 LongAdder源码分析
LongAdder源码分析
# LongAdder简介
JDK1.5开始就提供基本数据类型操作的原子类,通过CAS实现线程安全的数据累加,在高并发场景下,这些原子类会因为竞争的激烈导致大量线程频繁的CAS频繁失败,影响程序执行效率。
所以JDK1.8提供了线程安全的计数器LongAdder,它底层是由一个数组进行计数,不同线程会根据哈希算法会得到底层数组的某个索引位置,然后将累加的值通过CAS的方式累加到该索引位置上。因为LongAdder底层的数组最大容量为CPU核心数,所以在高并发场景下的CAS操作成功率远高于JDK1.5的原子类,所以在JDK8以上的版本,高并发场景我们更建议使用LongAdder进行累加计数操作。
# LongAdder使用示例
# 基础示例
LongAdder基础示例如下,笔者创建了和CPU核心数相等的线程,并让这些线程使用LongAdder进行累加操作。
public static void main(String[] args) {
System.out.println("CPU核心数:"+Runtime.getRuntime().availableProcessors());
ExecutorService threadPool = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
LongAdder longAdder = new LongAdder();
//多线程操作longAdder进行累加操作
for (int i = 0; i < Runtime.getRuntime().availableProcessors(); i++) {
threadPool.execute(() -> {
longAdder.increment();
});
}
threadPool.shutdown();
while (!threadPool.isTerminated()) {
}
//输出累加结果
System.out.println("sum:" + longAdder.sum());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
从输出结果来看,16核的计算机创建16个线程,累加操作结果也是16,在并发场景下LongAdder累加是可以保证线程安全的。
CPU核心数:16
sum:16
2
# 并发场景下和原子类的性能比较
笔者这里基于1000个线程操作LongAdder或原子类AtomicLong进行累加100w次。
public static void main(String[] args) {
//使用1000个线程,每个线程操作LongAdder 100W 次
StopWatch stopWatch = new StopWatch();
stopWatch.start("使用 LongAdder");
System.out.println("使用 LongAdder计算结果:" + longAddrTest());
stopWatch.stop();
System.out.println("使用 LongAdder耗时:" + stopWatch.getLastTaskTimeMillis() + "ms");
//使用1000个线程,每个线程操作 AtomicLong 100W 次
stopWatch.start("使用 AtomicLong");
System.out.println("使用 AtomicLong 计算结果:" + atomicAddTest());
stopWatch.stop();
System.out.println("使用 AtomicLong 耗时:" + stopWatch.getLastTaskTimeMillis() + "ms");
}
private static long atomicAddTest() {
//创建1000个线程
ExecutorService threadPool = Executors.newFixedThreadPool(1000);
AtomicLong num = new AtomicLong(0);
//每个线程操作AtomicLong 100w次
for (int i = 0; i < 1000; i++) {
threadPool.execute(() -> {
for (int j = 0; j < 100_0000; j++) {
num.incrementAndGet();
}
});
}
threadPool.shutdown();
while (!threadPool.isTerminated()) {
}
return num.get();
}
private static long longAddrTest() {
//创建1000个线程
ExecutorService threadPool = Executors.newFixedThreadPool(1000);
LongAdder num = new LongAdder();
//每个线程操作LongAdder 100w次
for (int i = 0; i < 1000; i++) {
threadPool.execute(() -> {
for (int j = 0; j < 100_0000; j++) {
num.increment();
}
});
}
threadPool.shutdown();
while (!threadPool.isTerminated()) {
}
return num.longValue();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
输出结果如下,可以看出竞争激烈的情况下LongAdder的性能优于AtomicLong 。
使用 LongAdder计算结果:1000000000
使用 LongAdder耗时:1004ms
使用 AtomicLong 计算结果:1000000000
使用 AtomicLong 耗时:12822ms
2
3
4
# LongAdder源码分析
# 核心成员变量
在正式讨论核心方法源码前,我们必须了解一下LongAdder的核心成员变量,首先是base,该变量是volatile类型,即该变量是对多线程保证可见性的,LongAdder初始化时,所有线程的累加操作都是在base上进行的。
transient volatile long base;
如下图,在LongAdder计数操作竞争不激烈时,线程操作LongAdder都是基于CAS对base进行累加。
