 Nginx性能优化
Nginx性能优化
# 简介
nginx作为常用的web代理服务器,某些场景下对于性能要求还是蛮高的,所以本片文章会基于操作系统调度以及网络通信两个角度来讨论一下Nginx性能的优化思路。
# 基于操作系统调度进行Nginx优化
# CPU工作方式
对于用户进程,CPU会按照下面的规则完成工作调度:
- 每个用户进程被加载到内存中,就会采用
CFS调度算法,即对于vruntime少的优先运行,得到CPU的运行时间片就会运行,时间一到就会被挂起。 - 进程优先级越高得到时间片的时间就越长。
- 进程实际运行时间不一定和时间片相等,当进程遇到IO阻塞时也会被挂起。
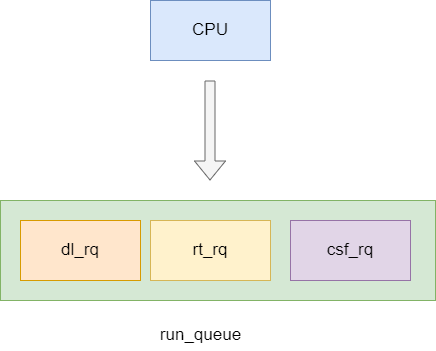
如下图,我们的用户进程nginx就会被放到csf_rq中,操作系统会等deadline进程(dl_rq中的进程)和实时进程(rt_rq中的进程)拿到时间片运行完之后,从cfs_rq中取出最左节点运行。
# 优化的整体方向
基于CPU工作原理的优化,我们一般都从以下两个角度考虑:
- 尽可能让操作系统历用尽可能多的
CPU资源 - 尽可能占用更多的
CPU时间片、减少进程间切换。
# 策略1(提升CPU利用率)
在多核CPU的情况下,我们可以设置多个nginx进程使其尽可能利用CPU资源。
首先我们可以使用vmstat ,查看CPU整体资源使用情况。
# 查看系统资源使用情况,2秒输出一次,输出3次
vmstat 2 3
2
如下所示,可以发现用户进程+系统进程所占用的时间比小于80%,系统资源充裕。
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 265472 177356 0 317180 10 49 778 55 78 67 1 1 98 0 0
0 0 265472 177356 0 317180 0 0 0 0 81 115 0 0 100 0 0
0 0 265472 177356 0 317180 0 0 0 0 72 114 0 0 100 0 0
2
3
4
5
6
7
所以们可以使用top命令并键入1查看操作系统的CPU核心数。
top
如下所示,笔者的机器有6个CPU核心,所以我们可以设置6个nginx进程,使每个worker进程与CPU核心一一对应。
top - 14:20:33 up 18 min, 2 users, load average: 0.20, 0.13, 0.23
Tasks: 255 total, 1 running, 254 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.3 us, 0.0 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 0.3 us, 0.0 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu2 : 0.0 us, 0.3 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu3 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu4 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu5 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
2
3
4
5
6
7
8
9
查看我们的worker进程:
ps -ef |grep nginx |grep -v grep
此时我们的Linux中的nginx实际接收用户请求的worker进程数为1,很明显未能很好的利用CPU资源,所以我们需要调整一下
root 2891 1 0 14:06 ? 00:00:00 nginx: master process /usr/local/nginx/sbin/nginx
nginx 2892 2891 0 14:06 ? 00:00:00 nginx: worker process
nginx 2893 2891 0 14:06 ? 00:00:00 nginx: cache manager process
2
3
4
5
打开nginx.conf,将worker_processes 设置为auto,这样
worker_processes auto;
2
完成后重新加载一下配置。
/usr/local/nginx/sbin/nginx -s reload
可以看到worker进程和CPU核心数一样,这样一来nginx就能更好的利用CPU资源了。
root 2891 1 0 14:06 ? 00:00:00 nginx: master process /usr/local/nginx/sbin/nginx
nginx 3179 2891 0 14:29 ? 00:00:00 nginx: worker process
nginx 3180 2891 0 14:29 ? 00:00:00 nginx: worker process
