 Linux线程管理
Linux线程管理
[toc]
# 写在文章开头
本文将从操作系统底层深入探究线程的诞生及其出色的设计理念和调度策略,通过对本文的阅读,你将对计算机程序设计的基本理念和设计思想有更深入的掌握。
我是 SharkChili ,Java 开发者,Java Guide 开源项目维护者。欢迎关注我的公众号:写代码的SharkChili,也欢迎您了解我的开源项目 mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)。
为方便与读者交流,现已创建读者群。关注上方公众号获取我的联系方式,添加时备注加群即可加入。
# 详解线程结构设计与常见问题
# 线程的历史和基本理念
传统操作系统的理念下,进程是一个相对重量级的单位,本质上都是由一个地址空间和一个控制线程构成。对于现代计算机而言,许多的应用活动会随着时间的推移而陷入阻塞。于是就有了基于进程这一单位衍生出一个更加轻量级的准并行运行单位——线程。
通过多个轻量级线程共享进程的地址空间和所有可用的数据,以更加轻量级的方式快速完成多道工序并销毁,创建效率比进程快10~100倍,在保证降低开销的同时提升程序执行效率。 这种设计理念在现代操作系统中会带来质的提升,例如一个支持查找、全局替换、生成分页的字处理软件,在单线程的情况下,针对如下工作都可以通过一条指令一次性对整个文档进行全局管理:
- 文本检查
- 指定文字替换
- 生成页分隔符
对此我们试想一下这样一个场景,我们的字处理软件收到一个300页的未整理过的文件,此时我们希望定位到600页并删除某一行数据,在原有的单线程模型模式下,对应处理步骤则是:
- 整理文件,确定分页
- 定位到指定数据行
- 删除数据,重新分页
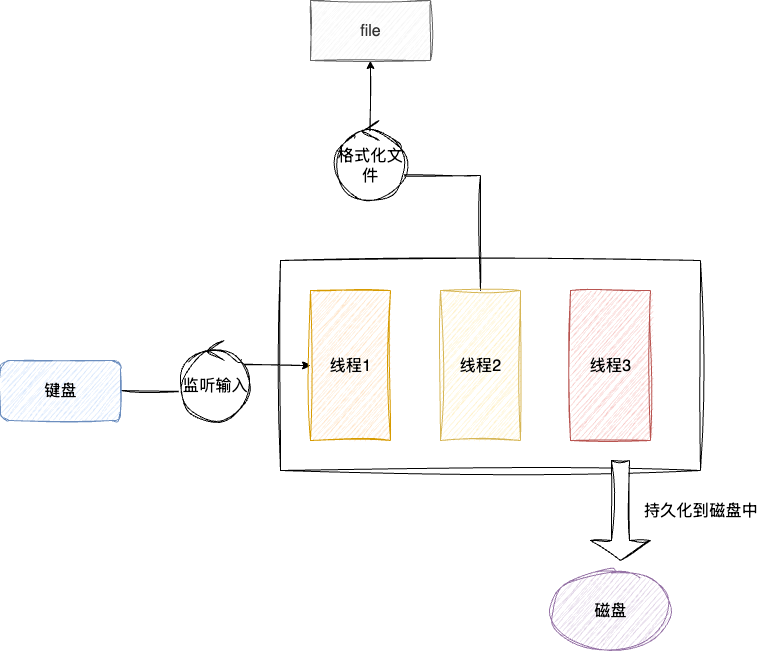
这种模式就意味着如果在分页未完成之前,步骤二和步骤三就无法执行。此时我们就可以引入多线程的方案,分别建立:
- 一个后台写入刷盘持久化
- 自动分页格式化建立分隔符
- 读取键盘输入
这3个线程并行处理这些工作,在理想的情况下,我们的修改操作完全可以在格式化线程处理完成之后,快速定位到600页数据完成修改,通过多线程尽可能利用CPU时间片,完成文件处理的各个工序,避免单线程阻塞带来的耗时等待,这就是多线程的设计哲学:
# 线程基本数据结构分配
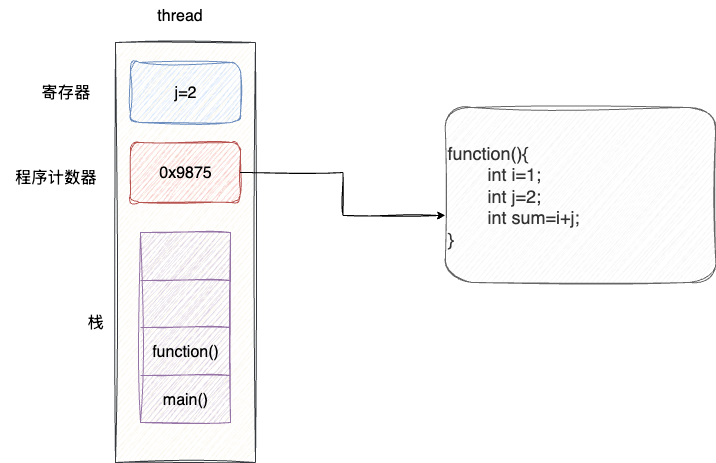
以同一个进程为例,针对单一进程的职责,开发者可以拆解并创建出多个线程,共享进程的地址空间和内存数据、文件描述符和环境变量信息,并在多核CPU下并行执行,对应的每个线程都具备如下组件:
- 程序计数器:记录接下来要执行的指令
- 寄存器:保存程序当前的工作变量
- 堆栈:记录每个线程的执行历史,例如本示例中的线程通过main调用function1,通过栈帧就可以记录调用历史完成过程调用和返回
