CPU核心知识点小结
CPU核心知识点小结
# 来聊聊图灵机
# 简介
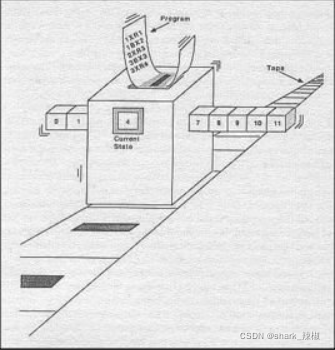
就像下面这张图一样,这就是大名鼎鼎的图灵机,他的工作方式也和现代计算机工作的原理差不多,我们的冯诺依曼模型就是以图灵机作为前身而设计的。 可以看出他时由一条很长的纸袋以及一个读写不断工作的盒子组成,这个盒子就是所谓的读写头。
# 用1+2=3来了解图灵机的工作机制
要想理解图灵机,我们不妨用一个1+2=3的例子来介绍和了解图灵机。
可以想象我们的纸带上有1、2、+这三个字符。他们不断向前进,逐渐走向读写头。
- 当读写头读到了1,发现这个是一个数字。于是就把他放到一个存储设备中,我们可以称他为图灵机的状态。
- 2也是同理,也被存到了图灵机的状态中。
- 最后遇到了+号,图灵机首先会将其放到所谓的控制单元
(ALU)中,因为它是一个运算符,就不能直接存放到状态中,这时图灵机就会通知运算单元出来干活。 - 于是1、2都会读出来,配合+号完成了一次加法计算,得到结果3,再将这个值写回纸袋中。
# 什么是冯诺伊曼模型
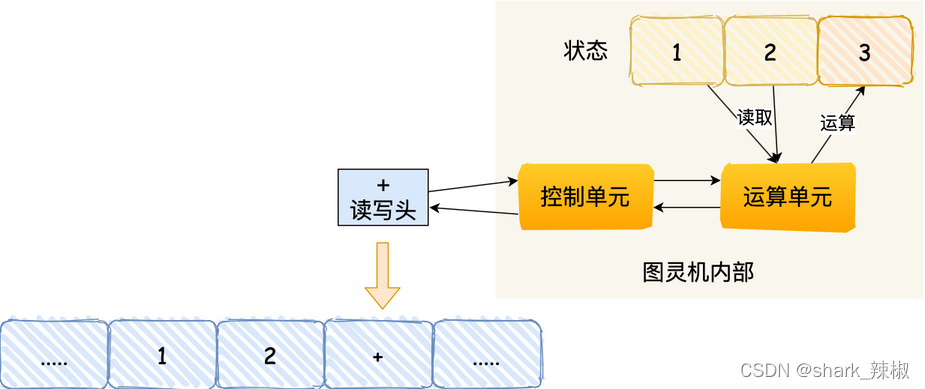
借着图灵机的思想,冯诺依曼模型也诞生了。他的工作原理也是图灵机的进阶版,相较于图灵机,他职责划分更加清晰明确。
可以看到他将进行工作的不妨划分为CPU、存储单元、输入输出设备通过控制单元调度工作,然后寄存器和运算器负责数据加载以及指令计算。而其余存储和输出输入都划分到外部。
# CPU详解
# 32位和64位CPU有什么区别
翻译成中文就是中央处理器,这东西常分为32位和64位。那么问题来了,它为什么要分32和64位呢?它的区别又是什么呢?