nginx 3181 2891 0 14:29 ? 00:00:00 nginx: worker process
nginx 3182 2891 0 14:29 ? 00:00:00 nginx: worker process
nginx 3183 2891 0 14:29 ? 00:00:00 nginx: worker process
nginx 3184 2891 0 14:29 ? 00:00:00 nginx: worker process
nginx 3185 2891 0 14:29 ? 00:00:00 nginx: cache manager process
2
3
4
5
6
7
8
9
10
11
# 策略2(避免Nginx进程切换)
即使创建与CPU核心数一样,nginx也不一定能够按序分别到每一个CPU上。所以我们希望能够将worker进程与CPU进行一一绑定,尽可能的避免nginx进程在CPU之间切换导致的伪共享带来的性能问题。
我们可以使用sar命令去查看每个CPU的资源使用情况(可能不一定准确,因为系统中还有别的进程在使用CPU,假如你这台服务器完全给nginx使用,那么这条指令是极具参考作用的)
# 查看第一个CPU的资源使用情况,每个1秒输出一次,共输出5次
sar -P 0 1 5
2
输出结果如下:
Linux 3.10.0-1160.el7.x86_64 (localhost.localdomain) 07/24/2022 _x86_64_ (6 CPU)
02:25:49 PM CPU %user %nice %system %iowait %steal %idle
02:25:50 PM 0 0.00 0.00 0.00 0.00 0.00 100.00
02:25:51 PM 0 0.00 0.00 0.00 0.00 0.00 100.00
02:25:52 PM 0 0.00 0.00 0.00 0.00 0.00 100.00
02:25:53 PM 0 0.00 0.00 0.00 0.00 0.00 100.00
02:25:54 PM 0 0.00 0.00 0.00 0.00 0.00 100.00
Average: 0 0.00 0.00 0.00 0.00 0.00 100.00
2
3
4
5
6
7
8
9
10
11
所以我们可以在nginx.conf配置下面这条命令,使得worker进程一一与下面的CPU对应
worker_cpu_affinity 0001 0010 0011 0100 0101 0110;
2
# 策略3(提升进程优先级)
Linux实时进程priority处于0-99,用户进程priority处于100-139,这个值越小优先级越高。priority的值的计算如下所示。
root用户nice可以将nice值 -20~19,普通用户只能0~19(避免抢占系统资源进程优先级)
priority(new) = priority(old) + nice
在演示提高优先级前,我们先查看一下nginx的进程优先级,
ps -elf |grep nginx
如下所示worker进程priority都是80。
5 S root 2891 1 0 80 0 - 19456 sigsus 14:06 ? 00:00:00 nginx: master process /usr/local/nginx/sbin/nginx
5 S nginx 5108 2891 0 80 0 - 20085 ep_pol 17:33 ? 00:00:00 nginx: worker process
5 S nginx 5109 2891 0 80 0 - 20085 ep_pol 17:33 ? 00:00:00 nginx: worker process
5 S nginx 5110 2891 0 80 0 - 20085 ep_pol 17:33 ? 00:00:00 nginx: worker process
5 S nginx 5111 2891 0 80 0 - 20085 ep_pol 17:33 ? 00:00:00 nginx: worker process
5 S nginx 5112 2891 0 80 0 - 20085 ep_pol 17:33 ? 00:00:00 nginx: worker process
5 S nginx 5113 2891 0 80 0 - 20085 ep_pol 17:33 ? 00:00:00 nginx: worker process
5 S nginx 5114 2891 0 80 0 - 20032 ep_pol 17:33 ? 00:00:00 nginx: cache manager process
0 S root 5205 4963 0 80 0 - 28203 pipe_w 17:39 pts/0 00:00:00 grep --color=auto nginx
2
3
4
5
6
7
8
9
10
对于nginx提高优先级的配置也非常简单,只需在nginx.conf加下面一行即可,这条配置就会将nice改为-20。
worker_priority -20;
2
再次查看发现nice变为-20,优先级变为60.
