 Nginx核心指令小结
Nginx核心指令小结
# 简介
本文将对配置文件main段核心参数进行讲解;对server_name、location指令进行了重点讲解;通过本文的阅读,读者将能够熟练使用location指令来部署WEB业务
# main段核心参数详解
# main简介
main为nginx核心配置,它的配置参数决定nginx全局的核心配置。
# main段核心参数
# user username [group]
作用:指定nginx运行worker子进程的用户和用户组,其中用户组可以不指定。
示例:
user root;
user root root;
2
# pid dir
作用:指定nginx的master时,master写入pid的文件路径。
示例:
pid: /usr/nginx/logs/nginx.pid
# worker_rlimit_nofile number
作用:worker子进程可以打开的最大文件句柄数(注:Linux可打开最大文件句柄数为65535,所以你配置值再大最多也只能达到65535)
示例:
worker_rlimit_nofile 20480;
# worker_rlimit_core size
作用:指定worker子进程终止后写入的core文件路径,用于记录分析问题。
示例:
worker_rlimit_core 50M;
working_directory /usr/nginx/tmp;
2
# worker_cpu_affinity cpumask1 cpumask2 ......
作用:将每个worker子进程和物理CPU绑定,这样做的好处就是尽可能避免worker进程频繁在多CPU cache line中切换进而导致缓存利用率降低,导致性能下降的问题。注意这里说的是尽可能避免,worker子进程切换CPU的情况还是有可能出现的。 示例:
# 假如CPU四核 我们的4个worker需要一一绑定的话
worker_cpu_affinity 0001 0010 0100 1000;
# 假如CPU双核,我们4个worker需要绑定的话(1、3worker绑定同一个CPU,2、4同理)
worker_cpu_affinity 0001 0010 0001 0010 ;
2
3
4
# worker_priority number
作用: 指定worker子进程的nice值,以调整运行nginx的优先级(对于操作系统而言,nice值越小优先级越高) 示例:
worker_priority -10;
# worker_shutdown_timeout time
作用:指定worker子进程优雅退出的超时时间,例如在热部署时,新旧worker交接时,旧的worker遇到超时的请求的等待时间 示例:
worker_shutdown_timeout 5s;
# time_resolution time;
作用:调整worker子进程从用户态调用内核态获取时间的频率,调用频率越小,精度越粗,性能开销也小。
示例:
timer_resolution 100ms;
# daemon on|off;
作用:设定nginx的运行方式,前台运行还是后台运行,默认后台运行 示例:
daemon off;
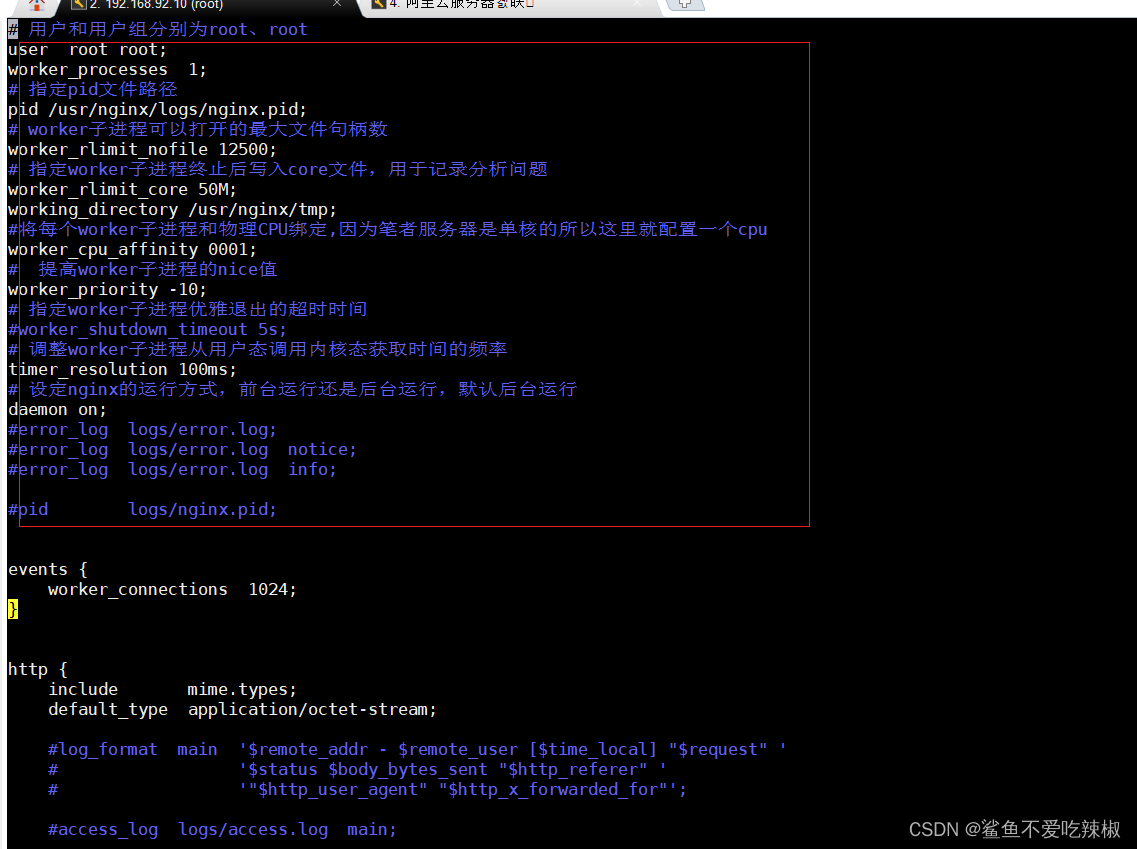
# 配置示例
这里就给出main段这些配置的示例,读者可参考注释自行了解:
# 用户和用户组分别为root、root
user root root;
worker_processes 1;
# 指定pid文件路径
pid /usr/nginx/logs/nginx.pid;
# worker子进程可以打开的最大文件句柄数
worker_rlimit_nofile 12500;
# 指定worker子进程终止后写入core文件,用于记录分析问题
worker_rlimit_core 50M;
working_directory /usr/nginx/tmp;
#将每个worker子进程和物理CPU绑定,因为笔者服务器是单核的所以这里就配置一个cpu
worker_cpu_affinity 0001;
# 提高worker子进程的nice值
worker_priority -10;
# 指定worker子进程优雅退出的超时时间
#worker_shutdown_timeout 5s;
