 一步一步教你:用 Docker Compose 完成 Seata 的整合部署
一步一步教你:用 Docker Compose 完成 Seata 的整合部署
# 写在文章开头
在当今分布式系统大行其道的时代,确保数据在不同服务间的一致性和完整性,已然成为开发者们面临的关键挑战之一。分布式事务管理因此成为了构建可靠、高效分布式应用不可或缺的一部分。 Seata,作为一款优秀的分布式事务解决方案,为解决分布式环境下的数据一致性问题提供了强大的支持。它致力于提供高性能且易于使用的分布式事务服务,帮助开发者轻松应对复杂的业务场景。 而 Docker Compose,无疑是容器编排领域的得力助手。它能够让我们通过一个简单的配置文件,便捷地定义和运行多个相互关联的 Docker 容器,极大地提升了开发和部署的效率,简化了环境管理的复杂度。 那么,当功能强大的 Seata 遇上便捷高效的 Docker Compose,会碰撞出怎样的火花呢?在本文中,我们将深入探索基于 Docker Compose 整合 Seata 的全过程,不仅会详细介绍每一个步骤,还会剖析其中的关键要点和潜在问题。无论你是分布式系统开发的新手,渴望深入了解分布式事务管理,还是经验丰富的开发者,希望借助容器技术优化现有架构,相信本文都能为你带来有价值的参考和启发。
Hi,我是 sharkChili ,是个不断在硬核技术上作死的技术人,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
# 详解docker-compose整合seata步骤
# 实践案例描述
我们用一共比较简单的购物下单的实例介绍一下本文示例的业务,当前业务用户通过接口提交订单请求,对应参数为如下,分别是用户账号id、产品id、购买的产品数量:
{
"accountCode": "0932897",
"productCode": "P001",
"count": 1
}
2
3
4
5
然后执行如下步骤:
- 基于传入的商品id和数量计算售价。
- 基于用户id和商品id、数量生成订单信息。
- 基于售价信息到用户账户上进行扣减。
- 基于传入的数量和商品id进行库存扣减。
需要注意的是上述的创建订单、余额扣减、库存扣减分别对应3个服务,这也就意味着一个原子业务需要在分布式环境下保证如下几个业务合理性:
- 用户余额不足扣款直接回滚,将生成的订单信息销毁。
- 商品库存不足同样回滚订单和库存扣减。
所以我们需要借助seata来实现分布式事务以保证分布式事务的ACID:
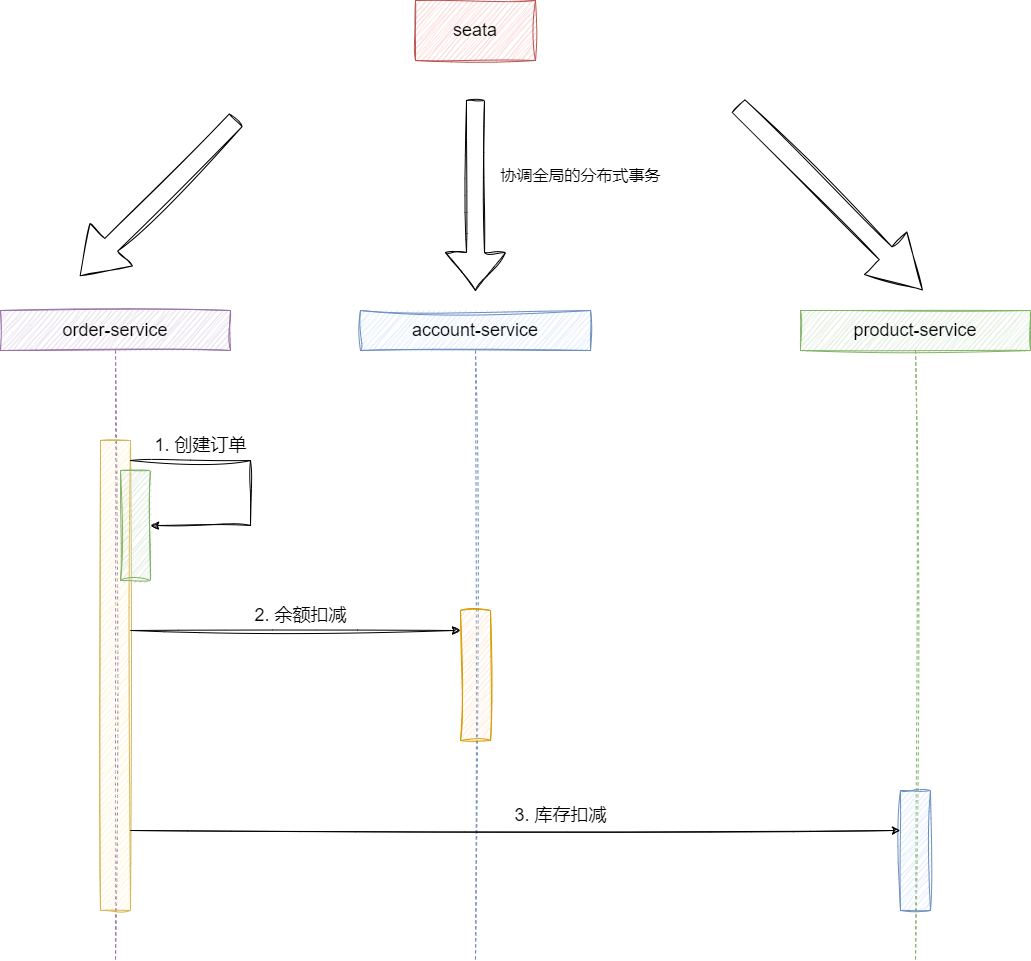
这里我们先给出对应的业务代码,后续我们将通过seata保证这块分布式事务的ACID:
public void createOrder(OrderDto orderDTO) {
Order order = new Order();
BeanUtils.copyProperties(orderDTO, order);
//调用产品服务获取商品详情
ResultData<ProductDTO> productInfo = productFeign.getByCode(orderDTO.getProductCode());
//计算总金额
BigDecimal total = productInfo.getData().getPrice().multiply(new BigDecimal(order.getCount()));
order.setAmount(total);
//创建订单
save(order);
//扣减金额
accountFeign.reduceAccount(orderDTO.getAccountCode(), order.getAmount());
//扣减商品
productFeign.deduct(orderDTO.getProductCode(), orderDTO.getCount());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 容器编排和基础环境配置
既然要用到docker-compose,所以我们就需要创建一个yml文件,以笔者为例创建一个名为seata-compose.yaml的文件,笔者都已给出注释,内容如下:
version: "3"
services:
seata-server:
image: seataio/seata-server:1.4.2
ports:
# 内外部端口映射
- "8091:8091"
environment:
