 深度探索:Spring借助Easy - Es开启ElasticSearch操作实战篇章
深度探索:Spring借助Easy - Es开启ElasticSearch操作实战篇章
# 写在文章开头
这篇文章原本是采用spring-boot-starter-data-elasticsearch演示如何在spring boot项目中使用es,经一个读者的建议打算将文章加以重构,改用一个更强大号称傻瓜级ElasticSearch搜索引擎ORM框架Easy-Es,像操作MP一样操作ES。
需要补充的是,在编写这篇文章之前,笔者对Easy-Es文档进行相对详细的阅读,个人认为Easy-Es1.0版本在实际项目中的集成和使用相对稳定一些,所以本文将以Easy-Es1.0版本展开演示,所以为保证后续集成步骤的顺利建议读者采用2.5.x +版本的Spring Boot(笔者直接使用2.6.0)。

Hi,我是 sharkChili ,是个不断在硬核技术上作死的技术人,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
# 详解Easy-Es集成与操作
# 集成Easy-Es与创建索引
集成Easy-Es的时首先自然是引入相关依赖,以笔者为例,项目中引用的版本就是1.1.1版本:
<dependency>
<groupId>cn.easy-es</groupId>
<artifactId>easy-es-boot-starter</artifactId>
<version>1.1.1</version>
</dependency>
2
3
4
5
Easy-Es默认情况下会扫描我们的文档实体完成索引创建,所以我们就可以直接声明文档的实体类型即直接使用,以本文为例,笔者创建的测试文档包含id、标题、内容几个字段,因为本案例多用内容的检索且文本内容多是中文,所以在进行字段设计的时候针对内容字段尝试将其设置为text类型,并将索引文档时用的分词器设置为ik_max_word以保证切出尽可能多的词项提升检索相关性数据的概率,同时指明搜索分词器为ik_smart以保证检索词汇尽可能少切割得到最相关的结果:
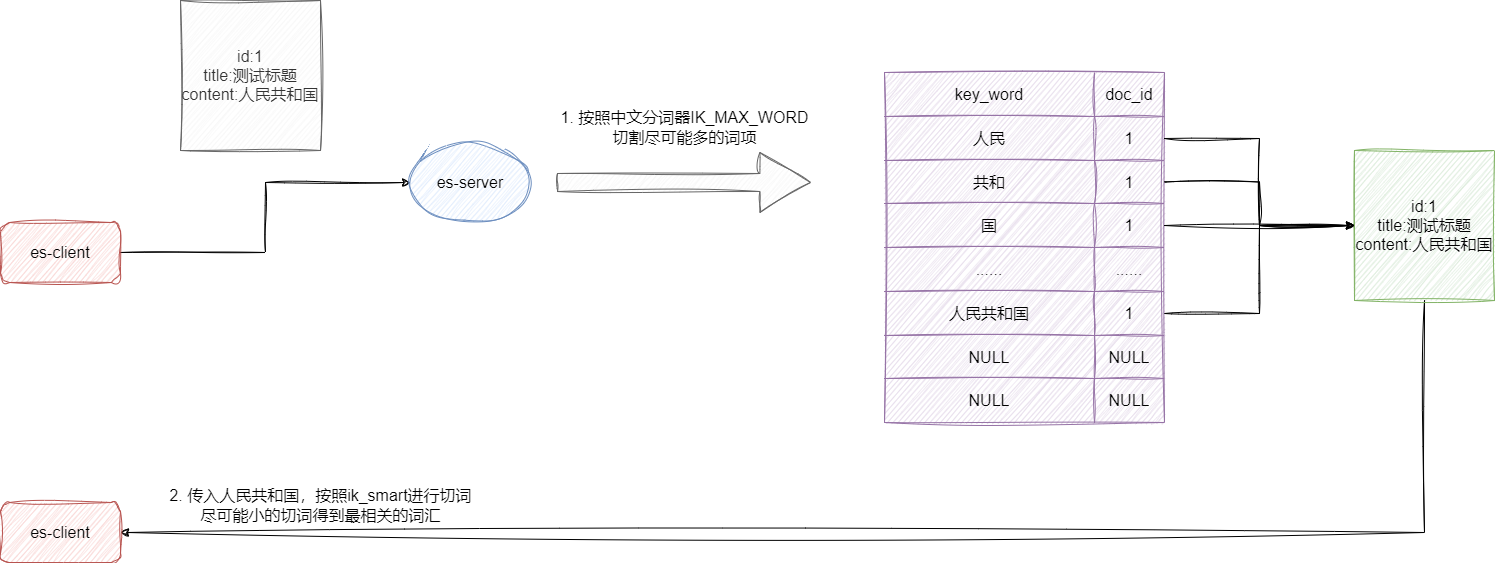
对应的我们给出这段代码示例,默认情况下Easy-Es会将所有的字符串类型设置为keyword,由于内容字段的特殊性,笔者通过IndexField指明索引和搜索的分词器以达到上述效果:
@Data
public class Document {
/**
* es中的唯一id
*/
private String id;
/**
* 文档标题
*/
private String title;
/**
* 文档内容
*/
@IndexField(fieldType = FieldType.TEXT, analyzer = Analyzer.IK_MAX_WORD, searchAnalyzer = Analyzer.IK_SMART)
