 CPU任务调度和伪共享问题小结
CPU任务调度和伪共享问题小结
# CPU是如何执行任务的
# CPU MESI策略导致的性能下降问题
我们都知道CPU为了解决缓存一致性的问题,用了MESI协议,虽然它很好的解决了缓存一致性的问题。但是他却暴露一个很大的问题——缓存命中率下降。
# 图解缓存一致性问题
CPU 核心1从内存中加载一个cache line,如下图所示,我们都知道64位的操作系统的cache line都是64k,所以我们加载一个cache line的时候把变量A B都加载进来了。此时其他CPU缓存中都没有的这个数据,于是CPU cache就把这个cache line设置为独占状态,即E。
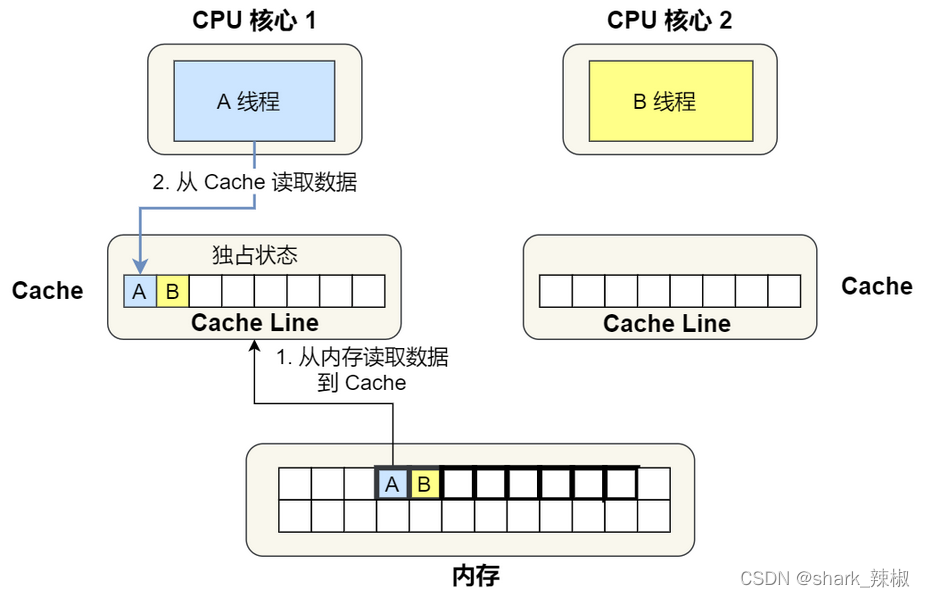
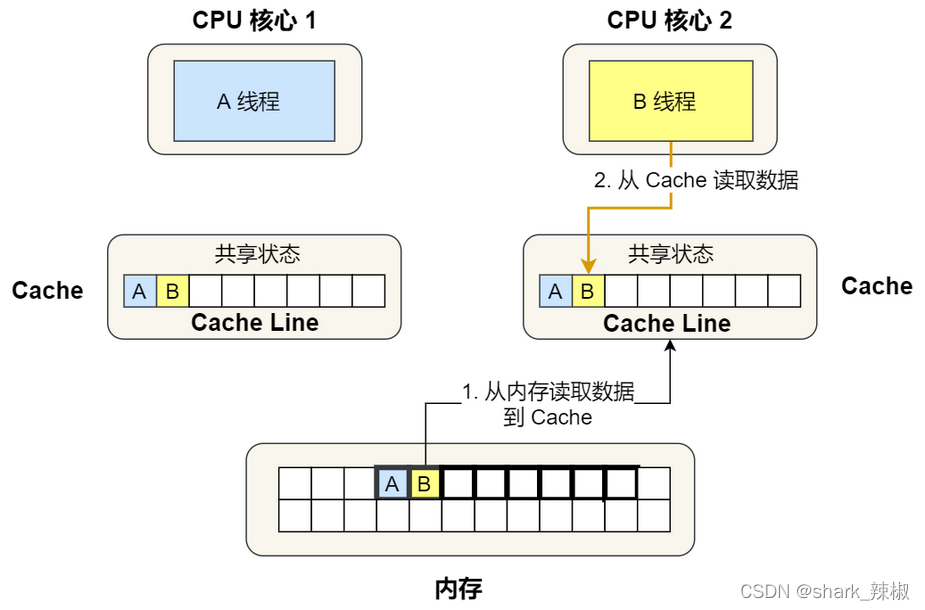
- 然后CPU核心2也加载了同样地址的内存数据,在总线(BUS)上发了消息问问有没有CPU加载过该数据,发现CPU核心1有加载,于是CPU们都把这个数据设置为共享状态
S。
- 然后CPU1改了变量A B的数据,发出了通知,CPU2知道之后,就将自己cache line中的数据设置为无效I。CPU1就将这个数据的状态标志设置为修改(M)
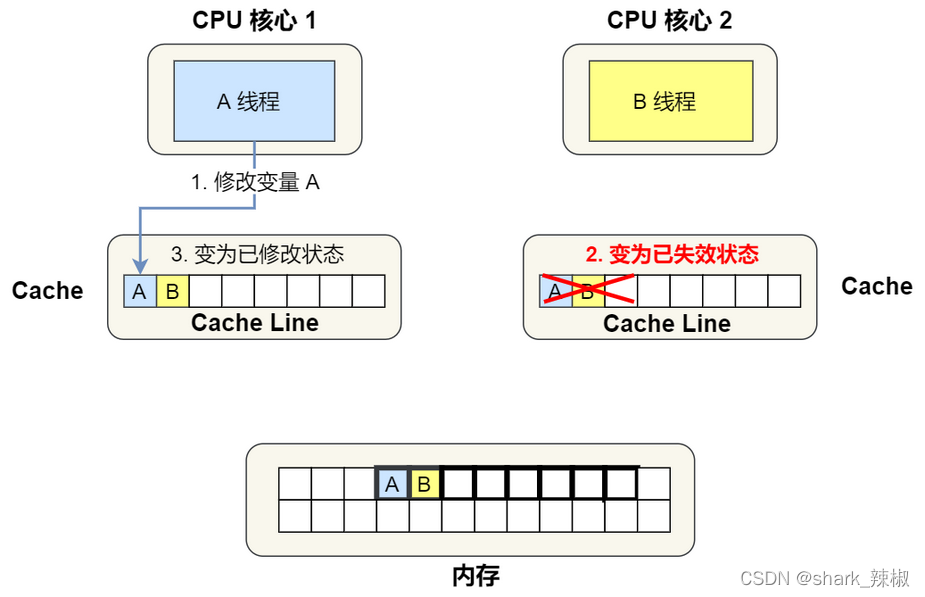
- 然后CPU2也要改数据了,他发现自己cache line中的数据无效了,所以需要CPU1把修改的数据写回内存,CPU2去内存中捞出来改,然后CPU将改完的数据设置为M。CPU1将当前cache line中的数据设置为I(无效)。
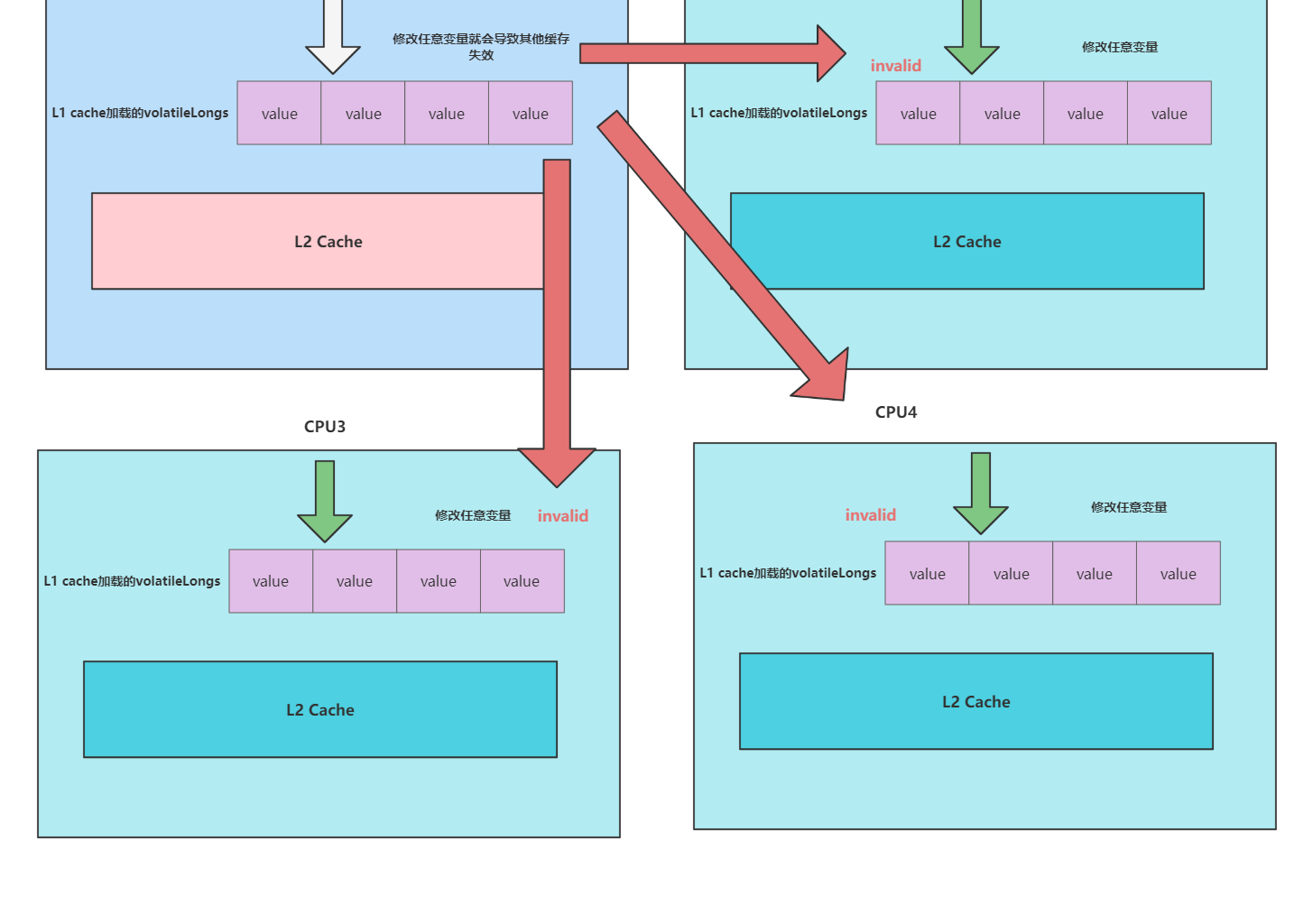
如上所说,CPU1和CPU2缓存都有AB数据,只要一方修改了A或者B,就会导致对方缓存数据失效,虽然保证了缓存一致性,却失去的一定的性能。这就是所谓的伪共享问题
