 从Java程序员视角聊聊CPU缓存
从Java程序员视角聊聊CPU缓存
# 引言
近期和读者交流谈及CPU缓存这块知识点,遂借此契机对此文进行详细的梳理和优化,帮助大家更好的理解这块知识点。
我是 SharkChili ,Java 开发者,Java Guide 开源项目维护者。欢迎关注我的公众号:写代码的SharkChili,也欢迎您了解我的开源项目 mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)。
为方便与读者交流,现已创建读者群。关注上方公众号获取我的联系方式,添加时备注加群即可加入。
# 回顾计算机体系
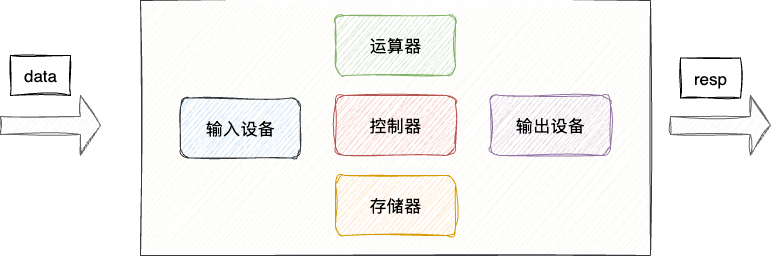
# 冯诺依曼计算机体系
早期的冯诺依曼计算机,大抵功能和工作流程如下:
- 输入设备接收用户输入的指令信息
- 数据到达存储器,控制器从存储器中取出指令交给运算器执行
- 运算器完成运算,最后交由输出设备响应给用户
可以看到控制流程的调度由控制器负责,导致一个简单的执行需要经过多个不必要的工序,使得整个执行流程变得繁琐冗长:
# 现代计算机
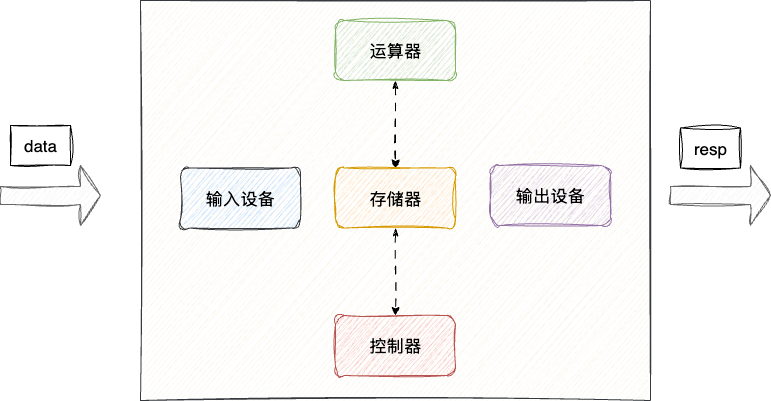
现在计算机对此进行了改造,可以看出他们将需要处理的数据的运算器和存储器放到两边:
- 存储器负责运输数据给这运算器和控制器
- 数据经过运算器计算之后再将数据写回存储器
- 存储器将数据交给控制器转发到输出设备:
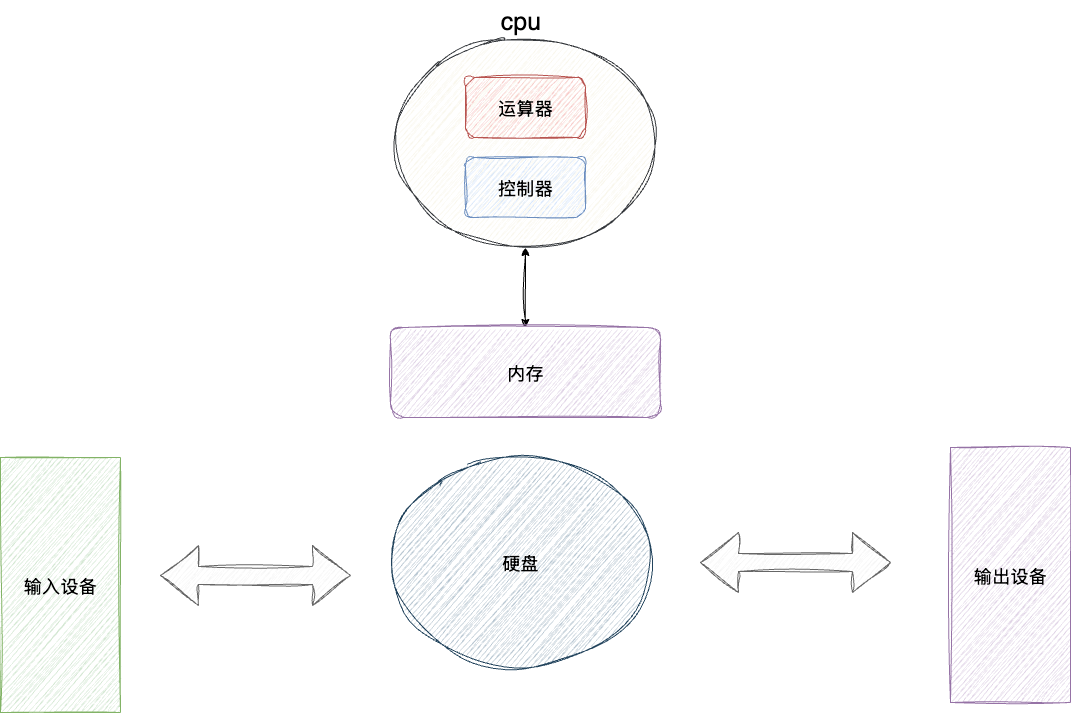
了解这样的体系结构后,我们将这些组成部分整合起来,就得到了现代计算机的重要组成部分——CPU。CPU包含了运算器和控制器,主存储器(也就是我们常说的内存)以及辅存(就是硬盘):
