 技术洞察:深入剖析Elasticsearch文档读取的原理与实现
技术洞察:深入剖析Elasticsearch文档读取的原理与实现
@[toc]
# 写在文章开头
本文将从一份或者多份文档请求的角度讲解es集群如果完成文档检索,了解该流程有助于更好的理解后续es性能调优的篇章。
Hi,我是 sharkChili ,是个不断在硬核技术上作死的技术人,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。

# 详解ES查询的基本概念
# ES查询语句的分类
- 按照
RESTful API风格通过请求体进行查询,这也是我们最常用的一种方式:
GET join_example_index/_search
{
"query": {
"has_parent": {
"type": "parent",
"query": {
"match_all": {}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
- 类似于的sql的方式查询,这种方案不太成熟,不建议使用:
POST /_sql
{
"query": "SELECT * FROM employees"
}
2
3
4
- 将请求参数放在url上,比较反人类,了解一下即可:
GET /your_index_name/_search?q=*:*
# term查询和全文检索的区别
该问题我们可以从以下几个角度进行分析比对:
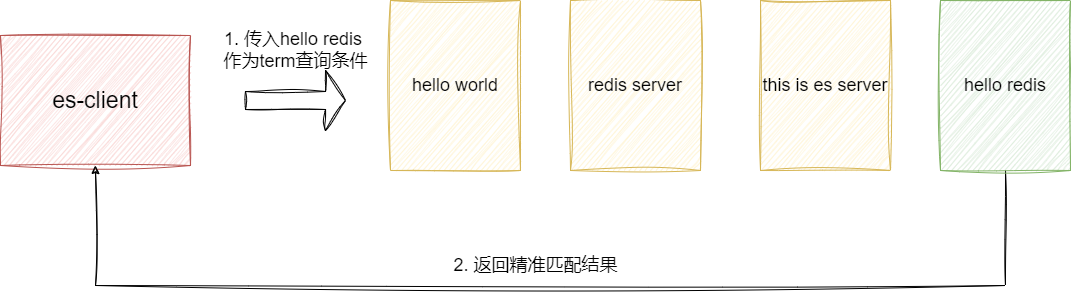
从使用角度来说,term查询时是直接基于传入的词项直接针对倒排索引词项进行精准匹配的,在查询时是不会针对查询词项进行分词处理,如下图,按照term查询的工作机制,传入结果就是最终查询结果匹配值:
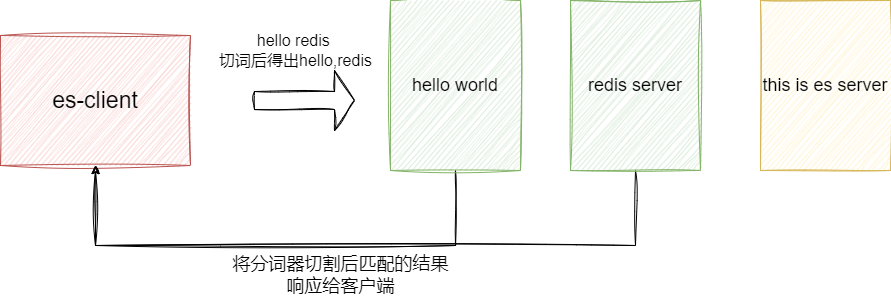
而全文检索是一种基于自然语言处理的检索方式,传入词项之后会通过分词器进行过滤、切词后得到一组词项进行全文匹配,然后再按照匹配结果进行相关性打分,如下所示,全文检索按照分词切词后的结果得到hello、redis两个词项此时就会到文档中查找存在这些词项的文档并进行打分再返回:
从应用场景来说,term查询使用哪些需要精准匹配的数据检索的字段,例如:邮箱、电话号码、出生日期等,而全文检索适用于对于自然语言的相关性检索,例如查询带有某关键字的文章、博客、评论等。
对此我们不妨给出使用示例,首先我们创建一份测试索引books:
PUT books
{
"mappings": {
"properties": {
"title": {
"type": "text"
},
"author": {
"type": "text"
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
然后分别添加两份文档:
PUT books/_doc/1
{
"title": "Elasticsearch实战",
"author": "Rivers"
}
PUT books/_doc/2
{
"title": "Elasticsearch核心技术",
"author": "Cay S. Horstmann"
}
2
3
4
5
6
7
8
9
10
11
使用全文检索查询Elasticsearch可以发现两本书的信息都出来了,并且还能看到相关性打分:
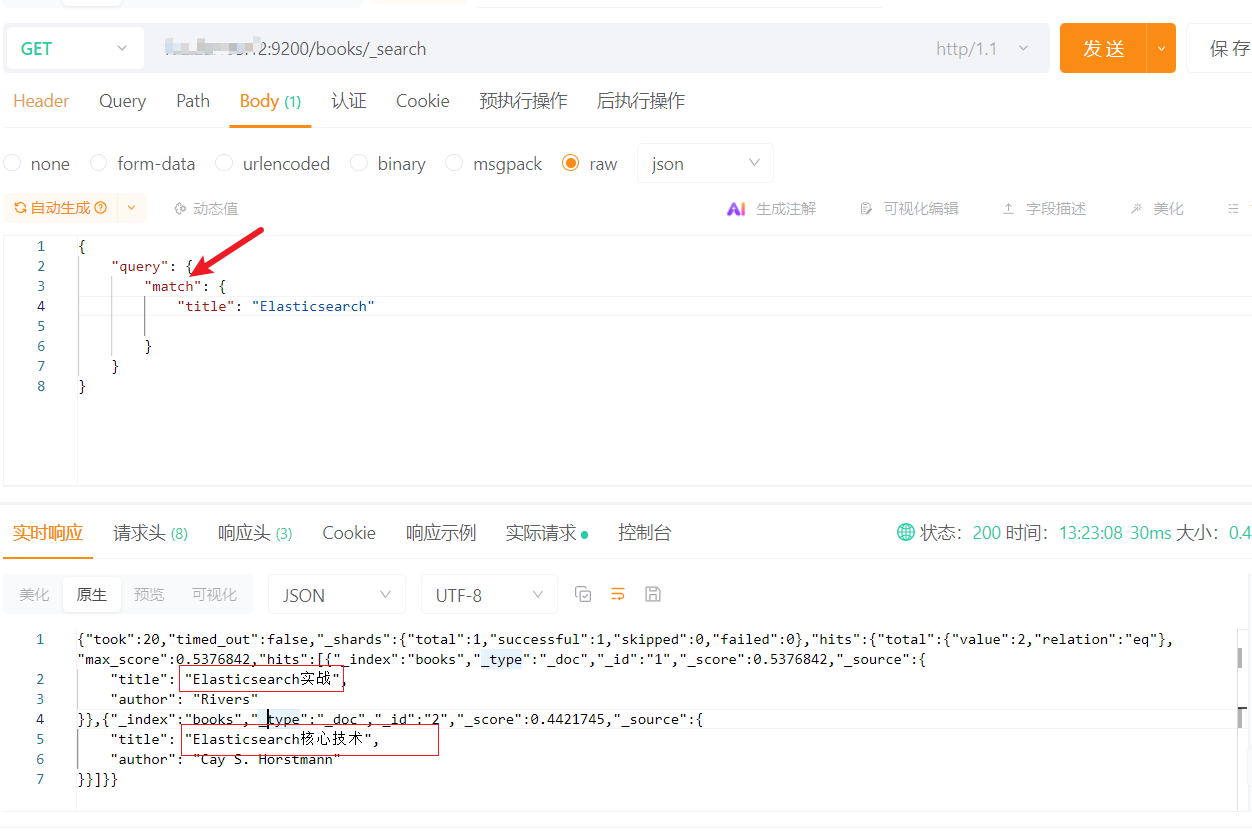 而使用
而使用term查询却没有相关性结果,这意味着我们必须给出精准的词汇才能完成数据查询:
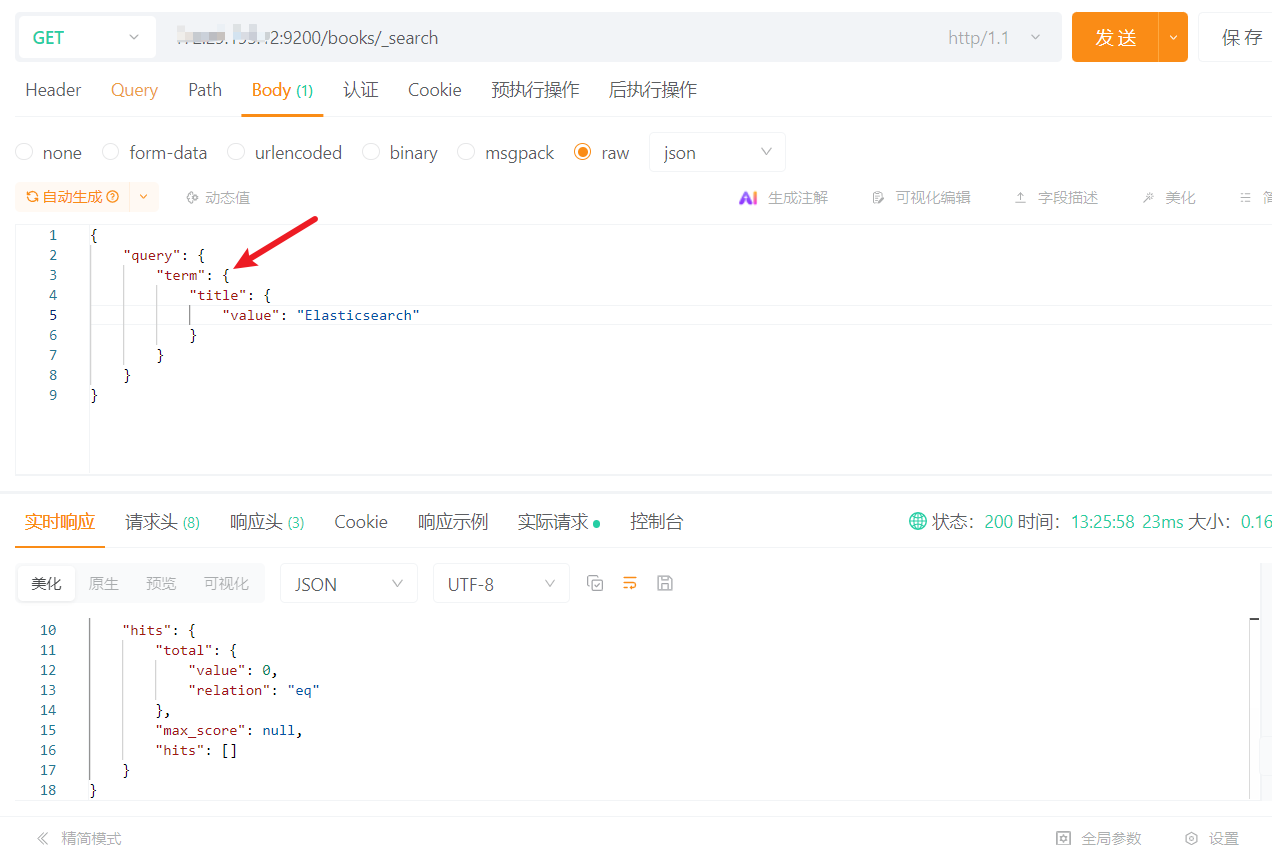
从性能角度来说:term查询是精确匹配的,省去了分词器分词这一步,直接通过传入的检索词汇到倒排索引中进行精准匹配,计算量较小,无论在耗时还是资源消耗上都是相对较少的,所以在性能表现上相较于全文检索会高效一些。
