 MySQL 索引进阶指南:深入探秘关键知识点
MySQL 索引进阶指南:深入探秘关键知识点
# 写在文章开头
在 MySQL 的浩瀚世界中,索引犹如高效查询的魔法钥匙,为数据的快速检索和操作打开便捷之门。当我们对 MySQL 索引有了初步认知后,是时候踏上进阶之旅,深入挖掘那些隐藏在背后、更具深度和复杂性的索引知识点。
在这篇文章中,我们将一同突破常规理解的局限,去探索 MySQL 索引更为精妙和细微之处。从索引的高级特性到复杂场景下的运用策略,从性能优化的关键要点到可能遇到的疑难问题解析,每一个知识点都将如拼图般为你构建起更为完整和强大的索引知识体系。无论你是经验丰富的开发者,还是正在进阶道路上努力前行的技术探索者,都将在这里收获新的启迪和宝贵的见解。让我们开启这场精彩的进阶之旅,一同揭开 MySQL 索引的神秘面纱,释放其更为强大的力量。
Hi,我是 sharkChili ,是个不断在硬核技术上作死的技术人,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
# 详解创建高性能的索引准则
# 前缀索引的选择
使用前缀的索引的重要原则就是用尽可能小的前缀获取最高校的查询性能,例如我们现在有下面这样一张表。
CREATE TABLE db1.city (
city varchar(50) NULL
)
ENGINE=InnoDB
DEFAULT CHARSET=utf8
COLLATE=utf8_general_ci;
2
3
4
5
6
7
表中会有这样的数据,读者可以按需下面的脚本创建随机的几百万条:
INSERT INTO db1.city (city) VALUES('London');
INSERT INTO db1.city (city) VALUES('Hiroshima');
INSERT INTO db1.city (city) VALUES('teboksary');
INSERT INTO db1.city (city) VALUES('pak kret');
INSERT INTO db1.city (city) VALUES('yaound');
INSERT INTO db1.city (city) VALUES('tel aviv-jaffa');
INSERT INTO db1.city (city) VALUES('Shimoga');
INSERT INTO db1.city (city) VALUES('Cabuyao');
....```
执行上述脚本之后,我们不妨看看表的数据分布情况
```sql
select count(*) as c,city from city group by city;