# 端口号和seata的ip地址
- SEATA_PORT=8091
- SEATA_IP=x.x.x.x
volumes:
# 宿主和容器之间registry.conf文件映射地址
- "/usr/local/seata/seata-config/registry.conf:/seata-server/resources/registry.conf"
# 宿主和容器之间file.conf文件映射地址
- "/usr/local/seata/seata-config/file.conf:/seata-server/resources/file.conf"
expose:
# 暴露端口号
- 8091
# 容器名称
container_name: seata-server
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
可以看到笔者上文配置中registry.conf宿主存放位置在/usr/local/seata/seata-config/,所以我们需要在这个位置创建registry.conf,以笔者为例,这个registry.conf内容如下,可以看到笔者指明了注册中心的地址、命名空间id以及分组名。
这里唯一需要的注意的就是registry 上指明的cluster 集群节点名称,该配置会将seata绑定到nacos对应的default节点上:
registry {
# 将seata注册到nacos上
type = "nacos"
nacos {
# nacos地址
serverAddr = "ip:8848"
# 命名空间id
namespace = "63f0dbe6-ac91-4a2e-a88e-82b76f8187b6"
# 组名
group = "DEFAULT_GROUP"
# 集群节点名称
cluster = "default"
}
}
config {
# 通过nacos获取配置
type = "nacos"
nacos {
serverAddr = "ip:8848"
namespace = "63f0dbe6-ac91-4a2e-a88e-82b76f8187b6"
group = "DEFAULT_GROUP"
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 将seata常规配置存到nacos中
完成上述步骤后,我们的seata已经可以注册到nacos上了。只不过我们还需要在上述的命名空间(63f0dbe6-ac91-4a2e-a88e-82b76f8187b6)创建一个seataServer.properties的配置文件,将seata存储设置为MySQL存储,对应的配置如下注释所示:
store.mode=db
#-----db-----
store.db.datasource=druid
store.db.dbType=mysql
# 需要根据mysql的版本调整driverClassName
# mysql8及以上版本对应的driver:com.mysql.cj.jdbc.Driver
# mysql8以下版本的driver:com.mysql.jdbc.Driver
store.db.driverClassName=com.mysql.jdbc.Driver
store.db.url=jdbc:mysql://ip:3306/seata?useUnicode=true&characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useSSL=false
store.db.user= 用户
store.db.password= 数据库密码
# 数据库初始连接数
store.db.minConn=1
# 数据库最大连接数
store.db.maxConn=20
# 获取连接时最大等待时间 默认5000,单位毫秒
store.db.maxWait=5000
# 全局事务表名 默认global_table
store.db.globalTable=global_table
# 分支事务表名 默认branch_table
store.db.branchTable=branch_table
# 全局锁表名 默认lock_table
store.db.lockTable=lock_table
# 查询全局事务一次的最大条数 默认100
store.db.queryLimit=100