回答这个问题之前,笔者要说一句废话:
1字节(byte)=8位(bit)
32位就是4个字节,若CPU是32位,则说明它一次只能计算4个字节的数据。64位就是8个字节的数据。
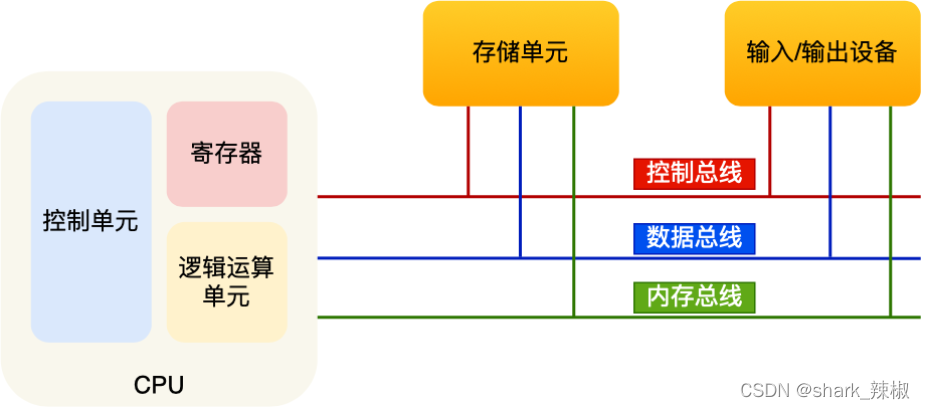
# CPU组成简介
控制单元:负责CPU工作的调度
逻辑运算单元:负责逻辑运算的。
寄存器:CPU中的寄存器就很多了,我们大概可以将他们分为三类
1. 通用寄存器:就是存那些要被计算的数据的,例如上面两个被加数1、2。 2. 程序计数器:存着下一个被运行的指令的地址。 3. 指令寄存器:存着下一条要被执行的指令,在当前指令都没结束运算前,他都会一直存在指令寄存器中。
# 什么是内存
存数据的地方,单元是byte,1byte=8bit。从0开始按顺序排列。
# 什么是总线
总线分为地址总线、数据总线和控制总线
- 地址总线:顺着这条线就知道找到数据或者指令的地址。
- 数据总线:用于读写内存中的数据。
- 控制总线:用于发送和接收信号,例如中断信号等。当然CPU收到信号后的响应也是通过控制总线来通知的。
# 计算机存储器介绍
计算机有着各种各样的存储设备,比如一断电数据就会丢失的内存,以及可以持久化数据的磁盘等等。
其实CPU内部也有可以存储数据的东西,他就是寄存器。说到寄存器,可以说他是CPU内部最核心的存储器,因为它最接近CPU,所以速度是最快的。根据CPU的位宽,32位的CPU寄存器可以存储4字节。64位则是8字节。
# 寄存器
一个CPU中一般就会有几十到几百不等的寄存器。
寄存器的访问速度一般在半个时钟周期就能够完成了,以笔者的电脑为例,笔者电脑主频为2.8Ghz,换算成时钟周期就是1/2.8=0.36ns(纳秒),所以半个时钟周期就是0.18ns。可见寄存器的访问速度是有多快,也正是寄存器的速度足够快,CPU才能够快速读写寄存器的数据,再通过进行译码指令,再计算和执行。给人感觉电脑很"快"。