2
3
4
5
6
7
8
9
10
11
12
13
14
最终输出比重如下
66 London
50 Hiroshima
49 teboksary
50 pak kret
50 yaound
48 tel aviv-jaffa
48 Shimoga
46 Cabuyao
46 Callao
46 Bislig
2
3
4
5
6
7
8
9
10
由于city字段存在大量的重复,所以我们选择前缀索引,通过前缀索引的方式实现最尽可能小的长度区分尽可能多的数据,从而做到高效查询且解决索引维护的开销。
对此,我们提出了这样一种做法,首先我们先算出city列的基数,查看不重复列所占用所有数据的比值是多少:
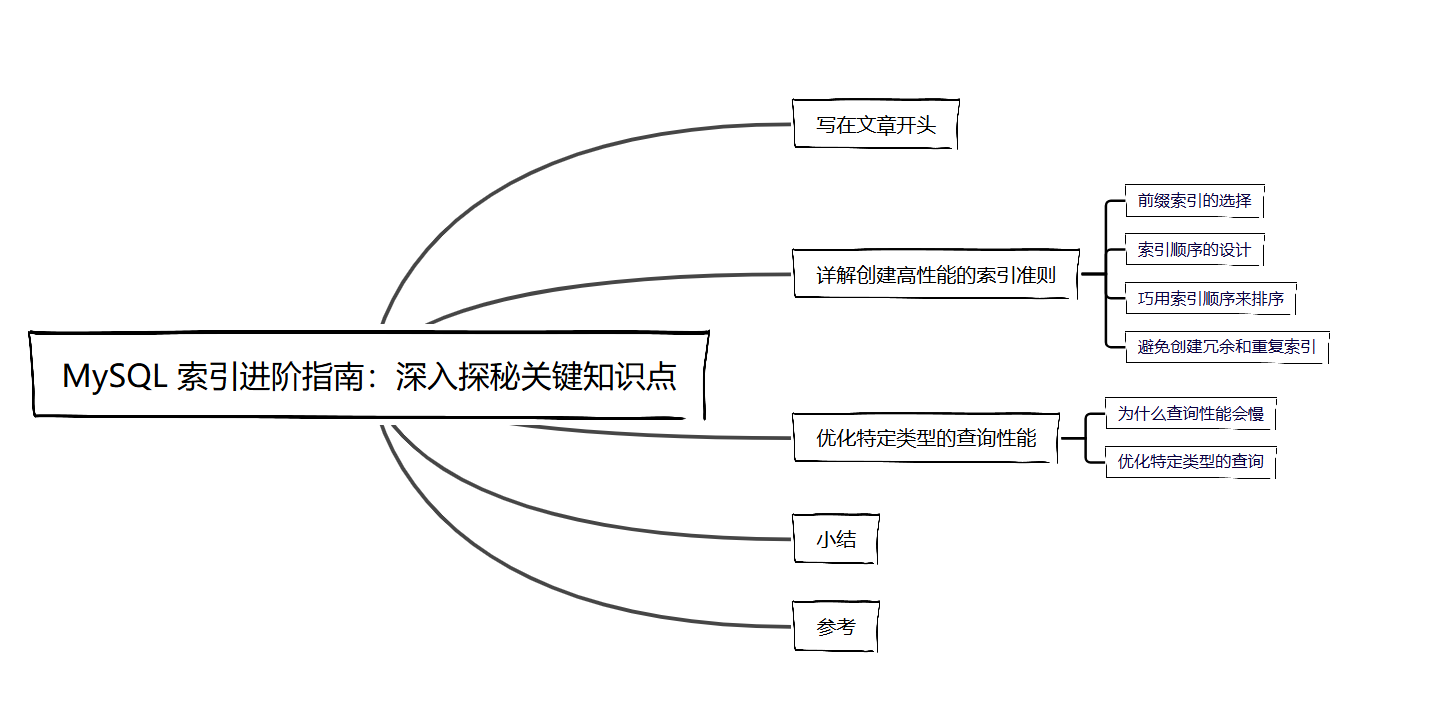
select count(distinct city)/count(*) from city;
输出结果如下,说明完全不重复的city仅仅占用2%,所以我们创建的前缀索引的基数要尽可能接近这个值,才能做到数据区分最大化:
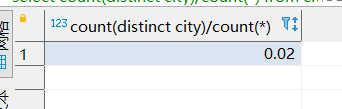
所以我们截取不同的长度的前缀计算基数的值:
select
count(distinct left(city,1))/count(*) as sel1,
count(distinct left(city,2))/count(*) as sel2,
count(distinct left(city,3))/count(*) as sel3,
count(distinct left(city,4))/count(*) as sel4,
count(distinct left(city,5))/count(*) as sel5,
count(distinct left(city,6))/count(*) as sel6,
count(distinct left(city,7))/count(*) as sel7
from city;
2
3
4
5
6
7
8
9
最终我们输出结果如下,可以看到选择长度为3的时候,基数就和完整列的值一样了,所以我们的前缀索引长度设置为3即可:
CREATE INDEX city_idx ON city (city(3));
需要注意的是,我们使用前缀索引进行查询时,MySQL是无法使用前缀索引进行group by和order by的,所以有涉及这种查询的读者需要注意一下使用场景。
# 索引顺序的设计
在不考虑排序和分组的情况下,涉及多列查询的sql我们建议使用多列索引,而创建多列索引的原则也能很简单,将选择性比较大的列放在最前面即可。
为了完成这个实验,我们可创建下面这张表:
CREATE TABLE `payment` (
`payment_id` SMALLINT UNSIGNED NOT NULL AUTO_INCREMENT,
`customer_id` SMALLINT UNSIGNED NOT NULL,
`staff_id` TINYINT UNSIGNED NOT NULL,
`rental_id` INT DEFAULT NULL,
`amount` DECIMAL(5,2) NOT NULL,
`payment_date` DATETIME NOT NULL,
`last_update` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`payment_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
2
3
4
5
6
7
8
9
10
11
12
然后我们使用脚本或者别的方式创建100w条数据并插入到数据库中。
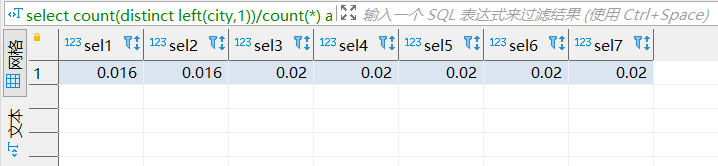
因为我们的查询sql需要用到customer_id和staff_id作为查询条件,所以我们希望为这两列字段创建组合索引,所以我们使用了如下sql语句获取这两列的基数。
select count(*) as total,
count(distinct customer_id)/count(*) customer_id,
count(distinct staff_id)/count(*) staff_id
from payment;
2
3
4
可以看到,customer_id基数更大,区分度更高,所以我们建议customer_id放在前面。
最终我们的创建如下索引,感兴趣的读者可以将两者位置调换一下,查看百万级别数据性能。
CREATE INDEX idx ON payment ( customer_id, staff_id );
2
以下便是笔者的查询sql,可以看到执行计划走了索引。
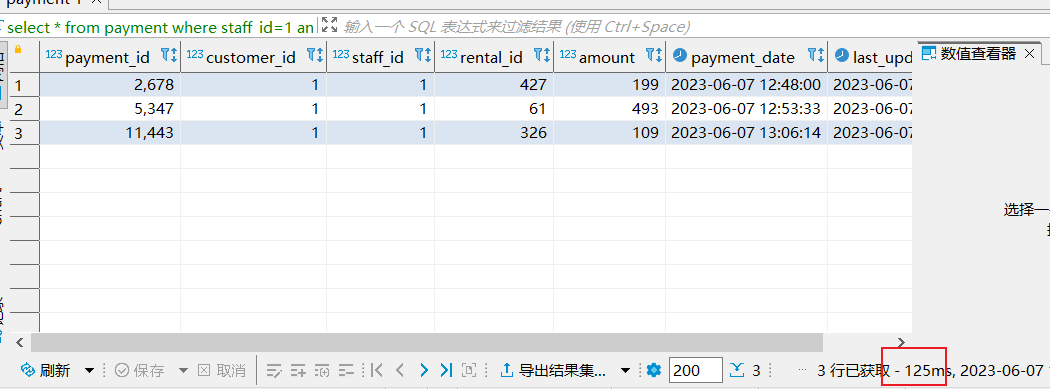
select * from payment where staff_id=1 and customer_id=1;
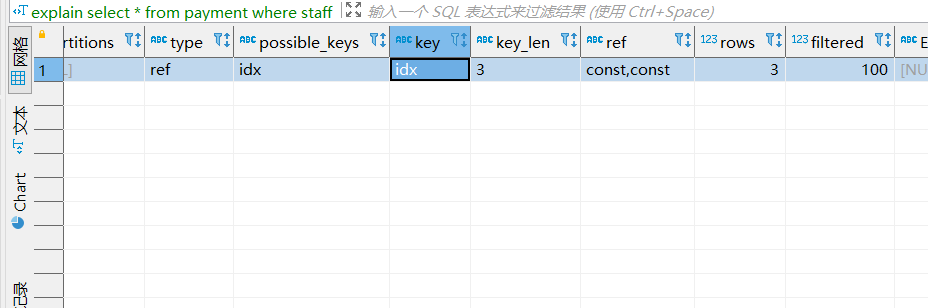
而且查询时间为125ms左右:
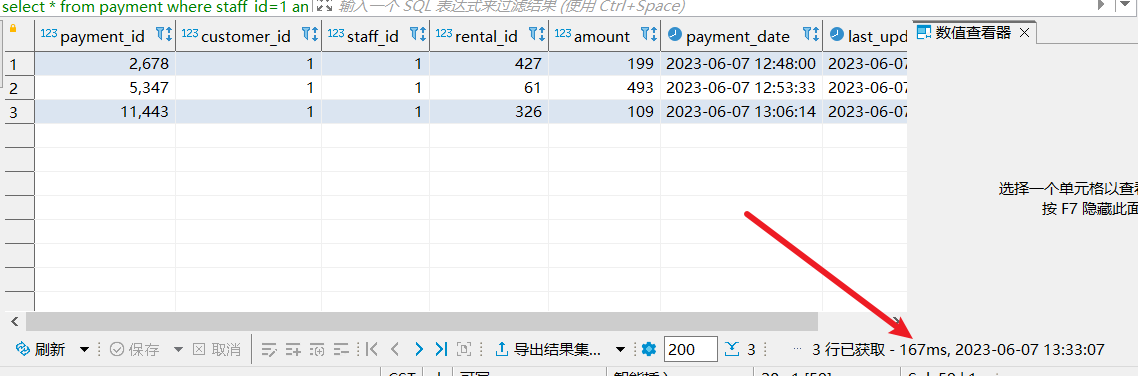
有的读者可能不相信笔者的思路,我们不妨将索引顺序反过来。
DROP INDEX idx ON payment;
CREATE INDEX idx ON payment ( staff_id , customer_id);
