 从Lucene到Elasticsearch:底层引擎与分布式搜索的进化之路
从Lucene到Elasticsearch:底层引擎与分布式搜索的进化之路
@[toc]
# 写在文章开头
elasticSearch一直是笔者希望整理的一个系列,于是elasticSearch专栏计划也提上了笔者的写作日程,本篇文章将作为一个引子,笔者将从lunece开始逐步讲解elasticSearch的设计理念和工作机制,希望对你有帮助。

Hi,我是 sharkChili ,是个不断在硬核技术上作死的技术人,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
# 详解lucene的基本概念
# lucene如何实现快速检索
假设我们现在有这样极端文本数据:
1. hello world
2. elasticSearch in action
3. redis in action
4. effective java
5. i am sharkchili
2
3
4
5
我们希望从中找到elasticSearch这个关键词的数据,若按照原有的关系型数据库查询思路,我们就需要遍历并逐一比对文本关键词才能获得目标文本。
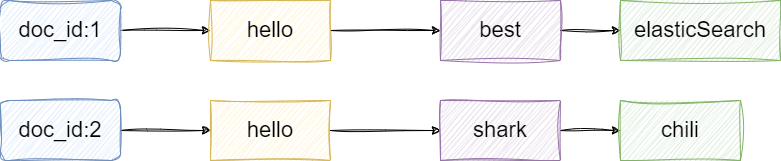
考虑到查询效率,lucene提出一个优化思路,即基于上述文本,我们以单词为单位生成多个词项,也就是term,以这些词项作为索引与文本id进行关联,查询时我们只需匹配到对应词项即可快速定位到文本id也就收document_id。
基于这个文本id我们又可以快速定位到对应的文本文档数据,需要补充的是,lucene中文档内容有个专业的术语——行式存储(store fields),我们将词项term以及对应的文档id和存储字段stored fields这几个概念组合在一起,就构成下图中这样一个便于检索数据的数据结构:

# 优化词项检索——倒排索引
# 倒排索引的基本概念
我们的文本远远不止这些词项,随着时间的推移需要维护的词项越来越多,基于当前的场景,我们的查询词项时需要进行扫描遍历,平均下来时间复杂度为O(n),于是lucene提出将这些词项按照字典序从小到大进行排序,通过二分查找法将时间复杂度从O(n)提升为O(logN)。
我们再整理一下这些简单的概念:
- 排序的字典统称为
term dictionary。 - 字典匹配的文本文档统称为
posting list。
这几个部分构成共同构成lucene的核心——倒排索引(Inverted Index)。

这种方案还是存在问题,随着词项逐渐增加,查询性能仍然会逐渐降低,即使是二分查询,我们也无法将如此庞大的term dictionary加载到内存中进行查询处理,所以我们需要通过一套方案提升快速检索term dictionary的效率。
于是就有了term index,它通过一个树形结构,按照词项前缀构成一颗有序树,将相关前缀挂到同一个树节点上,通过少量的内存存储这颗目录树,从而完成快速检索到磁盘中的term dictionary的物理地址,进而提升检索文本文档的速度:

# 倒排索引和正排索引的比较
正排索引也就是和倒排索引相反的概念,即通过文档去维护各个关键字的信息,所以相较于倒排索引,正排索引在关键词检索需要扫描文档上的词项,所以在查询性能上远不如倒排索引,但也因此避免了各个关键词项对于相关文档的关联,每次更新都是针对文档维度的修改,相较于倒排索引来说维护成本会小很多。
# 优化数据排序
有时候我们还希望检索的数据可以看到我们的规则进行排序,例如我们希望检索到的elasticSearch关键字相关文本的插入日期排序。尽管我们可以查询出来在内存中进行排序,但为了提升排序的性能,lunece利用了空间换时间的思想,通过doc value将文本需要排序的关键字整合起来,如此一来当我们检索到相应的数据时,就可以基于doc value得到排序结果:

# 提升数据读写
基于上述的概念,我们将Inverted Index、term index、doc value、store fields等概念组合起来,就构成lucene中一个非常重要的文件segment。lucene支持将多份文档写入一个segment中,并且为了保证并发写入的效率,lucene提出每次一旦segment生成后就不可修改,所有新的写操作都在新的的segment中进行。
segment也会不断增加,此时lucene底层就会将这些相关的segment进行合并构成一个大的segment。
这种设计导致要检索的数据可能分布在不同的segment上,所以lucene在进行数据检索查询时,往往会通过并发查询并将结果聚合的方式完成:

