 基于sharding-jdbc拓展点实现复杂分库分表算法
基于sharding-jdbc拓展点实现复杂分库分表算法
# 写在文章开头
我们之前介绍一款轻量级的分库分表中间件sharding-jdbc,默认情况下该框架的分表算法都是采用内联表达式进行配置,对于某些比较灵活的需求无法实现,所以本文就以一个基于电话号码号头的案例介绍一下如何通过基于sharding-jdbc拓展点实现复杂分库分表算法。
PS: 如果对于sharding-jdbc不了解的读者,可以移步笔者之前写的这两篇文章深入了解sharding-jdbc的使用和原理:
sharding-jdbc如何实现分页查询:https://mp.weixin.qq.com/s/20jdhjj20kcN61ICNn4GeQ (opens new window)
Hi,我是 sharkChili ,是个不断在硬核技术上作死的技术人,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
# 详解自定义分表逻辑开发
# 基于复杂发表算法的案例说明
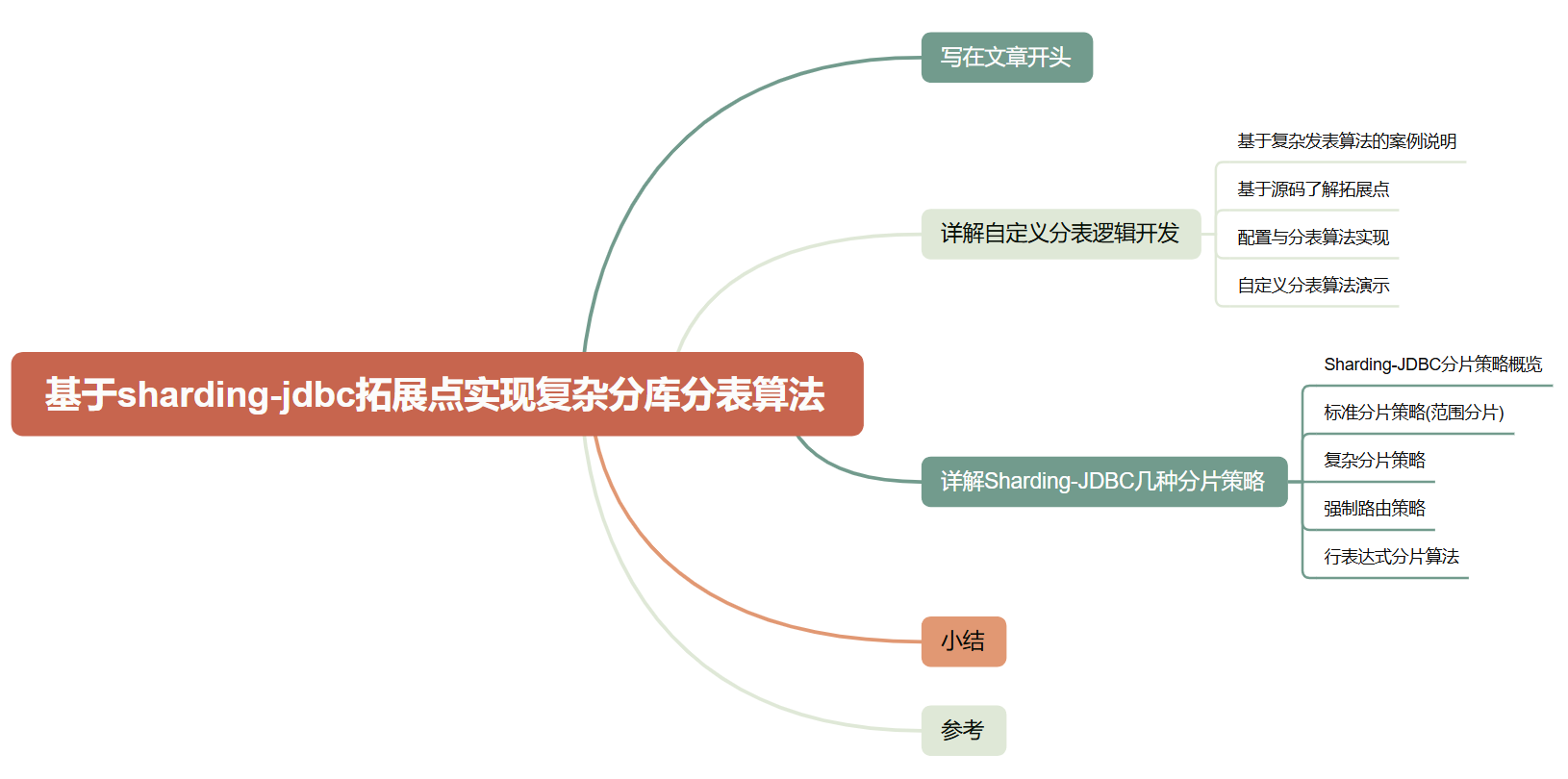
我们的案例是为了采集不同地区的电话号码用户的信息,希望相同号头的电话号码会落到同一张分表上,例如我们现在有分表3张,有一个电话号码10658888,我们必须截取到1065和分表数进行取模运算得到分表名user_0:
# 基于源码了解拓展点
我们直接定位到框架进行分库分表计算的代码段StandardRoutingEngine的routeTables,可以看到该方法会通过程序初始化加载好的shardingRule定位到当前分表策略:
private Collection<DataNode> routeTables(final TableRule tableRule, final String routedDataSource, final List<RouteValue> tableShardingValues) {
//获取分表的前缀,以本文为例就是user
Collection<String> availableTargetTables = tableRule.getActualTableNames(routedDataSource);
//基于shardingRule调用getTableShardingStrategy获取分表策略
Collection<String> routedTables = new LinkedHashSet<>(tableShardingValues.isEmpty() ? availableTargetTables
: shardingRule.getTableShardingStrategy(tableRule).doSharding(availableTargetTables, tableShardingValues));
Preconditions.checkState(!routedTables.isEmpty(), "no table route info");
Collection<DataNode> result = new LinkedList<>();