# undo保留天数 默认7天,log_status=1(附录3)和未正常清理的undo
server.undo.logSaveDays=7
# undo清理线程间隔时间 默认86400000,单位毫秒
server.undo.logDeletePeriod=86400000
# 二阶段提交重试超时时长 单位ms,s,m,h,d,对应毫秒,秒,分,小时,天,默认毫秒。默认值-1表示无限重试
# 公式: timeout>=now-globalTransactionBeginTime,true表示超时则不再重试
# 注: 达到超时时间后将不会做任何重试,有数据不一致风险,除非业务自行可校准数据,否者慎用
server.maxCommitRetryTimeout=-1
# 二阶段回滚重试超时时长
server.maxRollbackRetryTimeout=-1
# 二阶段提交未完成状态全局事务重试提交线程间隔时间 默认1000,单位毫秒
server.recovery.committingRetryPeriod=1000
# 二阶段异步提交状态重试提交线程间隔时间 默认1000,单位毫秒
server.recovery.asynCommittingRetryPeriod=1000
# 二阶段回滚状态重试回滚线程间隔时间 默认1000,单位毫秒
server.recovery.rollbackingRetryPeriod=1000
# 超时状态检测重试线程间隔时间 默认1000,单位毫秒,检测出超时将全局事务置入回滚会话管理器
server.recovery.timeoutRetryPeriod=1000
# 指定SeaTa的命名空间
seata.config.nacos.namespace=63f0dbe6-ac91-4a2e-a88e-82b76f8187b6
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
# 创建seata配置库存储分支事务和全局事务表
上文配置中我们指明一个名为seata_config的数据库,所以我们就需要到创建一个名为seata_config的数据库并刷入分支事务和全局事务表以及lock_table表:
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- 分支事务表
-- ----------------------------
DROP TABLE IF EXISTS `branch_table`;
CREATE TABLE `branch_table` (
`branch_id` bigint(20) NOT NULL,
`xid` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`transaction_id` bigint(20) NULL DEFAULT NULL,
`resource_group_id` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`resource_id` varchar(256) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`branch_type` varchar(8) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`status` tinyint(4) NULL DEFAULT NULL,
`client_id` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`application_data` varchar(2000) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`gmt_create` datetime(6) NULL DEFAULT NULL,
`gmt_modified` datetime(6) NULL DEFAULT NULL,
PRIMARY KEY (`branch_id`) USING BTREE,
INDEX `idx_xid`(`xid`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
-- ----------------------------
-- 全局事务表
-- ----------------------------
DROP TABLE IF EXISTS `global_table`;
