 LinkedHashMap源码到面试题的全解析
LinkedHashMap源码到面试题的全解析
# 写在文章开头
在 Java 集合框架中,LinkedHashMap 是一个非常重要的数据结构,它不仅具备 HashMap 的高效性能,还保留了插入顺序或访问顺序的特性。这对于许多实际应用场景来说是非常有价值的。本文将深入探讨 LinkedHashMap 的内部实现机制,并通过详细的源码分析帮助读者理解其工作原理。此外,我们还将介绍一些常见的面试题及其解答,以帮助读者更好地准备技术面试。
Hi,我是 sharkChili ,是个不断在硬核技术上作死的技术人,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。

# LinkedHashMap简介
LinkedHashMap是Java提供的一个集合类,它继承自HashMap,并在HashMap基础上维护一条双向链表,使得具备如下特性:
- 支持遍历时会按照插入顺序有序进行迭代。
- 支持按照元素访问顺序排序,适用于封装
LRU缓存工具。 - 因为内部使用双向链表维护各个节点,所以遍历时的效率和元素个数成正比,相较于和容量成正比的
HashMap来说,迭代效率会高很多。
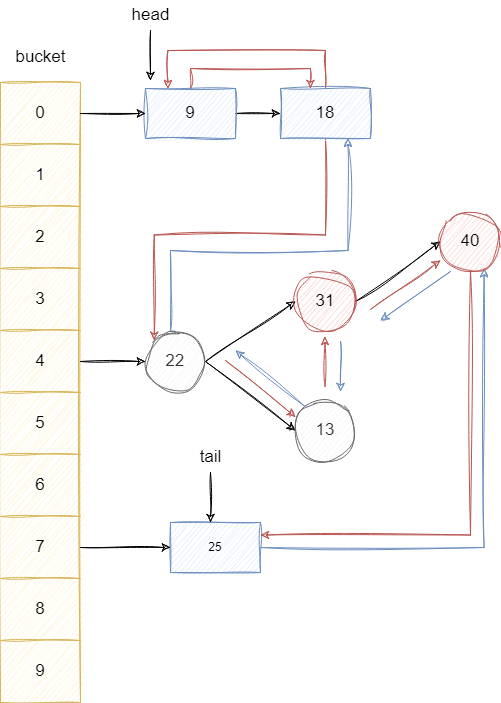
LinkedHashMap逻辑结构如下图所示,它是在HashMap基础上在各个节点之间维护一条双向链表,使得原本散列在不同bucket上的节点、链表、红黑树有序关联起来。
# LinkedHashMap使用示例
# 顺序遍历
如下所示,我们按照顺序往LinkedHashMap添加元素然后进行遍历。
HashMap<String,String> map=new LinkedHashMap<>();
map.put("a","2");
map.put("g","3");
map.put("r","1");
map.put("e","23");
map.put("h","54");
map.put("j","22");
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println(entry.getKey()+":"+entry.getValue());
}
2
3
4
5
6
7
8
9
10
11
输出结果如下,可以看出,LinkedHashMap的迭代顺序是和插入顺序一致的,这一点是HashMap所不具备的。
a:2
g:3
r:1
e:23
h:54
j:22
2
3
4
5
6
# 最近最少访问优先
再来看看这段代码,我们将accessOrder设置为true,使之具备访问有序性,随后我们顺序插入key为1、2、3的键值对,再访问一次key为2的键值对。
LinkedHashMap<Integer, String> map = new LinkedHashMap<>(16, 0.75f, true);
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
System.out.println(map.get(2)); // 访问元素2,元素2会被移动到链表末端
for (Map.Entry<Integer, String> entry : map.entrySet()) {
System.out.println(entry.getKey() + " : " + entry.getValue());
}
2
3
4
5
6
7
8
9
10
从输出结果来看,将accessOrder设置为true的LinkedHashMap排序时会按照最近最少访问(LRU)进行元素迭代,所以当我们访问key为2的键值对之后,该键值对就会被移动至链表末端,所以迭代顺序才变为1、3、2。
two
1 : one
3 : three
2 : two
2
3
4
# LRU(Least Recently Used)缓存
从上一个我们可以了解到通过LinkedHashMap我们可以封装一个LRU缓存,确保当存放的元素超过容器容量时,将最近最少访问的元素移除。