for (String each : routedTables) {
result.add(new DataNode(routedDataSource, each));
}
return result;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
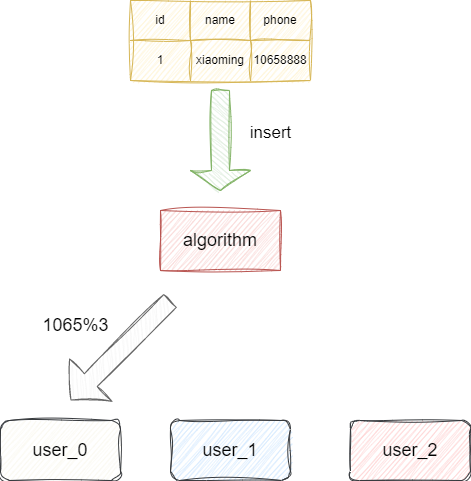
查看getTableShardingStrategy方法可以看到,如果tableRule没有实现默认分表策略,则采用默认也就是我们配置的内敛策略defaultTableShardingStrategy ,反之返回我们自定义实现的分表策略:
public ShardingStrategy getTableShardingStrategy(final TableRule tableRule) {
//若getTableShardingStrategy返回空说明我们没有自定义实现类,返回defaultTableShardingStrategy 通过内联表达式进行分表运算,反之返回我们的自定义实现类
return null == tableRule.getTableShardingStrategy() ? defaultTableShardingStrategy : tableRule.getTableShardingStrategy();
}
2
3
4
5
6
此时我们可以推测tableShardingStrategy的配置就决定了我们是走内联表达式还是自定义类分表算法,通过源码的定位笔者发现tableShardingStrategy关于分表的配置来源于配置,在程序启动时tableShardingStrategy会根据yml的配置得到分表前缀如果是.table-strategy.standard.则说明当前程序采用的是自定义分表算法,就会基于这段配置定位到Java类生分表引擎:
对应的我们给出分表算法初始化的入口:
public TableRule(final TableRuleConfiguration tableRuleConfig, final ShardingDataSourceNames shardingDataSourceNames, final String defaultGenerateKeyColumn) {
//......
//基于配置的值决定分表算法如何创建
tableShardingStrategy = null == tableRuleConfig.getTableShardingStrategyConfig() ? null : ShardingStrategyFactory.newInstance(tableRuleConfig.getTableShardingStrategyConfig());
//......
}
2
3
4
5
6
继续步进我们就可以直接定位到对应分表配置加载逻辑
@Override
public TableRuleConfiguration swap(final YamlTableRuleConfiguration yamlConfiguration) {
//......