CREATE TABLE `global_table` (
`xid` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`transaction_id` bigint(20) NULL DEFAULT NULL,
`status` tinyint(4) NOT NULL,
`application_id` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`transaction_service_group` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`transaction_name` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`timeout` int(11) NULL DEFAULT NULL,
`begin_time` bigint(20) NULL DEFAULT NULL,
`application_data` varchar(2000) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`gmt_create` datetime NULL DEFAULT NULL,
`gmt_modified` datetime NULL DEFAULT NULL,
PRIMARY KEY (`xid`) USING BTREE,
INDEX `idx_gmt_modified_status`(`gmt_modified`, `status`) USING BTREE,
INDEX `idx_transaction_id`(`transaction_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
CREATE TABLE `lock_table` (
`row_key` varchar(128) NOT NULL,
`xid` varchar(96) DEFAULT NULL,
`transaction_id` bigint DEFAULT NULL,
`branch_id` bigint NOT NULL,
`resource_id` varchar(256) DEFAULT NULL,
`table_name` varchar(32) DEFAULT NULL,
`pk` varchar(36) DEFAULT NULL,
`gmt_create` datetime DEFAULT NULL,
`gmt_modified` datetime DEFAULT NULL,
PRIMARY KEY (`row_key`),
KEY `idx_branch_id` (`branch_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;
SET FOREIGN_KEY_CHECKS = 1;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
# 创建undo.log表
上述步骤我们完成了seata相关的功能维护的配置,以本文的AT模式为例,为保证每个分支事务在回滚时都能准确还原,seata参照MySQL的mvcc设计思想提出undo.log的概念,如果需要实现AT模式,我们需要针对每一个分支事务的数据库刷入下面这张undo_log表:
-- 日志文件表--
CREATE TABLE IF NOT EXISTS `undo_log`
(
`branch_id` BIGINT NOT NULL COMMENT 'branch transaction id',
`xid` VARCHAR(128) NOT NULL COMMENT 'global transaction id',
`context` VARCHAR(128) NOT NULL COMMENT 'undo_log context,such as serialization',
`rollback_info` LONGBLOB NOT NULL COMMENT 'rollback info',
`log_status` INT(11) NOT NULL COMMENT '0:normal status,1:defense status',
`log_created` DATETIME(6) NOT NULL COMMENT 'create datetime',