# 避免伪共享的方法
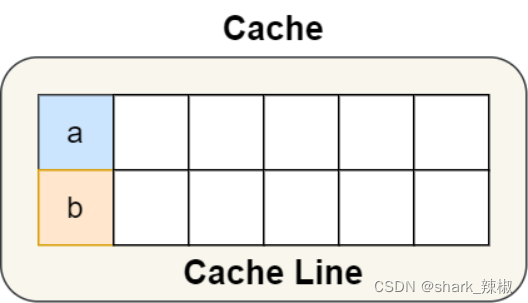
# 空间换时间
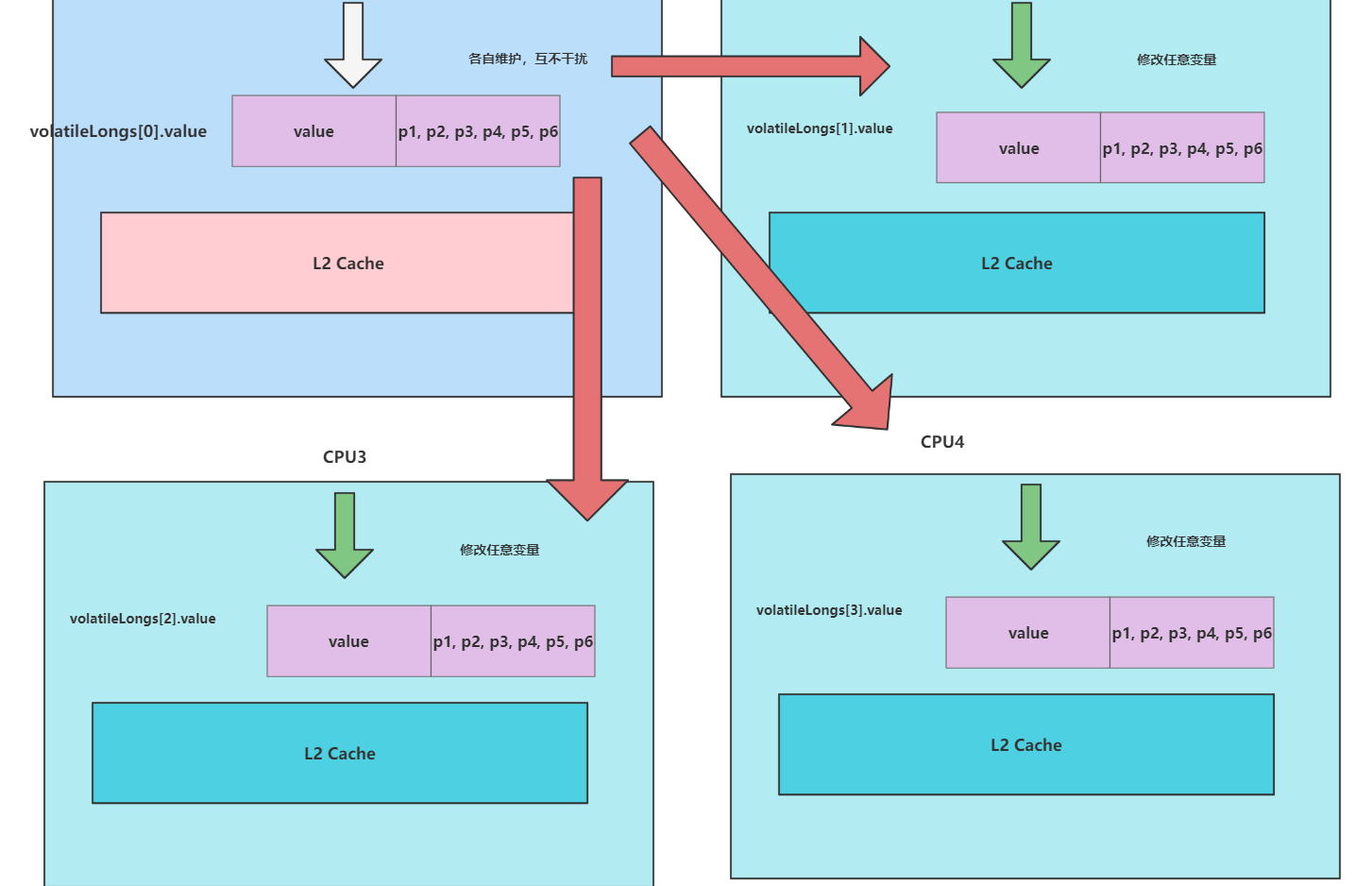
无论是算法还是说明,计算机解决性能的问题常用的手段就是空间换时间,如下图所示,我们既然都知道CPU的cache line是64k,那么我们为什么不让a占一个cache line大小的内存,b也占一个cache line的内存。 这样CPU1加载cache line只会加载到一个变量,这样就保证了双核的计算机,只要不把这个从缓存中移出,数据的加载都会在cache中读取,性能就得到了保证。
# Java中的伪共享解决方案
# 示例1
如下所示,这段代码就是要做的很简单,就是开4个线程,将一个长度的4的数组对象的value元素设置为0,读者不妨尝试将带有屏蔽此行的成员变量注释再解注释看看效果。
可以发现添加注释后的运行时间为:6573820850
去掉注释后的时间为:15142851950
public class FalseShareTest implements Runnable {
private static Logger logger = LoggerFactory.getLogger(FalseShareTest.class);
// 线程数
public static int NUM_THREADS = 4;
// 迭代次数
public final static long ITERATIONS = 500L * 1000L * 1000L;
//数组索引
private final int arrayIndex;
private static VolatileLong[] volatileLongs;
