 CPU性能优化技术详解
CPU性能优化技术详解
[toc]
# 引言
在现代计算系统中,CPU性能是决定程序执行效率的关键因素之一。随着应用程序复杂性的不断增加,对计算性能的要求也越来越高。为了应对这些挑战,CPU设计者们在处理器架构中引入了多种优化技术,以最大化硬件资源的利用效率。
本文将深入探讨三种核心的CPU优化技术:分支预测、并行运算和超线程技术。这些技术从不同角度解决了指令执行过程中的性能瓶颈问题:
- 分支预测技术通过预测程序控制流的方向,减少因分支指令造成的流水线停顿
- 并行运算(SIMD)通过单指令多数据流的方式,让一条指令同时处理多个数据元素
- 超线程技术通过在单个物理核心上模拟多个逻辑处理器,提高CPU资源的整体利用率
理解这些底层优化原理不仅有助于我们编写更高效的代码,还能帮助我们在系统设计和性能调优时做出更明智的决策。接下来,我们将逐一剖析这些关键技术的实现原理和实际应用。
我是 SharkChili ,Java 开发者,Java Guide 开源项目维护者。欢迎关注我的公众号:写代码的SharkChili,也欢迎您了解我的开源项目 mini-redis:https://github.com/shark-ctrl/mini-redis。
为方便与读者交流,现已创建读者群。关注上方公众号获取我的联系方式,添加时备注加群即可加入。
# CPU分支预测详解
# 预测思想
CPU采用流水线设计来避免逐条执行指令的低效问题,即完成读取指令、指令译码、执行指令、数据回写整个流程后再执行下一条指令。在之前的文章中,我们介绍了CPU通过保留站和重排序缓冲区解决了结构冒险(硬件资源竞争)和数据冒险(前后指令结果依赖性)问题。现在还剩下控制冒险问题,即当前指令需要基于之前的结果决定走哪个分支。
设计者们发现,大部分程序逻辑中下一次走的分支都是有迹可循的。例如下面这段循环,它从0到99都会在循环内部执行,只有当i自增到100时才会退出循环:
for (int i = 0; i < 100; i++) {
//执行业务逻辑
}
2
3
因此,设计者们考虑采用一种预测机制,即根据前一次的结果将下一条指令直接预加载。如果预测正确就直接执行,预测错误则重新加载。以上述代码为例,当我们执行i为0时,执行的就是循环内部的指令。按照分支预测的思想,我们认为下一次执行的指令还是循环内部的指令。按照这种思路,分支预测会将循环内部的指令预先加载到内存中:
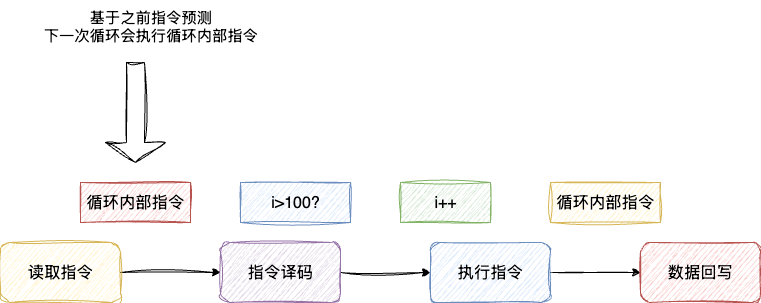
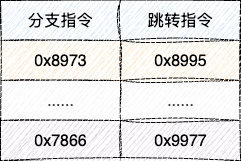
基于这种方案,设计者们提出在CPU存储电路中建立一张表格,记录每一个分支指令对应的跳转指令信息,由此完成分支预测信息的维护:
但这种情况并不常见。试想下面这个循环,交替执行奇数和偶数判断分支内部的逻辑,按照我们原有的分支预测设计,预加载指令会频繁失效,流水线效率仍然没有得到提升:
int i = 0;
while (true) {
if (i % 2 == 0) {
//执行业务逻辑
i++;
} else {
//执行其他业务逻辑
}
}
2
3
4
5
6
7
8
9
10
# 分支预测表优化
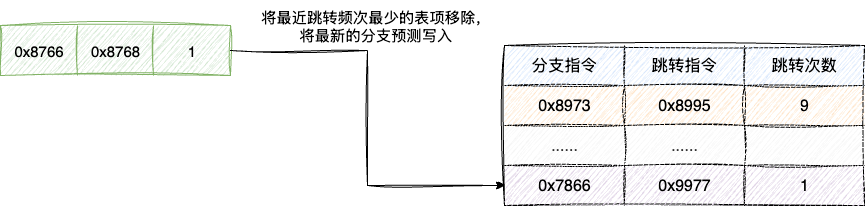