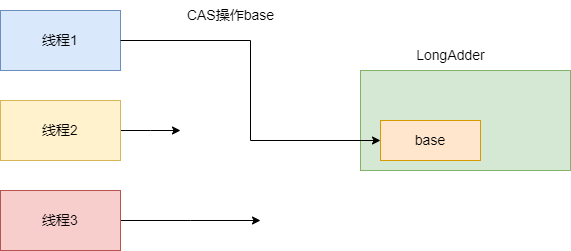
然后就是LongAdder的有一个重要的累加操作数组cells。
transient volatile Cell[] cells;
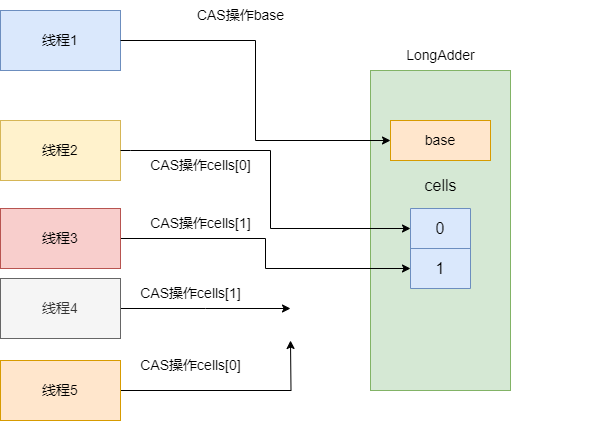
当线程逐渐增多导致大量线程基于变量base进行CAS累加操作失败时,LongAdder就会初始化一个数组cells,让这些失败的线程根据哈希算法得到cells数组中某个索引位置的Cell进行CAS操作,尽可能避免多线程累加操作的竞争的激烈程度。
如下图所示,可以看到在大量线程操作LongAdder时,大量线程就会因为竞争失败进而通过哈希算法到cells数组某个索引空间进行CAS累加操作。
查阅Cell 类源码如下,它的特点如下:
- 通过
@sun.misc.Contended填充每一个Cell,确保每一个Cell被加载到CPU缓存行时都能将缓存行填满,避免因为局部性原理加载到邻近的Cell,导致CPU伪共享问题。 - 内部声明一个
volatile变量value,确保多线程操作时对其他线程可见。 - 提供一个
CAS方法,基于UNSAFE实现CAS赋值操作。
@sun.misc.Contended static final class Cell {
//多线程操作该类的value对彼此可见
volatile long value;
//构造方法
Cell(long x) { value = x; }
//CAS完成赋值操作
final boolean cas(long cmp, long val) {
return UNSAFE.compareAndSwapLong(this, valueOffset, cmp, val);
}
// 略
}
2
3
4
5
6
7
8
9
10
11
12
# increment方法
了解的LongAdder几个核心成员变量后,我们就对LongAdder的组成有了一个整体了认识,接下来我们就可以开始了解increment方法。increment方法是LongAdder中最核心的方法,在正式阅读源码实现细节之前,我们不妨以图解的方式了解一下它大致的执行步骤。
首先,在LongAdder初始化时候,因为还没有出现竞争,所以内部结构只有一个base,用于记录线程累加的值。

随后线程1开始调用累加器,通过CAS操作对base完成累加,此时base就由原来的0变成1。

紧接着的活跃的线程增多,线程2也需要用到LongAdder,它同样用CAS的方式和线程1几乎同时对base进行累加操作,结果线程1累加成功,线程2累加失败,所以此时base的值为2。
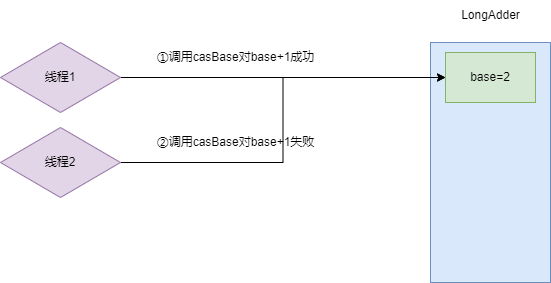
于是LongAdder就初始化cells数组,默认情况下cells数组初始化时的容量为2,然后线程2通过哈希运算得到数组索引位置0,将数组位置0初始化一个Cell并将其累加为1。此时base的值为2,cells中只有索引0位置的value为1,总和为3。

不久后线程3也来参与累加操作了,因为数组已经初始化,所以后续线程累加的值都需要以CAS的方式存储到cells数组中,所以当前的线程2和线程3进行累加操作时可能出现下面这样的情况。
首先是线程2,经过哈希运算它再次得到索引位置0,并完成CAS累加操作。然后是线程3,经过哈希运算也得到索引位置0,CAS操作失败。
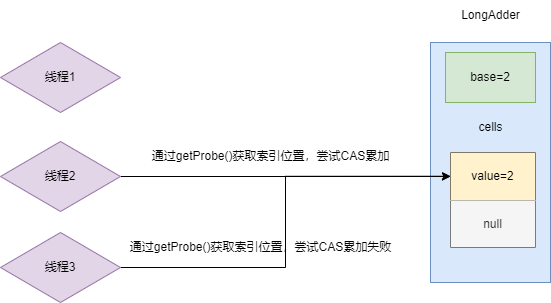
于是线程3再次进行哈希运算得到索引位置1,因为索引1为空,于是初始化一个Cell并累加为1,此时base的值为2,数组中的每一个空间的value都为1。
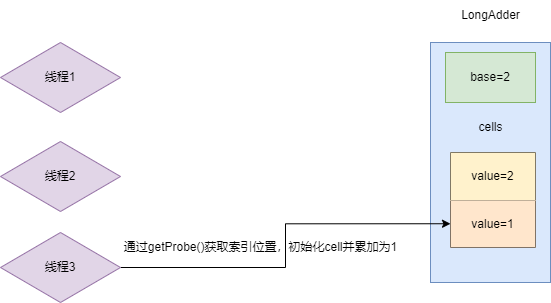
上述的情况完成累加操作后不久,又出现3个线程的累加就会出现这种情况,而且3个线程经过哈希运算得cells数组中同一个索引0,其中两个线程CAS操作失败,如下图所示:
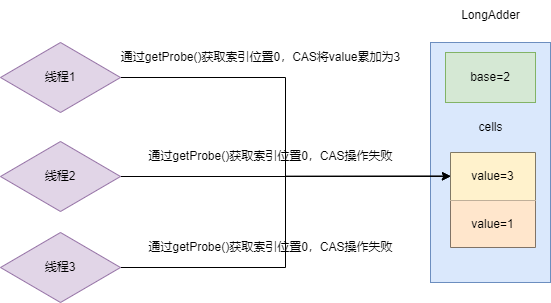
于是线程2再哈希得到索引0进行CAS累加操作成功,线程3同样哈希操作得到索引1进行CAS操作成功,本轮累加工作完成。
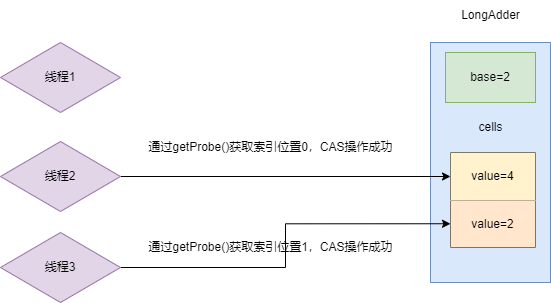
随着竞争的愈发激烈,线程4也参与到了竞争中,最终出现下图这个情况:
- 线程1经过哈希运算得到索引0进行
CAS累加操作成功,此时索引0的值为5。 - 线程2经过哈希运算得到索引1进行
CAS累加操作成功,此时索引1的值为3。 - 线程3经过哈希运算得到索引1进行累加操作失败,再次哈希进行
CAS累加操作成功,此时索引1的值为4。 - 线程3成功之后又进行两次累加操作,这两次哈希运算都得到索引1累加操作都成功了,此时索引1的值+2为6。
- 线程4在此期间经过3次哈希运算都得到索引1,操作都失败了(因为线程3一直优先于线程4
CAS操作索引1)。
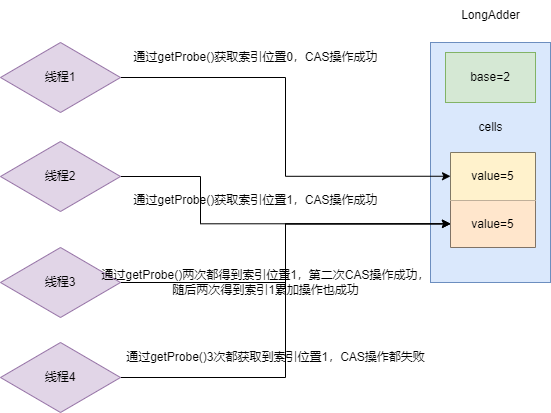
因为尝试3次的失败,LongAdder认为当前竞争情况比较激烈,并且当前cells数组长度小于CPU核心数,于是对数组进行了一次扩容。随后线程4在哈希得到索引3完成对Cell的初始化并完成了累加操作,自此本轮累加操作所有线程都完成计数。
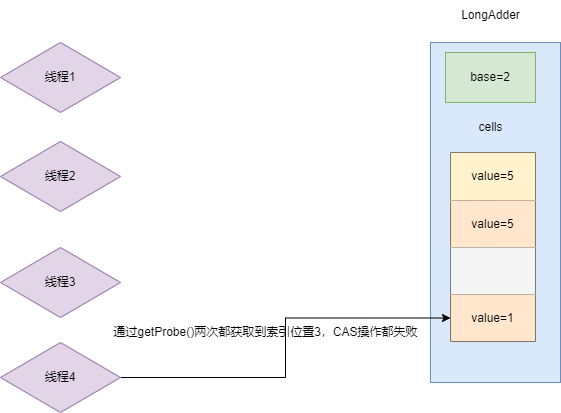
自此我们比较详细的介绍完了一次完整的LongAdder多线程累加操作,了解从无竞争到竞争激烈时LongAdder的工作流程。阅读increment源码,我们看到它会调用add方法,传入一个参数1,很明显它的累加操作就是通过调用这个add方法实现的,我们不妨步入查看其内部逻辑。
public void increment() {
add(1L);
}
2
3
add涉及比较多的判断逻辑,我们分步骤进行说明:
首先代码会得到这样一个if判断,这里笔者为了简化阅读将if内部逻辑略去,先了解一下这个逻辑判断的作用:
- 将
cells数组赋值给as,如果as不为空说明此前出现过线程竞争激烈进而初始化了cells数组,则当前线程需要进入if逻辑尝试CAS操作cells完成累加操作。 - 如果
cells为空,则说明cells还未初始化,尝试CAS操作base,如果CAS操作失败,说明也有线程操作base,当前存在竞争,同样进入if逻辑操作base。
if ((as = cells) != null || !casBase(b = base, b + x)) {
