 深入理解synchronized同步机制
深入理解synchronized同步机制
[toc]
# 写在文章开头
synchronized关键字算是日常编程开发中较常用的线程安全关键字,本文将基于底层工作原理和日常运用的角度深入分析该关键字,希望对你有所帮助。
我是 SharkChili,Java 开发者,Java Guide开源项目维护者。欢迎关注我的公众号:写代码的SharkChili,也欢迎您了解我的开源项目 mini-redis:https://github.com/shark-ctrl/mini-redis。
为方便与读者交流,现已创建读者群。关注上方公众号获取我的联系方式,添加时备注加群即可加入。
# synchronized是什么?有什么用?
synchronized是在多线程场景经常用到的关键字,通过synchronized将共享资源设置为临界资源,确保并发场景下共享资源操作的正确性:
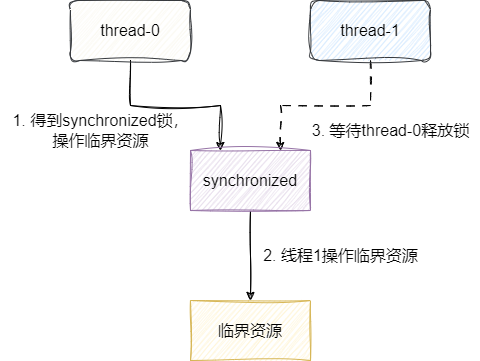
# synchronized基础使用示例
# 作用于静态方法
synchronized作用于静态方法上,锁的对象为Class,这就意味着方法的调用者无论是Class还是实例对象都可以保持互斥,所以下面这段代码的结果为200:
public class SynchronizedDemo {
private static Logger logger = LoggerFactory.getLogger(SynchronizedDemo.class);
private static int count = 0;
/**
* synchronized作用域静态类上
*/
public synchronized static void method() {
count++;
}
@Test
public void test() {
IntStream.rangeClosed(1,1_0000)
.parallel()
.forEach(i->SynchronizedDemo.method());
IntStream.rangeClosed(1,1_0000)
.parallel()
.forEach(i->new SynchronizedDemo().method());
logger.info("count:{}",count);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
输出结果
22:59:44.647 [main] INFO com.sharkChili.webTemplate.SynchronizedDemo - count:20000
2
# 作用于对象方法
作用于方法上,则锁住的对象是调用的示例对象,如果我们使用下面这段写法,最终的结果却不是10000。
private static Logger logger = LoggerFactory.getLogger(SynchronizedDemo.class);
private static int count = 0;
/**
* synchronized作用域实例方法上
*/
public synchronized void method() {
count++;
}
@Test
public void test() {
IntStream.rangeClosed(1,1_0000)
.parallel()
.forEach(i->new SynchronizedDemo().method());
logger.info("count:{}",count);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
输出结果
2023-03-16 21:03:44,300 INFO SynchronizedDemo:30 - count:8786
2
因为synchronized 作用于实例方法,会导致每个线程获得的锁都是各自使用的实例对象,而++操作又非原子操作,导致互斥失败进而导致数据错误。
什么是原子操作呢?通俗的来说就是一件事情只要一条指令就能完成,而count++在底层汇编指令如下所示,可以看到++操作实际上是需要3个步骤完成的:
- 从内存将
count读取到寄存器 count自增- 写回内存
__asm
{
moveax, dword ptr[i]