代码如下所示,可以看到笔者封装了一个LRUCache并继承LinkedHashMap,构造函数初始化容量之后,将accessOrder设置为true。并且笔者重写了removeEldestEntry方法,该方法会返回一个boolean值,告知LinkedHashMap是否需要移除链表首元素,因为我们将accessOrder设置为true,所以首元素就是最近最少访问的元素,由此我们的LRU缓存就封装完成了。
public class LRUCache<K, V> extends LinkedHashMap<K, V> {
private final int capacity;
public LRUCache(int capacity) {
super(capacity, 0.75f, true);
this.capacity = capacity;
}
/**
* 判断size超过容量时返回true,告知LinkedHashMap移除最近最少访问的元素(即链表的第一个元素)
* @param eldest
* @return
*/
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > capacity;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
测试代码如下,笔者初始化缓存容量为2,然后按照次序先后添加4个元素。
public static void main(String[] args) {
LRUCache<Integer, String> cache = new LRUCache<>(2);
cache.put(1, "one");
cache.put(2, "two");
cache.put(3, "three");
System.out.println(cache.get(1)); // 输出null
cache.put(4, "four");
System.out.println(cache.get(2)); // 输出null
System.out.println(cache.get(3)); // 输出"three"
}
2
3
4
5
6
7
8
9
10
11
12
13
14
从输出结果来看,添加3时,因为缓存size为2,于是将key为1的键值对删除了,所以第一次输出为null。同理我们再次添加4,size超过了容量大小,将2移除,所以输出的key为2的键值对为null,而键值对为3的输出结果为three。
null
null
three
2
3
# LinkedHashMap源码解析
# Node的设计
在正式讨论LinkedHashMap前,我们先来聊聊LinkedHashMap节点Entry的设计,我们都知道HashMap的bucket上的因为冲突转为链表的节点会在符合以下两个条件时会将链表转为红黑树:
- 链表上的节点个数达到树化的阈值-1,即
TREEIFY_THRESHOLD - 1。 bucket的容量达到最小的树化容量即MIN_TREEIFY_CAPACITY。
而LinkedHashMap是在HashMap的基础上为bucket上的每一个节点建立一条双向链表,这就使得转为红黑树的树节点也需要具备双向链表节点的特性,即每一个树节点都需要拥有两个引用存储前驱节点和后继节点的地址,所以对于树节点类TreeNode的设计就是一个比较棘手的问题。
对此我们不妨来看看两者之间节点类的类图,可以看到:
LinkedHashMap的节点内部类Entry基于HashMap的基础上,增加before和after指针使节点具备双向链表的特性。HashMap的树节点TreeNode继承了具备双向链表特性的LinkedHashMap的Entry。
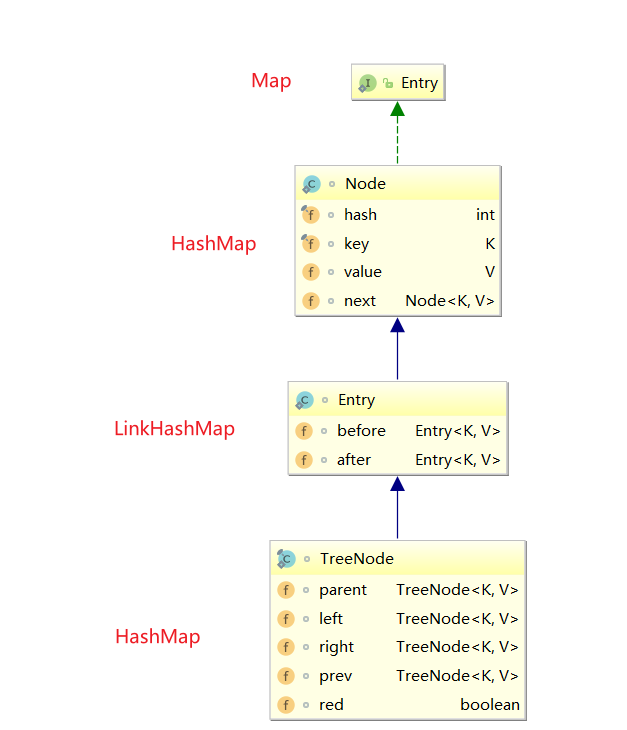
很多读者此时就会有这样一个疑问,为什么HashMap的树节点TreeNode要通过LinkedHashMap获取双向链表的特性呢?为什么不直接在Node上实现前驱和后继指针呢?
