 ElasticSearch如何写入一篇文档
ElasticSearch如何写入一篇文档
@[toc]
# 写在文章开头
这篇文章我们来聊聊ES底层是如何完成文档的索引,需要强调的是这里索引的概念是一个动词,即通过指定规则将用户数据按照ES规定的数据结构存储到物理磁盘中,通过对本文的阅读,你将会对ES底层的工作机制有着更深刻的理解和掌握。
Hi,我是 sharkChili ,是个不断在硬核技术上作死的技术人,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
# 详解ES检索数据的全流程
# 路由寻址
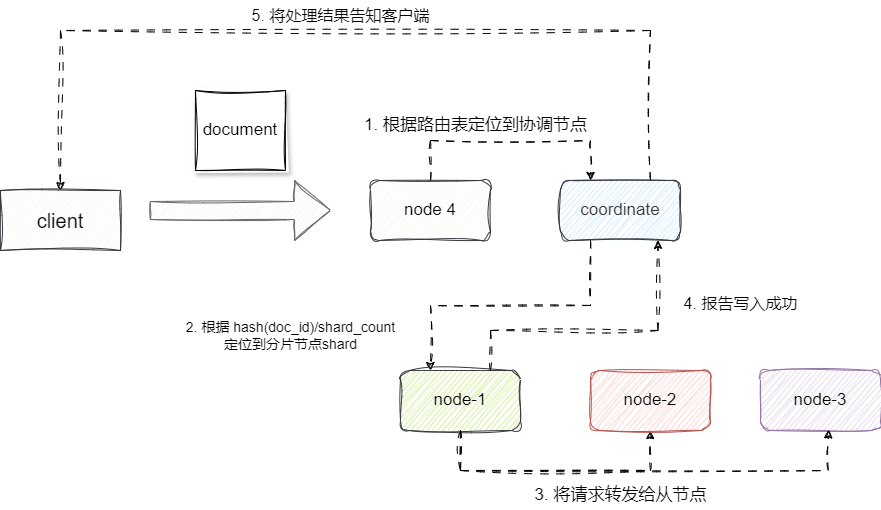
当我们希望索引一份数据时,首先会向elasticSearch集群的coordinate node协调节点发送请求,实际上及时没有发送到coordinate node,即使将请求转发到其他节点,其他节点也能够根据自己的路由表将数据转发到coordinate node上。
随后coordinate node就会根据生成的文档的_id通过路由算法定位(默认情况下的路由算法为hash(_id)/shard_count)定位到目标shard分片对应的node-1。一旦该node-1处理成功,它就会将请求准发到自己的副本分片node-2、node-3上,一旦所有副本分片都报告成功,那么node-1就会向coordinate node成功,最终coordinate node就会将结果告知客户端:
# write写入
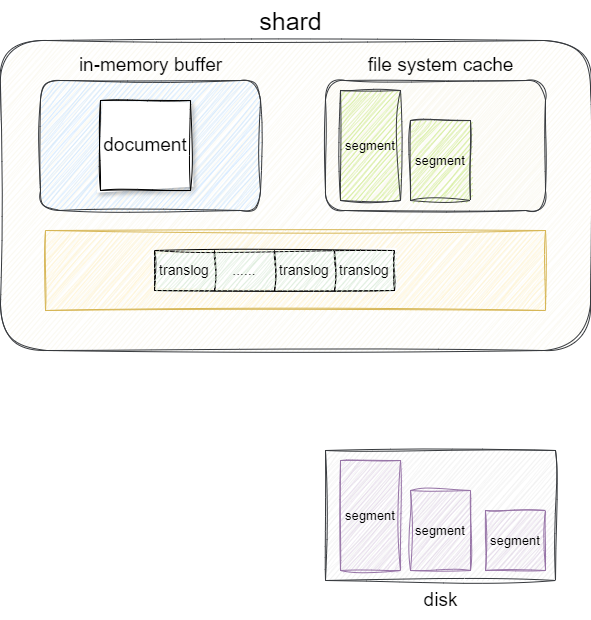
上一步我们已经定位到了目标shard的节点,这时候就开始文档的写入操作了,首先elasticSearch会将这份文档写入到in-memory-buffer中,写入成功后将这份文档记录到translog事务日志中。这也就意味着这份数据还未写入shard底层的lucene index的segment中,所以当前这份数据文档还不可被检索:
# refresh生效检索数据
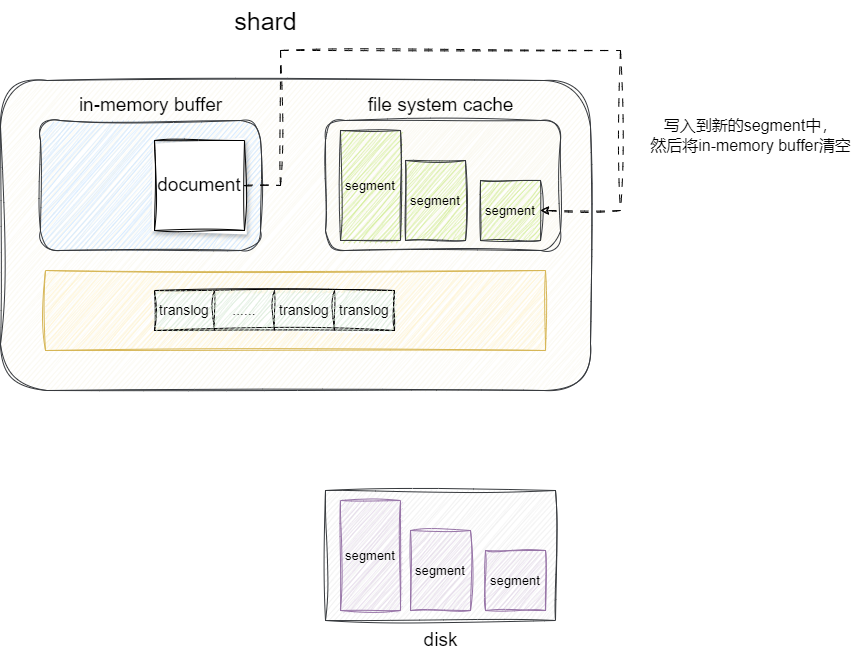