2
我们还是用同样的sql,可以看到执行时间变长了,这还是1w条数据的情况,如果达到百万级别想想更是灾难。
# 巧用索引顺序来排序
如果我们查询的时用的order by和索引顺序是一致的,而且查询时还是索引覆盖的话,那么我们就可以认为这是一个良好的设计。
使用索引排序同样遵循最左匹配原则,而且在多表查询时用到的永远是第一张表的索引。当然这里也有一些特殊情况,笔者会在后文中详细阐述。
为了完成实验,笔者创建了下面这样一张数据表(注意这个下面的唯一索引UNIQUE KEY,笔者后续的查询都会基于这个唯一索引完成),并插入几条数据。
CREATE TABLE rental (
rental_id INT NOT NULL AUTO_INCREMENT,
rental_date DATETIME NOT NULL,
inventory_id MEDIUMINT UNSIGNED NOT NULL,
customer_id SMALLINT UNSIGNED NOT NULL,
return_date DATETIME DEFAULT NULL,
staff_id TINYINT UNSIGNED NOT NULL,
last_update TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (rental_id),
UNIQUE KEY (rental_date,inventory_id,customer_id),
KEY idx_fk_inventory_id (inventory_id),
KEY idx_fk_customer_id (customer_id),
KEY idx_fk_staff_id (staff_id),
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
2
3
4
5
6
7
8
9
10
11
12
13
14
对应的脚本都在这个仓库,有需要的读者可以自取,注意选用MySQL版本的:https://github.com/ivanceras/sakila](https://github.com/ivanceras/sakila (opens new window)
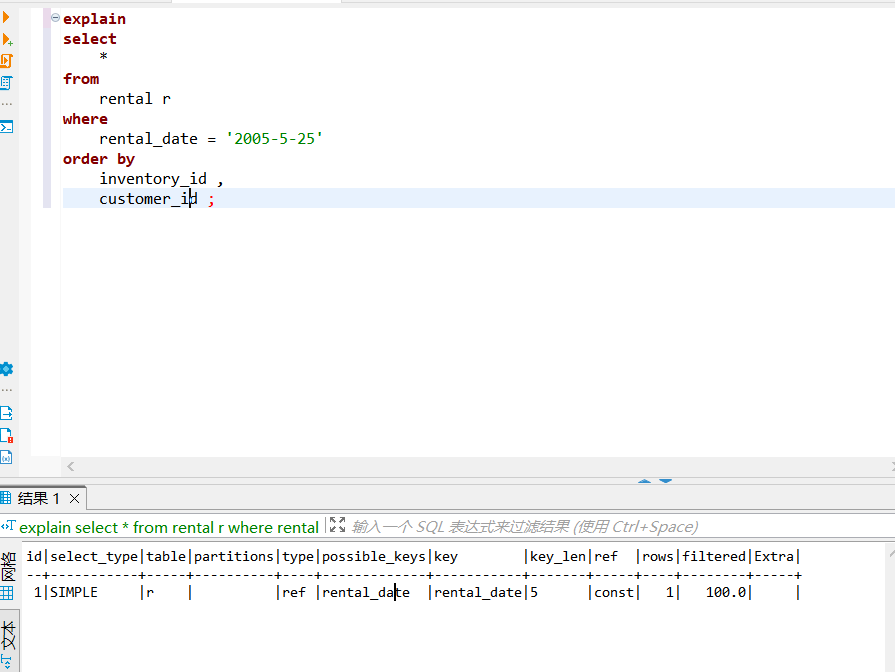
先来看看下面这个语句,这就是我们上文所说的特殊情况,请问这条sql会走索引吗?
select *
from
rental r
where
rental_date = '2005-5-25'
order by
inventory_id ,
customer_id ;