先来回答第一个问题,我们都知道LinkedHashMap是在HashMap基础上对节点增加双向指针实现双向链表的特性,所以LinkedHashMap内部链表转红黑树时,对应的节点会转为树节点TreeNode,为了保证使用LinkedHashMap时树节点具备双向链表的特性,所以树节点TreeNode需要继承LinkedHashMap的Entry。
再来说说第二个问题,我们直接在HashMap的节点Node上直接实现前驱和后继指针,然后TreeNode直接继承Node获取双向链表的特性为什么不行呢?其实这样做也是可以的。只不过这种做法会使得使用HashMap时存储键值对的节点类Node多了两个没有必要的引用,占用没必要的内存空间。
所以为了保证HashMap底层的节点类Node没有多余的引用,又要保证LinkedHashMap的节点类Entry拥有存储链表的引用,设计者就让LinkedHashMap的节点Entry去继承Node并增加存储前驱后继节点的引用before、after,让需要用到链表特性的节点去实现需要的逻辑。然后树节点TreeNode再通过继承Entry获取before、after两个指针。
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
2
3
4
5
6
但是这样做,不也使得使用HashMap时的TreeNode多了两个没有必要的引用吗?这不也是一种空间的浪费吗?
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
//略
}
2
3
4
对于这个问题,引用作者的一段注释,作者们认为在良好的hashCode算法时,HashMap转红黑树的概率不大。就算转为红黑树变为树节点,也可能会因为移除或者扩容将TreeNode变为Node,所以TreeNode的使用概率不算很大,对于这一点资源空间的浪费是可以接受的。
Because TreeNodes are about twice the size of regular nodes, we
use them only when bins contain enough nodes to warrant use
(see TREEIFY_THRESHOLD). And when they become too small (due to
removal or resizing) they are converted back to plain bins. In
usages with well-distributed user hashCodes, tree bins are
rarely used. Ideally, under random hashCodes, the frequency of
nodes in bins follows a Poisson distribution
2
3
4
5
6
7
# 构造方法
LinkedHashMap构造方法有4个实现也比较简单,直接调用父类即HashMap的构造方法完成初始化,在设置accessOrder ,默认情况下accessOrder 为false,所以假如我们若要LinkedHashMap实现键值对按照访问顺序排序(即将最近最少访问的元素排在链表首部、最近访问的元素移动到链表尾部),需要下述构造方法将accessOrder 设置为true。
//accessOrder设置为true,保证访问过的节点,会直接移动到链表末端
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
2
3
4
5
6
7
8
# get方法
get方法是LinkedHashMap增删改查操作中唯一一个重写的方法,它会在元素查询完成之后,将当前访问的元素移到链表的末尾。
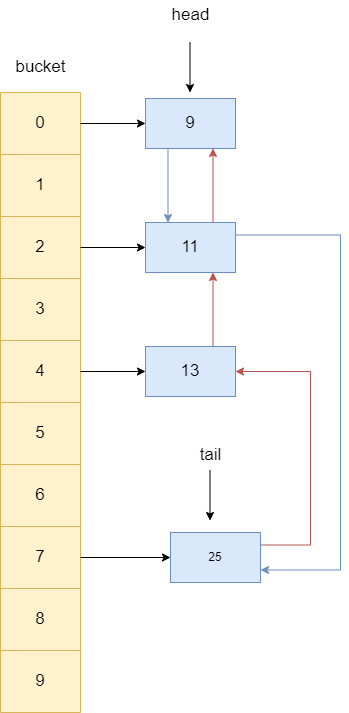
我们就以下面这张图为例,我们的双向链表指向前驱节点的指针为红色,指向后继节点的指针为蓝色,演示一下访问key为13(后文统称为13)的元素后LinkedHashMap的如何将其移动至链表尾部。
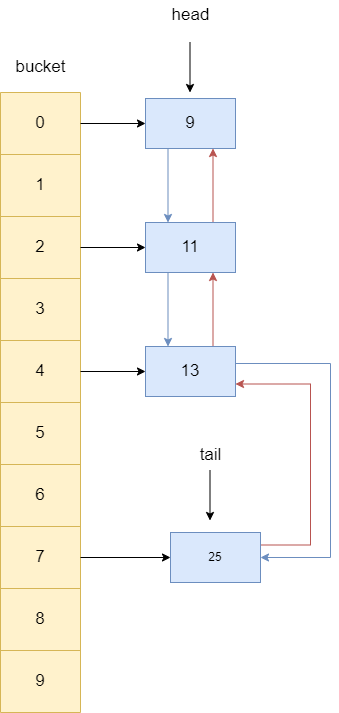
当我们访问LinkedHashMap中key为13的元素时,双向链表首先会将13的后继指针指向null,所以笔者这里索性将指针删除。
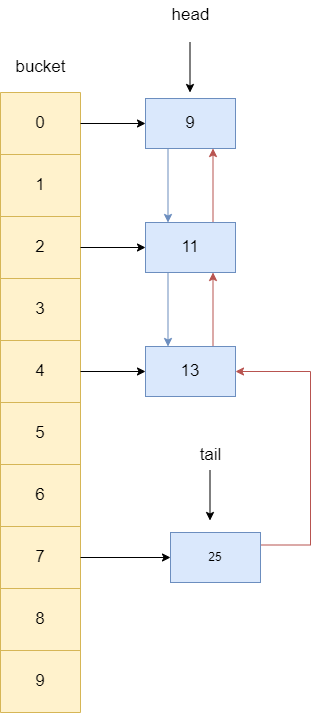
随后,查看13是否有前驱节点,发现其前驱节点是一个key为11的节点,故让11直接指向13的后继节点25。
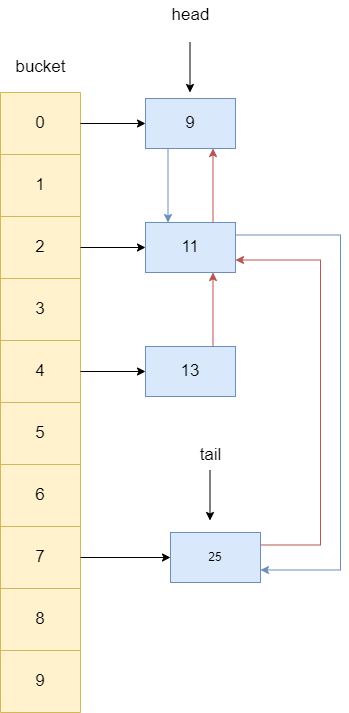