//基于yml配置得到分表算法采用哪种方式
result.setTableShardingStrategyConfig(shardingStrategyConfigurationYamlSwapper.swap(yamlConfiguration.getTableStrategy()));
//......
return result;
}
2
3
4
5
6
7
8
9
10
最终查看配置加载的swap就可以看到自定分表配置加载的逻辑可以看到,只要我们配置的是StandardShardingStrategyConfiguration前缀的配置,这段配置就会为我们生成自定义算法:
@Override
public YamlShardingStrategyConfiguration swap(final ShardingStrategyConfiguration data) {
//基于yml中给定的字段、分表类生成标准的分表策略配置
StandardShardingStrategyConfiguration得到自定义分表算法
YamlShardingStrategyConfiguration result = new YamlShardingStrategyConfiguration();
if (data instanceof StandardShardingStrategyConfiguration) {
result.setStandard(createYamlStandardShardingStrategyConfiguration((StandardShardingStrategyConfiguration) data));
}
//......
return result;
}
2
3
4
5
6
7
8
9
10
11
# 配置与分表算法实现
基于上述源码,笔者得到对应配置前缀,我们开始进行自定义分库分表算法的配置步骤,首先自然是完成数据源的配置,如下所示,笔者自定义分表数据源名称为ds0,后续数据源信息配置的datasource后面都要拼上这个自定义的数据源名称ds0:
# 数据源名称
spring.shardingsphere.datasource.names=ds0
# 数据源基本链接、账号、密码信息
spring.shardingsphere.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds0.url=jdbc:mysql://localhost:3306/db?characterEncoding=utf-8
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=123456
2
3
4
5
6
7
8
完成数据源基本配置后就到最重要分表核心配置了,对应选项含义分别是:
actual-data-nodes:配置分库分表的库表区间,以笔者为例,配置为单库多表,对应的配置为ds0.user_$->{0..2},即ds0这个数据源下的user_0、user_1、user_2。precise-algorithm-class-name:指定分库分表的策略的实现类的全路径,以笔者为例包的全路径为com.sharkChili.algorithm.TableShardingAlgorithm。sharding-column:配置分片键,本文采用的是用户表的电话号码也就是phone字段。key-generator.column:该表的主键id为id。key-generator.type:id算法采用雪花算法。
# 配置分表区间
spring.shardingsphere.sharding.tables.user.actual-data-nodes=ds0.user_$->{0..2}
# 指定自定义分表类的包全路径
spring.shardingsphere.sharding.tables.user.table-strategy.standard.precise-algorithm-class-name=com.sharkChili.algorithm.TableShardingAlgorithm
# 配置分表分片键
spring.shardingsphere.sharding.tables.user.table-strategy.standard.sharding-column=phone
# 配置主键生成策略,指定数据表的主键为id字典,id算法采用雪花算法
spring.shardingsphere.sharding.tables.user.key-generator.column=id
# id使用雪花算法,因为雪花算法生成的id具有全球唯一性,并且又有自增特性,适合mysql的innodb引擎
spring.shardingsphere.sharding.tables.user.key-generator.type=SNOWFLAKE
2
3
4
5
6
7
8
9
10
11
如果我们希望打印分库分表执行SQL日志可以加上这条配置:
# 打开sql输出日志
spring.shardingsphere.props.sql.show=true
2
最后我们给出分表实现类,直接继承PreciseShardingAlgorithm并执行泛型为phone字典的类型String,通过截取电话号码头4位通过取模算法返回分表名称:
@Slf4j
public class TableShardingAlgorithm implements PreciseShardingAlgorithm<String> {
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<String> phoneNum) {
log.info("分表信息:{}", JSONUtil.toJsonStr(collection));
//号头小于4位,放到默认表
if (StrUtil.isEmpty(phoneNum.getValue()) || phoneNum.getValue().length() < 4) {
return "user";
}
//获取号头进行取模获取表号
String phonePrex = phoneNum.getValue().substring(0, 4);
int tableNo = (Integer.valueOf(phonePrex)) % collection.size();
log.info("preciseShardingValue:{} table no:{}", phoneNum, tableNo);
//返回分表名
return "user_" + tableNo;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 自定义分表算法演示
最后我们给出插入的测试代码:
@Test
void insert() {
User user = new User();
user.setId((long) RandomUtil.randomInt());
user.setName("user" + 7879879843L);
user.setPhone("10658888");
userMapper.insert(user);
}
2
3
4
5
6
7
8
9