inc eax
mov dwordptr[i], eax
}
2
3
4
5
6
正是由于锁互斥的失败,导致两个线程同时到临界区域加载资源,获得的count都是0,经过自增后都是1,导致数据少了1。
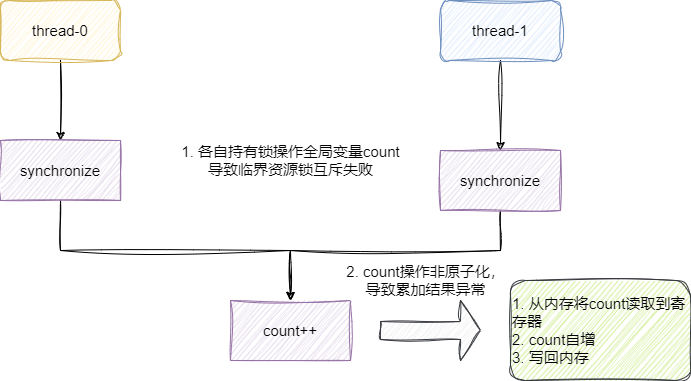
所以正确的使用方式是多个线程使用同一个对象调用该方法
SynchronizedDemo demo = new SynchronizedDemo();
IntStream.rangeClosed(1,1_0000)
.parallel()
.forEach(i->demo.method());
logger.info("count:{}",count);
2
3
4
5
6
7
这样一来输出的结果就正常了。
2023-03-16 23:08:23,656 INFO SynchronizedDemo:31 - count:10000
2
# 作用于代码块
作用于代码块上的synchronized锁住的就是括号内的对象实例,以下面这段代码为例,锁的就是当前调用者:
//锁住当前调用实例
public void method() {
synchronized (this) {
count++;
}
}
2
3
4
5
6
所以我们的使用的方式还是和作用与实例方法上一样:
SynchronizedDemo demo = new SynchronizedDemo();
IntStream.rangeClosed(1, 1_0000)
.parallel()
.forEach(i -> demo.method());
logger.info("count:{}", count);
2
3
4
5
6
7
8
9
10
输出结果也是10000
2023-03-16 23:11:08,496 INFO SynchronizedDemo:33 - count:10000
2
# 详解synchronized关键字
# synchronized是如何工作的
为了更好的讲解synchronized关键字的底层原理,我们给出一段synchronized作用于代码块上的方法:
public class SynchronizedDemo {
private static int count = 0;
/**
* synchronized作用域实例方法内
*/
public void method() {
synchronized (this) {
count++;
}
}
public static void main(String[] args) {
SynchronizedDemo demo = new SynchronizedDemo();
IntStream.rangeClosed(1, 1_0000)
.parallel()
.forEach(i -> demo.method());
System.out.println("count:" + count);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
先使用javac指令生成class文件:
javac SynchronizedDemo.java
然后再使用反编译指令javap获取反编译后的代码信息:
javap -c -s -v SynchronizedDemo.class
最终我们可以看到method方法的字节码指令,可以看到关键字synchronized 的锁是通过monitorenter和monitorexit指令来确保线程间的同步。
public void method();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=2, locals=3, args_size=1
0: aload_0
1: dup
2: astore_1
3: monitorenter
4: getstatic #2 // Field count:I
7: iconst_1
8: iadd
9: putstatic #2 // Field count:I
12: aload_1
13: monitorexit
14: goto 22
17: astore_2
18: aload_1
19: monitorexit
20: aload_2
21: athrow
22: return
