 来聊聊redis数据库的设计与实现
来聊聊redis数据库的设计与实现
# 写在文章开头
很多人认为redis是内存中间件,对于这个观点,我其实不是很认同,从使用和redis工作机制来看,它无非是基于内存实现快速的非关系型数据的操作而已,然后在一定的时间段进行一次刷盘持久化,所以从我的认知来看,我觉得redis应该算是内存数据库。
于是我们就有了今天这篇文章,redis是如何实现非关系型数据库结构的。
Hi,我是 sharkChili ,是个不断在硬核技术上作死的 java coder ,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。

# 详解redis数据库的设计与实现
# redis服务端对于数据库的管理
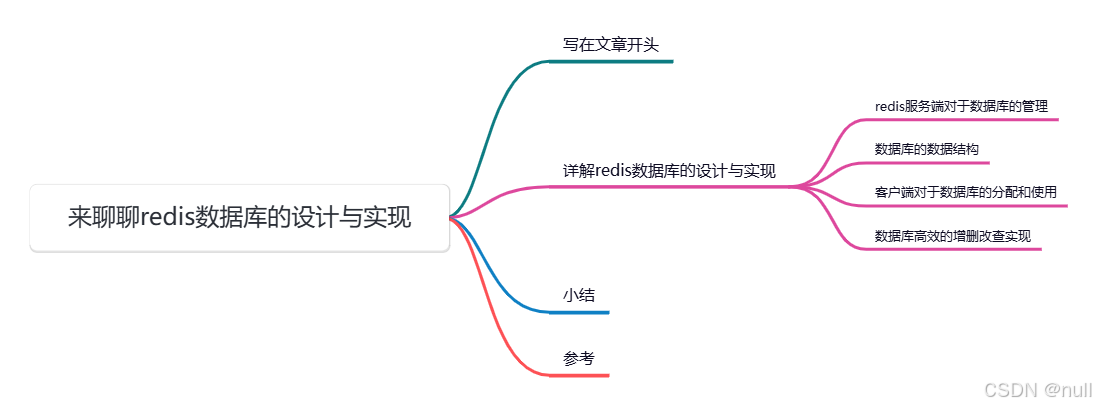
我们都知道用户想操作redis都需要和redis服务器建立连接,对应的redis将服务端对象抽象为redisServer,对应的数据库都会交给这个redisServer的db指针进行统一的管理,在redis服务器初始化阶段,redis会基于配置的参数dbnum分配一块连续的内存空间(默认为16)来存储数据库对象:
对应的初始化的代码我们可以在redis.c的initServer函数看到这段调用,用户在进行数据库切换的时候,可以通过select指令切换要操作的数据库:
void initServer(void) {
//......
//基于dbnum分配一块连续的内存空间给db指针
server.db = zmalloc(sizeof(redisDb)*server.dbnum);
}
2
3
4
5
# 数据库的数据结构
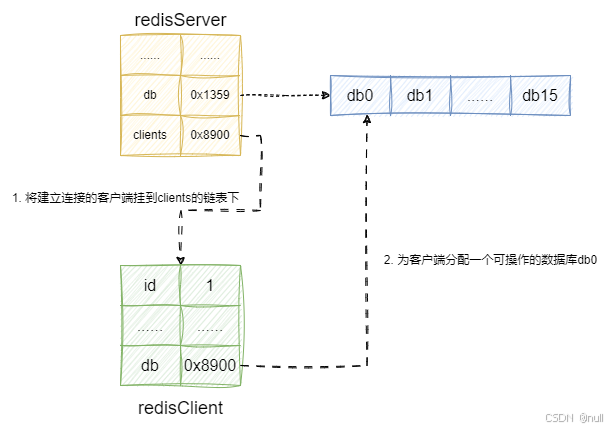
redis数据库通过redisDb这个结构体进行封装,其本质就是通过一个字典结构管理非关系型键值对,利用字典的哈希算法实现尽可能O(1)级别的增删改查操作,为什么说是尽可能O(1)级别呢?因为字典有可能存在不同key得到相同的哈希值则定位相同的索引空间,从而造成碰撞,我们通过拉链法解决冲突的情况,于是我们的查询的时间复杂度有时候可能是O(n):