private String content;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
基于文档的实体类,编写Es持久层mapper,和MP类似通过继承BaseEsMapper获得文档操作的所有能力并通过泛型指明操作的文档类型为Document:
public interface DocumentMapper extends BaseEsMapper<Document> {
}
2
3
完成上述操作后,在启动器上注明mapper的全路径开启自动扫描注入:
@EsMapperScan("com.sharkChili.mapper")
完成上述配置之后将项目启动,如果输出Congratulations auto process index by Easy-Es is done !则说明文档自动创建完成,此时我们就可以开始基本操作了:

当然Easy-Es也支持显示的创建和删除索引,需要注意1.x版本使用的模式是平滑模式回基于原有索引进行迁移,如果我们希望手动创建索引可以将模式改为手动模式:
easy-es.global-config.process_index_mode: manual
这里我们也直接给出使用示例:
Boolean createRes = documentMapper.createIndex();
Boolean delRes = documentMapper.deleteIndex("document");
2
# 插入数据
对应我们也给出一份插入的基础使用示例,如下所示可以看到操作步骤也只是声明一下待插入文档的实体然后调用insert即可完成插入:
Document document = new Document();
document.setTitle("测试标题");
document.setContent("测试的文本内容");
Integer count = documentMapper.insert(document);
log.info("count:{}", count);
2
3
4
5
在用户使用的角度,看起来像是操作MP一样,实际上在执行insert方法时,Easy-Es底层也是和Mybatis类似,用到动态代理的机制,通过扫描实体类信息获得索引名称,然后构建restful风格的API请求执行文档插入,完成后直接将生成的id结果设置到组装实体中,并返回操作成功数:
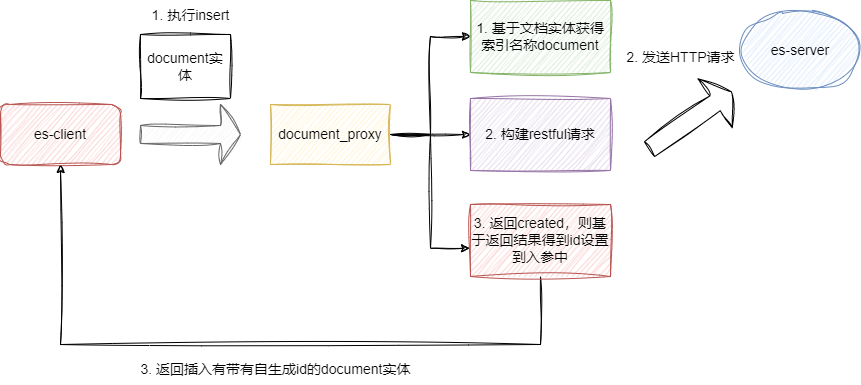
我们可以直接从BaseEsMapperImpl的insert方法的源码中看到实现,它首先会基于实体类调用getIndexName获得索引名称,然后调用insert执行当前文档的插入工作:
@Override
public Integer insert(T entity) {
//......