完成上述数据生成之后,es会定期执行refersh逻辑这份生成segment写入到文件系统缓存中,这时候文档的数据就可以被检索。需要注意的是refresh操作默认情况情况下是每秒执行一次,这个时间间隔我们可以通过参数 index.refresh_interval进行修改。
一旦文档写入到segment之后,in-memory-buffer中的数据就会被删除,但是translog的数据发不会被删除,因为translog是否保证写入到文件系统缓存的segment写入到磁盘的关键。
# flush刷盘持久化
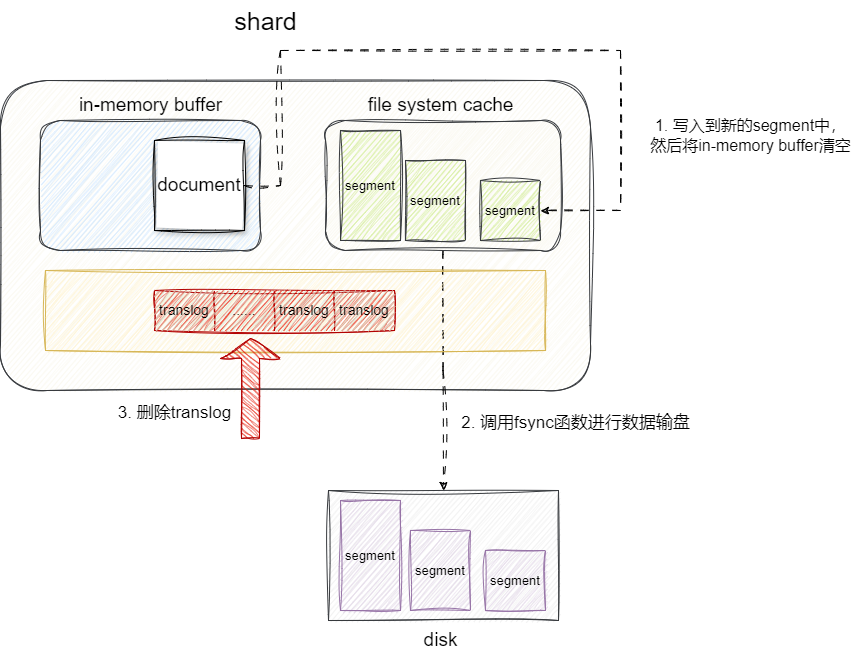
随着时间的推移内存中的translog会逐渐增大(默认情况下translog达到512M),亦或者上次flush操作时间距离现在已经过30min,这块内存空间我们就必须想办法让他空闲出来,此时我们就需要将文件系统缓存的segment的数据写入到磁盘中。具体来说它的写入过程如下:
- 将所有
in-memory buffer的数据都生成一个新的segment写入到文件系统缓存。 - 将
in-memory buffer内存空间清空。 - 文件系统缓存调用
fsync将数据写入磁盘。 - 系统内核按照刷盘策略将数据写入磁盘。
- 完成上述操作后将
translog数据删除。
可以看到它只有在完全刷盘成功后,es才会将translog数据清空,这就是保证故障恢复后数据会再次被加载的保障:
# segment合并
自动刷新的流程会导致短时间内写入的segment数量暴增,并且这些segment都会消耗文件句柄、内存、CPU资源,最重要的是检索时请求都必须轮流检查这些segment,这无疑对es的查询性能造成致命打击。
对此elasticSearch会默默在后台进行合并操作来解决这个问题,将所有的小段合成大段,然后再将大段合并成更大段以最大化的减少segment在磁盘中的数量。
当进行合并的时候,其整体过程如下:
- 新刷盘的
segment会找到一个不包含旧的较小segment作为提交点完成写入。 - es将这个较小的新