同理,如果13的后继节点不为空,也让其指向13的前驱节点,所以25的前驱指针指向11。
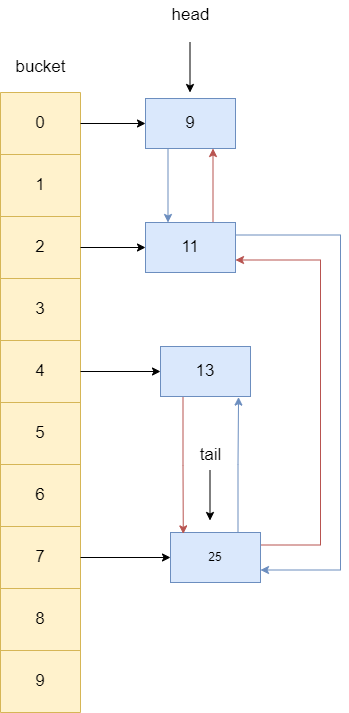
回到13节点,如果它发现双向链表存在尾节点,则将自己的前驱指针指向尾节点,而尾节点也会将前驱指针指向13。
最终链表的指向尾节点的指针tail指向13,由此完成将访问过的节点移动至链表尾部。
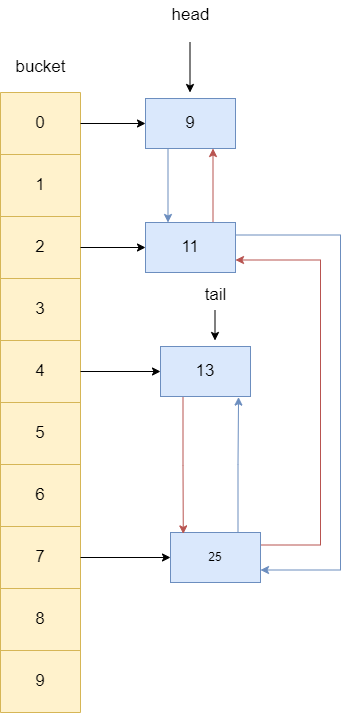
通过图解我们大抵了解了LinkedHashMap访问后置的流程,接下来我们从get方法的源码为入口复盘一下上述的操作,get的执行步骤为:
- 调用父类即
HashMap的getNode获取键值对,若为空则直接返回。 - 判断
accessOrder是否为true,若为true则说明需要保证LinkedHashMap的链表访问有序性,执行步骤3。 - 调用
LinkedHashMap重写的afterNodeAccess将当前元素添加到链表末尾。
public V get(Object key) {
Node<K,V> e;
//获取key的键值对,若为空直接返回
if ((e = getNode(hash(key), key)) == null)
return null;
//若accessOrder为true,则调用afterNodeAccess将当前元素移到链表末尾
if (accessOrder)
afterNodeAccess(e);
//返回键值对的值
return e.value;
}
2
3
4
5
6
7
8
9
10
11
上文提到保证访问有序的调用方法afterNodeAccess,从源码中我可以看到它完成的操作:
- 如果
accessOrder为true且链表尾部不为当前节点p,我们则需要将当前节点移到链表尾部。 - 获取当前节点p、以及它的前驱节点b和后继节点a。
- 将当前节点p的后继指针设置为null,使其和后继节点p断开联系。
- 尝试将前驱节点指向后继节点,若前驱节点为空,则说明当前节点p就是链表首节点,故直接将后继节点a设置为首节点,随后我们再将p追加到a的末尾。
- 再尝试让后继节点a指向前驱节点b。
- 上述操作让前驱节点和后继节点完成关联,并将当前节点p独立出来,这一步则是将当前节点p追加到链表末端,如果链表末端为空,则说明当前链表只有一个节点p,所以直接让head指向p即可。
- 上述操作已经将p成功到达链表末端,最后我们将tail指针即指向链表末端的指针指向p即可。
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
//如果accessOrder 且当前节点不未链表尾节点
if (accessOrder && (last = tail) != e) {
//获取当前节点、以及前驱节点和后继节点
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
//将当前节点的后继节点指针指向空,使其和后继节点断开联系
p.after = null;
//如果前驱节点为空,则说明当前节点是链表的首节点,故将后继节点设置为首节点
if (b == null)
head = a;
else
//如果后继节点不为空,则让前驱节点指向后继节点
b.after = a;
//如果后继节点不为空,则让后继节点指向前驱节点
if (a != null)
a.before = b;
else
//如果后继节点为空,则说明当前节点在链表最末尾,直接让last 指向前驱节点,这个 else其实 没有意义,因为最开头if已经确保了p不是尾结点了,自然after不会是null
last = b;
//如果last为空,则说明当前链表只有一个节点p,则将head指向p
if (last == null)
head = p;
else {
//反之让p的前驱指针指向尾节点,再让尾节点的后继指针after指向p
//即
p.before = last;
last.after = p;
}
//tail指向p,自此将节点p移动到链表末尾
tail = p;
++modCount;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# remove方法后置操作——afterNodeRemoval
LinkedHashMap并没有对remove方法进行重写,而是直接继承HashMap的remove方法,为了保证键值对移除后双向链表中的节点也会同步被移除,LinkedHashMap重写了HashMap的空实现方法afterNodeRemoval。
我们还是以这个链表为例,来演示一下在LinkedHashMap的afterNodeRemoval方法如何将已和bucket断开联系的节点13从链表中移除。