//通过CAS逻辑操作cells数组
}
2
3
随后我们进入这个分支内部,可以看到只要符合下述任意一个条件,就说明cells数组竞争激烈,需要通过longAccumulate方法操作cells数组或者对cells数组进行扩容:
- 如果
as为空,即cells数组为空,说明此时数组未初始化,当前需要进行累加操作线程是因为casBase(b = base, b + x)对base累加失败才进来的,故直接调用longAccumulate方法尝试初始化数组并完成累加操作。 - 如果
(m = as.length - 1) < 0则说明当前线程通过CAS操作base失败,且当前cells已初始化但数组容量为0,需要调用longAccumulate进行对cells数组进行初始化并完成计数累加。 - 如果判断来到了
(a = as[getProbe() & m]) == null,则说明当前线程因为CAS操作base失败,且cells数组已经初始化好了,当前线程通过哈希算法得到的cells数组中的一个空位,需要直接调用longAccumulate对该空位初始化Cell并完成累加。 - 最后一个分支意味着当前线程
CAS操作base失败,且cells数组通过运算后的索引位置不为空,需要通过a.cas(v = a.value, v + x)尝试累加,如果累加失败,则调用longAccumulate方法对Cell进行CAS操作。
具体代码如下所示:
// 初始化uncontended 为true,说明此时还不存在线程竞争
boolean uncontended = true;
// 如果as指向的cells数组为空、或者数组长度为0、
// 数组不为空并且通过getProbe() & m算得要进行CAS操作的位置为空、
//亦或者通过CAS对数组某个位置进行累加操作失败时,则调用longAccumulate方法
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
longAccumulate(x, null, uncontended);
2
3
4
5
6
7
8
9
10
自此我们将add的大体逻辑都梳理完成了,完整的代码和注释如下所示:
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
//1. 如果cells为空或者 cells数组不为空,但当前线程CAS操作base失败则进入if逻辑
if ((as = cells) != null || !casBase(b = base, b + x)) {
// 2. 初始化uncontended 为true,说明此时还不存在线程竞争
boolean uncontended = true;
// 3. 如果as指向的cells数组为空、或者数组长度为0、
// 数组不为空并且通过getProbe() & m算得要进行CAS操作的位置为空、
//亦或者通过CAS对数组某个位置进行累加操作失败时,则调用longAccumulate方法
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
longAccumulate(x, null, uncontended);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
以上述4个分支都会进入longAccumulate都会完成最终的累加,所以我们步入查看longAccumulate的内部实现,因为longAccumulate逻辑较长,所以我们这里同样采用分段的方式进行分析:
首先代码会进行这样一个分支判断,如果getProbe()返回0,则说明当前线程之前并没有操作过cells数组,是第一次因为竞争激烈操作CAS操作base累加失败进入当前方法的,所以需要进行下面几个步骤完成一些初始化工作:
- 强制初始化得到一个
h值,用于后续的哈希运算获取cells数组索引位置。 wasUncontended设置为true,意味当前线程还未出现CAS操作cells数组失败的情况。
//1.如果h为0说明此前线程没有参与cells数组CAS累加竞争,需要对h进行强制初始化
if ((h = getProbe()) == 0) {
ThreadLocalRandom.current();
//2. 将哈希结果赋值给h
h = getProbe();
//3. wasUncontended 设置为true,意味当前线程还未出现`CAS`操作`cells`数组失败的情况。
wasUncontended = true;
}
2
3
4
5
6
7
8
到了这一步,longAccumulate的初始化步骤就都完成了,接下来就是真正执行累加逻辑一个无限for循环。循环内部出现大量的分支,我们还是逐步进行拆解分析。
先来看看第一个大分支,它会检查cells是否不为空容量大于0,如果是则说明LongAdder之前出现过激烈竞争已把cells初始化好了,进入步骤后续内部的if-else逻辑。
//3.1 如果数组不为空且容量大于0则进入此逻辑
if ((as = cells) != null && (n = as.length) > 0) {
//略
}
2
3
4
步入分支内部,可以看到它的第一个子分支:
- 判断当前线程通过哈希算法得到
cells索引位置是否为空,如果为空,则说明cells数组这个位置之前没有被任何线程操作过,进入步骤2。 - 判断
cellsBusy是否为0,若为0则说明还没有线程为cellsBusy上锁,进入步骤3。 - 初始化一个
Cell,值设置为传入的值x(即add传入的1L),进入步骤4。 - 为保证线程安全再次判断
cellsBusy是否为0,若为0则通过CAS将其设置为1,视为对cellsBusy上锁。 - 为保证线程安全再次判断
cells数组是否不为空以及对应索引位置是否还是为空,若符合情况则将上文初始化的Cell存到cells数组中。 - 将
cellsBusy设置为0,视为释放锁,退出循环。
//3.1.1 判断当前线程要操作的索引位置为空,若为空则说明此前没有其他线程操作过,则进入此if逻辑
if ((a = as[(n - 1) & h]) == null) {
//判断cellsBusy是否为0,若为0说明此时没有线程在操作
if (cellsBusy == 0) {
//初始化Cell
Cell r = new Cell(x);
//为保证线程安全,再次判断cellsBusy是否为0,若为0则CAS设置为1,在进入分支