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
我们再将synchronized 关键字改到方法上再次进行编译和反编译:
public synchronized void method() {
count++;
}
2
3
可以看到synchronized 实现锁的方式编程了通过ACC_SYNCHRONIZED关键字来标明该方法是一个同步方法:
public synchronized void method();
descriptor: ()V
flags: ACC_PUBLIC, ACC_SYNCHRONIZED
Code:
stack=2, locals=1, args_size=1
0: getstatic #2 // Field count:I
3: iconst_1
4: iadd
5: putstatic #2 // Field count:I
8: return
LineNumberTable:
line 17: 0
line 19: 8
2
3
4
5
6
7
8
9
10
11
12
13
了解了不同synchronized在不同位置使用的指令之后,我们再来聊聊这些指令如何实现"锁"的。
因为JDK1.6之后提出锁升级的机制,涉及不同层面的锁的过程,这里我们直接以默认情况下最高级别的重量级锁为例展开探究。
每个线程使用的实例对象都有一个对象头,每个对象头中都有一个Mark Word,当我们使用synchronized 关键字时,这个Mark Word就会指向一个monitor。
这个monitor锁就是一种同步工具,是实现线程操作临界资源互斥的关键所在,在Java HotSpot虚拟机中,monitor就是通过ObjectMonitor实现的。
其代码如下,我们可以看到_EntryList、_WaitSet 、_owner三个关键属性:
ObjectMonitor() {
_header = NULL;
_count = 0; // 记录线程获取锁的次数
_waiters = 0,
_recursions = 0; //锁的重入次数
_object = NULL;
_owner = NULL; // 指向持有ObjectMonitor对象的线程
_WaitSet = NULL; // 处于wait状态的线程,会被加入到_WaitSet
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ;//竞争队列,和_EntryList作用类似
FreeNext = NULL ;
_EntryList = NULL ; // 处于等待锁block状态的线程,会被加入到该列表
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
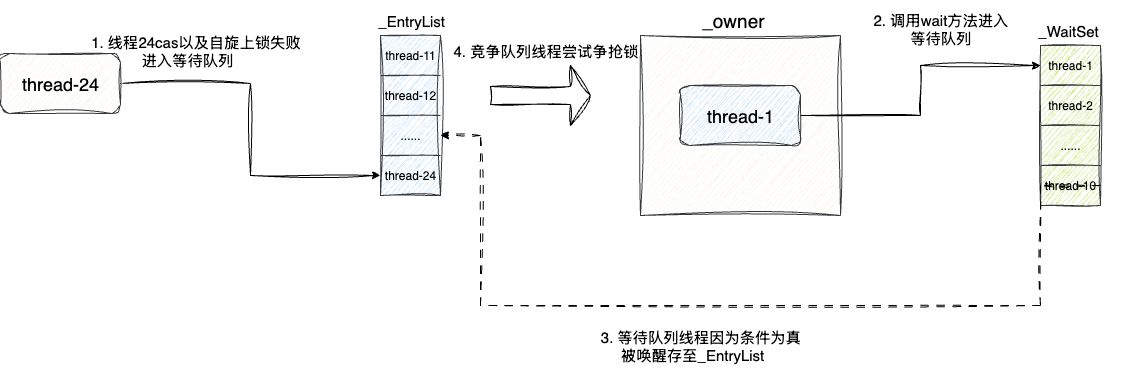
我们假设自己现在就是一个需要获取锁的线程-24,要获取ObjectMonitor锁,所以我们经过了下面几个步骤:
- 线程24发现_owner为空,尝试cas获取锁失败,进入步骤2。
- 再次自旋尝试取锁,发现
_owner还是被其他线程持有,无法获取,以头插法的方式进入_cxq队列(这里之所以采用头插法是因为新来的线程数据可能被cpu缓存,优先被唤醒处理效率高,可能造成老线程饥饿,所以不同jvm版本针对_cxq和__EntryList队列的调度策略都有所不同)。 - 线程1用完锁,将
count--变为0,释放锁,_owner被清空,jvm唤醒__EntryList中的队列(期间_cxq队列的数据可能会被合并到_EntryList),所有线程执行步骤4。 - 线程-24有机会获取
_owner,尝试cas争抢并成功获取锁,_owner指向当前线程0,将count++。 - 线程-24执行某些方法再次尝试针对当前线程上锁,执行锁重入,累加_recursions
- 因为等待某些条件,线程-24主动调用
wait方法释放锁,线程进入_WaitSet,count--变为0,_owner被清空,其他线程尝试争抢锁。 - 因为条件为真线程24被notify()唤醒,再次进入_EntryList等待时机获取锁,成功后
_owner指针再次指向线程0 - 这一次,我们用完临界资源,准备释放锁,
count--变为0,_owner清空,其他线程继续进行monitor争抢。