ps -elf |grep nginx
输出结果如下:
5 S root 2891 1 0 80 0 - 19456 sigsus 14:06 ? 00:00:00 nginx: master process /usr/local/nginx/sbin/nginx
5 S nginx 5208 2891 0 60 -20 - 20089 ep_pol 17:40 ? 00:00:00 nginx: worker process
5 S nginx 5209 2891 0 60 -20 - 20089 ep_pol 17:40 ? 00:00:00 nginx: worker process
5 S nginx 5210 2891 0 60 -20 - 20089 ep_pol 17:40 ? 00:00:00 nginx: worker process
5 S nginx 5211 2891 0 60 -20 - 20089 ep_pol 17:40 ? 00:00:00 nginx: worker process
5 S nginx 5212 2891 0 60 -20 - 20089 ep_pol 17:40 ? 00:00:00 nginx: worker process
5 S nginx 5213 2891 0 60 -20 - 20089 ep_pol 17:40 ? 00:00:00 nginx: worker process
5 S nginx 5214 2891 0 80 0 - 20036 ep_pol 17:40 ? 00:00:00 nginx: cache manager process
0 S root 5222 4963 0 80 0 - 28203 pipe_w 17:40 pts/0 00:00:00 grep --color=auto nginx
2
3
4
5
6
7
8
9
# 策略4(延迟处理新连接)
我们可以在location模块的监听后面加一个deferred,加上这个配置后,当用户与nginx服务器建立连接时,只有用户有请求数据时才会将TCP连接状态改为ESTABLISHED,否则就直接丢弃这条连接。
通过减少服务器和客户端之间发生的三次握手建立连接的数量来帮助提高性能。
listen 80 deferred;
# 提升nginx的网络性能
# 简介网络四层模型
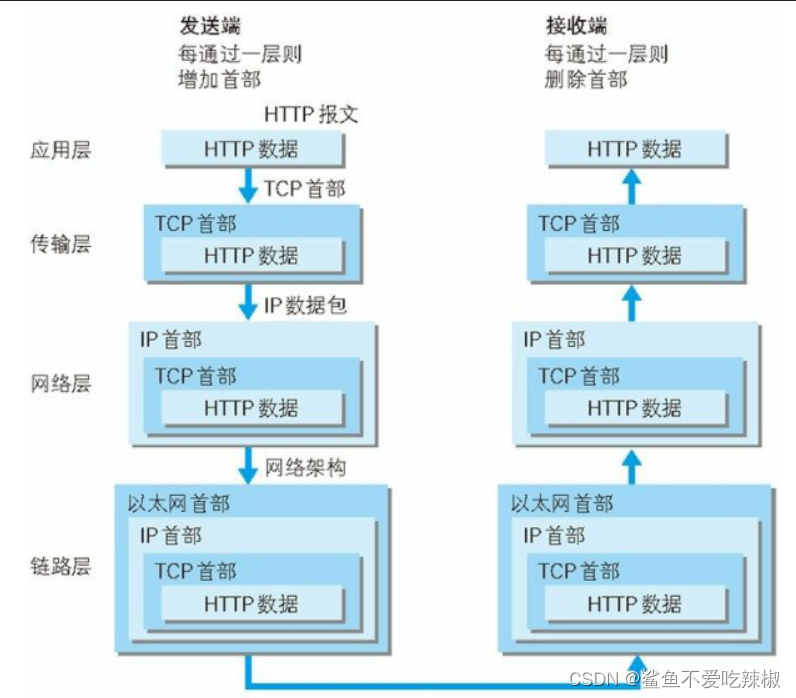
我们的大学教程大部分讲述七层模型,实际上现代网络协议使用的都是四层模型,如下图,应用层报文经过四层的首部封装到对端。对端链路层拆开首部查看mac地址是自己在网上,拆开ip首部查看目的地址是不是自己,然后到达传输层应用层完成报文接收。
# 基于TCP连接实现nginx网络性能优化
对于网络问题,我们可以使用tcpdump、ping、sar等指令排查
如下我们使用ping查看网络连通性
ping -c 3 192.168.12.128
们ping的服务器是上游服务器0% packet loss说明连通性没问题。
PING 192.168.12.128 (192.168.12.128) 56(84) bytes of data.