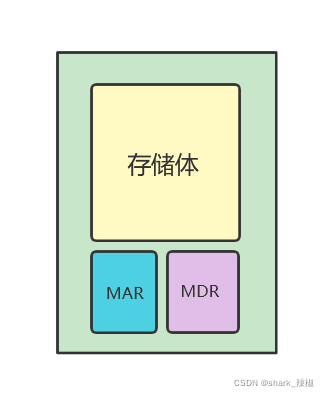
而它的结构也如下所示,具体部件工作内容大抵是:
- 存储体:是数据的存储单元。
- MAR(存储地址寄存器
Memory Address Register):由译码器进行地址译码后,它再拿着译码结果找到相应的存储单元,说白了就是个找存储单元的。 - MDR(存储数据寄存器
Memory Data Register):暂存要从MAR找到的存储单元对应的数据
如果说我们把CPU比作我们的脑子的话,那么上文所描述的寄存器存储的数据就可以比作我们脑子刚刚获取到且正处于思考的事务,虽然数据量有限但是处理速度非常快。
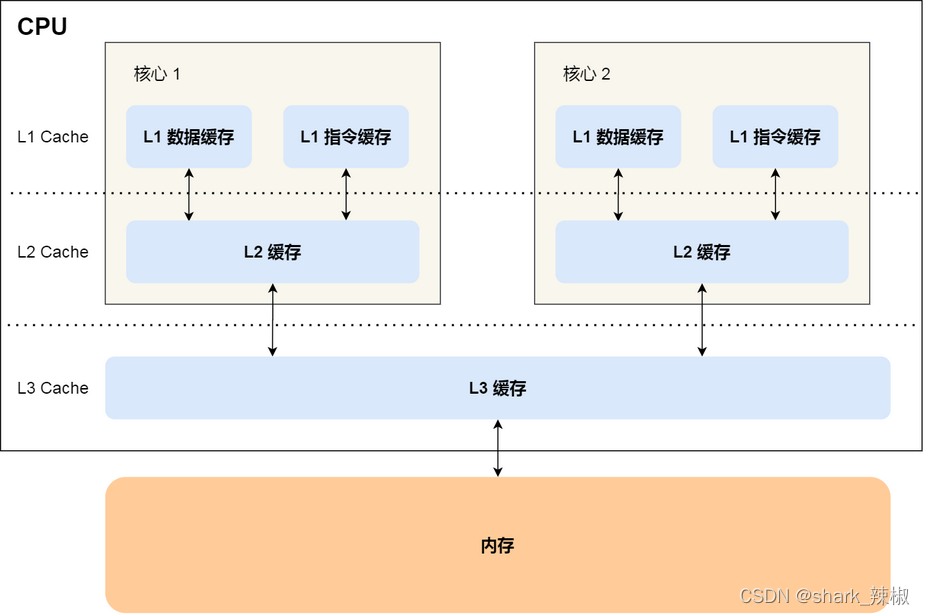
# CPU CACHE
相比于寄存器相对慢一些的就是CPU cache,它是一种用SRAM(Static Random-Access Memory,静态随机存储器) 的芯片,通常1个bit的数据需要6个晶体管,明显密度不大。也正说明他电路简单,所以访问速度很快。缺点也很明显,一断电数据就没了。
它分为三级,L1 cache,L2 cache,L3 cache。其中L1 cache相较于其他两种缓存更加接近CPU,访问速度差不多2-4个时钟周期。所以它的速度也比后两者快一些。
我们可以是使用如下两条命令查看L1 cache的数据容量大小和指令容量大小,以笔者虚拟机的Linux为例,他们的容量都是32k
cat /sys/devices/system/cpu/cpu0/cache/index0/size
cat /sys/devices/system/cpu/cpu0/cache/index1/size
2
3
根据存储的类别它可以分成数据缓存和指令缓存两种类别。如果说我们思考的数据好比寄存器中的数据。那么人脑中短期记忆的数据就是L1 cache,长期记忆的数据就是L2、L3 cache。而L2 cache访问速度差不多10-20个时钟周期,在笔者的虚拟机的容量为256k(数据基本都在几百k到几MB那样),具体可以键入如下指令查看