针对上述这种以偏概全的欠拟合情况,设计者们考虑在原有表格的基础上增加一个跳转次数的维护。每当分支预测跳转一次,对应的表项就自增一次。同时考虑到CPU缓存空间的限制,一旦发现空间不足,就将跳转频次最小的跳转指令移除,从而避免分支预测表格空间被无效的跳转表项占用,还能进一步提升分支预测的准确率:
现代处理器采用了更加复杂的分支预测技术,如两级自适应预测器、神经网络预测器和TAGE预测器等,能够达到95%以上的预测准确率。这些高级预测器通过分析历史分支模式和上下文信息,能够更好地处理复杂的控制流结构。
# 分支预测技术的运用
了解CPU分支预测设计后,我们在日常编码中就可以尽可能保证循环中的逻辑分支稳定保持在同一个跳转指令上来提升程序运行效率。如下代码,我们创建两个数组并生成随机数填充,执行这样一个累加逻辑:
- 如果遍历的数组值大于5000则先
*2再累加 - 如果小于5000则直接累加
唯一的区别是sortedArray在进行循环累加时会先进行一次排序:
public static void main(String[] args) {
// 创建测试数据
int[] sortedArray = new int[10000000];
int[] unsortedArray = new int[10000000];
// 随机填充数据
Random random = new Random();
for (int i = 0; i < 10000000; i++) {
int value = random.nextInt(10000);
sortedArray[i] = value;
unsortedArray[i] = value;
}
// 测试有序数组的分支预测,提升array[i] > 5000这段if判断的成功率
Arrays.sort(sortedArray);
long startTime = System.currentTimeMillis();
processArray(sortedArray);
long sortedTime = System.currentTimeMillis() - startTime;
// 测试无序数组的分支预测
startTime = System.currentTimeMillis();
processArray(unsortedArray);
long unsortedTime = System.currentTimeMillis() - startTime;
System.out.println("有序数组处理时间: " + sortedTime + "ms");
System.out.println("无序数组处理时间: " + unsortedTime + "ms");
System.out.println("性能差异: " + Math.abs(sortedTime - unsortedTime) + "ms");
}
/**
* 处理数组,包含条件分支
* @param array 待处理的数组
*/
public static void processArray(int[] array) {
long sum = 0;
for (int i = 0; i < array.length; i++) {
// 这个条件在有序数组中更容易预测
if (array[i] > 5000) {
sum += array[i] * 2;
} else {
sum += array[i];
}
}
// 避免JIT优化掉整个循环