由于线程具备进程的部分特质,所以线程常常也被称之为轻量级进程:
# 线程的基本使用示例
关于线程的基本使用,我们从更加接近于底层的C语言展开探究,在Linux系统下,通过C语言内置的库函数就可以完成线程的基本创建和使用,如下代码我们以线程1为例:
- 通过
pthread_create指明线程执行的函数thread_function_1、通过参数3传值给thread_function_1告知线程id号,并通过返回值确定线程是否成功创建 - 通过
join使其加入主线程,确保该线程完成执行后才能推出 - 通过
pthread_exit结束线程的调用
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
// 线程函数1
void* thread_function_1(void* arg) {
int thread_id = *(int*)arg;
for (int i = 0; i < 5; i++) {
printf("线程%d正在执行: %d\n", thread_id, i);
sleep(1); // 模拟工作
}
printf("线程%d执行完毕\n", thread_id);
pthread_exit(NULL);
}
// 线程函数2
void* thread_function_2(void* arg) {
char* message = (char*)arg;
printf("线程2收到消息: %s\n", message);
printf("线程2执行完毕\n");
pthread_exit(NULL);
}
int main() {
pthread_t thread1, thread2;
int id1 = 1;
// 创建第一个线程
int result1 = pthread_create(&thread1, NULL, thread_function_1, &id1);
if (result1 != 0) {
fprintf(stderr, "创建线程1失败\n");
exit(EXIT_FAILURE);
}
// 创建第二个线程
char* msg = "hello thread-2";
int result2 = pthread_create(&thread2, NULL, thread_function_2, msg);
if (result2 != 0) {
fprintf(stderr, "创建线程2失败\n");
exit(EXIT_FAILURE);
}
// 等待线程1结束
pthread_join(thread1, NULL);
printf("主线程: 线程1已结束\n");
// 等待线程2结束
pthread_join(thread2, NULL);
printf("主线程: 线程2已结束\n");
printf("所有线程执行完毕,主线程结束\n");