从日志可以看出,我们的插入数据定位到了分表0,与预期一致:
INFO 11940 --- [ main] ShardingSphere-SQL : Actual SQL: ds0 ::: insert into user_0 (id, name, phone) VALUES (?, ?, ?) ::: [-1687644961, user7879879843, 10658888]
# 详解Sharding-JDBC几种分片策略
# Sharding-JDBC分片策略概览
上述代码我们已经通过inline关键字指明基于表达式user_$->{id % 3}所实现的内联策略,通过该配置与之关联的关系类YamlShardingStrategyConfiguration我们可以看出,Sharding-JDBC总共一共了如下几种分片策略:
standard:精确分片策略,即基于用户给定的单个分片键定位对应的库表。complex:复杂分片策略,即基于用户传入的多个字段定位对应的库表。hint:强制路由策略,比较少用,该策略用基于用户传参并结合路由策略实现类定位库表。inline:内联表达式,基于用户给定的分片键值和表达式获取对应的库表。none:无分片策略。
对应的我们给出YamlShardingStrategyConfiguration 的配置类印证这种说法:
@Getter
@Setter
public class YamlShardingStrategyConfiguration implements YamlConfiguration {
private YamlStandardShardingStrategyConfiguration standard;
private YamlComplexShardingStrategyConfiguration complex;
private YamlHintShardingStrategyConfiguration hint;
private YamlInlineShardingStrategyConfiguration inline;
private YamlNoneShardingStrategyConfiguration none;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 标准分片策略(范围分片)
我们先来说说标准分片策略,也就是我们上文所实现的自定义分片算法,这里我们介绍另一种基于范围分片的策略实现,如下所示,可以看到我们分片键为user表的id之后,指明range-algorithm-class-name即范围分片查询算法的实现类为TableRangeShardingAlgorithm:
spring.shardingsphere.sharding.tables.user.table-strategy.standard.sharding-column=id
# 指明user表的范围分片算法类为TableRangeShardingAlgorithm
spring.shardingsphere.sharding.tables.user.table-strategy.standard.range-algorithm-class-name=com.sharkChili.algorithm.TableRangeShardingAlgorithm
2
3
4
对应我们也给出范围分片实现的算法实现类TableRangeShardingAlgorithm :
@Slf4j
public class TableRangeShardingAlgorithm implements RangeShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) {
//记录分片键对应的分表
Set<String> resTbSet = new ConcurrentHashSet<>();
//获取id起始值
long begin = rangeShardingValue.getValueRange().lowerEndpoint();
//获取id结束值
long end = rangeShardingValue.getValueRange().upperEndpoint();
//基于这个id的范围取模定位分表名称写入set中
LongStream.rangeClosed(begin, end).forEach(i -> resTbSet.add("user_" + i % 3));
log.info("res tb set:{}", resTbSet);
return resTbSet;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
这里我们给出测试代码:
UserMapper userMapper = SpringUtil.getBean(UserMapper.class);
UserExample userExample = new UserExample();
//指明id为2、3对应算法%3后的分表为0、1
userExample.createCriteria()
.andIdBetween(2L, 3L);
List<User> userList = userMapper.selectByExample(userExample);
log.info("user list:{}", userList);
2
3
4
5
6
7
8
输出结果如下,可以看到定位到了0和3两个分表,与预期的逻辑一致:

需要补充的是范围分片和标准精准匹配的分片策略是兼容的,所以我们在标准分片的配置情况下可以同时实现两套算法针对不同维度的查询:
# 标准分片策略
spring.shardingsphere.sharding.tables.user.table-strategy.standard.sharding-column=id
# 标准分片的精准定位算法
spring.shardingsphere.sharding.tables.user.table-strategy.standard.precise-algorithm-class-name=com.sharkChili.algorithm.TableShardingAlgorithm
# 指明user表的范围分片算法类为TableRangeShardingAlgorithm
spring.shardingsphere.sharding.tables.user.table-strategy.standard.range-algorithm-class-name=com.sharkChili.algorithm.TableRangeShardingAlgorithm
2
3
4
5
6
# 复杂分片策略
涉及多字段条件的查询,sharding-jdbc同样提供了复杂分片策略配置,例如我们的分表查询算法的是基于id和age两个字段,那么我们就可以指明complex声明分片键为id和age,通过ComplexTableShardingAlgorithm实现分表逻辑:
# 指名复杂分片算法键为id和age
spring.shardingsphere.sharding.tables.user.table-strategy.complex.sharding-columns=id,age
