 Netty Reactor模型常见知识点小结
Netty Reactor模型常见知识点小结
# 写在文章开头
Netty作为一款强大的高性能网络编程框架,其底层Reactor的设计理念和实现都是非常值得我们研究和学习了解的,本文将从以下几个问题为导向,带读者深入理解netty reactor线程模型:
- Netty有Reactor线程模型
- Netty如何实现Reactor模式
- 为什么 main Reactor线程池大部分场景只用到一个线程
- Netty线程分配策略是什么
- Netty中的IO多路复用的概念
- Netty基于哪几个组件搭配实现IO多路复用
- Netty如何实现通用NIO多路复用器
- Netty如何优化工作线程调度平衡
- Netty如何解决CPU 100% 即空轮询问题
- Netty对于事件轮询器做了哪些优化?
- Netty无锁化的串行设计理念
Hi,我是 sharkChili ,是个不断在硬核技术上作死的技术人,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
# 详解Netty Reactor网络模型
# Netty有Reactor线程模型
Reactor模型的用户层面的IO模型,按照结构它可分为:
Reactor单线程Reactor多线程- 主从
Reactor模型
先来说说单Reactor单线程模型,每个客户端与服务端建立连接时,所有的请求建立、读写事件分发都由这个Reactor线程处理。很明显,所有的连接建立、读写和业务逻辑处理等工作都分配到一个线程上,对于现如今多核的服务器场景,这种方案未能很好的利用CPU资源,对应高并发场景表现也不算特别出色(会比传统的BIO好一些):
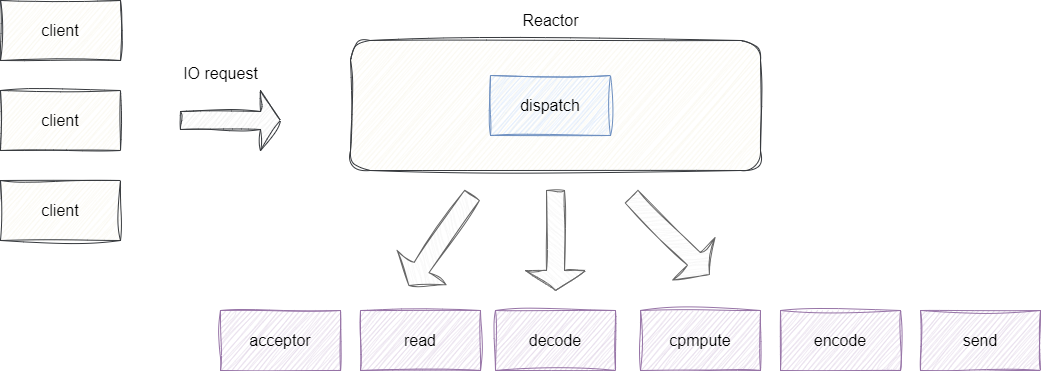
于是就有了单Reactor多线程模型,与前者相比,Reactor监听到就绪的IO连接并建立连接后,它会将所有的读写请求交给一个业务线程池进行处理。
该模型较好利用了CPU资源,提升的程序执行效率,但是面对大量的并发连接请求时,因为只有一个Reactor处理IO请求,系统的吞吐量还是没有提升。
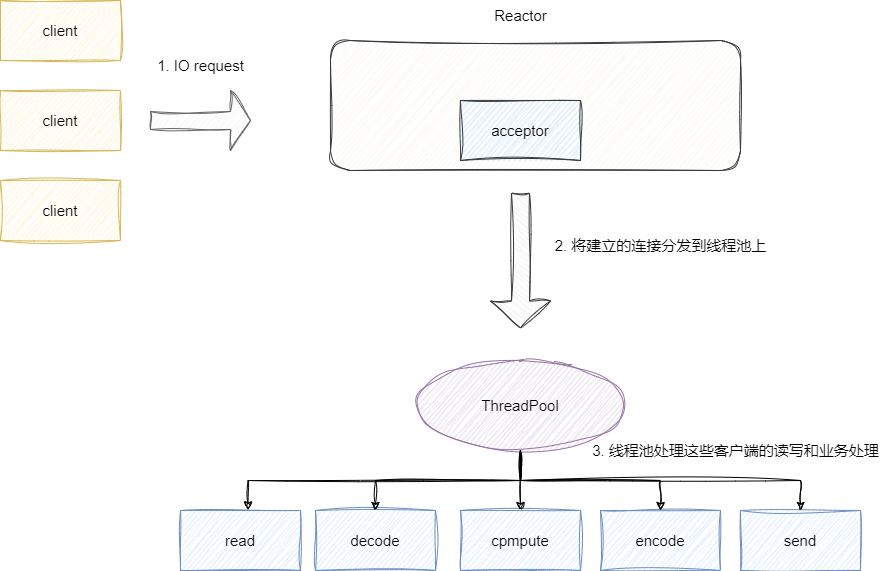
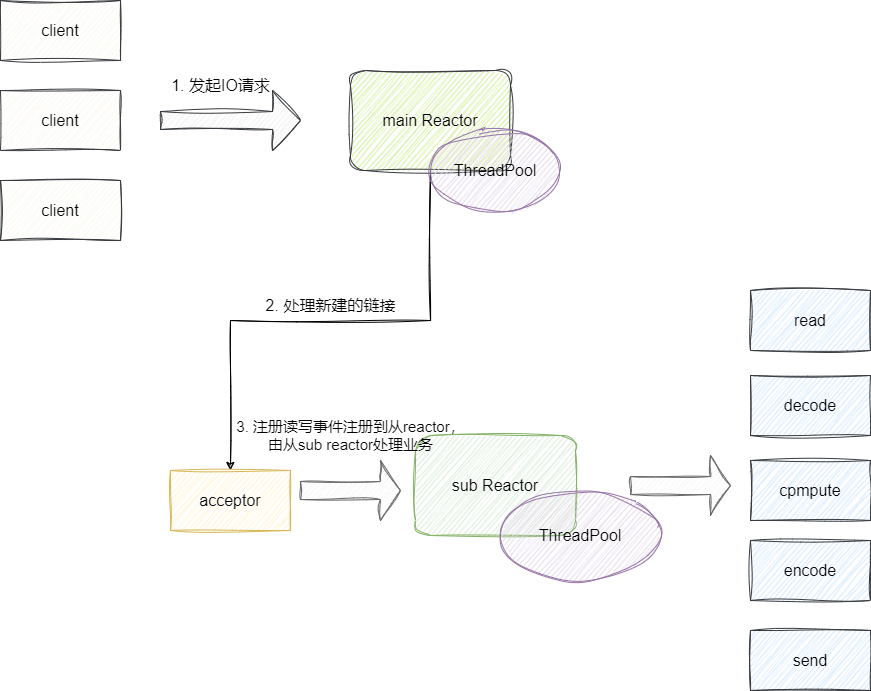
最后就是主从Reactor模型,也就是如今主流的Reactor模型,该模型为用分为主Reactor和从Reactor,各自都是以线程池的形式存在,由主Reactor专门处理连接事件,随后将每个建立连接的客户端socket读写事件注册到从Reactor中,由从Reactor负责处理这些读写以及业务逻辑。
主从Reactor模型是一种改进的事件驱动编程模型,相比于单Reactor单线程模型,它具有以下几个优势:
多线程并发处理:主从
Reactor模型允许多个线程同时处理事件,每个线程都有一个独立的Reactor负责事件分发。这样可以充分利用多核处理器的优势,提高系统的并发处理能力和性能。高吞吐量:由于使用了多线程并发处理,
主从Reactor模型能够同时处理多个事件,从而提高系统的吞吐量。每个线程都可以独立处理事件,不会被其他事件的处理阻塞。负载均衡:
主从Reactor模型中,主Reactor负责监听和接收连接请求,然后将连接分配给从Reactor进行具体的事件处理。这种分配方式可以实现负载均衡,将连接均匀地分配给多个Reactor,避免某个Reactor的负载过重。异步IO支持:主从
Reactor模型可以结合异步IO技术,充分利用操作系统提供的异步IO接口。这样可以在进行IO操作时立即返回,不会阻塞线程,提高系统的并发性和响应性能。容错能力:通过使用多个Reactor和线程,主从Reactor模型具有更好的容错能力。如果某个Reactor或线程出现错误或崩溃,其他Reactor和线程仍然可以继续处理事件,保证系统的正常运行。
主从Reactor模型通过多线程并发处理、负载均衡、异步IO支持和容错能力的提升,能够更好地满足高并发、高性能的网络应用程序的需求。
# Netty如何实现Reactor模式
通过上文我们大体了解了几种常见的Reactor模式,实际上Netty已经将这三种Reactor模式都封装好了,假设我们需要单Reactor服务端,只需指明NioEventLoopGroup的线程数为1即可:
ServerBootstrap serverBootstrap = new ServerBootstrap();
NioEventLoopGroup nioEventLoopGroup = new NioEventLoopGroup(1);
serverBootstrap.group(nioEventLoopGroup);
2
3
同理多Reactor则将线程数设置为大于1即可,当然我们也可以设置NioEventLoopGroup参数为空,因为如果NioEventLoopGroup不设置参数时,该分发内部会创建CPU核心数2倍的线程:
ServerBootstrap serverBootstrap = new ServerBootstrap();
NioEventLoopGroup nioEventLoopGroup = new NioEventLoopGroup();
serverBootstrap.group(nioEventLoopGroup);
2
3
这一点我们直接步入NioEventLoopGroup内部只需流程即可看到,默认情况下我们传入的thread为0,它就取DEFAULT_EVENT_LOOP_THREADS 的值,而这个值初始情况下回去CPU核心数2倍:
//不传参时nThreads值为0,super即MultithreadEventLoopGroup
public NioEventLoopGroup(int nThreads, Executor executor, final SelectorProvider selectorProvider,
final SelectStrategyFactory selectStrategyFactory) {
super(nThreads, executor, selectorProvider, selectStrategyFactory, RejectedExecutionHandlers.reject());
}
//MultithreadEventLoopGroup看到nThreads为0则取DEFAULT_EVENT_LOOP_THREADS
protected MultithreadEventLoopGroup(int nThreads, Executor executor, Object... args) {
super(nThreads == 0 ? DEFAULT_EVENT_LOOP_THREADS : nThreads, executor, args);
}
//DEFAULT_EVENT_LOOP_THREADS 取CPU核心数的2倍
private static final int DEFAULT_EVENT_LOOP_THREADS;
static {
DEFAULT_EVENT_LOOP_THREADS = Math.max(1, SystemPropertyUtil.getInt(
"io.netty.eventLoopThreads", Runtime.getRuntime().availableProcessors() * 2));
if (logger.isDebugEnabled()) {
logger.debug("-Dio.netty.eventLoopThreads: {}", DEFAULT_EVENT_LOOP_THREADS);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 为什么 main Reactor大部分场景只用到一个线程
上文介绍Reactor模式时已经介绍到了,它主要负责处理新连接,而Netty服务端初始化时只会绑定一个ip和端口号然后生成serverSocketChannel,而每个channel只能和一个线程绑定,这就导致了main Reactor主服务端连接大部分场景(连接没有断开)只会用到一个线程:
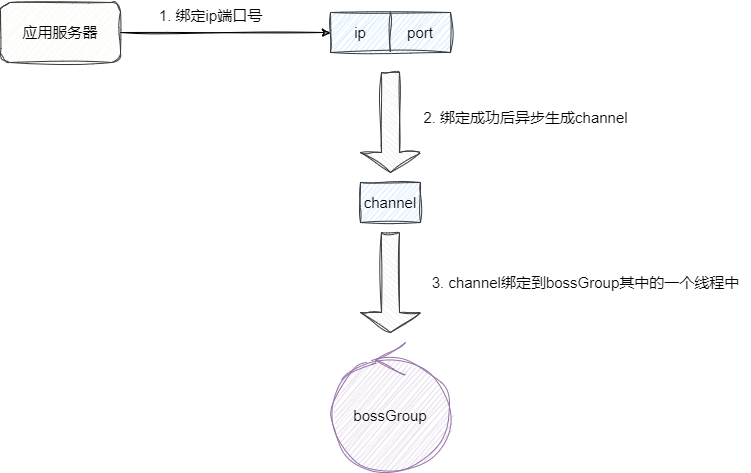
我们不妨通过代码的方式进行印证,我们服务端初始化时都是通过这个bind方法完成连接建立:
// Start the server.
ChannelFuture f = serverBootstrap.bind(PORT).sync();
2
查看bind内部的调用doBind即可看到它通过异步任务完成服务端serverSocketChannel创建之后,就会调用doBind0完成ip和端口号绑定:
private ChannelFuture doBind(final SocketAddress localAddress) {
//生成创建服务端serverSocketChannel的regFuture
final ChannelFuture regFuture = initAndRegister();
final Channel channel = regFuture.channel();
if (regFuture.cause() != null) {
return regFuture;
}
//如果regFuture完成了则将channel和ip端口号即localAddress绑定
if (regFuture.isDone()) {
// At this point we know that the registration was complete and successful.
ChannelPromise promise = channel.newPromise();
doBind0(regFuture, channel, localAddress, promise);
return promise;
} else {
//......