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
对应的输出结果如下,读者可以参考笔者的说明调试理解一下线程的基本使用:
线程1正在执行: 0
线程2收到消息: hello thread-2
线程2执行完毕
线程1正在执行: 1
线程1正在执行: 2
线程1正在执行: 3
线程1正在执行: 4
线程1执行完毕
主线程: 线程1已结束
主线程: 线程2已结束
所有线程执行完毕,主线程结束
2
3
4
5
6
7
8
9
10
11
# 线程的调度
Linux系统操作的哲学是,线程调度也是非常灵活的。若我们的线程执行一个长耗时的任务,希望线程自动让出CPU,就可以通过yield函数让CPU执行其他线程的任务,它仅仅提示操作系统当前线程愿意让出CPU,具体是否采纳这个提示,完全由操作系统决定,所以这也就是为什么笔者的实践中会补充一个sleep阻塞式调用来提升yield的概率:
Thread t1 = new Thread(() -> {
Thread.currentThread().setName("t1");
for (int i = 0; i < 100; i++) {
if (i == 10) {
System.out.println("t1先执行,把cpu时间片让给t2");
Thread.yield();
//利用sleep阻塞式调用更有效的让出CPU时间片
ThreadUtil.sleep(400);
}
}
System.out.println("t1执行结束");
});
Thread t2 = new Thread(() -> {
Thread.currentThread().setName("t2");
ThreadUtil.sleep(100);
System.out.println("t2再执行,把cpu时间片让给t1");
Thread.yield();
});
t1.start();
t2.start();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
若我们希望一个线程可以阻塞等待其他线程完成后结束,则可以通过join函数。但需要注意的是,下面的示例展示的是守护线程的使用方式:
Thread thread = new Thread(() -> {
ThreadUtil.sleep(5000);
System.out.println("子线程执行完成");
});
// 将线程设置为守护线程
thread.setDaemon(true);
System.out.println("启动子线程...");
thread.start();
// 主线程等待2秒后就结束,不等待子线程执行完成
ThreadUtil.sleep(2000);
System.out.println("主线程执行结束");