64 bytes from 192.168.12.128: icmp_seq=1 ttl=64 time=0.446 ms
64 bytes from 192.168.12.128: icmp_seq=2 ttl=64 time=4.33 ms
64 bytes from 192.168.12.128: icmp_seq=3 ttl=64 time=2.44 ms
--- 192.168.12.128 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2003ms
rtt min/avg/max/mdev = 0.446/2.409/4.336/1.588 ms
2
3
4
5
6
7
8
9
10
同样我们也可以使用sar来查看网络数据包的收发情况
sar -n DEV 1 3
输出结果如下:
Linux 3.10.0-1160.el7.x86_64 (localhost.localdomain) 07/24/2022 _x86_64_ (6 CPU)
06:11:22 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
06:11:23 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
06:11:23 PM virbr0-nic 0.00 0.00 0.00 0.00 0.00 0.00 0.00
06:11:23 PM virbr0 0.00 0.00 0.00 0.00 0.00 0.00 0.00
06:11:23 PM ens33 0.00 0.00 0.00 0.00 0.00 0.00 0.00
# 略
2
3
4
5
6
7
8
9
对应参数含义:
#IFACE 本地网卡接口的名称
#rxpck/s 每秒钟接受的数据包
#txpck/s 每秒钟发送的数据库
#rxKB/S 每秒钟接受的数据包大小,单位为KB
#txKB/S 每秒钟发送的数据包大小,单位为KB
#rxcmp/s 每秒钟接受的压缩数据包
#txcmp/s 每秒钟发送的压缩包
#rxmcst/s 每秒钟接收的多播数据包
2
3
4
5
6
7
8
9
10
11
如下所示通过netstat 这条指令可以看到网口的收发情况
netstat -I
RX-ERR/TX-ERR基本为0,说明网络质量良好
Kernel Interface table
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
ens33 1500 3393 0 0 0 2101 0 0 0 BMRU
lo 65536 1600 0 0 0 1600 0 0 0 LRU
virbr0 1500 0 0 0 0 0 0 0 0 BMU
2
3
4
5
6
7
# TCP内核参数详解
# net.ipv4.tcp_syn_retries
表示应用程序进行 connect() 系统调用时,在对方不返回 SYN + ACK 的情况下 (也就是超时的情况下),第一次发送之后,内核最多重试几次发送 SYN 包,并且决定了等待时间。
Linux 上的默认值是 net.ipv4.tcp_syn_retries = 6 ,也就是说如果是本机主动发起连接(即主动开启 TCP 三次握手中的第一个 SYN 包),如果一直收不到对方返回 SYN + ACK ,那么应用程序最大的超时时间就是 127 秒。
我们可以通过以下指令看到,他的默认值为6
cat /proc/sys/net/ipv4/tcp_syn_retries
6
2
3
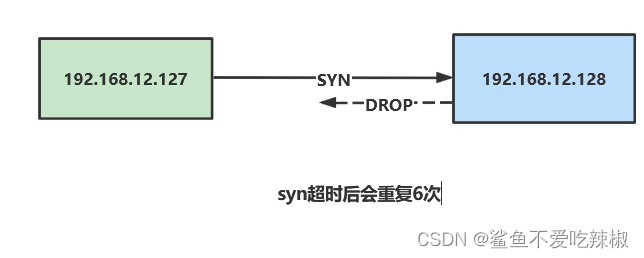
对此我们可以实验以下印证这个问题,128服务器将127的包drop掉,看看127这台服务器的请求会不会重试6次
首先我们开启一个终端抓一次127服务器的发送给128的HTTP包
tcpdump -i ens33 -nn 'dst 192.168.12.128 and tcp port 80'
然后设置128的服务器将127服务器的包丢弃
iptables -I INPUT -s 192.168.12.127 -j DROP
2
这时候127使用curl尝试连通
curl http://192.168.12.128
2
