 Redis SDS动态字符串深度解析
Redis SDS动态字符串深度解析
[toc]
# 写在文章开头
我们都知道Redis基于单线程实现的一个高性能内存数据库,所以了解其底层设计,会让我们具备一个从微观的视角极致压榨Redis性能的能力,这其中对于数据结构的设计也是非常巧妙,所以关于Redis源码解析的系列将直接从最基本的字符串的设计说起。
Hi,我是 sharkChili ,是个不断在硬核技术上作死的 java coder ,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
# 详解SDS字符串
# 为什么需要SDS字符串
C语言自带的字符串通过一个char*字符串数组存储字符构成一个完整的字符串,判断当前字符串是否到达末尾则是通过判断末尾是否有\0作为依据。获取字符串长度操作的时候,也是通过指针进行遍历遇到第一个\0则说明当前字符串到达结尾了。

这一点我们可以直接在Linux上编写一个简单的C语言代码印证:
#include <stdio.h>
#include <string.h>
int main()
{
char *a = "redi\0s";
char *b = "redis\0";
printf("%lu\n", strlen(a));
printf("%lu\n", strlen(b));
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
通过gcc指令生成可执行文件后输出结果如下,可以看到原生C语言的长度是通过遍历字符串直至遇到第一个结束符\0为止的:
4
5
2
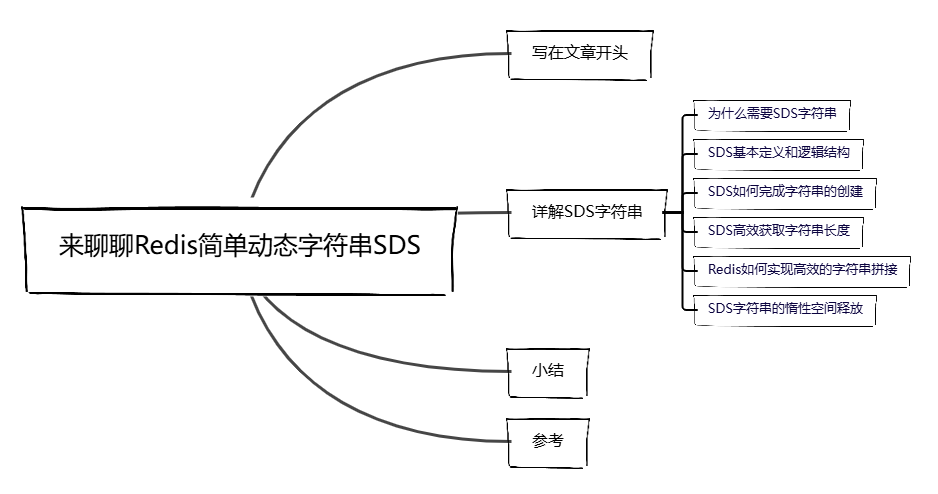
这种设计对于Redis来说非常不友好,原因很简单,某些场景下Redis可能会将文件的二进制数据流作为数据串存入,假设字符串存在\0的字符,使用原生的字符串数组无法做到很准确数据截断出现二进制安全问题:
除此之外,在进行字符串拼接操作的时候,C语言原生字符串需要从头到尾遍历到目标位置,然后将新的字符串拼接上去:
char *strcat(char *dest, const char *src) {
//指向要被拼接的字符串
char *tmp = dest;
//遍历到末尾
while(*dest)
dest++;
//将src拼接到desc上
while((*dest++ = *src++) != '\0' )
//返回结果
return tmp;
}
2
3
4
5
6
7
8
9
10
11
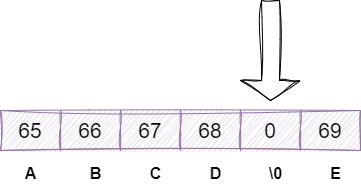
并且C语言的创建需要预先定义字符串长度,这使得我们如果没有在逻辑上加以控制的话,还可能出现缓冲区溢出的情况:
这种种细节上势必导致单线程操作的Redis存在各种耗时的开销,于是Redis设计者就专门设计了SDS字符串这种数据结构。
# SDS基本定义和逻辑结构
SDS通过三个关键字段来管理字符串:
len:记录当前字符串的实际长度free:记录当前分配但未使用的字节数buf[]:实际存储字符串内容的字符数组
那么问题来了,为什么需要free这个字段呢?