2
3
4
5
6
7
8
9
答案是会的,我们用explain可以看到这条语句用到了rental_date,原因也很简单,我们的唯一索引顺序为rental_date,inventory_id,customer_id,所以我们的where条件中带有rental_date是个常量查询(这里可以理解为等于号的查询),而且order条件方向顺序一致,使得where+order符合最左匹配原则,所以最终走了索引,而且extra也没用出现filesort。
我们上面提到order顺序不一致,或者where+order用的列不符合最左匹配原则查询效率会降低,并且会走文件排序,我们不妨写个sql印证一下。
先看看排序方向不一致的,如下所示,可以看到一个降序加一个升序,最终执行计划就是用了文件排序。
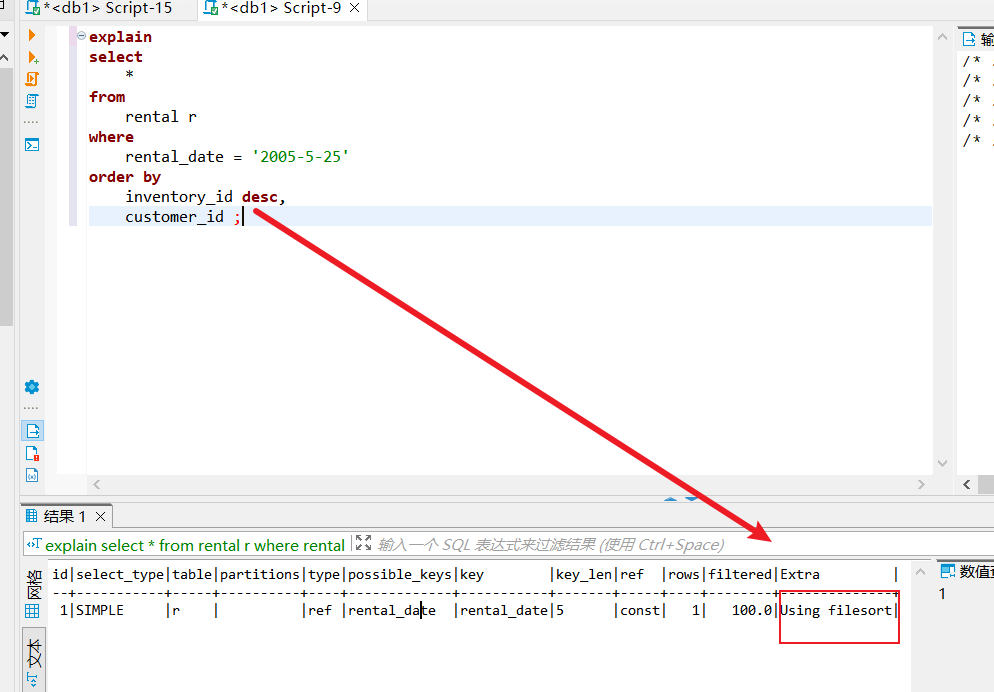
在看看where+order不符合最左匹配原则的情况,同样走了文件排序。
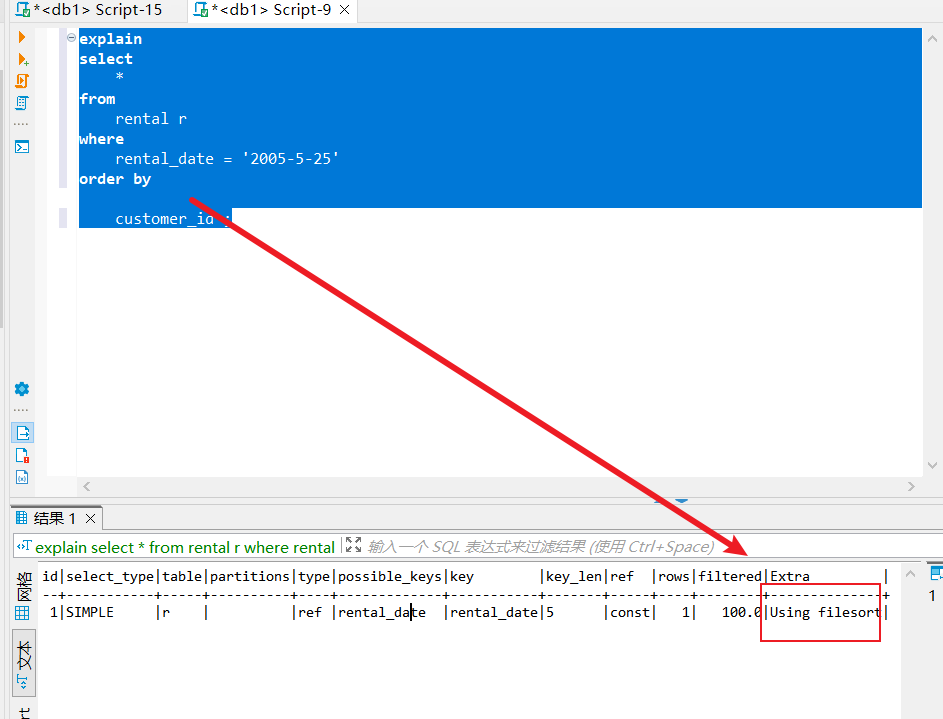
了解了特殊情况之后,我们再来看看一些常规的情况。如下所示,这条sql where+order符合最左匹配原则,所以走了索引。
explain select *
from
rental r
where
rental_date = '2005-5-25'
order by
inventory_id ;
2
3
4
5
6
7
输出结果如下
id|select_type|table|partitions|type|possible_keys|key |key_len|ref |rows|filtered|Extra|
--+-----------+-----+----------+----+-------------+-----------+-------+-----+----+--------+-----+
1|SIMPLE |r | |ref |rental_date |rental_date|5 |const| 1| 100.0| |
2
3
当然符合最左匹配原则并不意味着只要列符合最左前缀即可,如下所示,如果第一个列出现范围查询则索引就直接失效了。
explain select *
from
rental r
where
rental_date > '2005-5-25'
order by
inventory_id ,customer_id ;
2
3
4
5
6
7
输出结果如下,可以看到直接using where且文件排序,还不走索引
id|select_type|table|partitions|type|possible_keys|key|key_len|ref|rows |filtered|Extra |