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
随后我们查看doBind0(一般带有do+0的方法都是执行核心逻辑的方法)方法,即可看到它会从当前channel的eventLoopGroup找到一个线程真正执行ip和端口绑定,这也就是我们所说的为什么main Reactor大部分场景只用到一个线程:
private static void doBind0(
final ChannelFuture regFuture, final Channel channel,
final SocketAddress localAddress, final ChannelPromise promise) {
//从channel的eventLoopGroup中找到一个线程执行bind
channel.eventLoop().execute(new Runnable() {
@Override
public void run() {
if (regFuture.isSuccess()) {
channel.bind(localAddress, promise).addListener(ChannelFutureListener.CLOSE_ON_FAILURE);
} else {
promise.setFailure(regFuture.cause());
}
}
});
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
有读者可能会问,为什么时大部分呢?那么小部分是什么情况?
答案是连接失败的情况,一旦绑定ip端口失败,Netty内部会抛出异常,如果服务端有断线重连机制,进行重新绑定时,channel可能会绑定eventGroup中的另一个线程:
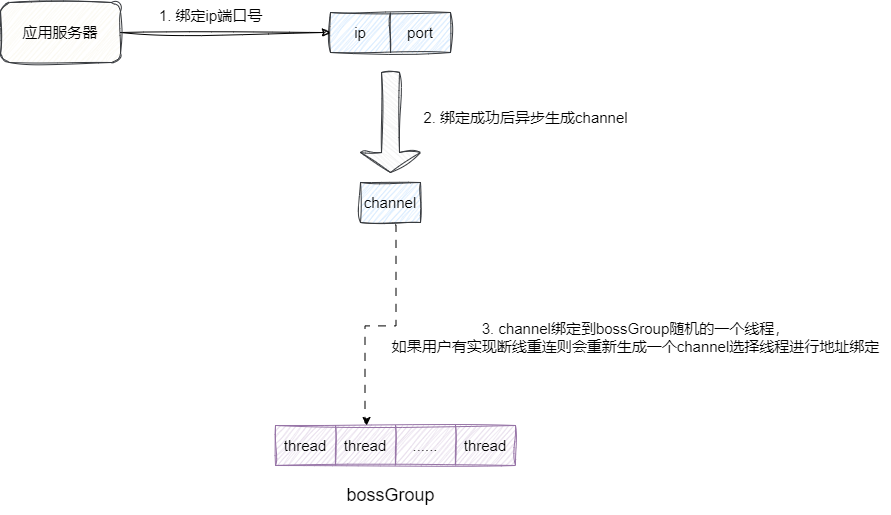
这里笔者也给出断线重连的服务端实现,可以看到我们通过channelInactive监听到断线后会重新创建channel进行绑定ip端口生成新的socket,此时我们就可以用到线程组中别的线程了:
@Override
public void channelInactive(ChannelHandlerContext ctx) {
ctx.channel().eventLoop().execute(()->{
//创建新的引导类
ServerBootstrap serverBootstrap =......;
//在地调用bind
serverBootstrap.bind("127.0.0.1",8080);
});
}
2
3
4
5
6
7
8
9
10
# Netty线程分配策略是什么
线程分配的负载均衡策略,也是在这里完成初始化的,chooserFactory会根据我们传入的线程数给定一个负载均衡算法。对于负载均衡算法Netty也做了很多的优化。我们查看chooserFactory创建策略可以看到,如果当前线程数的2的次幂则返回PowerOfTowEventExecutorChooser改选择使用位运算替代取模,反之返回GenericEventExecutorChooser这就是常规的取模运算。
@Override
public EventExecutorChooser newChooser(EventExecutor[] executors) {
//如果是2的次幂则用PowerOfTwoEventExecutorChooser选择器
if (isPowerOfTwo(executors.length)) {
return new PowerOfTwoEventExecutorChooser(executors);
} else {
//反之取常规的取模运算选择器
return new GenericEventExecutorChooser(executors);
}
}
2
3
4
5
6
7
8
9
10
先来说说PowerOfTowEventExecutorChooser ,其实它们的本质就是基于一个索引idx 通过原子自增并取模得到线程索引,只不过若线程数为2的次幂则可以通过位运算完成取模的工作,这么做的原因也是因为计算机对于位运算的执行效率远远高于算术运算。
这种算法通过位运算的方式提升计算效率,那么是否存在索引越界问题呢?假设线程数组长度为8,也就是2的3次方,那么实际进行与运算的值就是7,这个值也正是线程数组索引的最大值。笔者分别带入索引0、5、8,进行与运算时,真正参与的二进制永远是和永远是7以内的进制,得出的结果分别是0、5、0,永远不会越界,并且运算性能还能得到保证。
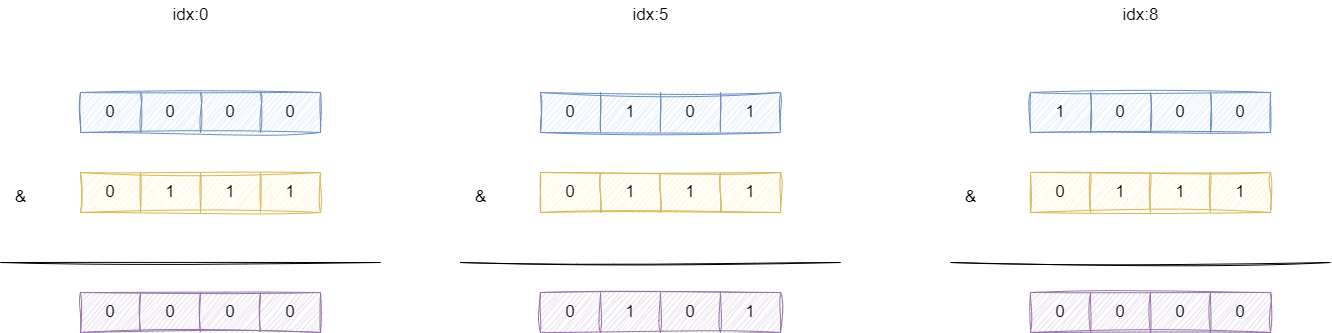
对此我们给出PowerOfTowEventExecutorChooser 选择器的实现,思路正如上文所说,通过按位与一个线程索引范围的最大值得到executors线程组索引范围以内的线程:
private static final class PowerOfTowEventExecutorChooser implements EventExecutorChooser {
//......
//原子类自增并和线程索引最大值进行按位与运算得到线程
@Override
public EventExecutor next() {
return executors[idx.getAndIncrement() & executors.length - 1];
}
}
2
3
4
5
6
7
8
9
而GenericEventExecutorChooser 则是原子自增和线程数组长度进行取模%运算得到线程,实现比较简单,这里笔者就直接给出代码了:
private static final class GenericEventExecutorChooser implements EventExecutorChooser {
//......
