 聊聊Redis中缓存淘汰算法的实现
聊聊Redis中缓存淘汰算法的实现
# 写在文章开头
reids作为内存数据,对于内存资源也有不错的管理的策略,最常见就是结合LRU算法进行缓存淘汰的实现,我们都知道redis主流程是由一个线程实现的,所以为了保证时间和空间的完美平衡,redis对于LRU算法做了一定的改造,而本文将从源码分析的角度深入分析一下redis中LRU算法的实现。
Hi,我是 sharkChili ,是个不断在硬核技术上作死的 java coder ,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。

# 详解redis缓存置换算法的设计与实现
# 传统LRU算法的实现
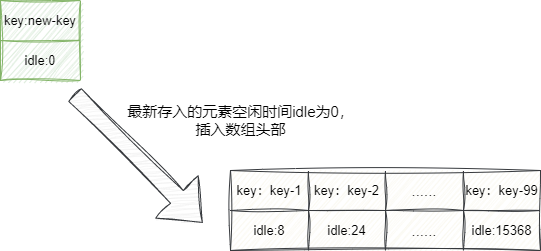
LRU顾名思义是最近最少使用算法(Least Recently Used),传统实现是通过链表来管理所有的键值对的访问情况,最新插入的节点默认为最近访问的元素所以直接插入在数组头。
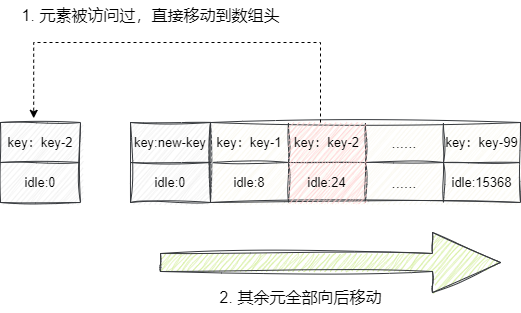
此后每当链表中元素被访问一次,该键值对的空闲时间就会做一次更新,并移动至数组头中,然后将其他的元素全部向后移动一位。
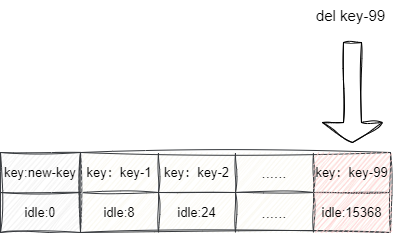
当内存无法容纳更多元素时,LRU算法就会从数组尾部即空闲时间最长的元素删除,以保证容纳最新插入的元素。
可以看到这种需要实时的维护各个元素的访问时间,对于时间的开销是非常大的,试想如果redis需要针对每个键值对都维护一个访问时间的操作,那么性能肯定是大打折扣的,显然不符合我们秒级操作的内存数据库的意愿。
可能很多读者认为造成这种操作低效的原因是使用数组,实际上笔者之所以用数组举例是结合redis的使用场景,要知道我们的redis操作和键值对大部分时间是活跃度内存中的,如果我们将LRU实现的数据结构改为链表,那么这其中的内存操作也是一个重量级的存在。
# 详解redis对于LRU算法改造
所以redis基于此算法的思路结合使用上做了一定的改造,redis本质上是通过maxmemory和maxmemory-policy决定内存淘汰策略,我们假设我们配置的maxmemory为8G以及maxmemory-policy这个淘汰策略配置为allkeys-lru ,当redis使用内存空间超过8G之后,redis就会随机从各个数据库中随机抽检5个键值对(这个只由maxmemory_samples变量决定默认为5),按照缓存置换算法将这些元素不断追加到eviction_pool这个数组中,待遍历结束后,将数组末尾的元素对应的键值对释放掉,如此往复直到使用空间小于配置的内存空间最大值。
可以看到这种做法,通过样本抽取和惰性缓存淘汰保证了时间和空间的完美平衡:
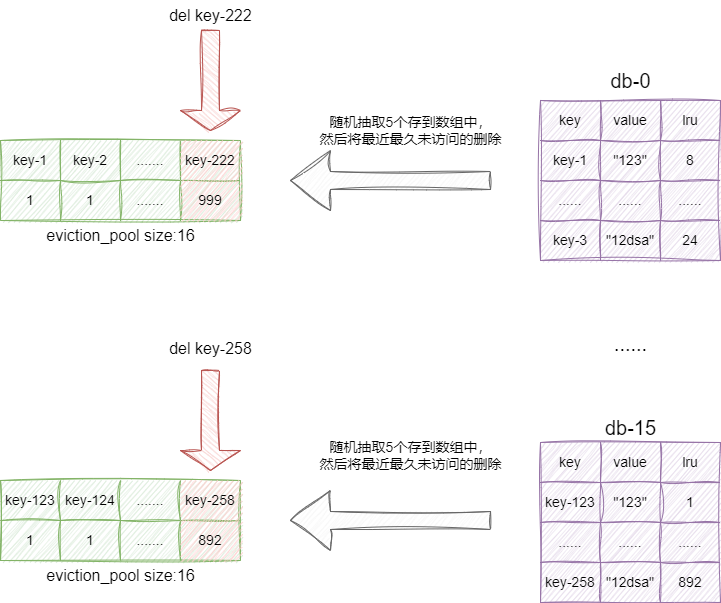
# 源码印证实现
通过上文的解析我们了解redis缓存淘汰算法的基本设计思路,我们不妨通过源码的方式加以印证,当调用set等指令添加新的键值对的时候,redis就会给这个键值对的key创建一个redisObject对象,然后将lru字段设置为当前时间,注意这个时间是精确到秒的时间戳,这意味着如果我们在同一秒内存创建多个key,它们得到的时间戳都是一样的:
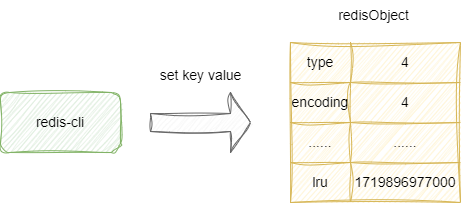
对应我们给出添加新元素时,创建key时分配redisObject内存空间时的核心代码段:
robj *createObject(int type, void *ptr) {
robj *o = zmalloc(sizeof(*o));
o->type = type;
o->encoding = REDIS_ENCODING_RAW;
o->ptr = ptr;
o->refcount = 1;