if (sum == Integer.MAX_VALUE) {
System.out.println("Sum: " + sum);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
最终输出结果如下:
有序数组处理时间: 7ms
无序数组处理时间: 24ms
性能差异: 17ms
2
3
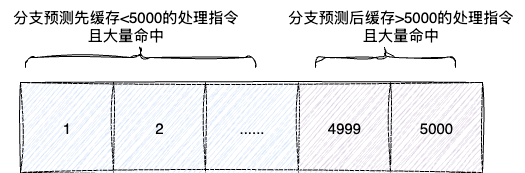
可以看到,排序后的数组因为数据有序,分支预测会先缓存<5000的逻辑并大量命中处理。当遍历到>5000的逻辑后,分支预测再次被缓存且大量命中,执行效率远高于随机数组:
# CPU并行运算的设计推进
# 重复指令的执行
通过分支预测解决了控制冒险问题后,我们继续探究CPU的优化。接下来我们来看下面这段代码,本质上是对一个数组进行遍历并将每个整数乘2的操作:
int[] arr = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
for (int i = 0; i < arr.length; i++) {
// 左移一位,即乘2操作
arr[i] = arr[i] << 1;
}
2
3
4
5
6
从CPU指令执行的角度来看,它本质上就是遍历数组后读取每个数组元素,然后进行乘法运算,最后将结果回写。从宏观来看,我们只是想将数组中所有元素都进行相同的修改操作,却需要多次循环,效率非常低下。因此我们思考是否存在一种策略可以让此类操作一次性完成。
答案是并行运算,整体思路是希望一次性加载一批连续的数组数据到寄存器中,一次性完成一致的运算,避免非必要的多次执行:
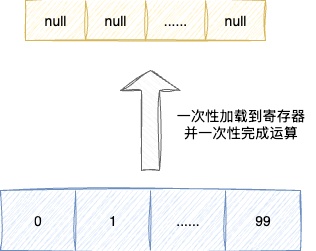
# FPU寄存器
一开始考虑到资源成本的开销以及方案的可行性,设计者打算借助浮点数运算单元寄存器即MM0~MM7,同时基于这套寄存器还新增了一套MMX指令集负责整数的批量运算:
- paddb(Parallel Add Byte):字节数据的并行加法
- paddw(Parallel Add Word):字并行加法运算
- paddd(Parallel Add Doubleword):32位双字(doubleword)数据进行并行加法运算
- paddsb(Parallel Add Signed Byte with Saturation):有符号字节数据进行带饱和处理的并行加法运算
- .......
因为一条指令可以处理多个数据,所以我们给这种技术命名为单指令多数据流,即SIMD(Single Instruction Multiple Data)。
# XMM0~XMM7寄存器的诞生
但是问题随之而来,因为我们目前的并行运算是借助浮点寄存器FPU执行整数运算,而涉及图像、视频、深度学习的数据处理都是浮点型并行运算,这套指令集根本无法使用。
于是CPU新增了XMM0~XMM7总共8个128位的寄存器,位宽更大,能容纳更多数据,且补充了浮点数的并行处理指令集。这些寄存器是SSE(Streaming SIMD Extensions)指令集的一部分。
随着技术的发展,现代CPU还支持更宽的向量寄存器:
- YMM寄存器(256位):AVX指令集
- ZMM寄存器(512位):AVX-512指令集
这些扩展使得单条指令可以处理更多的数据元素,进一步提升了并行计算的效率。现代编译器通常具备自动向量化能力,能够自动将合适的循环转换为SIMD指令,充分发挥硬件的并行计算能力。