@Override
public EventExecutor next() {
//原子类自增和线程长度进行取模
return executors[(int) Math.abs(idx.getAndIncrement() % executors.length)];
}
}
2
3
4
5
6
7
8
9
# Netty中的IO多路复用的概念
默认情况,Netty是通过JDK的NIO的selector组件实现IO多路复用的,其实现的特点为:
- 功能上:轮询其是多路复用的,它支持将多个客户端(channel)的读写事件注册到一个selector上,由单个
selector进行轮询。 - 非阻塞:selector进行轮询是采用非阻塞轮询,即非阻塞的到内核态查看注册的读写事件是否就绪,如果没就绪则直接返回未就绪,而不是阻塞等待。
- 事件驱动:轮询到就绪事件后selector就会将结果返回给对应的EventLoop,交由其chanel pipeline上的处理器进行处理。
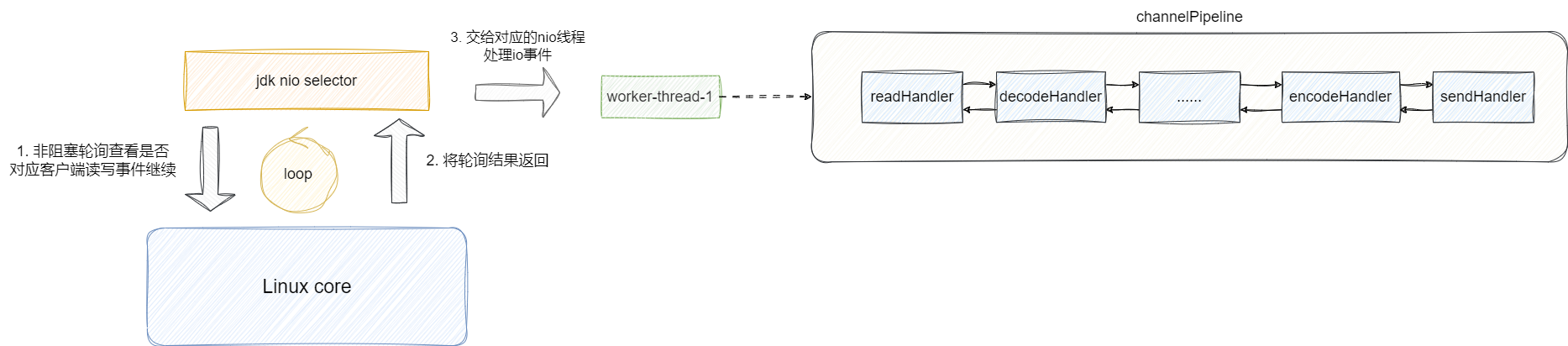
# Netty基于那几个组件搭配实现IO多路复用
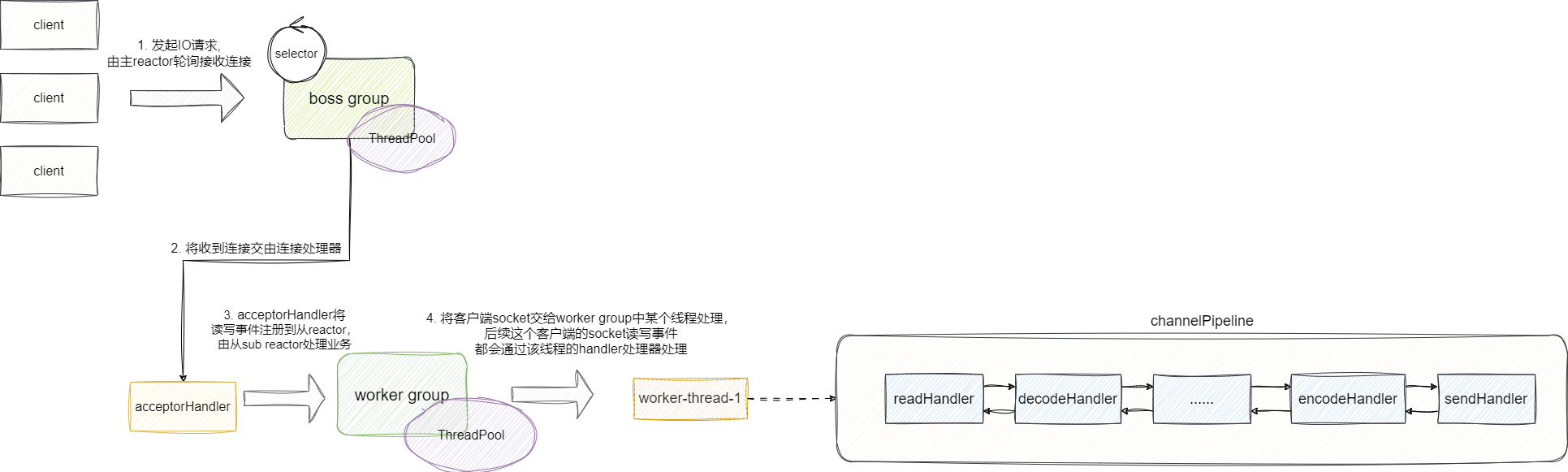
我们以最经典的reactor模型来探讨这个问题,整体来说,Netty是通过以下几个组件完成IO多路复用的方案落地:
- 声明
boss group线程组作为main reactor,它本质是Selector(对于Linux系统下是EpollEventLoop的封装),对于接收新连接的客户端socket,并通过acceptHandler分发连接请求。 - 通过
work group为分发过过来的连接分配一个线程,对应的它们都会被抽象为一个Channel对象,后续该socket的读写时间都在work group的线程上的处理,而这个线程内部也会有一个EventLoop通过selector针对这几个socket的读写事件进行io轮询查看是否就绪。 - 而每个一个客户端
channel注册到从reactor后续的读写事件都会通过对应的channel pipeline上的handler处理器进行处理。
对此我们也将这些组件的协作流程进行总结:
- 服务端初始化所有线程,各自都绑定一个
selector。 BossGroup初始化连接,绑定ip和端口,其底层selector轮询器会监听当前ServerSocketChannel对应的客户端新接入的连接事件。- 客户端连接到达时,
BossGroup将就绪的客户端channel件分发到worker group的某个线程的EventLoop上。 - work group为该channel分配处理器并将其读写事件注册到自己的selector上,同时监听其读写事件。
- 后续读写事件就绪时,
EventLoop就会触发ChannelPipeline中的处理器处理事件。
# Netty如何实现通用NIO多路复用器
实际上Netty对于JDK NIO SelectorProvider 做了一些灵活的处理,它可以让用户通过JVM参数或者SPI文件配置等方式让用户直接JDK NIO提供的selector。
我们配置引导类的时候,通常会声明b.channel(NioServerSocketChannel.class);,一旦我们通过引导类进行初始化的时候,其底层就会按照如下顺序执行:
- 首先会通过
loadProviderFromProperty查看用户是否有通过系统配置指定创建,即通过JVM参数-D java.nio.channels.spi.SelectorProvider指定selectorProvider的全限定名称,若存在则通过应用程序加载器即(Application Classloader)完成反射创建。 - 若步骤1明确没有配置,则查看SPI是否有配置,即查看工厂目录
META-INF/services下是否有定义名为SelectorProvider的SPI文件,若存在则会拿着第一个SelectorProvider的全限定名称进行反射创建。 - 若都没有则是创建
DefaultSelectorProvider这个DefaultSelectorProvider会根据操作系统内核版本决定提供那个DefaultSelectorProvider,以笔者为例是Windows操作系统所以提供的Provider是WindowsSelectorProvider,同理如果是Linux内核2.6以上则是EpollSelectorProvider。
这就是Netty如何保证NIO多路复用器通用的原因:

我们直接查看NioServerSocketChannel,可以看到其默认构造方法内部使用默认DEFAULT_SELECTOR_PROVIDER 进行NioServerSocketChannel创建:
private static final SelectorProvider DEFAULT_SELECTOR_PROVIDER = SelectorProvider.provider();
//......