//基于实体获得索引名称后调用insert进行插入
return insert(entity, EntityInfoHelper.getEntityInfo(entityClass).getIndexName());
}
2
3
4
5
6
不入其内部即可看到基于我们的实体信息构建restful api的入参,通过Easy-Es聚合的原生RestHighLevelClient发送POST请求提交文档,如果成功则将文档的id赋值到实体上返回给用户:
private Integer doInsert(T entity, String indexName) {
// 基于实体构建请求入参
IndexRequest indexRequest = buildIndexRequest(entity, indexName);
indexRequest.setRefreshPolicy(getRefreshPolicy());
try {
//发送POST请求插入文档
IndexResponse indexResponse = client.index(indexRequest, RequestOptions.DEFAULT);
//如果插入成功则将返回的id值赋值到传入的实体上
if (Objects.equals(indexResponse.status(), RestStatus.CREATED)) {
setId(entity, indexResponse.getId());
return BaseEsConstants.ONE;
} else if (Objects.equals(indexResponse.status(), RestStatus.OK)) {
// 该id已存在,数据被更新的情况
return BaseEsConstants.ZERO;
} else {
//......
}
} catch (IOException e) {
//......
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 查询数据
上文提到字符串类型默认情况下是keyword类型,所以title字段查出是精准匹配的,对应的查询组装如下所示通过LambdaEsQueryWrapper的eq函数指明等值查询,检索一条标题为测试标题,最终就可以将上一步插入操作的文档返回:
String title = "测试标题";
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
//底层走must term查询
wrapper.eq(Document::getTitle, title);
Document document = documentMapper.selectOne(wrapper);
log.info(JSONUtil.toJsonStr(document));
2
3
4
5
6
7
这里我们查看eq函数的底层实现可以看到实现精准匹配本质上就是通过must查询term为测试标题的文档:
@Override
public Children eq(boolean condition, String column, Object val, Float boost) {
return doIt(condition, TERM_QUERY, MUST, column, val, boost);
}
2
3
4
其底层操作逻辑和插入操作整体步骤是差不多的,即通过代理构建restful api发起请求并将结果映射为java bean返回,这里我们就贴出selectOne操作底层的核心实现,即位于BaseEsMapperImpl的getSearchResponse方法,它就是会基于我们的参数调用search接口,并将响应结果返回给上层组装成实体对象给用户:
private SearchResponse getSearchResponse(LambdaEsQueryWrapper<T> wrapper, Object[] searchAfter) {
// 构建es restHighLevelClient 查询参数
SearchRequest searchRequest = new SearchRequest(getIndexNames(wrapper.indexNames));
// 用户在wrapper中指定的混合查询条件优先级最高
SearchSourceBuilder searchSourceBuilder = Optional.ofNullable(wrapper.searchSourceBuilder)
.map(builder -> {
// 兼容混合查询时用户在分页中自定义的分页参数
Optional.ofNullable(wrapper.from).ifPresent(builder::from);
Optional.ofNullable(wrapper.size).ifPresent(builder::size);
return builder;
}).orElseGet(() ->
//基于我们的wrapper构建出请求入参
WrapperProcessor.buildSearchSourceBuilder(wrapper, entityClass));
//......
