 Java8流式编程入门
Java8流式编程入门
# 流的基础示例
# 需求描述
我们现在有一个菜肴类,其定义如下:
public class Dish {
/**
* 名称
*/
private final String name;
/**
* 是否是素食
*/
private final boolean vegetarian;
/**
* 卡路里
*/
private final int calories;
/**
* 类型
*/
private final Type type;
//类型枚举 分别是是:肉类 鱼类 其他
public enum Type {MEAT, FISH, OTHER}
public Dish(String name, boolean vegetarian, int calories, Type type) {
this.name = name;
this.vegetarian = vegetarian;
this.calories = calories;
this.type = type;
}
public String getName() {
return name;
}
public boolean isVegetarian() {
return vegetarian;
}
public int getCalories() {
return calories;
}
public Type getType() {
return type;
}
@Override
public String toString() {
return name;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
基于这个类,我们初始化一个菜肴集合:
public static final List<Dish> menu =
Arrays.asList( new Dish("pork", false, 800, Dish.Type.MEAT),
new Dish("beef", false, 700, Dish.Type.MEAT),
new Dish("chicken", false, 400, Dish.Type.MEAT),
new Dish("french fries", true, 530, Dish.Type.OTHER),
new Dish("rice", true, 350, Dish.Type.OTHER),
new Dish("season fruit", true, 120, Dish.Type.OTHER),
new Dish("pizza", true, 550, Dish.Type.OTHER),
new Dish("prawns", false, 400, Dish.Type.FISH),
new Dish("salmon", false, 450, Dish.Type.FISH));
2
3
4
5
6
7
8
9
10
我们希望从中筛选出400卡的菜肴名,并且我们希望筛选出来的结果按照热量升序排列。
# 使用java8之前的做法
使用java8之前版本的写法步骤比较繁琐,逻辑也很清晰,整体步骤为:
- 筛选出400卡以下的菜肴。
- 创建一个匿名比较器,并基于这个比较器对菜肴进行升序排列。
- 将排列后的菜肴集合的名字存入字符串列表。
- 输出结果。
public static void main(String[] args) {
List<Dish> lowCaloricDishes = new ArrayList<>();
//赛选出小于400卡的菜肴
for (Dish d : menu) {
if (d.getCalories() < 400) {
lowCaloricDishes.add(d);
}
}
//按照升序进行排序
List<String> lowCaloricDishesName = new ArrayList<>();
Collections.sort(lowCaloricDishes, new Comparator<Dish>() {
public int compare(Dish d1, Dish d2) {
return Integer.compare(d1.getCalories(), d2.getCalories());
}
});
//存入string列表
for (Dish d : lowCaloricDishes) {
lowCaloricDishesName.add(d.getName());
}
//输出