//使用DEFAULT_SELECTOR_PROVIDER创建server socket channel
public NioServerSocketChannel() {
this(newSocket(DEFAULT_SELECTOR_PROVIDER));
}
2
3
4
5
6
我们查看DEFAULT_SELECTOR_PROVIDER 的实现,即SelectorProvider.provider()内部逻辑,可以正如我们上文所说的顺序,这里笔者就不多做赘述了:
public static SelectorProvider provider() {
//临界加载上个锁
synchronized (lock) {
//......
return AccessController.doPrivileged(
new PrivilegedAction<SelectorProvider>() {
public SelectorProvider run() {
//使用jvm方式尝试反射创建
if (loadProviderFromProperty())
return provider;
//使用spi的方式进行反射创建
if (loadProviderAsService())
return provider;
//返回通过系统平台jdk系统的DefaultSelectorProvider
provider = sun.nio.ch.DefaultSelectorProvider.create();
return provider;
}
});
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# Netty如何优化工作线程调度平衡
Netty设计者为了提升单个NIO线程的利用率,对每一个线程调度分配都做了极致的压榨,其工作流程为先查看定时任务队列scheduledTaskQueue中查看是否有就绪的任务,若有则查看它的到期时间距今的时差,并基于这个时差进行非阻塞轮询查看是否存在就绪的任务。当然如果定时队列中没有就绪的任务,那么轮询IO任务的方法select就会阻塞轮询,直到被移步任务唤醒或者select有就绪事件。
得到就绪的IO事件后,Netty会调用processSelectedKeys进行处理,然后基于这个IO事件的处理时长,按照同等执行比例从taskQueue和tailTasks中获取任务并执行,可以看出Netty中的节点针对每一个时间点都做好了很好的安排,并完成相对公平的调度:
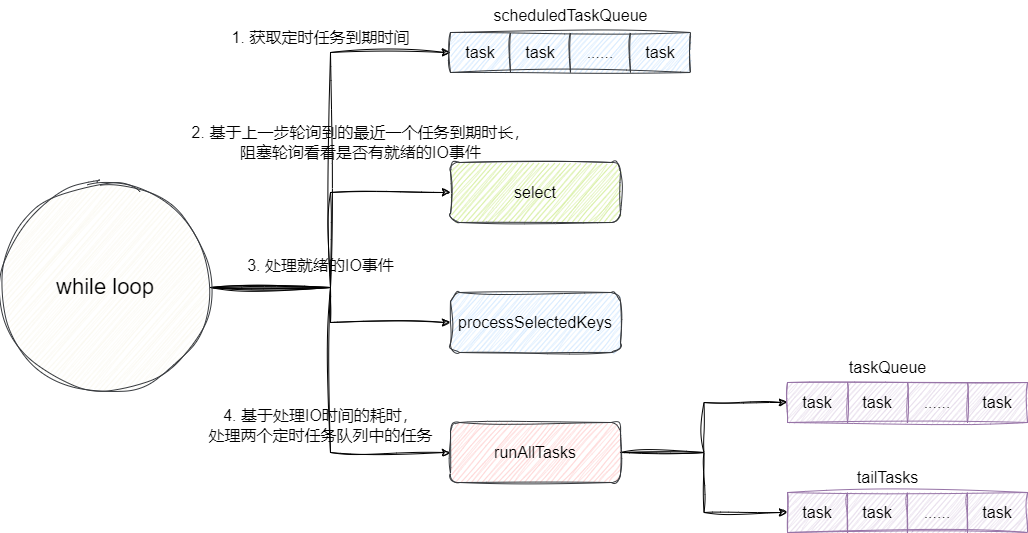
对应的我们给出Netty每一个线程NioEventLoop的run方法,逻辑和笔者上文描述一致,读者可自行参阅:
@Override
protected void run() {
int selectCnt = 0;
for (;;) {
try {
int strategy;
try {
strategy = selectStrategy.calculateStrategy(selectNowSupplier, hasTasks());
switch (strategy) {
//......
case SelectStrategy.SELECT:
//查看是否有就绪的定时任务,如果有则设置到期时间curDeadlineNanos
long curDeadlineNanos = nextScheduledTaskDeadlineNanos();
if (curDeadlineNanos == -1L) {
curDeadlineNanos = NONE; // nothing on the calendar
}
nextWakeupNanos.set(curDeadlineNanos);
//如果没有任务,则基于curDeadlineNanos进行定长时阻塞轮询就绪IO事件
try {
if (!hasTasks()) {
strategy = select(curDeadlineNanos);
}
} finally {
//......
}
default:
}
} catch (IOException e) {
//......
}
//......
//默认情况下ioRatio 为50,我们直接看else逻辑
if (ioRatio == 100) {
//......
} else if (strategy > 0) {
final long ioStartTime = System.nanoTime();
try {
//处理IO事件
processSelectedKeys();
} finally {
//基于IO事件处理的耗时继续处理其他异步任务
final long ioTime = System.nanoTime() - ioStartTime;
ranTasks = runAllTasks(ioTime * (100 - ioRatio) / ioRatio);
}
} else {
ranTasks = runAllTasks(0); // This will run the minimum number of tasks
}
//......