//建立连接后创建对象设置的时钟周期
o->lru = LRU_CLOCK();
return o;
}
2
3
4
5
6
7
8
9
10
11
12
后续的每当用户键入get等操作指令时,redis指令每次都会调用lookupKey方法查看这个key是否存在,如果存在就会更新这个key的LRU:
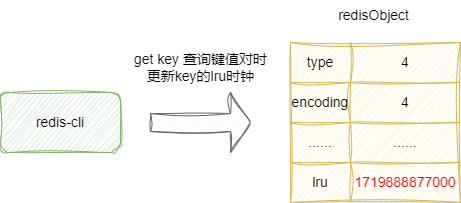
对应的我们可以在db.c中看到这段源码的实现:
robj *lookupKey(redisDb *db, robj *key) {
dictEntry *de = dictFind(db->dict,key->ptr);
//如果key存在进入循环
if (de) {
robj *val = dictGetVal(de);
//键值对被访问且未出于rdb和aof直接更新当前键值对的时钟
if (server.rdb_child_pid == -1 && server.aof_child_pid == -1)
//更新当前key对象的lru值
val->lru = LRU_CLOCK();
return val;
} else {
return NULL;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
后续的每次redis服务端解析指令时,都会调用processCommand方法,该方法就会检查当前用户是否配置最大内存,如果有则调用freeMemoryIfNeeded查看是否需要内存空间:
int processCommand(redisClient *c) {
//......
//如果最大内存设置为非0,则调用freeMemoryIfNeeded
if (server.maxmemory) {
int retval = freeMemoryIfNeeded();
if ((c->cmd->flags & REDIS_CMD_DENYOOM) && retval == REDIS_ERR) {
//......
return REDIS_OK;
}
}
//......
}
2
3
4
5
6
7
8
9
10
11
12
13
最终freeMemoryIfNeeded就可以看到redis对于LRU的核心实现,可以看到其内部会检查当前使用的内存并查看是否超过最大内存上限,如果超过了则根据策略定位数据,则进入循环每次淘汰一批元素直到内存空间充裕为止,以笔者为例配置的是allkeys-lru则用全局字典数据库中随机抽检5个元素(若是volatile-lru则到记录时效的数据库中随机抽检元素),按照直接插入排序算法将当前元素插入到有界的数组eviction_pool中,从最后排序结果的元素中将末尾的元素释放:
int freeMemoryIfNeeded(void) {
//......
//获取删除输出缓冲区和aof缓冲区大小的已使用内存
mem_used = zmalloc_used_memory();
//......
/* Check if we are over the memory limit. */
//未超过则直接返回
if (mem_used <= server.maxmemory) return REDIS_OK;
//......
/* Compute how much memory we need to free. */
mem_tofree = mem_used - server.maxmemory;
mem_freed = 0;
latencyStartMonitor(latency);
//释放空间小于需要释放空间才结束循环
while (mem_freed < mem_tofree) {
int j, k, keys_freed = 0;
//遍历数据库
for (j = 0; j < server.dbnum; j++) {
//.......