这种设计依然存在并发场景下大量请求读写导致资源争抢而阻塞,所以lucene通过index name区分不同的lucene完成缓解并发读写的压力:
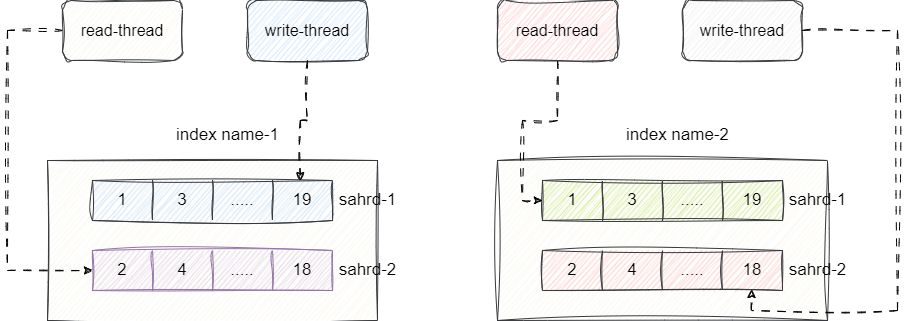
然后基于这个基础再将每个lucene内部再次进行分片,通过shard方式对lucene再次进行切片,然后分摊到多台服务器上,从缓解单台服务器CPU的压力:

# 详解ES数据类型的概念
# 详解ES常见的数据类型
# 关键词
我们先来说说关键词类型,ElasticSearch常见的关键词类型有:keyword、constant_keyword 和wildcard。
我们先来说说keyword类型,该类型进程查询时都是整个词项进行查询,无需像text类型那样进行分词,它主要是用于精准匹配和聚合操作。
精准匹配就是用于精确查找数据,例如我们创建一个key_word_index这个索引,该索引包含product_id和product_category两个字段且都是keyword类型,进行查询时我们无论传入任何文本参数,es都不会进行分词,而是原原本本的基于这个分词返回查询结果,如果比对没有一致的,那么就说明索引中没有对应的文档:
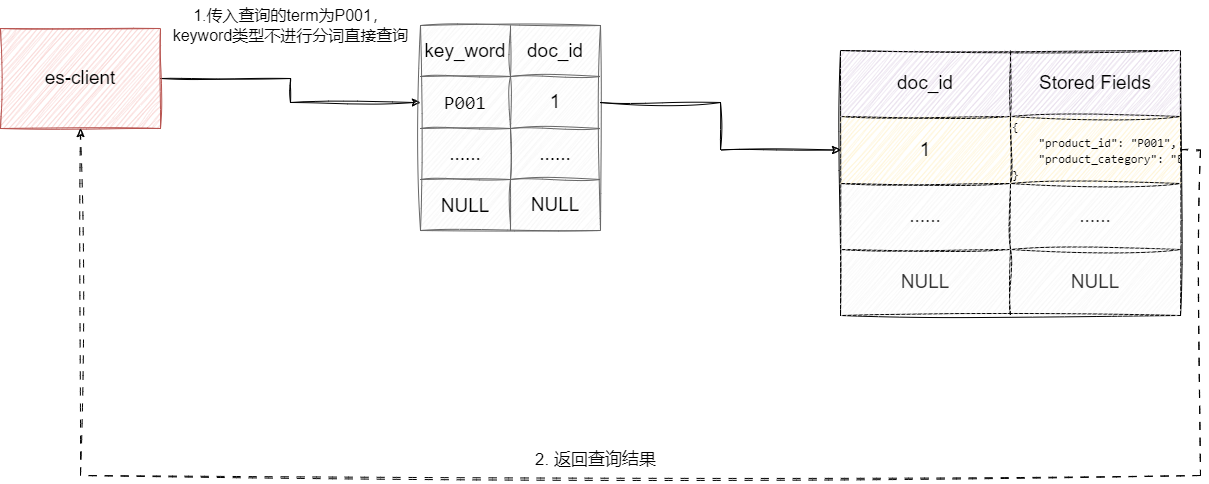
对此我们也不妨实验印证这一点,我们首先通过http的put请求键入ip:port/key_word_index创建索引,对应的参数为知名产品号和产品类别均为keyword类型:
{
"mappings": {
"properties": {
"product_id": {
"type": "keyword"
},
"product_category": {
"type": "keyword"
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
然后基于post请求xxxx:9200/key_word_index/_doc创建一份文档:
{
"product_id": "P001",
"product_category": "Electronics"
}
2
3
4
通过get请求发现ip:9200/key_word_index/_search,必须传入下面指定keyword类型才能精准匹配到数据:
{
"query": {
"term": {
"product_id": "P001"
}
}
}
2
3
4
5
6
7
而聚合操作也就收进行数据聚合分析时,因为keyword类型是精准匹配的所以在进行分类字段统计分析是可以高效完成。
我们再来说说constant_keyword类型,它工作原理和keyword差不多,唯一区别就是一旦某个字段被设置为constant_keyword,后续的文档对应字段的值都必须是相等且不可被改变,一旦被修改或者插入不一样的值就会报错。
例如笔者现在创建一份ck_index文档,指明fixed_category为constant_keyword,第一次提交或者默认创建索引时指明值为important_docs,那么后续只要fixed_category提交的值不是important_docs,就会报错:

对此我们也不妨举个例子,如下笔者基于ip:9200/ck_index创建索引:
{
"mappings": {
"properties": {
"fixed_category": {
"type": "constant_keyword",
"value": "important_docs"
},
"normal_field": {
"type": "text"
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
fixed_category使用默认值important_docs就不会报错,一旦我们基于ip:9200/ck_index/_doc指明非默认值的fixed_category就会报错:
{
"normal_field": "This is a sample document",
"fixed_category":"4"
}
2
3
4
所以在查询效率上,因为因为天然不可变以及精准匹配的特性的使得对于该类型数据检索效率相较于keyword会更加高效。
最后一种wildcard类型,这种比较少见,常用与类似于正则或者模糊匹配的场景,创建后使用查询样例大体如下,这里笔者就不多做演示了:
GET books/_search
{
"query": {
"wildcard": {
"title": "*search*"
}
}
}
2
3
4
5
6
7
8
总的来说,这种类型设计通配符查询所以性能上相较于精准匹配效率会低效很多,所以这种类型只适合于数据量小且查询方式多样的场景。
# 基本类型
基本类型其实也和一般的编程语言一样,对应数值类型有:
longintegershortbytedoublefloathalf_floatscaled_float
布尔型的boolean,然后就是日期型中的date和date_nanos,最后就是二进制中的binary类型。
# 结构化数据类型
结构化数据类型比较少使用,相对常见的是分范围型和ip地址类型,我们先来说说范围类型,该类型通过指明文档字段的数值区间,查询时也是通过区间进行查询,只要文档的区间在查询区间存在交集就会返回。
例如我们的索引中的创建一个数值类型price_range,创建一份文档的区间是10~20,如果此时我们查询的数值为15~25,那么10~20这份文档就会返回:
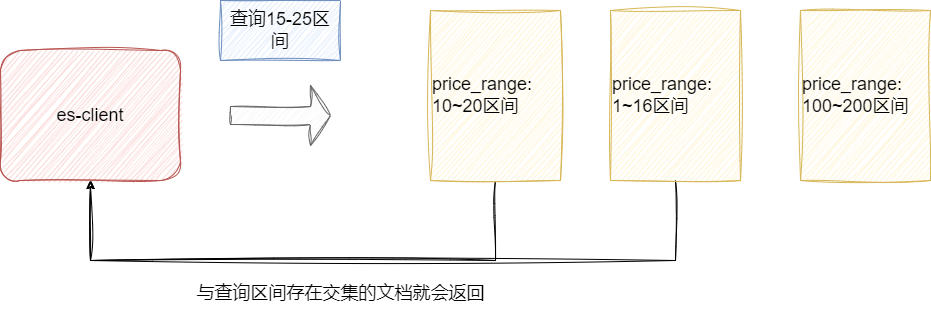
对此我们可以通过put指令创建一个测试索引:
PUT range_index
{
"mappings": {
"properties": {
"price_range": {
"type": "integer_range"
}
}
}
}
2
3
4
5
6
7
8
9
10
然后创建一份区间在10~20的文档:
POST range_index/_doc
{
"price_range": {
"gte": 10,
"lte": 20
}
}
2
3
4
5
6
7
此时我们查询15~25区间的数值就会看到这份文档:
GET range_index/_search
{
"query": {
"range": {
"price_range": {
"gte": 15,
"lte": 25
}
}
}
}
2
3
4
5
6
7
8
9
10
11
es除了上述的integer_range以外还有:
float_rangelong_rangedouble_rangedate_range
还有就是ip类型,该类型常用于记录ipv4和ipv6两种地址,支持范围查询,同时也支持格式校验,对于非法的ip数值,es会明确抛出错误并禁止插入。
# 文本搜索类型
文本类型算是比较常用的es类型了,它会基于我们给定的检索词按照分词器进行切词然后匹配合适结果,文本搜索类型范围:
textannotated-text(Elasticsearch 7.8.0 引入)completion
