 JVM内存问题排错最佳实践
JVM内存问题排错最佳实践
# 写在文章开头
上一篇的文章中分享了一个入门级别的调优实践,收到很多读者的好评,所以笔者今天再次分享一个进阶一点的案例,希望对近期在面试的读者对于JVM调优经验这一块的回答有所帮助。
Hi,我是 sharkChili ,是个不断在硬核技术上作死的 java coder ,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。

# 场景说明
先来说说本次案例的问题场景,我们都知道MySQL数据库的数据在单表数据量达到2000w的时候查询性能表现是非常差劲的。所以为了提升对于单表数据汇总查询的效率,很多团队都采用数据收敛的方式将大数据表的数据统计后迁移到另外一张统计表中。

而笔者本次分享的案例也是类似,当前有一张案例表batch_insert_test,其DDL语句如下,可以看到这张表的主键的int类型,其余字段都是字符串或日期类型,极端情况下一条数据大约1k左右:
CREATE TABLE `batch_insert_test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`fileid_1` varchar(100) DEFAULT NULL,
`fileid_2` varchar(100) DEFAULT NULL,
`fileid_3` varchar(100) DEFAULT NULL,
`fileid_4` varchar(100) DEFAULT NULL,
`fileid_5` varchar(100) DEFAULT NULL,
`fileid_6` varchar(100) DEFAULT NULL,
`fileid_7` varchar(100) DEFAULT NULL,
`fileid_8` varchar(100) DEFAULT NULL,
`fileid_9` varchar(100) DEFAULT NULL,
`create_date` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `batch_insert_test_create_date_IDX` (`create_date`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=10094926 DEFAULT CHARSET=utf8 COMMENT='测试批量插入,一行数据1k左右';
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
当前的需求会将上述数据表的数据按照某个业务规则进行汇总采集,然后存入batch_insert_test_bak,可以看到这张表除了表名以外,字段和上表是一致的。
CREATE TABLE `batch_insert_test_bak` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`fileid_1` varchar(100) DEFAULT NULL,
`fileid_2` varchar(100) DEFAULT NULL,
`fileid_3` varchar(100) DEFAULT NULL,
`fileid_4` varchar(100) DEFAULT NULL,
`fileid_5` varchar(100) DEFAULT NULL,
`fileid_6` varchar(100) DEFAULT NULL,
`fileid_7` varchar(100) DEFAULT NULL,
`fileid_8` varchar(100) DEFAULT NULL,
`fileid_9` varchar(100) DEFAULT NULL,
`create_date` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=9329929 DEFAULT CHARSET=utf8 COMMENT='测试批量插入,一行数据1k左右';
2
3
4
5
6
7
8
9
10
11
12
13
14
# 问题复现
基于上述表,我们给出本次案例的问题代码,可以看到这段代码通过JdbcTemplate 查询出10w条数据,然后为了适配JdbcTemplate 批处理的入参格式,将10w条数据通过流计算强转为List数组再进行插入操作:
JdbcTemplate jdbcTemplate = new JdbcTemplate(SpringUtil.getBean(DataSource.class));
//模拟汇总查询出10w条数据
List<Map<String, Object>> list = jdbcTemplate.queryForList("select * from batch_insert_test LIMIT 100000 ");
log.info("list size:{}", list.size());
//转为list数组
List<Object[]> objects = list.stream().map(d -> {
Object[] arr = new Object[10];
arr[0] = d.get("fileid_1");
arr[1] = d.get("fileid_2");
arr[2] = d.get("fileid_3");
arr[3] = d.get("fileid_4");
arr[4] = d.get("fileid_5");
arr[5] = d.get("fileid_6");
arr[6] = d.get("fileid_7");
arr[7] = d.get("fileid_8");
arr[8] = d.get("fileid_9");
arr[9] = d.get("create_date");
return arr;
}).collect(Collectors.toList());
//使用jdbcTemplate批处理进行批量插入操作
jdbcTemplate.batchUpdate("INSERT INTO batch_insert_test_bak (id, fileid_1, fileid_2, fileid_3, fileid_4, fileid_5, fileid_6, fileid_7, fileid_8, fileid_9, create_date)" +
" VALUES(null , ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)", objects);
log.info("迁移完成");
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
为了模拟出更实际的场景,我们通过下述指令调整堆内存以及在内存溢出时打印内存快照:
-Xms512m -Xmx512m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=F:\tmp\heapdump.hprof
随后我们将这个程序启动,毫无疑问抛出OOM异常:
java.lang.OutOfMemoryError: Java heap space
Dumping heap to F:\tmp\heapdump.hprof ...
