 redis集群中如何处理非本节点的slot
redis集群中如何处理非本节点的slot
# 写在文章开头
我们都知道redis集群有16384个槽,它会因为我们集群个数配置的不同而分配不同的slot给各个节点,而这篇文章就来聊聊当某个节点处理到非它所负责的slot时是如何处理的,这一点很好的体现了redis对于raft协议良好的设计与实现。
Hi,我是 sharkChili ,是个不断在硬核技术上作死的技术人,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
# 详解redis集群指令处理
# 整体流程
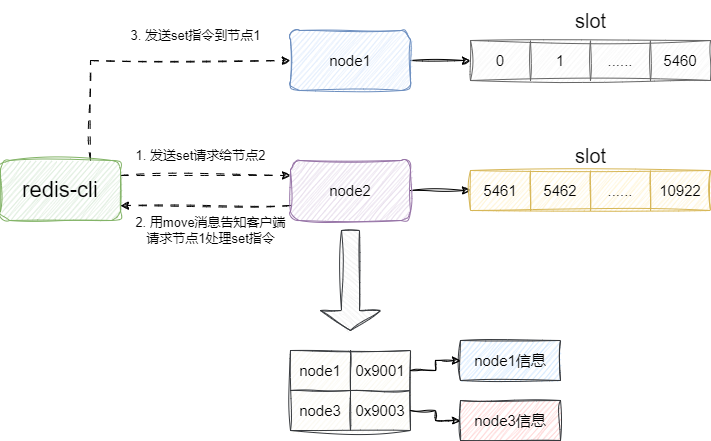
假设我们现在集群中有个节点,每个节点各自负责一部分槽,此时我们的客户端向节点2发起一个set指令,而该指令对应的key应该是要存放到节点1中,对此节点2的做法是查看自己所维护的节点列表是否有负责该slot的节点,如果发现了而回复给客户端move指令,告知客户端到指令的ip端口的节点进行键值对存储:
了解完整体流程之后,我们通过源码的方式来印证这些实现上的细节,我们都知道redis客户端发送的指令都会被redis的processCommand处理,该函数如果发现当前是以集群的方式启动并且符合以下两个条件则以集群的逻辑解析这条指令:
- 发送指令的不是
master服务器。 - 参数中带有
key。
那么redis就会调用getNodeByQuery查询重定向的节点,如果发现查询到的节点不是自己或者为空则调用clusterRedirectClient进行重定向处理:
int processCommand(redisClient *c) {
//......
//如果开启了集群,且发送者不是master且参数带key则步入逻辑
if (server.cluster_enabled &&
!(c->flags & REDIS_MASTER) &&
!(c->flags & REDIS_LUA_CLIENT &&
server.lua_caller->flags & REDIS_MASTER) &&
!(c->cmd->getkeys_proc == NULL && c->cmd->firstkey == 0))
{
int hashslot;
if (server.cluster->state != REDIS_CLUSTER_OK) {
//......
} else {
int error_code;
//查找可以处理的节点
clusterNode *n = getNodeByQuery(c,c->cmd,c->argv,c->argc,&hashslot,&error_code);
//如果为空且或者非自己,则调用clusterRedirectClient进行重定向
if (n == NULL || n != server.cluster->myself) {
flagTransaction(c);
clusterRedirectClient(c,n,hashslot,error_code);
return REDIS_OK;
}
}
}
//......
//处理当前请求指令并返回
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 详解节点定位步骤getNodeByQuery
步入getNodeByQuery即可看到查询的核心流程,无论是单条还是多条客户端指令,他都会封装成multiState结构体交由后续逻辑处理,而后续逻辑就会遍历这些指令并计算出对应的slot,然后执行如下逻辑:
- 如果发现定位到的节点是自己,且当前节点正在做迁移,则做个迁移标记,然后检查当前节点是否有这个槽,如果没有则发送
ASK指令告知客户端重定向到另一个迁移的目标槽试试看。 - 如果对应的
key没有找到对应的槽,则直接返回当前节点。 - 找到目标槽,直接返回
MOVE指令和目标槽的信息。
对应我们给出getNodeByQuery的核心代码段:
clusterNode *getNodeByQuery(redisClient *c, struct redisCommand *cmd, robj **argv, int argc, int *hashslot, int *error_code) {
//......