# 调整worker子进程从用户态调用内核态获取时间的频率
timer_resolution 100ms;
# 设定nginx的运行方式,前台运行还是后台运行,默认后台运行
daemon on;
#error_log logs/error.log;
#error_log logs/error.log notice;
#error_log logs/error.log info;
#pid logs/nginx.pid;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
配置对应nginx.conf的位置如下图所示:
为了查看配置是否生效,我们可以看看nginx的logs目录是否存在上文配置的nginx.pid文件,首先我们定位一下nginx的进程号。
# 查看nginx的pid
ps -ef |grep nginx |grep -v grep
root 4169 1 0 10:21 ? 00:00:00 nginx: master process ./nginx
2
3
然后查看pid文件
# 查看pid文件是否存在,以及pid是否与上一致,以确认配置是否生效
cat /usr/nginx/logs/nginx.pid
2
3
从输出结果来看,pid值一样说明配置生效了。
4169
# events段核心参数详解
# events段参数
# use
作用:nginx指定何种事件驱动模型。 可选值:select、poll、kqueue、epoll、/dev/poll、eventport 默认配置:无 推荐配置:不指定,让nginx自己选择。
# worker_connections
作用:worker子进程能够处理的最大并发连接数 语法:worker_connections 2035; 推荐配置: worker_connects 65535/worker数 或者直接配置65535让Linux尽可能发挥最大值;
# accept_mutex
作用:是否打开负载均衡互斥锁,该配置开启后新的请求就只会找一个worker,然后下次请求进来找另一个worker这样的轮询。 语法:accept_mutex on |off; 默认配置:accept_mutex off; 推荐配置:accept_mutex on;
# accect_mutex_delay
作用:新连接分配给worker子进程的超时时间,和第3条配置配合使用,当一个请求找到一个worker等到时间超过这条配置设置的时间时,就去找其他worker了。 默认配置:accect_mutex_delay 500ms; 推荐配置:accect_mutex_delay 200ms;
# lock_file:
作用:负载均衡互斥锁文件存放路径 默认值: lock_file /usr/nginx/logs/nginx.lock 推荐配置: lock_file /usr/nginx/logs/nginx.lock
# muti_accept
作用:worker子进程可以接收的多个请求 可选值:on、off 默认配置:multi_accept off; 推荐配置:multi_accept on;
# events 段配置示例
events 段配置示例如下所示,读者可参考注释了解:
events {
# worker能够处理的最大并发数
worker_connections 1024;
# 开启互斥锁
accept_mutex on;
# 请求分配到worker,等待worker的最大时间
accept_mutex_delay 100ms;
#开启后worker能够处理多请求
multi_accept on;
}
2
3
4
5
6
7
8
9
10
11
# server_name
# 指令用法
语法: server_name name1 name2 name3 ....;
示例1:server_name : www.nginx.org;
示例2:server_name : *.nginx.org;
示例3:server_name : www.nginx.* 192.168.0.100;
2
3
4
# 匹配优先级
从高到底依次为:
- 精确匹配
- 左侧通配符匹配
- 右侧通配符匹配
- 正则表达式匹配
# 示例
如下所示,我们配置了不同匹配规则的虚拟主机,由于该域名dns无法解析,所以笔者修改了/etc/hosts 将该域名和虚拟机服务器ip配置上去。 然后对下方的html分别创建一个网页。