而全文检索在索引构建时需要按照文档进行分词处理,将文本拆成一个个词项建立复杂的索引结构,实现灵活自然语言处理,虽然开销相较于前者要大,但是灵活性上更具优势。
# 如何实现范围检索
使用range指明范围区间即可,对此我们给出下面这样一段查询产品的使用示例,首先先基于创建一份索引:
PUT products
{
"mappings": {
"properties": {
"price": {
"type": "double"
},
"stock": {
"type": "integer"
},
"name": {
"type": "text"
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
然后插入三份文档数据:
POST products/_doc
{
"price": 25.5,
"stock": 100,
"name": "Product A"
}
POST products/_doc
{
"price": 50.0,
"stock": 50,
"name": "Product B"
}
POST products/_doc
{
"price": 15.0,
"stock": 200,
"name": "Product C"
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
此时若希望查询价格在10~30间的产品就可以按照如下REST API格式进行查询:
GET products/_search
{
"query": {
"range": {
"price": {
"gt": 10,
"lt": 30
}
}
}
}
2
3
4
5
6
7
8
9
10
11
# match和match_phrase的区别
针对match和match_phrase两种全文检索,针对两种查询我们可以从以下两个角度进行说明:
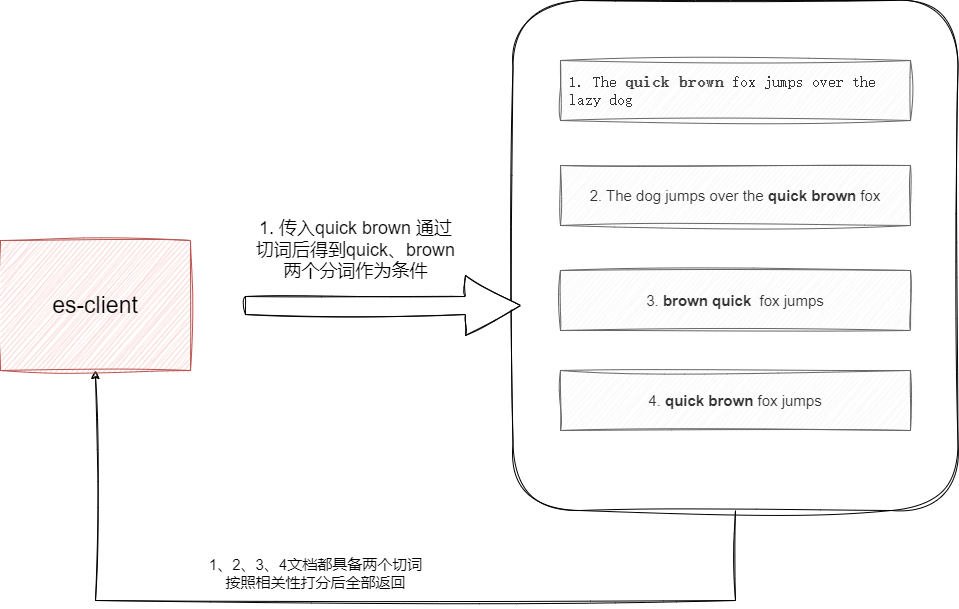
从工作机制上来说,match匹配会基于检索词项进行切词之后到倒排索引中直接进行灵活匹配获取相关性数据并进行打分,注意这里所指的灵活匹配指的是切词后得到的分词匹配无需按照顺序比对,只要任何一份文档有匹配的词项即可作为结果返回。
如下所示我们的倒排索引有下面3份文档,按照match的机制进行匹配quick brown,经过分词器分词后得到quick、brown会得到所有的文档结果:
match_phrase相较于前者来说会严苛一些,我们还是传入quick brown同样会进行分词检索,但是查询时它会严格按照该词项顺序完全一致的方式进行查找,再按照相关性检索打分返回,按照上图的示例我们只会得到文档1、2、4返回:
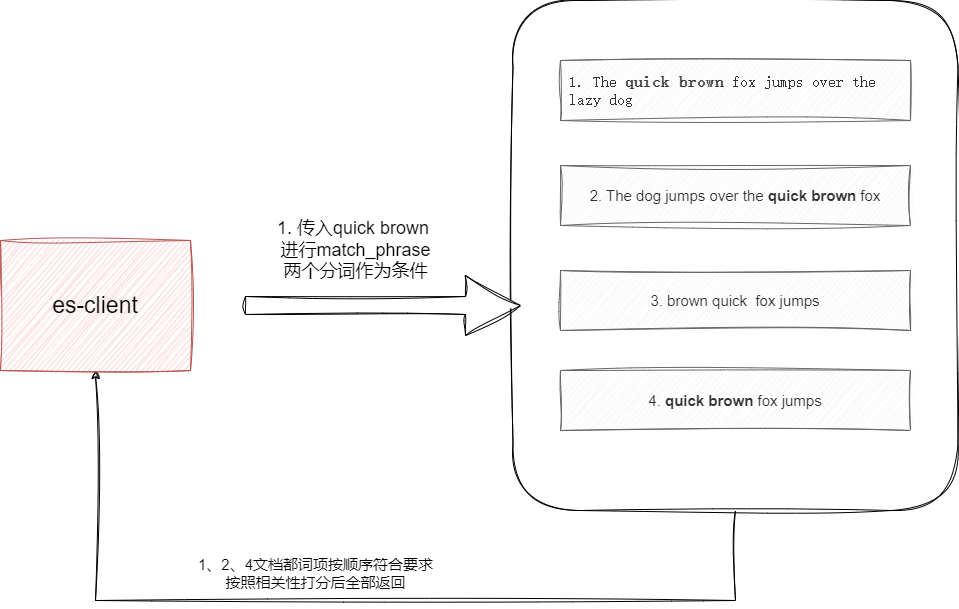
从使用场景上来说,前者检索范围会更大,所以对于相关性匹配获取的结果会更多,适用于希望获得尽可能多的相关词项检索匹配的场景,例如新闻搜索系统,通过match关键字的灵活性可以得到更多潜在的相关文档,召回率相对较高。而后者涉及顺序的匹配,所以检索的结果会少一些,更适用于一些对于词项有严谨顺序要求的文档检索。
对此我们不妨给出match和match_phrase的使用示例,我们首先使用PUT创建索引:
PUT http://localhost:9200/test_index
{
"mappings": {
"properties": {
"content": {
"type": "text"
}
}
}
}
2
3
4
5
6
7
8
9
10
然后插入几份测试文档:
# 创建索引
PUT http://localhost:9200/test_index
# 添加文档1
POST http://localhost:9200/test_index/_doc
{
"content": "The quick brown fox jumps over the lazy dog"