`log_modified` DATETIME(6) NOT NULL COMMENT 'modify datetime',
UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`)
) ENGINE = INNODB
AUTO_INCREMENT = 1
DEFAULT CHARSET = utf8 COMMENT ='AT transaction mode undo table';
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 启动seata将其注册到nacos中
完成这些步骤之后,我们就可以启动seata容器查看是否注册到容器中,我们在seata-compose.yaml文件所在的路径键入这条命令
docker-compose -f seata-compose.yaml up -d
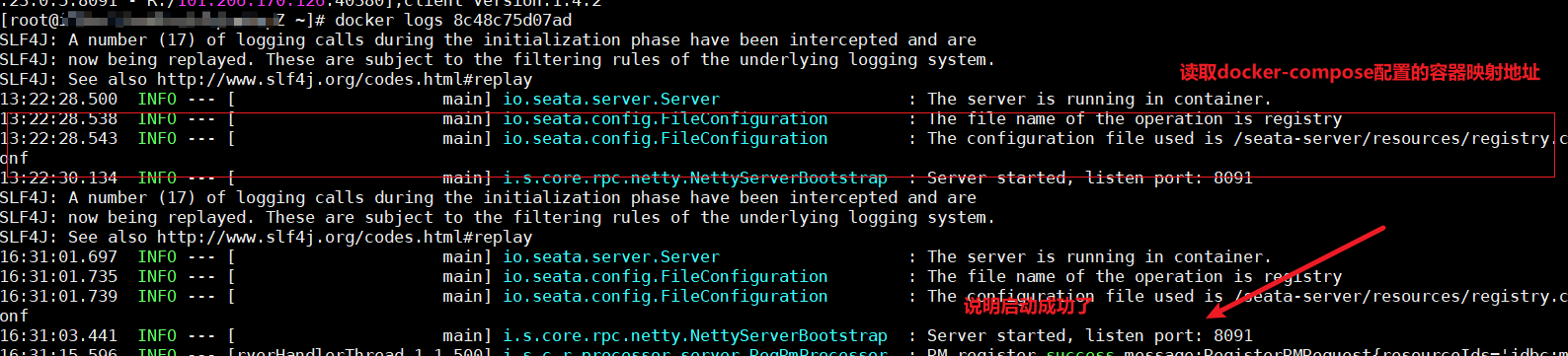
完成这条命令后,我们通过docker ps获取到seata的id值,以笔者为例,容器的id为8c48c75d07ad,所以我们键入:
docker logs 8c48c75d07ad
如下图所示,如果正常读取到registry.conf文件以及输出端口号,就说明启动成功了。
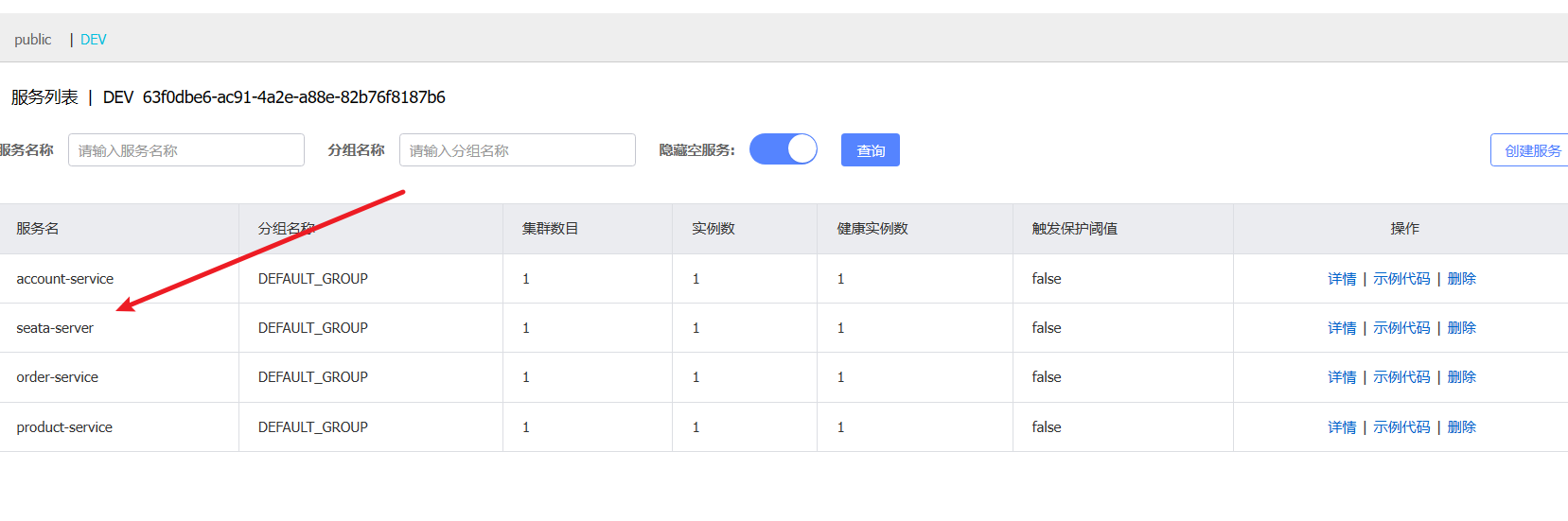
查看nacos对应命名空间的服务列表,可以看到seata-server已经成功注册了,自此我们的seata就已经部署成功了。
# 服务注册到seata
完成这些步骤后,我们就可以将本地服务注册到seata中,首先服务必须引入依赖seata-spring-boot-starter,只有引入这个依赖才会自动装配seata相关组件确保服务可以注册到seata中。
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
<exclusions>
<!--版本较低,1.3.0,因此排除-->
<exclusion>
<artifactId>seata-spring-boot-starter</artifactId>
<groupId>io.seata</groupId>
</exclusion>
</exclusions>
</dependency>
<!--版本在父工程中配置,seata starter 采用1.4.2版本-->
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
<version>1.4.2</version>
</dependency>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
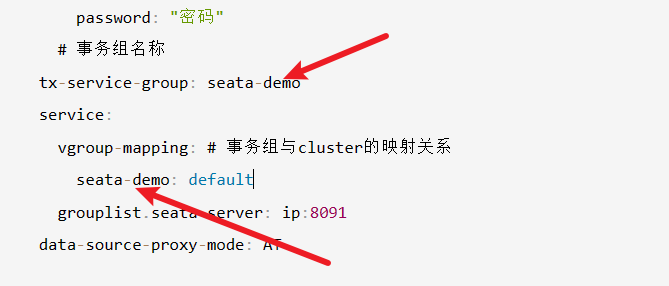
然后修改每个服务的yml文件配置,如下所示,这里需要注意一点,因为笔者在上文seataServer.properties指定事务分组名称为seata-demo,所以我们这里的tx-service-group也是seata-demo。然后vgroup-mapping也指明seata-demo和我们nacos集群(笔者在上文registry.conf将cluster配置为default)的映射关系。
具体配置如下所示:
seata:
# TC服务注册中心的配置,微服务根据这些信息去注册中心获取tc服务地址
registry:
# 注册中心类型 nacos
type: nacos
nacos:
# nacos地址
server-addr: ip:8848
# namespace,默认为空
namespace: 63f0dbe6-ac91-4a2e-a88e-82b76f8187b6
# 配置组
group: DEFAULT_GROUP
# seata服务名称
application: seata-server
username: nacos
password: 密码
config:
type: nacos
nacos:
server-addr: ip:8848
group : "DEFAULT_GROUP"
namespace: "63f0dbe6-ac91-4a2e-a88e-82b76f8187b6"
dataId: "seataServer.properties"
username: "nacos"
password: "密码"
# 事务组名称
tx-service-group: seata-demo