server {
listen 8081;
server_name www.test.com;
root html/all-match;
location / {
index index.html;
}
}
server {
listen 8081;
server_name *.test.com;
root html/left-match;
location / {
index index.html;
}
}
server {
listen 8081;
server_name ~^sport\.test\..*$;
root html/regular-match;
location / {
index index.html;
}
}
server {
listen 8081;
server_name www.test.*;
root html/right-match;
location / {
index index.html;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# 测试
我们使用curl访问一下配置的端口
curl www.test.com:8081
2
3
可以看到该域名最先匹配到了全匹配的映射的页面all match
all match
# root和alias区别
# root
root定义路径会合映射叠加,alias会将匹配路径等价替换
如下所示,使用root进行配置时,如果我们想看到index.html,我们就必须在html/pics下再创建一个pics文件夹然后添加一个index.html,否则就会报404,所以当我们使用root时,物理路径计算方式为root配置的相对路径+映射地址,以下面配置为例,我们就需要在 html/pics/pics创建一个index.html
server {
listen 8081;
server_name localhost;
root html/pics;
location /pics {
index index.html;
}
}
2
3
4
5
6
7
8
9
# alias
alias就是等价替换了,如下所示要想访问到index.html我们就需要在html/pics下创建一个index.html即可。
server {
listen 8081;
server_name localhost;
location /pics {
alias html/pics;
index index.html;
}
}
2
3
4
5
6
7
8
9
# location指令
# 基础用法
语法
location [= | ~ | ~* | ^~] url {.....}
上下文:
server、location
# 匹配规则
# “=”匹配
使用等号属于精确匹配,内容要同表达式完全一致才匹配成功。
location = /abc/ {
.....
}
# 只匹配http://abc.com/abc
#http://abc.com/abc [匹配成功]
#http://abc.com/abc/index [匹配失败]
2
3
4
5
6
# “~”符号
执行正则匹配,区分大小写。
location ~ /Abc/ {
.....
}
#http://abc.com/Abc/ [匹配成功]
#http://abc.com/abc/ [匹配失败]
2
3
4
5
# “~*”符号
执行正则匹配,与上面不同的是该匹配是忽略大小写的。
location ~* /Abc/ {
.....
}
# 则会忽略 uri 部分的大小写
#http://abc.com/Abc/ [匹配成功]
#http://abc.com/abc/ [匹配成功]
2
3
4
5
6
7
8
# “^~”符号
该匹配符表示普通字符串匹配上以后不再进行正则匹配。
location ^~ /index/ {
.....
}
#以 /index/ 开头的请求,都会匹配上
#http://abc.com/index/index.page [匹配成功]
#http://abc.com/error/error.page [匹配失败]
2
3
4
5
6
# 不加任何符号
这种即默认情况,默认是大小写敏感,前缀匹配,相当于加了“~”与“^~”
location /index/ {
......