对应的我们给出redis.h下的redisDb 的数据结构,可以看到其最核心字段就是作为数据库的dict指针:
typedef struct redisDb {
//作为内存数据库
dict *dict; /* The keyspace for this DB */
//......
int id; /* Database ID */
} redisDb;
2
3
4
5
6
7
为了让读者对于数据库的实际结构的源代码,笔者也贴出的字典的数据结构,和上图基本一致,其本质通过ht指针管理两张哈希表,基本上正常情况下都是使用ht[0],只有在渐进式再哈希期间会用到ht[1]进行扩容:
typedef struct dict {
//......
//哈希表数组,每个索引为止都存储的是哈希表
dictht ht[2];
//......
} dict;
2
3
4
5
6
# 客户端对于数据库的分配和使用
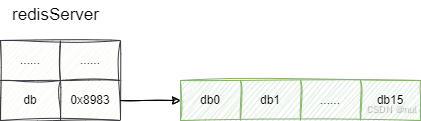
客户端连接上服务端之后,我们就需要为其分配可操作的数据库,默认情况下,客户端使用的都是db0这个数据库,所有在客户端与服务端建立期间,redis会为每一个redis客户端分配db0的指针:
对应的代码段我们可以在初始化客户端的核心代码段createClient方法看到这一操作,可以看到其通过selectDb将db0指针交给c->db :
redisClient *createClient(int fd) {
redisClient *c = zmalloc(sizeof(redisClient));
//......
selectDb(c,0);
//......
return c;
}
//默认情况下,将客户端的db指针指向db[0]
int selectDb(redisClient *c, int id) {
if (id < 0 || id >= server.dbnum)
return REDIS_ERR;
c->db = &server.db[id];
return REDIS_OK;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 数据库高效的增删改查实现
因为redisDb的存储是通过哈希表的哈希算法实现的,由此尽可能的O(1)级别的时间复杂度,且redis的数据库活跃于内存中,所以性能表现十分出色:
对应的我们给出redis哈希表查询、插入、删除的核心逻辑,都是哈希定位再操作:
//查询
dictEntry *dictFind(dict *d, const void *key)
{
dictEntry *he;
unsigned int h, idx, table;
//计算哈希值
h = dictHashKey(d, key);
for (table = 0; table <= 1; table++) {
//通过哈希值定位索引
idx = h & d->ht[table].sizemask;
//到表中查询并比对,如果一致则返回
he = d->ht[table].table[idx];
while(he) {
if (dictCompareKeys(d, key, he->key))
return he;
he = he->next;
}
//......
}
return NULL;
}
//插入
dictEntry *dictAddRaw(dict *d, void *key)
{
//......
//计算索引
if ((index = _dictKeyIndex(d, key)) == -1)
return NULL;
//......
//分配内存空间
entry = zmalloc(sizeof(*entry));
//存到对应的索引位置下
entry->next = ht->table[index];
//......
return entry;
}
//删除
static int dictGenericDelete(dict *d, const void *key, int nofree)
{
//......
//计算哈希值
h = dictHashKey(d, key);
for (table = 0; table <= 1; table++) {
//计算索引
idx = h & d->ht[table].sizemask;
//获取对应元素
he = d->ht[table].table[idx];
//......
while(he) {
//比对如果一致,则从链表中移除掉
if (dictCompareKeys(d, key, he->key)) {
//如果有前驱节点,则让前驱挂后当前节点的后继
if (prevHe)
prevHe->next = he->next;
else
//反之直接让当前索引指向下一个元素
d->ht[table].table[idx] = he->next;
//释放内存空间
if (!nofree) {
dictFreeKey(d, he);
dictFreeVal(d, he);
}
zfree(he);
d->ht[table].used--;
return DICT_OK;
}
prevHe = he;
he = he->next;
}
//......
}
return DICT_ERR; /* not found */
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
# 小结
以上便是笔者对于redis数据库设计与实现的基本剖析,希望对你有所帮助。
我是 sharkchili ,CSDN Java 领域博客专家,开源项目—JavaGuide contributor,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。 因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。

# 参考
《redis设计与实现》