}
# 添加文档2
POST http://localhost:9200/test_index/_doc
{
"content": "The dog jumps over the quick brown fox"
}
# 添加文档3
POST http://localhost:9200/test_index/_doc
{
"content": "quick brown fox jumps"
}
# 添加文档4
POST http://localhost:9200/test_index/_doc
{
"content": "brown quick fox jumps"
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
此时我们使用match就可以得到所有文档:
GET http://localhost:9200/test_index/_search
{
"query": {
"match": {
"content": "quick brown"
}
}
}
2
3
4
5
6
7
8
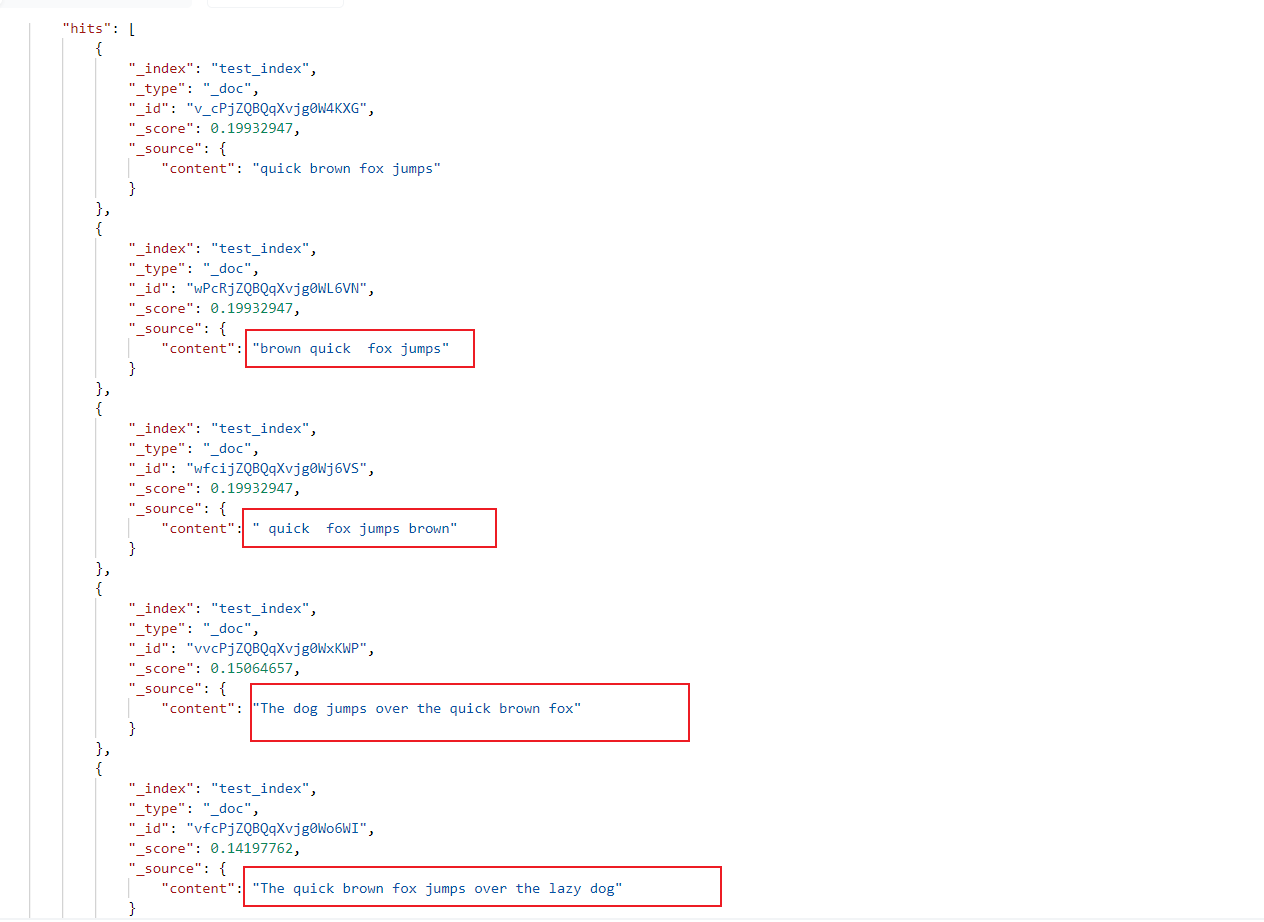
改为match_phrase之后得到的文档只有符合语序的几份:
GET http://localhost:9200/test_index/_search
{
"query": {
"match_phrase": {
"content": "quick brown"
}
}
}
2
3
4
5
6
7
8

# multi match几种匹配策略
# best_fields
multi_match 是Elasticsearch中用于在多个字段上执行 match 查询的查询类型,它有多种匹配策略,以下是几种常见的策略:
best_fields:该策略会为每个字段计算相关性得分,然后返回得分最高的单个字段的得分作为文档的最终得分。它的目标是找到与查询最匹配的单个字段。
示例场景:当你有一个包含 “title”(标题)和 “description”(描述)字段的文档索引,并且你认为标题字段通常更能准确反映文档的主题时,使用 best_fields 策略。例如,用户搜索一个产品名称,产品名称在标题中出现的概率较大,此时该策略会突出标题字段匹配度高的文档。
这里我们不妨举个电影搜索系统的例子,假设我们用es存储每个电影的标题、导演和情节,此时我们希望查出Christopher Nolan关键字的电影信息,就可以使用best_fields方式进行搜索,通过best_fields方式指明查询范围针对title、director、plot,此时es就会从该索引找到相关文档,看到某分文档director与查询检索完全匹配,给出较高的匹配度打分并返回:
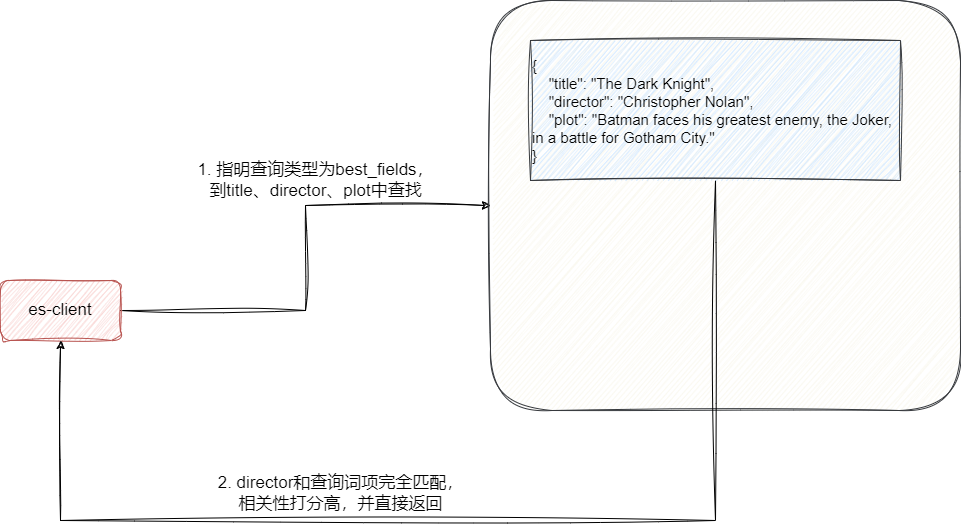
对此我们也不妨实验一下,首先创建电影搜索系统的索引:
# 创建索引
PUT http://localhost:9200/movies
{
"mappings": {
"properties": {
"title": {
"type": "text"
},
"director": {
"type": "text"
},
"plot": {
"type": "text"
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
然后添加3份文档:
# 添加文档1
POST http://localhost:9200/movies/_doc
{
"title": "The Dark Knight",
"director": "Christopher Nolan",
"plot": "Batman faces his greatest enemy, the Joker, in a battle for Gotham City."