# synchronized如何保证可见性、有序性、可重入性
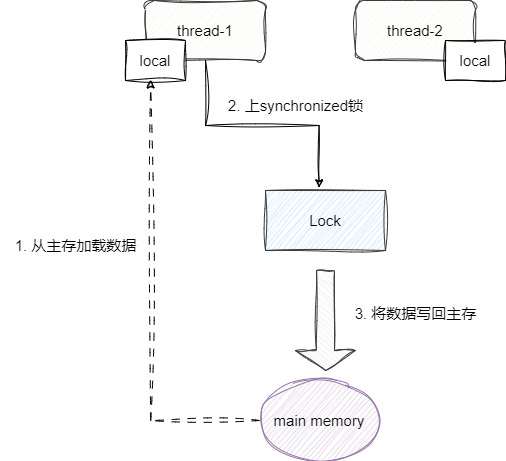
我们先来说说可见性,每个线程使用synchronized获得锁操作临界资源时,首先需要获取临界资源的值,为了保证临界资源的值是最新的,JMM模型规定线程必须将本地工作内存清空,到共享内存中加载最新的进行操作。
当前线程上锁后,其他线程是无法操作这个临界资源的。当前线程操作完临界资源之后,会立刻将值写回主存中,正是由于每个线程操作期间其他线程无法干扰,且临界资源数据实时同步,所以synchronized关键字保证了临界资源数据的可见性。
再来说说有序性,synchronized同步的代码块具备排他性,这就意味着同一个时刻只有一个线程可以获得锁,synchronized代码块的内部资源是单线程执行的。同时synchronized也遵守as-if-serial原则,可以当线程线程修改最终结果是可以保证最终有序性,注意这里笔者说的保证最终结果的有序性。
具体例子,某段线程得到锁Test.class之后,执行临界代码逻辑,可能会先执行变量b初始化的逻辑,在执行a变量初始化的逻辑,但是最终结果都会执行a+b的逻辑。这也就我们的说的保证最终结果的有序,而不保证执行过程中的指令有序。
synchronized (Test.class) {
int a=1;
int b=2;
int c=a+b;
}
2
3
4
5
这一点,我们在上文中已经说明了,synchronized底层的维护着一个monitor对象会通过_count维护当前线程重入次数,即同一个线程连续获取锁之后,这个_count都会累加,当_count变为0时,其他线程才能争抢这把锁。
# 详解synchronized锁粗化和锁消除
# JIT阶段下的锁粗化
当jvm发现操作的方法连续对同一把锁进行加锁、解锁操作,就会对锁进行粗化,所有操作都在同一把锁中完成:

如下代码所示,该方法内部连续3次上同一把锁,存在频繁上锁执行monitorenter和monitorexit的开销:
private static void func1() {
synchronized (lock) {
System.out.println("lock first");
}
synchronized (lock) {
System.out.println("lock second");
}
synchronized (lock) {
System.out.println("lock third");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
这一点我们通过jclasslib查看字节码即可知晓这一点:

对此JIT编译器一旦感知到这种一个操作频繁加解同一把锁的情况,便会将锁进行粗化,最终的代码效果大概是这样:
private static void func1() {
synchronized (lock) {
System.out.println("lock first");
System.out.println("lock second");
System.out.println("lock third");
}
}
2
3
4
5
6
7
8
9
# 逃逸分析下的锁消除
虚拟机在JIT即时编译运行时,对一些代码上要求同步,但是检测到不存在共享数据的锁的进行消除。
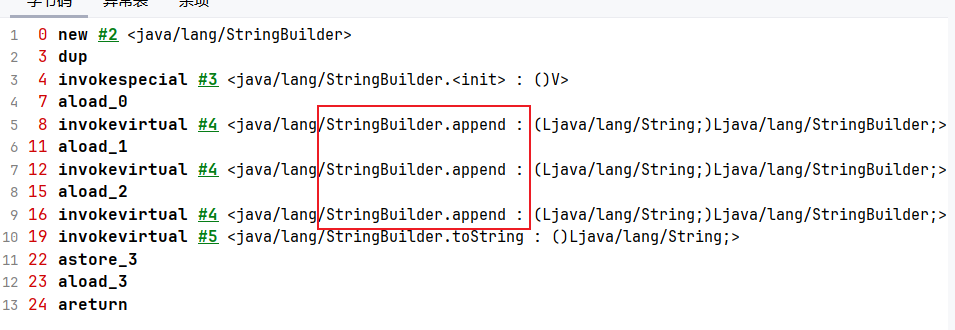
下面这段代码涉及字符串拼接操作,所以jvm会将其优化为StringBuffer或者StringBuilder,至于选哪个,这就需要进行逃逸分析了。逃逸分析通俗来说就是判断当前操作的对象是否会逃逸出去被其他线程访问到。
public String appendStr(String str1, String str2, String str3) {
String result = str1 + str2 + str3;
return result;
}
2
3
4
例如我们上面的result ,是局部变量,没有发生逃逸,所以完全可以当作栈上数据来对待,是线程安全的,所以jvm进行锁消除,使用StringBuilder而不是Stringbuffer完成字符串拼接:
这一点我们可以在字节码文件中得到印证
