 Nginx应用进阶HTTP核心模块配置小结
Nginx应用进阶HTTP核心模块配置小结
# 前言
在上篇文章Nginx基础入门总结 (opens new window)我们完成了nginx基础配置入门,这篇文章我们来探讨一些比较进阶的配置。 nginx为我们提供了灵活的表达式,通过这些表达式我们可以做到:
- 并发连接数限制。
- 根据请求参数做跳转。
- 根据请求参数做限制。
- 各种限流定制化配置。
- 黑白名单配置。
# 前置概念
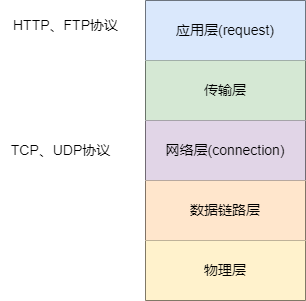
在nginx中有connection和request两个比较重要的概念,connection就是我们常见的传输层协议,例如:TCP或者UDP协议。
而request就是用户发起的请求,即应用层协议,例如我们web开发常用的HTTP协议,总的来说request上的协议都必须基于connection这些传输层协议上。
# limit_conn模块
# 简介
该模块的各种配置和限制都是针对connection模块,该模块默认情况下nginx已编译进去了,它常用于限制单位时间段内并发连接限制,而且该模块使用的是共享内存,对所有worker子进程都生效。
# 常见指令
# limit_conn_zone
- 语法格式:
limit_conn_zonnkeyzone=自定义名称.共享空间大小 - 默认值:无
- 上下文:http
- 示例:
limit_conn_zonn $binary_remote_addr zone=addr.10m - 作用:限制最大连接数。
注意:我们使用的key为binary_remote_addr,原因很简单,binary_remote_addr默认只用4字节的空间,而remote_addr却需要7-15个字节的空间,比较之下使用前者更节约内存空间。
上面的配置我们共享空间使用了10m,我们都知道1m可以维护3w2个连接,所以10m的共享空间可维护32w的空间对于一般应用系统是绰绰有余了。
# limit_conn_status
- 语法格式:
limit_conn_status code; - 默认值:
limit_conn_status 503; - 支持的上下文:http、server、location
- 作用:当打到限制要求时,弹出该配置设置的错误码。
# limit_conn_log_level
- 语法:
limit_conn_log_level info | notice | warn | error; - 默认值:
limit_conn_log_level error; - 支持的上下文:http、server、location
- 作用:配置日志等级
# 演示
# 需求
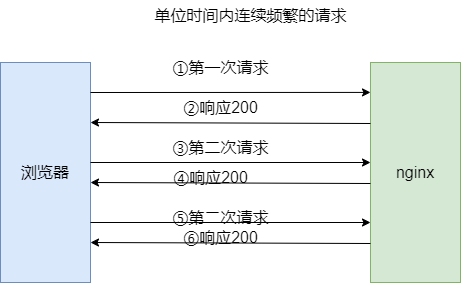
我们希望每个用户同一个时间段只能对nginx发起2次HTTP请求,一旦超过了这个次数,直接返回503错误。
# 配置演示
首先我们需要在http模块增加下面这段配置,意味建立一个共享内存为10m的limit_conn模块。
limit_conn_zone $binary_remote_addr zone=limit_addr:10m;
2
然后server模块配置如下,可以看到笔者做了如下配置:
- limit_addr :将limit_addr 设置为2,确保单个ip单位时间内请求频率最大为2。
- limit_conn_log_level :将日志级别设置为警告。
- limit_conn_status :当单位时间内请求频率达到上限时,就返回503。
server {
listen 8081;
server_name localhost;
location / {
root /etc/nginx/html;
index index.html;
# 并发数超过2返回503
limit_conn_status 503;
# 打印的日志等级为warn
limit_conn_log_level warn;
# 于限制来自单个IP地址的请求频率为2
limit_conn limit_addr 2;
# 为了演示并发请求不超过2这里nginx向客户端传送响应的速率修改为150字节每秒
limit_rate 150;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
配置后可以检查一下,在让nginx进行一次重载,确保配置生效。
/usr/sbin/nginx -t
1004 /usr/sbin/nginx -s reload
2
3