}
# 添加文档2
POST http://localhost:9200/movies/_doc
{
"title": "Inception",
"director": "Christopher Nolan",
"plot": "A skilled thief is hired to perform an impossible task of stealing an idea from a target's mind."
}
# 添加文档3
POST http://localhost:9200/movies/_doc
{
"title": "The Shawshank Redemption",
"director": "Frank Darabont",
"plot": "A banker is wrongfully imprisoned and spends years in prison before finally escaping."
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
此时按照best_fields策略到title、director、plot中进行检索,从输出结果可以看到导演名称为Christopher Nolan都会返回并给出较高的打分:
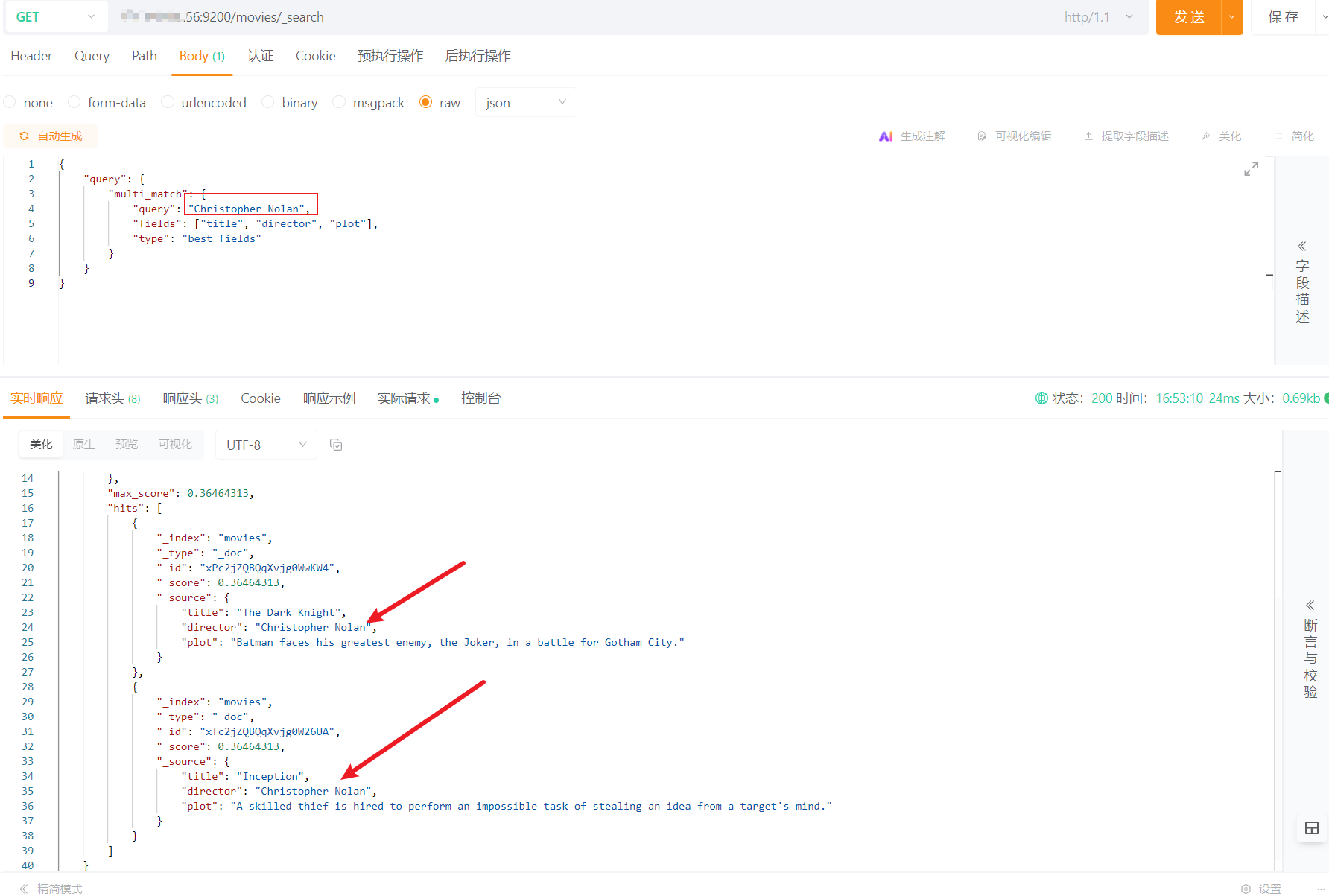
# most_fields
most_fields:most_fields 策略会计算每个字段的相关性得分,然后将所有字段的得分相加,以此作为文档的最终得分。它倾向于找到在多个字段中都有匹配词项的文档。
示例场景:在一个博客文章索引中,包含 “title”、“content”(正文)和 “tags”(标签)等多个字段。使用 most_fields 策略,当用户搜索一个关键词时,无论这个关键词在标题、正文还是标签中出现,都会增加文档的得分,从而使在多个字段都有相关信息的文档更有可能被返回。
# cross_fields
策略描述:此策略将多个字段视为一个大的文本块进行分词和匹配。它会忽略字段边界,就好像所有字段的文本都连接在一起。这样可以提高在多个字段分散出现查询词项时的匹配效果。 示例场景:比如在一个联系人信息索引中,有 “first_name”(名字)和 “last_name”(姓氏)字段。如果用户搜索 “John Doe”,使用 cross_fields 策略,即使 “John” 在 “first_name” 字段,“Doe” 在 “last_name” 字段,该文档也有机会被匹配到。
# phrase
策略描述:phrase 策略与 match_phrase 类似,它会在每个指定字段中执行短语匹配,要求文档中的词项顺序与查询短语的顺序一致。文档的最终得分是所有匹配字段得分的总和。 示例场景:在一个法律条文索引中,每个条文都存储在不同字段里。当用户搜索一个特定法律条款的精确表述时,使用 phrase 策略可以确保返回的文档中词项顺序与用户输入的查询短语顺序相同,以提高匹配的准确性。
# phrase_prefix
策略描述:phrase_prefix 策略结合了 phrase 和前缀匹配的特点。它在除了最后一个词项外的所有词项上执行短语匹配,最后一个词项执行前缀匹配。这对于用户输入的不完整短语或需要灵活性的搜索场景很有用。
示例场景:在一个产品搜索应用中,用户输入 “laptop with i7”。如果使用 phrase_prefix 策略,它会在多个字段中尝试找到 “laptop with” 的精确短语匹配,同时对 “i7” 进行前缀匹配,例如文档中包含 “laptop with i7 processor” 或 “laptop with i7-12700” 等都可能被匹配到。