//计时
public static long SUM_TIME = 0l;
public FalseShareTest(final int arrayIndex) {
this.arrayIndex = arrayIndex;
}
public static void main(final String[] args) throws Exception {
for (int j = 0; j < 10; j++) {
logger.info("第[{}]次工作", j);
if (args.length == 1) {
NUM_THREADS = Integer.parseInt(args[0]);
}
//要进行操作的变量数组,我们可以根据需要注释填充物解决为共享问题
volatileLongs = new VolatileLong[NUM_THREADS];
for (int i = 0; i < volatileLongs.length; i++) {
volatileLongs[i] = new VolatileLong();
}
final long start = System.nanoTime();
//运行业务逻辑
runTest();
final long end = System.nanoTime();
SUM_TIME += end - start;
}
System.out.println("平均耗时:" + SUM_TIME / 10);
}
private static void runTest() throws InterruptedException {
Thread[] threads = new Thread[NUM_THREADS];
for (int i = 0; i < threads.length; i++) {
//每个线程根据i修改VolatileLong数组的value值
threads[i] = new Thread(new FalseShareTest(i));
}
for (Thread t : threads) {
t.start();
}
for (Thread t : threads) {
t.join();
}
}
@Override
public void run() {
long i = ITERATIONS + 1;
// 修改对象value的值
while (0 != --i) {
volatileLongs[arrayIndex].value = i;
}
}
public final static class VolatileLong {
//value是多个线程要操作的数据,并用volatile保证可见性
public volatile long value = 0L;
public long p1, p2, p3, p4, p5, p6; //屏蔽此行
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
原因也很简单,我们都知道long类型占了8个字节,如果添加了注释,那么四个线程要操作的数组volatileLongs将会被加载到同一个cache line中,如下图所示,试想一下一个线程操作value使得其他cpu中的cache line失效的场景:
原因也很简单,我们都知道long类型占了8个字节,那么每个CPU的cache line就能够将所有volatileLongs加载到自己的缓存空间。这就导致一方修改,另一方就失效。
一旦解开注释那么cache line可能就会变这样,空间换时间,伪共享问题就解决了。