--+-----------+-----+----------+----+-------------+---+-------+---+-----+--------+---------------------------+
1|SIMPLE |r | |ALL |rental_date | | | |15840| 50.0|Using where; Using filesort|
2
3
同样的排序时,如果用到了非索引的列也会使得排序变为文件排序
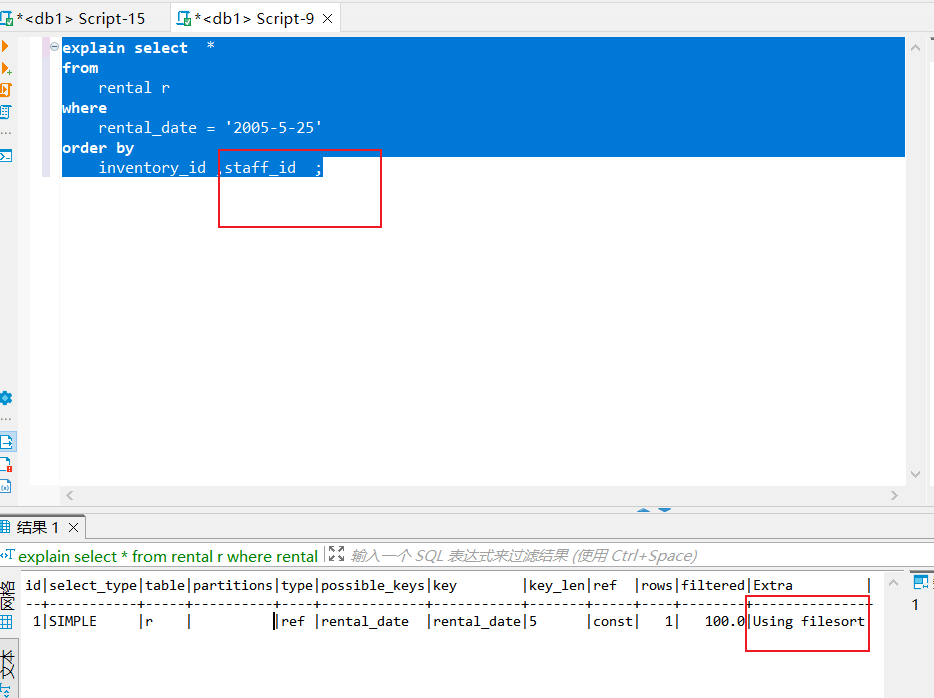
最后我们再来看一个联结查询的例子,首先我们建了个表再插入数据,脚本都在上方仓库读者可以自行获取,笔者这里为了省事把所有外键的定义都删了。
CREATE TABLE film_actor (
actor_id SMALLINT UNSIGNED NOT NULL,
film_id SMALLINT UNSIGNED NOT NULL,
last_update TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (actor_id,film_id),
KEY idx_fk_film_id (`film_id`)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE film (
film_id SMALLINT UNSIGNED NOT NULL AUTO_INCREMENT,
title VARCHAR(255) NOT NULL,
description TEXT DEFAULT NULL,
release_year YEAR DEFAULT NULL,
language_id TINYINT UNSIGNED NOT NULL,
original_language_id TINYINT UNSIGNED DEFAULT NULL,
rental_duration TINYINT UNSIGNED NOT NULL DEFAULT 3,
rental_rate DECIMAL(4,2) NOT NULL DEFAULT 4.99,
length SMALLINT UNSIGNED DEFAULT NULL,
replacement_cost DECIMAL(5,2) NOT NULL DEFAULT 19.99,
rating ENUM('G','PG','PG-13','R','NC-17') DEFAULT 'G',