我们先来说说text类型,这是比较常规的文本类型,它旨在支持全文搜索,允许在大量文本中进行模糊匹配和相关性搜索,当我们指明字段为文本类型之后,传入的检索词汇都会按照分词器的规则进行切词,通过match或者match_phrase等手段实现不同程度的文本匹配:
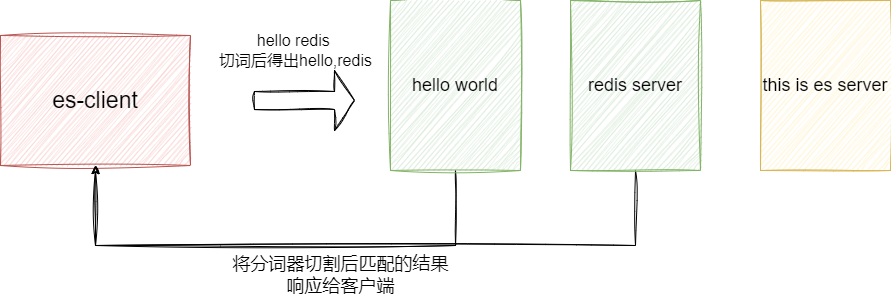
我们以上图为例创建一个带有text类型的索引:
PUT text_index
{
"mappings": {
"properties": {
"article_content": {
"type": "text"
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
然后尝试插入上图中的几份文档,这里笔者就以hello word为例给出样例:
POST text_index/_doc
{
"article_content": "hello word"
}
2
3
4
最后进行查询时就会查到redis server和hello world两份文档:
GET /text_index/_search
{
"query": {
"match": {
"article_content": "hello redis"
}
}
}
2
3
4
5
6
7
8
而annotated-text 则是text中的一个特殊的变种,主要是针对文本类型加以各种注释的文本结构,如下所示的annotated_text_field就是针对text文本通过annotation数值进行各种注释的典型用例。
因为支持结构化注释等特性,所以该类型支持根据注释信息进行过滤、分组、排序:
POST annotated_text_index/_doc
{
"annotated_text_field": {
"text": "Apple is looking at buying U.K. startup for $1 billion",
"annotations": [
{
"type": "entity",
"start": 0,
"end": 5,
"value": "Apple",
"category": "company"
},
{
"type": "entity",
"start": 23,
"end": 31,
"value": "U.K.",
"category": "country"
},
{
"type": "entity",
"start": 34,
"end": 40,
"value": "startup",
"category": "organization"
}
]
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
最后就是completion类型,它更多是强调对于相关性搜索的概念,例如下面completion_index索引中的suggestions就是completion类型,当我们插入下面这些数据后,通过搜索app时,他就会返回apple这个相关性的字段推荐。
所以该类型常用于搜索引擎中的输入关键词推荐功能:
POST completion_index/_doc
{
"suggestions": [
"apple",
"banana",
"cherry"
]
}
2
3
4
5
6
7
8
# 对象关系类型
对象关系类型强调对象间的组合关系,常见的两种对象关系大类有:
- 嵌套类型:
nested、join - 对象类型:
object、flattened
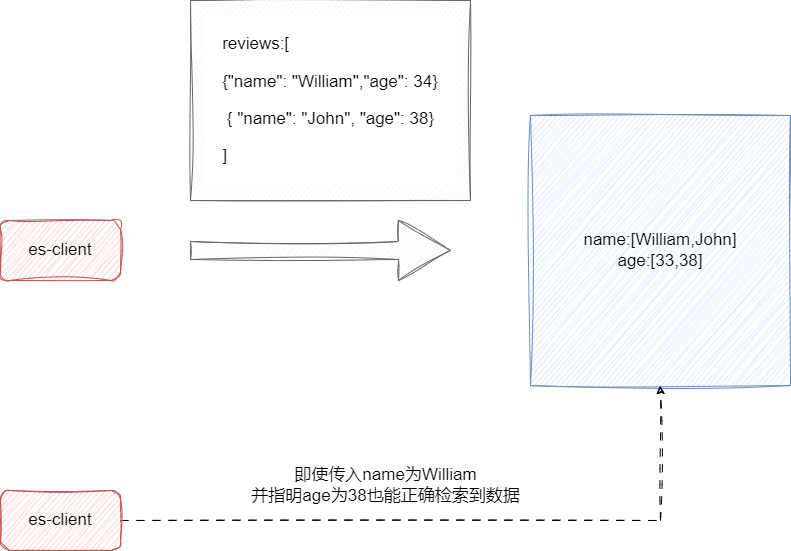
关于es的object类型也就是我们广义上所说的JSON类型,这里就不多做赘述。我们以nested类型为例讨论一下这样一个场景,我们希望通过es的review字段记录所有评论者信息,默认情况下我们使用object类型,对应传参如下图所示。
遗憾的是,es底层的lucene并没有针对该类型进行结构化,所以进行存储的时候,reviews会按照字段的方式归类并构建成一个个字段数组,这也就是为什么我们在查询38岁的William还是可以返回数据:

所以为了保证这种结构化数据的完整性,我们提出了nested类型,基于上述示例我们将评论者的定义声明为nested类型演示一下:
PUT nested_example_index
{
"mappings": {
"properties": {
"product_name": {
"type": "text"
},
"reviews": {
"type": "nested",
"properties": {
"reviewer_name": {
"type": "text"
},
"rating": {
"type": "integer"
},
"comment": {
"type": "text"
}
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
然后我们声明一份文档,该文档给出两名评论员:
POST nested_example_index/_doc
{
"product_name": "Sample Product",
"reviews": [
{
"reviewer_name": "Alice",
"rating": 4,
"comment": "This product is great!"
},
{
"reviewer_name": "Bob",
"rating": 3,
"comment": "It's okay, but could be better."
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
此时我们查询评分为4且名称为Alice评论的文章,就会返回上述我们创建的文档:
GET nested_example_index/_search
{
"query": {
"nested": {
"path": "reviews",
"query": {
"bool": {
"must": [
{
"match": {
"reviews.rating": 4
}
},
{
"match": {
"reviews.reviewer_name": "Alice"
}
}
]
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
nested类型将每个对象单独结构化,针对单个对象的字段使用数组的方式来维护,从而保证了对象的独立性:

join类型更多是强调文档间的父子关系,通过join可以使得不同的文档通过父子id构成关联,常用于一些需要父子结构化的数据场景:
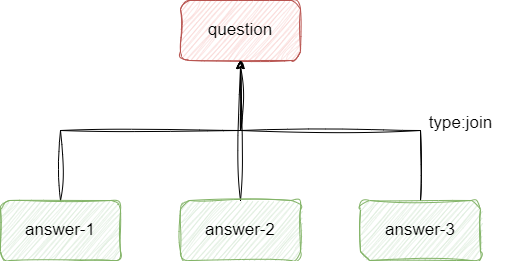
以上图为例,我们就创建一个父子索引的示例,对应的参数如下所示可以看到当前索引声明my_join_field字段并通过relations指明question和answer之间的关联父子关系:
PUT my_index
{
"mappings": {
"properties": {
"text":{"type": "keyword"},
"my_join_field": {
"type": "join",
"relations": {
"question": "answer"
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
然后声明一个id为1的quesion:
PUT my_index/_doc/1?refresh
{
"text": "我是第一个问题",
"my_join_field": {
"name": "question"
}
}
2
3
4
5
6
7
创建问题关联的答案时,通过parent指明其id为1和问题1进行关联,注意这里笔者用到了routing=1其目的是保证子文档和父文档即id为1的数据处在同一个分片中:
PUT my_index/_doc/3?routing=1&refresh
{
"text": "问题一的答案1",
"my_join_field": {
"name": "answer",