// 执行查询
SearchResponse response;
try {
response = client.search(searchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
throw ExceptionUtils.eee("search exception", e);
}
//将结果返回
printResponseErrors(response);
return response;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
源码逻辑实现如上所示,这里我们就看看document文档底层代理基于我们的入参所构建的请求参数searchSourceBuilder ,很明显就是一个典型的restful api参数:
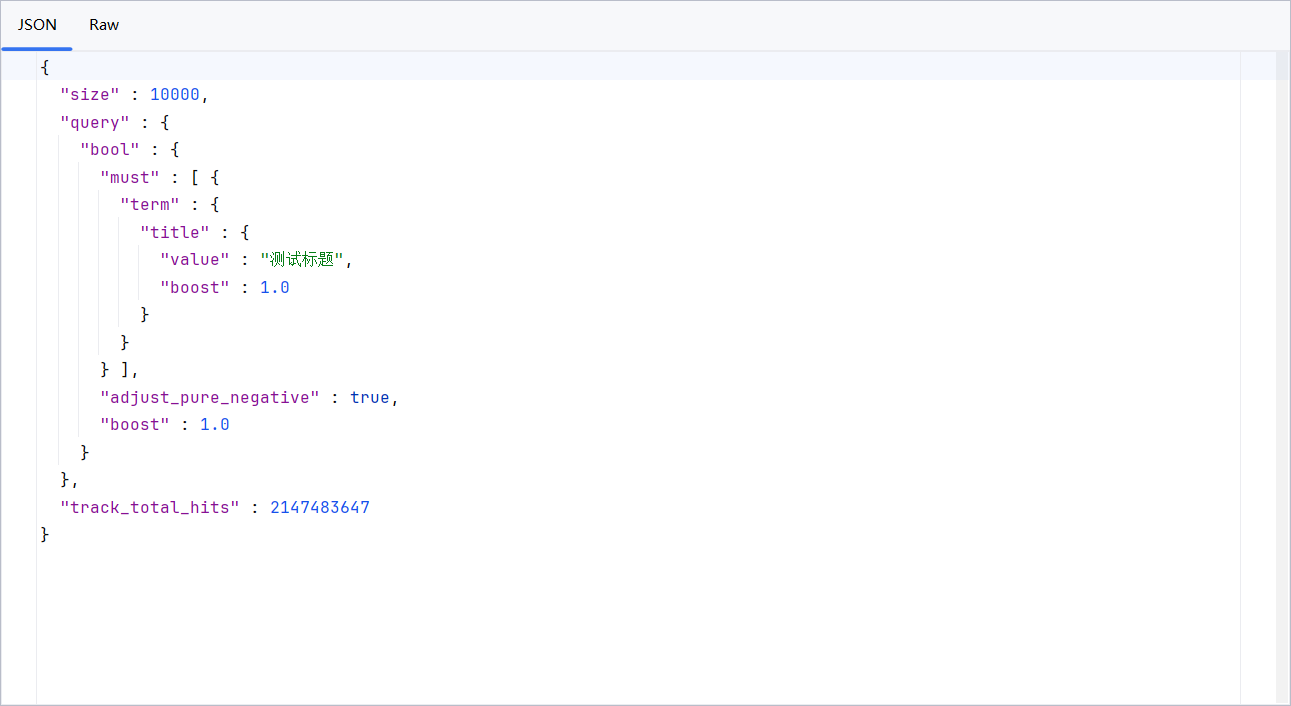
对于自然语言处理的文本检索,也就是match查询,Easy-Es也做了很好的封装,对应的使用示例如下所示:
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
wrapper.match(Document::getContent, "你好,这是 elasticsearch操作教程");
List<Document> documentList = documentMapper.selectList(wrapper);
if (CollUtil.isNotEmpty(documentList)) {
log.info("size:{}", documentList.size());
log.info("first data:{}", JSONUtil.toJsonStr(documentList.get(0)));
}
2
3
4
5
6
7
# 更新和删除数据
有了上述的基础,对于更新操作等操作都比较好理解了,这里我们直接贴出基于id更新操作的使用示例也是类似于主流ORM框架Mybatis,读者可参考源码了解使用步骤:
String id = "HVWfjpQBtr9x3QfTu299";
Document updateDocument = new Document();
updateDocument.setId(id);
updateDocument.setContent("修改后的文本内容");
Integer count = documentMapper.updateById(updateDocument);
log.info("update count:{}", count);
2
3
4
5
6
删除操作同理,这里就不多做赘述了:
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
String title = "测试标题";
wrapper.eq(Document::getTitle, title);
int successCount = documentMapper.delete(wrapper);
log.info("delete count:{}", successCount);
2
3
4
5
# 分页查询
和Mybatis-Plus类似,Easy-Es也针对分页查询做了很好的封装,使用时我们也仅需指定页码和页数即可完成查询:
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
wrapper.match(Document::getContent, "你好,这是 elasticsearch操作教程");
EsPageInfo<Document> documentPageInfo = documentMapper.pageQuery(wrapper, 1, 10);
log.info("query res:{}", documentPageInfo.toString());
2
3
4
从分页查询的API即pageQuery可以看到该查询本质上也是服用了BaseEsMapperImpl的getSearchResponse方法,底层回基于我们传入的参数封装from和size并发送HTTP请求获取分页结果:
private SearchResponse getSearchResponse(LambdaEsQueryWrapper<T> wrapper, Object[] searchAfter) {
// 构建es restHighLevelClient 查询参数