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
# Netty如何解决CPU 100% 即空轮询问题
JDK的NIO底层由Epoll实现,在部分Linux的2.6的kernel中,poll和epoll对于突然中断的连接socket会对返回的eventSet事件集合置为POLLHUP或POLLERR,进而导致eventSet事件集合发生了变化,这就可能导致selector会被唤醒,由此引发CPU 100%.问题。
关于这个问题的bug,感兴趣的读者可移步下面这个链接查看bug详情:
JDK-6670302:https://bugs.java.com/bugdatabase/view_bug.do?bug_id=6670302 (opens new window)
而Netty的NIO线程解决方案则比较简单了,每一次循环它都会查看本次是否有执行任务,如果有则不做处理,反之它会累加一个selectCnt,一旦selectCnt值大于或者等于512(默认值)时,就会调用rebuildSelector重新构建选择器从而解决这个问题:
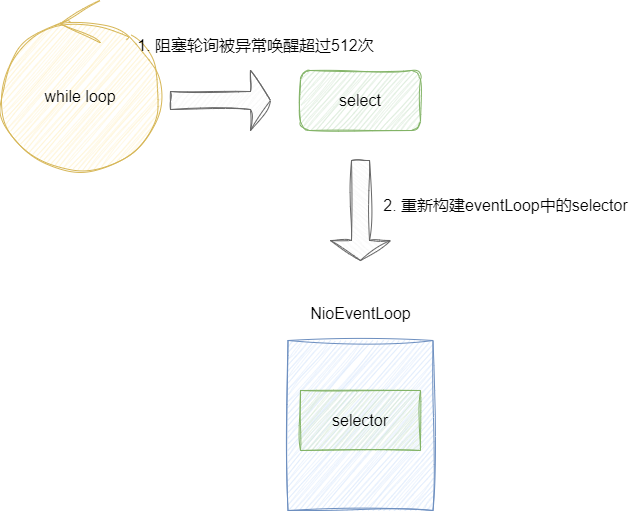
对应的源码仍然在NioEventLoop的run方法,当我们执行了异步任务则ranTasks 为true,如果有轮询到IO事件则strategy 大于0,在后续逻辑中selectCnt(这个变量代表空轮询次数) 会被重置,反之selectCnt会不断被累加直到超过512次,通过执行rebuildSelector重新构建轮询器避免CPU100%问题:
@Override
protected void run() {
int selectCnt = 0;
for (;;) {
try {
int strategy;
try {
//轮询并处理任务
//......
//累加一次selectCnt
selectCnt++;
//如果有执行任务则重置selectCnt
if (ranTasks || strategy > 0) {
//......
selectCnt = 0;
} else if (unexpectedSelectorWakeup(selectCnt)) { //反之视为异常唤醒,执行unexpectedSelectorWakeup
selectCnt = 0;
}
} catch (CancelledKeyException e) {
//......
} //......
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
步入unexpectedSelectorWakeup即可印证笔者所说的,当空轮询大于或者等于512次之后就会重新构建轮询器:
private boolean unexpectedSelectorWakeup(int selectCnt) {
//......
//如果selectCnt 大于SELECTOR_AUTO_REBUILD_THRESHOLD(512)则执行rebuildSelector重新构建当前eventLoop的轮询器
if (SELECTOR_AUTO_REBUILD_THRESHOLD > 0 &&
selectCnt >= SELECTOR_AUTO_REBUILD_THRESHOLD) {
//......
rebuildSelector();
return true;
}
return false;
}
2
3
4
5
6
7
8
9
10
11
# Netty对于事件轮询器做了哪些优化
默认情况下JDK的DefaultSelectorProvider在Windows系统下创建的是WindowsSelectorImpl,而Linux则是EpollSelectorImpl,它们都继承自SelectorImpl,查看SelectorImpl的源码可以发现它如下几个核心参数:
selectedKeys:存放就绪IO事件集。publicSelectedKeys:和上述概念一致,只不过是selectedKeys的一个视图,给用户读取就绪IO事件时用的,且外部线程对于这个publicSelectedKeys只能做删除操作。keys:我们都知道对于socket感兴趣的IO事件都会注册到keys上。publicKeys:和上述概念类似,只不过是keys一个对外的视图,不可增加元素,只能读取和删除。
public abstract class SelectorImpl extends AbstractSelector {
//存储感兴趣的IO事件
protected HashSet<SelectionKey> keys = new HashSet();
//keys的只读视图层
private Set<SelectionKey> publicKeys;
//存放就绪IO事件的集合
protected Set<SelectionKey> selectedKeys = new HashSet();
//上一个集合的视图层
private Set<SelectionKey> publicSelectedKeys;
//......
protected SelectorImpl(SelectorProvider var1) {
super(var1);
if (Util.atBugLevel("1.4")) {
//......
} else {
//......
//使用ungrowableSet封装selectedKeys作为视图
this.publicSelectedKeys = Util.ungrowableSet(this.selectedKeys);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
应用程序从内核获取就绪的IO事件也就是添加到selectedKeys 上,以服务端接收客户端读写请求为例,我们的主reactor为了拿到客户端的连接请求,就会将自己的channel依附即attach到SelectionKeyImpl上,一旦这个轮循到就绪连接事件继续后就会调用attachment方法通知这个channel处理连接。很明显遍历就绪的key用HashSet效率不是很高效(无需的哈希集):

所以Netty为了提高处理时遍历的效率,对存储就绪事件的集合进行了优化,它会判断创建的selector 是否是默认的selector ,且DISABLE_KEYSET_OPTIMIZATION 这个变量是否为false(默认为false),如果符合这两个条件,则初始化时会通过反射将selectedKeys改为数组,通过数组的连续性保证CPU缓存可以一次性加载尽可能多的key以及提升迭代效率:
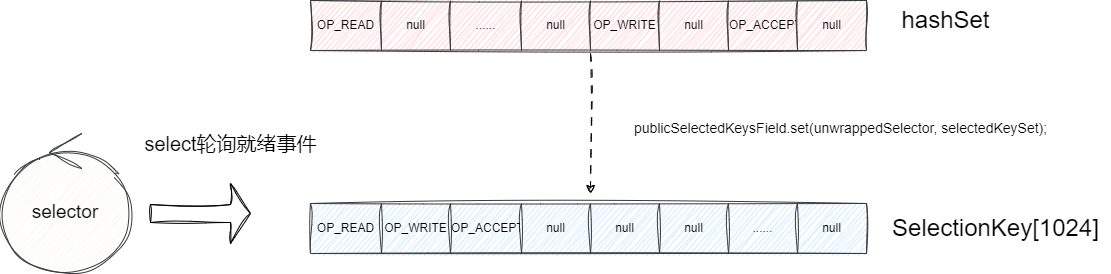
对此我们给出NioEventLoop的构造方法,可以看到NioEventLoop初始化时回调用openSelector完成selector创建,其内部就存在我们上述所说的如果是原生jdk的selector且DISABLE_KEYSET_OPTIMIZATION为false(即允许key优化)则通过反射修改集合类型:
NioEventLoop(NioEventLoopGroup parent, Executor executor, SelectorProvider selectorProvider,
SelectStrategy strategy, RejectedExecutionHandler rejectedExecutionHandler,
EventLoopTaskQueueFactory queueFactory) {
super(parent, executor, false, newTaskQueue(queueFactory), newTaskQueue(queueFactory),
rejectedExecutionHandler);
//......
//创建selector,如果是原生jdk的selector且DISABLE_KEYSET_OPTIMIZATION为false(即允许key优化)则通过反射修改集合类型
final SelectorTuple selectorTuple = openSelector();
this.selector = selectorTuple.selector;
//......