我们将职责进行划分就构成了下图所示的样子:
- 由运算器和控制器构成CPU
- 主存也就是我们常说的内存
- 外设部分由一些I/O设备、辅存(就是硬盘)组成
# CPU时钟周期
为了让读者更好的理解文章后续的内容,笔者这里带读者回顾一下CPU时钟周期的概念,关于CPU时钟周期的分析,我们必须了解服务器的CPU主频,它反应CPU每秒震荡次数,对此我们可以通过lscpu查看。
以笔者服务器为例,对应CPU主频为2.80GHz:
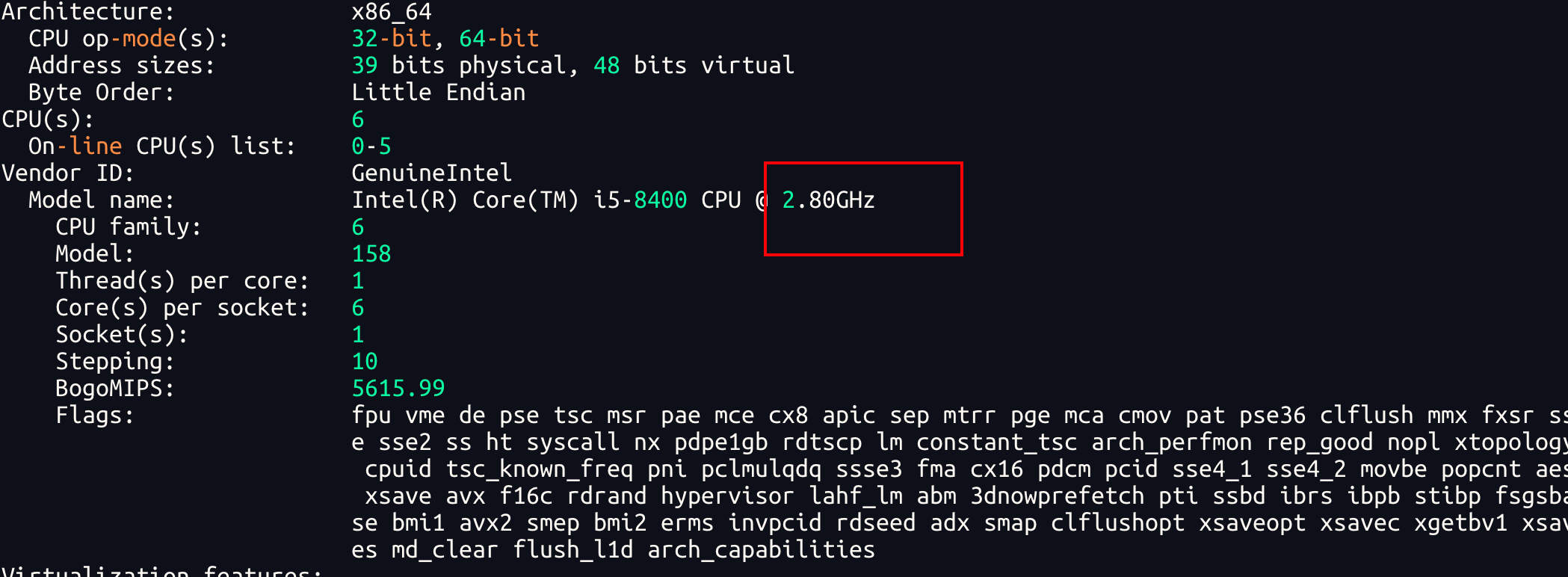
已知 1GHz=10⁹ 对应我们的cpu也就是每秒震荡 2.8 * 10⁹次,而时钟周期反应的是每次震荡的耗时,由此公式时钟周期 = 主频的倒数
时钟周期 = 1/主频
= 1/ 2.8 * 10⁹
= 0.357 纳秒
2
3
4
5
6
也就是一个时钟周期为0.357 纳秒 ,假设执行一个读指令在笔者的服务器需要20个时钟周期,那么这个执行耗时就0.357 * 20也就是7.14纳秒。
# 详解cpu缓存
# 内存性能的局限性
计算机发展初期,CPU执行指令时用到的数据都必须从内存中加载,但由于内存的读写速度与CPU不在一个级别,这就使得CPU的性能受到内存读写效率的制约而降低。由此设计者们开始思考,在CPU流水线指令设计理念的基础上,CPU的执行效率是否还有提升的空间。
通过观察发现,CPU每次执行指令时用到的数据,其前后相邻的数据有很大概率也会被用到。例如下面这段循环代码,每次输出元素后都会访问其后方的元素,因此设计者开始考虑在CPU上增加一层缓存,通过提前预读数据来提升CPU运算效率,从而避免因等待内存读取而产生的阻塞问题:
for (int i = 0; i < 10; i++) {
System.out.println(list.get(i));
}
2
3
由此引入了CPU缓存的设计,也就有了CPU缓存行的概念,即当CPU使用到内存中的某块数据时,会将这块内存数据连同其附近的数据一起加载到CPU缓存中:
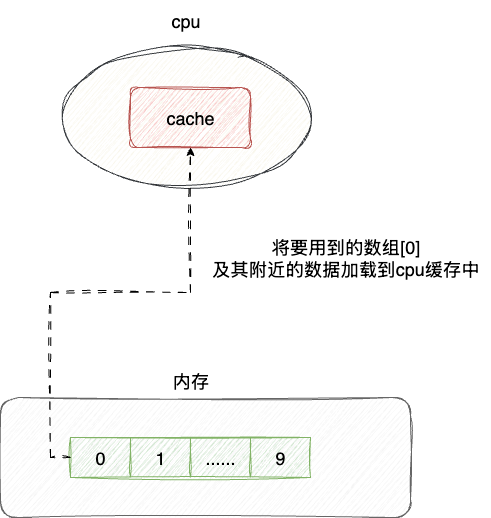
考虑到CPU中缓存电路采用读写速度较高的SRAM电路,耗用的晶体管数量比较多,现代CPU L1缓存通常为每个核心32KB到64KB,同时缓存对应的基本单位默认是缓存行,默认大小为64字节。
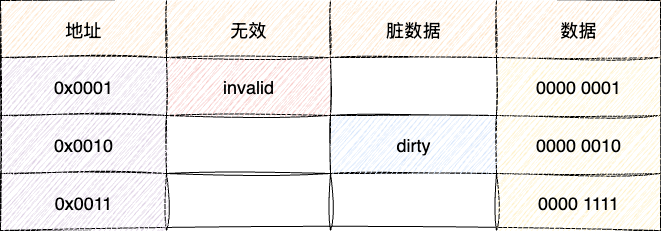
于是我们就有了这样一组cpu缓存的粗略设计:
- 每个缓存行都有一个内存空间记录缓存的数据地址
- 缓存行专门用无效标识记录当前数据是否有效,若标识为无效则cpu需要从内存中读取数据
- 脏数据标识说明这个数据被cpu修改过,需要刷新到内存中
- 数据字段记录cpu要操作的数据信息
# 缓存加载的算法
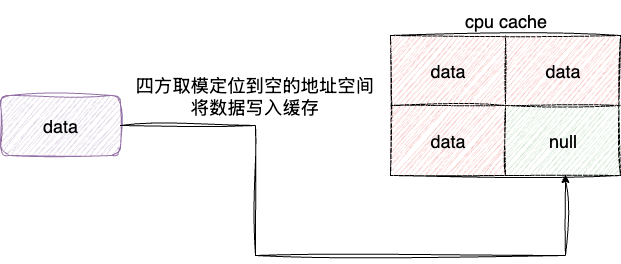
有了缓存基础之后,设计者们就开始考虑如何从内存中高效地加载数据并写入CPU缓存行中。一开始考虑采用遍历寻址的方式,但这种方式不仅效率低下,还违背了缓存行设计的初衷,无法实现快速预读和使用。
因此设计者考虑采用数据取模地址并写入的设计思路,但是问题又来了,如果两个要写入的数据地址发生冲突要如何解决?于是设计者打算将缓存空间分为四块,也就是四路组相连。在进行缓存写入时,对四个缓存空间都进行取模运算,将数据写入有空闲空间的缓存块中,这样既能保证写入效率,又能尽可能减少冲突:
# 指令与数据缓存分离
在CPU内部流水线中,如果执行指令的电路和读取数据的电路都需要访问内存,而访问内存的地址译码器只有一个,这就使得一方必须阻塞等待,导致双方中必有一方需要阻塞等待,这就是结构冒险:
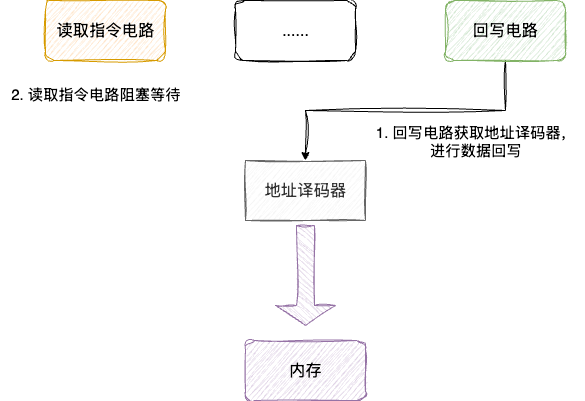
于是就考虑到一种名为哈佛架构的设计,即将内存空间分为指令空间和数据空间,由此避免这种冲突,但是这种做法会导致内存失去动态分配的优势。
考虑到当前CPU引入了缓存的概念,可以在缓存的基础上将执行指令和数据读取两个模块的缓存空间分离,利用CPU缓存读取来尽可能避免指令和数据访问冲突。当然,这种情况在缓存未命中的情况下还是会出现结构冒险:
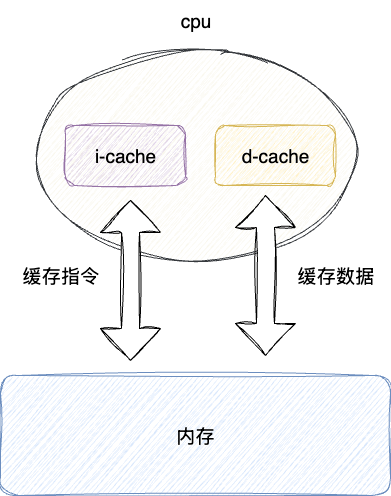
# 多级缓存空间
看到引入缓存后的优势,设计者提出了多级缓存概念。结合缓存电路和晶体管的制作成本,最终的折中方案为:
一级缓存容量最小,每个
CPU独有一份一级缓存L1-cache,效率最高,CPU访问数据的时间成本只需要2~4个时钟周期,缓存分为i-cache和d-cache分别存储指令和数据二级缓存容量稍大,成本相对控制,所以访问时间表现稍差,大约需要10~20个时钟周期
三级缓存多核CPU共享,CPU访问时间大约
20~60个时钟周期内存大约是
200~300个时钟周期
按照我们先前对时钟周期的说法,2GHz的CPU时钟周期的计算过程如下:
时钟周期=1/主频
因为:主频单位为hz即 次/秒
2GHz= 2*10^9 hz
时钟周期=1/ 2*10^9
= 0.0000000005次/秒
= 0.5ns
2
3