service:
vgroup-mapping: # 事务组与cluster的映射关系
seata-demo: default
grouplist.seata-server: ip:8091
data-source-proxy-mode: AT
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
注意yml文件对缩进的格式要求很高,读者可以参考笔者的配置进行修改,笔者本次部署时遇到服务始终无法注册到seata中,控制台持续输出can not get cluster name in registry config xxxx, please make sure registry config correct
经过查阅源码NettyClientChannelManager的代码段,大抵推测yml配置没有生效,排查半天得出yml缩进有问题。
//笔者这里debug进去发现group取的SEATA-GROUP和我们的指定的DEFAULT-GROUP不一样
String clusterName = registryService.getServiceGroup(transactionServiceGroup);
if (StringUtils.isBlank(clusterName)) {
LOGGER.error("can not get cluster name in registry config '{}{}', please make sure registry config correct",
ConfigurationKeys.SERVICE_GROUP_MAPPING_PREFIX,
transactionServiceGroup);
return;
}
2
3
4
5
6
7
8
9
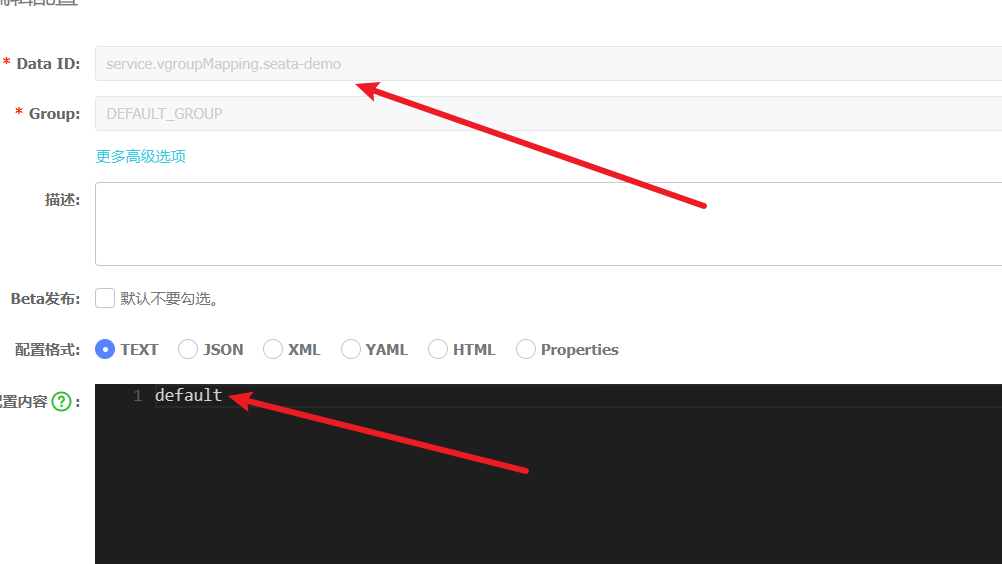
笔者查阅github一些issue发现,上面这个问题可能还需要补充这样一个步骤:
在上文配置的命名空间中增加一条配置,data-id为service.vgroupMapping.事务分组名称,以笔者为例就是service.vgroupMapping.seata-demo,内容为default
# 启动服务将其注册到seata中
完成后启动服务,以笔者的order-service为例,启动后如果seata日志中输出这样一段话,则说明启动成功了。
16:31:15.596 INFO --- [rverHandlerThread_1_1_500] i.s.c.r.processor.server.RegRmProcessor : RM register success,message:RegisterRMRequest{resourceIds='jdbc:mysql://ip:3306/cloud_alibaba', applicationId='order-service', transactionServiceGroup='seata-demo'},channel:[id: 0x25ec75ef, L:/172.23.0.5:8091 - R:/220.200.39.1:30735],client version:1.4.2
16:31:15.732 INFO --- [rverHandlerThread_1_2_500] i.s.c.r.processor.server.RegRmProcessor : RM register success,message:RegisterRMRequest{resourceIds='jdbc:mysql://ip:3306/cloud_alibaba', applicationId='order-service', transactionServiceGroup='seata-demo'},channel:[id: 0x25ec75ef, L:/172.23.0.5:8091 - R:/220.200.39.1:30735],client version:1.4.2
2
3

其他服务同理,都完成后,我们的下单服务代码加一个GlobalTransactional注解,即可完成分布式事务了,感兴趣的读者可以在扣款或者库存扣减调用上设置一个错误的调用,最终都会看到订单回滚且当前用户的余额和库存都不会有扣减:
@Override
@GlobalTransactional
@Transactional(rollbackFor = RuntimeException.class)