}
#http://abc.com/index [匹配成功]
#http://abc.com/index/index.page [匹配成功]
#http://abc.com/test/index [匹配失败]
#http://abc.com/Index [匹配失败]
2
3
4
5
6
7
# 匹配优先级
优先级由高到低如下所示,可以看到匹配规则越精确,优先级越高。
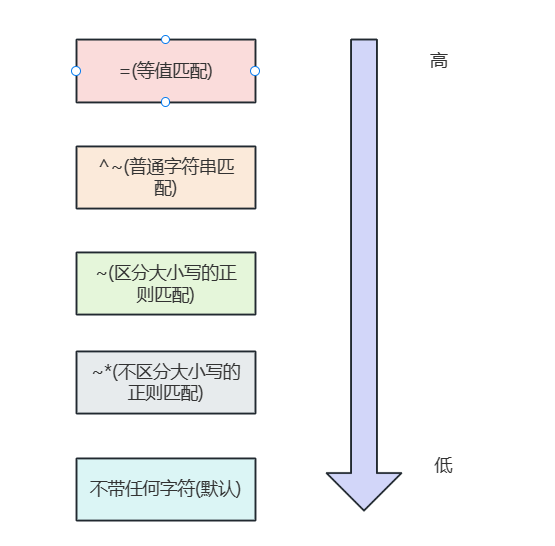
对此我们给出这样一个实例,如下所示,按照优先级规则,我们配置了精准匹配对应页面内容为match,在配置一个匹配到了即停止的匹配。完成配置后使用浏览器查阅到的页面正是精准匹配的页面,更多实验细节读者可以自行尝试,这里制作一个简单的尝试。
server {
listen 8081;
server_name localhost;
charset utf-8;
root html;
location = /pics/ {
index match_all.html;
}
location ^~ /pics/ {
index match_stop.html;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
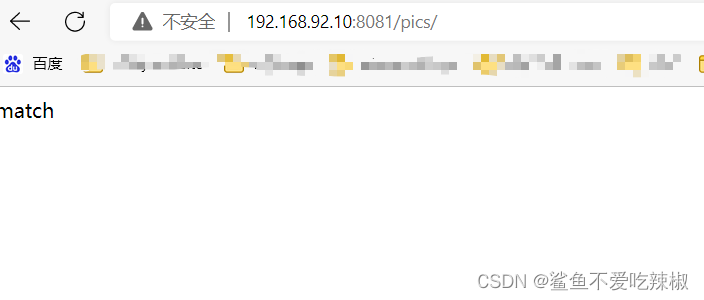
# 测试
我们键入上方配置的地址,可以看到直接匹配上了match all的网页,说明精确匹配的等值符号优先级更高。
# location中URL后结尾的反斜线
# 简介
不带斜杠的URL会优先按照目录进行查到映射文件夹的网页文件,若不存在则按照文件进行匹配,而带斜杆的一律按照文件目录进行匹配。
# 演示
不带斜杠的配置如下,我们在html下创建一个test文件夹,并编写一个网页之后键入地址可以看到下图内容
server {
listen 8081;
server_name localhost;
charset utf-8;
root html;
location /test {
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
可以看到不带斜杠的先查物理文件查到就直接返回了。

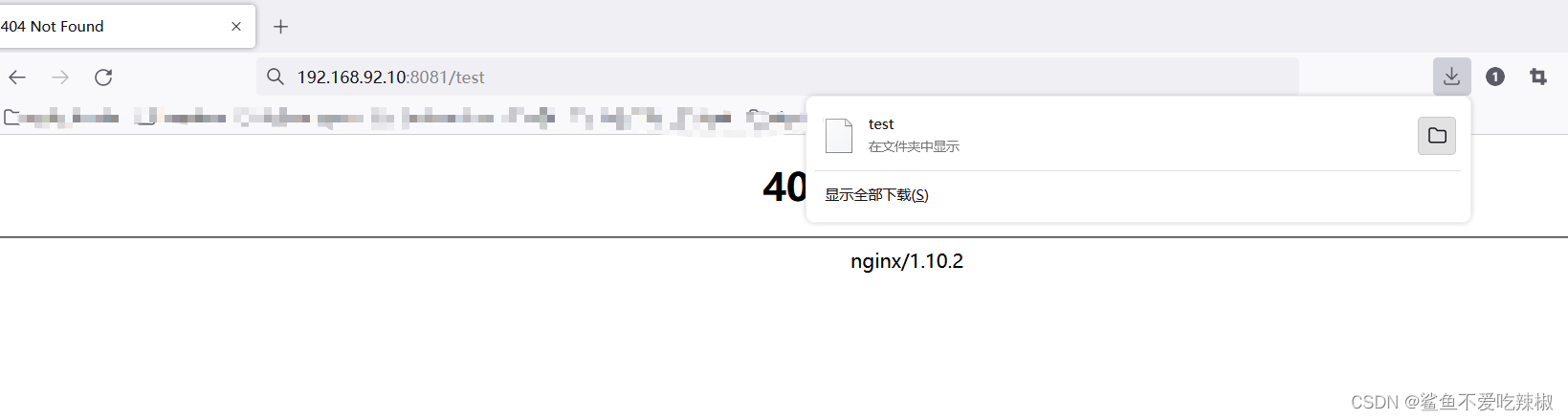
为了验证文件夹不存在就回去匹配文件,我们将test文件夹删除,并创建一个名为test的文件,内容为test file,再次请求。
可以看到浏览器直接下载了test文件。
我们再来看看带斜杠的配置。
server {
listen 8081;