# bool查询有几种查询子句
# must
作用:文档必须满足 must 子句中的所有查询条件才能被包含在结果中。同时,must 子句中的查询会影响文档的相关性得分,匹配的查询越多、匹配程度越高,文档的得分越高。
示例:假设我们有一个博客文章索引,要搜索标题中包含“人工智能”且正文包含“机器学习”的文章。
{
"query": {
"bool": {
"must": [
{ "match": { "title": "人工智能" } },
{ "match": { "content": "机器学习" } }
]
}
}
}
2
3
4
5
6
7
8
9
10
# should
作用:文档只要满足 should 子句中的任意一个查询条件就可能被包含在结果中。如果 bool 查询没有 must、filter 子句,那么文档至少要满足一个 should 子句中的查询才能被返回。此外,should 子句中的查询也会影响文档的相关性得分,满足的 should 查询越多,得分越高。
示例:在一个商品索引中,搜索商品名称包含“运动鞋”或者品牌是“耐克”的商品。
{
"query": {
"bool": {
"should": [
{ "match": { "product_name": "运动鞋" } },
{ "term": { "brand": "耐克" } }
]
}
}
}
2
3
4
5
6
7
8
9
10
# must_not
作用:文档必须不满足 must_not 子句中的所有查询条件才能被包含在结果中。在单条件或者数据量较小的情况下must_not 子句中的查询不会影响文档的相关性得分,只起到排除的作用。但是若查询条件足够多且数据量足够大的情况下,must_not会对整体检索结果的得分发布情况产生间接影响。
示例:在一个人员索引中,搜索年龄不是30岁的人员。
{
"query": {
"bool": {
"must_not": [
{ "term": { "age": 30 } }
]
}
}
}
2
3
4
5
6
7
8
9
# filter
作用:与 must 类似,文档必须满足 filter 子句中的所有查询条件才能被包含在结果中。但是,filter 子句中的查询不会影响文档的相关性得分,它主要用于过滤数据,提高查询效率。通常用于一些不需要计算相关性得分,只关注文档是否匹配特定条件的场景,比如按日期范围、分类等条件过滤。
示例:在一个订单索引中,搜索订单金额大于1000且订单状态为“已完成”的订单,并且不希望这些条件影响相关性得分。
{
"query": {
"bool": {
"filter": [
{ "range": { "order_amount": { "gt": 1000 } } },
{ "term": { "order_status": "已完成" } }
]
}
}
}
2
3
4
5
6
7
8
9
10
这些子句可以灵活组合,以构建复杂的查询逻辑,满足各种不同的搜索需求。
# must_not和filter的区别
# 对相关性得分的影响
must_not:must_not子句主要用于排除不满足条件的文档,但它会影响文档的相关性得分计算。当一个文档不符合must_not中的条件时,它会被排除;而在计算其他匹配文档的相关性得分时,must_not中的条件也会参与整体的相关性评估逻辑,尽管它本身不直接为文档加分,但会对整体的得分分布产生间接影响。
filter:filter子句仅用于过滤文档,它完全不影响文档的相关性得分。它的主要作用是快速筛选出符合特定条件的文档子集,专注于数据过滤,而不关心文档与查询的“匹配程度”得分,因此适用于对结果相关性要求不高,仅需按条件筛选的场景。
# 缓存策略
must_not:由于must_not参与相关性得分计算,其执行的结果不会被缓存。这是因为每次查询的相关性得分计算都可能因查询条件和数据的不同而变化,缓存must_not的结果可能会导致不准确的结果返回。