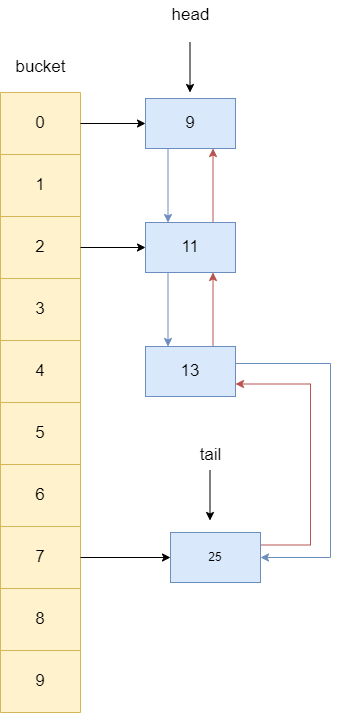
首先将13的前驱和后继指针指置空,确保被删节点和其他节点断开联系。
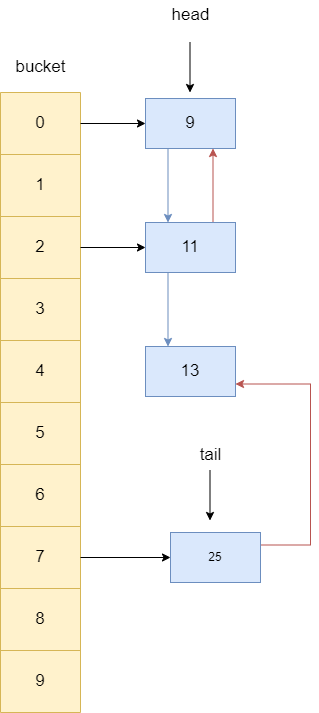
判断13是否有前驱节点,如果有则将其后继指针指向13的后继节点,让其与13断开联系,所以前驱节点11指向了25。
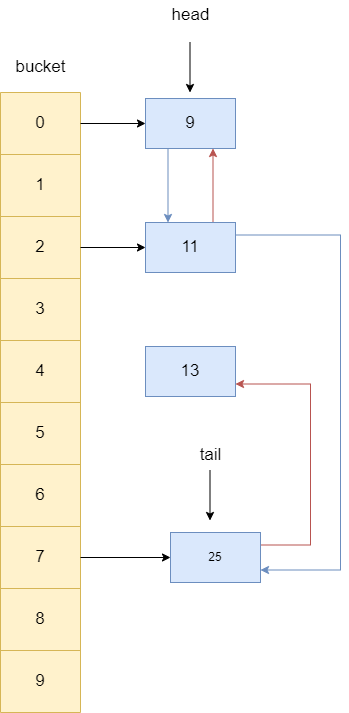
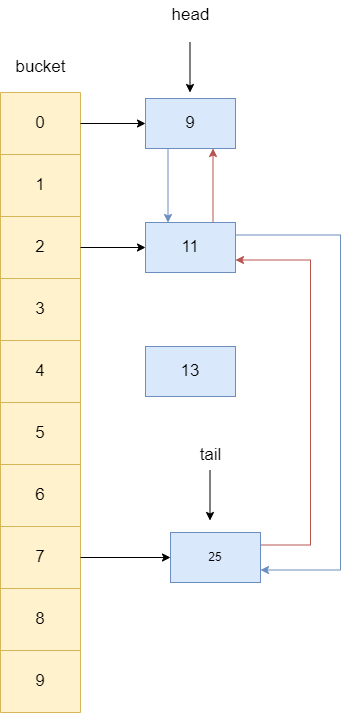
同理13后继节点若不为空,则让其指向13的前驱节点,所以25的前驱指针指向了11,最终13就变成没有被任何引用指向的对象,等待被gc。
再来看看源码,我们可以看到从HashMap继承来的remove方法内部调用的removeNode方法将节点从bucket删除后,调用了afterNodeRemoval。
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
//略
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
//HashMap的removeNode完成元素移除后会调用afterNodeRemoval进行移除后置操作
afterNodeRemoval(node);
return node;
}
}
return null;
}
//空实现
void afterNodeRemoval(Node<K,V> p) { }
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
查看afterNodeRemoval的源码,它的整体操作就是让当前节点p和前驱节点、后继节点断开联系,等待gc回收,整体步骤为:
- 获取当前节点p、以及e的前驱节点b和后继节点a。
- 让当前节点p和其前驱、后继节点断开联系。
- 尝试让前驱节点b指向后继节点a,若b为空则说明当前节点p在链表首部,我们直接将head指向后继节点a即可。
- 尝试让后继节点a指向前驱节点b,若a为空则说明当前节点p在链表末端,所以直接让tail指针指向前驱节点a即可。
void afterNodeRemoval(Node<K,V> e) { // unlink
//获取当前节点p、以及e的前驱节点b和后继节点a
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
//将p的前驱和后继指针都设置为null,使其和前驱、后继节点断开联系
p.before = p.after = null;
//如果前驱节点为空,则说明当前节点p是链表首节点,让head指针指向后继节点a即可
if (b == null)
head = a;
else
//如果前驱节点b不为空,则让b直接指向后继节点a
b.after = a;
//如果后继节点为空,则说明当前节点p在链表末端,所以直接让tail指针指向前驱节点a即可
if (a == null)
tail = b;
else
//反之后继节点的前驱指针直接指向前驱节点
a.before = b;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# put方法后置操作——afterNodeInsertion
同样的LinkedHashMap并没有实现插入方法,而是直接继承HashMap的所有插入方法交由用户使用,但为了维护双向链表访问的有序性,它做了这样两件事:
- 重写
afterNodeAccess(上文提到过),如果当前被插入的key已存在与map中,因为LinkedHashMap的插入操作会将新节点追加至链表末尾,所以对于存在的key则调用afterNodeAccess将其放到链表末端。 - 重写了
HashMap的afterNodeInsertion方法,当removeEldestEntry返回true时,会将链表首节点移除。
这一点我们可以在HashMap的插入操作核心方法putVal中看到。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
//略
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
//如果当前的key在map中存在,则调用afterNodeAccess
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
//调用插入后置方法,该方法被LinkedHashMap重写