// 不调用thread.join()方法,主线程直接结束
// 由于子线程是守护线程,当主线程结束时,JVM会直接退出,不会等待守护线程完成
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 详解线程栈的基本调用
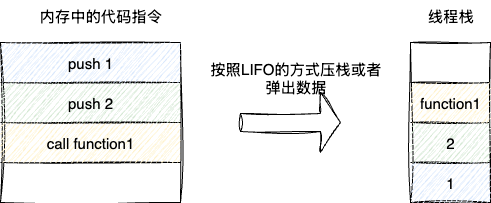
上文提及,线程是作为进程的基本单位,所以同一个进程中的多线程会共享进程的地址空间和数据。为避免临界资源共享时数据竞争操作的开销,操作系统为每个线程都分配了栈,所有数据或者函数调用都会通过push或者pop操作并按照LIFO的方式压入或者弹出堆栈,与此同时CPU还有一个RSP寄存器始终会指向栈顶的位置,保证数据压入或者弹出的准确性。
除了push和pop以外,线程还支持通过call指令将函数压入栈中,例如我们代码中调用function,对应的就是call指令完成function调用,此时对应的function函数地址压入栈中,随后函数调用结束,再通过ret指令返回函数调用前的地址:
因为函数调用涉及多参传入等问题,所以对于传参顺序也有一定的约定,例如在某些调用约定中参数自左向右压入栈中,确保CPU执行函数指令的正确性。但是随着计算机的发展,计算机的寄存器也在原有的8个通用寄存器的基础上增加了R8~R15寄存器,对应函数的参数可以直接存放在CPU的寄存器而非线程栈(内存中),大大提升函数执行效率。
# 线程栈的内存分配策略
线程的栈最大容量为8MB,对应的我们可以通过ulimit指令查看,但操作系统并不是一开始就分配这么大的内存空间,毕竟如果为操作系统成百上千的线程分配这么大一块内存空间作为线程栈,是一种非必要的浪费。默认情况下线程初始情况下仅仅分配几个页面,当空间不足时会触发缺页中断,再动态扩容,直到8MB,如果超了就会抛出stack overflow,这也就是为什么递归调用会时常报错的原因:
sharkchili@xxx-xxx:/tmp$ ulimit -a |grep stack
stack size (kbytes, -s) 8192
2
当然,线程运行时也会涉及一些中断、异常或者系统调用,为保证操作系统的安全避免重要信息在用户层暴露,线程的内核态调用都会在内核栈中开辟一个4~8KB大小的内核栈作为内核调用的历史记录维护栈。基于此内核栈说明了线程栈对于程序运行的安全性也是至关重要的,在互联网发展早期涉及线程栈的调用,黑客就会利用线程栈回溯的特性,在修改ret指令前修改跳转地址,然后注入恶意指令完成线程的劫持与攻击,这就是大名鼎鼎的缓冲区溢出攻击。
# 用户态线程和内核态线程的探究
关于线程的创建一般是有两种方式,即用户态创建和内核态创建,我们先来说第一种实现方式——用户空间实现线程,创建即线程的计数器、寄存器、堆栈都交由开发者自实现线程包,这种方式有着如下优点:
- 可以在不支持线程的操作系统下高效运行