# 测试
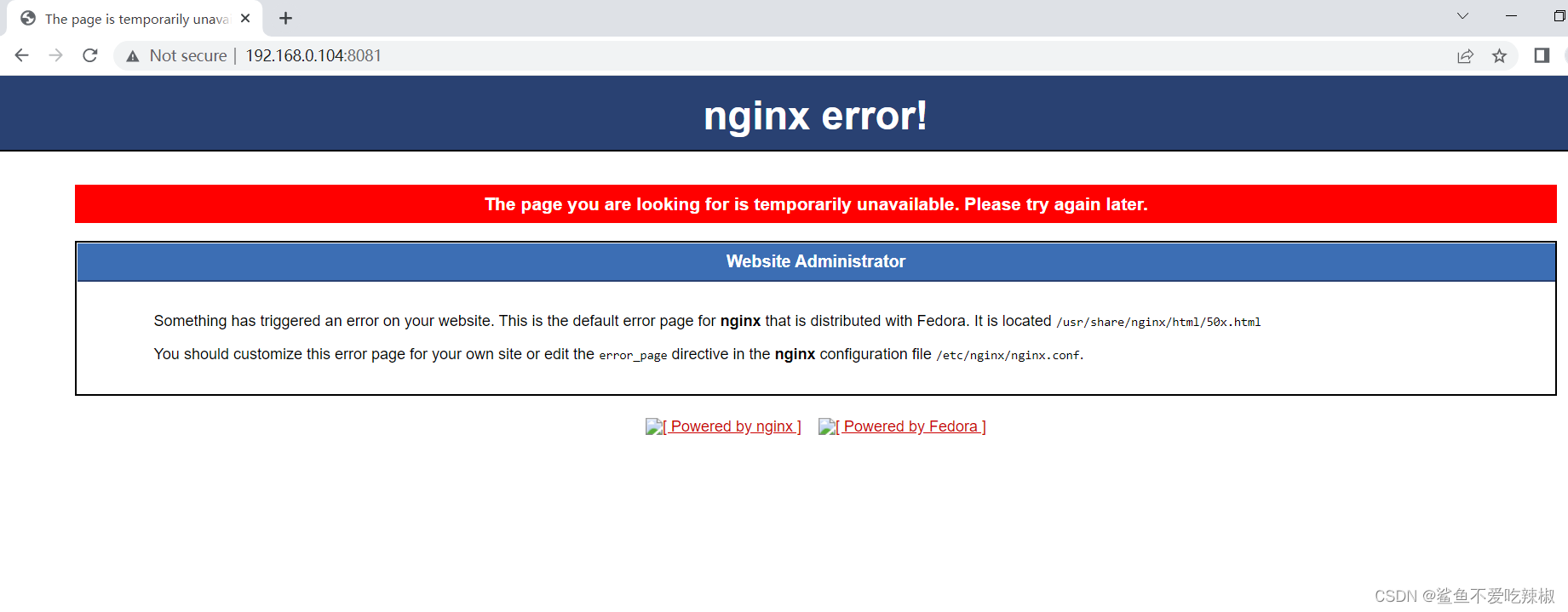
可以看到若单位时间内连续刷新超过2次,页面就会出现503错误页面。
# limit_req模块
# 简介
该模块作用于request,用于限制客户端请求的连接速率,nginx默认会编译该模块,使用的也是共享内存,对所有worker子进程都有效,对应连接速率的限流算法采用的是leaky_bucket算法。
如下图,上方表格在0~2s为12Mbps,而7-9s有2Mbps,计算一下10s内速率为12*2+2*3=30。
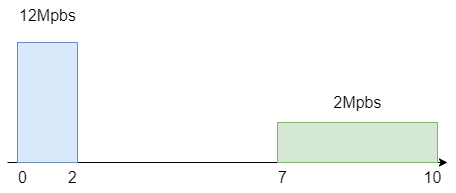
所以平均一下10s的速率我们可以设定为3Mbps,这样设置就可以将突发的流量削平,确保应用稳定,当请求超过的负载后就会被拒绝。

# 涉及语法
# limit_req_zone
- 语法:
limit_req_zone key zone=自定义名称:共享空间大小 rate=速率值 - 默认值:无
- 上下文:http
- 示例:
limit_req_zone $binary_remote_addr zone =one:10m rate=2r/m - 作用:配置限制速率的作用作用域以及速率。
# limit_req_status
- 语法:
limit_req_status code - 默认值:
limit_req_status 503 - 上下文:http、server、location
- 作用:达到上限要求时,响应给用户的错误码。
# limit_req_log_level
语法: limit_req_log_level info | notice |warn |error
默认值:limit_req_log_level 503
上下文:http、server、location
# limit_req
语法:limit_req zone =name [burst=number] [nodelay | delay =number];
默认值: 无
上下文:http、server、location
示例:limit_req=one;
# 演示
# 需求
我们希望所有在1分钟内,请求数达到2次后,响应504给剩下请求的用户。
# 配置
首先http模块添加以下配置,即创建一个限流模块,一分钟只能请求两次即30s内只能请求一次
limit_req_zone $binary_remote_addr zone=limit_req:15m rate=2r/m;
2
然后server模块添加如下配置,配置含义在指令中都已给出,读者可自行参阅。
location / {
root /etc/nginx/html;
index index.html;
# 连接数超过数量返回504
limit_req_status 504;
# 打印的日志级别为notice
limit_req_log_level notice;
# 使用上面配置的limit_req模块
limit_req zone=limit_req;
# 下面这条配置会在2+7次连接后报504
# limit_req zone=limit_req burst=7 nodelay;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 测试
从access.log中可以看到请求超过2之后就会在日志出现notice日志

# access模块
# 简介
access默认已经编译进了nginx,用于限制特定网段、ip地址的访问。
# 常用语法
# allow
- 语法:
allow address | cidr | unix |all; - 默认值:无
- 上下文:http、server、location、limit_except
- 示例:
allow 192.168.1.110; - 作用:设置准入ip。
# deny
- 语法:
deny address | cidr | unix |all; - 默认值:无
- 上下文:http、server、location、limit_except
- 示例:
deny 192.168.1.0/24; - 作用:配置不允许访问的ip。
# 示例
如果我们希望只允许192.168.0.0/24网段访问,按照下面这段配置即可。
location / {
root /etc/nginx/html;
# 允许192.168.0.0/24网段访问
allow 192.168.0.0/24
# 其余ip统统拒绝
deny all;
index index.html;
limit_req_status 504;
limit_req_log_level notice;