afterNodeInsertion(evict);
return null;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
上述步骤的源码上文已经解释过了,所以这里我们着重了解一下afterNodeInsertion的工作流程,假设我们的重写了removeEldestEntry,当链表size()超过capacity时,就返回true。
/**
* 判断size超过容量时返回true,告知LinkedHashMap移除最近最少访问的元素(即链表的第一个元素)
* @param eldest
* @return
*/
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > capacity;
}
2
3
4
5
6
7
8
以下图为例,假设笔者最后新插入了一个不存在的节点19,假设capacity为4,所以removeEldestEntry返回true,我们要将链表首节点移除。
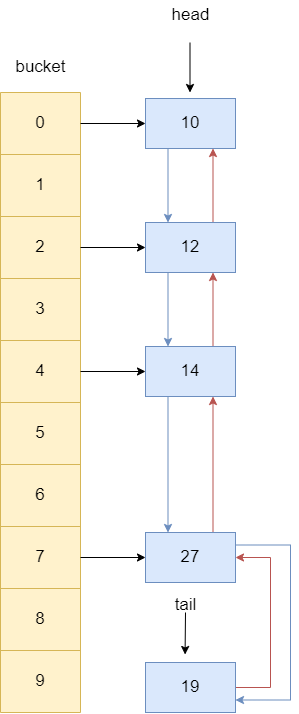
移除的步骤很简单,查看链表首节点是否存在,若存在则断开首节点和后继节点的关系,并让首节点指针指向下一节点,所以head指针指向了12,节点10成为没有任何引用指向的空对象,等待GC。
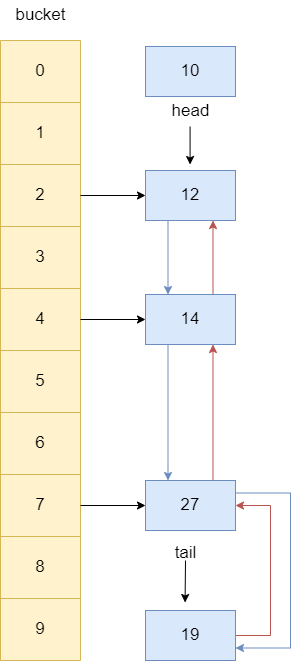
通过图解后我们查看源码,可以看到afterNodeInsertion执行步骤为:
- 判断eldest是否为true,只有为true才能说明可能需要将最年长的键值对(即链表首部的元素)进行移除,具体是否具体要进行移除,还得确定链表是否为空
((first = head) != null),以及removeEldestEntry方法是否返回true,只有这两个方法返回true才能确定当前链表不为空,且链表需要进行移除操作了。 - 获取链表第一个元素的key。
- 调用
HashMap的removeNode方法,该方法我们上文提到过,它会将节点从HashMap的bucket中移除,并且LinkedHashMap还重写了removeNode中的afterNodeRemoval方法,所以这一步将通过调用removeNode将元素从HashMap的bucket中移除,并和LinkedHashMap的双向链表断开,等待gc回收。
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
//如果evict为true且队首元素不为空以及removeEldestEntry返回true,则说明我们需要最老的元素(即在链表首部的元素)移除。
if (evict && (first = head) != null && removeEldestEntry(first)) {
//获取链表首部的键值对的key
K key = first.key;
//调用removeNode将元素从HashMap的bucket中移除,并和LinkedHashMap的双向链表断开,等待gc回收
removeNode(hash(key), key, null, false, true);
}
}
2
3
4
5
6
7
8
9
10
# removeEldestEntry
还记得我们上文中LRU缓存案例吗?我们继承LinkedHashMap后重写了空方法removeEldestEntry,该方法会在LinkedHashMap中的从HashMap继承的任何一个插入方法的后置方法中被调用到:
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
2
3
4
5
6
7
所以我们的LRU缓存就是通过重写该方法的逻辑,告知LinkedHashMap在链表的大小大于容量时就返回true,让LinkedHashMap将链表首元素移除。
/**
* 判断size超过容量时返回true,告知LinkedHashMap移除最近最少访问的元素(即链表的第一个元素)
* @param eldest
* @return
*/
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > capacity;
}
2
3
4
5
6
7
8
# LinkedHashMap和HashMap遍历性能比较
LinkedHashMap维护了一个双向链表来记录数据插入的顺序,因此在迭代遍历生成的迭代器的时候,是按照双向链表的路径进行遍历的。这一点相比于HashMap那种遍历整个bucket的方式来说,高效需多。