segment和另外的segment进行合并,在此期间它们依然对外提供服务。 - 完成合并,新的
segment对外提供服务。 - 旧有的合并小段被删除。
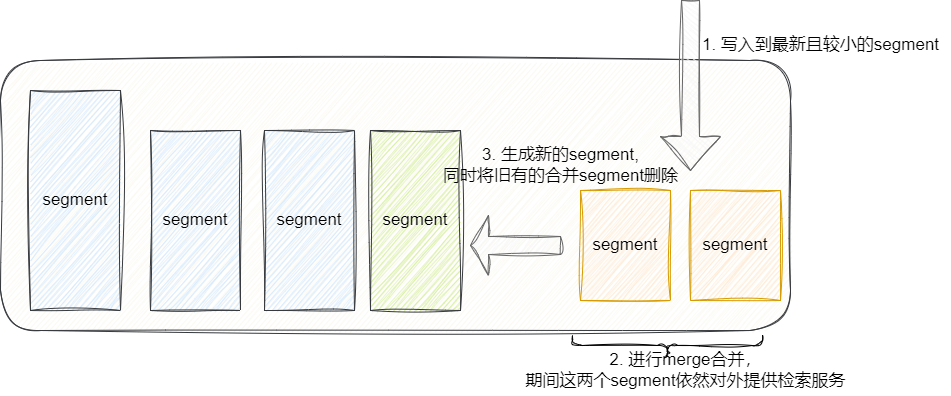
需要注意的是合并大的segment需要消耗大量IO和CPU资源,如果任其肆意合并也会影响检索性能,所以ES默认情况下会对合并流程所消耗的资源进行限制,以最大化保证检索性能。
# 详解ES写入的常见问题
# ES是否支持乐观锁
es是支持乐观锁的,在ES6.7等早期版本可以通过_version关键字进行CAS更新,但是在之后的版本废弃了_version关键字。原因也很简单,_version关键字是递增整数作用域仅针对当前文档,在复杂分布式系统环境下,一旦某个节点因为故障下线或网络波动导致多个副本间_version不一致进而出现集群脑裂,就可能导致过期_version版本号进行乐观锁更新成功的异常。
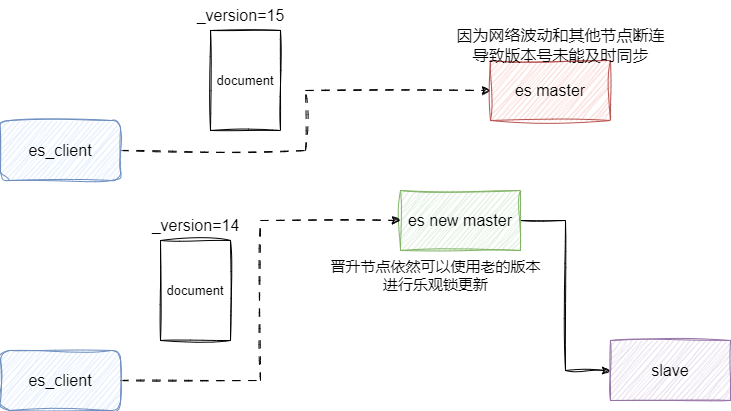
取而代之的是每次查询数据时使用if_seq_no和if_primary_term指定版本,通过比对当前文档所用的全局seq_no和文档编号primary_term比对并完成乐观锁更新:
PUT my_index/_doc/1?if_seq_no=10&if_primary_term=1
{
"foo": "bar"
}
2
3
4
# ES是否支持事务
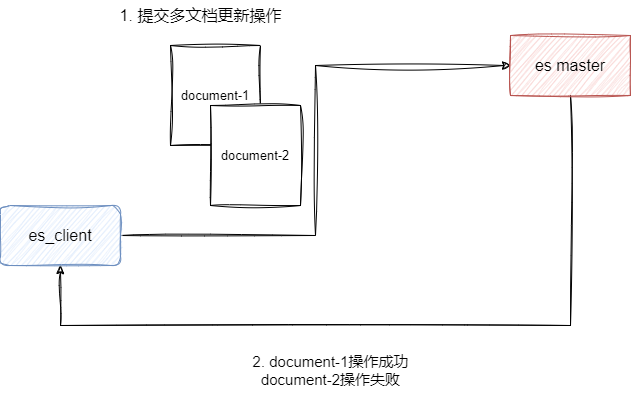
es多用于搜索引擎,考虑到海量数据检索的效率,所以不支持类似于MySQL这种传统数据库的ACID的事务,所以涉及跨域多文档操作的时候,如果需要保证业务原子性和一致性,读者需要在代码层面做好兜底:
# ES不支持decimal如何避免精度丢失
虽然es没有decimal这个字段,所以我们可以通过一下手段保证精度计算正常:
使用
double类型,对于大部分业务场景该类型可以保证精度运算准确性。将需要高精度计算的字段用
keyword进行存储,运算时在应用层面进行转换计算再写回。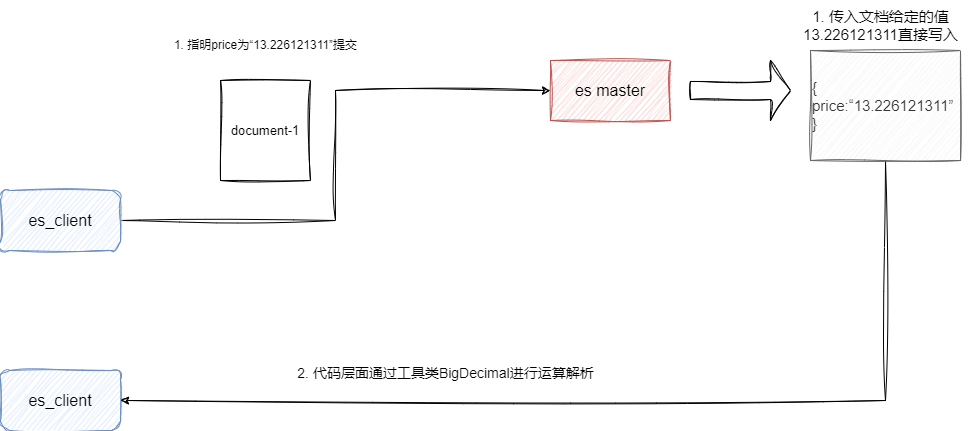
