 来聊聊Redis中的字符串对象的设计
来聊聊Redis中的字符串对象的设计
# 写在文章开头
redis对于性能的追求做到了极致,在之前的文章中我们redis的简单动态字符串SDS进行了详细的介绍了,而本文我将从顶层的视角来聊聊Redis基于SDS等数据结构实现一个平衡时间与空间的字符串对象。
Hi,我是 sharkChili ,是个不断在硬核技术上作死的 java coder ,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
# 详解redis中的字符串对象
# redis对象的数据结构抽象
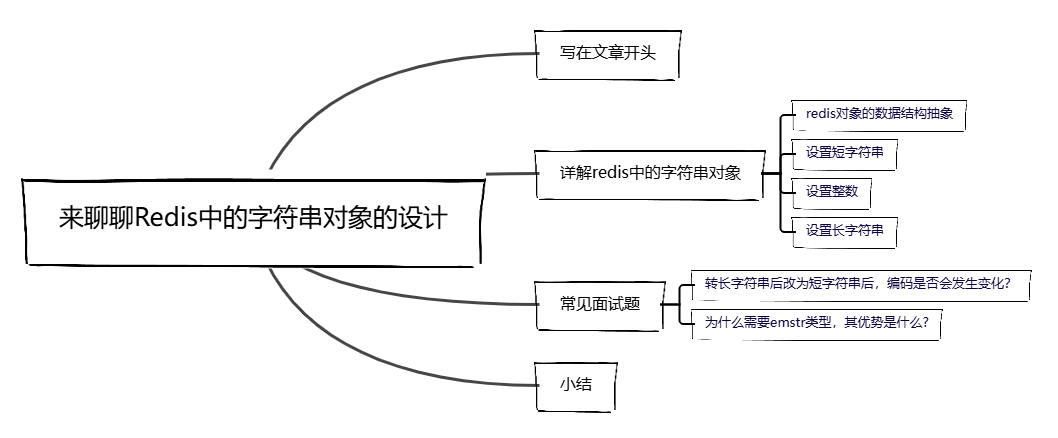
在介绍字符串对象之前,我们需要了解一下redis用redisobject来记录不同类型的对象,它用type来表示当前的对象类型,假设我们现在通过set key Hello存储一个Hello字符串,redis就会通过redisobject来维护这个字符串:
- 指定类型
type为REDIS_STRING。 - 当字符串小于39字节时,对应编码类型
encoding为embstr。 - 指针
ptr指向sds字符串数组。
我们可以在redis.h这个头文件中看到redisObject 的定义:
typedef struct redisObject {
//类型
unsigned type:4;
//编码
unsigned encoding:4;
//......
//指向值的指针
void *ptr;
} robj;
2
3
4
5
6
7
8
9
# 设置短字符串(底层采用embstr)
我们通过redis设置key的值为短字符串val:
127.0.0.1:6379> set key val
redis通过命令解析之后得到键值对的值为val,发现当前字符串val的小于39字节,便采用embstr这种编码格式创建字符串对象。embstr这种编码格式的字符串就是专门用于存储这种短字符串的,进行字符串足够小,所以在进行内存空间分配时,redis是直接一次性开辟一块连续的空间完成redisObject 和字符串对象SDS创建:
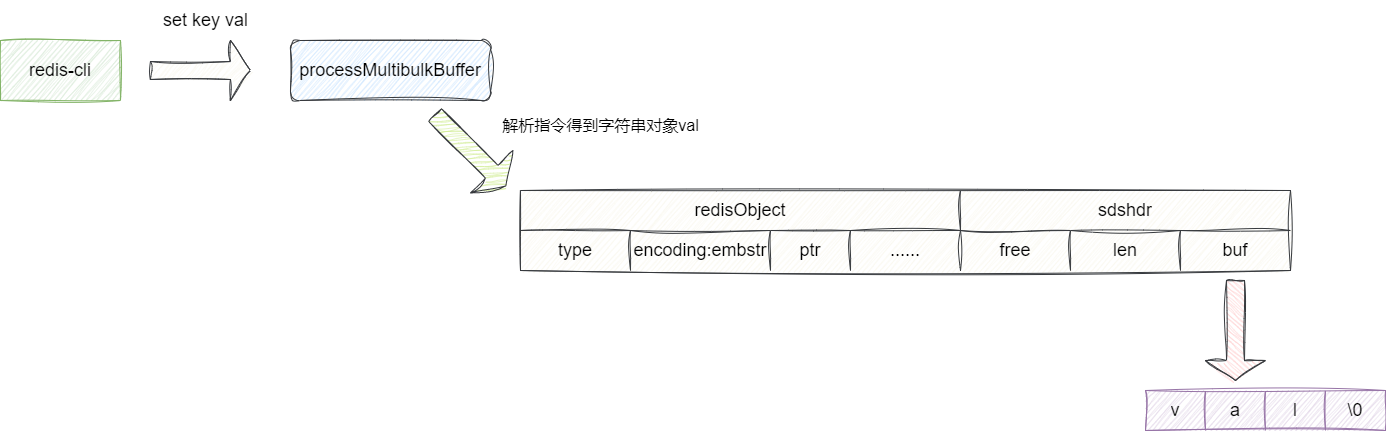