这一点我们可以从两者的迭代器中得以印证,先来看看HashMap的迭代器,可以看到HashMap迭代键值对时会用到一个nextNode方法,该方法会返回next指向的下一个元素,并会从next开始遍历bucket找到下一个bucket中不为空的元素Node。
final class EntryIterator extends HashIterator
implements Iterator<Map.Entry<K,V>> {
public final Map.Entry<K,V> next() { return nextNode(); }
}
//获取下一个Node
final Node<K,V> nextNode() {
Node<K,V>[] t;
//获取下一个元素next
Node<K,V> e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
//将next指向bucket中下一个不为空的Node
if ((next = (current = e).next) == null && (t = table) != null) {
do {} while (index < t.length && (next = t[index++]) == null);
}
return e;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
相比之下LinkedHashMap的迭代器则是直接使用通过after指针快速定位到当前节点的后继节点,简洁高效需多。
final class LinkedEntryIterator extends LinkedHashIterator
implements Iterator<Map.Entry<K,V>> {
public final Map.Entry<K,V> next() { return nextNode(); }
}
//获取下一个Node
final LinkedHashMap.Entry<K,V> nextNode() {
//获取下一个节点next
LinkedHashMap.Entry<K,V> e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
//current 指针指向当前节点
current = e;
//next直接当前节点的after指针快速定位到下一个节点
next = e.after;
return e;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
为了验证笔者所说的观点,笔者对这两个容器进行了压测,测试插入1000w和迭代1000w条数据的耗时,代码如下:
public static void main(String[] args) {
int count = 1000_0000;
Map<Integer, Integer> hashMap = new HashMap<>();
Map<Integer, Integer> linkedHashMap = new LinkedHashMap<>();
Long start, end;
start = System.currentTimeMillis();
for (int i = 0; i < count; i++) {
hashMap.put(RandomUtil.randomInt(1,count),RandomUtil.randomInt(1,count));
}
end = System.currentTimeMillis();
System.out.println("map time putVal: " + (end - start));
start = System.currentTimeMillis();
for (int i = 0; i < count; i++) {
linkedHashMap.put(RandomUtil.randomInt(1,count),RandomUtil.randomInt(1,count));
}
end = System.currentTimeMillis();
System.out.println("linkedHashMap putVal time: " + (end - start));
start = System.currentTimeMillis();
for (Integer v : hashMap.values()) {
}
end = System.currentTimeMillis();
System.out.println("map get time: " + (end - start));
start = System.currentTimeMillis();
for (Integer v : linkedHashMap.values()) {
