 StarRocks基础入门指南
StarRocks基础入门指南
[toc]
# 写在文章开头
本文将针对starrocks(后续简称为sr)基本概念和架构设计等理念展开介绍,希望对具有OLAP需求的数据库使用者有所启发。
我是 SharkChili,Java 开发者,Java Guide开源项目维护者。欢迎关注我的公众号:写代码的SharkChili,也欢迎您了解我的开源项目 mini-redis:https://github.com/shark-ctrl/mini-redis。
为方便与读者交流,现已创建读者群。关注上方公众号获取我的联系方式,添加时备注加群即可加入。
# SR基本介绍
作为一款新型的OLAP类型数据库,sr利用MPP(Massively Parallel Processing)框架,即大规模并行处理数据库,它通过数据和处理任务分布在多服务节点并行处理各自子单元,最大化的利用各个节点的CPU和IO资源,同时该结构还支持灵活的水平拓展且可以保证线性的性能增长,所以在框架设计层面,SR的具备着如下几个优势:
- 高性能:可快速处理TB、PB级别的数据
- 高可用:分布式节点可灵活调整
- 高扩展:分布式算法保证灵活的水平拓展,且单机故障不会导致整个系统瘫痪
- 适合复杂分析:最大化利用各个节点资源,保证高效处理任务
同时,SR采用向量化存储引擎,即针对数据采用列式存储的方式组织数据,即一条完整的元用户数据,会拆分成不同的列进行组织,例如我们现在有一条数据电子产品,3000,手机,在传统OLTP例如mysql数据库上,它是将整条数据以二进制数据的方式写入到指定页上。而SR则是以列式存储的方式将列别、价格、产品名称拆分写入到每个列的数据行上:
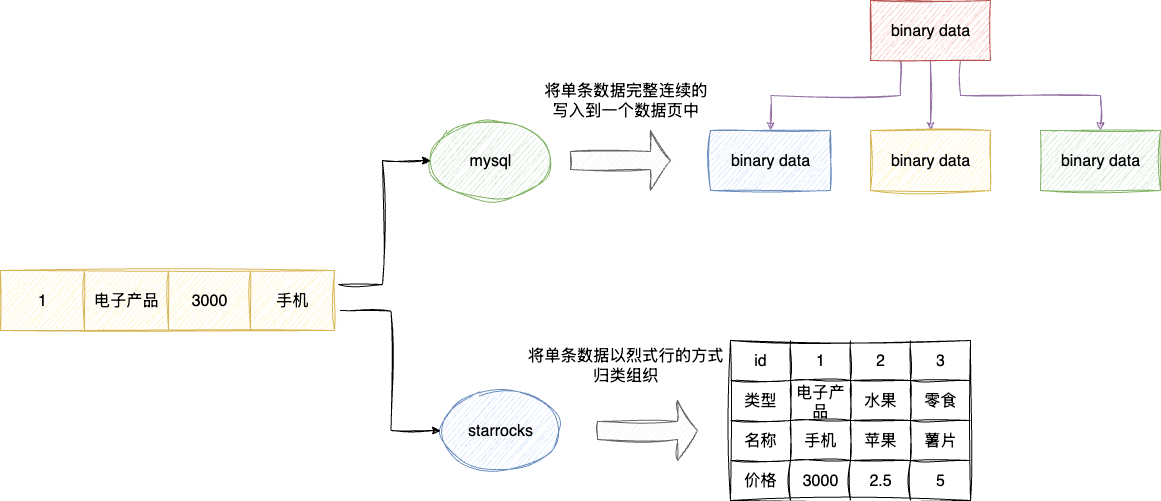
因为向量化存储的方式,所以sr在数据编排组织管理上也有着如下的优势:
- 列示存储保证支持批量大数据写入,相同类型数据写入指令CPU可以直接通过SIMD的方式批量写入
- 查询时可以利用CPU局部性一次性检索出最相关数据,这一点对于OLAP报表分析极具优势
- 最后一点是延迟查询聚合,传统数据的