# 复合分片算法
spring.shardingsphere.sharding.tables.user.table-strategy.complex.algorithm-class-name=com.sharkChili.algorithm.ComplexTableShardingAlgorithm
2
3
4
这里为了简单演示复杂分片算法的实现和使用,笔者简单的取出多值查询中id和age各一个,然后定位到分表集合,对应逻辑如下,读者可以参考注释了解一下逻辑,对应的我们查询时只需传入id和age后就会走到该算法,这里就不多做结果演示了:
public class ComplexTableShardingAlgorithm implements ComplexKeysShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> collection, ComplexKeysShardingValue<Long> complexKeysShardingValue) {
Map<String, Collection<Long>> map = complexKeysShardingValue.getColumnNameAndShardingValuesMap();
Collection<Long> idList = map.get("id");
Collection<Long> ageList = map.get("age");
Set<String> tbSet = new HashSet<>();
//定位到age字段值
long age = Long.valueOf(String.valueOf(ageList.stream().findFirst().get()));
//定位到id字段值
long id = idList.stream().findFirst().get();
//如果年龄大于100则说明是无效数据,到user表查
if (age > 100) {
tbSet.add("user");
} else {//反之基于id进行取模运算定位分表
tbSet.add("user_" + id % 3);
}
return tbSet;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 强制路由策略
强制路由算是比较少用的分片策略,它的分表算法由用户自行实现且定位分表的逻辑与SQL语句没有任何关系,常用于系统维度的分表算法,所以配置时只需给出分表实现的策略类即可:
spring.shardingsphere.sharding.tables.user.table-strategy.hint.algorithm-class-name=com.sharkChili.algorithm.TableHintShardingAlgorithm
可以看到分表实现策略如下:
- 通过用户入参中获取逻辑分表
- 从入参出获取逻辑分表对应的value
- 基于上述两个值组装成分表
public class TableHintShardingAlgorithm implements HintShardingAlgorithm<String> {
@Override
public Collection<String> doSharding(Collection<String> tableNames, HintShardingValue<String> hintShardingValue) {
//定位传入的逻辑分表
String logicTableName = hintShardingValue.getLogicTableName();
String logicTableValue = hintShardingValue.getValues().stream().findFirst().get();
//基于values的第一个值定位分表号码,并于逻辑分配构成分表名称
String tbName = logicTableName+"_"+logicTableValue;
return Arrays.asList(tbName);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
hint算法是通过外部指定分片信息让分片策略决定路由最终指向,所以我们都是通过HintManager实例传入组装当前线程的逻辑表名和值从而定位到分表:
HintManager hintManager = HintManager.getInstance();
try {
//逻辑分表传入user,value传入0,让分表算法组成user_0
hintManager.addTableShardingValue("user", 0L);
List<User> userList = SpringUtil.getBean(UserMapper.class).selectByExample(null);
log.info(JSONUtil.toJsonStr(userList));
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
//因为hintManager是基于threadLocal进行传值,所以用完后注意手动clear清除线程数据
hintManager.clear();
}
2
3
4
5
6
7
8
9
10
11
12
13
从输出结果就可以看出,我们通过传参实现参数驱动式的分片算法是成功的:

# 行表达式分片算法
最后还有一种行表达式的分片策略算法,只需给定id并在配置给定分片算法即可,使用于简单的分表算法的实现:
## 行表达式 使用哪一列用作计算分表策略,我们就使用id
spring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column=id
##具体的分表路由策略,我们有3个user表,使用主键id取余3,余数0/1/2分表对应表user_0,user_2,user_2
spring.shardingsphere.sharding.tables.user.table-strategy.inline.algorithm-expression=user_$->{id % 3}
2
3
4
# 小结
本文结合源码实现了解到sharding-jdbc自定义分表算法实现的拓展点,并基于该拓展点完成我们的的号头分表逻辑,希望对你有所帮助。
我是 sharkchili ,CSDN Java 领域博客专家,mini-redis的作者,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
# 参考
SpringBoot集成ShardingSphere4.1.1(自定义分库、分表算法):https://zhuanlan.zhihu.com/p/414253622 (opens new window)
sharding-jdbc 分库分表的 4种分片策略,还蛮简单的:https://www.cnblogs.com/chengxy-nds/p/13919981.html (opens new window)
Sharding-JDBC强制路由案例实战:https://bbs.huaweicloud.com/blogs/407215 (opens new window)