special_features SET('Trailers','Commentaries','Deleted Scenes','Behind the Scenes') DEFAULT NULL,
last_update TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (film_id),
KEY idx_title (title),
KEY idx_fk_language_id (language_id),
KEY idx_fk_original_language_id (original_language_id)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
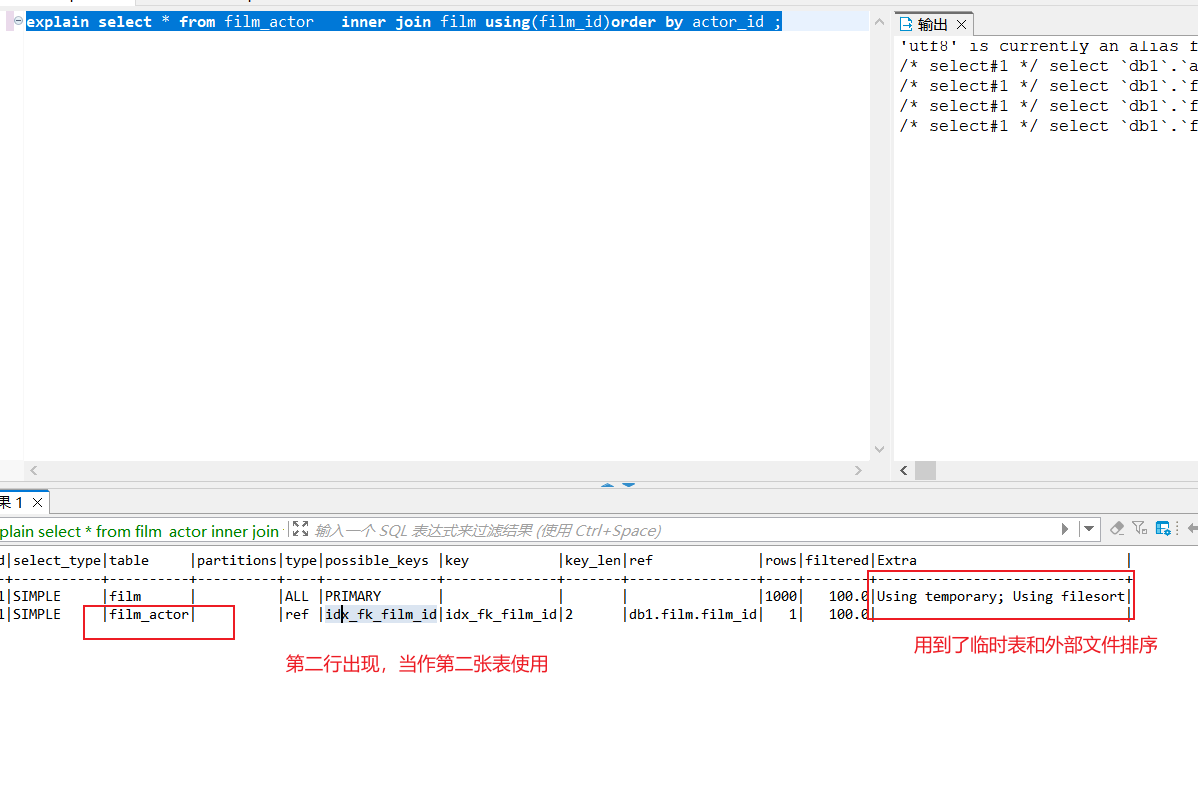
如下所示,这句sql理论上是可以走索引的,但MySQL优化器将film_actor当作第二张表导致order by无法使用索引。
explain select * from film_actor inner join film using(film_id)order by actor_id ;
所以我们看到了这样的输出,非常低效。
最后我们总结一下使用排序的原则:
- order by顺序方向一致。
- where+order要符合最左匹配原则。
- where条件不要用范围查询。
- 多表联查是观察MySQL优化器会不会做一些奇奇怪怪的优化。
# 避免创建冗余和重复索引
有时因为开发人员对于数据库的立即偏差会创建出一些冗余的索引,如下所示:
CREATE table t1(
id int not null primary key,
name varchar(20),
unique(id),
index(id)
)engine=innodb;
2
3
4
5
6
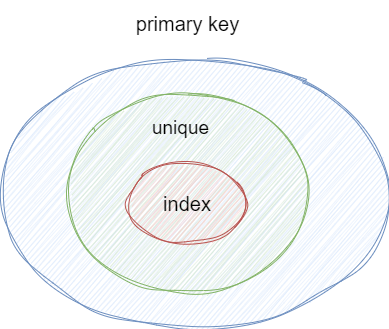
实际上主键、unique、index的关系如下图所示,由于开发对于三者关系的不了解,导致了创建了两个没有必要的索引,所以我们日常还是需要多留心一下这些问题:
还有一种情况我们也必须要了解一下,有时候我们为了提高多列查询的效率会创建组合索引。例如我们的sql语句为
select * from t where a=123 and b='aa'
这种情况下我们肯定会为了a、b创建索引。
如此一来,按照最左匹配原则,我们就无需单独为字段a创建一个索引。
select * from t where a=123;
如下图可以看到,单独使用a作为查询条件时a也会走我们创建的组合索引。

但是某些场景之下,我们可能又会写出这样一条sql,所以我们还是要为(b,a)创建一条索引,请问该索引是冗余索引吗?