}
end = System.currentTimeMillis();
System.out.println("linkedHashMap get time: " + (end - start));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
从输出结果来看,因为LinkedHashMap需要维护双向链表的缘故,相较于Hashmap会更耗时,但是有了双向链表明确的前后节点关系,迭代效率相对于前者高效了需多。
map time putVal: 6794
linkedHashMap putVal time: 7882
map get time: 131
linkedHashMap get time: 59
2
3
4
# LinkedHashMap常见面试题
# 什么是LinkedHashMap?
LinkedHashMap是Java集合框架中HashMap的一个子类,它继承了HashMap的所有属性和方法,并且在HashMap的基础重写了afterNodeRemoval、afterNodeInsertion、afterNodeAccess方法。使之拥有顺序插入和访问有序的特性。
# LinkedHashMap如何按照插入顺序迭代元素?
LinkedHashMap按照插入顺序迭代元素是它的默认行为。LinkedHashMap内部维护了一个双向链表,用于记录元素的插入顺序。因此,当使用迭代器迭代元素时,元素的顺序与它们最初插入的顺序相同。
# LinkedHashMap如何按照访问顺序迭代元素?
LinkedHashMap可以通过构造函数中的accessOrder参数指定按照访问顺序迭代元素。当accessOrder为true时,每次访问一个元素时,该元素会被移动到链表的末尾,因此下次访问该元素时,它就会成为链表中的最后一个元素,从而实现按照访问顺序迭代元素。
# LinkedHashMap如何实现LRU缓存?
将accessOrder设置为true并重写removeEldestEntry方法当链表大小超过容量时返回true,使得每次访问一个元素时,该元素会被移动到链表的末尾。一旦插入操作让removeEldestEntry返回true时,视为缓存已满,LinkedHashMap就会将链表首元素移除,由此我们就能实现一个LRU缓存。
void afterNodeInsertion(boolean evict) {
LinkedHashMap.Entry<K,V> first;
//如果首元素为空,且removeEldestEntry(用户需重写)返回true,则LinkedHashMap会将链表首元素移除
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
2
3
4
5
6
7
8
# LinkedHashMap和HashMap有什么区别?
LinkedHashMap和HashMap都是Java集合框架中的Map接口的实现类。它们的最大区别在于迭代元素的顺序。HashMap迭代元素的顺序是不确定的,而LinkedHashMap提供了按照插入顺序或访问顺序迭代元素的功能。
此外,LinkedHashMap内部维护了一个双向链表,用于记录元素的插入顺序或访问顺序,而HashMap则没有这个链表。因此,LinkedHashMap的插入性能可能会比HashMap略低,但它提供了更多的功能并且迭代效率相较于HashMap更加高效。
# 关于我
我是 sharkchili ,CSDN Java 领域博客专家,mini-redis的作者,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。

# 参考
LinkedHashMap 源码详细分析(JDK1.8:https://www.imooc.com/article/22931 (opens new window)
HashMap与LinkedHashMap:https://www.cnblogs.com/Spground/p/8536148.html#:~:text=LinkedHashMap 和 HashMap 性能的比较:在基本的 put,get remove 操作,两者的性能几乎相近,由于 LinkedHashMap 维护着一个双向链表,因此性能可能稍微差一点点。 (opens new window)
源于 LinkedHashMap源码:https://leetcode.cn/problems/lru-cache/solution/yuan-yu-linkedhashmapyuan-ma-by-jeromememory/ (opens new window)