对应我们给出创建字符串对象的函数createStringObject的实现:
//决定字符串编码大小的宏定义
#define REDIS_ENCODING_EMBSTR_SIZE_LIMIT 39
robj *createStringObject(char *ptr, size_t len) {
//小于39字节,直接开辟一块连续的空间创建redisObj和sds字符串,并让redisObj指针指向这个sds字符串
if (len <= REDIS_ENCODING_EMBSTR_SIZE_LIMIT)
return createEmbeddedStringObject(ptr,len);
else
//若大于39字节则创建raw对象
return createRawStringObject(ptr,len);
}
2
3
4
5
6
7
8
9
10
11
步入createEmbeddedStringObject的逻辑我们就可以看到上文所说的逻辑:
- 开辟一块连续的内存空间创建
redisObject和SDS字符串。 redisObject维护并记录本次创建的字符串,指定类型为REDIS_STRING,编码为REDIS_ENCODING_EMBSTR。redisObject的ptr指针指向SDS字符串。- 通过
SDS记录本次字符串val。
robj *createEmbeddedStringObject(char *ptr, size_t len) {
//一次性开辟一块连续的内存空间创建robj和字符串sds
robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr)+len+1);
struct sdshdr *sh = (void*)(o+1);
//设置类型为REDIS_STRING对应编码为REDIS_ENCODING_EMBSTR
o->type = REDIS_STRING;
o->encoding = REDIS_ENCODING_EMBSTR;
//指向指向创建的sds数组
o->ptr = sh+1;
o->refcount = 1;
o->lru = LRU_CLOCK();