select * from t where b='aa3' and a=12
答案不是的,原因很简单,尽管SQL优化器会让上述SQL走组合索引(a,b),但是我们单独以b作为查询条件时,是走不了组合索引(a,b)的,所以我们创建组合索引(b,a)并不算冗余索引。
# 优化特定类型的查询性能
# 为什么查询性能会慢
我们首先了解一下一条sql的生命周期:
- 客户端向服务端建立连接,并将sql发送给服务端、
- 服务端进行语法解析,查看语法是否存在问题。
- 生成执行计划。
- 服务端执行sql。
- 将sql执行结果返回给客户端。
这其中我们不难发现,执行是最重要的一环,造成查询慢的重要部分基本都是执行,其原因基本都是访问的数据量太大,或者一次需要筛选出大量的数据。
所以,对于这类问题,我们解决方向基本是:
- 避免检索没必要的行。
- 尽可能避免查询大量的数据,对于某些查询,我们建议使用分页查询的方式。
很多人可能认为某一些查询慢的问题也出现在客户端和服务端建立连接和断开连接这一部分,实际上MySQL的设计很少会出现这些问题,在某些版本的MySQL中对于简单查询,它支持1秒10w次,即使是千兆网卡,这一个数字也基本是2000左右,所以对于现如今的服务器配置,这里的开销基本可以忽略。
# 优化特定类型的查询
下面笔者会介绍一些常见的错误类型的特定类型查询,我们先来说一个常见的查询,count,count常用于统计某列非null的总数量,所以某些情况下,我们可能常用于统计列的总数。所以我们统计数据库的列数时可能会写出这样一句sql
--用主键统计数据库行数
select count(rental_id) from rental r ;
2
3
实际上,我们使用count()就行了,很多人认为count(*)会扩展出所有的列造成性能问题,实际恰恰相反,count(*)不仅不会扩展所有的列,而且也能统计出当前表中所有的行。所以对于要统计的sql语句我们更简易使用count(),不仅更能清晰表达意图还有更不错的性能表现。
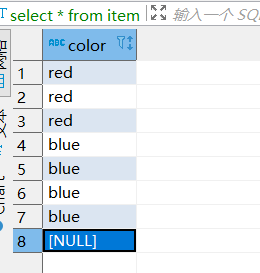
对于count我们也可以用于某列的归类操作,例如我们希望查询出颜色为蓝色或者红色的行的数量。我们的数据如下所示,可以看到颜色为3红4蓝1空。
所以我们可能会用到这样一条sql,但是我们不想为此多写一列。
select count(*),color from item i group by color ;
所以我们用到了这样一条sql,但是用到了函数嵌套很不直观
select sum(if(color='blue',1,0)) as blue ,sum(if(color='red',1,0)) as red from item;
其实我们运用count统计非null的特性,就可以写出这面这样一条精致的sql
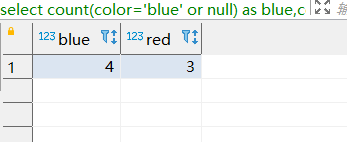
select count(color='blue' or null) as blue,count(color='red' or null) as red from item;
可以看到查询结果也符合预期。
最后我们再来说说union,如果我们能够保证union的数据是不重复,我们还是建议使用union all,如下所示:
explain select rental_id from rental where inventory_id <10000
union
select rental_id from rental where inventory_id >10000
2
3
使用union因为需要去重的缘故,导致两个查询结果进行拼接操作时用到了temporary即外部排序,该操作就会创建临时表并且还会对临时表作唯一性检查,即distinct操作,这就使得这句sql代价非常高。
1 PRIMARY rental range rental_date,idx_fk_inventory_id idx_fk_inventory_id 3 16215 100.0 Using where; Using index
2 UNION rental range rental_date,idx_fk_inventory_id idx_fk_inventory_id 3 1 100.0 Using where; Using index
UNION RESULT <union1,2> ALL Using temporary
2
3
所以如果我们有办法或者说查询结果绝对不重复,我们还是建议使用下面这段sql
explain select rental_id from rental where inventory_id <10000
union all
select rental_id from rental where inventory_id >10000
2
3
从执行计划我们就可以看出,在拼接操作时,因为无需考虑重复就避免了创建临时表和distinct去重的操作了。
id|select_type|table |partitions|type |possible_keys |key |key_len|ref|rows |filtered|Extra |
--+-----------+------+----------+-----+-------------------------------+-------------------+-------+---+-----+--------+------------------------+
1|PRIMARY |rental| |range|rental_date,idx_fk_inventory_id|idx_fk_inventory_id|3 | |16215| 100.0|Using where; Using index|
2|UNION |rental| |range|rental_date,idx_fk_inventory_id|idx_fk_inventory_id|3 | | 1| 100.0|Using where; Using index|
2
3
4
# 小结
我是 sharkchili ,CSDN Java 领域博客专家,mini-redis的作者,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
# 参考
《高性能MySQL(第4版)》
