 内存深度解析
内存深度解析
[toc]
# 引言
在Java开发中,我们经常关注JVM内存管理、垃圾回收等高层概念,但要真正理解程序性能瓶颈和优化方向,有必要深入了解底层硬件的工作原理。本文将带您深入计算机内存的底层世界,从最基本的DRAM和SRAM存储单元工作原理开始,逐步介绍内存条的物理结构,探讨CPU与内存的交互机制,最后分析多核环境下NUMA架构对内存访问性能的影响及优化策略。
无论您是希望提升系统性能的Java开发者,还是对计算机底层原理感兴趣的程序员,相信本文都能为您提供有价值的技术洞察。
我是 SharkChili ,Java 开发者,Java Guide 开源项目维护者。欢迎关注我的公众号:写代码的SharkChili,也欢迎您了解我的开源项目 mini-redis:https://github.com/shark-ctrl/mini-redis。
为方便与读者交流,现已创建读者群。关注上方公众号获取我的联系方式,添加时备注加群即可加入。
# 详解内存DRAM存储
计算机的世界是0和1,所以表达数据的方式都是采用0和1构成。我们先来介绍内存是如何表达和存储这些数据的。按照专业领域的说法,内存主要是DRAM(Dynamic Random Access Memory,动态随机存取存储器)技术,本质是通过电容和MOS晶体管构成一个DRAM存储单元。当需要使用这些DRAM单元表达数据时,字线(Word Line)会发出信号,从而导通晶体管,就能进行数据的读写操作:
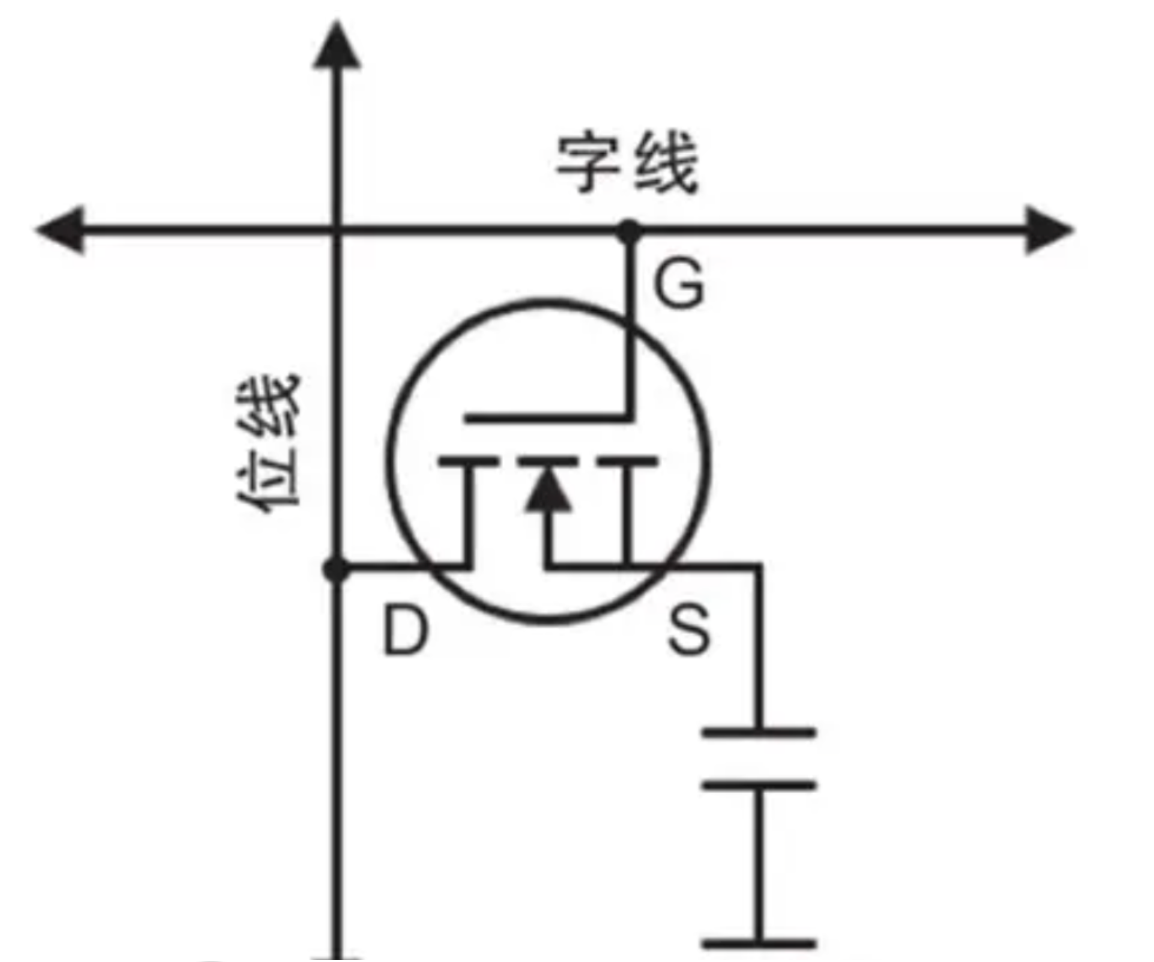
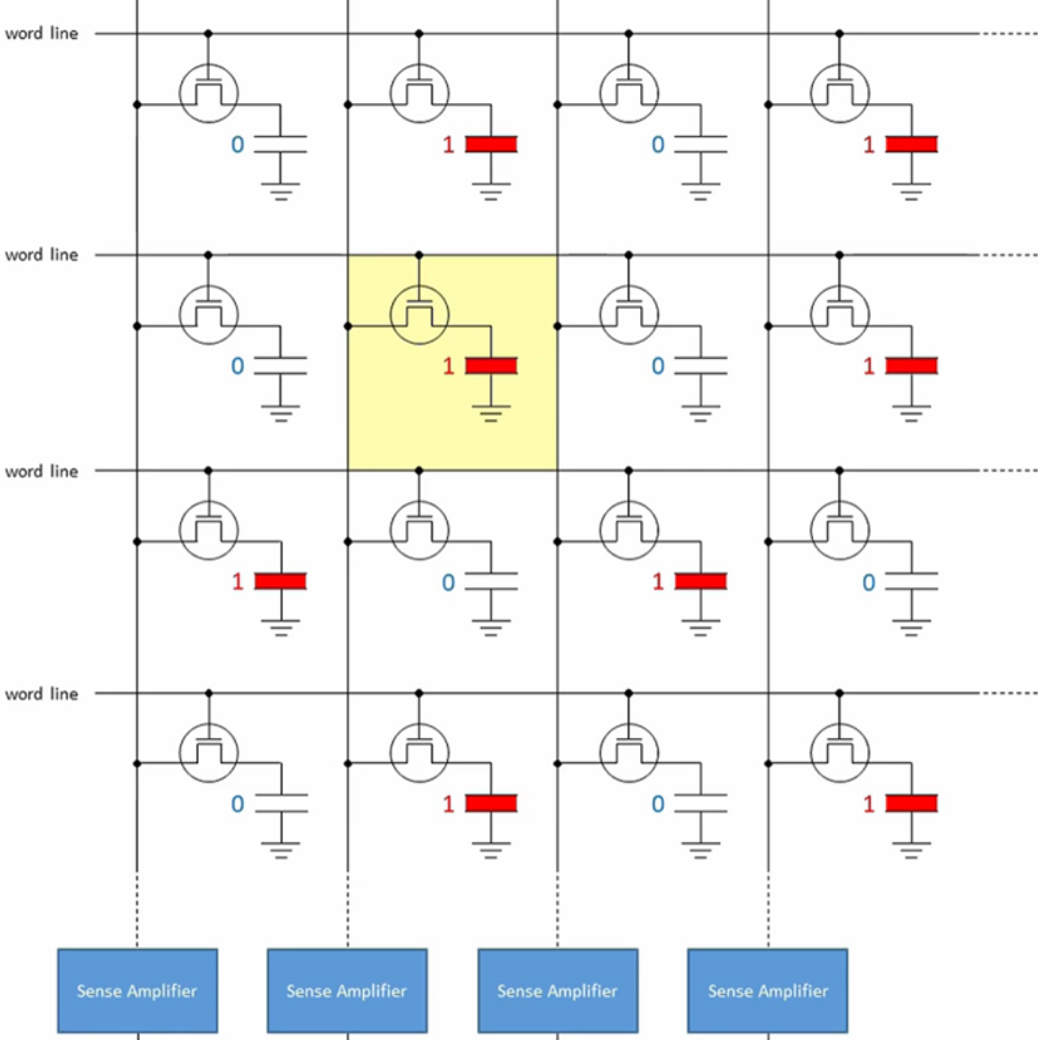
由此地址译码电路根据译码生成的地址定位到指定的DRAM单元,构成二进制数并生成相应的数据。同时也因为电容会逐渐漏电的原因,内存必须定期进行刷新操作来维持这份数据,否则内存数据就会丢失,这也就是为什么内存被称为动态随机存取存储器(需要动态刷新):
# 详解缓存SRAM存储
而CPU的缓存则是采用更精确的SRAM(Static Random Access Memory,静态随机存取存储器)技术,即通过电路设计来保证电流维持在一个稳定的循环电路中,无需定期刷新即可长期存储数据。
对应的我们给出sram的电路,如下所示,我们先来介绍一下它是如何存储1的:
- 当WL(Word Line)字线接收到高电平信号时,对应的NMOS管N3和N4导通,此时BL(Bit Line)和BLB(Bit Line Bar)的信号就可以通过这两个管子输入
- 此时,假设左边的BL是我们的输入端,我们输入1,通过导通的N3管子,信号传递到P2和N2,对应N2为NMOS管且导通接地,所以输出为0,P2导通(P型管在栅极为低电平时导通)
- 对应BLB输入的是与BL数值相反的0,通过导通的N4管子与上述的0相遇,0与0仍然是0