}
2
3
4
5
6
7
8
9
10
11
12
13
如果我们有这样的需求:
- 允许192.168.1.0/24网段访问,但是192.168.1.1不允许访问。
- 允许10.1.1.0/16网段ip访问。
- 其余ip都拒绝访问。
我们就可以按照下属的方式,针对某个网段特殊的拒绝ip需要配置在allow 网段前面,剩下的规则则按照先配置allow再配置deny即可。
location / {
# 先拒绝192.168.1.0网段特殊网段,再配置允许的网段,确保符合需求
deny 192.168.1.1;
allow 192.168.1.0/24;
# 允许10.1.1.0/16;网段访问
allow 10.1.1.0/16;
# 剩下ip全部拒绝
deny all;
}
2
3
4
5
6
7
8
9
# auth_basic模块
# 简介
该模块是基于HTTP基本认证authentication协议进行用户密码认证,常用于实现nginx用户认证功能,该模块默认已编译进nginx。
# 语法
# 指明加密配置名称
- 语法:
auth_basis string | off ; - 默认值:
auth_basic off; - 上下文: http、server、location、limit_except
- 作用:指定一个字符串参数作为身份验证领域。
# 文件
- 语法:
auth_basic_user_file file; - 默认值: -
- 上下文:http、server、location、limit_except;
- 作用:指定用户名和密码文件的存储路径。
# 演示
# 需求
我们现在希望通过nginx实现认证配置,确保用户在访问index网页时,需通过输入用户名和密码的方式进行认证,只有认证通过了才能访问网页。
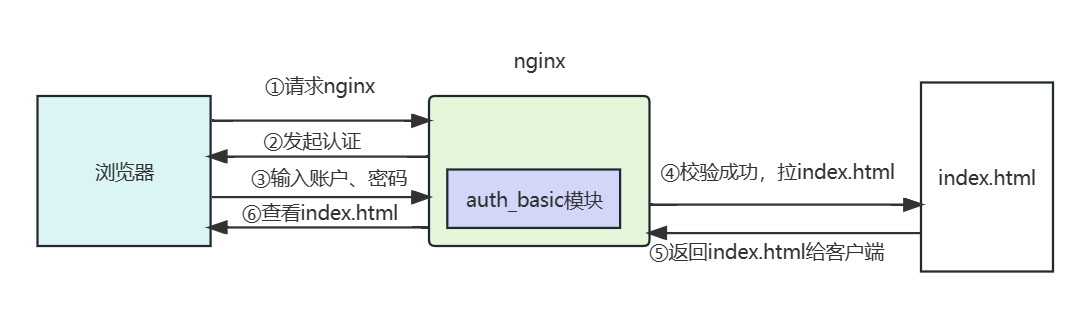
# 配置步骤
认证功能我们需要借助第三方工具完成账号密码密文的生成,所以我们需要安装这下面这几个依赖:
yum -y install apr apr-util
rpm -ivh httpd-tools-2.4.6-90.el7.centos.x86_64.rpm
2
3
然后进入nginx目录创建一个名为auth的文件夹,并进入该目录
# 创建一个auth文件夹
mkdir auth
# 进入该文件夹
cd auth/
2
3
4
紧接着我们需要创建一个encry_pass 存储对应用户名和密码
# 创建一个encry_pass 文件,添加一个jack用户,密码为123456
htpasswd -b -c encry_pass jack 123456
# 追加一个mike用户
htpasswd -b encry_pass mike 123456
2
3
4
5
此时使用cat指令就可以看到下方内容
jack:$apr1$.H1TiTiN$Sid9MY8sU9wirj5X56u3Q1
mike:$apr1$L8gMN2Lp$ZT7rrOuza0ELPrVc.o3uu1
2
3
最后针对需要进行认证的请求映射的文件上添加auth_basis配置:
location / {
root /etc/nginx/html;
index index.html;
auth_basic "test user pass";
auth_basic_user_file /etc/nginx/auth/encry_pass;
}
2
3
4
5
6
7
8
# 测试
这时候我们键入网站就会弹出这个页面,输入上文的账号密码即可进入页面:
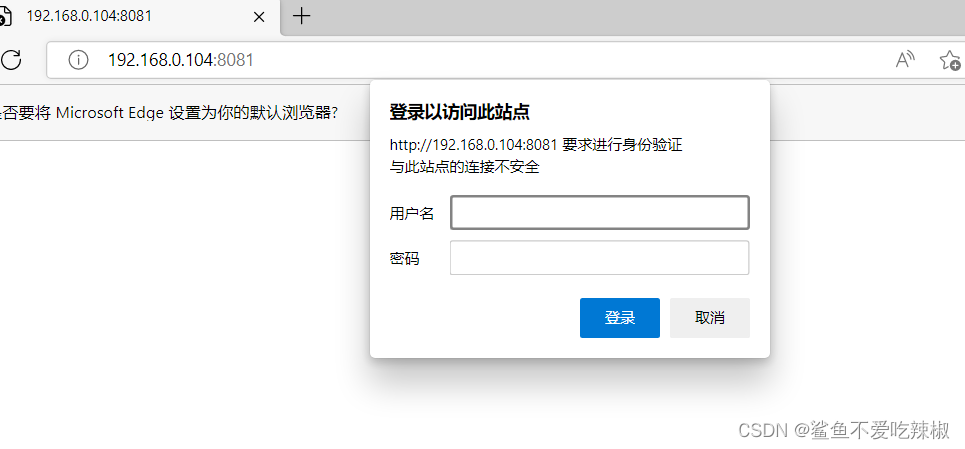
# auth_request模块
# 简介
该模块是基于HTTP响应码做权限控制,通过将请求转到鉴权服务器上进行认证,只有当鉴权服务器认证通过才能访问nginx服务器资源,从而做到访问控制,该模块默认未编译进nginx。
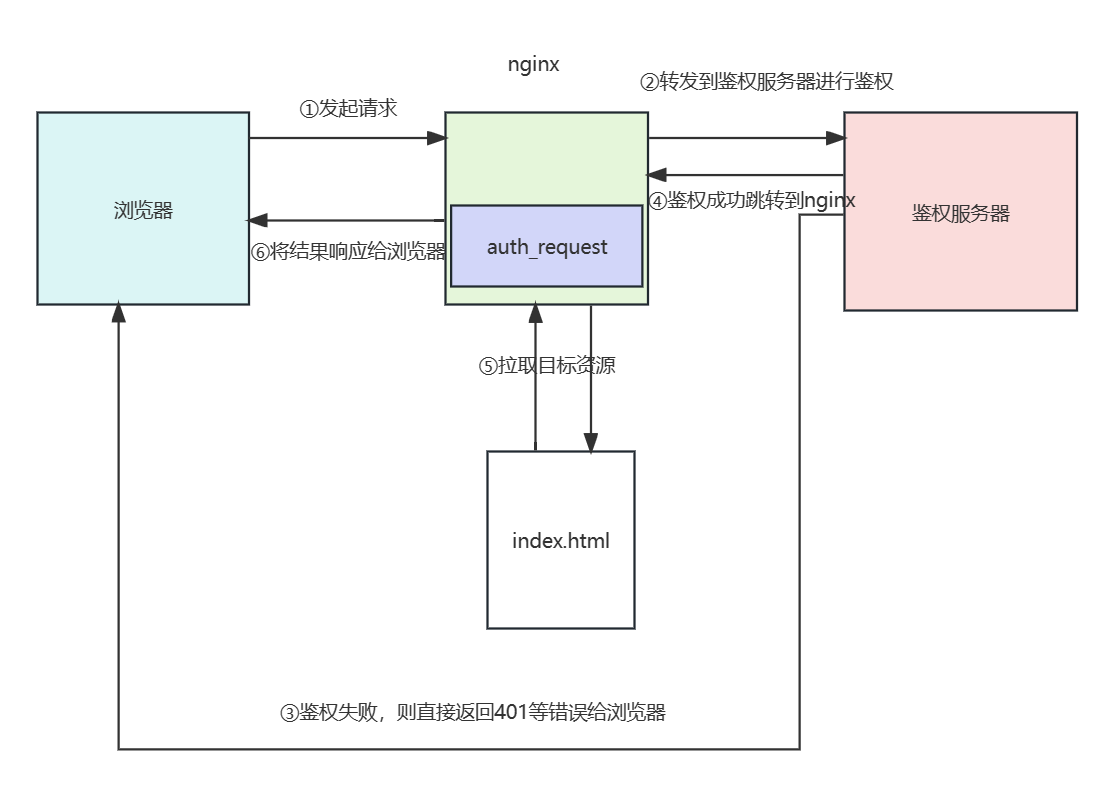
# 语法
# 基于uri配置鉴权服务器
- 语法:
auth_request uri |off; - 默认值:
auth_request off; - 上下文:http、server、location
- 作用:配置鉴权服务器uri映射。
# 基于变量配置鉴权服务器
- 语法:
auth_request|_set $variable value; - 默认值:-
- 上下文:http、server、location
- 作用:配置健全服务器相关的变量配置(不常用)