4
5
6
7
所以一个一个2GHz的cpu对应的时钟周期大约是0.5ns即0.5ns执行一次cpu事件,也就是每秒钟发生20亿次事件。
# cpu缓存基本概念
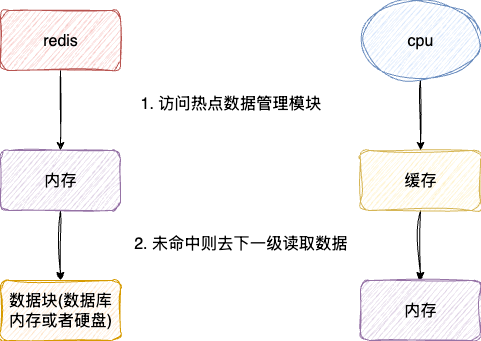
在CPU访问数据的时候,都会优先从缓存中获取数据,如果没有找到再去内存中读取,若内存中也找不到,则从磁盘中读取数据并加载到CPU CACHE中。
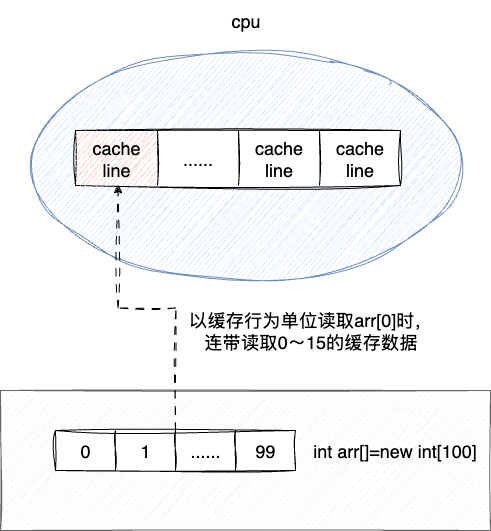
当CPU CACHE开始加载数据的时候,并不是按需精确读取一段数据,而是一小块一小块地进行数据读取。而这一小块数据就是我们日常所说的CPU Line(缓存行)。
在Linux中执行命令cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size,我们就能看到自己CPU L1 Cache对应的CPU Line的大小。以笔者服务器为例,每个缓存行大小为64字节:
这64字节是什么概念呢?我们都知道一个整型变量是4个字节。假如我们声明一个数组int data[] = new int[32768];,当CPU cache载入data[0]时,由于cache line的大小为64字节,也就是说还会有一些空闲的空间没用到,根据局部性原理,CPU就会将剩余部分用于存储data[0]附近的数据,也就是说载入data[0]时,cache line顺手将索引1-15的元素也加载到CPU cache line中.
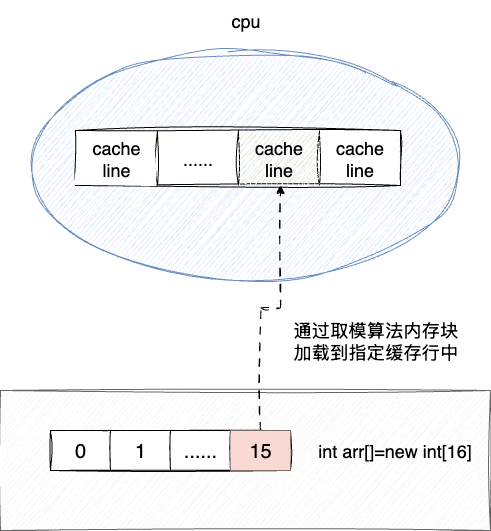
当cache中有内存加载的数据时,我们怎么知道这个数据对应的内存那块数据呢?