Heap dump file created [324233414 bytes in 0.907 secs]
2
3
# 排查过程
上述指令我们将内存快照存放到了F:\tmp\下,所以我们通过mat打开这个文件,可以看到大量的内存被HashMap相关的对象实例所占用:
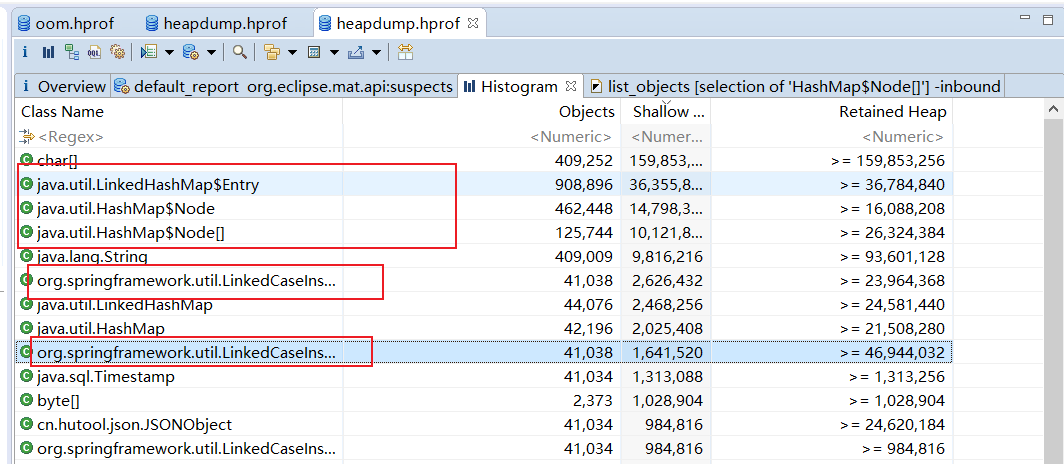
通过mat我们定位到了其外部引用,很明显这些Map就是在我们的jdbcTemplate的queryForList查询结果转换过程中出现的。
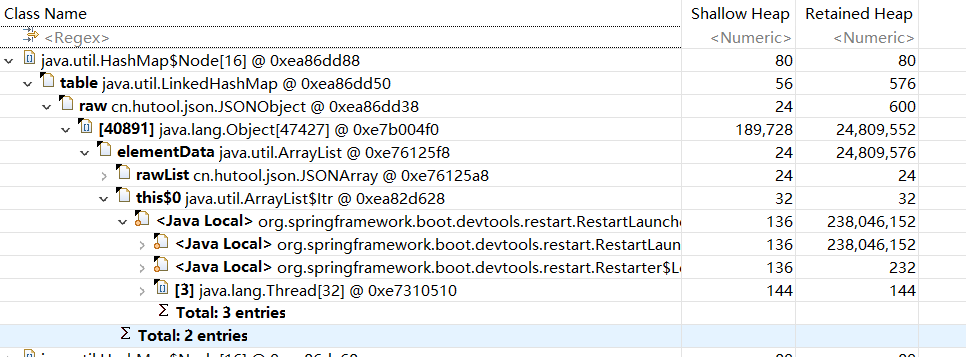
对此笔者通过对源码进行断点调试发现,jdbcTemplate的queryForList会将采集结果存入一个LinkedCaseInsensitiveMap,这个集合结构会将查询结果的字段作为key,值作为value构成HashMap的每一个Entry,从集合的名字也不难看出,这个集合为了保证遍历的有序性,还专门为这个Map维护一条链表。
正是因为这样一个为了保证数据散列均摊且还能顺序遍历的数据结构,导致仅仅10w条的数据占用了大量的内存,从而导致了OOM。
# 逐步优化
# 对于查询内存溢出的优化
了解了问题的原因之后,我们就可以进行解决和优化了,既然上述问题是因为jdbcTemplate查询结果的映射出问题,那我们将查询映射转换换成转为专门的Java对象并将其存入更加精简的ArrayList即可,所以笔者将查询的工作交给Mybatis:
JdbcTemplate jdbcTemplate = new JdbcTemplate(SpringUtil.getBean(DataSource.class));
PageHelper.startPage(1, 10_0000, false);
BatchInsertTestMapper testMapper = SpringUtil.getBean(BatchInsertTestMapper.class);
List<BatchInsertTest> list = testMapper.selectByExample(null);
log.info("查询结束,size:{}", list.size());
List<Object[]> objects = list.stream().map(d -> {
Object[] arr = new Object[10];
arr[0] = d.getFileid1();
arr[1] = d.getFileid2();
arr[2] = d.getFileid3();
arr[3] = d.getFileid4();
arr[4] = d.getFileid5();
arr[5] = d.getFileid6();
arr[6] = d.getFileid7();
arr[7] = d.getFileid8();
arr[8] = d.getFileid9();
arr[9] = d.getCreateDate();
return arr;
}).collect(Collectors.toList());
log.info("插入开始");
long begin = System.currentTimeMillis();
jdbcTemplate.batchUpdate("INSERT INTO batch_insert_test_bak (id, fileid_1, fileid_2, fileid_3, fileid_4, fileid_5, fileid_6, fileid_7, fileid_8, fileid_9, create_date)" +
" VALUES(null , ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)", objects);
long end = System.currentTimeMillis();
log.info("插入完成,总耗时:{}", end - begin);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
随后我们再次运行,可以看到查询结果正常返回了,但是在插入之前还是报了OOM:
2024-03-10 01:26:41.489 INFO 18168 --- [ restartedMain] com.sharkChili.OOMApplication : 插入开始
java.lang.OutOfMemoryError: GC overhead limit exceeded
Dumping heap to F:\tmp\heapdump.hprof ...