server_name localhost;
charset utf-8;
root html;
location /test/ {
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
毫无疑问,直接进行映射文件查询,不存在直接404报错了。

# stub_status模块用法
# 语法
低于1.7.5版本:stub_status on;
高于1.7.5版本:stub_status;
上下文:server location
2
3
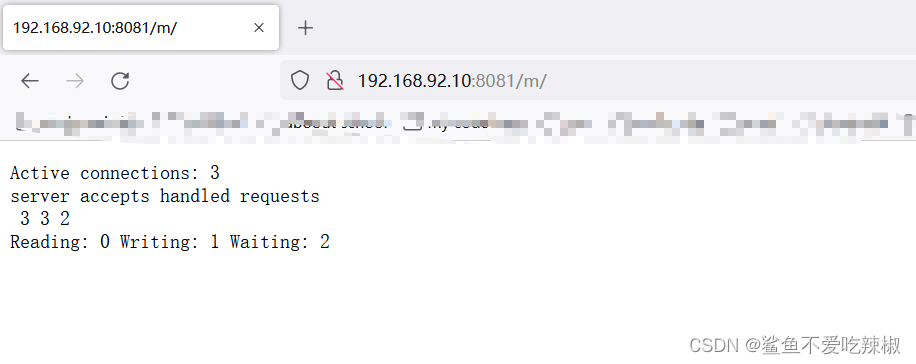
# 状态项
状态项 含义
Active Connections 活跃的连接数量
accepts 接受的客户端连接总数量
handled 处理的客户端连接总数量
requests 客户端总的请求数量
Reading 读取客户端的连接数
Writing 响应数据到客户端的连接数
Waiting 空闲客户端请求连接数量
2
3
4
5
6
7
8
9
# 内嵌变量
变量名 含义
$connections_active 同Active connections值
$connections_reading 同Reading值
$connections_wrting 同Writing值
$connections_waiting 同Waiting值
2
3
4
5
6
# 示例
server {
listen 8081;
server_name localhost;
charset utf-8;
root html;
location /m {
stub_status on;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
注意若在启动nginx时报了如下问题,说明安装nginx时没有安装stub_status模块
unknown directive "stub_status" in /usr/local/openresty/nginx/conf/conf.d/ngx_metric....
我们就需要到nginx安装包目录下用configure 文件重新编译安装一下
./configure --prefix=/usr/nginx --with-http_stub_status_module
# 测试
可以看到,我们请求到了对应地址即可监控到nginx各项指标参数。
# 参考文献
Nginx体系化深度精讲, 给开发和运维的刚需课程:https://coding.imooc.com/class/405.html (opens new window)