其实CPU早就考虑到这点了,实现方式也很简单,通过直接映射Cache(Direct Mapped Cache),说白了就是将内存地址和CPU cache line做一个映射,我们都知道内存的一块块数据称为内存块,实现地址映射的方式也很简单,就是将内存块地址进行取模运算后再将存到对应的cache line中。
例如:我们有8个cache line以及32个内存块,当cache需要载入15号块时,cache就会将其存到15%8=7,即7号cache line中。
假如映射地址冲突了怎么办?这个问题也很简单,针对每个cache line 增加一个Tag标记就好了,例如第4个cache line 存储的是内存块15的数据,对应第4个cache line的缓存空间数据结构为:
- 设置
valid标识为1说明当前缓存数据有效且未过期(缓存数据有效,操作系统其他线程未对缓存对应的内存数据做修改) - 设置设置
tag标识说明cache line对应的内存数据是内存块15 offset告知cache line中对应的偏移地址是我们实际要用到数据,这样的数据用专业术语称为字(word)
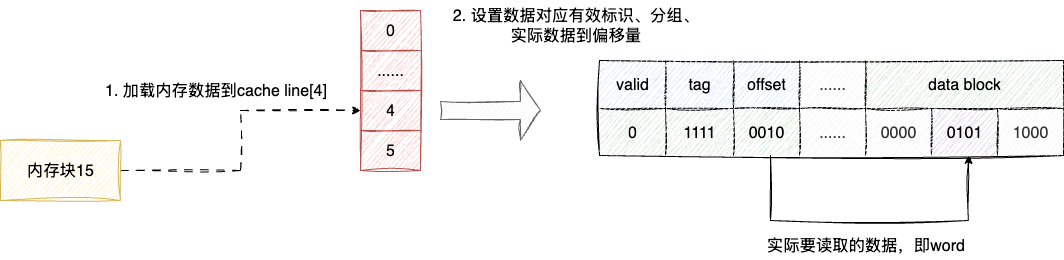
基于cache line,当cpu需要用到这份数据时,就会执行如下流程:
- 基于内存地址通过运算定位到
cache line cache line无数据则从内存加载,反之进入步骤3- 查看
valid标识为是否为有效,若无效则从内存重新加载,若有效进入步骤4 - 查看
offset从cache line定位到实际用到的字(word)
# (实践)通过CPU的缓存工作机制编写高性能代码
# 遍历顺序适配CPU缓存加载顺序
先看看下面这段代码,这段代码按列遍历二维数组,在笔者电脑上运行需要291毫秒:
int[][] arr = new int[10000][10000];
long start = System.currentTimeMillis();
// 逐列遍历数据
for (int i = 0; i < 10000; i++) {
for (int j = 0; j < 10000; j++) {
arr[j][i] = 0;
}
}
long end = System.currentTimeMillis();
2
3
4
5
6
7
8
9
10
再看看这段按行遍历的代码,在笔者电脑上运行只需要30毫秒:
int[][] arr = new int[10000][10000];
long start = System.currentTimeMillis();
//逐行遍历二维数据
for (int i = 0; i < 10000; i++) {
for (int j = 0; j < 10000; j++) {
arr[i][j] = 0;
}
}
long end = System.currentTimeMillis();
System.out.println("耗时:" + (end - start));
2
3
4
5
6
7
8
9
10
11
12
13
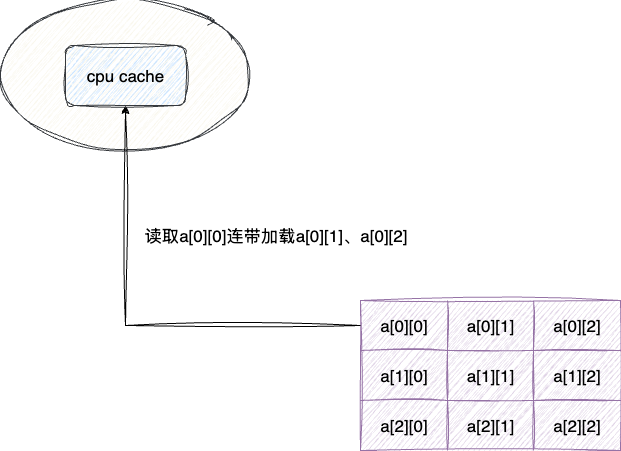
让我们回顾一下CPU cache的原理,由于局部性原理,加载某个数据时会加载其附近的数据,而第一段代码是按列(纵向)遍历数据的。这意味着CPU CACHE中的数据不一定包含for循环所需的数据。
CPU cache只会顺序加载其附近的数据,假如我们访问arr[0][0],那么它会顺序加载arr[0][1]、arr[0][2]、arr[0][3]等。这就导致按列遍历过程中,只有第一次访问的列在缓存中,其他列的数据都要从内存中读取。这就是为什么第二段代码的遍历顺序与局部性原理的加载顺序一致,所以效率更高.