2
3
我们再次查看内存快照,结合日志可以猜出大概率是因为在插入那些List<Object[]> objects数组对象作为入参进行插入时生成MySQL相关映射对象导致了OOM:
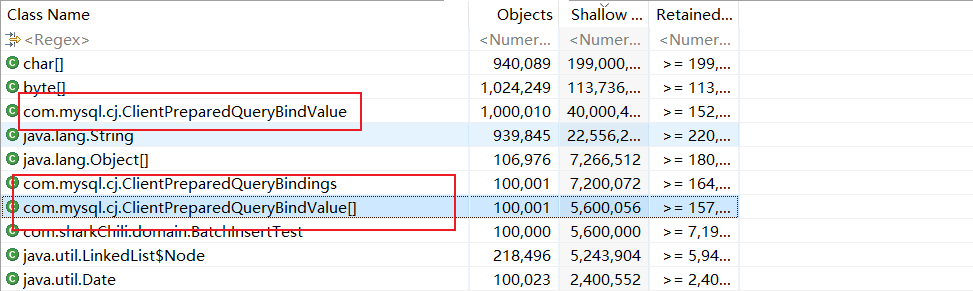
# 对于插入导致的内存溢出的优化
所以我们还是采用Mybatis插入进行优化,可以看到笔者对于本次插入的优化做了两件事:
- 插入的对象直接采用查询结果,避免
List<BatchInsertTest>转List<Object[]>时数组空间的占用,避免没必要的GC。 - 将查询结果用链表存储查询结果,通过分批弹出元素并进行插入,实现一个批次一个批次的插入,从而保证数据尽早被
GC,节约内存。

对应优化后的代码示例如下:
BatchInsertTestMapper testMapper = SpringUtil.getBean(BatchInsertTestMapper.class);
PageHelper.startPage(1, 10_0000, false);
LinkedList<BatchInsertTest> list = testMapper.selectByExample(null);
log.info("查询结束,size:{}", list.size());
SqlSessionFactory sqlSessionFactory = SpringUtil.getBean(SqlSessionFactory.class);
SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH);
BatchInsertTestMapper mapper = sqlSession.getMapper(BatchInsertTestMapper.class);
long b = System.currentTimeMillis();
BatchInsertTest batchInsertTest;
int counter = -1;
while ((batchInsertTest = list.pollFirst()) != null) {
++counter;
mapper.insert(batchInsertTest);
if (counter % 5000== 0 || counter == list.size() - 1) {
long beginTime = System.currentTimeMillis();
sqlSession.commit();
long endTime = System.currentTimeMillis();
log.info("批处理耗时:{}ms", endTime - beginTime);
}
}
long e = System.currentTimeMillis();
log.info("处理结束:{}ms", e - b);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
我们在确保了业务的正确性之后,通过监控工具jvisualvm查看程序的GC情况,可以看到GC情况还是比较稳定的,基本都能在每个批次插入完成后将数据回收。
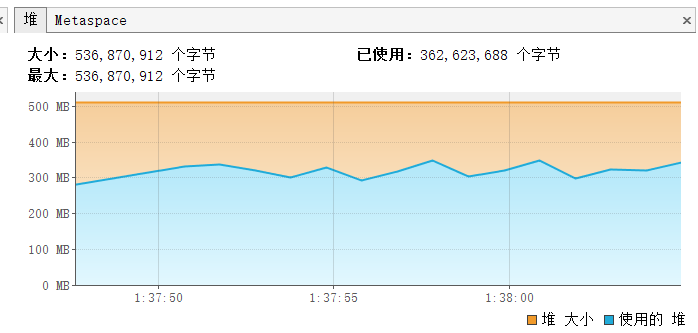
# 我们可以做的更好
对于上述例子,其实我们还有一些细节可以完成更极致的优化:
- 对于非必要的字段,我们就不要查出来,对于这一点,因为笔者的业务要求所有字段必须,所以无法做到。
- 对于基本类型,如果能保证非空尽量用基本类型而不是包装类,我们都知道
Java对象默认情况下都会包含对象头等各种信息,这在无形间对内存都有着一定的占用,考虑到我们的功能,对于查询结果的包装类型,我们完全可以改为基本类型,所以笔者将查询的id由Integer改为int:
public class BatchInsertTest {
private int id;
}
2
3
# 小结
我是 sharkchili ,CSDN Java 领域博客专家,开源项目—JavaGuide contributor,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。 因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。

# 参考
springboot获取应用配置的数据源:https://blog.csdn.net/liu_xue_xue/article/details/108334451 (opens new window)