filter:filter子句执行的结果通常会被缓存。因为filter操作不涉及得分计算,其结果相对稳定,对于相同的查询条件和数据集,过滤结果是一致的。缓存filter结果可以显著提高后续相同查询的性能,减少重复计算。
# 应用场景
must_not:当你需要在查询中排除某些特定的文档,同时又希望查询结果能够根据其他条件进行相关性排序时,使用must_not。例如,在搜索新闻文章时,你希望排除某个特定来源的文章,同时让结果按照与查询词的相关性和其他因素(如发布时间)进行排序。
{
"query": {
"bool": {
"must": [
{ "match": { "content": "科技新闻" } }
],
"must_not": [
{ "term": { "source": "特定来源" } }
]
}
}
}
2
3
4
5
6
7
8
9
10
11
12
filter:当你需要快速筛选出满足某些条件的文档,而不关心文档之间的相关性排序时,使用filter。例如,在电商搜索中,你想要快速筛选出价格在某个范围内、库存不为零的商品,此时使用filter可以提高查询效率。
{
"query": {
"bool": {
"filter": [
{ "range": { "price": { "gte": 100, "lte": 500 } } },
{ "term": { "stock": { "gt": 0 } } }
]
}
}
}
2
3
4
5
6
7
8
9
10
综上所述,must_not和filter虽然都有排除文档的功能,但在功能侧重点、缓存机制和应用场景上存在明显差异。
# 详解ES读取文档流程
# 基于单文档和多文档概览整体流程
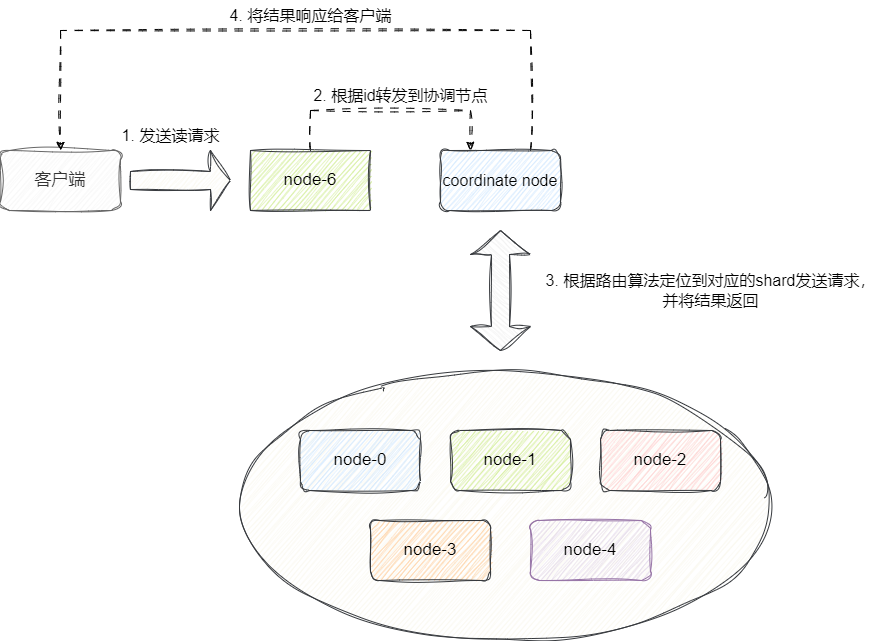
我们先以单文档为例详解,当客户发起单文档向集群节点发起请求时,若请求的节点不是coordinate node,则当前节点会根据路由表找到coordinate node并转发该请求。
然后coordinate node根据_doc_id即文档id找到对应的shard,然后根据路由表找到对应的shard的node并转发该请求。随后这些节点收到这些请求后就会根据请求参数找到文档信息,交由coordinate node返回给客户端。
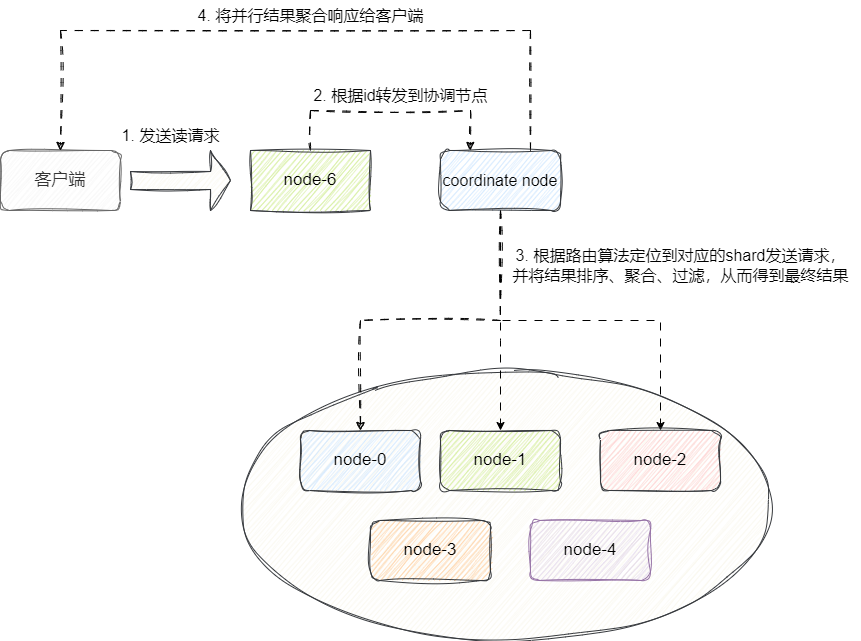
请求多份文档的整体流程也和上述差不多,唯一的区别即coordinate node会通过mget并发向对应的shard分片对应的node转发请求,直到收到所有主分片或者副本分片(主分片下线)的所有答复之后,构建生成响应结果给客户端。
# 详解文档查询细节
接下来我们就来深入分析每个流程,先来说说查询的流程,我们以单文档为例,总的来说es的查询是一个二阶段查询也就是query_then_fetch。
本质上当客户端将请求打到coordinate node时,coordinate node会根据文档id值通过路由算法hash(_doc_id)/shard_count将定位到所有的路由分片,然后将请求广播到这些分片上。
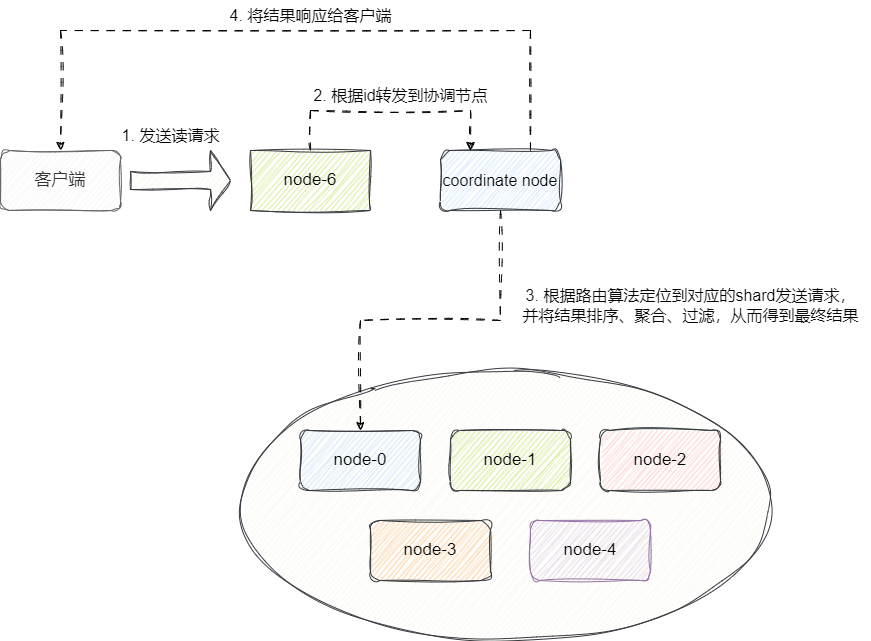
假设这个请求是个分页请求,那么每个节点都会根据from、size两个参数进行数据检索,进行数据检索时,每个节点就会到各自的segment、文件系统缓冲区(那些还未进行refresh的文档)查看是否有符合要求的文档,也就是说elasticsearch的查询是近实时的。如果有则将文档id按照doc value进行排序生成一个优先队列并返回给coordinate node:
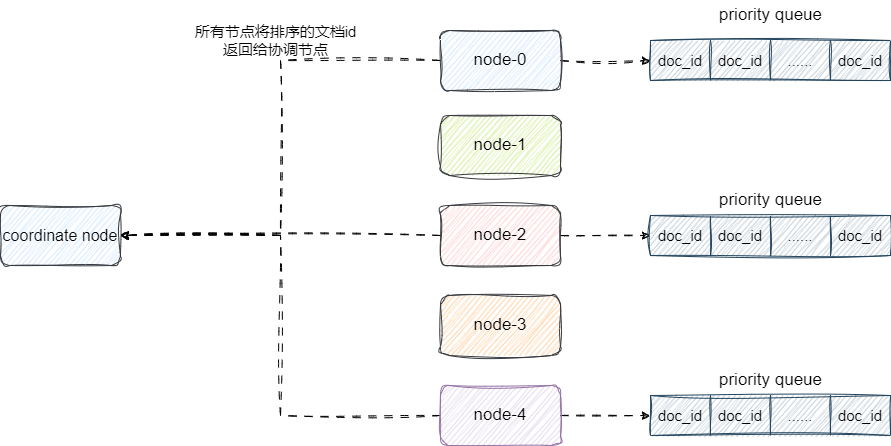