然后基于tcpdump进行监控:
tcpdump -i ens33 -nn 'dst 192.168.12.128 and tcp port 80'
实验结果最终为发现,确实超市重试了6次,每次超时等待时间都是上一次的2倍
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
19:35:02.372499 IP 192.168.12.127.41216 > 192.168.12.128.80: Flags [S], seq 3711897357, win 29200, options [mss 1460,sackOK,TS val 19661434 ecr 0,nop,wscale 7], length 0
# 超时重试6次
19:35:03.375342 IP 192.168.12.127.41216 > 192.168.12.128.80: Flags [S], seq 3711897357, win 29200, options [mss 1460,sackOK,TS val 19662436 ecr 0,nop,wscale 7], length 0
19:35:05.378852 IP 192.168.12.127.41216 > 192.168.12.128.80: Flags [S], seq 3711897357, win 29200, options [mss 1460,sackOK,TS val 19664440 ecr 0,nop,wscale 7], length 0
19:35:09.386363 IP 192.168.12.127.41216 > 192.168.12.128.80: Flags [S], seq 3711897357, win 29200, options [mss 1460,sackOK,TS val 19668448 ecr 0,nop,wscale 7], length 0
19:35:17.402651 IP 192.168.12.127.41216 > 192.168.12.128.80: Flags [S], seq 3711897357, win 29200, options [mss 1460,sackOK,TS val 19676464 ecr 0,nop,wscale 7], length 0
19:35:33.418587 IP 192.168.12.127.41216 > 192.168.12.128.80: Flags [S], seq 3711897357, win 29200, options [mss 1460,sackOK,TS val 19692480 ecr 0,nop,wscale 7], length 0
19:36:05.482794 IP 192.168.12.127.41216 > 192.168.12.128.80: Flags [S], seq 3711897357, win 29200, options [mss 1460,sackOK,TS val 19724544 ecr 0,nop,wscale 7], length 0
2
3
4
5
6
7
8
9
10
11
12
13
14
在网络情况良好的情况下,TCP连接完全不需要这么多次的重试,对此我们可以调小可以参数值
为了将这个值永久生效,我们需要编辑如下文件
vim /etc/sysctl.conf
2
添加一行
net.ipv4.tcp_syn_retries = 2
2
使用sysctl -p使之生效
[root@localhost run]# sysctl -p
# 可以看到这条命令会输出刚刚修改的内容
net.ipv4.tcp_syn_retries = 2
2
3
4
5
再次实验,可以看到127的抓包,仅仅重试了两次而已
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
20:33:43.041369 IP 192.168.12.127.41218 > 192.168.12.128.80: Flags [S], seq 2527903951, win 29200, options [mss 1460,sackOK,TS val 23182103 ecr 0,nop,wscale 7], length 0