}
2
3
4
5
6
7
8
9
10
11
最终步入openSelector即可看到我们所说的条件判断和反射修改集合的逻辑:
private SelectorTuple openSelector() {
//......
//反射获取当前selector类型
Object maybeSelectorImplClass = AccessController.doPrivileged(new PrivilegedAction<Object>() {
@Override
public Object run() {
try {
return Class.forName(
"sun.nio.ch.SelectorImpl",
false,
PlatformDependent.getSystemClassLoader());
} catch (Throwable cause) {
return cause;
}
}
});
//非平台提供的selector则直接封装返回
if (!(maybeSelectorImplClass instanceof Class) ||
//......
return new SelectorTuple(unwrappedSelector);
}
final Class<?> selectorImplClass = (Class<?>) maybeSelectorImplClass;
//创建一个1024长度的SelectionKey数组存放事件
final SelectedSelectionKeySet selectedKeySet = new SelectedSelectionKeySet();
Object maybeException = AccessController.doPrivileged(new PrivilegedAction<Object>() {
@Override
public Object run() {
try {
//反射获取当前selector字段
Field selectedKeysField = selectorImplClass.getDeclaredField("selectedKeys");
Field publicSelectedKeysField = selectorImplClass.getDeclaredField("publicSelectedKeys");
//......
//通过反射将selector设置为数组类型的selector
selectedKeysField.set(unwrappedSelector, selectedKeySet);
publicSelectedKeysField.set(unwrappedSelector, selectedKeySet);
return null;
} catch (NoSuchFieldException e) {
//......
}
}
});
//......
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
我们不妨看看SelectedSelectionKeySet做了那些优化,首先从定义来看它的SelectionKey是一个数组,很明显数组的添加和遍历效率都是顺序的所以处理效率相较于HashSet会高效需多。而且因为数组内存空间是连续的,可以更好的利用CPU缓存行从而一次性读取并遍历更多的key进行高效处理,所以每次CPU都可以加载对应元素和其邻接元素,所以处理效率相较于不规则的HashSet要高效许多。
# Netty无锁化的串行设计理念
为尽可能提升NioEventLoop的执行效率,出了上述提到的空闲等待、基于定时任务定长时轮询以及IO和计算任务平衡配比等设计以外,在提交任务时,Netty采用MpscChunkedArrayQueue作为任务队列,这是一个无锁的多生产者单消费者的任务队列,提交任务时,该队列就会基于CAS得到这个队列的索引位置,然后将任务提交到队列中,然后我们的NioEventLoop一样通过原子操作或者可以消费的索引位置进行任务消费:
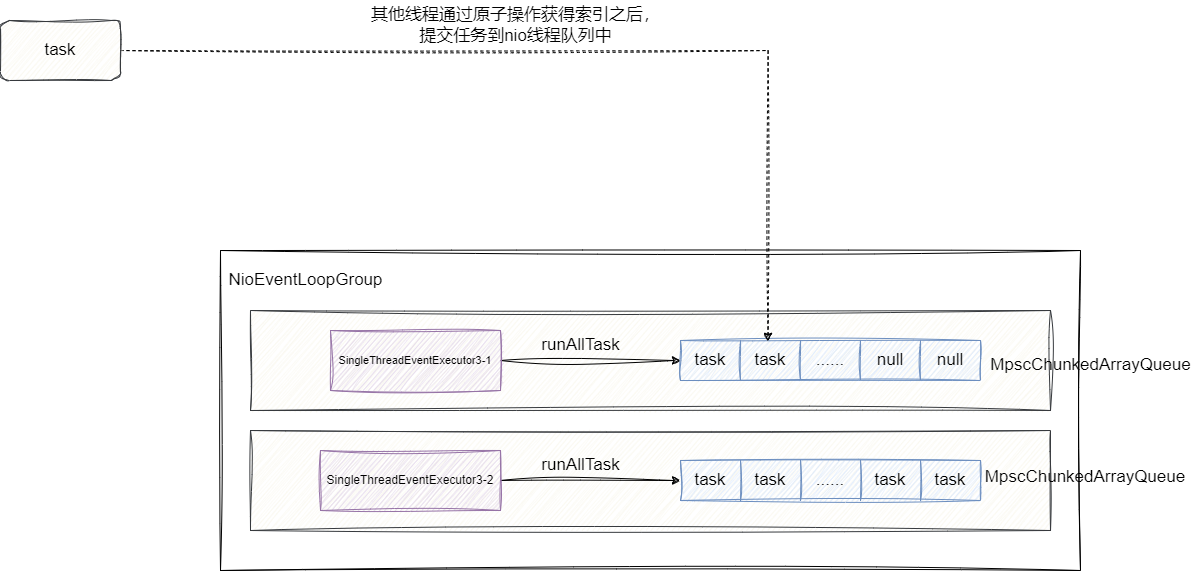
这一点我们可以直接查看NioEventLoopGroup 的构造函数即可看到,初始化时其内部会调用newTaskQueue创建MpscChunkedArrayQueue来管理任务:
NioEventLoop(NioEventLoopGroup parent, Executor executor, SelectorProvider selectorProvider,
SelectStrategy strategy, RejectedExecutionHandler rejectedExecutionHandler,
EventLoopTaskQueueFactory queueFactory) {
//......
//指明创建队列为mpscQueue
super(parent, executor, false, newTaskQueue(queueFactory), newTaskQueue(queueFactory),
rejectedExecutionHandler);
}
2
3
4
5
6
7
8
9
10
11
addTask本质上就是调用MpscChunkedArrayQueue的offer方法,其本质就是通过CAS操作获得可以添加元素的索引位置pIdex,然后基于这个pIndex得到物理地址并完成赋值:
@Override
public boolean offer(final E e)
{
if (null == e)
{
throw new NullPointerException();
}
long mask;
E[] buffer;
long pIndex;
while (true)
{
//各种索引位计算
//cas获取生产者索引位置
if (casProducerIndex(pIndex, pIndex + 2))
{
break;
}
}
// 获取cas之后得到的pIndex的位置然后赋值
final long offset = modifiedCalcCircularRefElementOffset(pIndex, mask);
soRefElement(buffer, offset, e); // release element e
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
而数据消费也是同理,Netty的NIO线程通过poll进行获取,其内部通过lpConsumerIndex进行CAS获得消费者的消费端索引,然后通过原子操作拿到元素值,如果e不存在则继续CAS自旋直到可以得到这个值为止:
@Override
public E poll()
{
//CAS获取索引位置
final long index = lpConsumerIndex();
//......
//定位到索引偏移量
final long offset = modifiedCalcCircularRefElementOffset(index, mask);
Object e = lvRefElement(buffer, offset);
//如果元素为空,不断自旋拿到值为止
if (e == null)
{
if (index != lvProducerIndex())
{
// poll() == null iff queue is empty, null element is not strong enough indicator, so we must
// check the producer index. If the queue is indeed not empty we spin until element is
// visible.
do
{
e = lvRefElement(buffer, offset);
}
while (e == null);
}
//......