# 查询结果聚合
收到各个节点汇报的结果之后,coordinate node就会按照用户的分页结果进行聚合,假设用户只需要查询100页的数据,那么coordinate node就会基于汇聚的结果进行全局排序再过滤,从而将实质上的前99页的结果过滤掉,然后将这些需要详细信息的文档的id通过get请求发送给shard节点以获取丰富后的结果:
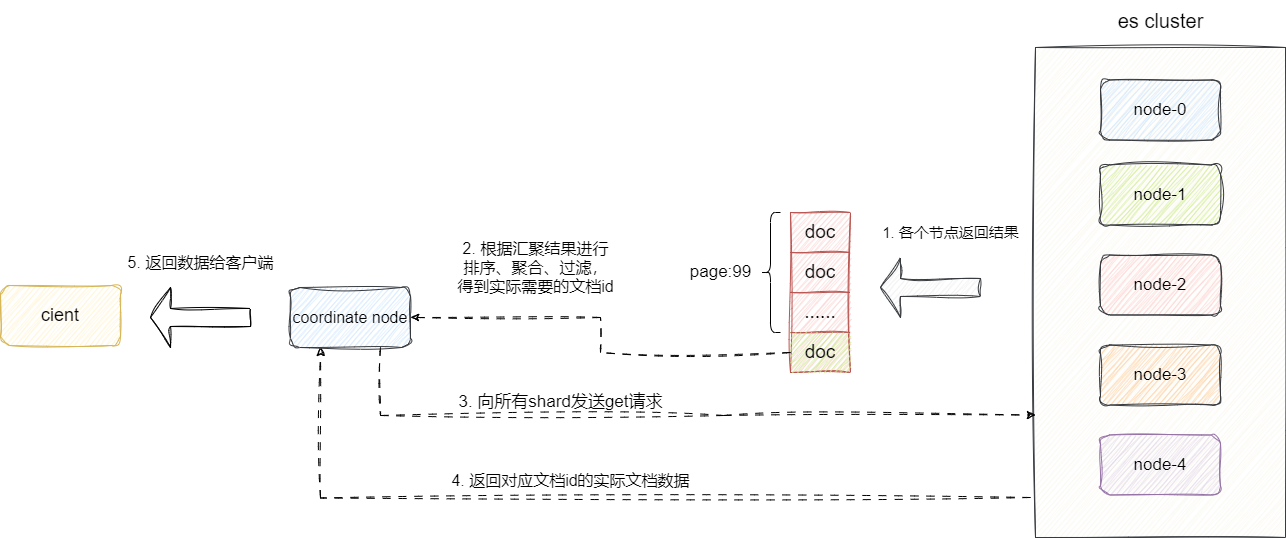
# 分页问题及其最佳解决方案
假设每次分页查询10条数据,若我们希望查询到第10w页的结果,按照常规单节点的查询,我们只需设置from为(10w-1),size为10即可:
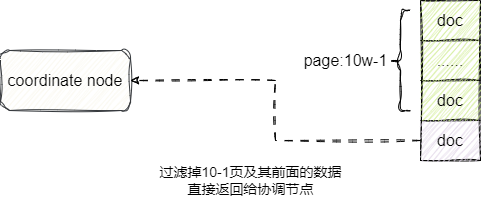
在之前的章节提到,若涉及多个shard的分页查询,ecoordinate node会将一阶段所有节点查询的完整结果(当前要查询的页及其之前的页)排序后的优先队列进行归并然后过滤,这意味着如果涉及多节点的分页查询,es会将所有shard当前及其分页前的数据全部查询并进行归并排序,从而得到分布式集群下的分页结果。
例如我们希望拿到10w1页的数据,那么我们就需要拿到所有shard的10w1页及其之前的所有数据,再到coordinate node进行归并排序,从而得到一个全局的10w1页的数据,很明显在深分页的场景下,这种做法极容易导致内存溢出:
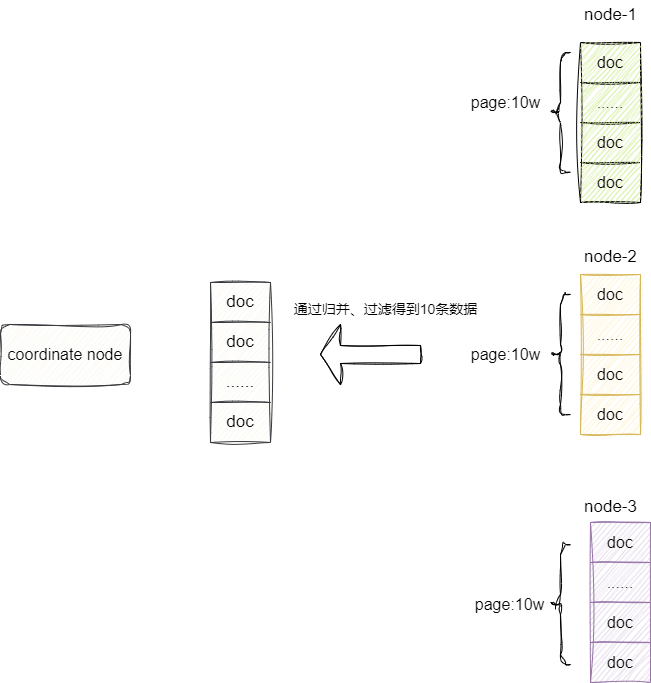
对此es提出了两种解决方案,第一种则是scroll查询法,使用原理是第一页查询时传入页码和分页大小,通过本次查询得到一个全局唯一的且具有时效性的scroll_id,后续的查询我们可以基于这个scroll_id不断进行翻页,直到scroll_id时效到期或者scroll_id被用户删除,所以这种方式非常适用于深分页的上下翻页场景:
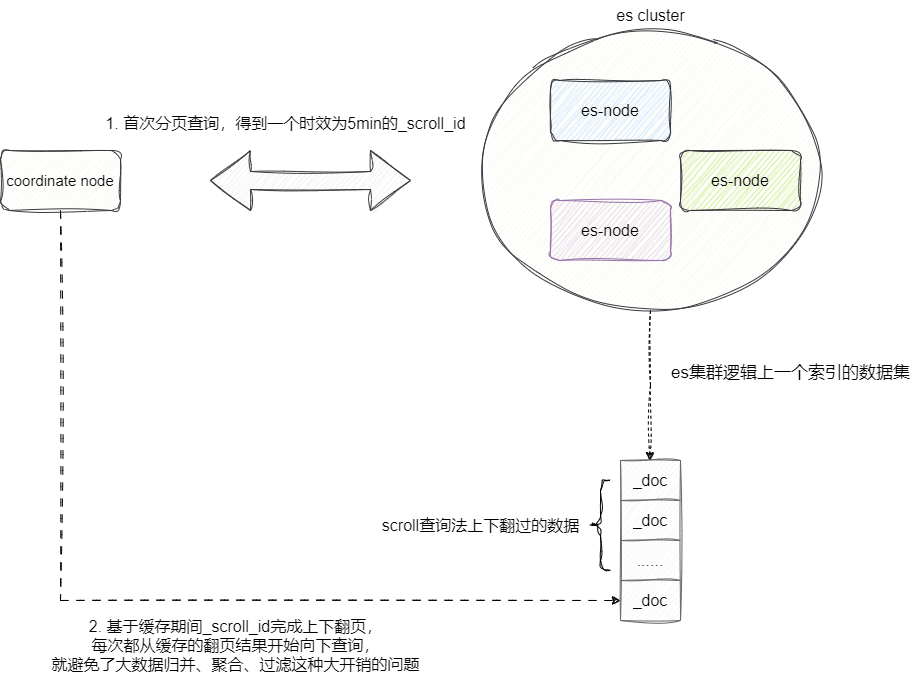
这意味这种方式尽管对于实时的深分页查询有着不错的表现,但因为scroll_id缓存的特性会占用大量资源且会生成历史快照,所以我们建议评估好内存空间,并保证在用户使用完成之后手动使用删除scroll_id。
scroll查询方式使用的方法就比较简单,只需按需传入检索参数后在_search后追加scroll后续跟上缓存的时间即可,以笔者为例是5min:
GET /kibana_sample_data_ecommerce/_search?scroll=5m
{
"query": { "match_all": {} },
"sort": [
{ "order_id": "asc" }
],
"from": 0,
"size": 1
}
2
3
4
5
6
7
8
9
首次第一页查询就会得到这个唯一的id值,这个值就是用于后续向下翻页查询的唯一凭据,注意因为上文的时间关系,这个分页的实时查询进度只会缓存5min:
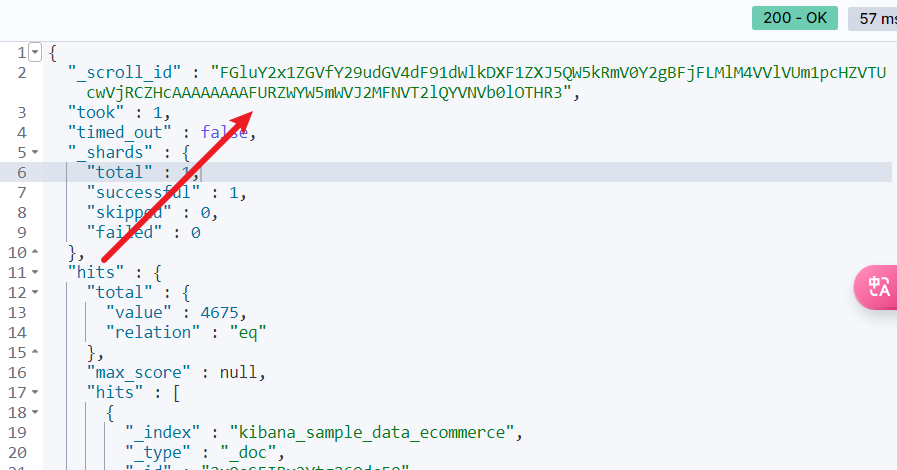
基于这个scroll_id在有效时间内不断请求,即可得到下一个的结果,并且实时的分页结果都会被缓存,直到这个id被删除或者缓存到期:
GET /_search/scroll/
{
"scroll":"1m",
"scroll_id":"FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFjFLMlM4VVlVUm1pcHZVTUcwVjRCZHcAAAAAAAAFURZWYW5mWVJ2MFNVT2lQYVNVb0lOTHR3"
}
2
3
4
5
另一种则是search_after查询,该方法和上述的的差不多,但是相对轻量级一些,查询时会返回本页查询结果的唯一标识,这意味着我们可以基于这个标识进行翻页,虽然不能解决跳页问题,但由于其查询的原理是利用上一页或者下一页的唯一id值,所以不占用大量缓存空间,所以这种解决方案是笔者认为是大数据量场景下解决上下翻页问题的最优方案。