# 示例
鉴权服务器使用情况较少,所以笔者这里就给出简单的配置示例,可以看到笔者通过uri的方式配置auth_request ,而uri指向另一个location,该配置指明鉴权服务器地址为http://127.0.0.1:8080/verify
location /private/{
auth_request /auth;
}
location /auth {
proxy_pass http://127.0.0.1:8080/verify ;
proxy_pass_request_body off ;
proxy_set_header Content-Length "";
proxy_set_header x-Original-URl $request_uri ;
}
2
3
4
5
6
7
8
9
10
# rewrite模块
# return指令
# 简介
直接返回HTTP响应码或者将请求重定向到指定URL上,和一般编程语言一样,return指令执行之后,后续的语句就不会执行了。
# 语法
- return 语法:
return code [text](text为可选项文本);
return code URL;
return URL;
2
3
- 默认值:-
- 上下文:server、location、if
# 示例1-直接返回响应码
如下所示,该配置会将访问8081网页的请求全部返回404。
server {
listen 8081;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
root /etc/nginx/html;
# 直接响应404
return 404;
index index.html;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
完成后,我们做个访问测试,可以看到笔者的请求直接返回404响应码了。
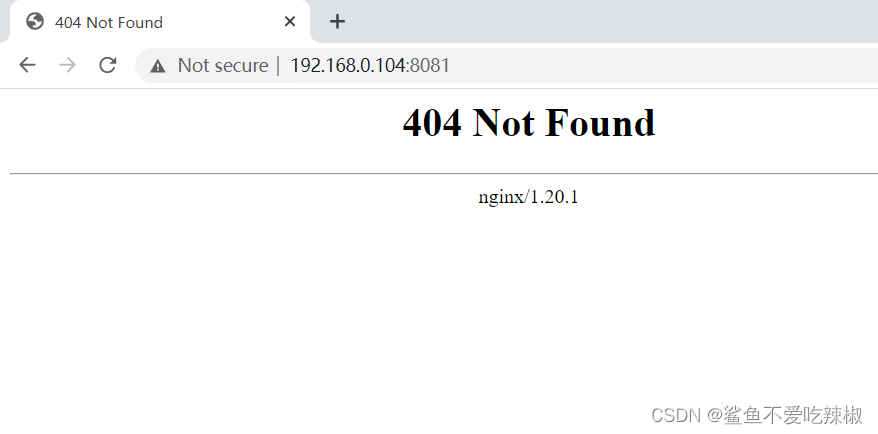
# 示例2-返回响应码及网页
我们也可以返回302(临时重定向),并响应一个页面,如下所示,笔者在return语句后配置了响应码,以及网页对应的映射地址即可实现改需求。
server {
listen 8081;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
root /etc/nginx/html;
# 响应302 并跳转到notFound这个映射
return 302 /notFound;
index index.html;
}
# notFound硬核对应的网页配置
location /notFound {
root /etc/nginx/html;
# 注意 我们必须在nginx的html文件夹下创建一个notFound文件夹,然后创建一个notFound.html
index notFound.html;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
完成后我们进行测试,可以看到被不仅返回302还重定向到notFound网页。
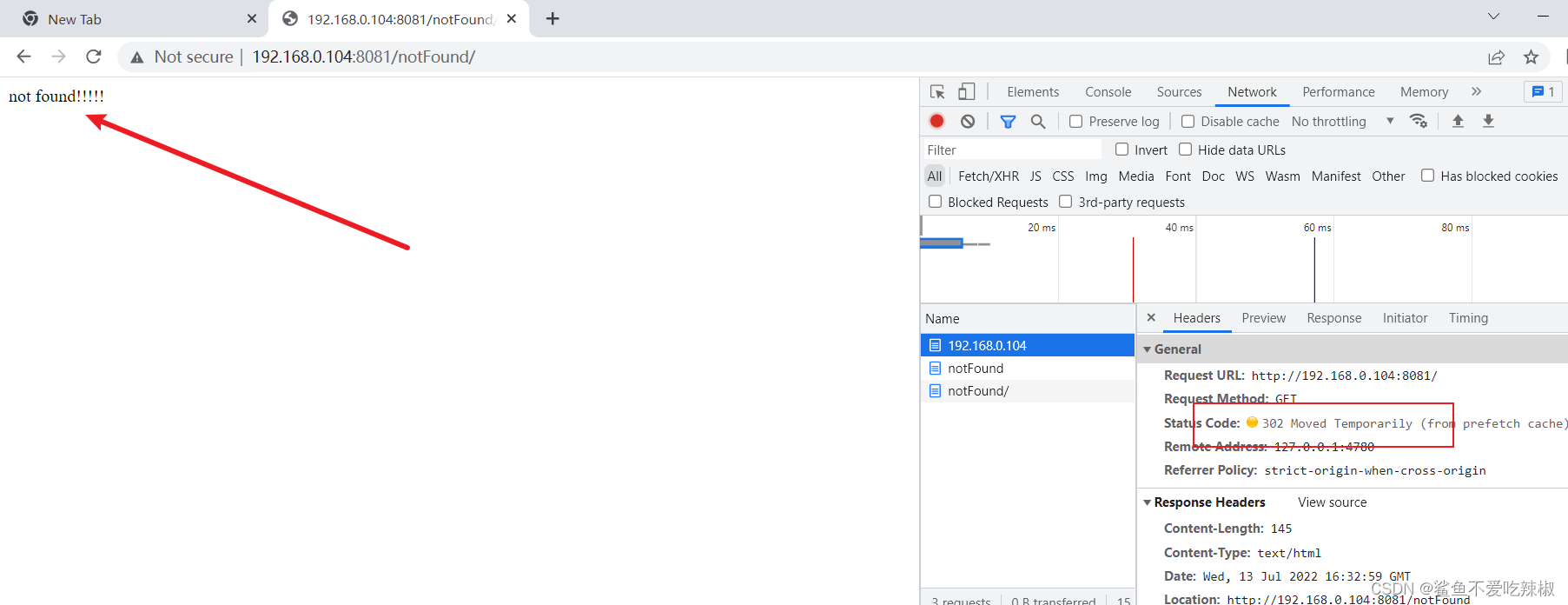
# 示例3-直接重定向
对于要求访问对应网页直接重定向的,我们可以直接在return后面配置重定向的地址即可。
server {
listen 8081;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
root /etc/nginx/html;
return http://192.168.0.104:8081/notFound/;
index index.html;
}
location /notFound {
root /etc/nginx/html;
index notFound.html;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# rewrite指令
# 简介
通过该配置可以将请求重定向到指定的地址上。
# 语法
- 语法:rewire regex replacement [flag];
- 默认值:无
- 上下文:server、location、if
- 示例:
rewrite/images/(.*\.jpg)$ /pic/$1
rewrite中几个配置的flag:
- last:重写后的URL会再次进入server段匹配location
- break:匹配到下一个url后不再匹配其他location
- redirect:302临时重定向
- permanent:301永久重定向