public void createOrder(OrderDto orderDTO) {
Order order = new Order();
BeanUtils.copyProperties(orderDTO, order);
//调用产品服务获取商品详情
ResultData<ProductDTO> productInfo = productFeign.getByCode(orderDTO.getProductCode());
//计算总金额
BigDecimal total = productInfo.getData().getPrice().multiply(new BigDecimal(order.getCount()));
order.setAmount(total);
//创建订单
save(order);
//扣减金额
accountFeign.reduceAccount(orderDTO.getAccountCode(), order.getAmount());
//扣减商品
productFeign.deduct(orderDTO.getProductCode(), orderDTO.getCount());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 小结
以上便是笔者基于Docker 整合seata的整体步骤,希望对你有帮助。
我是 sharkchili ,CSDN Java 领域博客专家,mini-redis的作者,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
# 参考
SpringCloud Alibaba微服务实战九 - Seata 容器化:https://mp.weixin.qq.com/s?__biz=MzAwMTk4NjM1MA==&mid=2247484301&idx=1&sn=530c1b08f73baf7c6bc8585ea4ed9469&chksm=9ad019ccada790da478e8acf50519cf8e293040e468433503ee64f0c7bc00d5f7aab32897553&token=1863605670&lang=zh_CN#rd (opens new window)
Seata 番外篇:使用 docker-compose 部署 Seata Server(TC)及 K8S 部署 Seata 高可用:https://juejin.cn/post/7139788897961115678 (opens new window)
分布式事务解决方案之 Seata(二):Seata AT 模式:https://juejin.cn/post/7141187088971972621#heading-4 (opens new window)
分布式事务解决方案之 Seata(二):Seata AT 模式:https://juejin.cn/post/7141187088971972621#heading-2 (opens new window)
SpringCloud-Alibaba-Nacos服务注册和配置中心--一篇入门:https://blog.csdn.net/weixin_44520739/article/details/109811171 (opens new window)
seata-server启动是内网ip导致springboot项目无法找到seata服务 :https://blog.csdn.net/calm_encode/article/details/123032336 (opens new window)
Seata AT模式所需的表global_table、branch_table 、lock_table和undo_log :https://blog.csdn.net/weixin_45950398/article/details/124043857 (opens new window)
Seata AT模式所需的表global_table、branch_table 、lock_table和undo_log :https://blog.csdn.net/weixin_45950398/article/details/124043857 (opens new window)
分布式事务seata1.4.2使用配置 :https://juejin.cn/post/7024023033094504479 (opens new window)