if (cellsBusy == 0 && casCellsBusy()) {
boolean created = false;
try {
Cell[] rs; int m, j;
//如果数组不为空,且长度大于0,并且要存储的元素仍然为空,则将初始化的cell存到cells数组中
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
//将初始化的cell存到cells数组中
rs[j] = r;
//created 为true,表名本次初始化累加操作完成
created = true;
}
} finally {
//解锁,即将cellsBusy 设置为0
cellsBusy = 0;
}
if (created)
break;
continue;
}
}
collide = false;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
如果线程没有走到上述的分支,则说明当前cells数组竞争较为激烈,结果哈希计算后得到的索引位置不为空,需要将wasUncontended设置为true,到达循环末尾再次进行哈希运算,进入下一论的循环。
//3.2 wasUncontended为false,则说明在尝试过CAS操作cells数组失败了,这里直接将其设置为true,通过再哈希再次尝试CAS操作数组某个位置
else if (!wasUncontended)
wasUncontended = true;
//略
//计算下一次的哈希值
h = advanceProbe(h);
2
3
4
5
6
7
8
于是下一次循环基于上一轮循环得到的h计算索引位置得到cell变量a之后,进行CAS累加操作,如下所示,如果成功则直接推退出循环。
//3.3 尝试CAS操作数组某元素的值,如果成功则直接退出循环
else if (a.cas(v = a.value, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break;
2
3
4
如果上一个分支CAS操作失败,则代码会走到这里,它进行如下判断:
cells长度是否超过CPU核心数,如果没超过则会对cells数组进行扩容,反之将collide设置为false。cells数组不等于as,说明cells数组被被其他线程进行扩容修改了。
符合上述任意条件都会将collide设置为false,再进行进行哈希运算后,进入下一轮循环,进行第二次的CAS累加操作。
//3.4 数组长度以达到或超过CPU核心数,或者cells数组再次期间已扩容,当前as为过期数组空间,将collide 设置为false
else if (n >= NCPU || cells != as)
collide = false;
//略
//if分支判断完成后来到这里再哈希获取新的h值到下一次循环进行CAS修改操作
h = advanceProbe(h);
2
3
4
5
6
7
8
9
上一步设置后进行的CAS操作再次失败,则进入这个分支,如果到collide为false说明此时cells数组已经扩容到最大值已不能再一次进行扩容,只能不断一轮接一轮的哈希运算在CAS累加直到成功。
我们假设我们此时cells数组还没达到CPU核心数,所以跳过这个分支,于是代码走到下一个分支。
// 3.5如果collide为false则将其设置为true,说明此时数组竞争激烈
else if (!collide)
collide = true;
//略
//不断进行哈希,然后进入下一轮的CAS尝试
h = advanceProbe(h);
2
3
4
5
6
7
走到了这里,说明当前cells数组容量还未超过CPU核心数,且经过两次的CAS操作cells数组累加失败,竞争已经非常激烈了,LongAdder就会通过CAS对cellsBusy 上锁的方式对cells进行扩容,减小多线程操作cells的激烈程度,如果成功则进入下一次循环继续进行CAS操作。
//3.6 判断cellsBusy 是否为0,若为0,则通过CAS设置为1,意为上锁
else if (cellsBusy == 0 && casCellsBusy()) {
try {
if (cells == as) {
//上锁成功,为rs 数组进行左移扩容
Cell[] rs = new Cell[n << 1];
//将cells数组的内容复制到rs上
for (int i = 0; i < n; ++i)
rs[i] = as[i];
//cells指向rs
cells = rs;
}
} finally {
//完成扩容,解锁cellsBusy
cellsBusy = 0;
}
collide = false;
continue;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
自此我们将完整的longAccumulate源码第一个大分支即cells数组不为空的的情况分析完成了,完整的分支以及子分支代码如下:
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
int h;
//1.如果h为0说明此前线程没有参与cells数组CAS累加竞争,需要对h进行强制初始化
if ((h = getProbe()) == 0) {
ThreadLocalRandom.current();
h = getProbe();
wasUncontended = true;
}
//2. 初始化collide 为false,默认此时竞争不激烈
boolean collide = false;
//3. 进入无限for循环
for (;;) {
Cell[] as; Cell a; int n; long v;
//3.1 如果数组不为空且容量大于0则进入此逻辑
if ((as = cells) != null && (n = as.length) > 0) {
//判断当前线程要操作的索引位置为空,即此前没有其他线程操作过,则进入此分支内部
if ((a = as[(n - 1) & h]) == null) {
//判断cellsBusy 是否为0,若为0则说明没有线程操作cellsBusy
if (cellsBusy == 0) {
Cell r = new Cell(x);
//通过cas将cellsBusy 设置为1,意为上锁
if (cellsBusy == 0 && casCellsBusy()) {