cat /sys/devices/system/cpu/cpu0/cache/index2/size
L3最慢的,访问速度差不多20-60个时钟周期吧,容量相较于上面两种缓存更大一些,笔者键入如下命令时看到差不多有9000k那样
cat /sys/devices/system/cpu/cpu0/cache/index3/size
# 什么是内存
紧接的是内存,它的速度排在三级缓存之后,我们可以把它比作人们工作或者学习时使用的笔记本,当脑子记不起东西时,就会翻阅自己之前的笔记本。
内存的组成就比较特殊了,它是由DRAM (Dynamic Random Access Memory,动态随机存取存储器)的芯片制作的。 相较于cache,密度更高,功耗也会更低一些,所以访问速度很慢,要200-300个时钟周期,造价也便宜,而且断电了数据也不会丢失。
# 什么是硬盘
最后就是硬盘,它的速度是最慢的,接着上面的例子来说,它可以那些人脑记不起来,笔记本都找不到的数据,只有去书房的书柜查找对应书籍对应的数据。
硬盘分为SSD和HDD两种,前者结构和内存差不多,但是数据可以持久化,速度大概是内存的 1/10-1/1000。
HDD是读写性能最差的,同样可以持久化,通过物理读写的方式来访问数据,速度大概是内存的1、10w。
由于近几年,SSD价格和HDD差不多,老硬盘逐渐被淘汰了。
让我们来总结一下CPU的存储器的结构,可以看出每个CPU都有1、2级的缓存,3级是共享的。然后就是内存和硬盘。
访问数据也是同理寄存器没有找缓存,缓存一直往下找也没有,就找内存,在没有就去硬盘里面查询。
# 小结
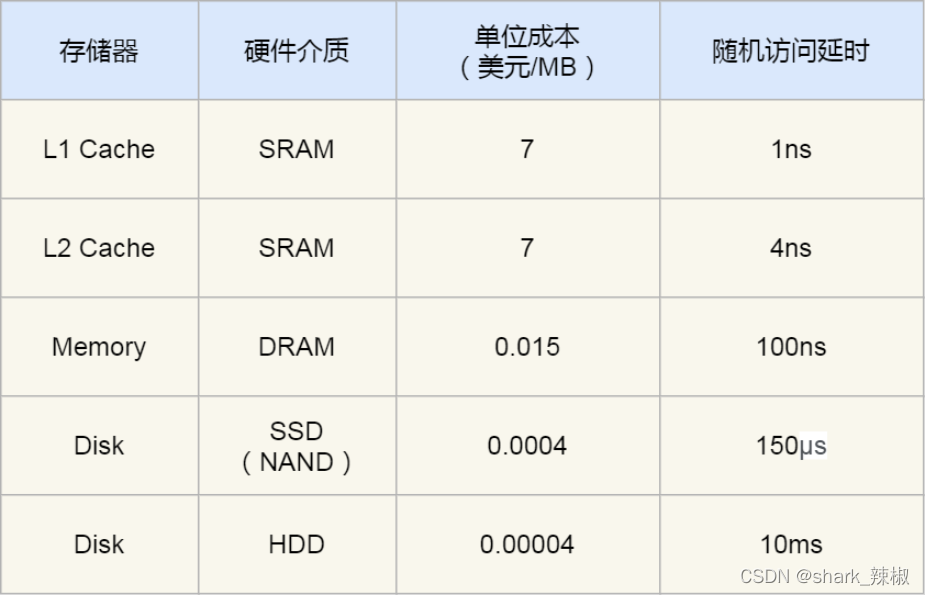
再总结一下,速度越往下越慢,价格也是越往下越便宜。具体可以参照下图的对照表