}
//......
//返回元素
return (E) e;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 关于网络IO框架的一些展望——网络IO模型io_uring
文章补充更新:近期和业界的一些大牛进行深入交流时了解到一个除了epoll以外更强大的io模型——io_uring,相较于epoll和其它io模型,它有着如下优点:
- 用户态和内存态进行IO操作时共享一块内存区域,由此避免切态开销。
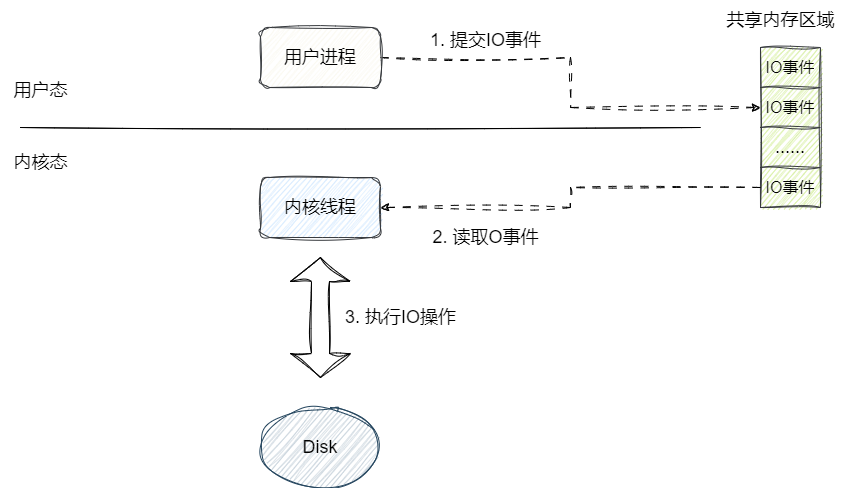
- 发起IO调用无需内核态调用,在SQPOLL模式下,sq线程会自行从提交队列中获取IO事件并处理,完成后会将结果写入共享区域的完成队列告知用户。
- 用户态的应用程序可可直接通过完成队列这个环形缓冲区获得完成的IO事件并进行进一步操作。
这里我们以一个简单的到磁盘中读取数据的流程为例看看io_uring的整体流程:
- 用户发起IO请求,希望从
/tmp目录下读取某个文本文件的内容 - 发起IO请求,该调用会在
io_uring的提交队列(它是一个环形缓冲区)中追加该事件,用tail指针指向该事件。 - 底层的sq线程轮询提交队列中待完成的事件指针,拿到这个IO事件,发起磁盘IO调用。
- 完成数据读写之后,将该事件和结果写入完成队列。
- 应用程序直接从完成队列中读取该事件结果并进行业务处理。
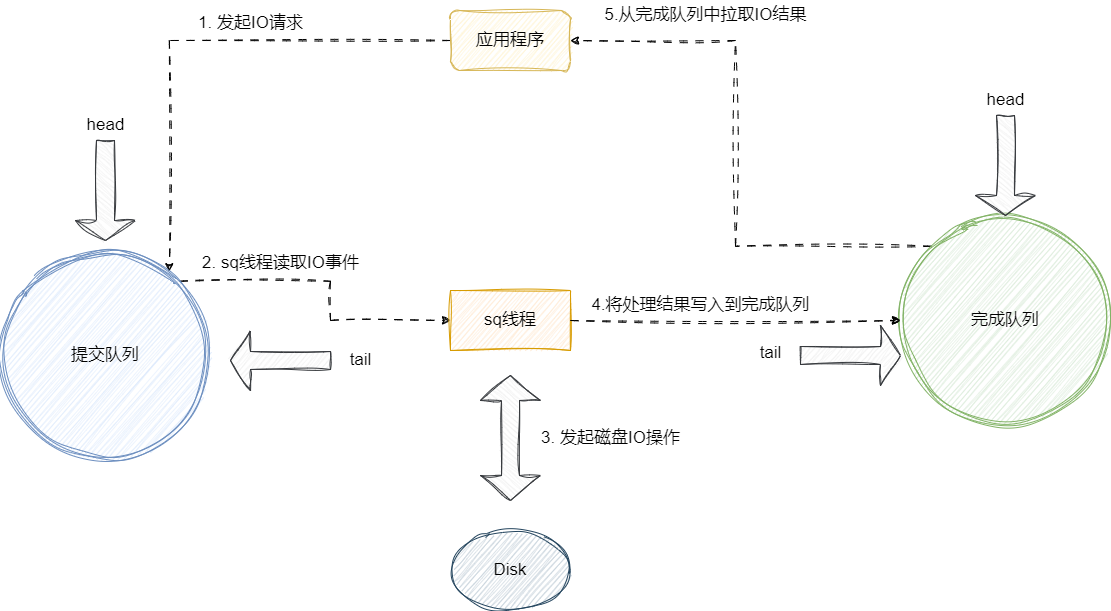
用户态从完成队列中获取到我们的磁盘读取事件的指针地址,从而拿到数据。可以看到,整个流程用户态在完成一次IO期间完全没有进行切态和数据拷贝的开销,相较于epoll来说性能损耗小了很多。
# 小结
以上便是笔者对于Netty Reactor知识点的分析与讲解,希望对你有帮助。
我是 sharkchili ,CSDN Java 领域博客专家,mini-redis的作者,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
# 参考
面试官:Netty的线程模型,可不只是主从多Reactor这么简单! :https://zhuanlan.zhihu.com/p/344628838 (opens new window)
Netty实战与源码剖析(二)——Netty线程模型 :https://juejin.cn/post/7179242201212256312 (opens new window)
Netty线程模型 - Reactor 模式:https://juejin.cn/post/7028491415608885255 (opens new window)
详细图解Netty Reactor启动全流程 | 万字长文 | 多图预警 https://mp.weixin.qq.com/s?__biz=Mzg2MzU3Mjc3Ng==&mid=2247484005&idx=1&sn=52f51269902a58f40d33208421109bc3&chksm=ce77c422f9004d340e5b385ef6ba24dfba1f802076ace80ad6390e934173a10401e64e13eaeb&scene=178&cur_album_id=2217816582418956300#rd (opens new window)
面试难题:Netty如何解决Selector空轮询BUG?:https://blog.csdn.net/crazymakercircle/article/details/120636420 (opens new window)
Netty无锁串行化: https://www.cnblogs.com/Irving/p/5709130.html (opens new window)
JDK Epoll空轮询bug:https://www.jianshu.com/p/3ec120ca46b2 (opens new window)
图解原理|Linux I/O 神器之 io_uring:https://zhuanlan.zhihu.com/p/583413166 (opens new window)