- 此时步骤3生成的0通过电路传递到对端的P1和N1,因为输入值为0,所以P1导通(P1连接电源),输出变为1,N1截止,此时的1与N3的1保持一致,形成稳定的存储状态。
为了存储这份数据,我们在完成上述的写入操作后,将WL(Word Line)变为低电平,使N3、N4截止,这样电流就维持在由P1、N1、P2、N2构成的稳定环路之间,从而无需持续通电即可保持数据。后续如果需要读取这份数据,我们也只需重新给WL加高电平导通电路,通过检测BL或BLB的电平状态即可知晓电路内存储的值。
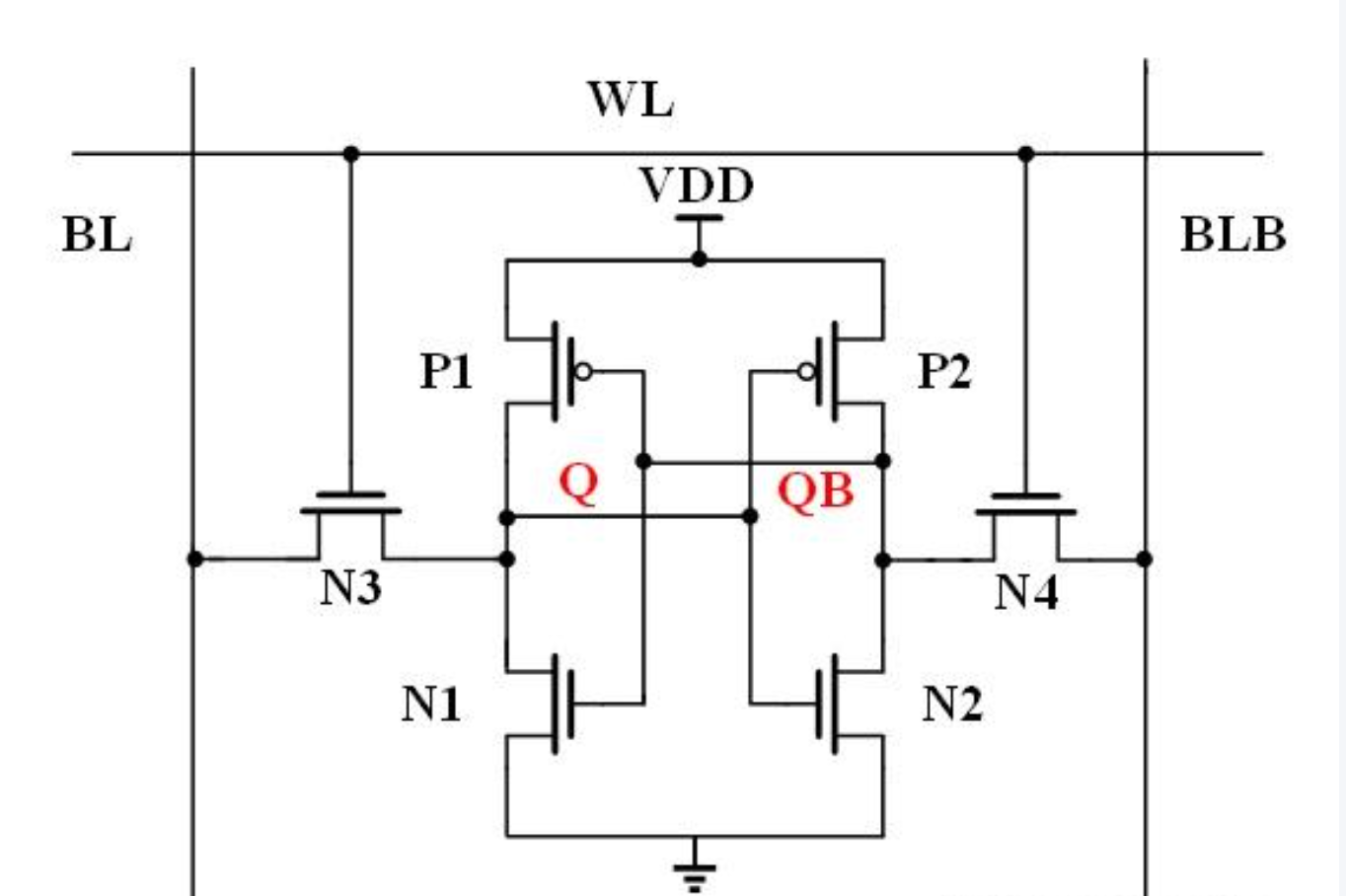
同理,如果BL输入的是0,那么信号传递到对端就会变为1,与BLB的1相遇后保持为1,而BLB的1传递到P1和N1后变为0,然后将WL电路关闭,再次形成稳定的存储状态,最终通过检测BL或BLB的电平状态就知道这个电路存储的是0。
缓存正是通过无数个这种电路来存储每个数值。由于SRAM电路的复杂性以及每存储1bit数据就需要耗费6个晶体管,所以缓存无法像DRAM那样构建大容量的存储阵列,这也是为什么CPU缓存容量相对较小的原因。
# 详解内存条
# 内存条基本结构
内存条是计算机运转的关键组件,因为CPU工作需要的指令和数据都需要通过内存来传输。内存条基本结构如下图所示,主要包括以下几个部分:
- 黑色的存储芯片即Bank,是内存条的核心存储部件。不同容量的内存条具有不同数量的存储芯片,具体的存储容量取决于芯片的规格和数量
- 脚下的一排金色部分是金手指,即连接主板插槽的接触点。不同代际的内存条(如DDR3、DDR4、DDR5)具有不同数量的金手指,同时为了避免正反面的混淆,金手指还在特定位置设置了一个缺口用于区分

# 内存如何存储数据
内存在发展初期统一称为RAM(Random Access Memory,随机存取存储器),即支持随机读写数据。存储二进制bit的方案有上述的SRAM和DRAM两种技术。为了节约成本,大容量内存通常采用DRAM技术,这种方式的晶体管结构相对简单,但存在电容漏电的缺陷,所以需要周期性刷新(通常每隔64ms以内)来保证电容持续保持当前的电荷状态,从而记录二进制数值0或者1。
# 内存如何与CPU交互
内存条读写数据时需要提供芯片Bank号、行地址、列地址才能定位到具体的存储单元进行读写操作。为了减轻CPU的管理负担,引入了内存控制器。内存控制器将8bit看作一个整体,也就是我们常说的字节,并负责CPU与内存条之间的地址转换。后续需要读写指定地址数据时,CPU只需将地址信息交给内存控制器,由内存控制器基于该地址定位到指定Bank、行地址、列地址上的具体存储单元进行读写操作。
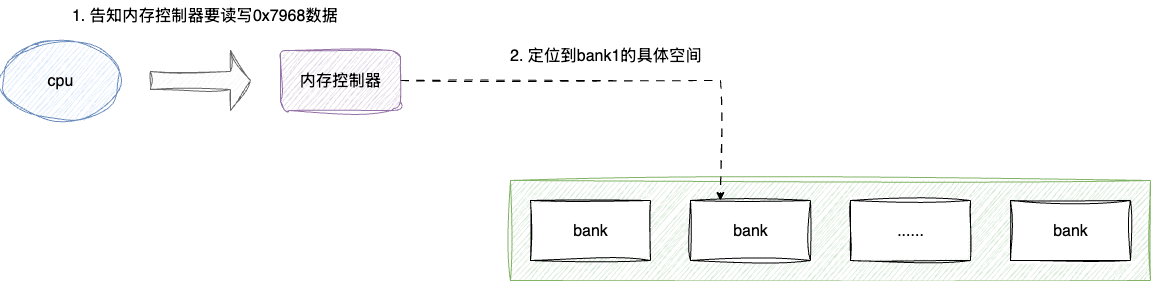