//根据内存淘汰策略选择全局字典dict或者是设置过期时间的字典expires
if (server.maxmemory_policy == REDIS_MAXMEMORY_ALLKEYS_LRU ||
server.maxmemory_policy == REDIS_MAXMEMORY_ALLKEYS_RANDOM)
{
dict = server.db[j].dict;
} else {
dict = server.db[j].expires;
}
//.......
/* volatile-lru and allkeys-lru policy */
//lru缓存置换逻辑
else if (server.maxmemory_policy == REDIS_MAXMEMORY_ALLKEYS_LRU ||
server.maxmemory_policy == REDIS_MAXMEMORY_VOLATILE_LRU)
{
struct evictionPoolEntry *pool = db->eviction_pool;
while(bestkey == NULL) {
//传入待淘汰的字典和存储淘汰的空间eviction_pool
evictionPoolPopulate(dict, db->dict, db->eviction_pool);
for (k = REDIS_EVICTION_POOL_SIZE-1; k >= 0; k--) {
if (pool[k].key == NULL) continue;
de = dictFind(dict,pool[k].key);
//从pool将这key的索引元素清空
sdsfree(pool[k].key);
//......
//如果de不为空则说明本次释放了有效的元素空间,跳出循环,执行后续逻辑将这个de键值对内存空间释放
if (de) {
bestkey = dictGetKey(de);
break;
} else {
/* Ghost... */
continue;
}
}
}
}
//......
//释放这个最近最近被访问的key
if (bestkey) {
long long delta;
robj *keyobj = createStringObject(bestkey,sdslen(bestkey));
//......
dbDelete(db,keyobj);
//......
keys_freed++;
//......
}
}
//......
}
latencyEndMonitor(latency);
latencyAddSampleIfNeeded("eviction-cycle",latency);
return REDIS_OK;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
这里我们给出evictionPoolPopulate中采集元素并通过直接插入法选拔出最近最少被访问的16个元素的核心实现,可以看到它通过直接插入排序法找到当前元素可插入的索引位置k将元素插入,然后调整前后元素,如果元素空间不足以容纳新元素则将0位置即相对访问较多的元素释放,然后将当前元素追加到数组中:
#define EVICTION_SAMPLES_ARRAY_SIZE 16
void evictionPoolPopulate(dict *sampledict, dict *keydict, struct evictionPoolEntry *pool) {
int j, k, count;
dictEntry *_samples[EVICTION_SAMPLES_ARRAY_SIZE];
dictEntry **samples;
//创建samples数组空间
if (server.maxmemory_samples <= EVICTION_SAMPLES_ARRAY_SIZE) {
samples = _samples;
} else {
samples = zmalloc(sizeof(samples[0])*server.maxmemory_samples);
}
//.......
//随机采样5个key
count = dictGetSomeKeys(sampledict,samples,server.maxmemory_samples);
//遍历count
for (j = 0; j < count; j++) {
unsigned long long idle;
sds key;
robj *o;
dictEntry *de;
//获取采样的键值对
de = samples[j];
key = dictGetKey(de);
//.......
if (sampledict != keydict) de = dictFind(keydict, key);
//定位这个对象并判断这个对象空闲时间
o = dictGetVal(de);
idle = estimateObjectIdleTime(o);
//.......
k = 0;
while (k < REDIS_EVICTION_POOL_SIZE &&
pool[k].key &&
pool[k].idle < idle) k++;
//基于循环结果计算合适的查询位置k
//插入到第一个位置
if (k == 0 && pool[REDIS_EVICTION_POOL_SIZE-1].key != NULL) {
//.......
continue;
} else if (k < REDIS_EVICTION_POOL_SIZE && pool[k].key == NULL) {//找到中间的位置插入
/* Inserting into empty position. No setup needed before insert. */
} else {
if (pool[REDIS_EVICTION_POOL_SIZE-1].key == NULL) {//在k处插入,并移动k到end所有的元素
memmove(pool+k+1,pool+k,
sizeof(pool[0])*(REDIS_EVICTION_POOL_SIZE-k-1));
} else {
//将最前面的元素淘汰,然后追加进去
k--;
sdsfree(pool[0].key);
memmove(pool,pool+1,sizeof(pool[0])*k);
}
}
//插入到pool数组中
pool[k].key = sdsdup(key);
pool[k].idle = idle;
}
if (samples != _samples) zfree(samples);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
# 小结
以上便是笔者对于缓存淘汰算法的实现的源码分析,除了LRU以外,其实redis在3.0之后的新版本中也给出LFU(最少使用)算法的实现,其本质思路都是差不多的,只不过规则改为访问频率,本文到此结束,希望对你有帮助。
我是 sharkchili ,CSDN Java 领域博客专家,开源项目—JavaGuide contributor,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。 因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。