对此我们也给出search after的查询示例,可以看到使用时只需在第一页传入size及其排序条件即可:
GET /kibana_sample_data_ecommerce/_search
{
"query": { "match_all": {} },
"sort": [
{ "order_id": "asc" }
],
"from": 0,
"size": 1
}
2
3
4
5
6
7
8
9
10
该查询的结果会得到排序的值553075:
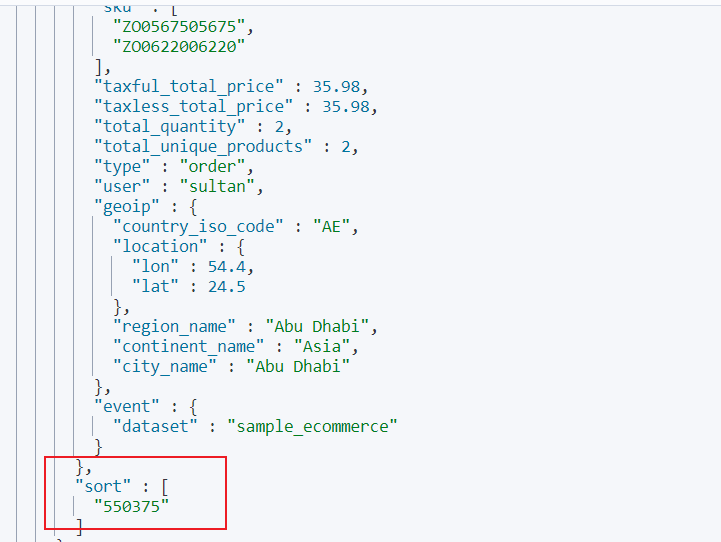
基于这个值我们就可以使用search_after即可获得下一页的内容:
GET /kibana_sample_data_ecommerce/_search
{
"query": { "match_all": {} },
"sort": [
{ "order_id": "asc" }
],
"size": 1,
"search_after": ["550375"]
}
2
3
4
5
6
7
8
9
10
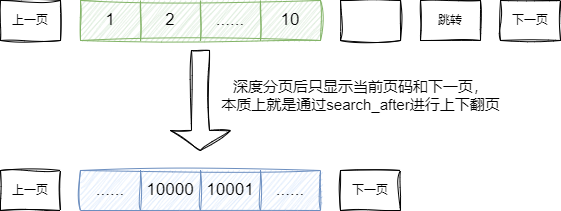
综上所述,对于大数量的分页查询场景,综合来说,对于深分页查询问题我们可以采用折中的方案,因为前几页查询检索的数据量需要进行并归过滤的数据量不是很大,所以在前几页我们可以适配用户的体验采用跳页方式。
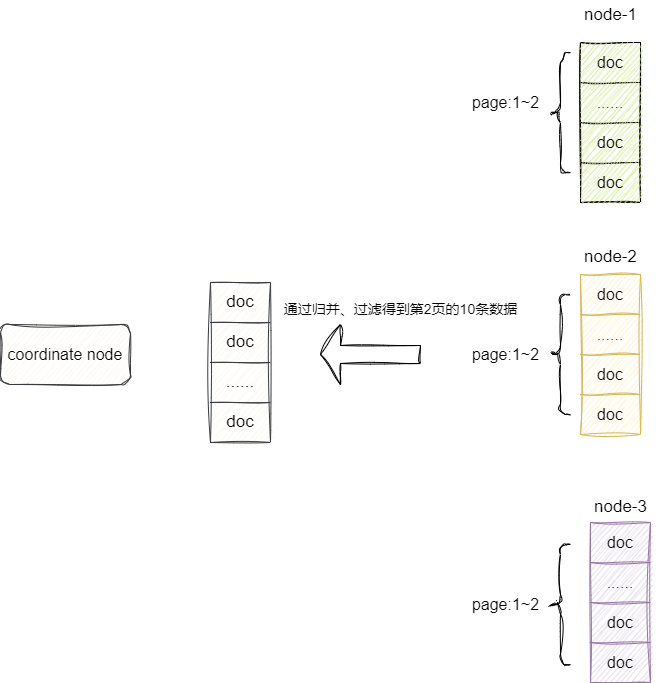
随着分页的页码不断底层,需要进行检索的深度也会越来越深,这时候我们的分页查询则直接采用search_after的方式完成分页。
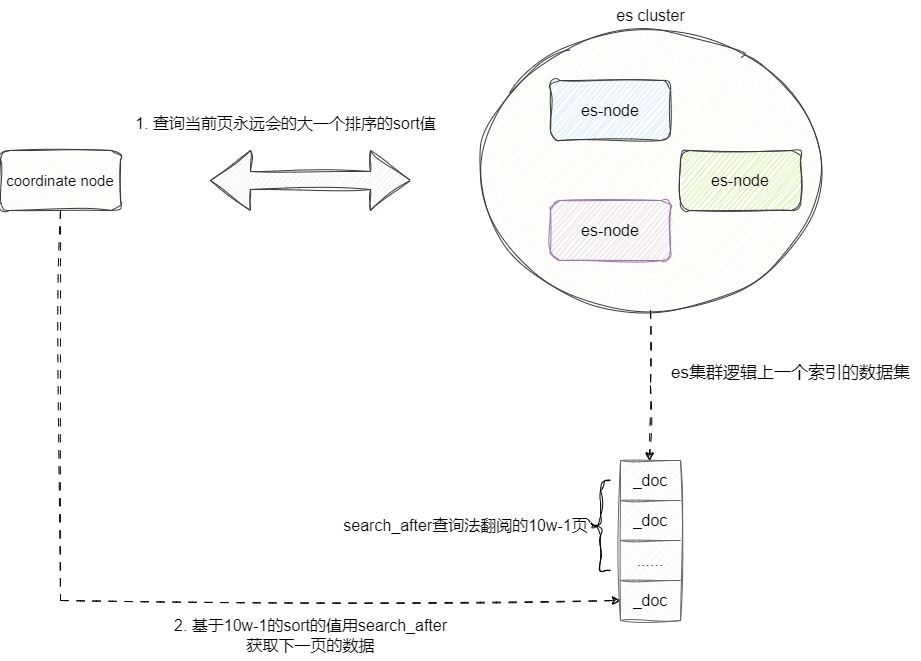
这也就是为什么在各种电商网站前几页的数据都显示大量页码,一旦到了后续的深度分页时只会显示当前页面的下一页:
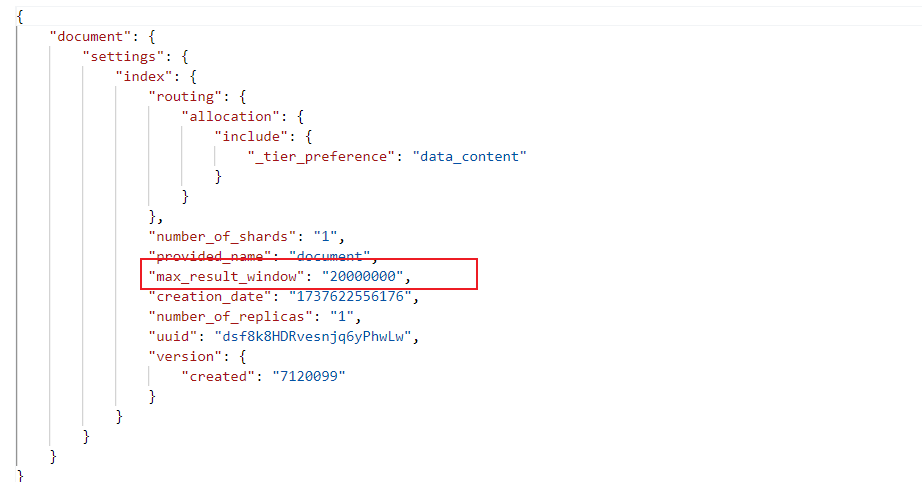
当然如果读者的业务场景明确需要跳页查询等需求,我们可以结合业务场景分析请求所需要的最大页数得出数据量,调整es的堆内存同时,适当调整index.max_result_window增加es分页查询时from + size总和的上限。
如下所示,这里笔者通过PUT接口指明_all即所有的索引上限都调整为2000w,如果读者希望指明特定索引,则可以将_all改为索引名称:
PUT /_all/_settings
{
"index.max_result_window": 20000000
}
2
3
4
5
完成后可以通过ip:9200/索引名/_settings查看设置结果是否生效:
此时我们就可以愉快的查询深分页数据了:
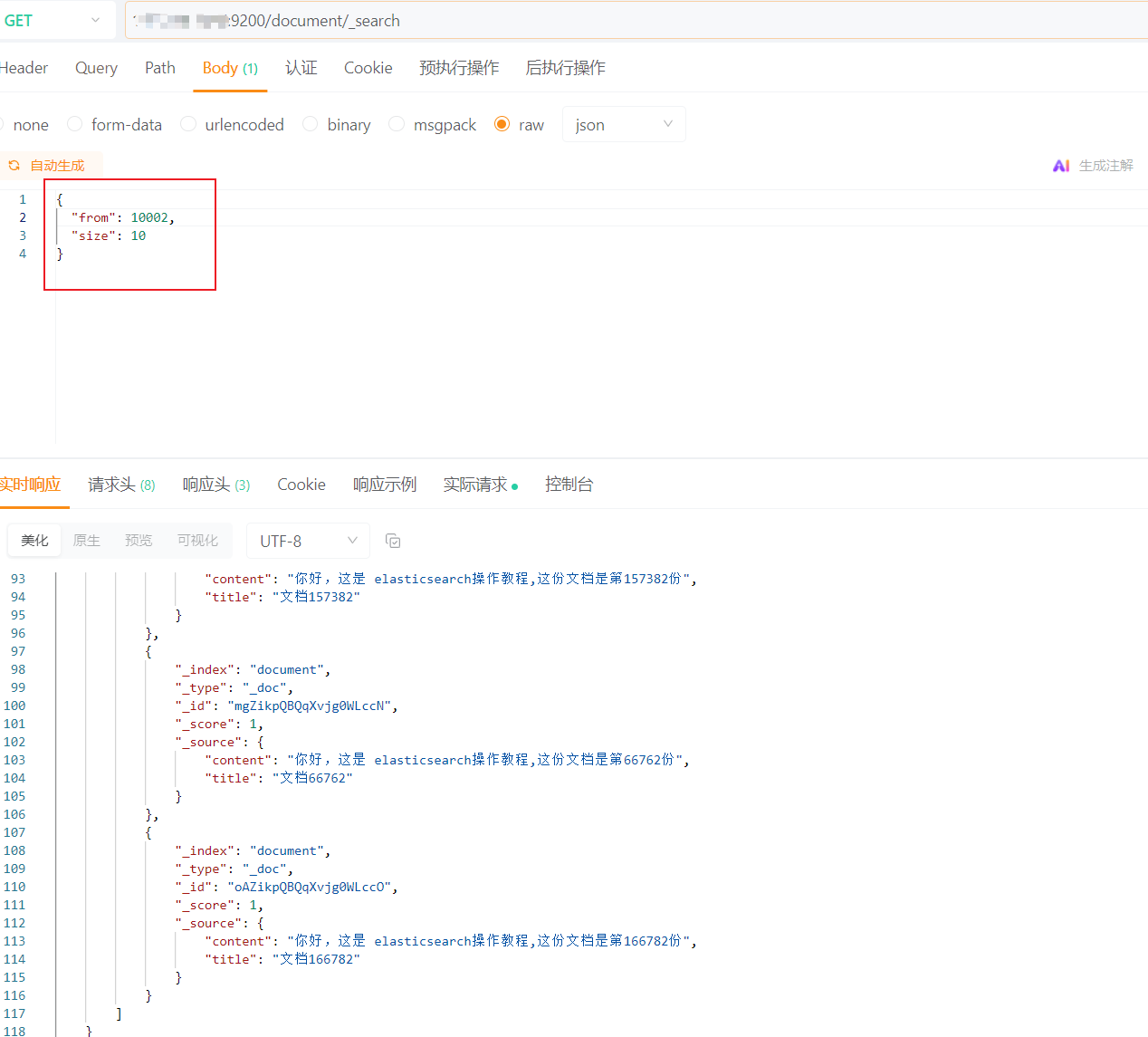
# 小结
自此我们将es文档读取细节流程都进行了较为深入的讲解,希望对你有帮助。
我是 sharkchili ,CSDN Java 领域博客专家,mini-redis的作者,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
# 参考
ES详解 - 原理:ES原理之读取文档流程详解:https://www.pdai.tech/md/db/nosql-es/elasticsearch-y-th-4.html (opens new window)
java实现es的search after查询(三种方式详解):https://blog.csdn.net/m0_50008952/article/details/123532395 (opens new window)