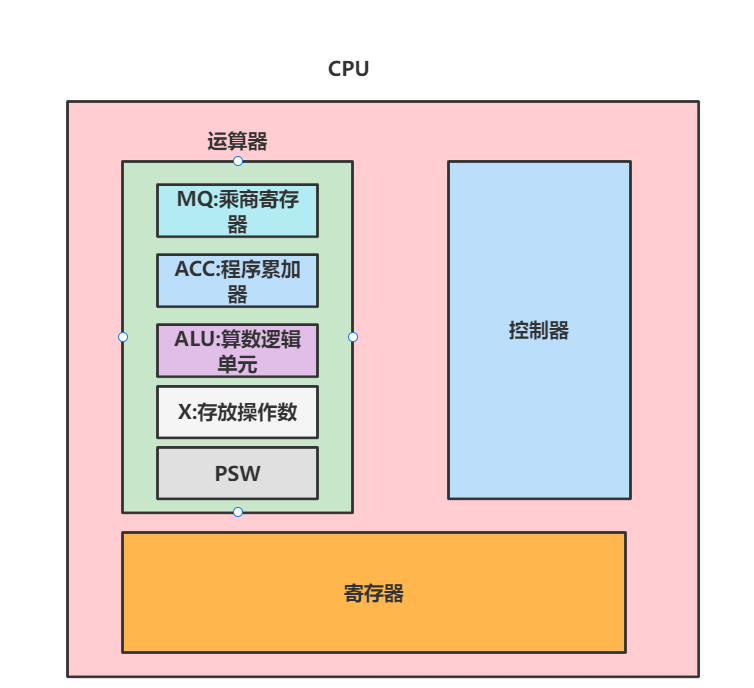
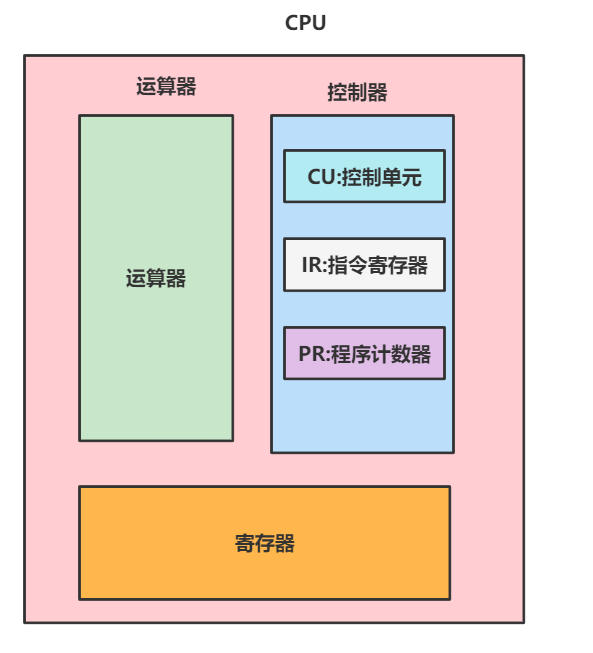
# 运算器
运算器也是CPU的主要组成部分,如下图所示,运算器是由以下几个部分组成的。
- ACC:程序累加器,用于存放操作数,或者运算符。
- MQ:乘商寄存器,在乘、除运算时,用于存放操作数或者运行结果。
- X:这个是操作数寄存器,用于存放操作数。
- ALU:算数逻辑单元,是运算器的核心部分,他就是通过内部复杂的电路实现算术运算、逻辑运算。
# 什么是控制器
控制器则是调度指令执行的核心组成部分,它有以下几个部分:
- CU控制单元:分析指令,给出控制信号。
- IR:存放当前执行的指令。
- PR:存放指令地址。
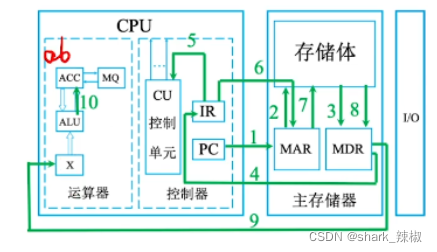
# 总线日常工作流程
一般情况下,CPU的工作只需通过地址总线找到数据的内存地址,再通过数据总线完成传输即可。
# 输入、输出设备
我们的键盘、显示器、鼠标等就是典型的输入、输出设备了。他们的和cpu的交互也是通过控制总线来进行的。
# 线路位宽与cpu位宽的把控
数据是通过线路来传输的,假如线路位宽只有1位,且我们的内存有4G,也就是2 ^ 32,那么访问某个内存地址就需要cpu来来回回的和地址总线交互32次才知道,这种效率肯定是非常低下的。 对此,解决办法就是加大cpu的位宽,尽可能的做到cpu位宽大于或者等于线路位宽。 当然,这种说法也不是说小于线路位宽不行,只是运算效率不高而已。假如我们有两个8字节(64位)的数据要相加,而我们的cpu是32位。那么我们只能先将高32位相加,再将低32位相加,最后在进行进位等操作后才能得到结果。
# 通过一个更细致的例子了解这些过程CPU工作过程
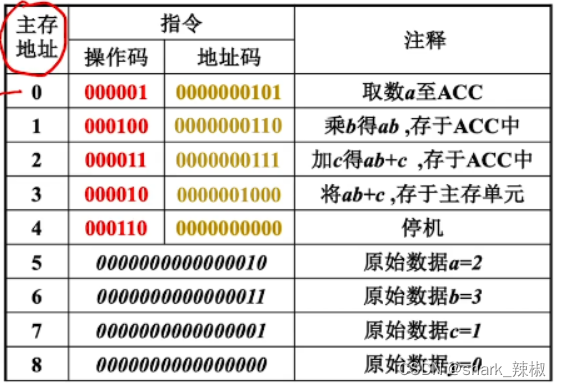
这就是我们日常开发所写的代码,一段很简单的乘法加法综合运算再赋值给y