for (Dish lowCaloricDish : lowCaloricDishes) {
System.out.println(lowCaloricDish);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
对应输出结果如下,season fruit为120卡,rice为350卡,符合预期:
season fruit
rice
2
# jdk8的做法
jdk8的写法相较于之前版本要简洁很多,它将集合视作一个流,并基于这个集合的流实现筛选、排序、映射等组合操作。
public static void main(String[] args) {
menu.stream()
//找出低于400卡的菜肴
.filter(d -> d.getCalories() < 400)
//按照升序排列
.sorted(comparing(Dish::getCalories))
//得到这些菜肴的名称
.map(Dish::getName)
//组成list
.collect(toList())
//输出结果
.forEach(m -> System.out.println(m));
}
2
3
4
5
6
7
8
9
10
11
12
13
# 流式编程简介
# 流的优势
- 声明性:流式编程的所有操作都是语义化的,我们完全可以通过方法名大致猜出操作目的。
- 可复合:流式编程无需像jdk8之前的版本为了实现组合操作而取创建各种临时集合,取而代之的是基于一段连续的流自顶而下的实现组合操作。
- 可并行:当我们需要提高计算密集型任务的性能时,只需将
stream改为parallelStream,就可以开启并行流开启多个线程一起工作(默认情况下,线程数和计算机的CPU核心数是一样的)。
public static List<String> getLowCaloricDishesNamesInJava8(List<Dish> dishes) {
return dishes.parallelStream()
//找出低于400卡的菜肴
.filter(d -> d.getCalories() < 400)
//按照升序排列
.sorted(comparing(Dish::getCalories))
//得到这些菜肴的名称
.map(Dish::getName)
//组成list
.collect(toList());
}
2
3
4
5
6
7
8
9
10
11
- 流水线:流式编程会将组合操作构成一个大的流水线,这使得我们代码能够更进一步优化,例如延迟和短路操作,使得代码可以实现类似于数据库式的查询。
- 内部迭代:流式编程将迭代操作封装起来,对开发者透明,如此一来,开发者专注与对流内部的元素的操作,而无需关注繁琐的非业务代码。
# 流的工作原理
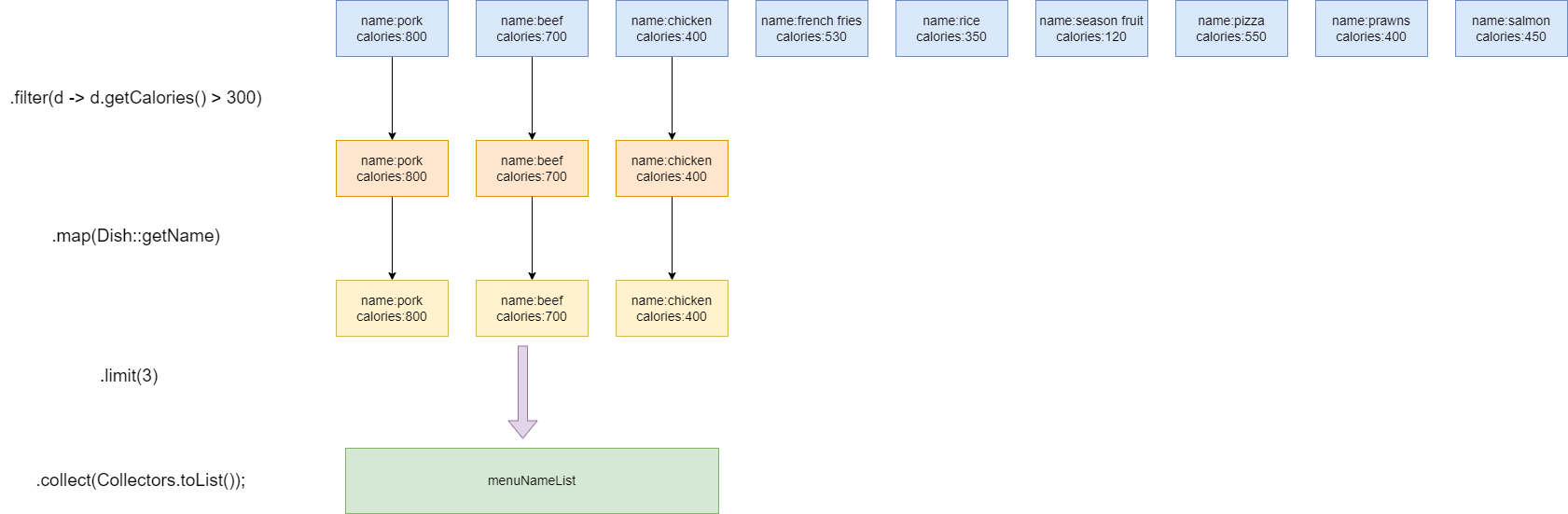
这个例子的目的是从菜肴中找到前三个菜肴大于300卡的菜名:
public static void main(String[] args) {
List<String> menuNameList = menu.stream()
//找到大于300卡的菜肴
.filter(d -> d.getCalories() > 300)
//取出这个菜肴的名称
.map(Dish::getName)
//取前3个
.limit(3)
//存入list中
.collect(Collectors.toList());
//输出结果
System.out.println(menuNameList);
}
2
3
4
5
6
7
8
9
10
11
12
13
流式编程的工作原理非常高效,它将组合操作作为一条工作的流水线,将集合中的每一个元素都放到这个流水线上进行工作,所以对于上面的代码,它的工作过程是这样的:
- 拿到
pork,进入filter操作,因为其热量大于300卡,继续走到流水线下一个步骤。 - 进入
map操作,拿到pork对象的name。 - 进入
limit操作,pork还在limit限定范围,继续走到下一个操作。 - 进入
toList操作,将pork存入list中。 - 同理对
beef和chicken完成同样的操作,然后limit达到上限,停止流水线。
所以和指令时编程比较起来,流式操作更像是互联网观看视频,只有用户观看到某一分钟时才会去加载需要的数据。而jdk8之前的集合操作更像是DVD加载视频,必须将整张光盘数据都加载完成了,用户才能按需跳到需要的片段。