SearchRequest searchRequest = new SearchRequest(getIndexNames(wrapper.indexNames));
// 用户在wrapper中指定的混合查询条件优先级最高
SearchSourceBuilder searchSourceBuilder = Optional.ofNullable(wrapper.searchSourceBuilder)
.map(builder -> {
// 兼容混合查询时用户在分页中自定义的分页参数,基于我们传参的wrapper得到页数和页码构建from和size参数
Optional.ofNullable(wrapper.from).ifPresent(builder::from);
Optional.ofNullable(wrapper.size).ifPresent(builder::size);
return builder;
}).orElseGet(() -> WrapperProcessor.buildSearchSourceBuilder(wrapper, entityClass));
//......
// 执行查询
SearchResponse response;
try {
response = client.search(searchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
throw ExceptionUtils.eee("search exception", e);
}
//......
return response;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
按照ES官方的说法,默认情况下超过10000条之后的数据,from-size查询是不允许的,原因是避免多分片归并聚合所导致的OOM问题,所以对于深分页,ES官方是推荐采用search_after:https://www.elastic.co/guide/en/elasticsearch/reference/8.3/paginate-search-results.html#search-after (opens new window)
对此我们也给出searchAfter 的使用示例:
LambdaEsQueryWrapper<Document> lambdaEsQueryWrapper = EsWrappers.lambdaQuery(Document.class);
lambdaEsQueryWrapper.size(10);
// 必须指定一种排序规则,且排序字段值必须唯一 此处我选择用id进行排序 实际可根据业务场景自由指定,不推荐用创建时间,因为可能会相同
lambdaEsQueryWrapper.orderByDesc(Document::getId);
SAPageInfo<Document> saPageInfo = documentMapper.searchAfterPage(lambdaEsQueryWrapper, null, 10);
// 第一页
log.info("first page:{}", saPageInfo);
// 获取下一页
List<Object> nextSearchAfter = saPageInfo.getNextSearchAfter();
SAPageInfo<Document> next = documentMapper.searchAfterPage(lambdaEsQueryWrapper, nextSearchAfter, 10);
log.info("second page:{}", next);
2
3
4
5
6
7
8
9
10
11
12
# 小结
自此本文将Easy-Es基本集成与文档和索引的基础操作都进行的比较详尽的演示,希望对你有帮助。
我是 sharkchili ,CSDN Java 领域博客专家,mini-redis的作者,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
# 参考
es解决只能默认查询10000条数据方案:https://blog.csdn.net/m0_37899908/article/details/126687141 (opens new window)
Easy-ES官网:https://www.easy-es.cn/pages/afda12/#searchafter (opens new window)