假设我们使用SDS创建一个初始内容为Redis的字符串,之后将其修改为Res。SDS的做法除了修改buf数组的字符串内容外,还会同步维护len和free字段。通过维护free字段,确保后续需要再追加2个字符时可以直接利用现有内存,而无需创建全新的数组来存放字符。这也就是所谓的惰性释放的设计思想:
对于这段结构的定义,我们可以redis的sds.h看到这段定义:
// Redis 3.2之前版本的SDS结构体定义
struct sdshdr {
//字符串长度
unsigned int len;
//空闲的数组空间大小
unsigned int free;
//字符数组
char buf[];
};
2
3
4
5
6
7
8
9
需要注意的是,在Redis 3.2版本之后,SDS的实现进行了优化,引入了多种头部结构以节省内存。根据字符串长度的不同,Redis会选择不同的结构体类型:
sdshdr5:用于存储长度小于32字节的字符串(不存储free字段)sdshdr8:用于存储长度小于256字节的字符串sdshdr16:用于存储长度小于65536字节的字符串sdshdr32:用于存储长度小于2^32字节的字符串sdshdr64:用于存储长度小于2^64字节的字符串
这种设计通过使用不同大小的整型来存储长度和空闲空间,避免了小字符串的空间浪费。
# SDS如何完成字符串的创建
我们先从SDS字符串的创建聊起,进行字符串创建时Redis会调用sdsnewlen函数进行创建,假设我们要创建一个字符串abc,那么对应的创建代码就是:
mystring = sdsnewlen("abc",3);
首先Redis会为abc创建一个长度为3+1的数组,然后将abc放到数组前3个位置,末尾用\0收尾,同时记录此时字符串的长度为3(不包括结束符),free为0即当前空间全部填满:
对应的我们也给出sds.c中这段代码的实现:
sds sdsnewlen(const void *init, size_t initlen) {
struct sdshdr *sh;
//初始化创建一个sdshdr加上(字符串长度+1)的内存空间
if (init) {
sh = zmalloc(sizeof(struct sdshdr)+initlen+1);
} else {
sh = zcalloc(sizeof(struct sdshdr)+initlen+1);
}
if (sh == NULL) return NULL;
//记录字符串长度
sh->len = initlen;
//空闲空间记录为0
sh->free = 0;
//将字符串存到buf数组中,完成后buf数组用\0收尾
if (initlen && init)
memcpy(sh->buf, init, initlen);
sh->buf[initlen] = '\0';
//返回buf指针
return (char*)sh->buf;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# SDS高效获取字符串长度
相较于C语言默认字符串通过遍历字符串获取长度的设计,SDS这种通过创建时即实时维护长度字段的设计实现了高效的O(1)级别字符串长度获取操作:
static inline size_t sdslen(const sds s) {
struct sdshdr *sh = (void*)(s-(sizeof(struct sdshdr)));
//通过sds的len字符快速得到当前字符串的长度
return sh->len;
}
2
3
4
5
# Redis如何实现高效的字符串拼接
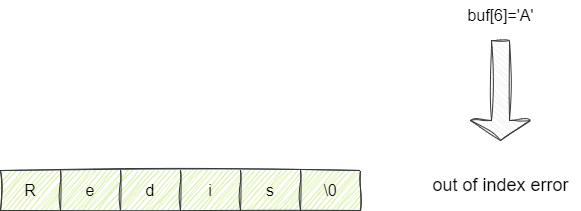
假设我们用sdsnewlen创建字符串red,此时我们的buf为red,len为3,而free则是0。此时希望将is拼接上去。很明显当前buf数组空间不够,基于空间预分配思想,Redis认为本次拼接操作之后可能还会存在拼接的情况,所以计算出拼接后的字符redis长度为5字节,在此基础上再开辟5+1的空间作为预分配空间+结束符空间,也就是创建一个全新的容量为11的数组空间装redis字符串。由此避免下次可能出现字符串拼接导致在此创建新数组的开销:
对应的我们给出拼接函数sdscat,可以看到其入参为当前字符串对象s和要拼接的字符串指针t:
PS : Redis的空间预分配机制并非一成不变采用拼接后的字符串长度*2+1,当当前字符串空间小于1MB时,预分配的空间是所需空间的两倍;当字符串长度大于等于1MB时,每次预分配的空间永远都是1MB。例如我们当前字符串大小为2MB,那么进行拼接操作扩容时得到的空间大小则是2MB+1MB+1byte:
对应的我们给出拼接函数sdscat,可以看到其入参为当前字符串对象s和要拼接的字符串指针t:
sds sdscat(sds s, const char *t) {
return sdscatlen(s, t, strlen(t));
}
2
3
查阅其底层实现可知,
sds sdscatlen(sds s, const void *t, size_t len) {
struct sdshdr *sh;
//获取当前长度
size_t curlen = sdslen(s);
//空间预分配,如果当前空间不够且小于1MB则基于拼接后的长度*2+1,反之基于拼接后的字符串长度+1MB+1
s = sdsMakeRoomFor(s,len);