随着技术发展,内存控制器也集成到了CPU中。同时考虑到CPU和内存之间的速率不匹配问题,引入了缓存机制。因此,内存控制器只有在缓存未命中、需要从内存读取数据时才会工作,由此CPU和内存之间的整体通信效率大大提升。
# 多核场景下的内存访问效率的优化
# 多核访问的竞态和NUMA架构
随着技术的发展,CPU核心数不断增加,从早期的双核、四核发展到现在的十六核甚至更多,多核心进行内存访问时都需要经过内存控制器,这就势必出现并发竞态进而演变出新的性能瓶颈,所以如何提升CPU内存访问的效率,成为了新的课题:
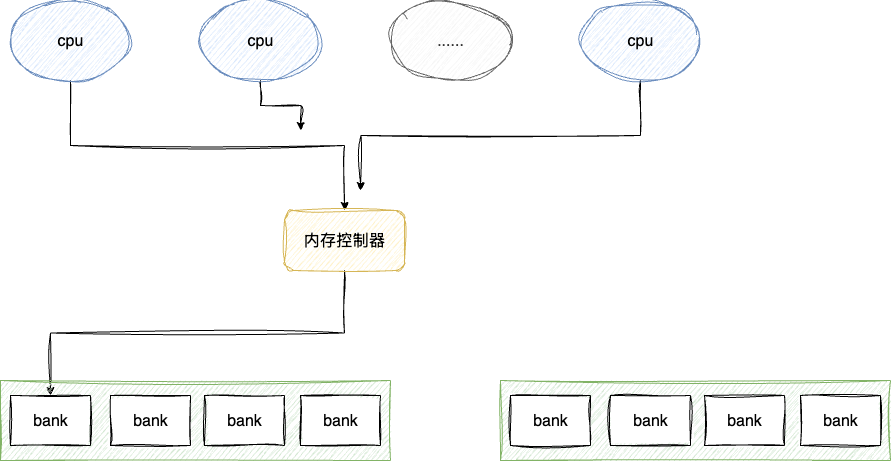
本着计算机哲学,面对竞争可以通过水平切割来降低多核之间竞争的压力,这一点在编程语言层面的ConcurrentHashMap或者数据库层面的分库分表都有着良好的应用,于是设计者就提出将cpu分组各自访问一部分的内存,当访问的内存不在当前组的时候则发送通知交给另外一组cpu处理:
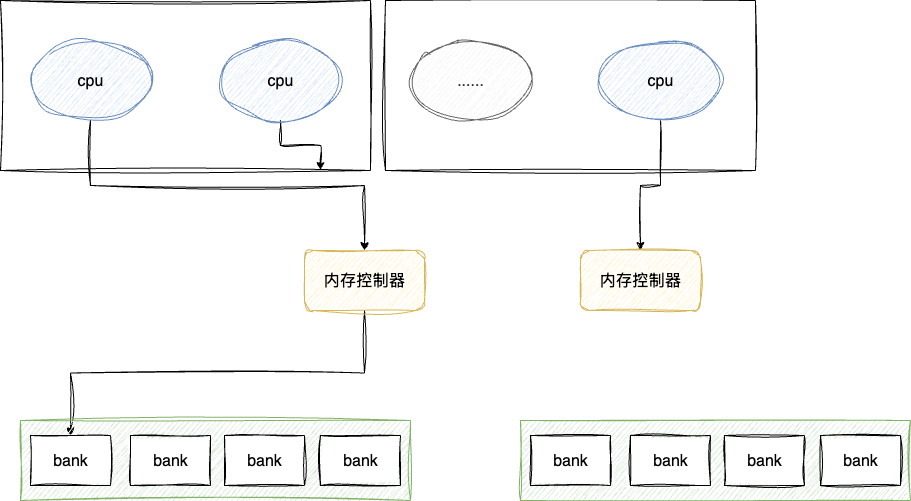
于是就有了NUMA架构的概念,其本质就是:
- 将多核cpu拆成两个部分,构成两个NUMA节点
- 每个节点访问一部分内存,这种访问方式叫做本地访问(local access)
- 当的数据在另一端内存时,则通知高速互联网络(如 Intel 的 QPI、AMD 的 Infinity Fabric 或 PCIe)连接对端的NUMA节点进行处理并返回,也就是远程访问(remote access)