- 在用户级空间,可以灵活调控线程切换,在进行任务切换时也不会涉及内核态的调用,更加高效和轻量级
- 因为所有的线程数行管理,对应的进程都会维护一份专用的线程表,所以可以灵活的涉及线程的调度算法和策略
唯一的缺陷是这些线程模型设计对于内核是感知不到的,从系统内核角度来看这个线程就是一个单线程进程,无法感知内核态调用的阻塞,即无法感知IO就绪而进行read调用,从而使得这些线程全部阻塞停止:
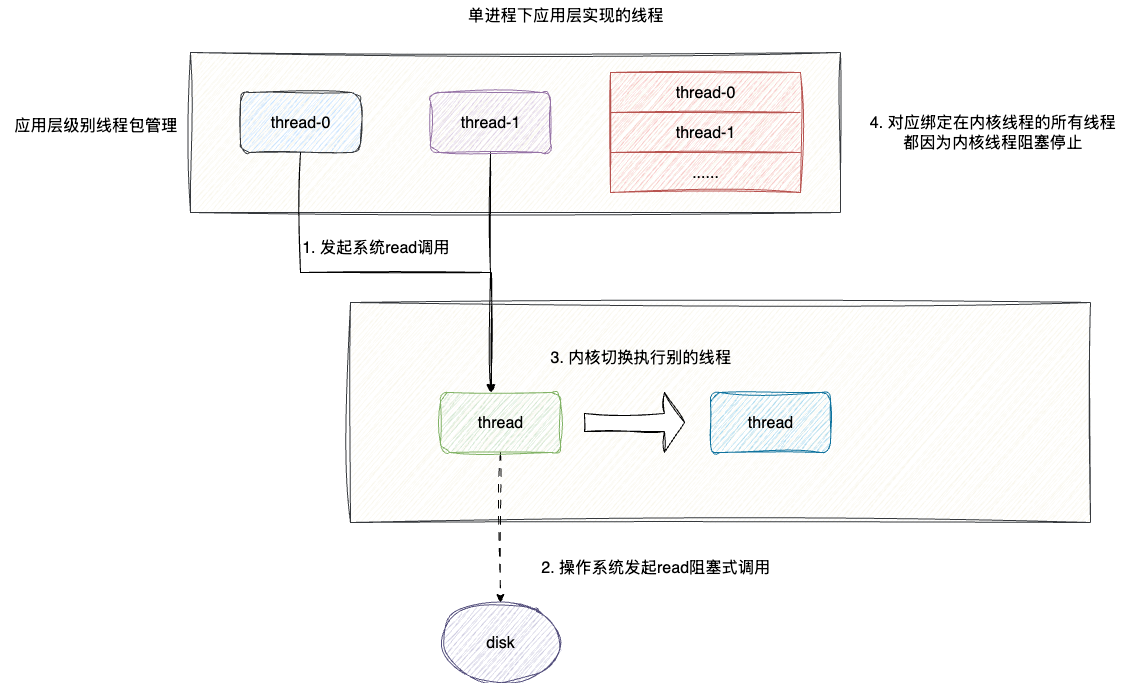
相比之下内核态线程的创建都在内核态中统一管理一个线程的线程表,在进行系统阻塞式调用时会主动进行线程表的更新工作,同时会根据调度策略从就绪的线程队列中指定一个线程获得CPU时间片。虽然大量线程创建、操作、终止开销相较于用户线程更大,但是内核可以非常方便地检查和管理操作系统中的所有线程,管理更加方便,这也就是目前传统编程中的一对一线程模型:
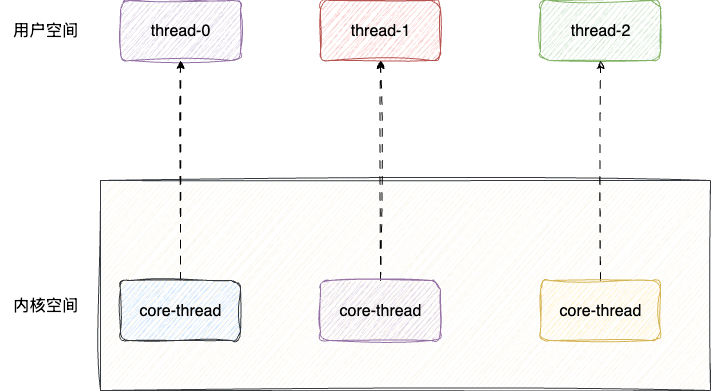
综上所述,操作系统哲学也提出一种多对多的线程创建理念,即多个用户态线程绑定一个内核态线程,应用层开辟线程组绑定一个内核态线程,使得用户级线程和内核线程构成一个多路复用的关系,既延续了用户级线程的轻量级调度,又拥有了内核级别的系统调用切换管理,通过多对多的绑定避免了大量用户态级别的线程阻塞,又避免了大量线程创建、终止的系统级开销:
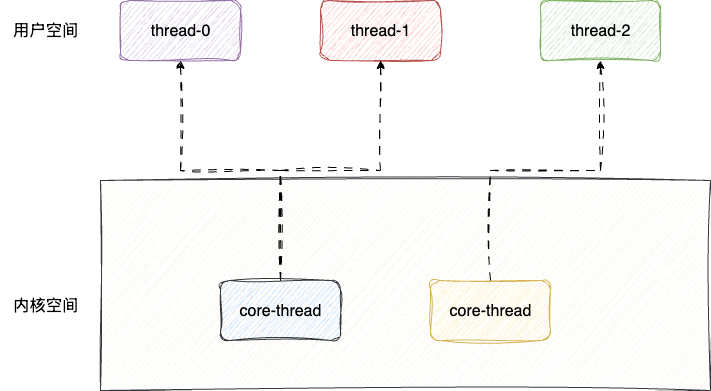
# 小结
本文简单介绍了:
- 线程的发展和设计理念,介绍了线程的诞生
- 线程的寄存器、栈、程序计数器作用
- 线程栈LIFO特性和push、pop流程,以及内核栈、缓冲区溢出攻击等问题
- 线程之间的关系和操作系统的调度策略
- 线程的基本创建、终止以及yield切换和调度以及线程间的阻塞join等待
- 线程内核调用阻塞切换的开销以及用户态线程和内核态线程创建的优秀设计理念
我是 SharkChili ,Java 开发者,Java Guide 开源项目维护者。欢迎关注我的公众号:写代码的SharkChili,也欢迎您了解我的开源项目 mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)。
为方便与读者交流,现已创建读者群。关注上方公众号获取我的联系方式,添加时备注加群即可加入。
# 参考
《趣话计算机底层技术》 《现代操作系统》
一文搞懂【线程】:https://blog.csdn.net/bufangbufang/article/details/144293546 (opens new window) 深入理解Java线程的yield()方法:原理、应用与陷阱:https://blog.csdn.net/weixin_51786043/article/details/147397017 (opens new window)