//设置sds的长度和空闲空间大小,并将我们本次传入的值存到buf数组中
sh->len = len;
sh->free = 0;
if (ptr) {
memcpy(sh->buf,ptr,len);
sh->buf[len] = '\0';
} else {
memset(sh->buf,0,len+1);
}
return o;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
基于上述指令完成创建之后,我们可以键入object encoding指令验证我们所说的观点:
127.0.0.1:6379> object encoding key
"embstr"
2
3
# 设置整数类型的内部优化工作
我们再假设此时执行下面这条指令将key设置为整数16:
set key 16
2
默认情况下redis还是会将16设置为短字符串emstr,在后续存储到键值对数据库之前,redis再次对齐做一个检查若发现这个值可以转换为数字时,便会将其encoding改为数字类型int。
又因为16这个数字小于10000,于是redis会直接从共享池中将16这个值的指针赋值给val字段,以此做到节约内存:
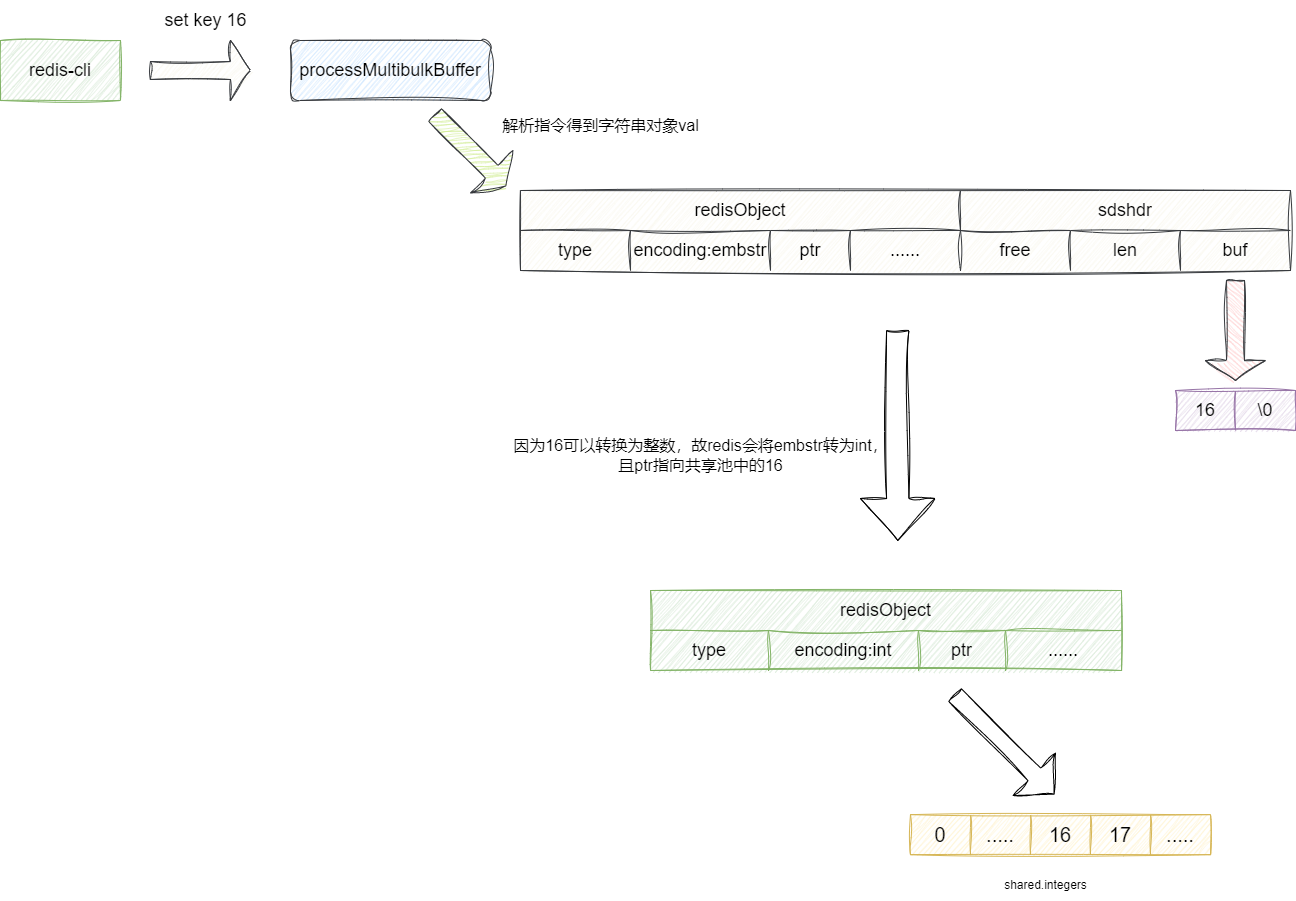
这里我们也给出解析完字符串准备执行指令将数据16存入字典的代码段,可以看到在存储前置操作时,redis会判断其是否可以进行编码转换在进行命令设置:
void setCommand(redisClient *c) {
//......
//尝试对应的value是否可以转换编码格式以节约内存空间
c->argv[2] = tryObjectEncoding(c->argv[2]);
//将(key,16)这个键值对存入内存数据库中
setGenericCommand(c,flags,c->argv[1],c->argv[2],expire,unit,NULL,NULL);
}
2
3
4
5
6
7
步入tryObjectEncoding我们之前所说的逻辑,因为16小于10000所以直接从共享池中拿到一个int对象返回出去即可:
robj *tryObjectEncoding(robj *o) {
//......