boolean created = false;
try {
//将初始化的cell存到cells数组中
Cell[] rs; int m, j;
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
//将初始化的cell存到cells数组空位中,并将created 设置为true,意为本次初始化Cell以及累加完成
rs[j] = r;
created = true;
}
} finally {
//解锁,即将cellsBusy 设置为0
cellsBusy = 0;
}
if (created)
break;
continue;
}
}
collide = false;
}
//3.2 wasUncontended为false,则说明在尝试过CAS操作cells数组失败了,这里直接将其设置为true,通过再哈希,下次循环再次尝试CAS操作
else if (!wasUncontended)
wasUncontended = true;
//3.3 尝试CAS操作数组某元素的值,如果成功则直接退出循环
else if (a.cas(v = a.value, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break;
//3.4 数组长度以达到或超过CPU核心数,或者cells数组再次期间已扩容,当前as为过期数组空间,将collide 设置为false,然后进行一次哈希运算,进入下一次循环再尝试CAS累加
else if (n >= NCPU || cells != as)
collide = false;
// 3.5如果collide为false则说明上一个循环执行到上一个分支,即当前cells数组操作竞争激烈,无法扩容,只能再次哈希进行下一次CAS累加操作。故将其设置为true,哈希运算后进入下一次循环
else if (!collide)
collide = true;
//3.6 代码能够走到这,说明cells竞争激烈,并且数组容量还未超过或达到CPU核心数,通过CAS对cellsBusy 上锁,对cells数组完成扩容,完成后将cellsBusy 设置为0意为解锁,当前线程会在下一次循环再次尝试CAS操作
else if (cellsBusy == 0 && casCellsBusy()) {
try {
if (cells == as) {
Cell[] rs = new Cell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
h = advanceProbe(h);
}
//略
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
以上是cells数组不为空的大分支,接下来我们再将进入longAccumulate之后,cells数组为空的另外两个分支补充一下,两个分支逻辑比较清晰:
- 一个分支会判断
cellsBusy是否为0、cells数组是否没有发生变化,即没有被其他线程初始化,若符合这几个条件,则CAS将cellsBusy设置为1,完成对cells数组初始化,并将累加结果存到初始化的数组的某个空位中。 - 若是来到下一个分支则说明当前数组为空,并且当前线程尝试对
cellsBusy上锁失败,所以无法初始化数组,只能再次尝试CAS操作base完成累加。
//4. 走到这里说明数组为空,尝试CAS操作初始化cells
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
boolean init = false;
try { // Initialize table
if (cells == as) {
Cell[] rs = new Cell[2];
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init)
break;
}
//5. 走到这里则说明数组为空,但是cas对cellsbusy上锁失败,所以只能再次尝试对base进行累加,如果成功则退出循环。
else if (casBase(v = base, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break; // Fall back on using base
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
自此我们将longAccumulate所有逻辑都覆盖到了,完整的代码如下:
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
int h;
//1.如果h为0说明此前线程没有参与cells数组CAS累加竞争,需要对h进行强制初始化
if ((h = getProbe()) == 0) {
ThreadLocalRandom.current();
h = getProbe();
wasUncontended = true;
}
//2. 初始化collide 为false,默认此时竞争不激烈
boolean collide = false;
//3. 进入无限for循环
for (;;) {
Cell[] as; Cell a; int n; long v;
//3.1 如果数组不为空且容量大于0则进入此逻辑
if ((as = cells) != null && (n = as.length) > 0) {
//判断当前线程要操作的索引位置为空,即此前没有其他线程操作过,则进入此分支内部
if ((a = as[(n - 1) & h]) == null) {
//判断cellsBusy 是否为0,若为0则说明没有线程操作cellsBusy
if (cellsBusy == 0) {
Cell r = new Cell(x);
//通过cas将cellsBusy 设置为1,意为上锁
if (cellsBusy == 0 && casCellsBusy()) {
boolean created = false;
try {
//将初始化的cell存到cells数组中
Cell[] rs; int m, j;
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
//将初始化的cell存到cells数组空位中,并将created 设置为true,意为本次初始化Cell以及累加完成
rs[j] = r;
created = true;
}