select 名称 from tb where type=电子产品 and price>5000必须一次性读取单条数据的所有行才能进行进一步的筛选并返回给用户,而sr对应的执行步骤是先通过类型列找到电子产品的列,例如本文就是索引0,基于该索引生成bit到价格列进行进一步筛选,最终得到一个符合要求的bitmap,需要返回结果给用户时,基于这个bitmap找到名称列数据写回给用户。
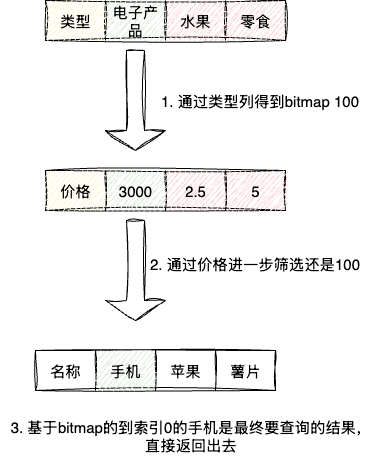
这使得sr进行查询时可以做到:
- 最小化IO
- CPU缓存友好
- 向量化处理利用SIMD指令完成高效检索
正是因为这些优势,使得用户可以灵活的选择设计雪花模型、星型模型这种多表联查亦或者宽表模型或者聚合模型等表结构,灵活的配置多维报表分析,业务场景包含:
- 用户行为分析
- 用户画像
- 业务指标报表
- 自助式报表平台
- 系统监控分析
同时,sr也设计了主键表,即支持各种TP(Transaction Processing)型数据库的秒级处理,所以常应用于:
- 电商促销数据分析
- 金融行业绩效分析
- 物流行业运单分析
# starrocks架构介绍
# 基本概念
SR的架构相对简洁明了,可直接分为前端和后端,前端节点称为FE,后端按照是否本地存储可否为BE和CN。我们先来介绍一下FE,它作为sr的执行前端,它有着如下几大职责:
- 元数据信息管理与同步:FE负责元数据信息的管理和同步,而元数据设计数据表的名称、字段信息、分区方式和分桶规则等信息,在FE以集群的方式部署的情况下,元数据必须保证强一致性才可避免表结构修改带来的一系列查询和写入的问题
- 客户端连接管理
- 查询规划:收到用户查询语句后,FE会在针对这句sql从逻辑和物理的角度进行优化,再生成分布式执行计划
- 查询调度:基于第三点的查询规划生成的计划,协调各个节点完成任务的查询并归并返回客户端
这里可能说的有点抽象,我们不妨基于一个简单的例子来说明这一点,假设我们现在要执行下面这句sql:
select t1.id,t1.name,t2.email from t1 left join t2 on t.id =t2.id where id <12931