len = sdslen(s);
//当前字符串长度小于21字节且可以转换为long类型,则进入该分支
if (len <= 21 && string2l(s,len,&value)) {
//如果value小于10000则从共享池返回对应数值的指针出去
if ((server.maxmemory == 0 ||
(server.maxmemory_policy != REDIS_MAXMEMORY_VOLATILE_LRU &&
server.maxmemory_policy != REDIS_MAXMEMORY_ALLKEYS_LRU)) &&
value >= 0 &&
value < REDIS_SHARED_INTEGERS)
{
decrRefCount(o);
incrRefCount(shared.integers[value]);
return shared.integers[value];
} else {
if (o->encoding == REDIS_ENCODING_RAW) sdsfree(o->ptr);
o->encoding = REDIS_ENCODING_INT;
o->ptr = (void*) value;
return o;
}
}
//......
return o;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 设置长字符串(底层采用raw类型)
有了上面的基础我们就知道当字符串长度大于39字节就会使用Raw类型来维护存入的字符串,进行Raw类型的redis对象创建时,它会指向如下步骤:
- 先创建
SDS字符串对象物理空间记录当前的长字符串 - 然后在创建
redis对象用ptr指向SDS字符串
这一点我们可以在createStringObject这段代码中得以印证:
robj *createStringObject(char *ptr, size_t len) {
if (len <= REDIS_ENCODING_EMBSTR_SIZE_LIMIT)
return createEmbeddedStringObject(ptr,len);
else
//大于39字节创建raw类型对象存入redisObject中
return createRawStringObject(ptr,len);
}
2
3
4
5
6
7
步入createRawStringObject就可以看到我们所说的,先通过sdsnewlen创建SDS字符串,然后再基于这个创建redisObject维护这个字符串:
robj *createRawStringObject(char *ptr, size_t len) {
//通过sdsnewlen创建字符串,并将SDS字符串指针作为入参传入createObject完成redisObject创建
return createObject(REDIS_STRING,sdsnewlen(ptr,len));
}
2
3
4
5
# 常见面试题
# 转长字符串后改为短字符串后,编码是否会发生变化?
通过上文的源码解析可知当redis解析命令得到类型为字符串时,会根据字节数指定编码格式并创建raw或者embstr类型的字符串,所以长字符串转短字符串时,编码类型也是会发生变化的,这一点我们也可以通过键入如下指令印证:
127.0.0.1:6379> object encoding key
"raw"
(5.03s)
127.0.0.1:6379> set key val
OK
(7.21s)
127.0.0.1:6379> object encoding key
"embstr"
(3.66s)
2
3
4
5
6
7
8
9
10
11
# 为什么需要emstr类型,其优势是什么?
从上文可知,当字节数小于39字节时,redis创建的是embstr编码类型的字符串,这种编码类型进行内存开辟时是一次性获取一段连续的内存空间,这种做法带来了如下的好处:
- 一次性开辟
redisObeject和SDS的内存空间,空间连续,无论在创建还是内存释放都十分高效。 - 因为内存空间是连续的,借助局部性原理,在加载当前字符串对象时可以一次性加载该对象到
CPU缓存行中,操作也是迅速且高效的。
robj *createEmbeddedStringObject(char *ptr, size_t len) {
//一次性为redisObject和SDS分配连续的内存空间段
robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr)+len+1);
struct sdshdr *sh = (void*)(o+1);
//初始化redisObject和SDS字符串
o->type = REDIS_STRING;
o->encoding = REDIS_ENCODING_EMBSTR;
o->ptr = sh+1;
o->refcount = 1;
o->lru = LRU_CLOCK();
sh->len = len;
sh->free = 0;
if (ptr) {
memcpy(sh->buf,ptr,len);
sh->buf[len] = '\0';
} else {
memset(sh->buf,0,len+1);
}
return o;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
与之相反的就是raw类型的字符串,进行内存空间时需要两次的分配过程,无论在内存管理还是对象操作上都没有embstr高效:
/* Create a string object with encoding REDIS_ENCODING_RAW, that is a plain
* string object where o->ptr points to a proper sds string. */
robj *createRawStringObject(char *ptr, size_t len) {
//先调用sdsnewlen创建SDS字符串,再将SDS字符串指针作为入参完成redisObject构建
return createObject(REDIS_STRING,sdsnewlen(ptr,len));
}
2
3
4
5
6
# 小结
以上便是笔者对于redis字符串对象的解析,希望对你有帮助。
我是 sharkchili ,CSDN Java 领域博客专家,开源项目—JavaGuide contributor,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。 因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
# 参考
《Redis设计与实现》