关于逃逸分析可以可以参考笔者的这篇文章: 聊点硬核的逃逸分析技术:https://mp.weixin.qq.com/s?__biz=MzkwODYyNTM2MQ==&mid=2247483845&idx=1&sn=8b199b7a3456c3c3c3cc75054d5d976b&chksm=c0c6557bf7b1dc6d54bc2f09c99892eadc8f19c558de1a3c83ddb05044a4731322c25097b80d#rd (opens new window)
# 详解synchronized中的锁升级
# 详解锁升级过程
synchronized关键字在JDK1.6之前底层都是直接调用ObjectMonitor的enter和exit完成对操作系统级别的重量级锁mutex的使用,这使得每次上锁都需要从用户态转内核态尝试获取重量级锁的过程。
这种方式也不是不妥当,在并发度较高的场景下,取不到mutex的线程会因此直接阻塞,到等待队列_WaitSet 中等待唤醒,而不是原地自选等待其他线程释放锁而立刻去争抢,从而避免没必要的线程原地自选等待导致的CPU开销,这也就是我们上文中讲到的synchronized工作原理的过程。
但是在并发度较低的场景下,可能就10个线程,竞争并不激烈可能线程等那么几毫秒就可以拿到锁了,而我们每个线程却还是需要不断从用户态到内核态获取重量级锁、到_WaitSet 中等待机会的过程,这种情况下,可能功能的开销还不如所竞争的开销来得激烈。
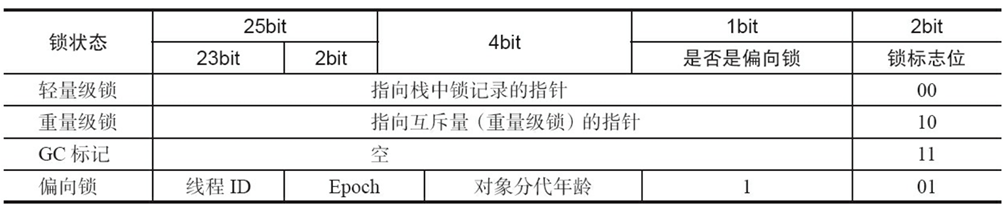
所以JDK1.6之后,HotSpot虚拟机就对synchronized底层做了一定的优化,通俗来说根据线程竞争的激烈程度的不断增加逐步进行锁升级的策略。对应的我们先给出32位虚拟机中不同级别的锁在对象头mark word中的标识变化:
我们假设有这样一个场景,我们有一个锁对象LockObj,我们希望用它作为锁,使用代码逻辑如下所示:
synchronized(LockObj){
//dosomething
}
2
3
4
5
6
我们把自己当作一个线程,一开始没有线程竞争时,synchronized锁就是无锁状态,无需进行任何锁争抢的逻辑。此时锁对象LockObj的偏向锁标志位为0,锁标记为01。
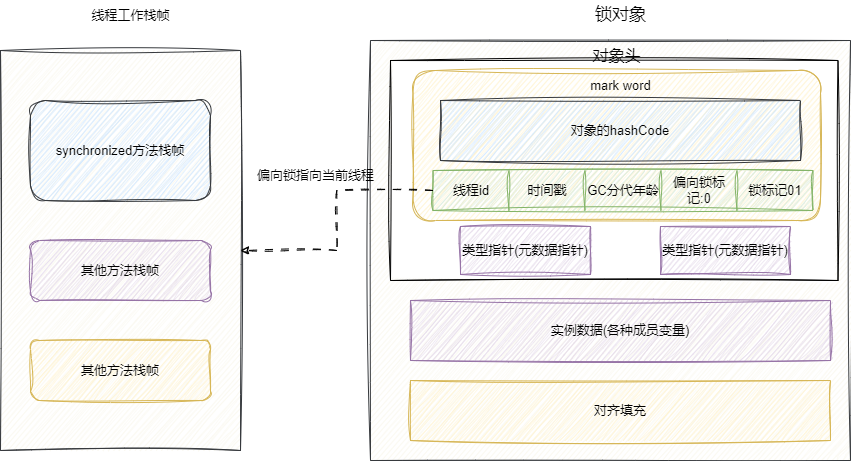
后续线程1需要尝试执行该语句块,首先通过CAS修改mark word中的信息,即锁的对象LockObj的对象头偏向锁标记为1,锁标记为01,我们的线程开始尝试获取这把锁,并将线程id就当前线程号即可。
后续线程1操作锁时,只需比较一下mark word中的锁是否是偏向锁且线程id是否是线程1即可:
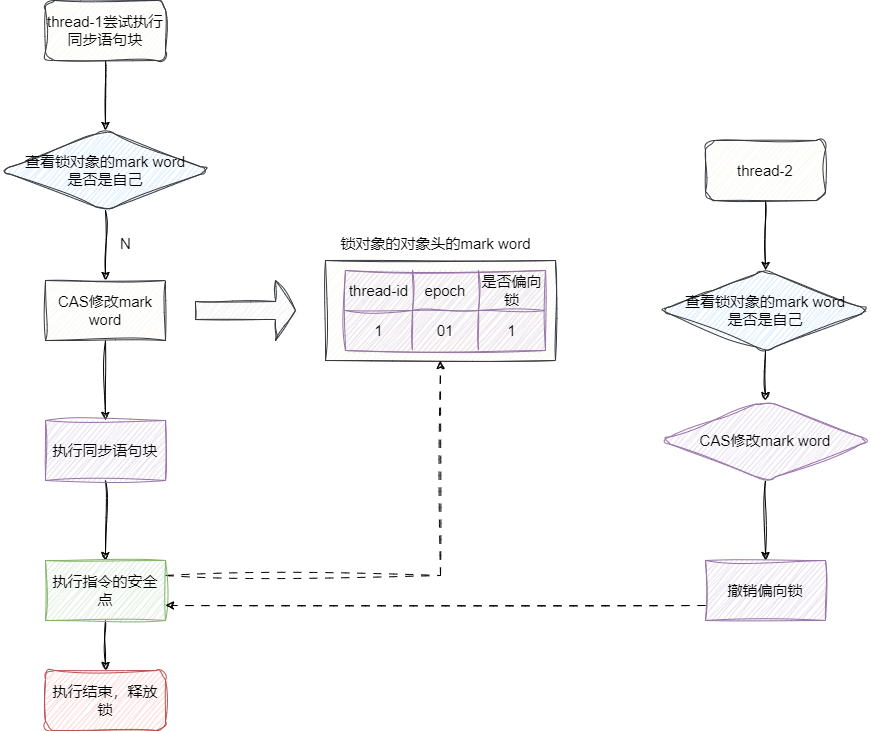
当我们发现偏向锁中指向的线程id不是我们时,就执行下面的逻辑:
- 我们尝试
CAS竞争这把锁,如果成功则将锁对象的markdown中的线程id设置为我们的线程id,然后执行代码逻辑。 - 我们尝试
CAS竞争这把锁失败,则当持有锁的线程到达安全点的时候,直接将这个线程挂起并执行锁撤销,将偏向锁升级为轻量级锁,然后持有锁的线程继续自己的逻辑,我们的线程继续等待机会。
可能很多读者对于安全点的概念不是很了解,感兴趣的读者可以移步阅读一下笔者的这篇文章:
来聊聊JVM中安全点的概念 (opens new window)
升级为轻量级锁时,偏向锁标记为0,锁标记变为是00。此时,如果我们的线程需要获取这个轻量级锁时的过程如下:
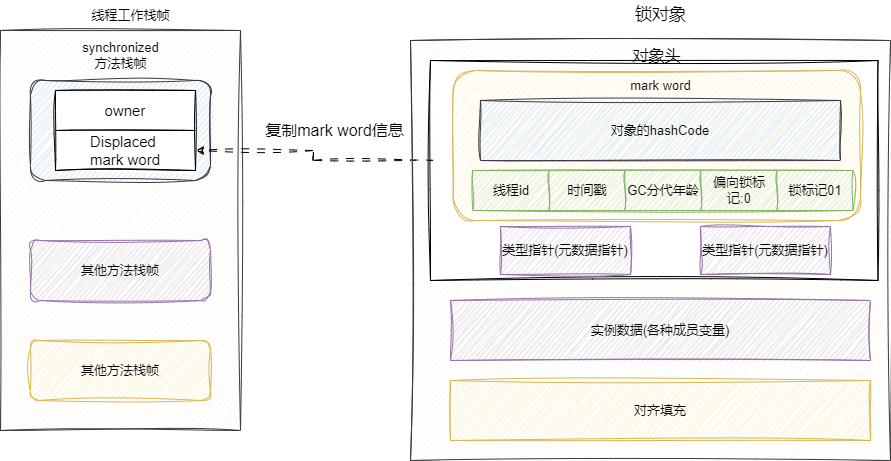
- 判断当前这把锁是否为轻量级锁,如果是则在线程栈帧中划出一块空间,存放这把锁的信息,我们这里就把它称为"锁记录",并将锁对象的
markword复制到锁记录中。
- 复制成功之后,通过
CAS的方式尝试将锁对象头中markword更新为锁记录的地址,并将owner指向锁对象头的markword。如果这几个步骤操作成功,则说明获取轻量级锁成功了。
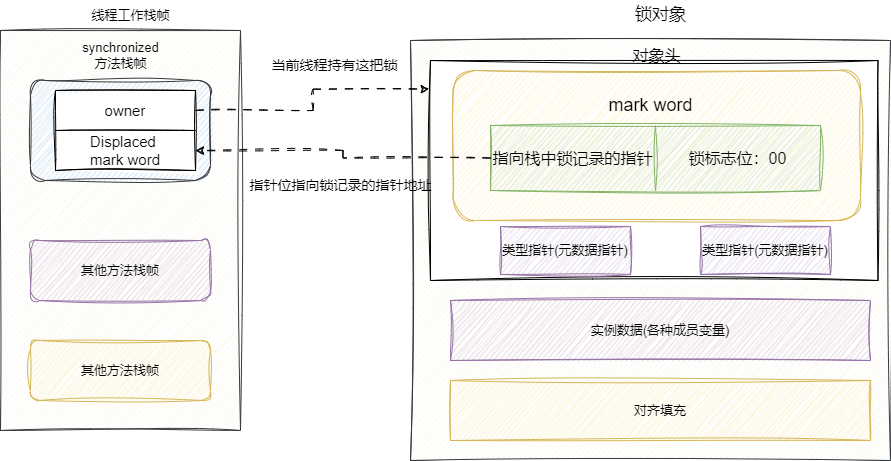
- 如果线程
CAS操作失败,则进行自旋获取锁,如果自旋超过10次(默认设置为10次)还没有得到锁则将锁升级为重量级锁,升级为重量级锁时,锁标记为0,锁状态为10。由此导致持有锁的线程进行释放时需要CAS修改mark word信息失败,发现锁已经被其他线程膨胀为重量级锁,对应释放操作改为将指针地址置空,然后唤醒其他等待的线程尝试获取锁。