# 重试了两次
20:33:44.043910 IP 192.168.12.127.41218 > 192.168.12.128.80: Flags [S], seq 2527903951, win 29200, options [mss 1460,sackOK,TS val 23183104 ecr 0,nop,wscale 7], length 0
20:33:46.046469 IP 192.168.12.127.41218 > 192.168.12.128.80: Flags [S], seq 2527903951, win 29200, options [mss 1460,sackOK,TS val 23185108 ecr 0,nop,wscale 7], length 0
2
3
4
5
6
7
8
# net.ipv4.tcp_synack_retries
当服务器接收到客户端发送的SYN连接请求报文后,回应SYNC+ACK报文,并等待客户端的ACK确认,如果超时会进行重传,重传次数由下列参数设置,默认为5
[root@localhost ~]# cat /proc/sys/net/ipv4/tcp_synack_retries
5
2
3
为了印证这一点,我们将将上文128的drop还原accept,将127收到的128的包drop掉
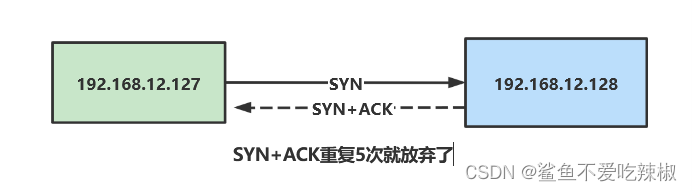
iptables -I INPUT -s 192.168.12.128 -j DROP
2
此时我们使用curl命令
[root@localhost run]# curl http://192.168.12.128
curl: (7) Failed connect to 192.168.12.128:80; Connection timed out
2
3
抓到128服务器的包发现果然重试了5次
# 在128服务器抓回给127服务器的包
[root@localhost ~]# tcpdump -i ens33 -nn 'dst 192.168.12.127 '
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
20:47:42.062075 IP 192.168.12.1.61588 > 192.168.12.127.22: Flags [P.], seq 3290041520:3290041568, ack 2422181631, win 4106, length 48
20:47:42.114303 IP 192.168.12.1.61588 > 192.168.12.127.22: Flags [.], ack 49, win 4106, length 0
20:47:42.587274 IP 192.168.12.1.61588 > 192.168.12.127.22: Flags [P.], seq 48:96, ack 49, win 4106, length 48
# 第一次
20:47:42.593961 IP 192.168.12.128.80 > 192.168.12.127.41224: Flags [S.], seq 806829342, ack 2654770401, win 28960, options [mss 1460,sackOK,TS val 23416004 ecr 24020034,nop,wscale 7], length 0
20:47:42.631701 IP 192.168.12.1.61588 > 192.168.12.127.22: Flags [.], ack 97, win 4105, length 0
# 超时重试第1次
20:47:43.595729 IP 192.168.12.128.80 > 192.168.12.127.41224: Flags [S.], seq 806829342, ack 2654770401, win 28960, options [mss 1460,sackOK,TS val 23417006 ecr 24020034,nop,wscale 7], length 0