使用
scaled_float,该类型通过scaling_factor这个缩放因子存储记录的值,如下所示我们的缩放因子指明为100:
PUT order
{
"mappings": {
"properties": {
"totalAmount": {
"type": "scaled_float",
"scaling_factor": 100
}
}
}
}
2
3
4
5
6
7
8
9
10
11
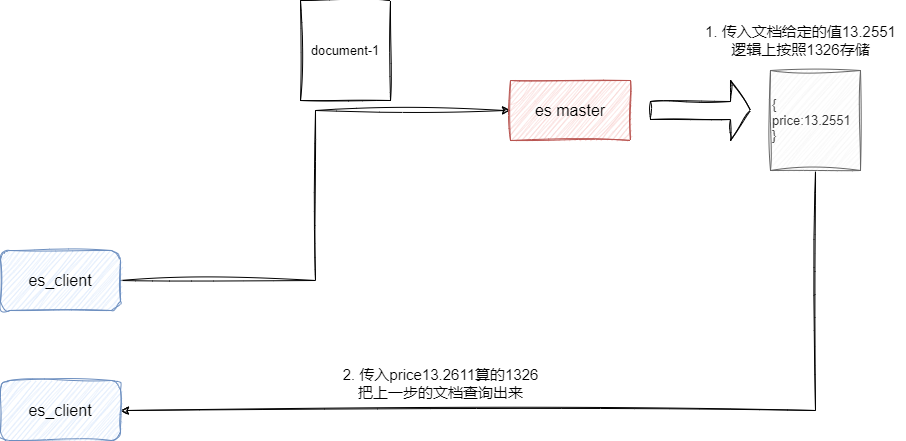
那么我们存储13.2551这个值的实际存储过程就是:
- 乘缩放因子得1325.51
- 四舍五入得1326
如果我们查询传入的值是13.2611,按照缩放因子计算得出结果也是1326,那么上面这份文档就会被返回,所以使用scaled_float的时候我们必须结合业务场景得出一个比较准确的缩放因子:
# 详解ES同步策略
# 和MySQL的同步策略如何设计
同步可以通过定时扫描和实时增量同步两种,这里笔者更推荐后者,常见有两种方案:
- 通过
cannel订阅bin.log将数据推到mq(保证消费可靠性)让用户进行消费。 - 直接基于
flink cdc写一个组件监听bin.log进行消费,如果需要保证可靠性也可以考虑解析后投递到MQ中。
# 小结
自此我们详尽分析了es底层数据写入的逻辑,希望对你有帮助。
我是 sharkchili ,CSDN Java 领域博客专家,mini-redis的作者,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。 因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。

# 参考
ES详解 - 原理:ES原理之索引文档流程详解:https://www.pdai.tech/md/db/nosql-es/elasticsearch-y-th-3.html (opens new window)
https://blog.csdn.net/Weixiaohuai/article/details/124667345