# 流与集合的关系
# 每一个集合的流只能使用一次
如下代码所示,每一个集合对应的流只能操作一次,每次操作完成之后这个流就会被关闭,这意味着用户再次使用这个流就会报错:
List<String> strings = Arrays.asList("java8", "in", "action");
Stream<String> stream = strings.stream();
stream.forEach(System.out::println);
stream.forEach(System.out::println);
2
3
4
输出结果如下,可以看到对于同一个流的多次操作抛出IllegalStateException错误:
java8
Exception in thread "main" java.lang.IllegalStateException: stream has already been operated upon or closed
in
action
at java.util.stream.AbstractPipeline.sourceStageSpliterator(AbstractPipeline.java:279)
at java.util.stream.ReferencePipeline$Head.forEach(ReferencePipeline.java:580)
at com.sharkChili.lambda.Main.main(Main.java:27)
2
3
4
5
6
7
8
9
10
# 集合的外部迭代和流的内部迭代
流式编程将循环操作内置,对于用户是无感的,如下代码所示,我们使用peek方法打印经过这个组合操作的元素有哪些:
public static void main(String[] args) {
List<String> menuNameList = menu.stream()
//找到大于300卡的菜肴
.filter(d -> d.getCalories() > 300)
.peek(d -> System.out.println("步骤1:" + d))
//取出这个菜肴的名称
.map(Dish::getName)
.peek(d -> System.out.println("步骤2:" + d))
//取前3个
.limit(3)
.peek(d -> System.out.println("步骤3:" + d))
//存入list中
.collect(Collectors.toList());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
我们就会得到这样一个结果,可以看到每一个元素都会依次经过filter、和map、limit,这就是jdk8流式编程的循环合并技术:
步骤1:pork
步骤2:pork
步骤3:pork
步骤1:beef
步骤2:beef
步骤3:beef
步骤1:chicken
步骤2:chicken
步骤3:chicken
2
3
4
5
6
7
8
9
# 流的两种操作
# 中间操作
例如filter、map、limit、sort等只涉及元素的流水线单一步骤且最终会返回stream类型的方法都是中间操作,它们只有在调用终端操作(即真正要结果的方法)才会开始工作:
filter:过滤出符合预期的元素,如果不符合预期就不会走到流水线的下一步。map:映射,将流水线的A元素转为B元素,例如上文示例中基于Menu的name字段将Menu对象转为String对象。limit:截取前n个对象,例如上文limit(3),这意味着流水线收集到3个元素之后就停止工作。sorted:排序操作,将流水线的元素按照指定顺序排序。distinct:去重,收集当前流水线上不重复的元素。
# 终端操作
终端操作通俗的理解就是将中间操作得到的元素放到流水线的终点开始真正的输出,一旦中间操作得到的元素都经过终端操作后,这个流就会被关闭。例如上文中经过filter、map、limit得到的元素都走到collect这个收集元素的终端操作后,流就关闭了,一旦我们再次使用这个流就会报错。
java8而对应的终端操作有:
forEach:将中间操作得到的元素进行一次遍历。count:统计中间操作得到的元素个数,个数的类型为long类型。collect:将中间操作得到的元素归为一个集合。
# 参考文献
Java 8 in Action:https://book.douban.com/subject/25912747/ (opens new window)