对应的FE会基于元数据信息定位到t1和t2表的元数据信息,在查询规划阶段对该sql进行语法解析再进行执行计划生成,而对应的优化有逻辑层面的优化和物理层面的优化,我们先来说说逻辑层面的优化,为了避免非必要的数据关联,这条sql在逻辑上被优化为先基于id定位t1表的数据,再进行关联也就是我们常说的谓词下推。
有了逻辑优化的基础后,物理层面的优化也就是基于代价模型Cost-Based Optimizer, CBO)获取最有的执行策略,例如当前表量级是多少,是进行全表扫描还是走索引,我们假设当前表上走索引,又因为看到t2表是一张小表,所以在小表广播(小表副本发送到各个BE节点)和大表重分布(关联表hash分布到各个节点执行join)之间选择的小表广播。
有了计划,便可执行查询调度,FE会基于BE的分布情况和当前负载的信息将执行计划拆分为多个分段交由这些BE并行执行,调度时考虑非必要的网络IO,FE会优先将执行计划交给分布在其物理位置上的BE上,同时考虑到可靠性,某个BE查询失败会自动重试或者重新调度到其他节点。
最后BE完成计划的执行之后将结果交给FE进行聚合汇总交给客户端。
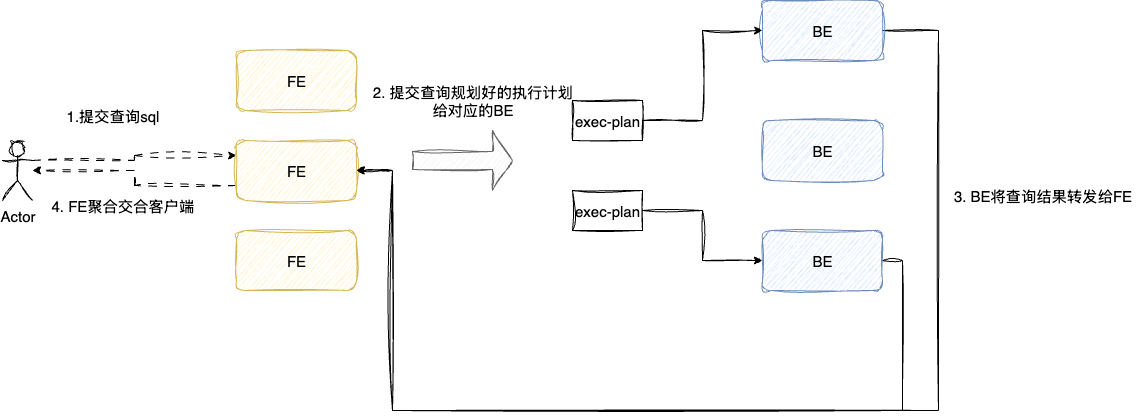
有了上述基于FE对于宏观流程的拆解后,我们再来介绍一下BE,BE主要负责sql计划执行和数据存储,通过FE与定义的规则将数据分发到各个BE,BE按照规定格式完成数据导入并生成索引。
上文提到如果数据在HDFS上存储时,采用的则是CN,CN也就是计算节点,只负责计算任务和缓存部分数据以尽可能保证计算任务的高效。
# 存算一体
有了上述几个组件的基本概念之后,我们就可以了解以下sr几种常见的存储架构,先来说说存算一体,在存算一体架构中,BE负责数据存储和计算,因为数据都存储在当前节点下,避免了数据传输和复制的开销,所以可提供极快的查询和分析性能,同时该架构还支持多副本数据存储,在保证高并发的同时还能提供高可靠,适合用追求最佳查询性的场景。
在存算一体的架构中,FE负责元数据管理和执行计划构建,对应BE负责数据存储和查询计算,BE利用本地存储加速查询,并使用多副本机制确保数据的高可用:
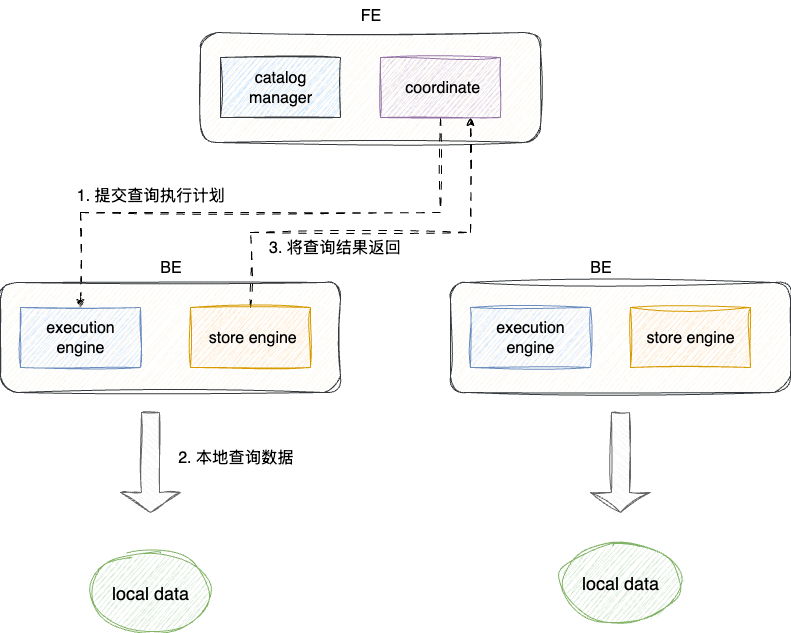
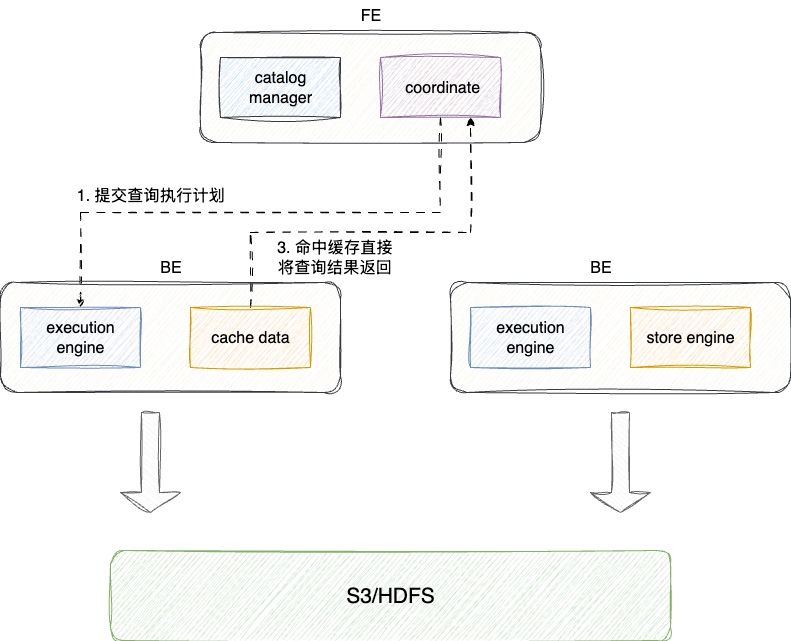
# 存算分离
存算分离是另外一种托管云的方案,即数据都存储在HDFS上,利用HDFS实现较低成本发挥高可靠和可拓展的优势,CN以计算节点的身份仅仅负责执行计算任务,并将请求提交到远端存储系统,因为数据不存储在cn节点上所以执行时存在一定的时延,为保证存储性能,cn设置了一定的缓存,在缓冲命中率较高的情况下,cn可以保证查询效率,一旦遇到各种非热点查询的情况,这种架构在性能表现就逊色于前者:
# 更多关于StarRocks
# CBO优化器
当涉及多表关联查询时,例如雪花模型的关联查询,执行引擎会基于成本分析选择合适的执行计划,这就是典型的np-hard问题即分析时会根据表的量级出现n!的连接顺序,考虑到这一点sr的优化器则是Cascades Like即级联友好,它通过规则驱动(即上述的逻辑与优化)配合代价模型以及memo存储等价计划避免重复计算等方式对此问题进行的优化。
除了上述的优化,CBO优化器还增加了如下细节:
- 公共表达式复用:sr针对已执行过的查询会将其缓存避免重复计算,例如当我们执行
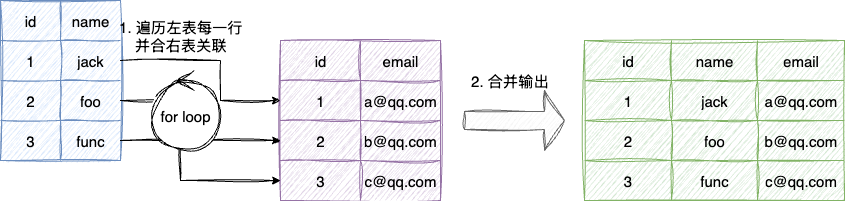
select (a+b) /c, (a+b) +d from tb优化器就会提取公共表达式a+b并将查询结果缓存,避免多次的重复运算。 - Lateral Join:即查询时可直接基于左边的结果右边右边查询语句的条件完成关联查询返回,例如执行
SELECT * FROM tbl1, LATERAL (SELECT * FROM tbl2 WHERE tbl2.id = tbl1.id)Lateral Join就会将tbl1的每一个数据查处然后作为右侧tbl2的关联条件进行查询,关联数据和左表数据合并返回
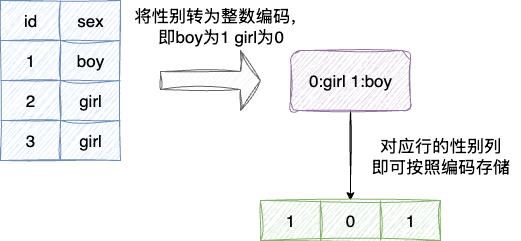
- 低基数字典压缩:针对一些区分度不是很明显的字段列,例如性别等字段,sr会将其进行压缩存储为整数字典以节省内存占用空间同时保证检索效率:
- Join Reorder:根据关联过滤性决定逻辑执行计划,例如a join b join c,如果b join c可以过滤更多的数据,那么优化器就会优先执行后一段计划,基于查询结果执行再关联a表。
- 分布式执行策略:这也就是上文所说的根据数据的分布选择小表广播还是大表重分布。
基于上述的各种优化手段,sr已经可以完整的支持TPC-DS 99条SQL
# 实时更新列
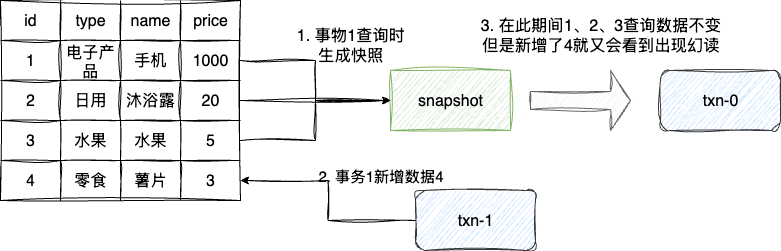
sr自持秒级的导入延迟,提供准实时的服务能力,同时sr的存储引擎在数据导入是能够保证一次导入的ACID,即每次导入要么都成功要么都失败,同时在查询上sr也是支持Snapshot Isolation即快照格式,这也就意味着sr针对当前事物读取结果期间,无论其他事物如何修改,都不会影响当前事物的视图。
这听起来可能和mysql的可重复度即rr隔离级别很类似,只不过sr说只能解决已有数据快照的幻读,但对于新增数据的幻读却无能为力,因为sr并没有像mysql那样查询时会带上间隙锁。
# 智能物化视图
sr视图是跟随着原始数据表一并更新,只要原始数据发生变更,对应的物化视图也会随之更新,不需要额外的运维操作,同时sr在进行查询规划时也会优化器一旦发现某张物化视图可加速查询,则会将查询改写转交到该视图下查询提升查询速度。
# 小结
本文基于理论向的角度介绍了sr的基本概念和常见架构和内置的一些优化理念,希望对你有帮助。
我是 SharkChili,Java 开发者,Java Guide开源项目维护者。欢迎关注我的公众号:写代码的SharkChili,也欢迎您了解我的开源项目 mini-redis:https://github.com/shark-ctrl/mini-redis。
为方便与读者交流,现已创建读者群。关注上方公众号获取我的联系方式,添加时备注加群即可加入。
# 参考
StarRocks官方文档:< https://docs.starrocks.io/zh/docs/introduction/what_is_starrocks/>