# 示例1-将请求永久重定向到notFound
永久重定向到notFound,可以看到笔者的配置在rewrite后面指定地址并且用permanent关键字。
server {
listen 8081;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
# 永久重定向到notFound映射
rewrite ^/(.*) http://192.168.0.104:8081/notFound permanent;
}
# notFound映射配置
location /notFound {
root /etc/nginx/html;
index notFound.html;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
完成配置后,进行测试可以发现响应码确实为301,并且网页也确实打到了notFound上。
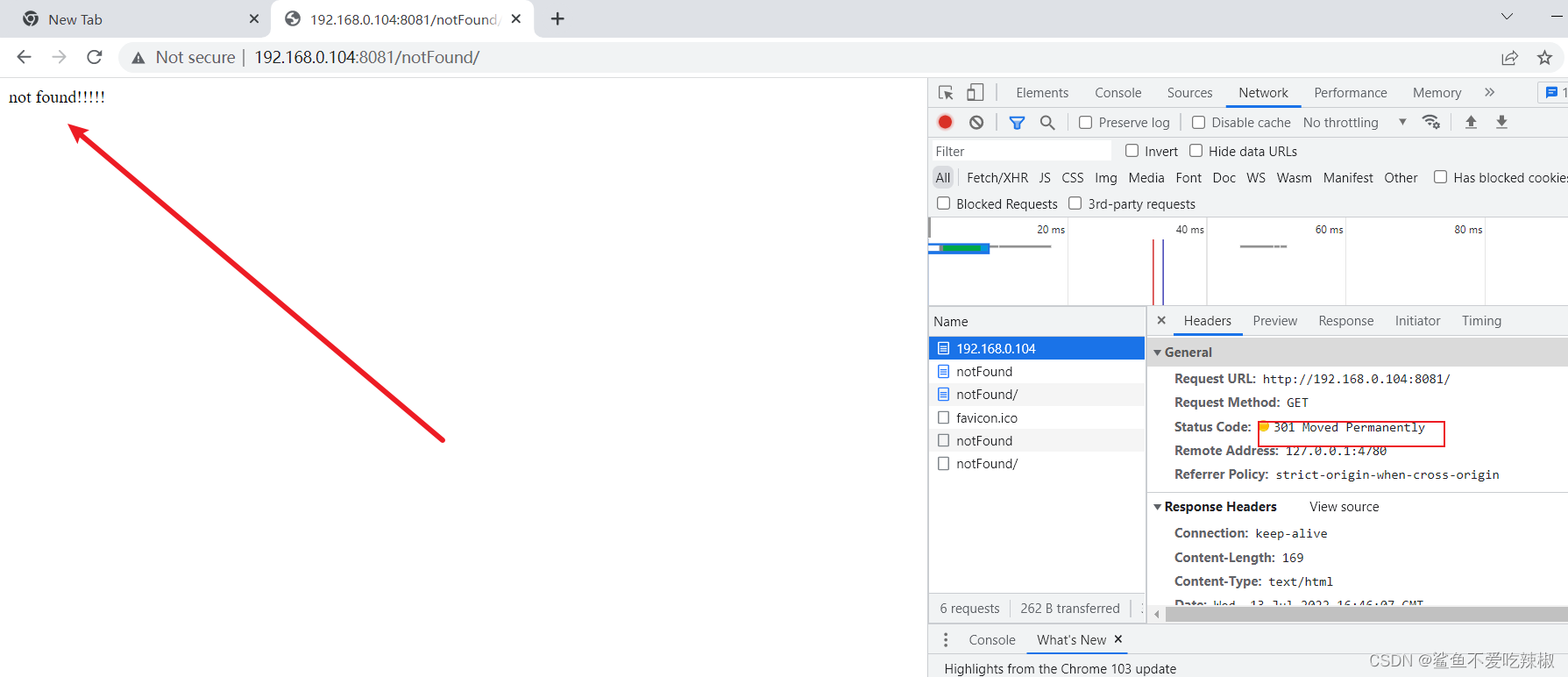
# 示例2-基于rewrite实现多级跳跃
如下所示配置所示,笔者通过rewrite实现了2次跳跃:
- 将用户的请求images重定向到pics
- pics将请求重定向到photos
- 将photos请求直接返回200+响应字符串。
server {
listen 8081;
server_name localhost;
location /images {
# 跳转/images 注意这里我们需要在html创建一个images文件夹,并在下面创建一个test.html
rewrite /images/(.*) /pics/$1 ;
}
location /pics {
# 跳转/photos 注意这里我们需要在html创建一个pics文件夹,并在下面创建一个test.html
rewrite /pics/(.*) /photos/$1 ;
}
location /photos {
return 200 "return 200 in /photos";
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
完成配置后的测试可以看到images请求确实跳转到photo这个映射上。
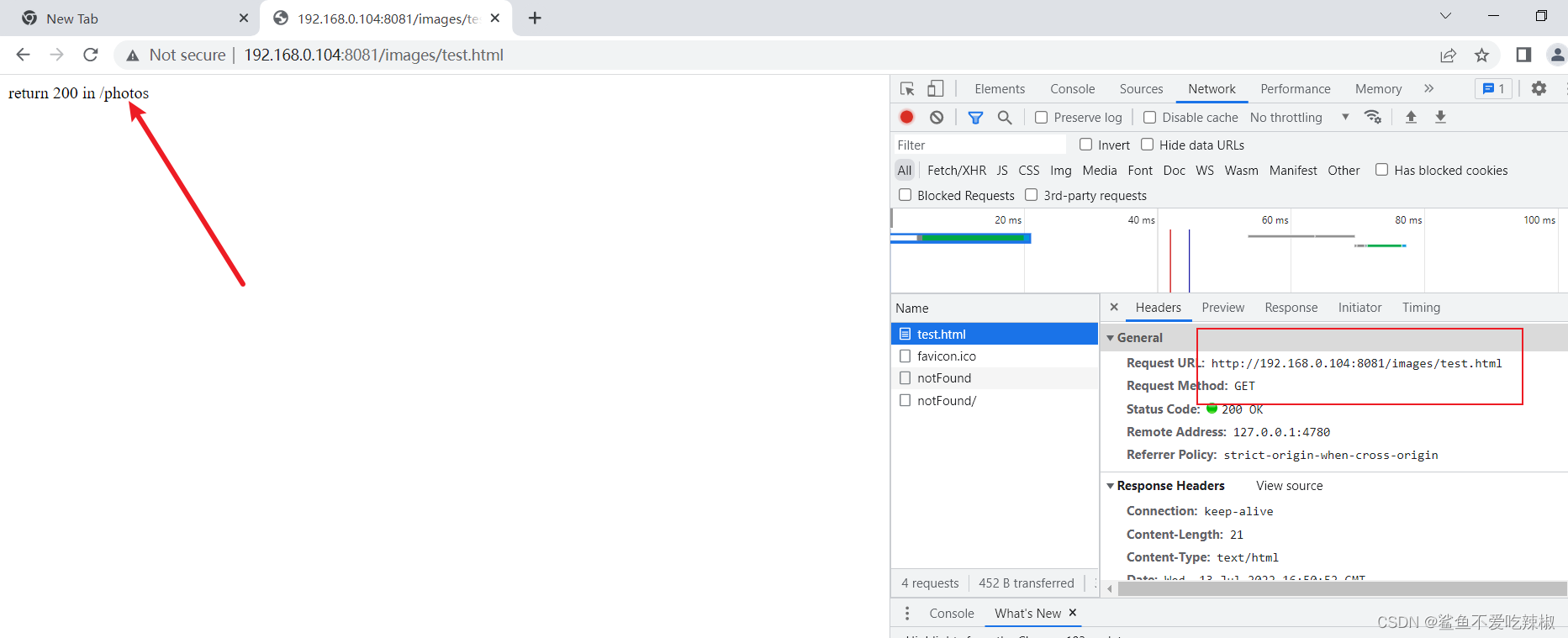
# 示例3-基于break截断请求
如下配置,在images的rewrite后面增加break,即可实现跳转pics映射之后,不再响应pics的任何跳转,直接返回pics资源。
server {
listen 8081;
server_name localhost;
root html;
location /images {
rewrite /images/(.*) /pics/$1 break;
}
location /pics {
rewrite /pics/(.*) /photos/$1 ;
}
location /photos {
return 200 "return 200 in /photos";
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
完成后我们直接通过curl来进行测试,从执行结果来看,获取的结果就是pics映射下的资源,说明请求跳到pics之后就不再进行跳转了。
curl 10.168.104.32:8081/images/test.html
this is pics page
2
3
# rewrite的if指令
- 语法:
if(condition){}; - 默认值:无
- 上下文:server、location
- 作用:条件判断
常见条件判断语法:
$variable:仅为变量时,值为空或以0开头字符串都会被当作false处理=或者!=: 等于或者不等于~或!~:匹配或者不匹配~*: 正则匹配,不区分大小写-f或!-f:检查文件存在或者不存在-d 或者!-d:检查目录存在或不存在-e 或!-e:检查文件、目录、符号连接等存在或不存在-x或!-x:检查文件可执行或不可执行
# 示例1-如果为谷歌代理则直接进行跳转
if($http_user_agent ~ Chrome){
rewirte /(.*) /browser/$1 break;
}
2
3
# 示例2-若远程连接的ip地址为指定ip返回200
配置实例如下,我们通过$remote_addr 获取请求的源ip,再通过if进行判断。
server{
listen 8081;
server_name localhost;
root html;