# 超时重试第2次
20:47:43.595941 IP 192.168.12.128.80 > 192.168.12.127.41224: Flags [S.], seq 806829342, ack 2654770401, win 28960, options [mss 1460,sackOK,TS val 23417006 ecr 24020034,nop,wscale 7], length 0
# 超时重试第3次
20:47:45.596646 IP 192.168.12.128.80 > 192.168.12.127.41224: Flags [S.], seq 806829342, ack 2654770401, win 28960, options [mss 1460,sackOK,TS val 23419007 ecr 24020034,nop,wscale 7], length 0
# 超时重试第4次
20:47:45.599521 IP 192.168.12.128.80 > 192.168.12.127.41224: Flags [S.], seq 806829342, ack 2654770401, win 28960, options [mss 1460,sackOK,TS val 23419010 ecr 24020034,nop,wscale 7], length 0
20:47:46.907779 ARP, Request who-has 192.168.12.127 (00:0c:29:bd:2b:9e) tell 192.168.12.1, length 46
20:47:47.597905 ARP, Request who-has 192.168.12.127 tell 192.168.12.128, length 28
20:47:49.655826 IP 192.168.12.1.61588 > 192.168.12.127.22: Flags [.], ack 161, win 4105, length 0
# 超时重试第5次
20:47:49.998252 IP 192.168.12.128.80 > 192.168.12.127.41224: Flags [S.], seq 806829342, ack 2654770401, win 28960, options [mss 1460,sackOK,TS val 23423408 ecr 24020034,nop,wscale 7], length 0
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
127作为nginx服务器,为了避免没必要的开销,无论与上游服务器还是和客户之前synack重试次数实际上也不要这么大,完完全全可以调小些例如2
net.ipv4.tcp_synack_retries = 2
# net.ipv4.tcp_syncookies
该参数在Centos6、7已经默认为1,这个参数开启后不会将还为建立的tcp连接存到SYN队列中,而是响应一个ACK+算好的cookie值,只要对方发送SYN+ACK+cookie包后才会将其存到队列中,这样的设置可以避免syn洪泛攻击
[root@localhost ~]# cat /proc/sys/net/ipv4/tcp_syncookies
1
2
3
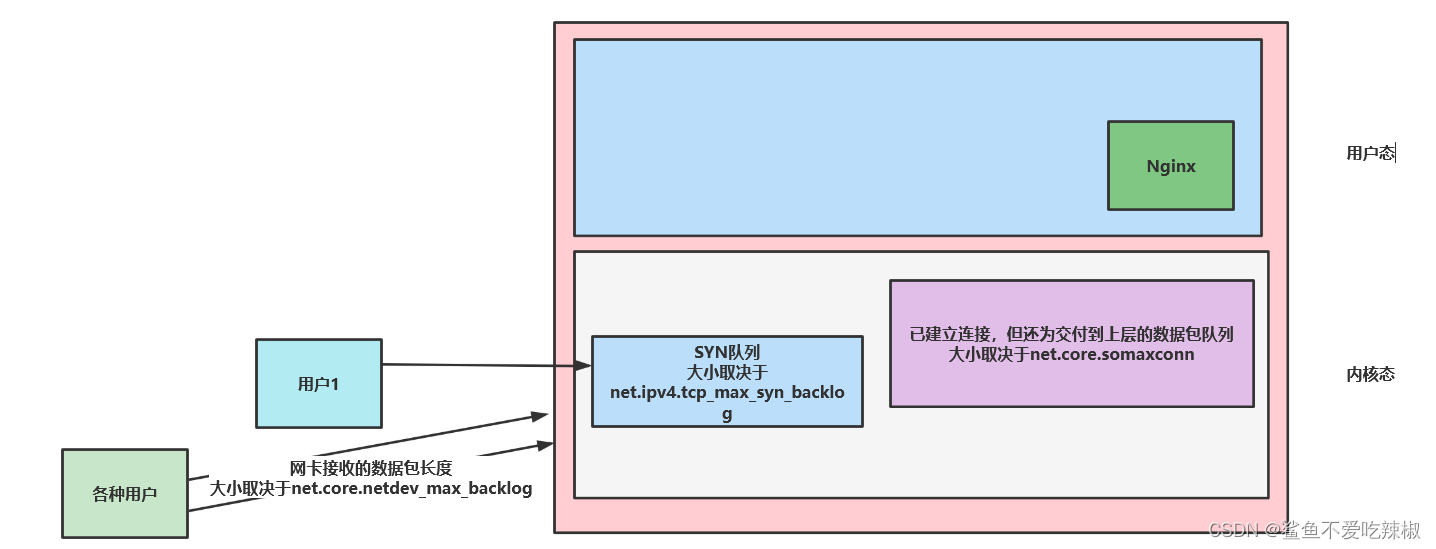
# net.core.netdev_max_backlog
net.core.netdev_max_backlog参数表示网卡接受数据包的队列最大长度,在阿里云服务器上,默认值是1000,可以适当调整。
# net.ipv4.tcp_max_syn_backlog
net.ipv4.tcp_max_syn_backlog参数决定已经收到syn包,但是还没有来得及确认的连接队列,这是传输层的队列,在高并发的情况下,必须调整该值,提高承载能力。
# net.core.somaxconn
net.core.somaxconn参数决定了端口监听队列的最大长度,存放的是已经处于ESTABLISHED而没有被用户程序(例如nginx)接管的TCP连接,默认是128,对于高并发的,或者瞬发大量连接,必须调高该值,否则会直接丢弃连接。