不难看出,本地访问因为直接通过本段内存控制器进行数据读写效率自然高效,但是远程访问时涉及inter- connect通道访问通知对端内存控制器处理,涉及的链路更多耗时自然更久。
# 操作系统在NUMA架构上的优化
引入NUMA架构后,同一条线程的执行会被不同NUMA节点下的CPU执行,这就出现一个缓存失效的问题,这就导致线程的执行涉及多次的内存访问,效率大大降低:
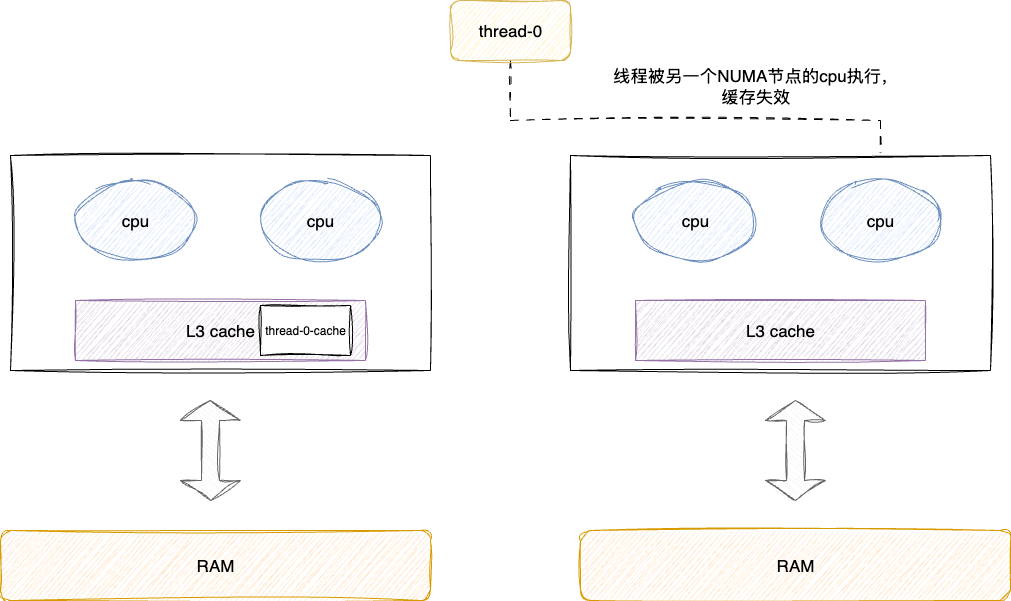
所以操作系统就对此进行优化,要求线程初次被那组NUMA节点的cpu访问后续就全部交由本组执行,通过CPU亲合力避免局部性遭到破坏。
# 内存占用偏斜问题
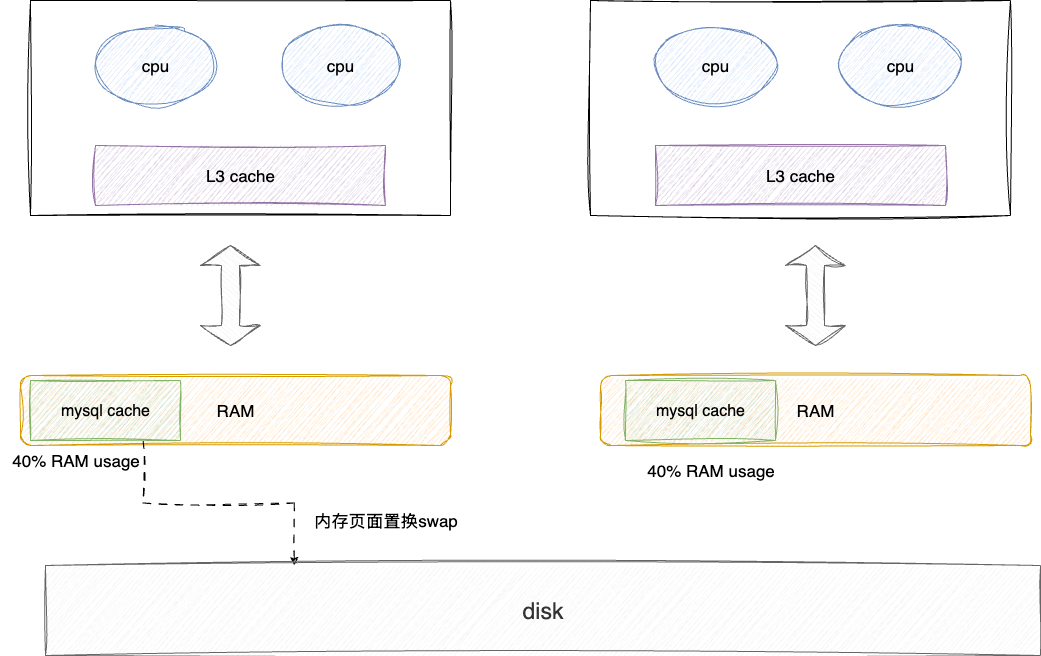
基于cpu亲和的设计理念又衍生了一个新的问题,操作系统启动加载MySQL之类的大进程时,为保证cpu亲和力和执行的高效性,将MySQL的数据全往一边内存灌、所有的读写,缓存swap置换都在这组NUMA。而另一边的内存利用率却不高,即整体资源利用率不高,所以操作系统对此问题进行了更进一步的优化,牺牲一部分性能表现,将大进程均匀的分摊到不同的内存中,避免内存占用偏斜的问题:
# 小结
本文从底层硬件原理出发,系统性地介绍了计算机内存的相关知识。我们首先深入探讨了DRAM和SRAM两种核心存储技术的工作原理和各自特点,然后分析了内存条的物理结构和数据存储机制,接着阐述了CPU与内存之间的交互方式,最后重点剖析了多核环境下NUMA架构的设计理念及其带来的性能挑战与优化策略。
通过本文的学习,相信您对计算机内存系统有了更深入的理解,这将有助于您在Java开发中更好地进行性能分析和优化工作。理解这些底层原理,能够帮助我们编写出更高效的代码,合理利用系统资源,提升应用程序的整体性能。
我是 SharkChili ,Java 开发者,Java Guide 开源项目维护者。欢迎关注我的公众号:写代码的SharkChili,也欢迎您了解我的开源项目 mini-redis:https://github.com/shark-ctrl/mini-redis。
为方便与读者交流,现已创建读者群。关注上方公众号获取我的联系方式,添加时备注加群即可加入。
# 参考
SRAM:SRAM入门指南与工作原理:https://blog.csdn.net/weixin_42896509/article/details/144434278 (opens new window) SRAM学习教程1——6T SRAM存储单元基础入门:https://zhuanlan.zhihu.com/p/1893683152792318881 (opens new window)