} finally {
//解锁,即将cellsBusy 设置为0
cellsBusy = 0;
}
if (created)
break;
continue;
}
}
collide = false;
}
//3.2 wasUncontended为false,则说明在尝试过CAS操作cells数组失败了,这里直接将其设置为true,通过再哈希,下次循环再次尝试CAS操作
else if (!wasUncontended)
wasUncontended = true;
//3.3 尝试CAS操作数组某元素的值,如果成功则直接退出循环
else if (a.cas(v = a.value, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break;
//3.4 数组长度以达到或超过CPU核心数,或者cells数组再次期间已扩容,当前as为过期数组空间,将collide 设置为false,然后进行一次哈希运算,进入下一次循环再尝试CAS累加
else if (n >= NCPU || cells != as)
collide = false;
// 3.5如果collide为false则说明上一个循环执行到上一个分支,即当前cells数组操作竞争激烈,无法扩容,只能再次哈希进行下一次CAS累加操作。故将其设置为true,哈希运算后进入下一次循环
else if (!collide)
collide = true;
//3.6 代码能够走到这,说明cells竞争激烈,并且数组容量还未超过或达到CPU核心数,通过CAS对cellsBusy 上锁,对cells数组完成扩容,完成后将cellsBusy 设置为0意为解锁,当前线程会在下一次循环再次尝试CAS操作
else if (cellsBusy == 0 && casCellsBusy()) {
try {
if (cells == as) {
Cell[] rs = new Cell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
h = advanceProbe(h);
}
//4. 走到这里说明数组为空,尝试CAS操作初始化cells
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
boolean init = false;
try { // Initialize table
if (cells == as) {
Cell[] rs = new Cell[2];
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init)
break;
}
//5. 走到这里则说明数组为空,但是cas对cellsbusy上锁失败,所以只能再次尝试对base进行累加,如果成功则退出循环。
else if (casBase(v = base, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break; // Fall back on using base
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
# sum方法
LongAdder完成计算之后,如果需要获取累加结果,就必须对cells和base进行求和,所以LongAdder获取结果的逻辑很简单:
- 将
base的值赋值给sum。 - 遍历数组,将每个值都累加到
sum中。 - 返回结果。
需要注意的是,在计算期间可能别的线程还会cells或者base进行累加,所以对于sum结果可能存在一定误差,读者使用时需要考虑到这一点。
public long sum() {
Cell[] as = cells; Cell a;
//sum设置为base的值
long sum = base;
//遍历cells数组,将cells数组的值都添加到sum中
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
//返回计算结果
return sum;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# reset方法
该方法用于重置base和cells数组,源码比较简单,即先重置base,再遍历cells数组并将cells数组元素设置为0,唯一需要注意的是该方法并没有任何互斥同步操作,所以最好在没有线程操作LongAdder进行计数时使用。
public void reset() {
Cell[] as = cells; Cell a;
//重置base
base = 0L;
//如果cells不为空,则遍历cells并将每一个索引位置的value重置为0
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
a.value = 0L;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
# sumThenReset方法
如果我们希望重置前获取累加结果,则可以使用sumThenReset方法,从源码可以看出该方法在累加时还会顺手进行重置。
public long sumThenReset() {
Cell[] as = cells; Cell a;
//sum设置为base的值
long sum = base;
//将base重置
base = 0L;
if (as != null) {
//遍历cells数组,累加一个value,重置一个value
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null) {
sum += a.value;
a.value = 0L;
}
}
}
//返回累加结果
return sum;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# LongAdder常见面试题
# LongAdder的作用是什么?
LongAdder是一个支持多线程累加操作的原子类,相较于AtomicLong,它在高并发场景下执行累加操作有着更好的执行效率。
# 与AtomicLong相比,LongAdder有什么优势?
高并发场景下,大量线程进行累加操作时,LongAdder会提供一个名为cells的数组,每个线程会通过哈希运算得到数组中的一个索引位置,然后通过CAS的方式操作该位置的元素完成累加操作。