# 注意,这里我们需要为search专门在html中配置一个search的文件夹并创建index.html文件,否则会报404
location /search/ {
#若远程连接的ip地址为指定ip返回200
if ( $remote_addr = "103.0.0.0") {
return 200 "test if ok ";
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
完成配置后,我们进行测试,可以看到通过非配置ip的curl访问直接返回301
[root@localhost ~]# curl 10.168.104.32:8081/search
2
响应结果
<html>
<head><title>301 Moved Permanently</title></head>
<body bgcolor="white">
<center><h1>301 Moved Permanently</h1></center>
<hr><center>nginx/1.10.2</center>
</body>
</html>
2
3
4
5
6
7
反之若使用指定ip访问,则可以看到对应请求的网页。
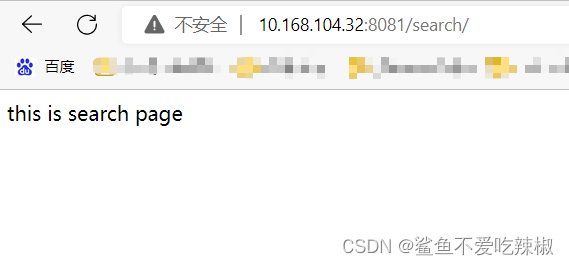
# 示例3-若location匹配到images,我们就将其重写到pics目录下
server{
listen 8081;
server_name localhost;
root html;
location / {
# 如果匹配到的uri为images,则重写到pics目录下
if ( $uri = "/images/") {
rewrite (.*) /pics/ break;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
完成配置后我们进行测试,直接请求images
curl http://10.168.104.32:8081/images/
可以看到输出结果跳转到了pics的index html了
this is pics index html
2
# return和rewrite执行顺序
我们给出一段配置实例,遇到last会重新遍历查找所有location,若没加last或者break则顺序执行,遇到return就返回结果不再执行后续动作。
server {
listen 8081;
server_name localhost;
root html;
location /search {
rewrite /(.*) http://www.cctv.com permanent;
}
location /images {
# 添加last重头查找符合要求的location
rewrite /images/(.*) /pics/$1 last;
return 200 "return 200 in /images";
}
location /pics {
rewrite /pics/(.*) /photos/$1 ;
return 200 "return 200 in /pics";
}
location /photos {
return 200 "return 200 in /photos";
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
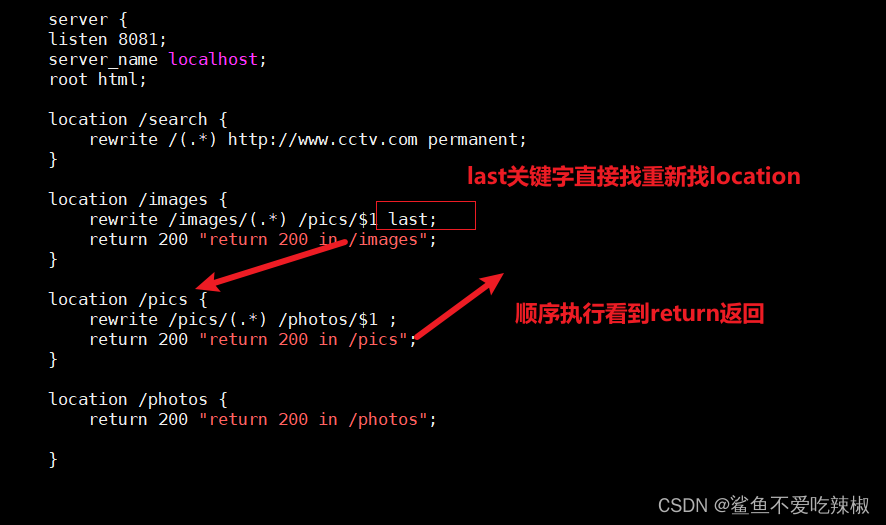
所以最终结果如下,可以看到直接定位到pics直接返回。
curl 10.168.104.32:8081/images/test.html
return 200 in /pics
2
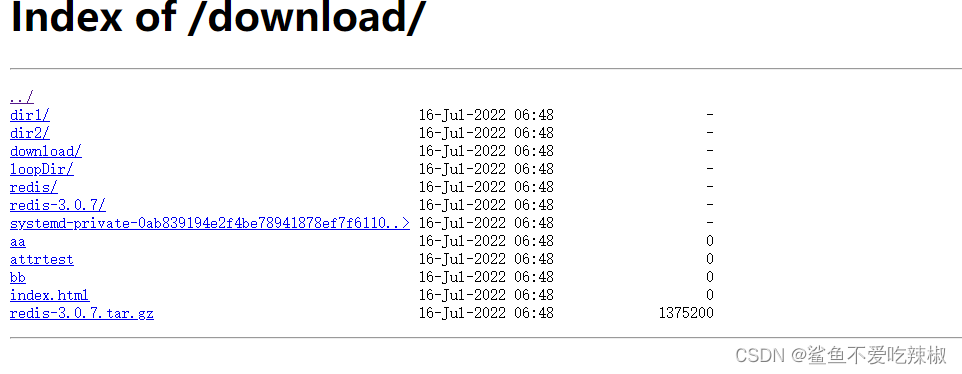
# autoindex
# 简介
当请求的location以/结尾时且请求对应地址为文件夹,若将autoindex开启,那么文件夹则会以文件列表的方式显示。
# 语法
# autoindex
- 语法:autoindex on |off
- 默认值:autoindex off;
- 上下文:http、server、location
- 作用:autoindex开关
# autoindex_exact_size
- 语法: autoindex_exact_size on | off;
- 默认值:autoindex_exact_size on;
- 上下文: http、server、location
- 作用:配置自动目录索引的精确文件大小显示
# autoindex_format
- 语法:autoindex_format html | xml | json | jsonp