"parent": "1"
}
}
2
3
4
5
6
7
8
后续我们就可以直接通过指明parent_id为1得到问题1的答案answer:
GET my_index/_search
{
"query": {
"parent_id": {
"type": "answer",
"id": "1"
}
}
}
2
3
4
5
6
7
8
9
10
需要补充的是join字段中使用has_child和has_parent查询都会对查询性能有着重大的影响,该查询会随着唯一父文档匹配的子文档数量增加而降低,不过结合网上压测的说法,在5个分片的情况下,十万级父表和千万级子表关联耗时基本是可以在100ms内完成,这一点对于大部分B端程序都是可以接受的。
总言之,join类型能少用尽量少用,在业务允许的情况下,我们更希望用户可以通过非规范化文档即宽表冗余的方案解决问题。
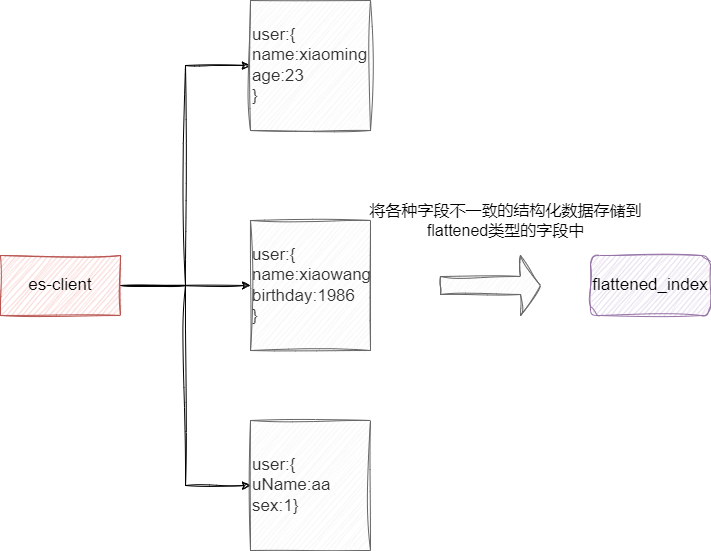
最后就是flattened类型了,我们都知道es在没有创建索引的情况下,插入文档时es会根据文档字段推断出相应字段类型完成索引创建。
这种做法也存在一定的局限性,例如某个json类型数据中键值对是动态变化的,我们无法完全统计出类型并进行创建,此时我们就可以将该类型声明为flattened,声明字段为该类型之后,我们所传入的值es都会动态解析出leaf并将它们作为关键索引存入字段中。所以,对于存在大量或者未知数量的JSON对象存储是非常有用的管理手段。
如下图所示,可以看到相同的user类型即使有不同的字段数据都可以动态的插入到flattened_index中:
基于上述说法我们给出labels这个flattened类型:
PUT bug_reports
{
"mappings": {
"properties": {
"title": {
"type": "text"
},
"labels": {
"type": "flattened"
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
此时我们就可以按照各种格式的JSON进行动态的插入数据:
POST bug_reports/_doc/1
{
"title": "Results are not sorted correctly.",
"labels": {
"priority": "urgent",
"release": [
"v1.2.5",
"v1.3.0"
],
"timestamp": {
"created": 1541458026,
"closed": 1541457010
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
查询时给只需给定某个字段的值即可得到整份文档的数据,可以看到flattened类型是支持精准查询的,但是对于某些数字范围查询和高亮显示都不支持:
GET /bug_reports/_search
{
"query": {
"term": {
"labels": "v1.2.5"
}
}
}
2
3
4
5
6
7
8
# 空间类型
控件类型常用于存储地理坐标等数据,常见的有如下类型,比较少用,读者了解一下即可:
- 地理坐标类型:geo_point
- 地理形状类型:geo_shape
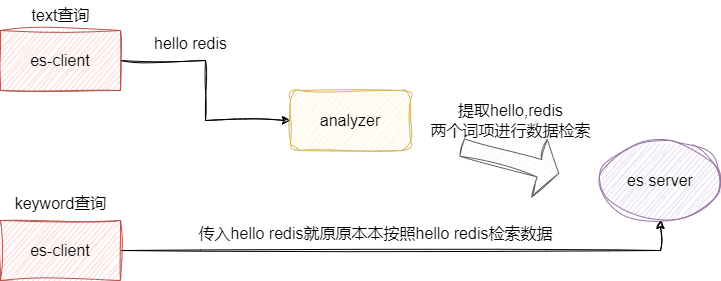
# keyword和text的区别
text格式进行数据检索的时候会经过分词的步骤,通过分词得到词项后在进行数据检索,而keyword则是直接作为检索词项进行查询,所以相比之下后者的查询效率会相对高效一些:
# 详解nest数据类型的基本概念
传统对象传入对象数组进行查询时会因数组扁平化导致查询时多字段笛卡尔积检索问题:
而nest本质上就是保持对象数组中各个对象的独立性,底层会将对象数组中每个对象独立划分,保证查询的维度能够精准的定位到数组中各个独立的对象,避免上述的问题:

# ES是否存在数组类型
没有明确定义数组类型,但是每个字段可以用数组格式符记录多个值,所以也是间接的存在数组类型,就像下面这个timestamp类型就是基于多字段构成的数组:
{
"title": "Results are not sorted correctly.",
"labels": {
"priority": "urgent",
"release": [
"v1.2.5",
"v1.3.0"
],
"timestamp": {
"created": 1541458026,
"closed": 1541457010
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# ES是否支持在mapping中直接修改字段类型
不支持,ES中的mapping可以类比于MySQL中的schema,所以mapping中的字段类型在存在数据的情况下是不能修改,但可以增加,如果需要修改只能通过reindex等方式进行重建。
# 如何防止mapping字段无限增加
可以参考es官网给出的这几条配置加以限定:https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-settings-limit.html (opens new window)
# 详解ES中mapping的概念
# 什么是mapping
本质上就是对索引中字段名称、数据类型、优化信息(是否索引)结构的定义,相当于数据表结构的schema,一般情况下一个index对应一个mapping。需要了解的是mapping范围动态mapping和静态mapping,前者会在用户提交索引数据时动态创建和映射,而后者则是通过PUT请求显示创建。
# 为什么插入数据不用指定mapping
es接受插入数据请求时会检查该索引是否存在,如果不存在则会基于参数进行推断并创建相应的索引,但是索引类型往往会和预期的有所出入,所以我们一般不建议自动创建。
# 如何保证某些字段不被索引
将index设置为false即可,如下所示:
PUT my_index/_mapping
{
"properties": {
"title": {
"type": "text",
"index": false
}
}
}
2
3
4
5
6
7
8
9
当我们插入数据时,通过description进行检索就会抛出failed to create query: Cannot search on field [description] since it is not indexed.这个异常:
POST my_index/_doc
{
"title": "示例文档标题",
"description": "这是一段示例描述",
"notes": "一些额外的备注信息"
}
2
3
4
5
6
# 详解elasticSearch的设计理念
# elasticSearch解决了什么问题及其使用场景
elasticSearch简称为es,是一款基于lucene实现的开源搜索引擎和分析引擎,它常被作用于以下几个功能:
- 数据全文检索。
- 结构化查询。
- 数据分析。
并且es对外提供restful webapi接口,所以我们可以非常方便的通过这些api接口快速完成数据查询与检索。
# 基于关系型数据库理解elasticSearch中的核心概念
初学ES的读者可能对于ES某些概念比较陌生,笔者就以关系型数据库作为比对简单介绍一下ES中的一些核心概念:
索引(index):一个索引代表具有相似特征的文档的集合,ES中索引的概念可以对应关系型数据库的数据表的概念。文档(document):即上文中索引所管理的一份数据,作为搜索的最小单位,对应关系型数据库中的行 ,es中的文档也是由于多个字段构成,字段的类型也可以是布尔、数值、字符串、二进制和日期类型等。- 类型(Type):每个文档在
ES中都有它对应的针对不同版本的es字段类型都有着不同的说法:
1. es6允许一个索引中有多个type
2. es7一个索引中只能创建一个类型_doc
3. es8直接取消了type这个概念
2
3
4
- 映射(mapping):我们可以直接将其理解为数据库中
schema,es中的mapping包含一份索引中字段名称、字段类型、分词器、是否索引的等定义。需要注意的是es6.0版本一个索引可以有多个mapping,但是在7.x之后的版本一个索引只能有一个mapping。 - 倒排索引
(Inverted Index):对应数据库中的索引,用于提升检索数据速度的。 - 字段
(sort fields):对应数据库中的列的定义。 DSL语句:用于ES数据查询检索的语法,对应关系型数据库的SQL语句。- 节点(node):每一个es实例都可以视为一个节点。
- 集群(cluster):基于上述es实例构建出一个集群将es水平拓展提升整体检索性能和吞吐量。
- 分片 (shard):相当于对于索引的水平拓展,将某个索引切分后分散到不同的节点中分散读写压力。
- 副本(replica):每一个es实例都可以视为一个节点,而节点也有主节点和从节点的概念,副本就是同步主节点的数据,保证主节点下线后副本节点直接晋升并对外提供服务。
# 自定义路由的好处是什么
默认路由会保证数据会均匀发布在每一个分片上,这使得某些查询结果需要向多个分片发送结果再进行归并、过滤、聚合,在数据量较大的情况下,查询的性能表现会非常差劲。
通过自定义路由保证按照自己的要求计算得出路由地址并通过routing参数指定,保证数据都能存放到同一个分片下,从而提升数据检索效率。
# 如何查看ES集群的鉴康状态
通过restful接口调用如下地址即可:
ip:9200/_cluster/health
# 如何完成高可用
按照常规的实现思路,为避免单个分片shard宕机导致服务不可用,ES是通过主从复制的方式保证shard分片主从数据同步,由此保证主分片(primary shard)服务不可用时,从分片(replica shard)可以直接取代主分片对外提供服务:

# 为什么需要角色化节点
ES不同的工作会交由不同的角色,分别是:
- 主节点
(master node):负责集群管理。 - 协作节点
(coordinate node):负责接收客户端搜索查询的所有请求。 - 数据节点
(data node):负责存储管理数据。
上文为了做到缓解单机压力,通过增加一个个具备所有功能的节点,显然这种做法会带来各种非必要的系统资源开销是非常不可取的。
所以,我们可以针对角色的维度进行拓展,例如:若我们希望拓展数据检索的能力,就可以将协作节点进行拓展,由此保证通过尽可能少的资源完成拓展保证服务可靠性。

# 如何实现主节点选举
为了减少系统的复杂度,ES并没有采用中心化进行主节点选举,取而代之的是通过Raft协议实现节点间集群节点通信,通过各个节点间数据信息交换完成各个节点实时状态更新和主节点下线时的选举:

# 如何完成数据写入
此时我们就完成了ES架构的,基于这套架构,我们简单介绍一下数据写入的流程:
- 客户端发起写请求。
- 请求分发到协作者节点也就是上文所说的coordinate node。
- 协作节点根据
hash算法定位到对应的主shard。 - 基于传入数据生成
inverted Index、doc value和store fields等信息。 - 将这些信息写入
shard底层lucene对应的segment中。 - 复制到从
shard中。 - 返回
ack告知客户端写入结果。

# 如何完成数据查询
同理我们再给出客户端检索数据的全流程:
- 客户端发起查询请求,到达集群中的协调节点。
- 协调节点根据
index name得到所有分片信息,从而定位到对应的主分片数据节点。 - 并发查询主分片中所有
segment,利用倒排索引定位文档id。 - 基于
doc value完成排序。 - 协调节点聚合结果并舍弃无用数据返回给协调节点。
- 将结果告知客户端。

# 分片数量如何设计(重点)
针对分片数量的设计,笔者建议从以下几个问题入手:
- 单个分片大小多少合适?
- 一个索引设置多少个分片合适?
- 一个索引副本分片设置多少合适。
- 单个节点允许多少个分片合适?
- 设置多少个节点合适?
先回答问题1:本质上分片都是由一个个lucene索引实例,每个lucene都是持有文件句柄的单独文件,这也就意味着每个分片都会占用文件句柄和、内存、CPU资源,过多的分片也会占用过多的系统资源导致系统资源吃紧。
按照ES社区的说法,单个分片尽量保持在50G以内可以保证数据再平衡(故障转移)的效率,就笔者的经验而言,ES建议堆内存尽量不要超过32G(避免指针压缩失效),按照极限思维单个分片单位时间内进行全量转移,单个分片应该尽量保持在30G左右比较合适。
再来所说问题2:按照ES社区所给的经验法则,每GB不超过20分片且分片越少越好,结合上述单个分片的最大值来说,假设我们单个索引最大值为200G,那么分片数尽量设置为200/30≈7个左右分片,尽量不要超过20个,如果超过这个值则考虑索引设计层面考虑需要进行水平拓展。
然后就是问题3:ES 6默认情况下是5主然后每个主分片都有1个副本,7之后改为1主1副,在分布式场景下笔者认为7版本的策略足够,如果读者对于高可用要求相对高一些,建议设置2个副本即可,这里我们也给出对硬分片设置的语法:
PUT /testindex
{
"settings" : {
"number_of_shards" : 7,
"number_of_replicas" : 2
}
}
2
3
4
5
6
7
8
问题4:按照业界公认的说法,单个节点分片数尽量结合堆内存来进行推算,假设我们的堆内存为32G,那么分片数最多是允许32*20即600个分片(从 8.3 版开始,我们大幅减小了每个分片的堆使用量,因此对本博文中的经验法则也进行了相应更新。请按照以下提示了解 8.3+ 版本的 Elasticsearch),所以我们认为每个节点分片数7~8个分片左右是比较合适的。
问题5:这就是解决问题的最后一步了,节点数的设置,我们可以结合上述步骤推算出所需分片数,然后按照总分片数/单节点分片数最大值得出最后的节点值,例如通过上述计算我们的业务大体需要25个分片,按照每个节点7~8个分片,我们的节点最好设置在5个左右。
当然,上述都是结合偏向理论的说法,具体而言建议读者参考这套方案结合业务场景进行基准测试做出调整。
# 小结
自此,我们通过lucene基础开始为始,逐步展开详细介绍了ES的基本概念,由此了解ES的架构和设计理念,希望对你有帮助。
我是 sharkchili ,CSDN Java 领域博客专家,mini-redis的作者,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。 因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
# 参考
ES详解 - 认知:ElasticSearch基础概念:https://www.pdai.tech/md/db/nosql-es/elasticsearch-x-introduce-1.html (opens new window)
elasticSearch 是什么?工作原理是怎么样的?:https://mp.weixin.qq.com/s/RUQXIyN95hvi2wM3CyPI9w (opens new window)
https://www.cnblogs.com/-wenli/p/12763887.html
https://blog.csdn.net/laoyang360/article/details/82950393
https://blog.csdn.net/ubuntutouch/article/details/103713730
https://www.cnblogs.com/vincentfhr/p/14006855.html
https://blog.csdn.net/ubuntutouch/article/details/103713730
https://blog.csdn.net/weixin_43930865/article/details/106445387
https://www.elastic.co/cn/blog/how-many-shards-should-i-have-in-my-elasticsearch-cluster
https://www.cnblogs.com/c9999/p/13686126.html