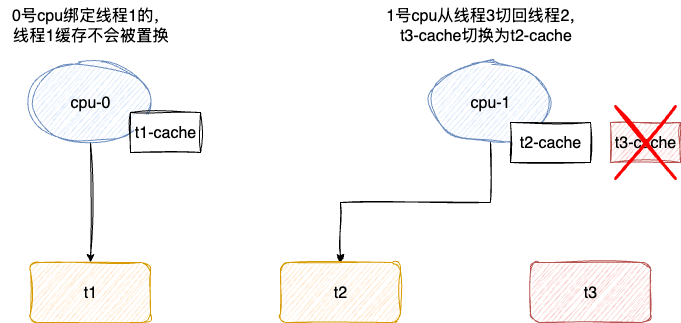
# 绑定CPU(设置cpu亲和力)实现多核 CPU 的缓存命中率
现代CPU都是多核心的,进程可能在不同CPU核心间来回切换执行,这对CPU Cache是不友好的的。虽然L3 Cache是多核心之间共享的,但是L1和L2 Cache都是每个核心独有的。如果一个进程在不同核心间来回切换,各个核心的缓存命中率就会受到影响;相反,如果进程都在同一个核心上执行,那么其数据的L1和L2 Cache的缓存命中率可以得到有效提高。缓存命中率高意味着CPU可以减少访问内存的频率。
当有多个「计算密集型」线程同时执行时,为了防止因切换到不同核心而导致缓存命中率下降的问题,我们可以将线程绑定在某一个CPU核心上,这样性能可以得到非常可观的提升。
在Linux上提供了sched_setaffinity方法,用于实现将线程绑定到某个CPU核心的功能,就像下面这段代码,笔者将两个线程绑定到4号和5号cpu上:
#include <stdio.h>
#include <unistd.h>
#include <time.h>
#include <signal.h>
#include <string.h>
#define __USE_GNU
#include <sched.h>
#include <pthread.h>
int cpu_core_count;
/**
* 线程函数1 - 绑定到指定CPU核心并执行空循环
* @param arg 指向CPU核心编号的指针
* @return NULL
*/
void *thread_func1(void *arg) {
cpu_set_t cpu_set_mask; // CPU核心集合掩码
int *cpu_core_id = (int*)arg; // CPU核心ID
// 显示要绑定的CPU核心
printf("Binding thread 1 to CPU core %d\n", *cpu_core_id);
// 初始化CPU集合并设置要绑定的CPU核心
CPU_ZERO(&cpu_set_mask); // 清空CPU集合
CPU_SET(*cpu_core_id, &cpu_set_mask); // 将指定CPU核心添加到集合中
// 设置当前线程的CPU亲和力
if (sched_setaffinity(0, sizeof(cpu_set_mask), &cpu_set_mask)) {
printf("Warning: set affinity failed!\n");
} else {
// 简单的无限循环
while (1) {
// 空循环,不执行任何操作
}
}
return NULL;
}
/**
* 线程函数2 - 绑定到指定CPU核心并执行空循环
* @param arg 指向CPU核心编号的指针
* @return NULL
*/
void *thread_func2(void *arg) {
cpu_set_t cpu_set_mask; // CPU核心集合掩码
int *cpu_core_id = (int*)arg; // CPU核心ID
// 显示要绑定的CPU核心
printf("Binding thread 2 to CPU core %d\n", *cpu_core_id);
// 初始化CPU集合并设置要绑定的CPU核心
CPU_ZERO(&cpu_set_mask); // 清空CPU集合
CPU_SET(*cpu_core_id, &cpu_set_mask); // 将指定CPU核心添加到集合中
// 设置当前线程的CPU亲和力
if (sched_setaffinity(0, sizeof(cpu_set_mask), &cpu_set_mask) == -1) {
printf("Warning: set affinity failed!\n");
} else {
// 简单的无限循环
while (1) {
// 空循环,不执行任何操作
}
}
return NULL;
}
/**
* 主函数 - 创建两个线程并分别绑定到CPU核心4和5
* @return 0表示正常退出
*/
int main() {
pthread_t thread1_handle; // 线程1句柄
pthread_t thread2_handle; // 线程2句柄
int target_cpu_core_4 = 4; // 目标CPU核心4
int target_cpu_core_5 = 5; // 目标CPU核心5
// 获取系统CPU核心数量
cpu_core_count = sysconf(_SC_NPROCESSORS_CONF);
// 检查系统是否有足够的CPU核心
if (cpu_core_count <= 5) {
printf("Warning: System has only %d CPU cores, binding to CPU 4 and 5 may fail\n", cpu_core_count);
}
// 创建线程并绑定到指定CPU核心