# 超线程
# 资源闲置问题
CPU的SIMD技术提升了大循环这种重复指令的并行运算效率,但是对CPU的资源利用率还不够,原因如下:
- 内存速率和CPU缓存不对等,读取内存速率较慢,虽然有缓存,但初次加载问题仍然存在
- 尽管乱序执行提升了流水线效率,但这种依赖性的指令并不常见
- 运算电路未能充分利用,例如在执行整数运算时,对应的浮点数运算电路就闲置下来了
于是设计者开始考虑,是否存在一种技术可以提升CPU电路的利用率,保证单位时间内尽可能多地执行指令,充分利用CPU电路单元,于是就有了超线程技术。
# 超线程技术
超线程技术的概念非常简单。我们都知道CPU单核执行的最小单位是线程,而每个线程执行时都需要通过寄存器来保存当前的执行上下文。因此,设计者在原有CPU架构的基础上增加一组配套的寄存器来保存运行的上下文信息,保证单位时间内多组运算电路可以执行指令。
有了超线程,CPU资源的利用率就显著提高:
- 一条线程执行指令阻塞停顿时,就去处理另一条线程
- 一条线程执行整数运算使用ALU,另一条线程就处理浮点数运算(FPU),彼此可以独立执行指令,因为不存在结构冒险,所以互不依赖并独立并发执行
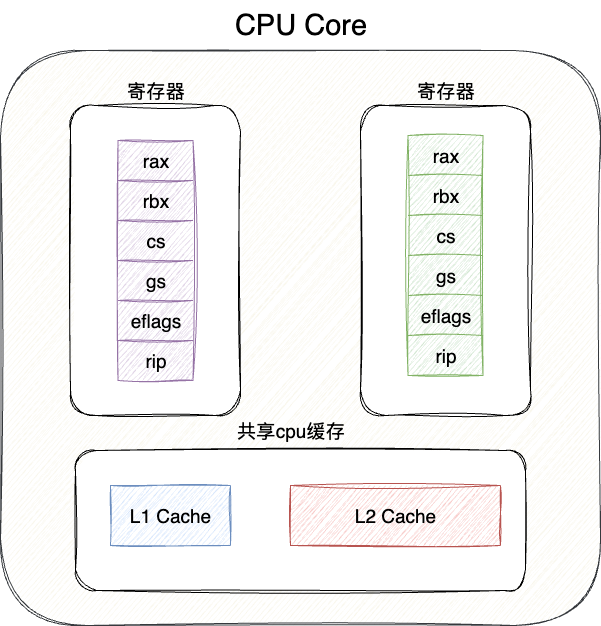
有了超线程技术,单核CPU具备了两个逻辑处理器的并行执行能力。尽管做到了这种优化,但性能表现也仅仅提升了20%~30%,即针对指令加载时、回写等可以并发执行,但针对结构冒险例如同时使用ALU运算时却会阻塞停顿。同时CPU的电路功耗也更大了,所以还需要考虑给CPU降温之类的问题。
需要注意的是,超线程技术在某些安全场景下可能存在风险。由于两个逻辑处理器共享物理核心资源,通过精确的时间测量可能泄露另一个逻辑处理器的信息,这在Spectre和Meltdown等安全漏洞中得到了体现。因此,在高安全性要求的环境中,有时会建议禁用超线程技术。
在实际应用中,超线程技术对多线程应用程序性能提升最为明显,特别是I/O密集型或存在较多分支预测失败的应用程序。但对于计算密集型且资源竞争激烈的应用,超线程可能不会带来显著性能提升,甚至可能因资源争用而降低性能。
# 小结
本文介绍了现代CPU中的三种重要优化技术:
分支预测:通过预测程序控制流的方向,减少因分支指令造成的流水线停顿,提高指令执行效率。现代处理器采用复杂的预测算法,能够达到95%以上的预测准确率。
并行运算(SIMD):通过单指令多数据流技术,让一条指令同时处理多个数据元素,大幅提升数据并行处理能力。从MMX到SSE再到AVX指令集的发展,使得向量计算能力不断增强。
超线程技术:通过在单个物理核心上模拟多个逻辑处理器,提高CPU资源利用率,在一个线程等待时执行另一个线程,提升整体吞吐量。
这些技术相互配合,共同构成了现代高性能处理器的基础。理解这些底层优化原理,有助于我们在编写代码时做出更好的性能优化决策,充分发挥硬件潜力。
我是 SharkChili ,Java 开发者,Java Guide 开源项目维护者。欢迎关注我的公众号:写代码的SharkChili,也欢迎您了解我的开源项目 mini-redis:https://github.com/shark-ctrl/mini-redis。
为方便与读者交流,现已创建读者群。关注上方公众号获取我的联系方式,添加时备注加群即可加入。
# 参考
《趣话计算机底层技术》