- 默认值:autoindex_format html;
- 上下文:http、server、location
- 作用:决定文件目录的格式
# autoindex_localtime
- 语法:autoindex_localtime on |off;
- 默认值:autoindex_localtime off;
- 上下文:http、server、location
- 作用:自动目录索引文件的时间显示方式
# 示例
可以看到笔者autoindex习惯配置一开始,并且开启autoindex_exact_size 显示精确大小,autoindex_localtime关闭不按照24h格式显示。
server{
listen 8081;
server_name localhost;
location /download/ {
# 这里选定目录为tmp目录,所以我们需要在tmp目录下新建一个download文件夹,否则会报404
root /tmp;
# 注意若该目录下有a.html页面就不会显示下载文件而是显示a.html的内容
index a.html;
# 开启autoindex
autoindex on;
# 配置为off就不会精确计算大小,更好看一些
autoindex_exact_size on;
autoindex_format html;
# on的话会按照24小时进行计算
autoindex_localtime off;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
完成配置后请求该地址,可以看到显示的目录就是文件列表,对应配置格式也是和预期一致。
# TCP连接相关变量
# 分类
- TCP连接变量
- HTTP请求变量
- nginx处理HTTP请求变量
- nginx返回响应变量
- nginx内部变量
# TCP连接相关变量
- remote_addr:客户端地址,例如192.168.1.1。
- remote_port :客户端端口,例如58473。
- binary_remote_addr:客户端地址的整型格式。
- connection:已处理连接,是一个递增的序号。
- connection_request:当前连接上执行的请求数,对于keepalive连接有意义。
- proxy_protocol_addr:如果使用proxy_protocol协议,则返回原始用户的地址,否则为空。
- proxy_protocol_port:如果使用proxy_protocol协议,则返回原始用户的端口,否则为空。
- server_addr:服务器地址,例如192.168.184.240。
- server_port:服务器端口,例如80。
- server_protocol:服务端协议,例如HTTP/1.1。
# 配置示例
如下所示,我们可以通过return指令打印这些变量的值。
server{
listen 8081;
server_name localhost;
location / {
return 200 "remote_addr: $remote_addr
remote_port: $remote_port
server_addr: $server_addr
server_port: $server_port
server_protocol: $server_protocol
connection: $connection
proxy_protocol_addr: $proxy_protocol_addr
";
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 测试
第一次curl请求
curl 10.168.104.32:8081
输出结果如下:
remote_addr: 10.168.104.32
remote_port: 54868
server_addr: 10.168.104.32
server_port: 8081
server_protocol: HTTP/1.1
connection: 20
proxy_protocol_addr:
2
3
4
5
6
7
8
9
然后我们第二次curl请求
[root@localhost download]# curl 10.168.104.32:8081
2
可以看到connection请求+1。
remote_addr: 10.168.104.32
remote_port: 54870
server_addr: 10.168.104.32
server_port: 8081
server_protocol: HTTP/1.1