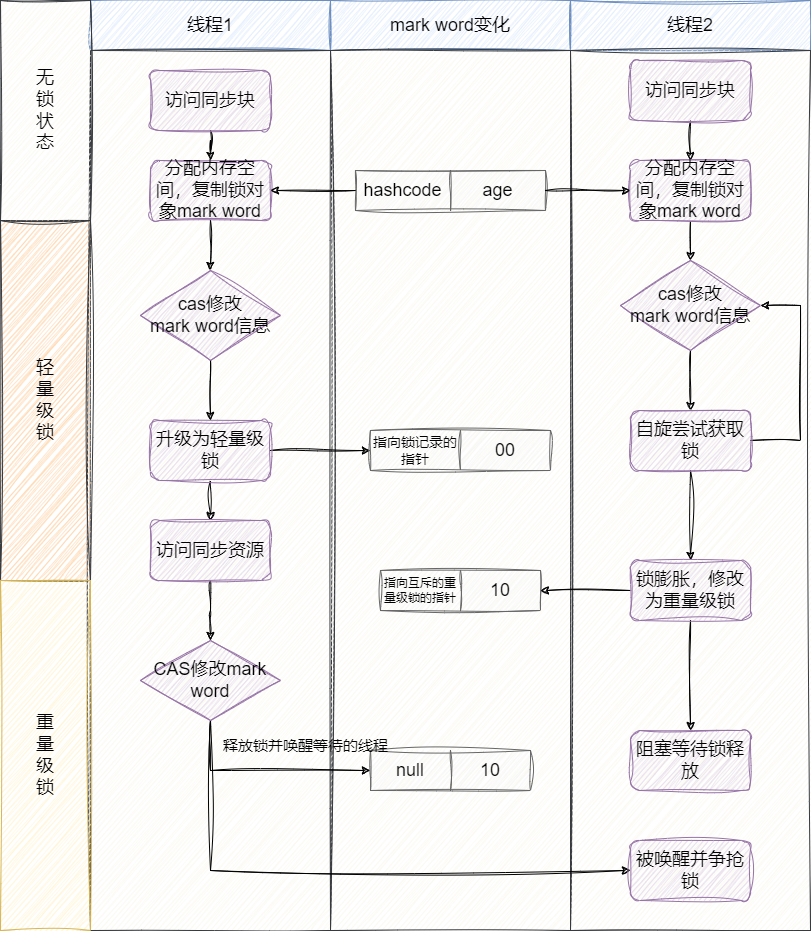
经过上述的讲解我们对锁升级有了一个全流程的认识,在这里做个阶段小结:
- 无线程竞争,无锁状态:偏向锁标记为0,锁标记为01。
- 存在一定线程竞争,大部分情况下会是同一个线程获取到,升级为偏向锁,偏向标记为1,锁标记为01。
- 线程CAS争抢偏向锁锁失败,锁升级为轻量级锁,偏向标记为0,锁标记为00。
- 线程原地自旋超过10次还未取得轻量级锁,锁升级为重量级锁,避免大量线程原地自旋造成没必要的CPU开销,偏向锁标记为0,锁标记为10。
# 基于jol-core代码印证
上文我们将自己当作一个线程了解完一次锁升级的流程,口说无凭,所以我们通过可以通过代码来印证我们的描述。
上文讲解锁升级的之后,我们一直在说对象头的概念,所以为了能够直观的看到锁对象中对象头锁标记和锁状态的变化,我们这里引入一个jol工具。
<!--jol内存分析工具-->
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.9</version>
</dependency>
2
3
4
5
6
然后我们声明一下锁对象作为实验对象。
public class Lock {
private int count;
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
}
2
3
4
5
6
7
8
9
10
11
12
首先是无锁状态的代码示例,很简单,没有任何线程争抢逻辑,就通过jol工具打印锁对象信息即可。
public class Lockless {
public static void main(String[] args) {
Lock object=new Lock();
System.out.println(ClassLayout.parseInstance(object).toPrintable());
}
}
2
3
4
5
6
7
打印结果如下,我们只需关注第一行的object header,可以看到第一列的00000001,我们看到后3位为001,偏向锁标记为0,锁标记为01,001这就是我们说的无锁状态。
com.zsy.lock.lockUpgrade.Lock object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 43 c1 00 20 (01000011 11000001 00000000 00100000) (536920387)
12 4 int Lock.count 0
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
2
3
4
5
6
7
8
接下来是偏向锁,我们还是用同样的代码即可,需要注意的是偏向锁必须在jvm启动后的一段时间才会运行,所以如果我们想打印偏向锁必须让线程休眠那么几秒,这里笔者就偷懒了一下,通过设置jvm参数-XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=0,通过禁止偏向锁延迟,直接打印出偏向锁信息
public class BiasLock {
public static void main(String[] args) {
Lock object = new Lock();
System.out.println(ClassLayout.parseInstance(object).toPrintable());
}
}
2
3
4
5
6
7
8
输出结果如下,可以看到对象头的信息为00000101,此时锁标记为1即偏向锁标记,锁标记为01,101即偏向锁。
com.zsy.lock.lockUpgrade.Lock object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 00 00 00 (00000101 00000000 00000000 00000000) (5)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 43 c1 00 20 (01000011 11000001 00000000 00100000) (536920387)