 它会被翻译成机器码后存到主存中,就会变成下图所示的一条条指令
它会被翻译成机器码后存到主存中,就会变成下图所示的一条条指令
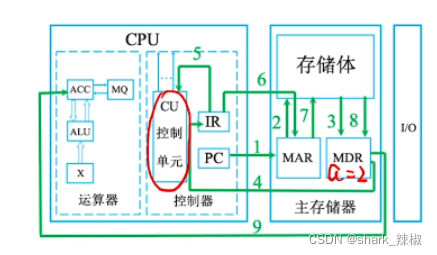
- 如下图所示,首先
PC(程序计数器)会指向第一条指令,MAR通过程序记录器中得到这条指令的地址 - 然后MAR会顺着这个地址从存储体中找到这个地址的实际指令将其存到MDR中。
MDR之后会通过数据总线将这条数据存放到IR中,IR会将指令操作码即指令前半部分送到CU中。- CU(控制单元)通过分析得知这是一个取数的操作
- 然后拿到指令后半段部分,得知地址是5
- 然后IR再将这个指令的地址码送到MAR中,MAR再从存储器中得到这个值,并放到MDR中
- 最后MDR再将数据放到ACC中
- 由此结束一次取值的操作,最后pc在自增一下指向下一条指令
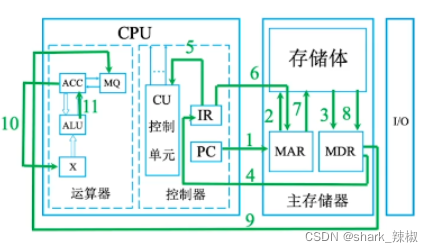
 pc拿到第2条指令时,会进行如下操作
pc拿到第2条指令时,会进行如下操作
- PC会将地址告诉MAR,MAR通过存储体中找到这个指令,将其放到MDR中
- MDR将指令通过总线送到IR中
- IR将前半部分给CU,CU分析出这是一个乘法
- 然后IR
(存放当前执行的部分)在通过MAR询问指令后半部分地址对应的内容,MAR通过存储体捞到数据送到MDR中 - MDR将数据送到MQ中(因为这是乘法)
- ACC将之前存储的值送到X中
- 然后CU告诉ALU这是一个乘法操作
- 然后ALU进行计算得出结果,再将其存放到ACC(累加器)中
- 由此完成第二条指令,程序计数器自增,增多少看cpu位宽。
同样的第3条指令也是如此,由于存取指令过程差不多,我们就从第9步开始分析:
- 首先顺着指令拿到被加数,将其放至X中
- CPU告诉ALU接下来要进行一个加法操作
- ALU将累加器的值与其进行一次运算,最终得到结果再存入ACC中