pthread_create(&thread1_handle, NULL, (void *)thread_func1, &target_cpu_core_4);
pthread_create(&thread2_handle, NULL, (void *)thread_func2, &target_cpu_core_5);
// 等待线程结束
pthread_join(thread1_handle, NULL);
pthread_join(thread2_handle, NULL);
printf("Main thread end\n");
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
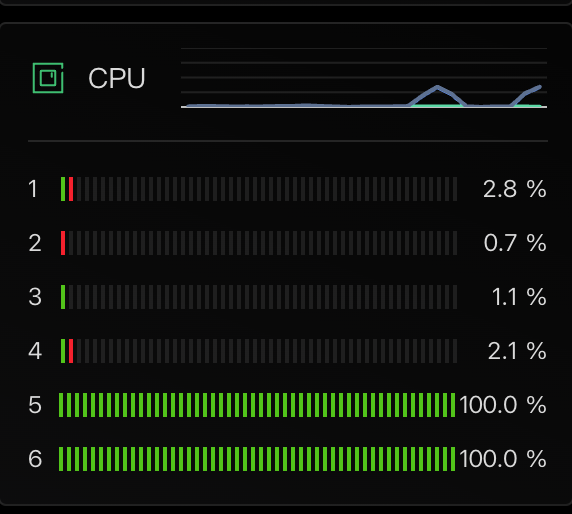
编译启动后,指定的两个cpu使用率跑满了:
当然,对应java语言也支持这一点,只是在高并发架构的今天,这种手段带来的收益远不如其他架构层面的优化,所以笔者就不多做赘述了,感兴趣的读者可以查阅这篇文章:http://www.enmalvi.com/2024/06/27/java-affinity/ (opens new window)
# 更多关于CPU缓存
# cpu缓存行是否是现代多核并行的一个条件
并非必要条件,缓存行的存在仅仅是为了减少CPU和内存的交互,通过局部性预缓存提升CPU指令执行效率。
# 一个spring boot接口,不考虑数据持久化的情况下,cpu完整执行一次接口会占用总线多少次?
按照常规的web请求,本质上都是无状态的业务执行并没有涉及任何并发临界资源竞争,如下这个get请求,可以看到本质上仅仅涉及一个全局单例对象userService的方法调用,所有的执行动作都是在方法栈内部完成,并没有涉及线程逃逸:
// 根据ID获取用户
@GetMapping("/{id}")
public ResponseEntity<User> getUserById(@PathVariable Long id) {
User user = userService.getUserById(id);
return ResponseEntity.ok(user);
}
2
3
4
5
6
理想情况下,假定我们的CPU缓存行足够大,且当前操作系统的CPU执行的都是这种读请求,因为不涉及缓存刷脏(不考虑数据库IO),我们基本可以认为锁定总线的次数为0。
# 小结
本文从计算机体系结构的发展历程作为切入点,深入介绍了CPU发展初期面临的性能瓶颈以及缓存技术的引入。基于程序执行的局部性特点,提出了局部性原理和缓存预加载思想。同时针对结构冒险问题,提出了指令和数据缓存分离的设计理念。
文章还详细阐述了多级缓存架构、缓存映射策略等核心技术,并通过实际代码示例展示了如何编写缓存友好型代码,包括合理的数据遍历顺序和条件判断优化等最佳实践。
此外,本文还介绍了多核CPU环境下通过线程绑定技术提升缓存命中率的方法,为优化程序性能提供了实用的指导。希望本文的内容能帮助您更好地理解和应用CPU缓存技术。
我是 SharkChili ,Java 开发者,Java Guide 开源项目维护者。欢迎关注我的公众号:写代码的SharkChili,也欢迎您了解我的开源项目 mini-redis:https://github.com/shark-ctrl/mini-redis。
为方便与读者交流,现已创建读者群。关注上方公众号获取我的联系方式,添加时备注加群即可加入.
# 参考
2.3 如何写出让 CPU 跑得更快的代码?:https://xiaolincoding.com/os/1_hardware/how_to_make_cpu_run_faster.html#cpu-cache-有多快 (opens new window)
深入理解CPU的分支预测(Branch Prediction)模型:https://zhuanlan.zhihu.com/p/22469702 (opens new window)
怎样才能写出让CPU跑的更快的代码?:https://blog.csdn.net/GYHYCX/article/details/118732289 (opens new window)
计算机组成原理:结构冒险和数据冒险:https://blog.csdn.net/zhizhengguan/article/details/121259357 (opens new window)
使用 sched_setaffinity 将线程绑到CPU核上运行:https://blog.csdn.net/Z_Stand/article/details/107883684 (opens new window)
一图搞懂CPU的时钟周期、机器周期和指令周期:https://zhuanlan.zhihu.com/p/660991686 (opens new window)
如何理解时钟周期及公式CPU执行时间 = CPU时钟周期数/主频 :https://blog.csdn.net/u012076669/article/details/84452264 (opens new window)
