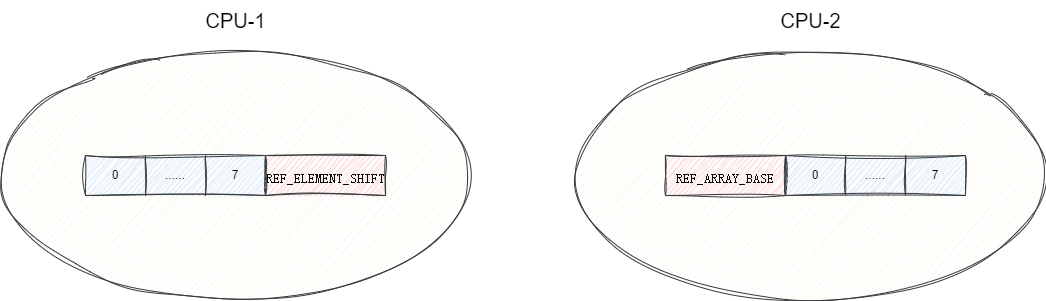
而Disruptor的RingBuffer中的字段RingBufferFields涉及RingBuffer中核心变量信息的记录,为了避免伪共享问题RingBufferFields继承RingBufferPad保证RingBufferFields每次被加载时前方都有7个8字节的数据填充。同理RingBuffer继承RingBufferFields在其后方填充7个8字节数据,由此保证了每一个RingBufferFields的任意字段被加载时,都有7个不可变的字段填充再任意CPU左右,避免RingBufferFields某个字段更新后,其他CPU缓存行的数据变为脏数据的缓存一致性问题:
对应的我们给出缓存填充的代码示例:
abstract class RingBufferPad
{
protected long p1, p2, p3, p4, p5, p6, p7;
}
abstract class RingBufferFields<E> extends RingBufferPad
{
//......
}
public final class RingBuffer<E> extends RingBufferFields<E> implements Cursored, EventSequencer<E>, EventSink<E>
{
public static final long INITIAL_CURSOR_VALUE = Sequence.INITIAL_VALUE;
protected long p1, p2, p3, p4, p5, p6, p7;
//....
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 分支预测
Disruptor通过数组构成一个循环队列,它在初始化时就固定了存储空间,按照局部性原理,一次即可加载批量的元素到缓存行中,结合CPU的分支预测机制,因为数组的顺序加载规律分支预测器可以非常高效的预测并缓存下一条指令从而快速获取到数组中的下一个元素,这就是Disruptor第2个高效的原因:

# 无锁操作
进行消息批量投递和消费时,Disruptor都会按照如下步骤:
- 计算要获取的序列范围。
CAS设置获取并更新序列号进度。- 若
CAS原子更新成功则获取并进行生产或者消费,反之循环重试CAS直至成功。
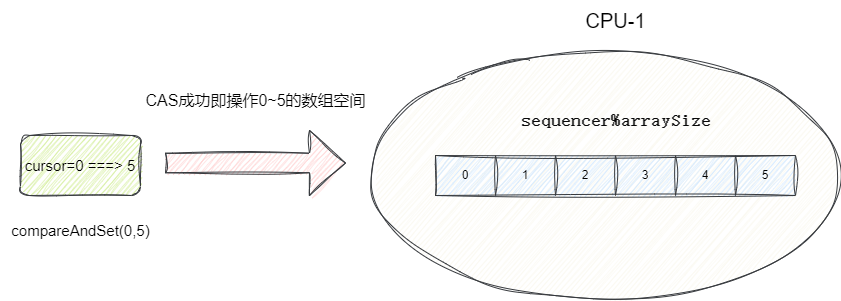
为了印证这一点,我们将生产模式模式改为多线程生产ProducerType.MULTI:
Disruptor<MessageModel> disruptor = new Disruptor<>(msgEventFactory, bufferSize, threadFactory,
ProducerType.MULTI, new BlockingWaitStrategy());
2
我们以上文中DisruptorMqServiceImpl投递消息前获取序列号这一步作为入口查看这一过程:
long sequence = messageModelRingBuffer.next();
可以看到底层用sequencer进行序列号自增:
@Override
public long next()
{
return sequencer.next();
}
2
3
4
5
对应MultiProducerSequencer的next方法可以看到,它会基于我们传入的n进行CAS累加操作,若成功则说明这批序列号获取成功,我们的生产者可以操作序列号对应的数组空间,从而进行消息投递,而这就是Disruptor高效的第3个原因——无锁。
@Override
public long next(int n)
{
//......
long current;
long next;
do
{
//获取当前序列号
current = cursor.get();
//获取自增范围
next = current + n;
//......
if (wrapPoint > cachedGatingSequence || cachedGatingSequence > current)
{
//......
}
//基于CAS原子更新cursor的数值,若成功则说明可以操作从current 到next这个范围的序列号的对应的数组元素空间,后续可以基于这个范围进行消息投递操作
else if (cursor.compareAndSet(current, next))
{
break;
}
}
//循环CAS操作直至成功
while (true);
return next;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 小结
以上便是笔者对于Disruptor剖析的全部内容,希望对你有帮助。
我是 sharkchili ,CSDN Java 领域博客专家,开源项目—JavaGuide contributor,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。 因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。

# 参考
SpringBoot + Disruptor 实现特快高并发处理,支撑每秒 600 万订单无压力:https://mp.weixin.qq.com/s/k-WiWvIQcNft_fX7uroE0A (opens new window)
官网文档:https://lmax-exchange.github.io/disruptor/user-guide/index.html#user-guide-models (opens new window)
高性能队列——Disruptor:https://tech.meituan.com/2016/11/18/disruptor.html (opens new window)
【计组】理解Disruptor--《计算机组成原理》(十五):https://blog.csdn.net/weixin_56814032/article/details/128999761 (opens new window)