# 上述三个队列位置图解
可以看到在高并发的情况下这些参数都必须调大。我们建议的配置如下,可以看到net.core.somaxconn设置为65535因为操作系统内核允许完全建立的连接大小不能超过65535,而另外两个参数可以24800是因为这些连接是尚未建立连接的数据包,所以数量可以多一些
net.core.netdev_max_backlog = 24800
net.ipv4.tcp_max_syn_backlog = 24800
net.core.somaxconn = 65535
2
3
4
5
这时候我们就可以调整nginx的backlog,可以看到笔者设置为24800,虽然这个值已经大于操作系统的somaxconn 大小,但这并不会报错,相反这样的设置可以使得nginx尽可能的榨取队列资源。
listen 80 deferred backlog=24800 ;
2
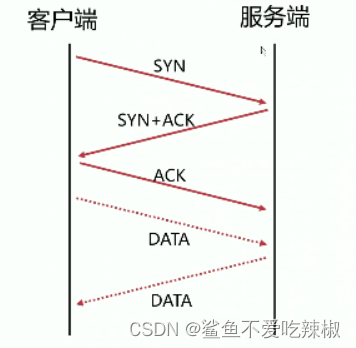
# TCP的Fast Open
该参数是用来加速TCP连接数据交互的TCP扩展协议,是Google在2011年论文提出的。 原有tcp协议三次握手以及数据交互如下图,必须完全建立连接后才能发送数据
而经过RFC优化之后的的TCP交互如下图,可以看到在最后一次确认的时候可以直接将请求数据携带过去
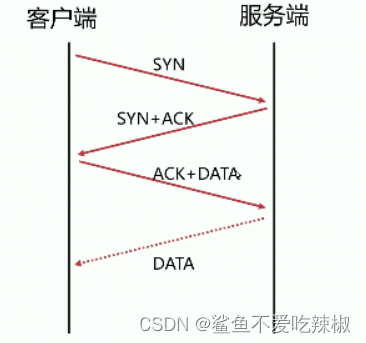
而TCP Fast Open在此基础上,新增一个特性,在建立TCP连接期间,服务端会发给用户一个cookie,当本次TCP连接断开后,用户可以使用这个cookie快速与服务端建立连接。这个机制很适合用于nginx服务器与上游服务器的交互。
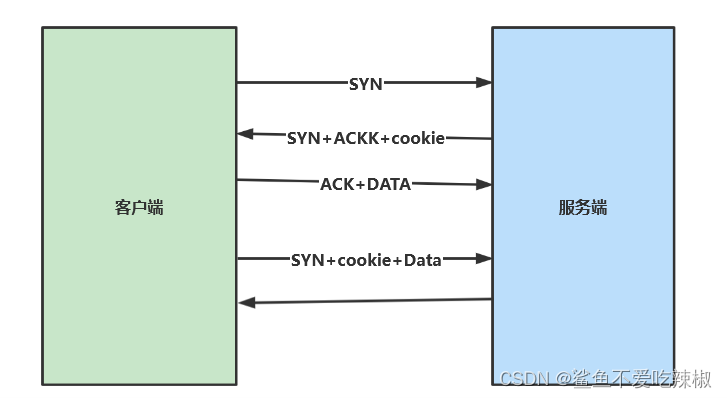
使用sysctl -a |grep tcp_fast即可看到这个值的默认值为0代表不开启TFO,1代表作为客户端时拥有TFO机制,2代表作为服务端才拥有TFO机制,3代表该服务器完全支持TFO机制。
[root@localhost ~]# sysctl -a |grep tcp_fast
net.ipv4.tcp_fastopen = 0
net.ipv4.tcp_fastopen_key = 00000000-00000000-00000000-00000000
2
3
4
所以我们建议nginx作为服务器的情况下可以开启TFO,参数可以设置为
net.ipv4.tcp_fastopen = 2
# 总结
文章是基于原有个人知识基础上,对旧知识进行巩固,以及新知识实践学习。对于基于操作系统的优化亦或者其他知识,我们在学习过程中势必会遇到很多陌生的概念,我们切不可急躁,善于使用搜索引擎以及原有积累的知识去理解每一个概念,将参考文献补充完善,以便于后续回顾以及后续遇到相同场景我们可以快速完成问题的解决。这就是学习的技巧——突破学习材料瓶颈,打破学习材料的局限性,完成技术栈的学习。
# 参考文献
Why not use "deferred" on nginx server block listen line? :https://community.centminmod.com/threads/why-not-use-deferred-on-nginx-server-block-listen-line.2711/ (opens new window)
nginx主配置调优之worker_priority:https://blog.csdn.net/weixin_45937255/article/details/115212834 (opens new window)
Linux的进程优先级 Nice 和 priority:https://blog.51cto.com/frankch/1773621 (opens new window)
Linux进程优先级:https://blog.51cto.com/moerjinrong/2092371 (opens new window)
(推荐)linux下修改内核参数进行Tcp性能调优 — 高并发:https://www.msnao.com/2020/08/23/4161.html#:~:text=net.core.netdev_max_backlog 参数表示网卡接受数据包的队列最大长度,在阿里云服务器上,默认值是1000,可以适当调整。,2. net.core.somaxconn (opens new window)