# 示例2
Java8以前一般都是填充解决. 而java1.8引入了 @Contended 注解(sun.misc.Contended).如下所示,我们要操作CacheLineTest 两个long变量,我们可以使用Contended使得这俩成员变量在加载的时候,存到不同的cache line中从而避免伪共享问题。
public class CacheLineTest {
@Contended
volatile long si;
@Contended
volatile long sj;
public static void main(String[] args) throws Exception{
for (int i = 0; i < 10; i++) {
CacheLineTest c=new CacheLineTest();
Thread t1=new Thread(()->{
for (int j = 0; j < 1000_000_00; j++) {
c.si=j;
}
});
Thread t2=new Thread(()->{
for (int j = 0; j < 1000_000_00; j++) {
c.sj=j;
}
});
final long start=System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
final long end=System.nanoTime();
System.out.println((end-start)/1000_000);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# cpu如何选择线程
如下图所示,无论是进程还是线程,在Linux系统中统统称为task_struct 结构体,只不过线程共享了进程的内存地址空间、文件描述、代码段等,所以线程也被称为轻量级的进程。
而Linux内核里的调度器,都是以task_struct 为单位调度一个个任务的。
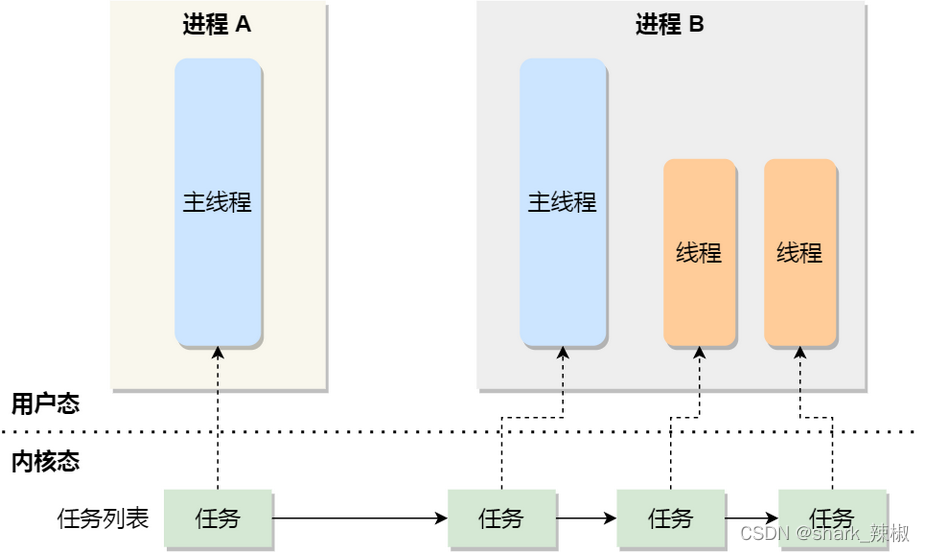
而Linux按照优先级的分类,可将一个个task_struct 任务分为实时任务和普通任务。
实时任务:对响应要求较高,一般优先级在0-99,数字越小,优先级越高。
普通任务:就是可以正常安排的任务,优先级一般在100-139,数字越小,优先级越高。
# 三个调度类介绍
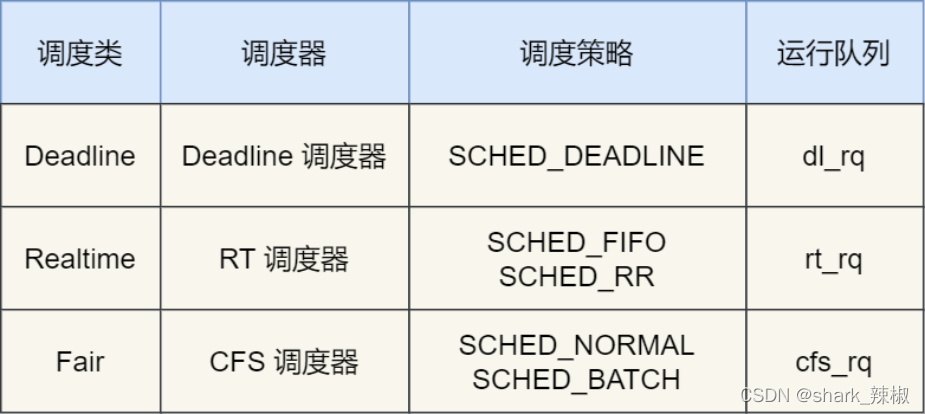
Deadline 和 Realtime 这两个调度类,都是应用于实时任务的,这两个调度类的调度策略合起来共有这三种,它们的作用如下:
SCHED_DEADLINE:是按照 deadline 进行调度的,距离当前时间点最近的 deadline 的任务会被优先调度;SCHED_FIFO:对于相同优先级的任务,按先来先服务的原则,但是优先级更高的任务,可以抢占低优先级的任务,也就是优先级高的可以「插队」;SCHED_RR:对于相同优先级的任务,轮流着运行,每个任务都有一定的时间片,当用完时间片的任务会被放到队列尾部,以保证相同优先级任务的公平性,但是高优先级的任务依然可以抢占低优先级的任务;
而 Fair 调度类是应用于普通任务,都是由 CFS 调度器管理的,分为两种调度策略:
SCHED_NORMAL:普通任务使用的调度策略;SCHED_BATCH:后台任务的调度策略,不和终端进行交互,因此在不影响其他需要交互的任务,可以适当降低它的优先级。
# 详细介绍一下完全公平调度
我们日常在Linux中跑的应用程序基本都是普通任务,Linux对这些任务设计了一个比较公平的算法,我们称之为CFS算法,即可完全公平调度(Completely Fair Scheduling)