12 4 int Lock.count 0
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
2
3
4
5
6
7
8
然后的轻量级锁的印证,我们只需使用Lock对象作为锁即可。
public class LightweightLock {
public static void main(String[] args) {
Lock object = new Lock();
synchronized (object) {
System.out.println(ClassLayout.parseInstance(object).toPrintable());
}
}
}
2
3
4
5
6
7
8
9
可以看到轻量级锁锁标记为0,锁标记为00,000即轻量级。
com.zsy.lock.lockUpgrade.Lock object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) e8 f1 96 02 (11101000 11110001 10010110 00000010) (43446760)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 43 c1 00 20 (01000011 11000001 00000000 00100000) (536920387)
12 4 int Lock.count 0
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
2
3
4
5
6
7
8
最后就是重量级锁了,我们只需打印出锁对象的哈希码即可将其升级为重量级锁。
public class HeavyweightLock {
public static void main(String[] args) {
Lock object = new Lock();
synchronized (object) {
System.out.println(object.hashCode());
}
synchronized (object) {
System.out.println(ClassLayout.parseInstance(object).toPrintable());
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
输出结果为10001010,偏向锁标记为0,锁标记为10,010为重量级锁。
1365202186
com.zsy.lock.lockUpgrade.Lock object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 8a 15 83 17 (10001010 00010101 10000011 00010111) (394466698)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 43 c1 00 20 (01000011 11000001 00000000 00100000) (536920387)
12 4 int Lock.count 0
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
2
3
4
5
6
7
8
9
# 更多关于jol-core
jol不仅仅可以监控Java进程的锁情况,在某些场景下,我们希望通过比较对象的地址来判断当前创建的实例是否是多例,是否存在线程安全问题。此时,我们就可以VM对象的方法获取对象地址,如下所示:
public static void main(String[] args) throws Exception {
//打印字符串aa的地址
System.out.println(VM.current().addressOf("aa"));
}
2
3
4
5
6
# synchronized常见面试题
# synchronized和ReentrantLock的区别
我们可以从三个角度来了解两者的区别:
- 从实现角度:
synchronized是JVM层面实现的锁,ReentrantLock是属于Java API层面实现的锁,所以用起来需要我们手动上锁lock和释放锁unlock。 - 从性能角度:在JDK1.6之前可能
ReentrantLock性能更好,在JDK1.6之后由于JVM对synchronized增加适应性自旋锁、锁消除等策略的优化使得synchronized和ReentrantLock性能并无太大的区别。 - 从功能角度:
ReentrantLock相比于synchronized增加了更多的高级功能,例如等待可中断、公平锁、选择性通知等功能。
# Spring上的一个单例对象,两个方法上用synchronized锁,两个线程调用,会发生阻塞吗?
答案是会的,我们不妨做个实验,首先给出一个单例bean并加上synchronized关键字:
@Service
@Slf4j
public class TestService {
public synchronized void method1() {
log.info("method1");
ThreadUtil.sleep(1, TimeUnit.DAYS);
}
public synchronized void method2() {
log.info("method2");
ThreadUtil.sleep(1, TimeUnit.DAYS);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
然后我们给出调用单例方法的示例:
CountDownLatch latch = new CountDownLatch(2);
//拿到单例bean
TestService testService = SpringUtil.getBean(TestService.class);
new Thread(() -> {
//调用单例bean的方法1
testService.method1();
latch.countDown();
}).start();
new Thread(() -> {
//调用单例bean的方法2
testService.method2();
latch.countDown();
}).start();
latch.await();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
可以看到线程1完成调用之后,线程2阻塞不输出:
2025-02-25 12:26:16.842 INFO 15248 --- [ Thread-1] com.sharkChili.TestService : method1
这个问题也很好解释,方法上修饰synchronized关键字,锁的对象就是当前实例,因为我们的bean是单例的,所以两个线程需要上的锁都是这个对象的实例底层的monitor对象,这就是为什么一个线程调用方法休眠后,另一个线程阻塞了:
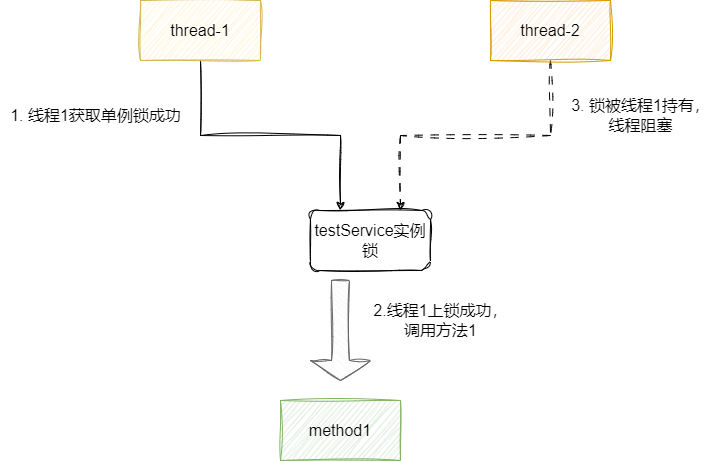
# 小结
我是 sharkchili ,CSDN Java 领域博客专家,mini-redis的作者,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
# 参考文献
关键字: synchronized详解:https://www.pdai.tech/md/java/thread/java-thread-x-key-synchronized.html#synchronized原理分析 (opens new window)
面渣逆袭(Java并发编程面试题八股文)必看👍 | Java程序员进阶之路 (tobebetterjavaer.com):https://tobebetterjavaer.com/sidebar/sanfene/javathread.html#_25-synchronized的实现原理 (opens new window)
内置锁(ObjectMonitor) :https://www.cnblogs.com/hongdada/p/14513036.html (opens new window)
【原理】【Java并发】【synchronized】适合中学者体质的synchronized原理:https://developer.aliyun.com/article/1656898 (opens new window)