这种通过空间换时间实现分段CAS累加存储的方式相较于AtomicLong多对一CAS的工作方式来说,避免了更激烈的竞争,提升累加执行效率。
# LongAdder的使用场景有哪些?
当涉及到高并发计数、统计聚合、资源分配与限制以及性能度量与监控时,以下是一些具体的使用场景,可以使用LongAdder:
- 网络服务器请求计数:在一个高并发的网络服务器中,你可能希望统计每秒钟接收到的请求数。你可以使用
LongAdder来创建一个计数器,每当有请求到达时,使用LongAdder的increment()方法进行增加操作。 - 并行数据处理:在并行处理大规模数据集时,你可能需要统计每个线程或任务处理的数据量。使用多个
LongAdder实例,每个实例用于跟踪一个线程或任务的处理数量,最后可以使用LongAdder的sum()方法将它们的计数值相加,得到总体处理数量。 - 限制资源并发访问:在某些场景中,你可能需要限制同时访问某个资源的并发数量。例如,一个数据库连接池可能有最大并发连接数的限制。你可以使用
LongAdder来维护当前的并发连接数,每当有新的连接请求时,使用LongAdder的increment()方法进行增加操作,当连接释放时,使用LongAdder的decrement()方法进行减少操作。 - 性能度量与监控:使用
LongAdder来收集性能指标和监控数据是很常见的。例如,你可以使用多个LongAdder实例来统计请求响应时间、吞吐量、错误数量等指标。每个LongAdder实例用于跟踪一个特定的指标,最后可以通过将它们的计数值相加来获取总体的性能数据。
# LongAdder的内部实现机制是什么?
LongAdder的核心思想就是空间换时间,通过base和cells数组完成计数,再通过base加cells数组求和完成统计,简单来说它的工作过程分为以下几步:
- 初始时线程通过
CAS操作base完成累加操作。 - 因为竞争激烈导致某个线程
CAS操作base失败,进而初始化cells数组,并通过哈希运算得到cells数组某个索引,再完成累加操作。 - 某个线程
CAS操作cells数组失败超过3次,并且cells数组容量不超过CPU核心,对cells进行扩容。 - 如果线程不断失败,且
cells数组容量大于或者等于CPU核心数,则当前线程会不断通过哈希运算得到cells数组索引位置进行累加操作,直到成功为止。
最终在需要获取结果时,通过sum方法将base和cells数组中的值相加得到最终结果并返回。
# 阿里为什么推荐使用LongAdder,而不是volatile?
volatile 解决多线程内存不可见问题。对于一写多读,是可以解决变量同步问题,但是如果多写,同样无法解决线程安全问题。 说明:如果是 count++ 操作,使用如下类实现:AtomicInteger count = new AtomicInteger(); count.addAndGet(1); 如果是 JDK8,推荐使用 LongAdder 对象,比 AtomicLong 性能更好(减少乐观 锁的重试次数)。
# 有了解LongAdder中的Cell的伪共享问题吗?
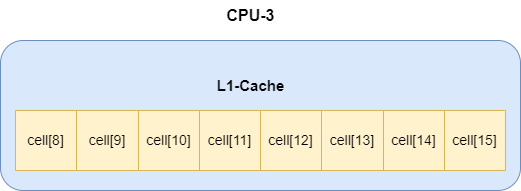
我们假设有这样一个场景,服务器有16核CPU,并且当前累加操作是通过LongAdder完成的,因为当前进行累加操作的线程比较多,LongAdder累加操作都需要通过哈希计算得到cells数组中某索引的cell元素完成。
假设线程1001经过哈希运算得到cells数组索引位置15,CPU-3为了完成线程1001的累加操作,需要将cells[15]加载到CPU1级缓存中(假设一级缓存为64字节),假如我们没有对cell进行填充,因为局部性原理,加载cells[15]时,可能会将cells[8-15]的元素也加载到CPU-3中。
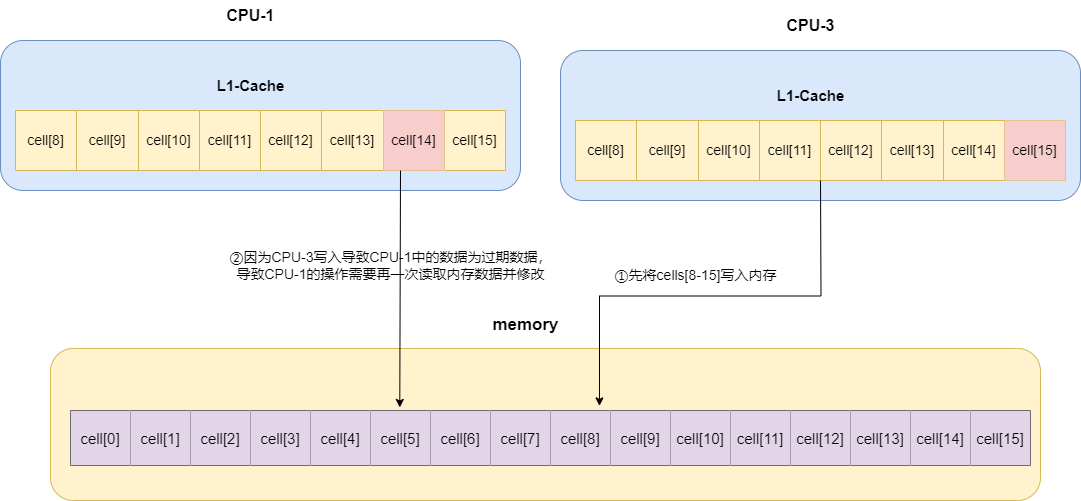
试想一下,如果CPU-1正在操作cells[14]还没写入内存中,我们的CPU-3因为修改了cells[15]正准备将修改后的cells[8-15]一起写到内存中,这就会使的CPU-1中的修改全部作废,CPU-1不得不为此重新到内存中加载新的cells[14]再次进行操作,如此往复,伪共享问题由此发生。
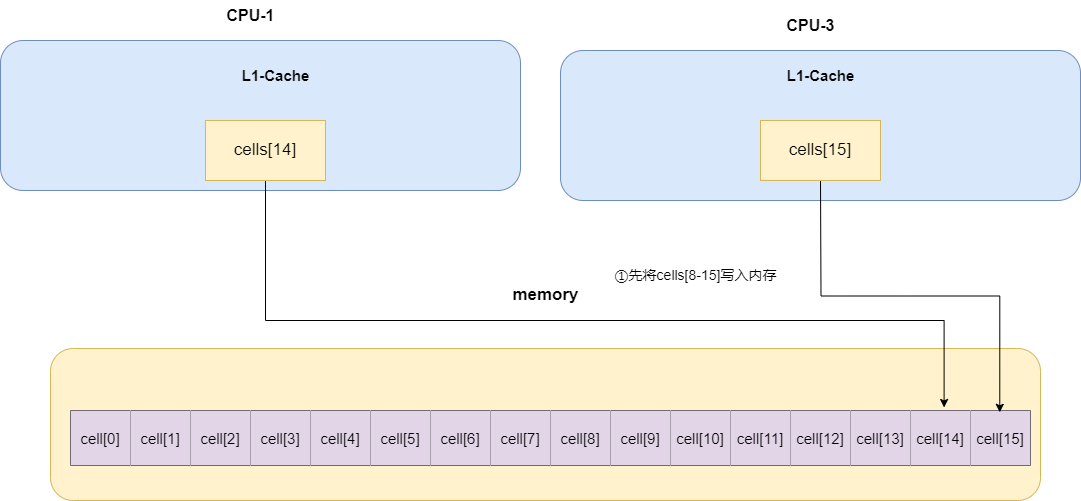
对此,解决办法只有一个,那就是让CPU加载Cell时只能加载到一个Cell,所以LongAdder为了做到这一点,通过在Cell上添加@sun.misc.Contended注解,确保每个Cell都能填满CPU一级缓存,从而避免某个线程修改Cell导致其他核心上的线程修改作废问题。