他的工作原理也很简单,就是对每个任务都设置一个虚拟运行时间vruntime,运行越久这个值越大,CFS在每次运行时会优先选择虚拟运行时间少的运行。这样就尽可能的保证了公平性。
在公平的情况下,我们有时候也需要考虑优先级,所以Linux还增加了一个nice级别的关键字段,nice设的越小,权重就越大,而权重和虚拟运行时间的关系公式如下所示
虚拟时间vruntime+=实际时间*NICE_0_LOAD(这个东西可不管当作固定值即可)/权重
从上公式可以看出,当我们nice值设置越小,权重就越大,那么vruntime就越小,优先级就越高。
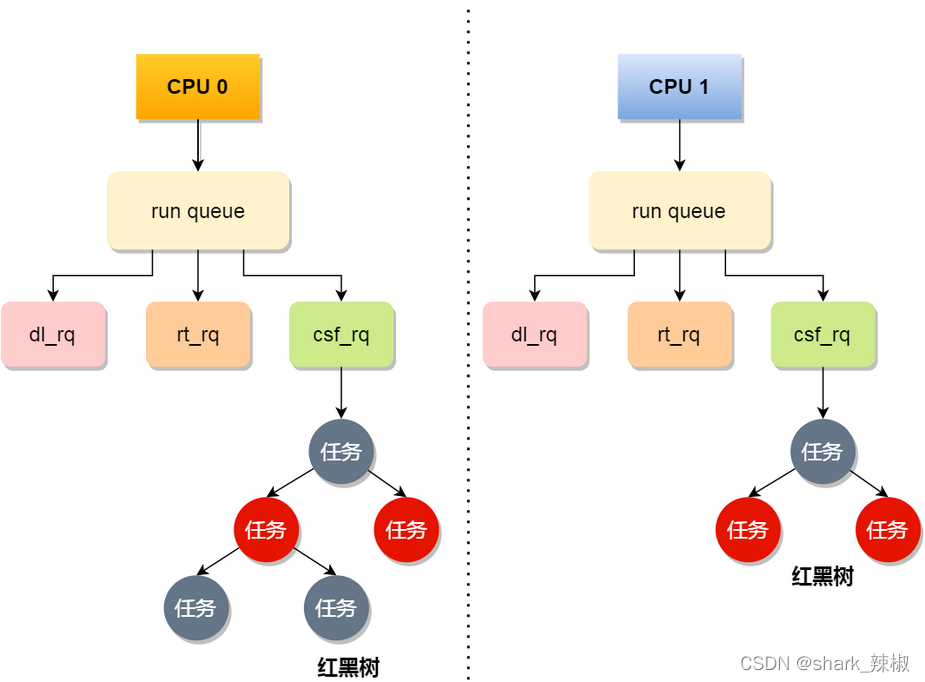
# 关于的CPU的运行队列
我们都知道操作系统任务不可能一次性运行完,所以运行不完的任务都会被存到队列中,对于不同优先级别的任务就会放到不同的队列中。
如下所示Deadline 的任务放到dl_rq, Realtime任务放到rt_rq,而 Fair任务放到csf_rq中,操作系统拿任务时也是按照Deadline > Realtime > Fair这样的顺序取任务跑的。
# 调整进程的优先级
例如我们要将普通应用的mysql优先级调高,我们就可以键入如下命令
nice -n -20 /usr/sbin/mysqld
上述命令意思也很简单,假如mysql任务级别是139那么减20,优先级就是100,就达到普通任务中的最高优先级了。

如果想修改运行中的任务优先级,我们可以使用
renice -10 -p [进程pid]
nice调整的是普通任务,如果你想任务搞成实时任务,我们可以使用如下命令,即将任务搞成实时任务,并且优先级为1,策略为SCHED_FIFO,先来先服务
chrt -f 1 -p [进程pid]
# 参考文献
2.5 CPU 是如何执行任务的? (opens new window)