connection: 21
proxy_protocol_addr:
2
3
4
5
6
7
# HTTP请求相关变量
对应变量的变量名如下所示:
- conten_length:请求包体头部长度
- content_type:请求包体类型
- arg_参数名:URL中某个参数
- args:所有URL参数
- is_args:URL中有参数,则返回?;否则返回空
- query_string:与args完全相同
- uri:请求的URL,不包含参数
- request_uri:请求的URL,包含参数
- scheme:协议名,http或者https
- request_method:请求的方法,GET、HEAD、POST等
- request_length:所有请求内容的大小,包含请求行,头部,请求体
- remote_user:由HTTP Basic Authentication协议传入的用户名
- http_cookie:用户请求cookie的内容
# 配置示例
我们还是通过return指令进行打印:
location / {
auth_basic "Test Auth";
auth_basic_user_file auth/encrypt_pass;
return 200 "uri: $uri
request_uri: $request_uri
scheme: $scheme
request_method: $request_method
request_length: $request_length
args: $args
is_args: $is_args
arg_pid: $arg_pid
query_string: $query_string
remote_user: $remote_user
host: $host
";
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 测试
我们发起一个get请求携带一个par参数
curl 10.168.104.32:8081?par=1
输出结果如下,可以看到该打印的都打印了
uri: /
request_uri: /?par=1
scheme: http
request_method: GET
request_length: 88
args: par=1
is_args: ?
arg_pid:
query_string: par=1
remote_user:
host: 10.168.104.32
2
3
4
5
6
7
8
9
10
11
12
同样的,请求地址也可以是字符串。
curl "10.168.104.32:8081?par=1&par2=2"
输出结果如下:
uri: /
request_uri: /?par=1&par2=2
scheme: http
request_method: GET
request_length: 95
args: par=1&par2=2
is_args: ?
arg_pid:
query_string: par=1&par2=2
remote_user:
host: 10.168.104.32
2
3
4
5
6
7
8
9
10
11
# Nginx变量
# 处理请求时相关变量(也可以作为配置变量,如limit_rate)
- request_time:请求处理到现在所耗费的时间,单位为秒,例如0.03代表30毫秒
- request_completion:请求处理完成,则返回OK,否则为空
- request_id:16进制显示的请求id,随机生成的
- server_name:匹配上请求的server_name值
- https:若开启https,则值为on,否则为空
- request_filename:待访问文件的完整路径
- document_root:由URI和root/alias规则生成的文件夹路径
- realpath_root:将document_root中的软链接换成真实路径
- limit_rate:返回响应时的速度上限值
# 返回响应时相关变量
- body_bytes_sent:响应体中真实内容的大小
- body_sent:全部响应体大小
- status:HTTP返回状态码
# 参考
Nginx体系化深度精讲, 给开发和运维的刚需课程:https://coding.imooc.com/class/405.html (opens new window)
302状态码代表什么,302状态码解决方法:https://zhuanlan.zhihu.com/p/266780524 (opens new window)