//如果是exec命令则用客户端的multiState封装这些命令
if (cmd->proc == execCommand) {
/* If REDIS_MULTI flag is not set EXEC is just going to return an
* error. */
if (!(c->flags & REDIS_MULTI)) return myself;
ms = &c->mstate;
} else {
//如果不是exec则自己创建一个multiState封装这单条指令保证后续逻辑一致
ms = &_ms;
_ms.commands = &mc;
//命令个数1
_ms.count = 1;
//命令参数
mc.argv = argv;
//命令参数个数
mc.argc = argc;
//对应的命令
mc.cmd = cmd;
}
//遍历multiState中的命令
for (i = 0; i < ms->count; i++) {
struct redisCommand *mcmd;
robj **margv;
int margc, *keyindex, numkeys, j;
//解析出命令、参数个数、参数
mcmd = ms->commands[i].cmd;
margc = ms->commands[i].argc;
margv = ms->commands[i].argv;
//解析出key以及个数
keyindex = getKeysFromCommand(mcmd,margv,margc,&numkeys);
for (j = 0; j < numkeys; j++) {
//拿到key
robj *thiskey = margv[keyindex[j]];
//计算slot
int thisslot = keyHashSlot((char*)thiskey->ptr,
sdslen(thiskey->ptr));
if (firstkey == NULL) {
firstkey = thiskey;
slot = thisslot;
//拿着计算的slot定位到对应的节点
n = server.cluster->slots[slot];
//如果定位到的节点就是当前节点正在做迁出或者迁入,则migrating_slot/importing_slot设置为1
if (n == myself &&
server.cluster->migrating_slots_to[slot] != NULL)
{
migrating_slot = 1;
} else if (server.cluster->importing_slots_from[slot] != NULL) {
importing_slot = 1;
}
} else {
//......
}
//如果正在做迁出或者嵌入,且当前找不到当前db找不到key的位置,则missing_keys++意为某个key可能正在被迁移中所以没有命中
if ((migrating_slot || importing_slot) &&
lookupKeyRead(&server.db[0],thiskey) == NULL)
{
missing_keys++;
}
}
getKeysFreeResult(keyindex);
}
//所有key都没有对应节点,直接返回当前节点
if (n == NULL) return myself;
//......
//正在迁出且这个key在当前节点没有被命中,则将error_code设置为ask,并返回迁出的节点信息,告知客户端到返回节点尝试指令
if (migrating_slot && missing_keys) {
if (error_code) *error_code = REDIS_CLUSTER_REDIR_ASK;
return server.cluster->migrating_slots_to[slot];
}
//......
//返回其他节点,error_code设置为move
if (n != myself && error_code) *error_code = REDIS_CLUSTER_REDIR_MOVED;
return n;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
# 结果告知客户端
上述流程发现处理的节点不是自己之后,调用clusterRedirectClient进行重定向,如果是REDIS_CLUSTER_REDIR_MOVED则告知客户端这些slot后续直接找重定向节点处理就好了,后续无需找自己。若是REDIS_CLUSTER_REDIR_ASK则说明当前节点正处于数据迁移到目标节点,你可以到迁移的节点进行请求,后续再次发起请求是还是找当前节点看看能否出去,如果不能在进行重定向:
void clusterRedirectClient(redisClient *c, clusterNode *n, int hashslot, int error_code) {
//......
if(......){
//......
} else if (error_code == REDIS_CLUSTER_REDIR_MOVED ||
error_code == REDIS_CLUSTER_REDIR_ASK)
{
//返回move命令告知要移动到的节点后续直接到move的,如果是ask则返回正在迁往的节点地址,是临时措施,下次客户端还会找当前节点
addReplySds(c,sdscatprintf(sdsempty(),
"-%s %d %s:%d\r\n",
(error_code == REDIS_CLUSTER_REDIR_ASK) ? "ASK" : "MOVED",
hashslot,n->ip,n->port));
} else {
redisPanic("getNodeByQuery() unknown error.");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 小结
这篇文章比较精简,我们通过源码的方式简单的剖析了去中心化的redis如何在不同节点处理不同槽的请求,大体过程比较简单:
- 接收并处理客户端传入的
key指令操作。 - 通过
getNodeByQuery获取key对应的slot所属节点。 - 如果是当前节点的slot直接处理。
- 如果不是则查看是否正在迁出,如果是则返回
ask让客户端到别的节点试试看,反之进入步骤5。 - 如果定位的
slot对应的节点是别的节点则直接用move指令重定向客户端,让客户端到另一个节点询问结果。
我是 sharkchili ,CSDN Java 领域博客专家,mini-redis的作者,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
# 参考
《Redis设计与实现》 Redis-集群搭建:https://blog.csdn.net/weixin_44642403/article/details/118885921 (opens new window)
redis ASK 和 MOVED 的区别 :https://blog.csdn.net/qinxinhe7/article/details/136160514 (opens new window)
# 参考
《Redis设计与实现》 Redis-集群搭建:https://blog.csdn.net/weixin_44642403/article/details/118885921 (opens new window)
redis ASK 和 MOVED 的区别 :https://blog.csdn.net/qinxinhe7/article/details/136160514 (opens new window)