# LongAdder可以做限流吗?存在那些问题?
LongAdder可以做限流但并不是最佳的选择,原因如下:
LongAdder累加器只能保证高并发场景下计数的效率,却无法保证实时计数统计的准确性,因为在高并发场景很可能出现大量线程CAS累加冲突失败,需要进行重试才能完成累加,并且获取累加器的结果时还需要进行求和操作,毫无疑问,这对于限流场景非常不理想。LongAdder只能用于计数,对于阈值设定以及限流还需要借助其他工具才能实现判断是否达到阈值以及限流操作。
综上所述,对于单体应用的限流,我们更建议使用RateLimiter等第三方成熟的限流工具。
# 为什么LongAdder底层的cells数组容量会设置在CPU核心数附近?为什么不是CPU核心数的两倍?
先说答案,为了尽可能利用CPU核心并避免没必要的内存置换。
从上文我们了解到LongAdder基于@sun.misc.Contended注解避免操作Cell所引发的伪共享问题,所以在竞争激烈的情况下,cells数组会扩大为无限接近与CPU核心的一个值,假设我们的计算机为4核,那么cells的数组则为4。
在竞争最激烈的情况下,每一个CPU核心的1级缓存都会对应一个Cell,如下图所示:
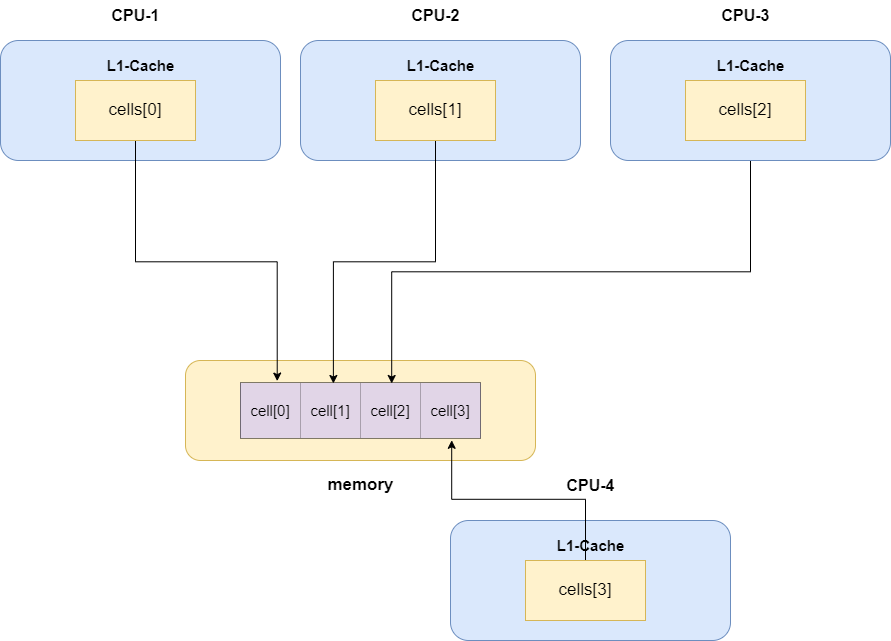
可以看到CPU核心和cells数组容量是一一对应的,假如我们设置为CPU核心数的2倍,那么我们例子中的cells数组容量为8,假如某个线程需要操作cells数组索引7位置的Cell,那么有一个CPU就需要将一级缓存中的Cell置换出来,如此往复,尽管在高并发之下碰撞率会减小那么一些些,但为了降低这么一点点的碰撞率而让CPU频繁的置换一级缓存中的Cell,这样的做法是得不偿失的。
# 参考文献
java线程安全的高效计数--LongAddr原理分析:https://blog.csdn.net/u013041642/article/details/99693447 (opens new window)
深入剖析LongAdder是咋干活的:https://juejin.cn/post/6844903891310477325#heading-6 (opens new window)
阿里为什么推荐使用LongAdder,而不是volatile? :https://zhuanlan.zhihu.com/p/197903344 (opens new window)
并发编程——多线程计数的更优解:LongAdder原理分析 :https://zhuanlan.zhihu.com/p/269240636 (opens new window)