if (s == NULL) return NULL;
sh = (void*) (s-(sizeof(struct sdshdr)));
//将字符串存入buf数组
memcpy(s+curlen, t, len);
//长度为拼接后的长度
sh->len = curlen+len;
//空闲空间为预分配后得到的free减去新字符串长度len
sh->free = sh->free-len;
//字符串末尾用\0收尾
s[curlen+len] = '\0';
return s;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
为保证文章的连贯性,我们也给出空间预分配的代码:
sds sdsMakeRoomFor(sds s, size_t addlen) {
struct sdshdr *sh, *newsh;
size_t len, newlen;
char *newbuf;
// 获取当前的sdshdr结构
sh = (void*)(s - sizeof(struct sdshdr));
len = sh->len;
newlen = len + addlen;
// 如果当前的free空间足够,直接返回
if (sh->free >= addlen) return s;
// 根据新长度决定预分配策略
// 如果新长度小于1MB则newlen为拼接后的长度*2,反之则是newlen+1MB
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
// 基于计算的newlen创建出sh+newlen+结束符大小的新空间newsh
newsh = zrealloc(sh, sizeof(struct sdshdr) + newlen + 1);
if (newsh == NULL) return NULL;
// 空闲空间为新长度减去新字符串长度len
newsh->free = newlen - len;
// 返回字符数组指针
return newsh->buf;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# SDS字符串的惰性空间释放
进行SDS字符串缩减操作时,Redis设计者为了避免后续还可能存在的拼接操作,采用了惰性空间释放的机制。例如我们希望将redis字符串改为red,SDS的做法是直接在d后面追加\0,并同时维护len和free字段的值,而不会重新分配一个新的buf数组空间。这样既保证了空间缩减的执行性能,也预防了未来可能的拼接操作需要重新分配内存:
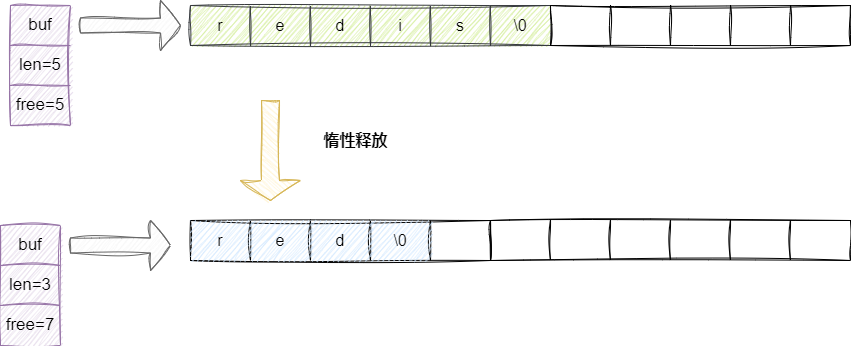
对应我们给出惰性空间释放的代码:
sds sdscpy(sds s, const char *t) {
//直接调用sdscpylen入参为当前字符串s和替换的字符串指针t
return sdscpylen(s, t, strlen(t));
}
sds sdscpylen(sds s, const char *t, size_t len) {
struct sdshdr *sh = (void*)(s - sizeof(struct sdshdr));
size_t totlen = sh->free + sh->len;
// 如果当前空间足够容纳新字符串,直接复制
if (totlen < len) {
// 空间不够,需要重新分配
s = sdsMakeRoomFor(s, len - totlen);
if (s == NULL) return NULL;
sh = (void*)(s - sizeof(struct sdshdr));
}
// buf指向字符串t
memcpy(s, t, len);
// 尾部用\0收尾
s[len] = '\0';
// 维护当前长度len和空闲空间大小free
sh->len = len;
sh->free = totlen - len;
return s;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 小结
本文从Redis源码的角度剖析了SDS字符串的设计思想和实现方式,希望对你有所启发。
SDS作为Redis的核心数据结构之一,通过以下几个关键设计提升了字符串操作的效率和安全性:
二进制安全:通过
len字段记录长度,而不是依赖\0作为字符串结束标识,可以安全地存储包含\0的二进制数据。高效获取长度:通过
len字段可以在O(1)时间内获取字符串长度,而C字符串需要O(N)时间遍历。空间预分配:在字符串增长时,SDS会预分配额外空间,减少内存重分配次数,提高性能。
惰性空间释放:在字符串缩短时,SDS不会立即释放空间,而是保留在
free字段中供后续使用,避免频繁的内存重分配。内存优化:Redis 3.2之后引入了多种SDS头部结构,根据字符串长度选择最适合的类型,避免小字符串的空间浪费。
这些设计使得SDS在Redis中能够高效地处理各种字符串操作,为Redis的高性能提供了基础保障。
我是 sharkchili ,CSDN Java 领域博客专家,开源项目—JavaGuide contributor,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 "加群" 即可和笔者和笔者的朋友们进行深入交流。
# 参考
《Redis设计与实现》
